Best AI tools for< Data Engineer >
Infographic
100 - AI tool Sites

Eztrackr
Eztrackr is an AI-powered application designed to help job seekers organize their job hunt efficiently. It offers features such as job tracking, AI answer generation, skill matching, cover letter generation, resume building, and powerful statistics to streamline the job search process. With Eztrackr, users can track job applications effortlessly, gain valuable insights, and manage their job hunt all in one place.
Granica
Granica is an AI tool designed for data compression and optimization, enabling users to transform petabytes of data into terabytes through self-optimizing, lossless compression. It works seamlessly across various data platforms like Iceberg, Delta, Trino, Spark, Snowflake, BigQuery, and Databricks, offering significant cost savings and improved query performance. Granica is trusted by data and AI leaders globally for its ability to reduce data bloat, speed up queries, and enhance data lake optimization. The tool is built for structured AI, providing transparent deployment, continuous adaptation, hands-off orchestration, and trusted controls for data security and compliance.

babs.ai
babs.ai is an AI-powered job matching platform that connects talent with opportunities. It leverages intelligent matching algorithms to streamline the recruitment process and ensure a seamless experience for both job seekers and employers. The platform caters to a wide range of job roles and industries, making it a versatile solution for all types of users.
Lume AI
Lume AI is an AI-powered data mapping suite that automates the process of mapping, cleaning, and validating data in various workflows. It offers a comprehensive solution for building pipelines, onboarding customer data, and more. With AI-driven insights, users can streamline data analysis, mapper generation, deployment, and maintenance. Lume AI provides both a no-code platform and API integration options for seamless data mapping. Trusted by market leaders and startups, Lume AI ensures data security with enterprise-grade encryption and compliance standards.
Accio
Accio is a data modeling tool that allows users to define consistent relationships, metrics, and expressions for on-the-fly computations in reports and dashboards across various BI tools. It provides a syntax similar to GraphQL that allows users to define models, relationships, and metrics in a human-readable format. Accio also offers a user-friendly interface that provides data analysts with a holistic view of the relationships between their data models, enabling them to grasp the interconnectedness and dependencies within their data ecosystem. Additionally, Accio utilizes DuckDB as a caching layer to accelerate query performance for BI tools.
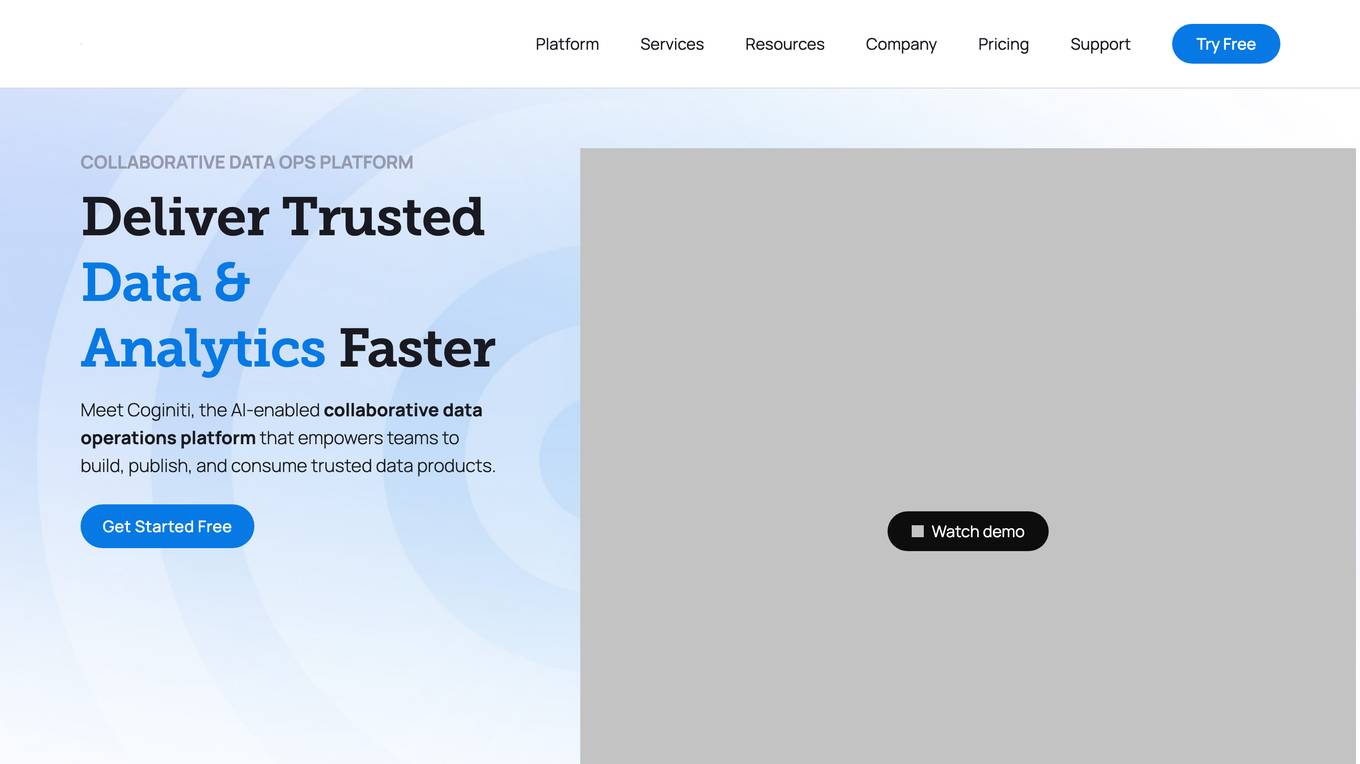
Coginiti
Coginiti is a collaborative analytics platform and tools designed for SQL developers, data scientists, engineers, and analysts. It offers capabilities such as AI assistant, data mesh, database & object store support, powerful query & analysis, and share & reuse curated assets. Coginiti empowers teams and organizations to manage collaborative practices, data efficiency, and deliver trusted data products faster. The platform integrates modular analytic development, collaborative versioned teamwork, and a data quality framework to enhance productivity and ensure data reliability. Coginiti also provides an AI-enabled virtual analytics advisor to boost team efficiency and empower data heroes.
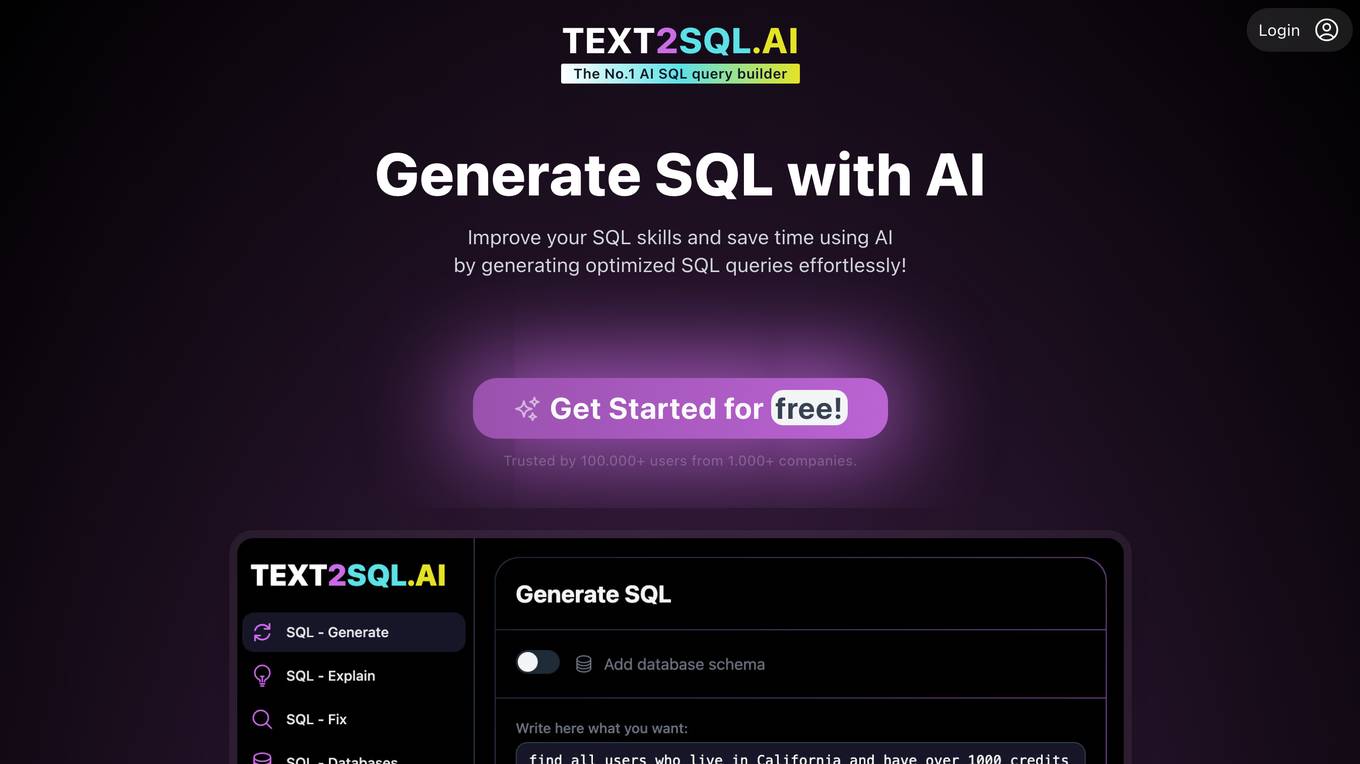
Text2SQL.AI
Text2SQL.AI is an AI-powered SQL query builder that helps users generate optimized SQL queries effortlessly. It supports various AI-powered services, including SQL query building from textual instructions, SQL query explanation to plain English, SQL query error fixation, adding custom database schemas, SQL dialects for various database types, Microsoft Excel and Google Sheets formula generation and explanation, and Regex expression generation and explanation. The tool is designed to improve SQL skills, save time, and assist beginners, data analysts, data scientists, data engineers, and software developers in their work.
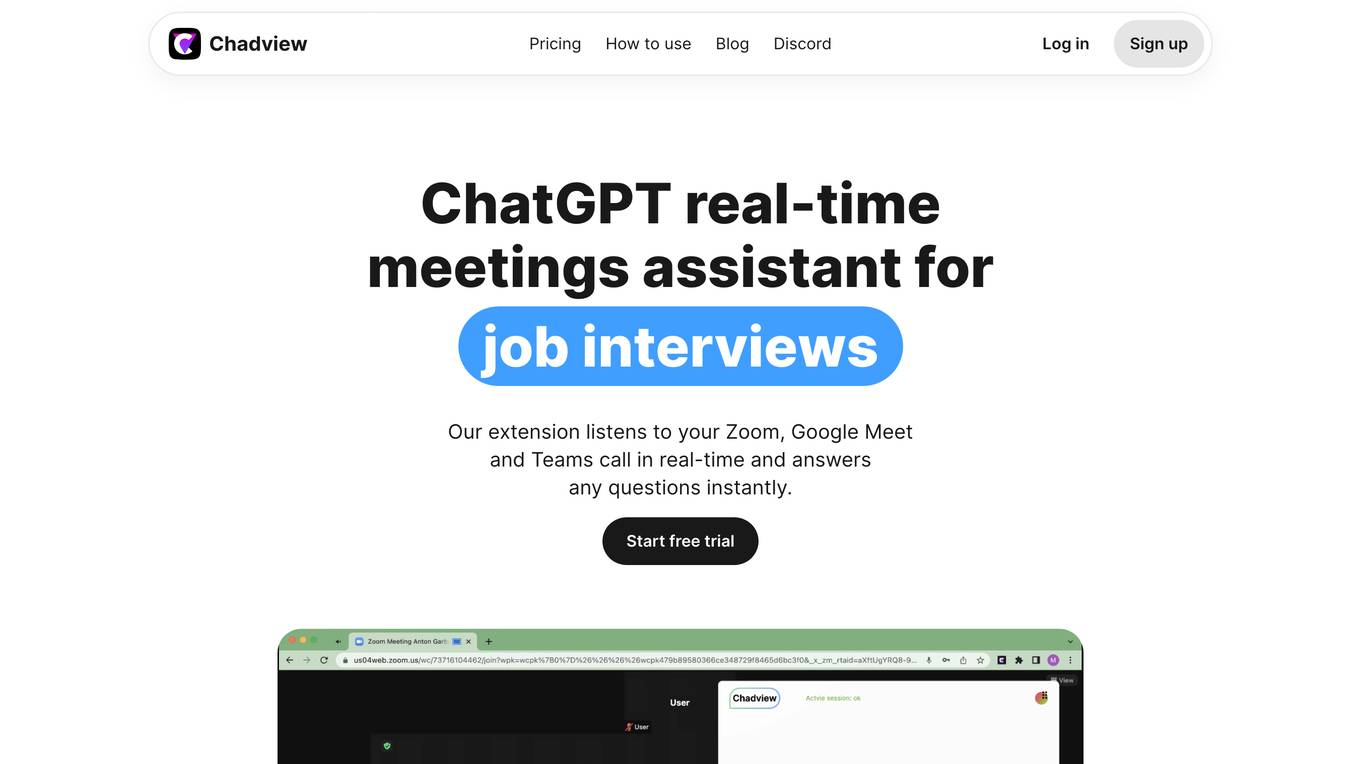
Chadview
Chadview is a real-time meetings assistant powered by ChatGPT that helps you answer questions during job interviews. It listens to your Zoom, Google Meet, or Teams call and provides instant answers to any questions asked. Chadview is easy to use, simply install the Chrome extension and start your free trial. It supports multiple languages and can be used for any technical role. Chadview is a valuable tool for anyone looking to improve their performance in job interviews.
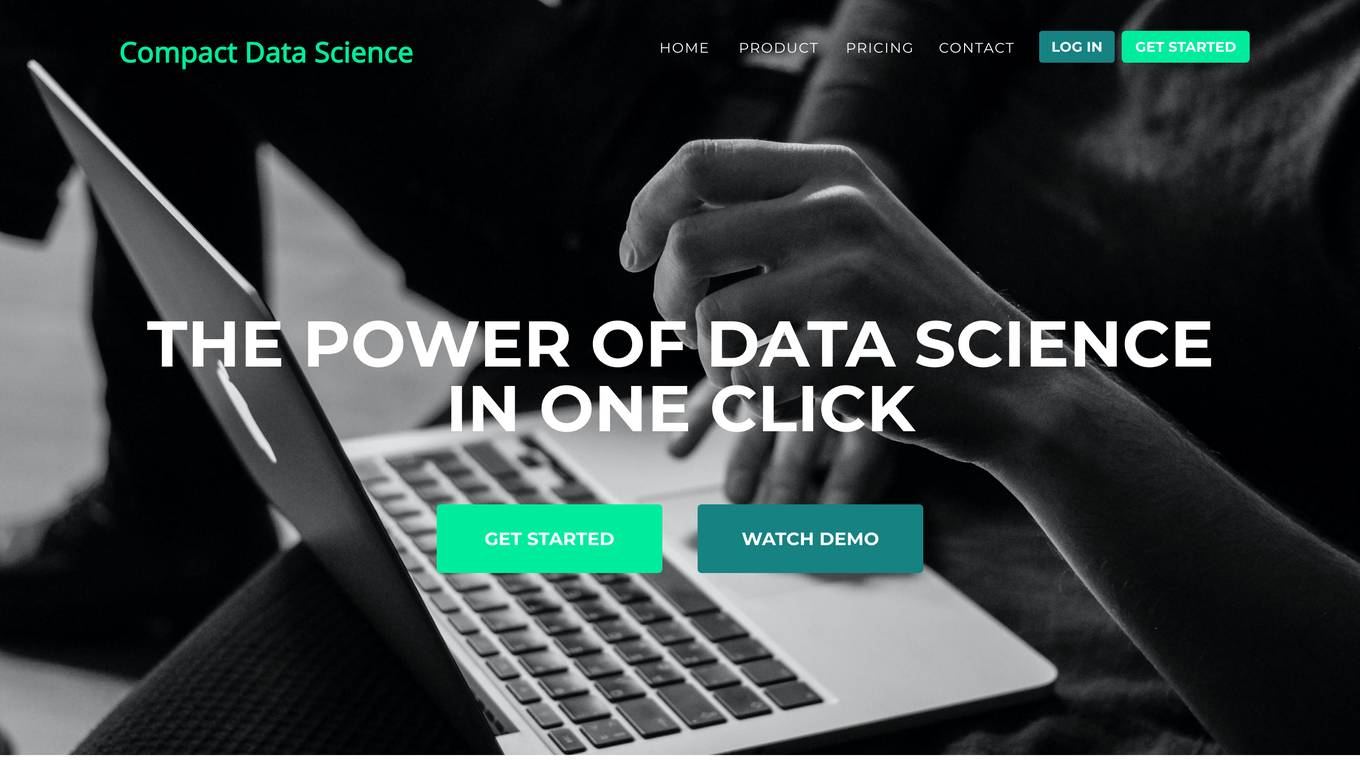
Compact Data Science
Compact Data Science is a data science platform that provides a comprehensive set of tools and resources for data scientists and analysts. The platform includes a variety of features such as data preparation, data visualization, machine learning, and predictive analytics. Compact Data Science is designed to be easy to use and accessible to users of all skill levels.

SID
SID is a data ingestion, storage, and retrieval pipeline that provides real-time context for AI applications. It connects to various data sources, handles authentication and permission flows, and keeps information up-to-date. SID's API allows developers to retrieve the right piece of data for a given task, enabling them to build AI apps that are fast, accurate, and scalable. With SID, developers can focus on building their products and leave the data management to SID.

NLSQL
NLSQL is a B2B SaaS tool that empowers employees with an intuitive text interface to inform and speed up business decisions with significant benefits for enterprises. It works as the first NLP to SQL API, which doesn't require any sensitive or confidential data transfer outside the corporate IT ecosystem. NLSQL supports integrations to all main database types and corporate messengers, which helps drive businesses forward faster with data-driven business decisions.
Latitude
Latitude is an open-source framework for building interactive data apps using code. It provides a workspace for data analysts to streamline their workflow, connect to various data sources, perform data transformations, create visualizations, and collaborate with others. Latitude aims to simplify the data analysis process by offering features such as data snapshots, a data profiler, a built-in AI assistant, and tight integration with dbt.
Defog.ai
Defog.ai provides fine-tuned AI models for enterprise SQL. It helps businesses speed up data analyses in SQL, Python, and R with AI assistants and agents tailored for their business - without sharing their data. Defog.ai's key features include the ability to ask questions of data in natural language, get results when needed, integrate with any SQL database or data warehouse, automatically visualize data as tables and charts, and fine-tune on your metadata to give results you can trust.

Amazon Q in QuickSight
Amazon Q in QuickSight is a generative BI assistant that makes it easy to build and consume insights. With Amazon Q, BI users can build, discover, and share actionable insights and narratives in seconds using intuitive natural language experiences. Analysts can quickly build visuals and calculations and refine visuals using natural language. Business users can self-serve data and insights using natural language. Amazon Q is built with security and privacy in mind. It can understand and respect your existing governance identities, roles, and permissions and use this information to personalize its interactions. If a user doesn't have permission to access certain data without Amazon Q, they can't access it using Amazon Q either. Amazon Q in QuickSight is designed to meet the most stringent enterprise requirements from day one—none of your data or Amazon Q inputs and outputs are used to improve underlying models of Amazon Q for anyone but you.
CodeSquire
CodeSquire is an AI-powered code writing assistant that helps data scientists, engineers, and analysts write code faster and more efficiently. It provides code completions and suggestions as you type, and can even generate entire functions and SQL queries. CodeSquire is available as a Chrome extension and works with Google Colab, BigQuery, and JupyterLab.

Ocular
Ocular is an AI-powered search platform that allows users to search, visualize, and take action on their work and engineering tools and data on one unified platform. It is designed to help engineers work more efficiently and effectively by providing them with a single, central location to access all of their relevant information.

Qubinets
Qubinets is a cloud data environment solutions platform that provides building blocks for building big data, AI, web, and mobile environments. It is an open-source, no lock-in, secured, and private platform that can be used on any cloud, including AWS, Digital Ocean, Google Cloud, and Microsoft Azure. Qubinets makes it easy to plan, build, and run data environments, and it streamlines and saves time and money by reducing the grunt work in setup and provisioning.
Tredence
Tredence is a data science and AI services company that provides end-to-end solutions for businesses across various industries. The company's services include data engineering, data analytics, AI consulting, and machine learning operations (MLOps). Tredence has a team of experienced data scientists and engineers who use their expertise to help businesses solve complex data challenges and achieve their business goals.

RIDO Protocol
RIDO Protocol is a decentralized data protocol that allows users to extract value from their personal data in Web2 and Web3. It provides users with a variety of features, including programmable data generation, programmable access control, and cross-application data sharing. RIDO also has a data marketplace where users can list or offer their data information and ownership. Additionally, RIDO has a DataFi protocol which promotes the flowing of data information and value.
DataCamp
DataCamp is an online learning platform that offers courses in data science, AI, and machine learning. The platform provides interactive exercises, short videos, and hands-on projects to help learners develop the skills they need to succeed in the field. DataCamp also offers a variety of resources for businesses, including team training, custom content development, and data science consulting.
Appen
Appen is a leading provider of high-quality data for training AI models. The company's end-to-end platform, flexible services, and deep expertise ensure the delivery of high-quality, diverse data that is crucial for building foundation models and enterprise-ready AI applications. Appen has been providing high-quality datasets that power the world's leading AI models for decades. The company's services enable it to prepare data at scale, meeting the demands of even the most ambitious AI projects. Appen also provides enterprises with software to collect, curate, fine-tune, and monitor traditionally human-driven tasks, creating massive efficiencies through a trustworthy, traceable process.
Radicalbit
Radicalbit is an MLOps and AI Observability platform that helps businesses deploy, serve, observe, and explain their AI models. It provides a range of features to help data teams maintain full control over the entire data lifecycle, including real-time data exploration, outlier and drift detection, and model monitoring in production. Radicalbit can be seamlessly integrated into any ML stack, whether SaaS or on-prem, and can be used to run AI applications in minutes.
Seudo
Seudo is a data workflow automation platform that uses AI to help businesses automate their data processes. It provides a variety of features to help businesses with data integration, data cleansing, data transformation, and data analysis. Seudo is designed to be easy to use, even for businesses with no prior experience with AI. It offers a drag-and-drop interface that makes it easy to create and manage data workflows. Seudo also provides a variety of pre-built templates that can be used to get started quickly.
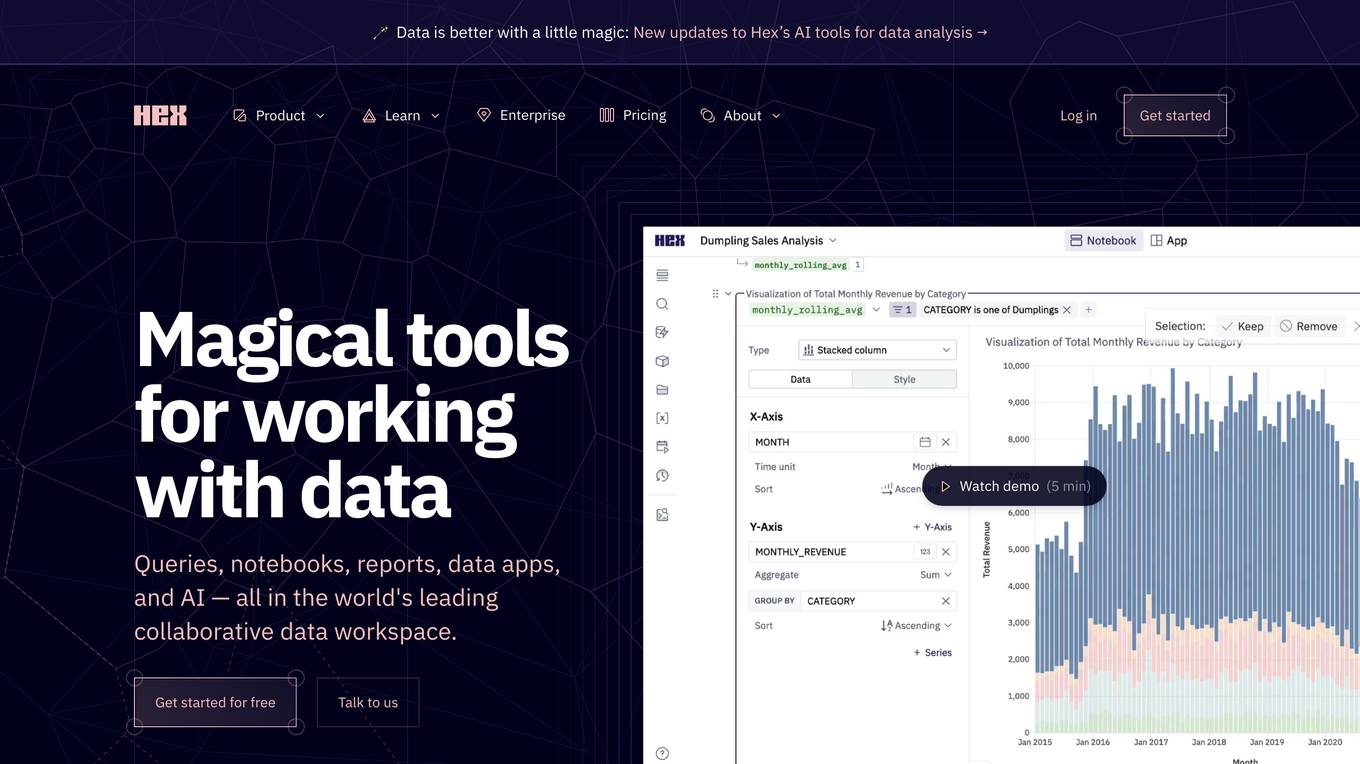
Hex
Hex is a collaborative data workspace that provides a variety of tools for working with data, including queries, notebooks, reports, data apps, and AI. It is designed to be easy to use for people of all technical skill levels, and it integrates with a variety of other tools and services. Hex is a powerful tool for data exploration, analysis, and visualization.
Domino Data Lab
Domino Data Lab is an enterprise AI platform that enables data scientists and IT leaders to build, deploy, and manage AI models at scale. It provides a unified platform for accessing data, tools, compute, models, and projects across any environment. Domino also fosters collaboration, establishes best practices, and tracks models in production to accelerate and scale AI while ensuring governance and reducing costs.
Databricks
Databricks is a data and AI company that provides a unified platform for data, analytics, and AI. The platform includes a variety of tools and services for data management, data warehousing, real-time analytics, data engineering, data science, and AI development. Databricks also offers a variety of integrations with other tools and services, such as ETL tools, data ingestion tools, business intelligence tools, AI tools, and governance tools.
Datamation
Datamation is a leading industry resource for B2B data professionals and technology buyers. Datamation’s focus is on providing insight into the latest trends and innovation in AI, data security, big data, and more, along with in-depth product recommendations and comparisons. More than 1.7M users gain insight and guidance from Datamation every year.
ConsciousML
ConsciousML is a blog that provides in-depth and beginner-friendly content on machine learning, data engineering, and productivity. The blog covers a wide range of topics, including ML model deployment, data pipelines, deep work, data engineering, and more. The articles are written by experts in the field and are designed to help readers learn about the latest trends and best practices in machine learning and data engineering.

Tableau Augmented Analytics
Tableau Augmented Analytics is a class of analytics powered by artificial intelligence (AI) and machine learning (ML) that expands a human’s ability to interact with data at a contextual level. It uses AI to make analytics accessible so that more people can confidently explore and interact with data to drive meaningful decisions. From automated modeling to guided natural language queries, Tableau's augmented analytics capabilities are powerful and trusted to help organizations leverage their growing amount of data and empower a wider business audience to discover insights.

Supersimple
Supersimple is an AI-native data analytics platform that combines a semantic data modeling layer with the ability to answer ad hoc questions, giving users reliable, consistent data to power their day-to-day work.
ChatDBT
ChatDBT is a DBT designer with prompting that helps you write better DBT code. It provides a user-friendly interface that makes it easy to create and edit DBT models, and it includes a number of features that can help you improve the quality of your code.
Tableau
Tableau is a visual analytics platform that helps people see, understand, and act on data. It is used by organizations of all sizes to solve problems, make better decisions, and improve operations. Tableau's platform is intuitive and easy to use, making it accessible to people of all skill levels. It also offers a wide range of features and capabilities, making it a powerful tool for data analysis and visualization.
KNIME
KNIME is a data science platform that enables users to analyze, blend, transform, model, visualize, and deploy data science solutions without coding. It provides a range of features and advantages for business and domain experts, data experts, end users, and MLOps & IT professionals across various industries and departments.
Dataiku
Dataiku is an end-to-end platform for data and AI projects. It provides a range of capabilities, including data preparation, machine learning, data visualization, and collaboration tools. Dataiku is designed to make it easy for users to build, deploy, and manage AI projects at scale.
Goptimise
Goptimise is a no-code AI-powered scalable backend builder that helps developers craft scalable, seamless, powerful, and intuitive backend solutions. It offers a solid foundation with robust and scalable infrastructure, including dedicated infrastructure, security, and scalability. Goptimise simplifies software rollouts with one-click deployment, automating the process and amplifying productivity. It also provides smart API suggestions, leveraging AI algorithms to offer intelligent recommendations for API design and accelerating development with automated recommendations tailored to each project. Goptimise's intuitive visual interface and effortless integration make it easy to use, and its customizable workspaces allow for dynamic data management and a personalized development experience.
Snaplet
Snaplet is a data management tool for developers that provides AI-generated dummy data for local development, end-to-end testing, and debugging. It uses a real programming language (TypeScript) to define and edit data, ensuring type safety and auto-completion. Snaplet understands database structures and relationships, automatically transforming personally identifiable information and seeding data accordingly. It integrates seamlessly into development workflows, providing data where it's needed most: on local machines, for CI/CD testing, and preview environments.
Alteryx
Alteryx offers a leading AI Platform for Enterprise Analytics that delivers actionable insights by automating analytics. The platform combines the power of data preparation, analytics, and machine learning to help businesses make better decisions faster. With Alteryx, businesses can connect to a wide variety of data sources, prepare and clean data, perform advanced analytics, and build and deploy machine learning models. The platform is designed to be easy to use, even for non-technical users, and it can be deployed on-premises or in the cloud.
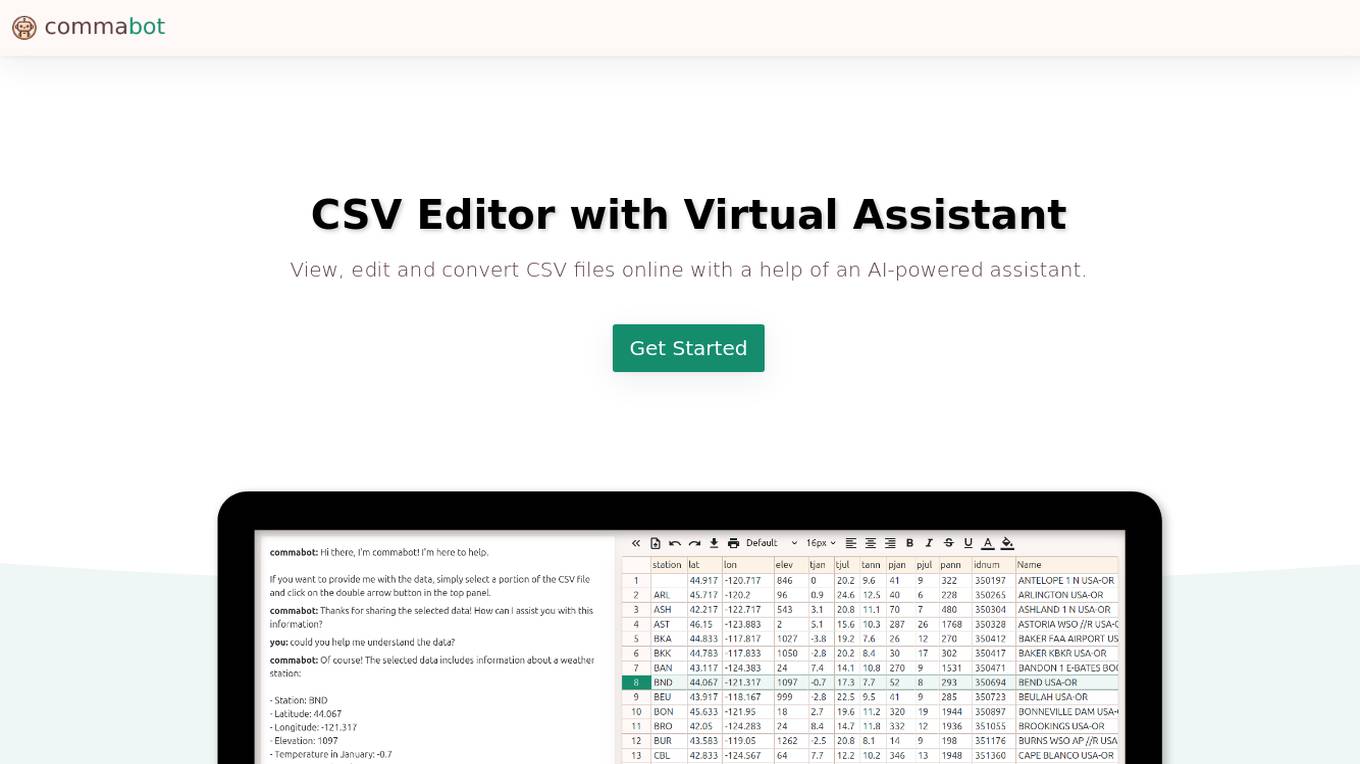
Commabot
Commabot is an online CSV editor that allows users to view, edit, and convert CSV files with the help of an AI-powered assistant. It features an intuitive spreadsheet interface, data operations capabilities, an AI virtual assistant, and transformation and conversion functionalities.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
Stack Overflow Blog
The Stack Overflow Blog is a platform that provides insights, updates, and discussions on various topics related to software development, technology, AI/ML, and career advice. It offers a space for developers and technologists to collaborate, share knowledge, and engage with the community. The blog covers a wide range of subjects, including product releases, podcast episodes, and industry trends. Users can explore articles, podcasts, and announcements to stay informed and connected with the tech community.
Databricks
Databricks is a data and AI company that offers a Data Intelligence Platform to help users succeed with AI by developing generative AI applications, democratizing insights, and driving down costs. The platform maintains data lineage, quality, control, and privacy across the entire AI workflow, enabling users to create, tune, and deploy generative AI models. Databricks caters to industry leaders, providing tools and integrations to speed up success in data and AI. The company offers resources such as support, training, and community engagement to help users succeed in their data and AI journey.
Innodata Inc.
Innodata Inc. is a global data engineering company that delivers AI-enabled software platforms and managed services for AI data collection/annotation, AI digital transformation, and industry-specific business processes. They provide a full-suite of services and products to power data-centric AI initiatives using artificial intelligence and human expertise. With a 30+ year legacy, they offer the highest quality data and outstanding service to their customers.
DevRev
DevRev is an AI-native modern support platform that offers a comprehensive solution for customer experience enhancement. It provides data engineering, knowledge graph, and customizable LLMs to streamline support, product management, and software development processes. With features like in-browser analytics, consumer-grade social collaboration, and global scale API calls, DevRev aims to bring together different silos within a company to drive efficiency and collaboration. The platform caters to support people, product managers, and developers, automating tasks, assisting in decision-making, and elevating collaboration levels. DevRev is designed to empower digital product teams to assimilate customer feedback in real-time, ultimately powering the next generation of technology companies.
Getin.AI
Getin.AI is a platform that focuses on AI jobs, career paths, and company profiles in the fields of artificial intelligence, machine learning, and data science. Users can explore various job categories, such as Analyst, Consulting, Customer Service & Support, Data Science & Analytics, Engineering, Finance & Accounting, HR & Recruiting, Legal, Compliance and Ethics, Marketing & PR, Product, Sales And Business Development, Senior Management / C-level, Strategy & M&A, and UX, UI & Design. The platform provides a comprehensive list of remote job opportunities and features detailed job listings with information on job titles, companies, locations, job descriptions, and required skills.
Supertype
Supertype is a full-cycle data science consultancy offering a range of services including computer vision, custom BI development, managed data analytics, programmatic report generation, and more. They specialize in providing tailored solutions for data analytics, business intelligence, and data engineering services. Supertype also offers services for developing custom web dashboards, computer vision research and development, PDF generation, managed analytics services, and LLM development. Their expertise extends to implementing data science in various industries such as e-commerce, mobile apps & games, and financial markets. Additionally, Supertype provides bespoke solutions for enterprises, advisory and consulting services, and an incubator platform for data scientists and engineers to work on real-world projects.
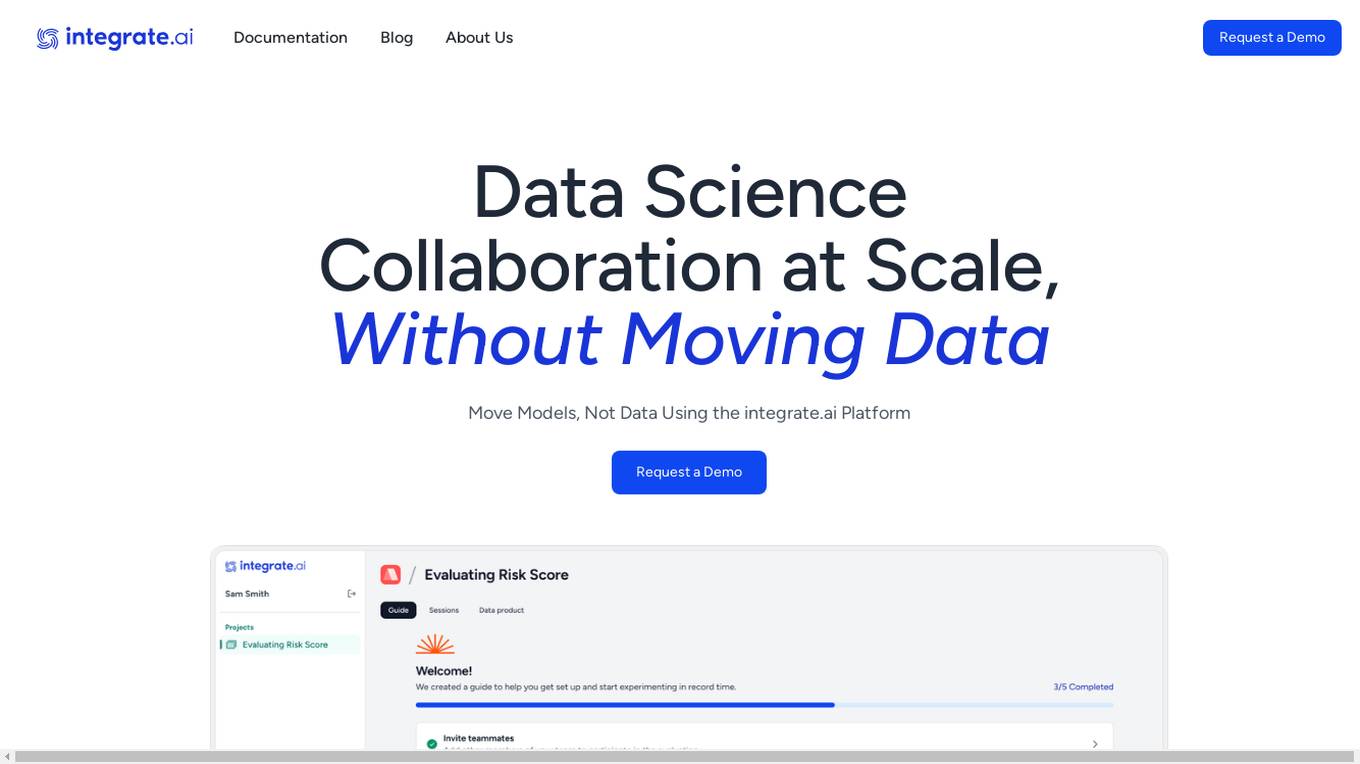
integrate.ai
integrate.ai is a platform that enables data and analytics providers to collaborate easily with enterprise data science teams without moving data. Powered by federated learning technology, the platform allows for efficient proof of concepts, data experimentation, infrastructure agnostic evaluations, collaborative data evaluations, and data governance controls. It supports various data science jobs such as match rate analysis, exploratory data analysis, correlation analysis, model performance analysis, feature importance & data influence, and model validation. The platform integrates with popular data science tools like Azure, Jupyter, Databricks, AWS, GCP, Snowflake, Pandas, PyTorch, MLflow, and scikit-learn.

ChatViz
ChatViz is an AI-powered data visualization tool that leverages ChatGPT to enhance data visualization capabilities. It offers features such as SQL translator and chart suggestion to streamline the visualization process. By utilizing ChatViz, users can optimize development time, simplify data visualization, and say goodbye to dashboard complexity. The tool provides a new way to visualize data, reducing development time and improving user experience.
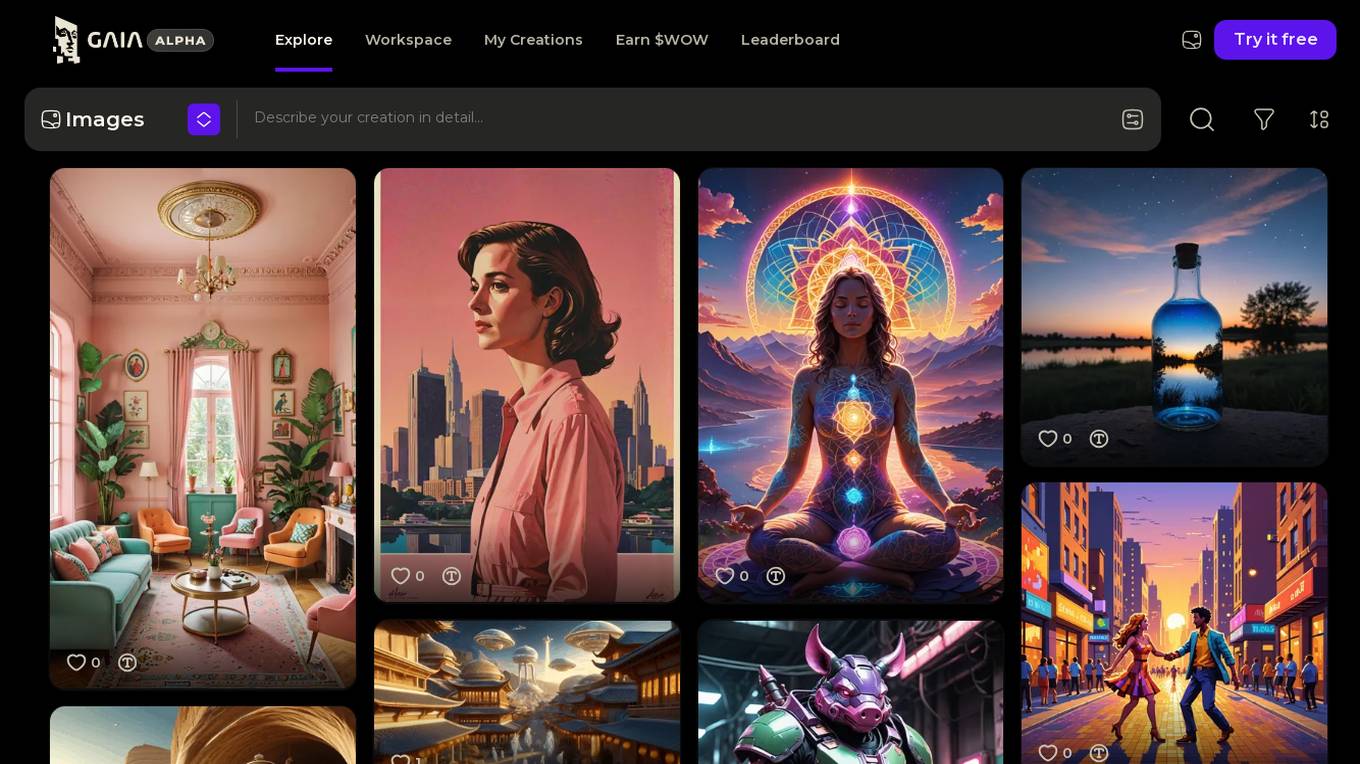
GAIA
GAIA is a powerful creation engine designed for the AI Age. It provides users with advanced tools and capabilities to develop AI applications, machine learning models, and data analytics solutions. With a user-friendly interface and robust features, GAIA empowers individuals and organizations to harness the potential of artificial intelligence for various projects and initiatives. Whether you are a data scientist, developer, or AI enthusiast, GAIA offers a comprehensive platform to bring your ideas to life and drive innovation in the rapidly evolving AI landscape.
Sicara
Sicara is a data and AI expert platform that helps clients define and implement data strategies, build data platforms, develop data science products, and automate production processes with computer vision. They offer services to improve data performance, accelerate data use cases, integrate generative AI, and support ESG transformation. Sicara collaborates with technology partners to provide tailor-made solutions for data and AI challenges. The platform also features a blog, job offers, and a team of experts dedicated to enhancing productivity and quality in data projects.
Teraflow.ai
Teraflow.ai is an AI-enablement company that specializes in helping businesses adopt and scale their artificial intelligence models. They offer services in data engineering, ML engineering, AI/UX, and cloud architecture. Teraflow.ai assists clients in fixing data issues, boosting ML model performance, and integrating AI into legacy customer journeys. Their team of experts deploys solutions quickly and efficiently, using modern practices and hyper scaler technology. The company focuses on making AI work by providing fixed pricing solutions, building team capabilities, and utilizing agile-scrum structures for innovation. Teraflow.ai also offers certifications in GCP and AWS, and partners with leading tech companies like HashiCorp, AWS, and Microsoft Azure.
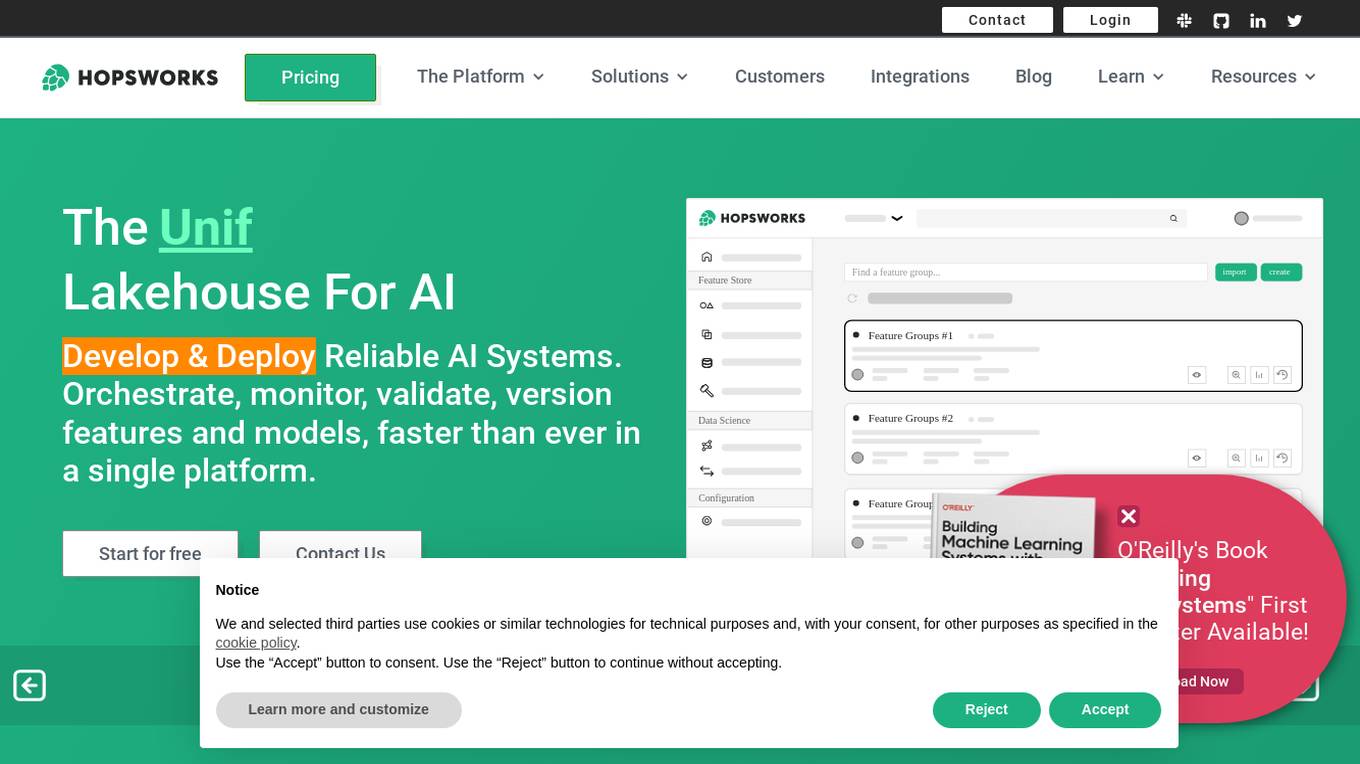
Hopsworks
Hopsworks is an AI platform that offers a comprehensive solution for building, deploying, and monitoring machine learning systems. It provides features such as a Feature Store, real-time ML capabilities, and generative AI solutions. Hopsworks enables users to develop and deploy reliable AI systems, orchestrate and monitor models, and personalize machine learning models with private data. The platform supports batch and real-time ML tasks, with the flexibility to deploy on-premises or in the cloud.
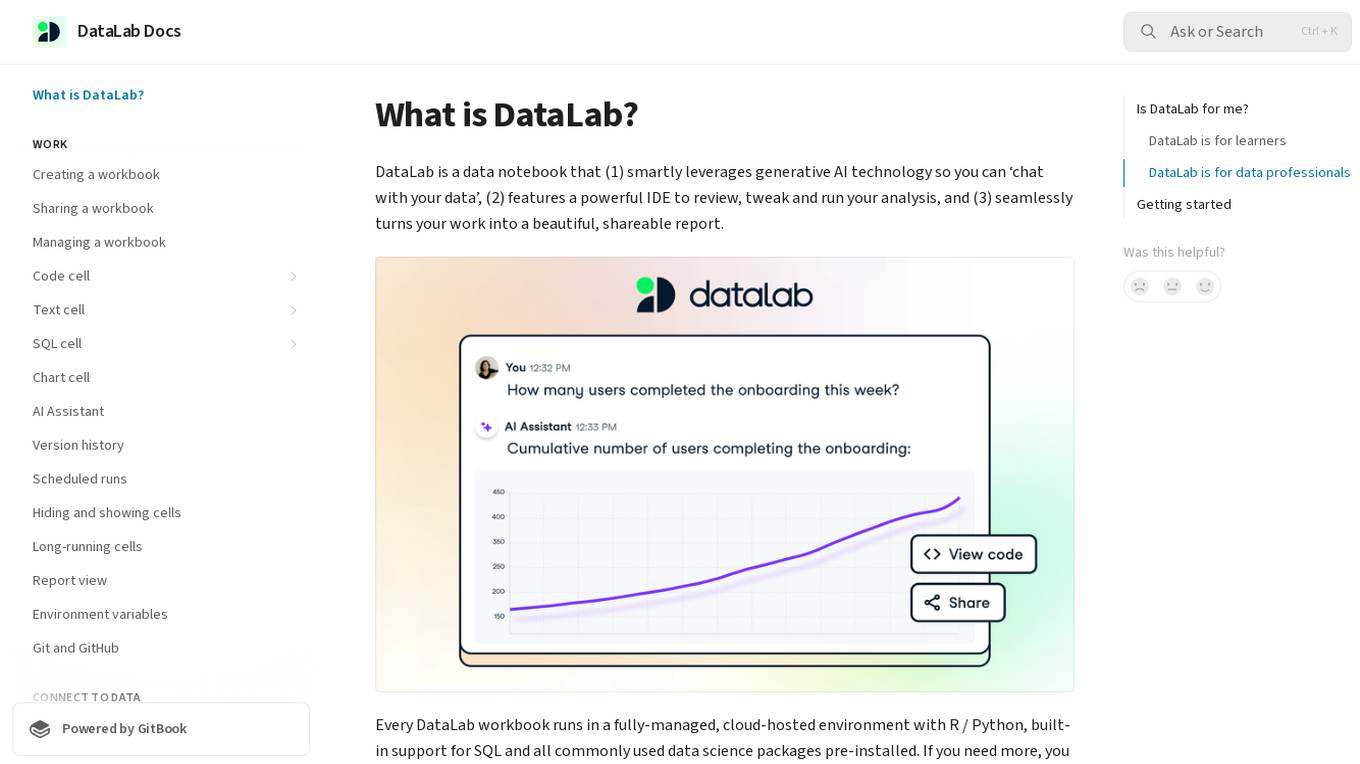
DataLab
DataLab is a data notebook that smartly leverages generative AI technology to enable users to 'chat with their data'. It features a powerful IDE for analysis, and seamlessly transforms work into shareable reports. The application runs in a cloud-hosted environment with support for R/Python, SQL, and various data science packages. Users can connect to external databases, collaborate in real-time, and utilize an AI Assistant for code generation and error correction.
New Relic
New Relic is an AI monitoring platform that offers an all-in-one observability solution for monitoring, debugging, and improving the entire technology stack. With over 30 capabilities and 750+ integrations, New Relic provides the power of AI to help users gain insights and optimize performance across various aspects of their infrastructure, applications, and digital experiences.
Alluxio
Alluxio is a data orchestration platform designed for the cloud, offering seamless access, management, and running of AI/ML workloads. Positioned between compute and storage, Alluxio provides a unified solution for enterprises to handle data and AI tasks across diverse infrastructure environments. The platform accelerates model training and serving, maximizes infrastructure ROI, and ensures seamless data access. Alluxio addresses challenges such as data silos, low performance, data engineering complexity, and high costs associated with managing different tech stacks and storage systems.
Sherloq
Sherloq is an AI-powered platform designed for SQL users in data-driven teams. It provides a single source of truth for SQL data, offering deep analysis capabilities and time-saving features. With a focus on accessibility and collaboration, Sherloq allows users to get quick answers to specific questions, share insights with saved queries, and manage SQL repositories efficiently. The platform prioritizes data security, being SOC2 Audit certified, and requires no integrations into user data or metadata. Sherloq is trusted by over 1000 SQL users and is recognized for its fast growth and user satisfaction.
PandasAI
PandasAI is an open-source AI tool designed for conversational data analysis. It allows users to ask questions in natural language to their enterprise data and receive real-time data insights. The tool is integrated with various data sources and offers enhanced analytics, actionable insights, detailed reports, and visual data representation. PandasAI aims to democratize data analysis for better decision-making, offering enterprise solutions for stable and scalable internal data analysis. Users can also fine-tune models, ingest universal data, structure data automatically, augment datasets, extract data from websites, and forecast trends using AI.
Magic Regex Generator
Magic Regex Generator is an AI-powered tool that simplifies the process of generating, testing, and editing Regular Expression patterns. Users can describe what they want to match in English, and the AI generates the corresponding regex in the editor for testing and refining. The tool is designed to make working with regex easier and more efficient, allowing users to focus on meaningful tasks without getting bogged down in complex pattern matching.
Dot Group Data Advisory
Dot Group is an AI-powered data advisory and solutions platform that specializes in effective data management. They offer services to help businesses maximize the potential of their data estate, turning complex challenges into profitable opportunities using AI technologies. With a focus on data strategy, data engineering, and data transport, Dot Group provides innovative solutions to drive better profitability for their clients.
DQLabs
DQLabs is a modern data quality platform that leverages observability to deliver reliable and accurate data for better business outcomes. It combines the power of Data Quality and Data Observability to enable data producers, consumers, and leaders to achieve decentralized data ownership and turn data into action faster, easier, and more collaboratively. The platform offers features such as data observability, remediation-centric data relevance, decentralized data ownership, enhanced data collaboration, and AI/ML-enabled semantic data discovery.
Dflux
Dflux is a cloud-based Unified Data Science Platform that offers end-to-end data engineering and intelligence with a no-code ML approach. It enables users to integrate data, perform data engineering, create customized models, analyze interactive dashboards, and make data-driven decisions for customer retention and business growth. Dflux bridges the gap between data strategy and data science, providing powerful SQL editor, intuitive dashboards, AI-powered text to SQL query builder, and AutoML capabilities. It accelerates insights with data science, enhances operational agility, and ensures a well-defined, automated data science life cycle. The platform caters to Data Engineers, Data Scientists, Data Analysts, and Decision Makers, offering all-round data preparation, AutoML models, and built-in data visualizations. Dflux is a secure, reliable, and comprehensive data platform that automates analytics, machine learning, and data processes, making data to insights easy and accessible for enterprises.

PurpleCube.ai
PurpleCube.ai is an AI-powered platform that revolutionizes data engineering by unifying, automating, and activating data processes. The platform offers real-time Gen AI assistance to enhance data team productivity, efficiency, and accuracy. PurpleCube.ai empowers data experts to drive business innovation, collaborate seamlessly, and deliver impactful business value through advanced analytics and data engineering capabilities. The platform is trusted by various enterprises globally for its comprehensive metadata management, governance, and generative AI features.

File Transcribe
File Transcribe is an AI-powered application that offers accurate and effortless transcription of audio and video files. The platform utilizes advanced AI technology, including features like diarization, summaries, speaker identification, and more, to simplify the transcription process. With File Transcribe, users can easily convert spoken words into written text, save time, and work more efficiently. The application provides comprehensive transcription solutions, customizable settings, and expert assistance to ensure a smooth transcription experience for individuals and businesses.
Dot Analytics
Dot Analytics is a growth-focused data analytics agency that offers a wide range of services including data analytics, data engineering, data visualization, data science, big data analytics, AI consulting, and more. They specialize in providing analytics solutions for data-driven business managers seeking accuracy, statistics, and data to drive revenue growth. With over 6 years of experience, they offer tailored analytics solutions to optimize customer acquisition cost, lifetime value, average order value, and conversions. Dot Analytics partners with clients from various industries to provide transparent, maintenance, and optimization services.
Deepnote
Deepnote is an AI-powered analytics and data science notebook platform designed for teams. It allows users to turn notebooks into powerful data apps and dashboards, combining Python, SQL, R, or even working without writing code at all. With Deepnote, users can query various data sources, generate code, explain code, and create interactive visualizations effortlessly. The platform offers features like collaborative workspaces, scheduling notebooks, deploying APIs, and integrating with popular data warehouses and databases. Deepnote prioritizes security and compliance, providing users with control over data access and encryption. It is loved by a community of data professionals and widely used in universities and by data analysts and scientists.
SD Times
The website is a comprehensive platform for software development news, covering a wide range of topics such as AI, DevOps, Observability, CI/CD, Cloud Native, Data, Test Automation, Mobile, API, Performance, Security, DevSecOps, Enterprise Security, Supply Chain Security, Teams & Culture, Dev Manager, Agile, Value Stream, Productivity, and more. It provides news articles, webinars, podcasts, and white papers to keep developers informed about the latest trends and technologies in the software development industry.
Walter Shields Data Academy
Walter Shields Data Academy is an AI-powered platform offering premium training in SQL, Python, and Excel. With over 200,000 learners, it provides curated courses from bestselling books and LinkedIn Learning. The academy aims to revolutionize data expertise and empower individuals to excel in data analysis and AI technologies.
Strong Analytics
Strong Analytics is a data science consulting and machine learning engineering company that specializes in building bespoke data science, machine learning, and artificial intelligence solutions for various industries. They offer end-to-end services to design, engineer, and deploy custom AI products and solutions, leveraging a team of full-stack data scientists and engineers with cross-industry experience. Strong Analytics is known for its expertise in accelerating innovation, deploying state-of-the-art techniques, and empowering enterprises to unlock the transformative value of AI.
Zaver
Zaver is an AI-powered tool designed to help users find, analyze, and outreach creators directly from Google Sheets. It leverages smart AI search to discover relevant influencers, provides 20+ AI-powered insights, and facilitates seamless communication. Zaver streamlines influencer marketing campaigns by offering effortless management of influencer data, access to performance metrics, AI-based insights, and email outreach capabilities all within Google Sheets. The tool aims to save time, money, and enhance team collaboration in influencer marketing efforts.

ThirdEye Data
ThirdEye Data is a data and AI services & solutions provider that enables enterprises to improve operational efficiencies, increase production accuracies, and make informed business decisions by leveraging the latest Data & AI technologies. They offer services in data engineering, data science, generative AI, computer vision, NLP, and more. ThirdEye Data develops bespoke AI applications using the latest data science technologies to address real-world industry challenges and assists enterprises in leveraging generative AI models to develop custom applications. They also provide AI consulting services to explore potential opportunities for AI implementation. The company has a strong focus on customer success and has received positive reviews and awards for their expertise in AI, ML, and big data solutions.
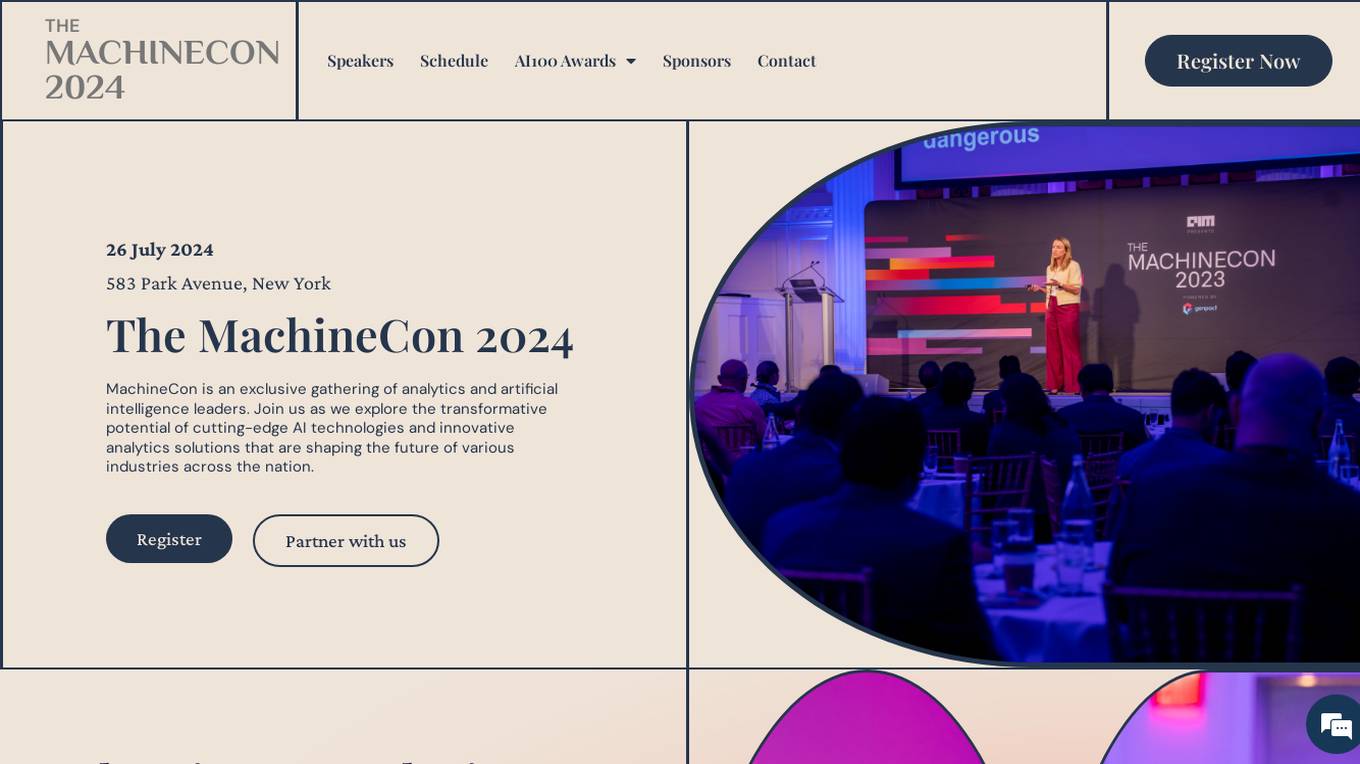
MachineCon 2024
MachineCon 2024 is an exclusive gathering of analytics and artificial intelligence leaders, organized by AIM Research. The conference focuses on exploring cutting-edge AI technologies and innovative analytics solutions that are shaping the future of various industries. It provides a platform for top analytics leaders to learn, network, and do business, emphasizing the transformative potential of data and AI in driving competitive advantage and business transformation.
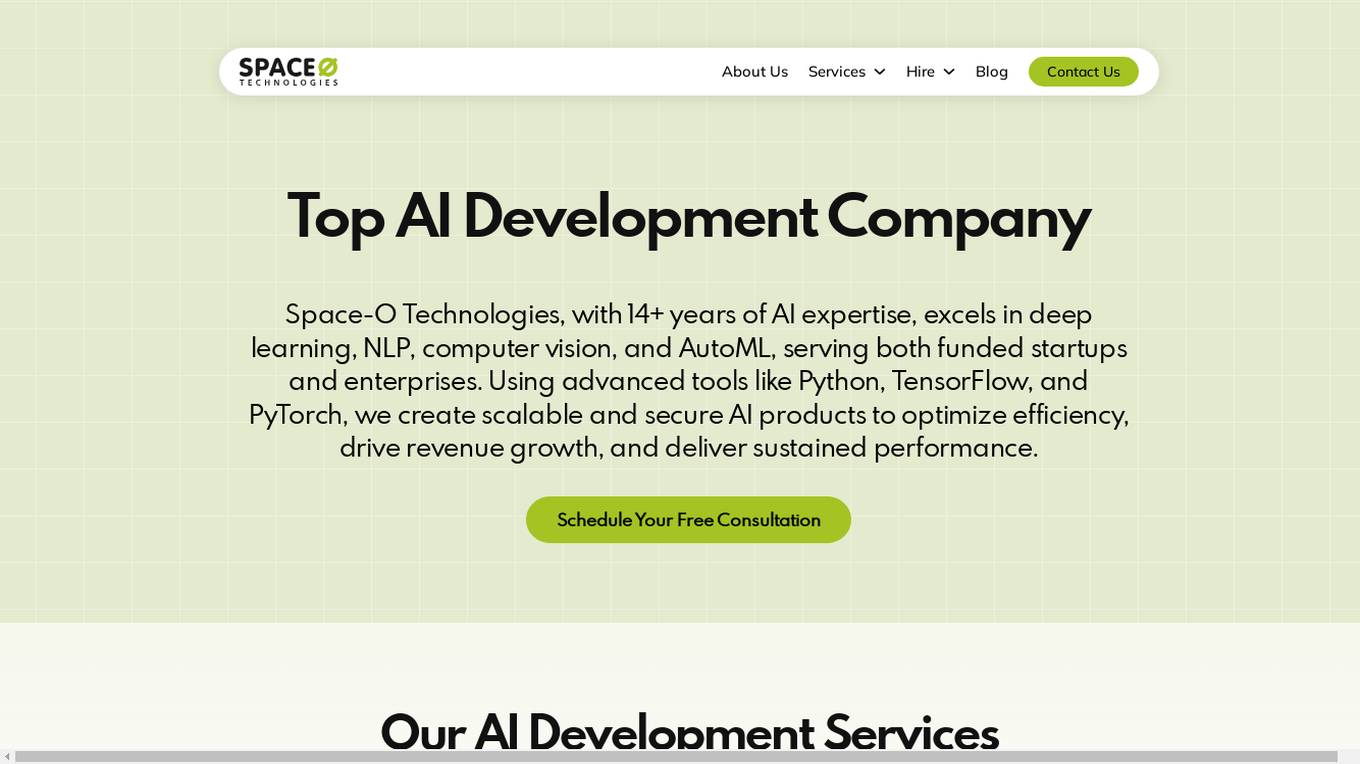
Space-O Technologies
Space-O Technologies is a top-rated Artificial Intelligence Development Company with 14+ years of expertise in AI software development, consulting services, and ML development services. They excel in deep learning, NLP, computer vision, and AutoML, serving both startups and enterprises. Using advanced tools like Python, TensorFlow, and PyTorch, they create scalable and secure AI products to optimize efficiency, drive revenue growth, and deliver sustained performance.

Open Data Science
Open Data Science (ODS) is a community website offering a platform for data science enthusiasts to engage in tracks, competitions, hacks, tasks, events, and projects. The website serves as a hub for job opportunities and provides a space for privacy policy, service agreements, and public offers. ODS.AI, established in 2015, focuses on various data science topics such as machine learning, computer vision, natural language processing, and more. The platform hosts online and offline events, conferences, and educational courses to foster learning and networking within the data science community.
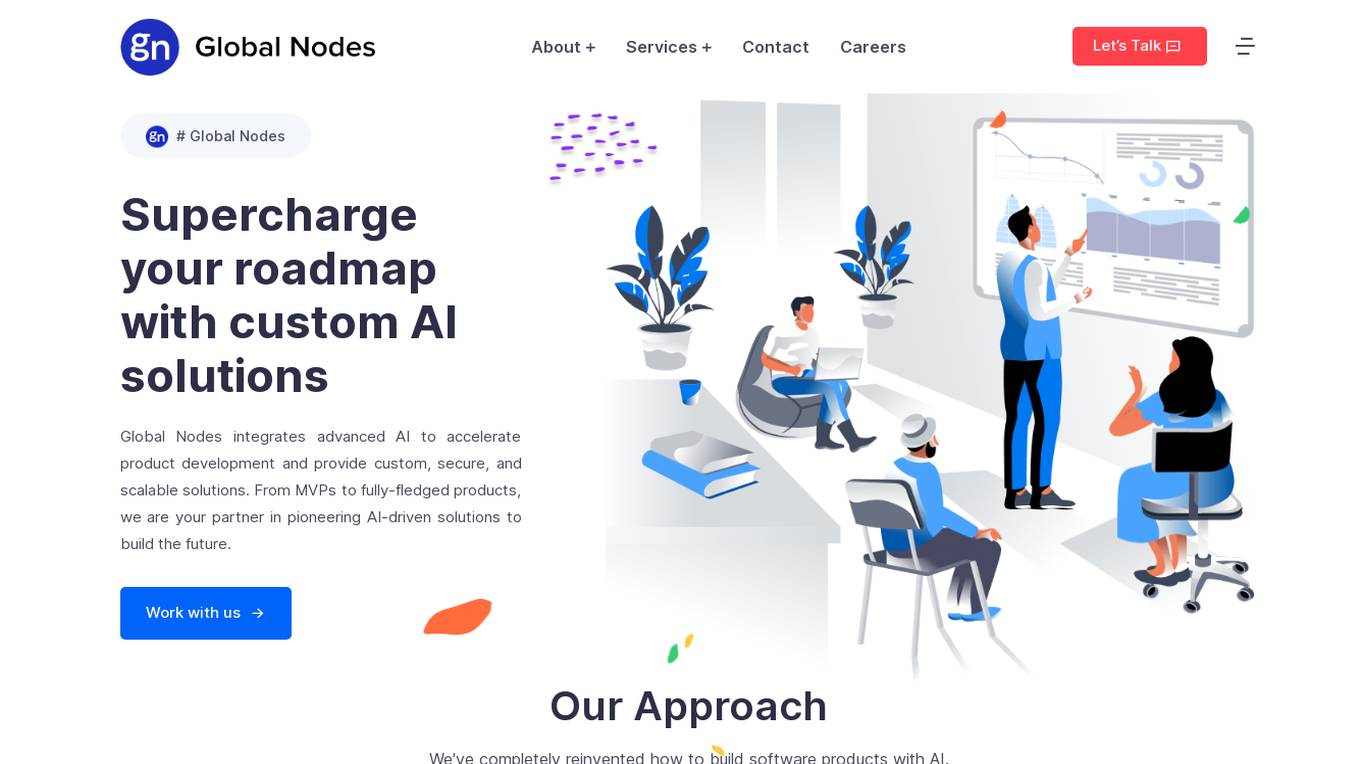
Global Nodes
Global Nodes is a global leader in innovative solutions, specializing in Artificial Intelligence, Data Engineering, Cloud Services, Software Development, and Mobile App Development. They integrate advanced AI to accelerate product development and provide custom, secure, and scalable solutions. With a focus on cutting-edge technology and visionary thinking, Global Nodes offers services ranging from ideation and design to precision execution, transforming concepts into market-ready products. Their team has extensive experience in delivering top-notch AI, cloud, and data engineering services, making them a trusted partner for businesses worldwide.

illumex
illumex is a generative semantic fabric platform designed to streamline the process of data and analytics interpretation and rationalization for complex enterprises. It offers augmented analytics creation, suggestive data and analytics utilization monitoring, and automated knowledge documentation to enhance agentic performance for analytics. The platform aims to solve the challenges of traditional tedious data analysis, incongruent data and metrics, and tribal knowledge of data teams.
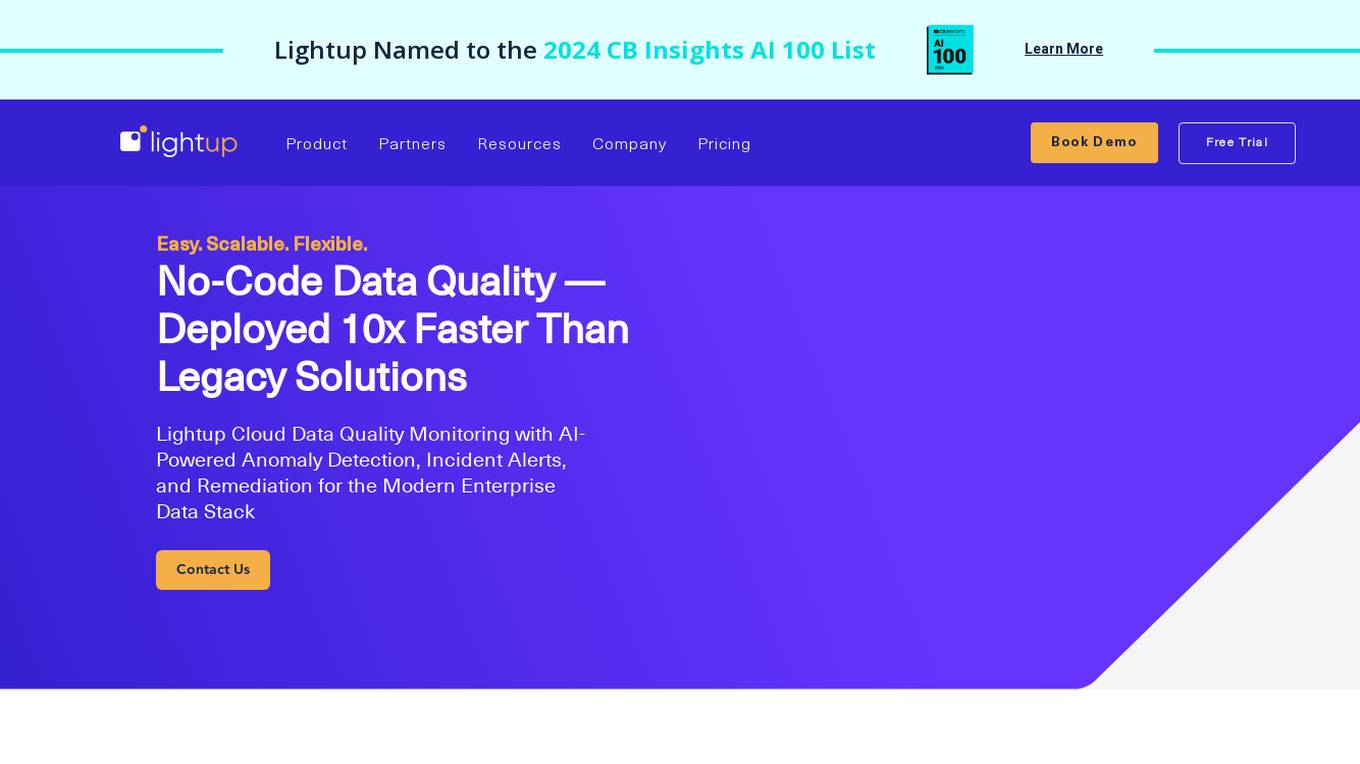
Lightup
Lightup is a cloud data quality monitoring tool with AI-powered anomaly detection, incident alerts, and data remediation capabilities for modern enterprise data stacks. It specializes in helping large organizations implement successful and sustainable data quality programs quickly and easily. Lightup's pushdown architecture allows for monitoring data content at massive scale without moving or copying data, providing extreme scalability and optimal automation. The tool empowers business users with democratized data quality checks and enables automatic fixing of bad data at enterprise scale.
AgentQL
AgentQL is an AI-powered tool for painless data extraction and web automation. It eliminates the need for fragile XPath or DOM selectors by using semantic selectors and natural language descriptions to find web elements reliably. With controlled output and deterministic behavior, AgentQL allows users to shape data exactly as needed. The tool offers features such as extracting data, filling forms automatically, and streamlining testing processes. It is designed to be user-friendly and efficient for developers and data engineers.
Datacog
Datacog is an AI application that offers a comprehensive solution for efficient data warehouse management, application integration, and machine learning. It enables organizations to leverage the complete capabilities of their data assets through intuitive data organization and model training features. With zero configuration, instant deployment, scalability, and real-time monitoring, Datacog simplifies model training and streamlines decision-making. Join the ranks of industry leaders who have harnessed the power of organized data and automation with Datacog.
Datasparq
Datasparq is a specialist AI & data firm that designs, builds, and runs high-impact AI & data solutions. They help businesses at every stage of their AI journey, from value discovery to managing AI solutions. Datasparq combines data science, data engineering, product thinking, and design to deliver valuable, operational AI solutions quickly. Their focus is on creating AI tools that drive business improvements, efficiency, and effectiveness through data platforms, analytics, and machine learning.
Helicone
Helicone is an open-source platform designed for developers, offering observability solutions for logging, monitoring, and debugging. It provides sub-millisecond latency impact, 100% log coverage, industry-leading query times, and is ready for production-level workloads. Trusted by thousands of companies and developers, Helicone leverages Cloudflare Workers for low latency and high reliability, offering features such as prompt management, uptime of 99.99%, scalability, and reliability. It allows risk-free experimentation, prompt security, and various tools for monitoring, analyzing, and managing requests.
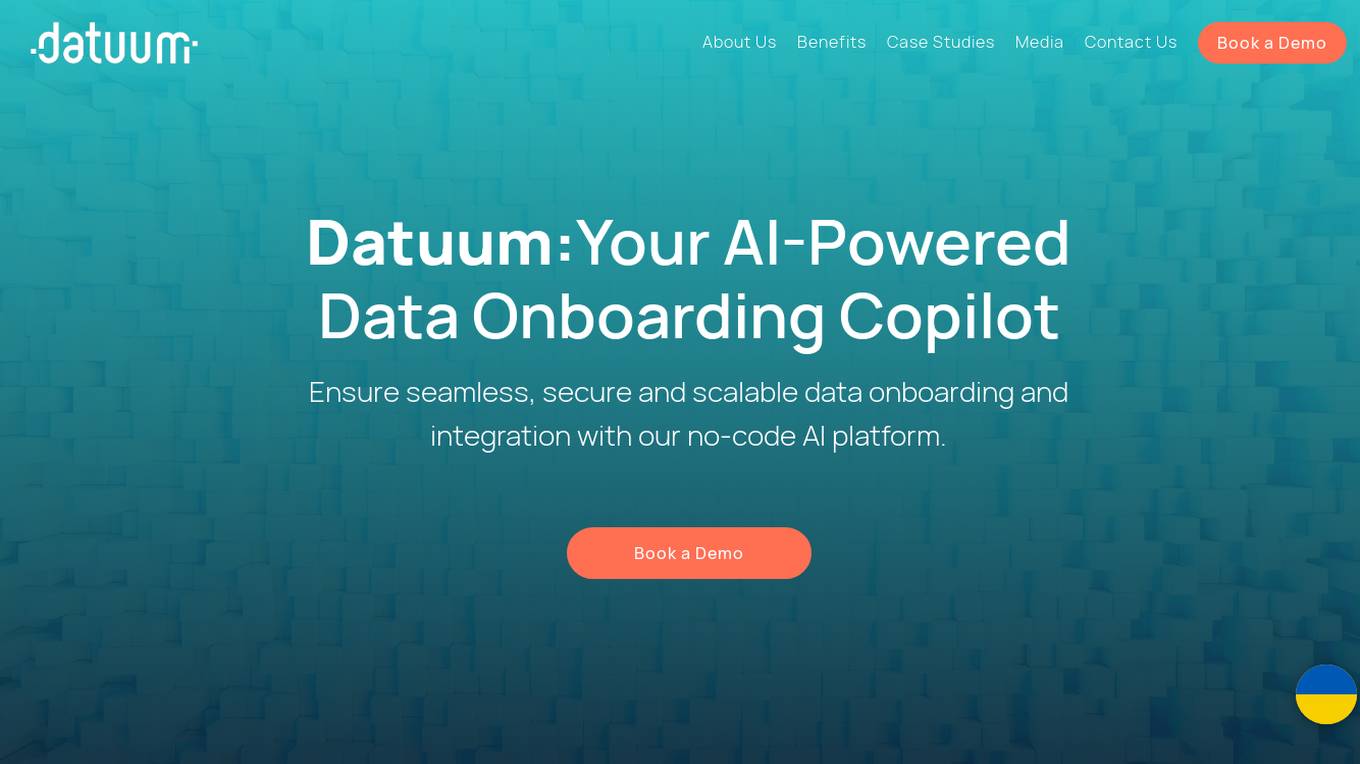
Datuum
Datuum is an AI-powered data onboarding solution that offers seamless integration for businesses. It simplifies the data onboarding process by automating manual tasks, generating code, and ensuring data accuracy with AI-driven validation. Datuum helps businesses achieve faster time to value, reduce costs, improve scalability, and enhance data quality and consistency.
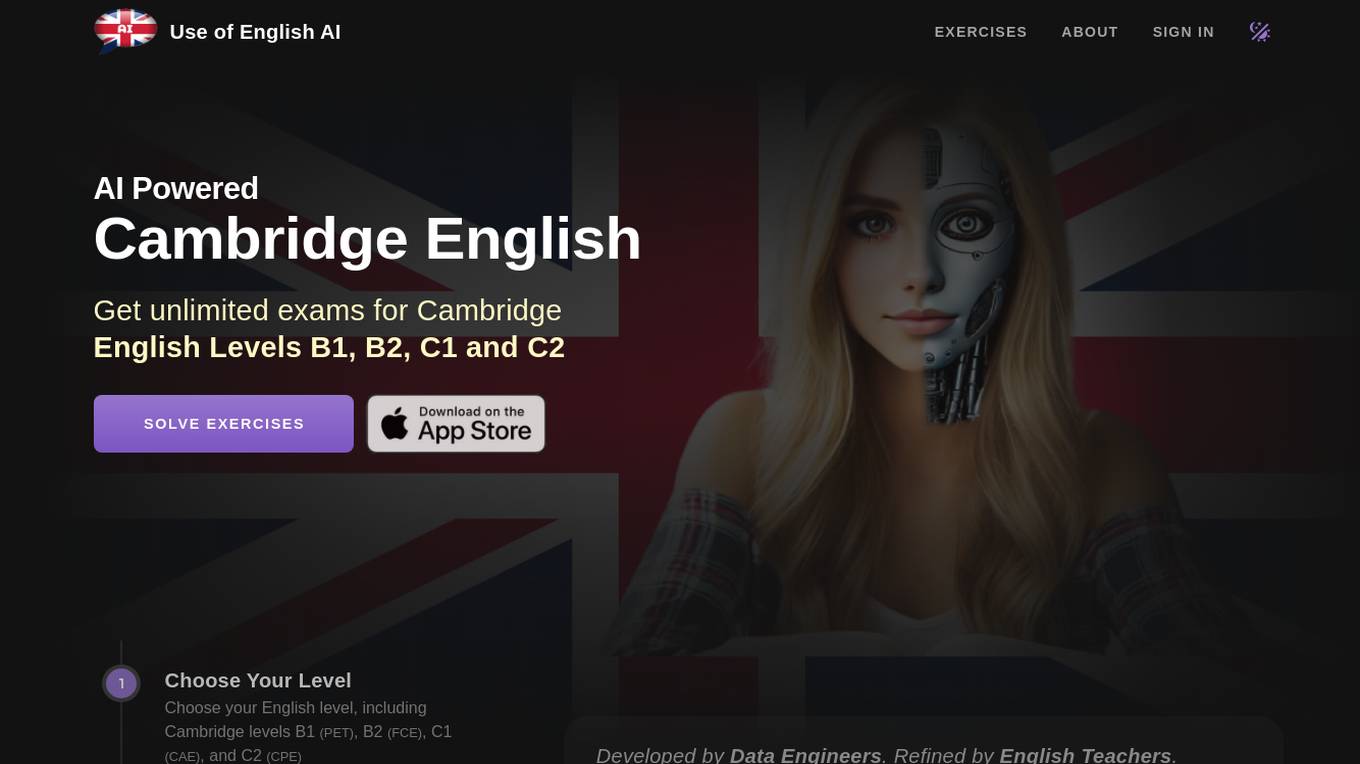
Cambridge English Test AI
The AI-powered Cambridge English Test platform offers exercises for English levels B1, B2, C1, and C2. Users can select exercise types such as Reading and Use of English, including activities like Open Cloze, Multiple Choice, Word Formation, and more. The AI, developed by Shining Apps in partnership with Use of English PRO, provides a unique learning experience by generating exercises from a database of over 5000 official exams. It uses advanced Natural Language Processing (NLP) to understand context, tweak exercises, and offer detailed feedback for effective learning.
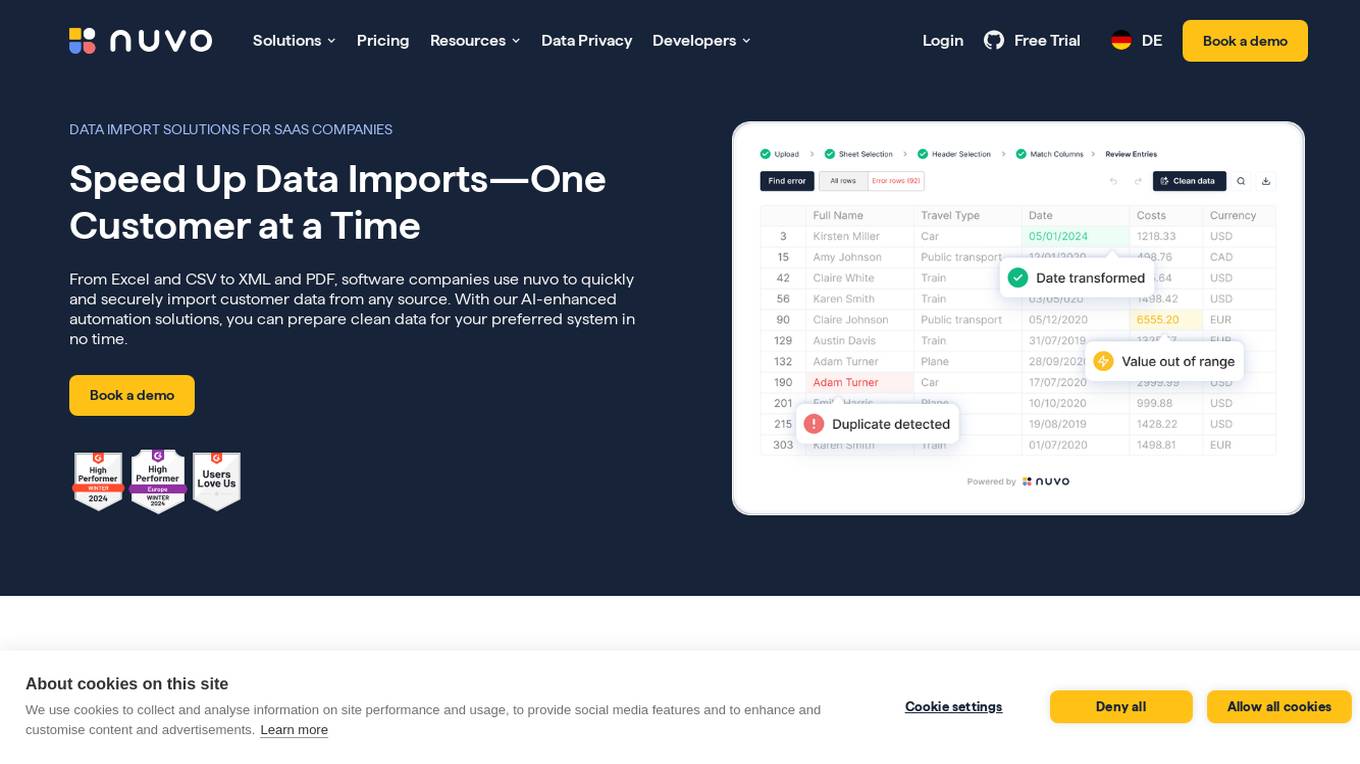
nuvo
nuvo is an AI-powered data import solution that offers fast, secure, and scalable data import solutions for software companies. It provides tools like nuvo Data Importer SDK and nuvo Data Pipeline to streamline manual and recurring ETL data imports, enabling users to manage data imports independently. With AI-enhanced automation, nuvo helps prepare clean data for preferred systems quickly and efficiently, reducing manual effort and improving data quality. The platform allows users to upload unlimited data in various formats, match imported data to system schemas, clean and validate data, and import clean data into target systems with just a click.
One Data
One Data is an AI-powered data product builder that offers a comprehensive solution for building, managing, and sharing data products. It bridges the gap between IT and business by providing AI-powered workflows, lifecycle management, data quality assurance, and data governance features. The platform enables users to easily create, access, and share data products with automated processes and quality alerts. One Data is trusted by enterprises and aims to streamline data product management and accessibility through Data Mesh or Data Fabric approaches, enhancing efficiency in logistics and supply chains. The application is designed to accelerate business impact with reliable data products and support cost reduction initiatives with advanced analytics and collaboration for innovative business models.

AIONTECH Solutions
AIONTECH Solutions is an AI and data solutions provider that empowers businesses to fully utilize data, fostering innovation and ensuring long-term success. They offer cutting-edge AI and data solutions, advanced data analytics, innovation, and a comprehensive suite to unlock the full potential of data. The company is trusted by clients for providing services in BI & Analytics, Cloud Services, Sustainability Services, Data Science and Analytics, and more.

AIxBlock
AIxBlock is an AI tool that empowers users to unleash their AI initiatives on the Blockchain. The platform offers a comprehensive suite of features for building, deploying, and monitoring AI models, including AI data engine, multimodal-powered data crawler, auto annotation, consensus-driven labeling, MLOps platform, decentralized marketplaces, and more. By harnessing the power of blockchain technology, AIxBlock provides cost-efficient solutions for AI builders, compute suppliers, and freelancers to collaborate and benefit from decentralized supercomputing, P2P transactions, and consensus mechanisms.
Pro5.ai
Pro5.ai is an AI-driven platform that connects businesses with the top 5% remote professionals across various tech and business domains. The platform utilizes AI-powered automation to source, vet, and match professionals, ensuring unbiased and efficient hiring processes. Pro5.ai offers a diverse pool of talents, ranging from backend developers to UX designers, and provides a streamlined approach to hiring full-time, long-term talent for remote collaboration.
Keebo
Keebo is an AI tool designed for Snowflake optimization, offering automated query, cost, and tuning optimization. It is the only fully-automated Snowflake optimizer that dynamically adjusts to save customers 25% and more. Keebo's patented technology, based on cutting-edge research, optimizes warehouse size, clustering, and memory without impacting performance. It learns and adjusts to workload changes in real-time, setting up in just 30 minutes and delivering savings within 24 hours. The tool uses telemetry metadata for optimizations, providing full visibility and adjustability for complex scenarios and schedules.
Bird Analytics
Bird Analytics is an AI-powered data analytics platform that offers a comprehensive suite of tools for businesses to manage and analyze their data effectively. With features like AI and Machine Learning, Visual Analysis, Anomaly Monitoring, and more, Bird Analytics provides users with actionable insights and intelligent data-driven solutions. The platform enables users to harness their business data, make better decisions, and predict future trends using advanced analytics capabilities.
Fastn
Fastn is a no-code, AI-powered orchestration platform for developers to integrate and orchestrate multiple data sources in a single, unified API. It allows users to connect any data flow and create hundreds of app integrations efficiently. Fastn simplifies API integration, ensures API security, and handles data from multiple sources with features like real-time data orchestration, instant API composition, and infrastructure management on autopilot.

DATAFOREST
DATAFOREST is an AI-powered data engineering company that offers a wide range of services including generative AI, data science, web and mobile development, DevOps, cloud solutions, digital transformation, and more. They provide custom data-driven solutions for small and medium-sized businesses, focusing on efficiency improvement, revenue growth, and cost reduction. With over 15 years of experience, DATAFOREST helps businesses automate complex tasks, enhance decision-making, boost productivity, and streamline operations through AI and machine learning technologies.
Valohai
Valohai is a scalable MLOps platform that enables Continuous Integration/Continuous Deployment (CI/CD) for machine learning and pipeline automation on-premises and across various cloud environments. It helps streamline complex machine learning workflows by offering framework-agnostic ML capabilities, automatic versioning with complete lineage of ML experiments, hybrid and multi-cloud support, scalability and performance optimization, streamlined collaboration among data scientists, IT, and business units, and smart orchestration of ML workloads on any infrastructure. Valohai also provides a knowledge repository for storing and sharing the entire model lifecycle, facilitating cross-functional collaboration, and allowing developers to build with total freedom using any libraries or frameworks.
Tecton
Tecton is an AI data platform that helps build smarter AI applications by simplifying feature engineering, generating training data, serving real-time data, and enhancing AI models with context-rich prompts. It automates data pipelines, improves model accuracy, and lowers production costs, enabling faster deployment of AI models. Tecton abstracts away data complexity, provides a developer-friendly experience, and allows users to create features from any source. Trusted by top engineering teams, Tecton streamlines ML delivery processes, improves customer interactions, and automates release processes through CI/CD pipelines.
Medeloop
Medeloop is a revolutionary platform in health research that leverages machine learning and big data analytics to accelerate breakthrough discoveries in disease research. The platform provides a comprehensive data-linking infrastructure to solve the problem of wasted health and medical data for both patients and researchers. Medeloop's multi-modal data linkage platform enables researchers to access and analyze diverse data types using analytical tools and programming languages. By utilizing machine learning and artificial intelligence algorithms, Medeloop drives the discovery and development of new therapies, making it a key player in changing the nature of healthcare for the better.
Oxygen Digital Recruitment
Oxygen Digital Recruitment is a specialized AI and Data Science recruitment platform that focuses on providing talent solutions for cutting-edge markets, including Geospatial & ESG, Energy Trading, Renewable Energy, Artificial Intelligence, and Data Science. The platform offers various services such as Permanent Search, Embedded Specialist Talent, Short-term Staffing, Retained Search, and Fractional Advisory. Oxygen Digital aims to accelerate decarbonization by delivering top talent to drive change in the industry. The platform collaborates with start-ups, scale-ups, and global enterprises to build domain-specific innovation teams, providing access to deep passive networks and the ability to hire blended workforces.
Astera Software
Astera Software offers enterprise-ready data management solutions, including data integration, unstructured data management, data warehousing, and EDI Connect. The platform provides automated data processing, data governance, and AI capabilities to transform data into powerful insights, enabling smarter decisions and innovation. Astera simplifies data management with features like data pipeline builder, data warehouse automation, and EDI transaction optimization. Trusted by leading enterprises worldwide, Astera boosts operational efficiency, accelerates time to market, ensures data accuracy, and reduces operational costs through AI-powered data management.
Vizio AI
Vizio AI is an advanced data analytics and automation services provider that empowers businesses with real-time data and AI insights. They offer services such as data app development, automated reporting, RPA bot development, dashboard development, and generative AI. Vizio AI collaborates with clients to connect and visualize data from various sources, automate tasks, and make AI-powered decisions with ease. Their expert data engineers and analysts work on data app development, dashboard creation, and RPA bot development to streamline business operations and enhance decision-making processes.
Talynce
Talynce is an AI-powered technical interview platform that revolutionizes the recruitment process by automating candidate screening through live coding interviews and technical Q&A sessions. It helps companies assess coding skills and theoretical knowledge efficiently, empowering them to identify top technical talent faster.
Domo
Domo is an AI and Data Products Platform that empowers users to connect and prepare data from any source, expand data access for exploration, and build powerful data products to accelerate business-critical insights with AI assistance at every step. It offers features such as Data Integration, Business Intelligence, Workflows and Intelligent Automation, and AI agents for various use cases.
Wizeline
Wizeline is an AI application that offers practical AI solutions for various industries such as media & entertainment, finance, healthcare, and retail. The application provides AI marketing, AI broadcast, and AI core services to help businesses boost revenue, enhance operational agility, and drive growth through AI-powered solutions. Wizeline excels in consultative thinking, AI innovation, and scaling operations with AI. The application is known for its deep industry expertise, real-world solutioning, and partnership with global tech leaders.
Cast AI
Cast AI is an intelligent Kubernetes automation platform that offers live migration for AWS EKS, enabling users to migrate stateful workloads with zero downtime. The platform provides application performance automation by automating and optimizing the entire application stack, including Kubernetes cluster optimization, security, workload optimization, LLM optimization for AIOps, cost monitoring, and database optimization. Cast AI integrates with various cloud services and tools, offering solutions for migration of stateful workloads, inference at scale, and cutting AI costs without sacrificing scale. The platform helps users improve performance, reduce costs, and boost productivity through end-to-end application performance automation.
286 - Open Source Tools

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.
ethereum-etl-airflow
This repository contains Airflow DAGs for extracting, transforming, and loading (ETL) data from the Ethereum blockchain into BigQuery. The DAGs use the Google Cloud Platform (GCP) services, including BigQuery, Cloud Storage, and Cloud Composer, to automate the ETL process. The repository also includes scripts for setting up the GCP environment and running the DAGs locally.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.
milvus
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment. Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility. For more architecture details, see Milvus Architecture Overview. Milvus was released under the open-source Apache License 2.0 in October 2019. It is currently a graduate project under LF AI & Data Foundation.

airbyte-connectors
This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
lance
Lance is a modern columnar data format optimized for ML workflows and datasets. It offers high-performance random access, vector search, zero-copy automatic versioning, and ecosystem integrations with Apache Arrow, Pandas, Polars, and DuckDB. Lance is designed to address the challenges of the ML development cycle, providing a unified data format for collection, exploration, analytics, feature engineering, training, evaluation, deployment, and monitoring. It aims to reduce data silos and streamline the ML development process.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide
raft
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
DeepBI
DeepBI is an AI-native data analysis platform that leverages the power of large language models to explore, query, visualize, and share data from any data source. Users can use DeepBI to gain data insight and make data-driven decisions.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
argilla
Argilla is a collaboration platform for AI engineers and domain experts that require high-quality outputs, full data ownership, and overall efficiency. It helps users improve AI output quality through data quality, take control of their data and models, and improve efficiency by quickly iterating on the right data and models. Argilla is an open-source community-driven project that provides tools for achieving and maintaining high-quality data standards, with a focus on NLP and LLMs. It is used by AI teams from companies like the Red Cross, Loris.ai, and Prolific to improve the quality and efficiency of AI projects.
oio-sds
OpenIO SDS is a software solution for object storage, targeting very large-scale unstructured data volumes.
n8n-docs
n8n is an extendable workflow automation tool that enables you to connect anything to everything. It is open-source and can be self-hosted or used as a service. n8n provides a visual interface for creating workflows, which can be used to automate tasks such as data integration, data transformation, and data analysis. n8n also includes a library of pre-built nodes that can be used to connect to a variety of applications and services. This makes it easy to create complex workflows without having to write any code.

WrenAI
WrenAI is a data assistant tool that helps users get results and insights faster by asking questions in natural language, without writing SQL. It leverages Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) technology to enhance comprehension of internal data. Key benefits include fast onboarding, secure design, and open-source availability. WrenAI consists of three core services: Wren UI (intuitive user interface), Wren AI Service (processes queries using a vector database), and Wren Engine (platform backbone). It is currently in alpha version, with new releases planned biweekly.
opendataeditor
The Open Data Editor (ODE) is a no-code application to explore, validate and publish data in a simple way. It is an open source project powered by the Frictionless Framework. The ODE is currently available for download and testing in beta.
terraform-provider-aiven
The Terraform provider for Aiven.io, an open source data platform as a service. See the official documentation to learn about all the possible services and resources.

vulcan-sql
VulcanSQL is an Analytical Data API Framework for AI agents and data apps. It aims to help data professionals deliver RESTful APIs from databases, data warehouses or data lakes much easier and secure. It turns your SQL into APIs in no time!
airflow-chart
This Helm chart bootstraps an Airflow deployment on a Kubernetes cluster using the Helm package manager. The version of this chart does not correlate to any other component. Users should not expect feature parity between OSS airflow chart and the Astronomer airflow-chart for identical version numbers. To install this helm chart remotely (using helm 3) kubectl create namespace airflow helm repo add astronomer https://helm.astronomer.io helm install airflow --namespace airflow astronomer/airflow To install this repository from source sh kubectl create namespace airflow helm install --namespace airflow . Prerequisites: Kubernetes 1.12+ Helm 3.6+ PV provisioner support in the underlying infrastructure Installing the Chart: sh helm install --name my-release . The command deploys Airflow on the Kubernetes cluster in the default configuration. The Parameters section lists the parameters that can be configured during installation. Upgrading the Chart: First, look at the updating documentation to identify any backwards-incompatible changes. To upgrade the chart with the release name `my-release`: sh helm upgrade --name my-release . Uninstalling the Chart: To uninstall/delete the `my-release` deployment: sh helm delete my-release The command removes all the Kubernetes components associated with the chart and deletes the release. Updating DAGs: Bake DAGs in Docker image The recommended way to update your DAGs with this chart is to build a new docker image with the latest code (`docker build -t my-company/airflow:8a0da78 .`), push it to an accessible registry (`docker push my-company/airflow:8a0da78`), then update the Airflow pods with that image: sh helm upgrade my-release . --set images.airflow.repository=my-company/airflow --set images.airflow.tag=8a0da78 Docker Images: The Airflow image that are referenced as the default values in this chart are generated from this repository: https://github.com/astronomer/ap-airflow. Other non-airflow images used in this chart are generated from this repository: https://github.com/astronomer/ap-vendor. Parameters: The complete list of parameters supported by the community chart can be found on the Parameteres Reference page, and can be set under the `airflow` key in this chart. The following tables lists the configurable parameters of the Astronomer chart and their default values. | Parameter | Description | Default | | :----------------------------- | :-------------------------------------------------------------------------------------------------------- | :---------------------------- | | `ingress.enabled` | Enable Kubernetes Ingress support | `false` | | `ingress.acme` | Add acme annotations to Ingress object | `false` | | `ingress.tlsSecretName` | Name of secret that contains a TLS secret | `~` | | `ingress.webserverAnnotations` | Annotations added to Webserver Ingress object | `{}` | | `ingress.flowerAnnotations` | Annotations added to Flower Ingress object | `{}` | | `ingress.baseDomain` | Base domain for VHOSTs | `~` | | `ingress.auth.enabled` | Enable auth with Astronomer Platform | `true` | | `extraObjects` | Extra K8s Objects to deploy (these are passed through `tpl`). More about Extra Objects. | `[]` | | `sccEnabled` | Enable security context constraints required for OpenShift | `false` | | `authSidecar.enabled` | Enable authSidecar | `false` | | `authSidecar.repository` | The image for the auth sidecar proxy | `nginxinc/nginx-unprivileged` | | `authSidecar.tag` | The image tag for the auth sidecar proxy | `stable` | | `authSidecar.pullPolicy` | The K8s pullPolicy for the the auth sidecar proxy image | `IfNotPresent` | | `authSidecar.port` | The port the auth sidecar exposes | `8084` | | `gitSyncRelay.enabled` | Enables git sync relay feature. | `False` | | `gitSyncRelay.repo.url` | Upstream URL to the git repo to clone. | `~` | | `gitSyncRelay.repo.branch` | Branch of the upstream git repo to checkout. | `main` | | `gitSyncRelay.repo.depth` | How many revisions to check out. Leave as default `1` except in dev where history is needed. | `1` | | `gitSyncRelay.repo.wait` | Seconds to wait before pulling from the upstream remote. | `60` | | `gitSyncRelay.repo.subPath` | Path to the dags directory within the git repository. | `~` | Specify each parameter using the `--set key=value[,key=value]` argument to `helm install`. For example, sh helm install --name my-release --set executor=CeleryExecutor --set enablePodLaunching=false . Walkthrough using kind: Install kind, and create a cluster We recommend testing with Kubernetes 1.25+, example: sh kind create cluster --image kindest/node:v1.25.11 Confirm it's up: sh kubectl cluster-info --context kind-kind Add Astronomer's Helm repo sh helm repo add astronomer https://helm.astronomer.io helm repo update Create namespace + install the chart sh kubectl create namespace airflow helm install airflow -n airflow astronomer/airflow It may take a few minutes. Confirm the pods are up: sh kubectl get pods --all-namespaces helm list -n airflow Run `kubectl port-forward svc/airflow-webserver 8080:8080 -n airflow` to port-forward the Airflow UI to http://localhost:8080/ to confirm Airflow is working. Login as _admin_ and password _admin_. Build a Docker image from your DAGs: 1. Start a project using astro-cli, which will generate a Dockerfile, and load your DAGs in. You can test locally before pushing to kind with `astro airflow start`. `sh mkdir my-airflow-project && cd my-airflow-project astro dev init` 2. Then build the image: `sh docker build -t my-dags:0.0.1 .` 3. Load the image into kind: `sh kind load docker-image my-dags:0.0.1` 4. Upgrade Helm deployment: sh helm upgrade airflow -n airflow --set images.airflow.repository=my-dags --set images.airflow.tag=0.0.1 astronomer/airflow Extra Objects: This chart can deploy extra Kubernetes objects (assuming the role used by Helm can manage them). For Astronomer Cloud and Enterprise, the role permissions can be found in the Commander role. yaml extraObjects: - apiVersion: batch/v1beta1 kind: CronJob metadata: name: "{{ .Release.Name }}-somejob" spec: schedule: "*/10 * * * *" concurrencyPolicy: Forbid jobTemplate: spec: template: spec: containers: - name: myjob image: ubuntu command: - echo args: - hello restartPolicy: OnFailure Contributing: Check out our contributing guide! License: Apache 2.0 with Commons Clause

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
aistore
AIStore is a lightweight object storage system designed for AI applications. It is highly scalable, reliable, and easy to use. AIStore can be deployed on any commodity hardware, and it can be used to store and manage large datasets for deep learning and other AI applications.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.

client
DagsHub is a platform for machine learning and data science teams to build, manage, and collaborate on their projects. With DagsHub you can: 1. Version code, data, and models in one place. Use the free provided DagsHub storage or connect it to your cloud storage 2. Track Experiments using Git, DVC or MLflow, to provide a fully reproducible environment 3. Visualize pipelines, data, and notebooks in and interactive, diff-able, and dynamic way 4. Label your data directly on the platform using Label Studio 5. Share your work with your team members 6. Stream and upload your data in an intuitive and easy way, while preserving versioning and structure. DagsHub is built firmly around open, standard formats for your project. In particular: * Git * DVC * MLflow * Label Studio * Standard data formats like YAML, JSON, CSV Therefore, you can work with DagsHub regardless of your chosen programming language or frameworks.
mobius
Mobius is an AI infra platform including realtime computing and training. It is built on Ray, a distributed computing framework, and provides a number of features that make it well-suited for online machine learning tasks. These features include: * **Cross Language**: Mobius can run in multiple languages (only Python and Java are supported currently) with high efficiency. You can implement your operator in different languages and run them in one job. * **Single Node Failover**: Mobius has a special failover mechanism that only needs to rollback the failed node itself, in most cases, to recover the job. This is a huge benefit if your job is sensitive about failure recovery time. * **AutoScaling**: Mobius can generate a new graph with different configurations in runtime without stopping the job. * **Fusion Training**: Mobius can combine TensorFlow/Pytorch and streaming, then building an e2e online machine learning pipeline. Mobius is still under development, but it has already been used to power a number of real-world applications, including: * A real-time recommendation system for a major e-commerce company * A fraud detection system for a large financial institution * A personalized news feed for a major news organization If you are interested in using Mobius for your own online machine learning projects, you can find more information in the documentation.
Data-Science-EBooks
This repository contains a collection of resources in the form of eBooks related to Data Science, Machine Learning, and similar topics.
SQLAgent
DataAgent is a multi-agent system for data analysis, capable of understanding data development and data analysis requirements, understanding data, and generating SQL and Python code for tasks such as data query, data visualization, and machine learning.

venice
Venice is a derived data storage platform, providing the following characteristics: 1. High throughput asynchronous ingestion from batch and streaming sources (e.g. Hadoop and Samza). 2. Low latency online reads via remote queries or in-process caching. 3. Active-active replication between regions with CRDT-based conflict resolution. 4. Multi-cluster support within each region with operator-driven cluster assignment. 5. Multi-tenancy, horizontal scalability and elasticity within each cluster. The above makes Venice particularly suitable as the stateful component backing a Feature Store, such as Feathr. AI applications feed the output of their ML training jobs into Venice and then query the data for use during online inference workloads.
dev-conf-replay
This repository contains information about various IT seminars and developer conferences in South Korea, allowing users to watch replays of past events. It covers a wide range of topics such as AI, big data, cloud, infrastructure, devops, blockchain, mobility, games, security, mobile development, frontend, programming languages, open source, education, and community events. Users can explore upcoming and past events, view related YouTube channels, and access additional resources like free programming ebooks and data structures and algorithms tutorials.
Oxen
Oxen is a data version control library, written in Rust. It's designed to be fast, reliable, and easy to use. Oxen can be used in a variety of ways, from a simple command line tool to a remote server to sync to, to integrations into other ecosystems such as python.
airda
airda(Air Data Agent) is a multi-agent system for data analysis, which can understand data development and data analysis requirements, understand data, and generate SQL and Python code for data query, data visualization, machine learning and other tasks.
aiocsv
aiocsv is a Python module that provides asynchronous CSV reading and writing. It is designed to be a drop-in replacement for the Python's builtin csv module, but with the added benefit of being able to read and write CSV files asynchronously. This makes it ideal for use in applications that need to process large CSV files efficiently.
CGraph
CGraph is a cross-platform **D** irected **A** cyclic **G** raph framework based on pure C++ without any 3rd-party dependencies. You, with it, can **build your own operators simply, and describe any running schedules** as you need, such as dependence, parallelling, aggregation and so on. Some useful tools and plugins are also provide to improve your project. Tutorials and contact information are show as follows. Please **get in touch with us for free** if you need more about this repository.

upgini
Upgini is an intelligent data search engine with a Python library that helps users find and add relevant features to their ML pipeline from various public, community, and premium external data sources. It automates the optimization of connected data sources by generating an optimal set of machine learning features using large language models, GraphNNs, and recurrent neural networks. The tool aims to simplify feature search and enrichment for external data to make it a standard approach in machine learning pipelines. It democratizes access to data sources for the data science community.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
ragna
Ragna is a RAG orchestration framework designed for managing workflows and orchestrating tasks. It provides a comprehensive set of features for users to streamline their processes and automate repetitive tasks. With Ragna, users can easily create, schedule, and monitor workflows, making it an ideal tool for teams and individuals looking to improve their productivity and efficiency. The framework offers extensive documentation, community support, and a user-friendly interface, making it accessible to users of all skill levels. Whether you are a developer, data scientist, or project manager, Ragna can help you simplify your workflow management and boost your overall performance.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

PowerInfer
PowerInfer is a high-speed Large Language Model (LLM) inference engine designed for local deployment on consumer-grade hardware, leveraging activation locality to optimize efficiency. It features a locality-centric design, hybrid CPU/GPU utilization, easy integration with popular ReLU-sparse models, and support for various platforms. PowerInfer achieves high speed with lower resource demands and is flexible for easy deployment and compatibility with existing models like Falcon-40B, Llama2 family, ProSparse Llama2 family, and Bamboo-7B.
aiosqlite
aiosqlite is a Python library that provides a friendly, async interface to SQLite databases. It replicates the standard sqlite3 module but with async versions of all the standard connection and cursor methods, along with context managers for automatically closing connections and cursors. It allows interaction with SQLite databases on the main AsyncIO event loop without blocking execution of other coroutines while waiting for queries or data fetches. The library also replicates most of the advanced features of sqlite3, such as row factories and total changes tracking.

litdata
LitData is a tool designed for blazingly fast, distributed streaming of training data from any cloud storage. It allows users to transform and optimize data in cloud storage environments efficiently and intuitively, supporting various data types like images, text, video, audio, geo-spatial, and multimodal data. LitData integrates smoothly with frameworks such as LitGPT and PyTorch, enabling seamless streaming of data to multiple machines. Key features include multi-GPU/multi-node support, easy data mixing, pause & resume functionality, support for profiling, memory footprint reduction, cache size configuration, and on-prem optimizations. The tool also provides benchmarks for measuring streaming speed and conversion efficiency, along with runnable templates for different data types. LitData enables infinite cloud data processing by utilizing the Lightning.ai platform to scale data processing with optimized machines.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.
hopsworks
Hopsworks is a data platform for ML with a Python-centric Feature Store and MLOps capabilities. It provides collaboration for ML teams, offering a secure, governed platform for developing, managing, and sharing ML assets. Hopsworks supports project-based multi-tenancy, team collaboration, development tools for Data Science, and is available on any platform including managed cloud services and on-premise installations. The platform enables end-to-end responsibility from raw data to managed features and models, supports versioning, lineage, and provenance, and facilitates the complete MLOps life cycle.
vscode-dbt-power-user
The vscode-dbt-power-user is an open-source extension that enhances the functionality of Visual Studio Code to seamlessly work with dbt™. It provides features such as auto-complete for dbt™ code, previewing query results, column lineage visualization, generating dbt™ models, documentation generation, deferring model builds, running parent/child models and tests with a click, compiled query preview and explanation, project health check, SQL validation, BigQuery cost estimation, and other features like dbt™ logs viewer. The extension is fully compatible with dev containers, code spaces, and remote extensions, supporting dbt™ versions above 1.0.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
aiokafka
aiokafka is an asyncio client for Kafka that provides high-level, asynchronous message producer and consumer functionalities. It allows users to interact with Kafka for sending and consuming messages in an efficient and scalable manner. The tool supports features like cluster layout retrieval, topic/partition leadership information, group coordination, and message consumption load balancing. Users can easily integrate aiokafka into their Python projects to work with Kafka seamlessly.

vectorflow
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.
aiomcache
aiomcache is a Python library that provides an asyncio (PEP 3156) interface to work with memcached. It allows users to interact with memcached servers asynchronously, making it suitable for high-performance applications that require non-blocking I/O operations. The library offers similar functionality to other memcache clients and includes features like setting and getting values, multi-get operations, and deleting keys. Version 0.8 introduces the `FlagClient` class, which enables users to register callbacks for setting or processing flags, providing additional flexibility and customization options for working with memcached servers.
ai-powered-search
AI-Powered Search provides code examples for the book 'AI-Powered Search' by Trey Grainger, Doug Turnbull, and Max Irwin. The book teaches modern machine learning techniques for building search engines that continuously learn from users and content to deliver more intelligent and domain-aware search experiences. It covers semantic search, retrieval augmented generation, question answering, summarization, fine-tuning transformer-based models, personalized search, machine-learned ranking, click models, and more. The code examples are in Python, leveraging PySpark for data processing and Apache Solr as the default search engine. The repository is open source under the Apache License, Version 2.0.

aiomisc
aiomisc is a Python library that provides a collection of utility functions and classes for working with asynchronous I/O in a more intuitive and efficient way. It offers features like worker pools, connection pools, circuit breaker pattern, and retry mechanisms to make asyncio code more robust and easier to maintain. The library simplifies the architecture of software using asynchronous I/O, making it easier for developers to write reliable and scalable asynchronous code.
amber-data-prep
This repository contains the code to prepare the data for the Amber 7B language model. The final training data comes from three sources: RedPajama V1, RefinedWeb, and StarCoderData. The data preparation involves downloading untokenized data, tokenizing the data using the Huggingface tokenizer, concatenating tokens into 2048 token sequences, merging datasets, and splitting the merged dataset into 360 chunks. Each tokenized data chunk is a jsonl file containing samples with 2049 tokens. The repository provides scripts for downloading datasets, tokenizing and concatenating sequences, validating data, and merging subsets into chunks.
quick-start-connectors
Cohere's Build-Your-Own-Connector framework allows integration of Cohere's Command LLM via the Chat API endpoint to any datastore/software holding text information with a search endpoint. Enables user queries grounded in proprietary information. Use-cases include question/answering, knowledge working, comms summary, and research. Repository provides code for popular datastores and a template connector. Requires Python 3.11+ and Poetry. Connectors can be built and deployed using Docker. Environment variables set authorization values. Pre-commits for linting. Connectors tailored to integrate with Cohere's Chat API for creating chatbots. Connectors return documents as JSON objects for Cohere's API to generate answers with citations.
rill-flow
Rill Flow is a high-performance, scalable distributed workflow orchestration service that supports the execution of tens of millions of tasks per day with task execution latency less than 100ms. It is distributed and supports the orchestration and scheduling of heterogeneous distributed systems. Rill Flow is easy to use, supporting visual process orchestration and plug-in access. It is cloud native, allowing for cloud native container deployment and cloud native function orchestration. Additionally, Rill Flow supports rapid integration of LLM model services.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.
lfai-landscape
LF AI & Data Landscape is a map to explore open source projects in the AI & Data domains, highlighting companies that are members of LF AI & Data. It showcases members of the Foundation and is modelled after the Cloud Native Computing Foundation landscape. The landscape includes current version, interactive version, new entries, logos, proper SVGs, corrections, external data, best practices badge, non-updated items, license, formats, installation, vulnerability reporting, and adjusting the landscape view.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.
aiolimiter
An efficient implementation of a rate limiter for asyncio using the Leaky bucket algorithm, providing precise control over the rate a code section can be entered. It allows for limiting the number of concurrent entries within a specified time window, ensuring that a section of code is executed a maximum number of times in that period.
aioclock
An asyncio-based scheduling framework designed for execution of periodic tasks with integrated support for dependency injection, enabling efficient and flexible task management. Aioclock is 100% async, light, fast, and resource-friendly. It offers features like task scheduling, grouping, trigger definition, easy syntax, Pydantic v2 validation, and upcoming support for running the task dispatcher on a different process and backend support for horizontal scaling.
comfy-cli
Comfy-cli is a command line tool designed to facilitate the installation and management of ComfyUI, an open-source machine learning framework. Users can easily set up ComfyUI, install packages, and manage custom nodes directly from the terminal. The tool offers features such as easy installation, seamless package management, custom node management, checkpoint downloads, cross-platform compatibility, and comprehensive documentation. Comfy-cli simplifies the process of working with ComfyUI, making it convenient for users to handle various tasks related to the framework.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
KsanaLLM
KsanaLLM is a high-performance engine for LLM inference and serving. It utilizes optimized CUDA kernels for high performance, efficient memory management, and detailed optimization for dynamic batching. The tool offers flexibility with seamless integration with popular Hugging Face models, support for multiple weight formats, and high-throughput serving with various decoding algorithms. It enables multi-GPU tensor parallelism, streaming outputs, and an OpenAI-compatible API server. KsanaLLM supports NVIDIA GPUs and Huawei Ascend NPU, and seamlessly integrates with verified Hugging Face models like LLaMA, Baichuan, and Qwen. Users can create a docker container, clone the source code, compile for Nvidia or Huawei Ascend NPU, run the tool, and distribute it as a wheel package. Optional features include a model weight map JSON file for models with different weight names.
export_llama_to_onnx
Export LLM like llama to ONNX files without modifying transformers modeling_xx_model.py. Supported models include llama (Hugging Face format), Baichuan, Alibaba Qwen 1.5/2, ChatGlm2/ChatGlm3, and Gemma. Usage examples provided for exporting different models to ONNX files. Various arguments can be used to configure the export process. Note on uninstalling/disabling FlashAttention and xformers before model conversion. Recommendations for handling kv_cache format and simplifying large ONNX models. Disclaimer regarding correctness of exported models and consequences of usage.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
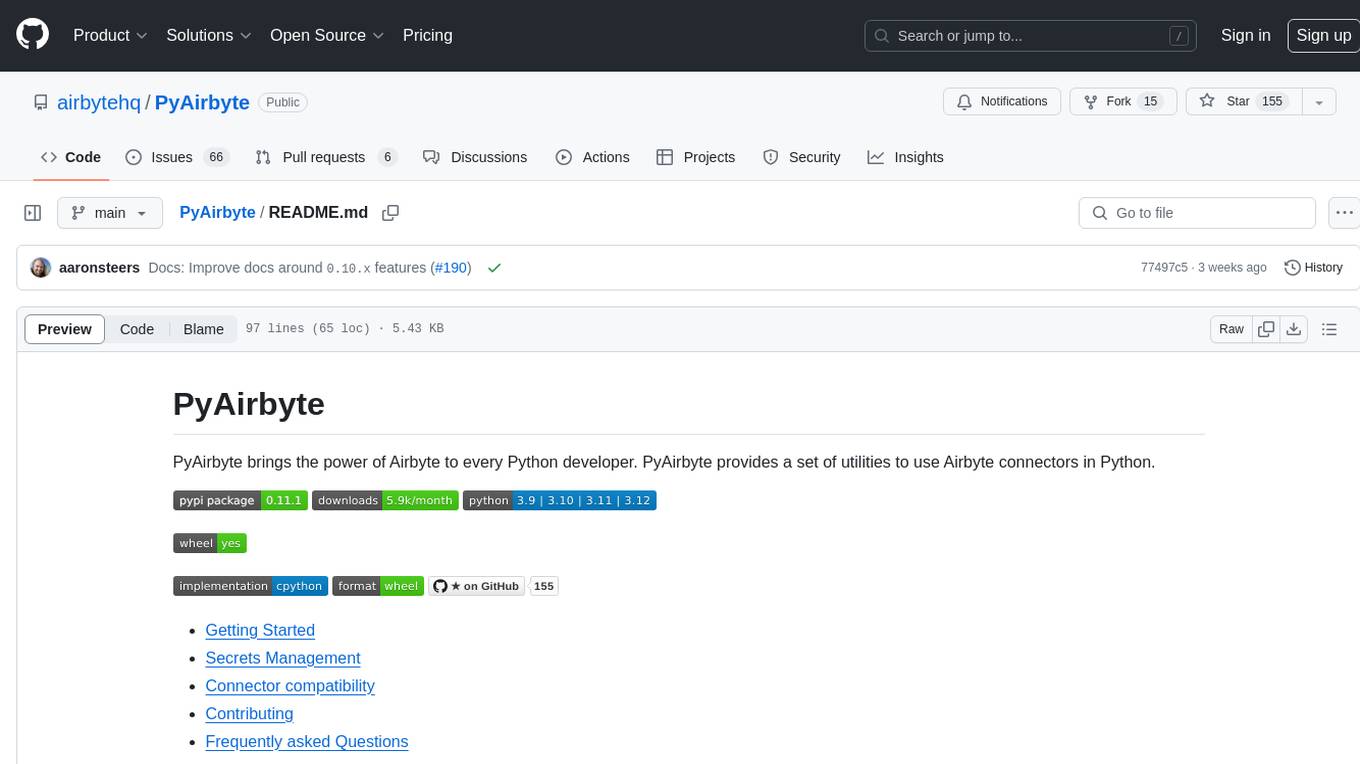
PyAirbyte
PyAirbyte brings the power of Airbyte to every Python developer by providing a set of utilities to use Airbyte connectors in Python. It enables users to easily manage secrets, work with various connectors like GitHub, Shopify, and Postgres, and contribute to the project. PyAirbyte is not a replacement for Airbyte but complements it, supporting data orchestration frameworks like Airflow and Snowpark. Users can develop ETL pipelines and import connectors from local directories. The tool simplifies data integration tasks for Python developers.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.
awesome-mlops
Awesome MLOps is a curated list of tools related to Machine Learning Operations, covering areas such as AutoML, CI/CD for Machine Learning, Data Cataloging, Data Enrichment, Data Exploration, Data Management, Data Processing, Data Validation, Data Visualization, Drift Detection, Feature Engineering, Feature Store, Hyperparameter Tuning, Knowledge Sharing, Machine Learning Platforms, Model Fairness and Privacy, Model Interpretability, Model Lifecycle, Model Serving, Model Testing & Validation, Optimization Tools, Simplification Tools, Visual Analysis and Debugging, and Workflow Tools. The repository provides a comprehensive collection of tools and resources for individuals and teams working in the field of MLOps.
redis-ai-resources
A curated repository of code recipes, demos, and resources for basic and advanced Redis use cases in the AI ecosystem. It includes demos for ArxivChatGuru, Redis VSS, Vertex AI & Redis, Agentic RAG, ArXiv Search, and Product Search. Recipes cover topics like Getting started with RAG, Semantic Cache, Advanced RAG, and Recommendation systems. The repository also provides integrations/tools like RedisVL, AWS Bedrock, LangChain Python, LangChain JS, LlamaIndex, Semantic Kernel, RelevanceAI, and DocArray. Additional content includes blog posts, talks, reviews, and documentation related to Vector Similarity Search, AI-Powered Document Search, Vector Databases, Real-Time Product Recommendations, and more. Benchmarks compare Redis against other Vector Databases and ANN benchmarks. Documentation includes QuickStart guides, official literature for Vector Similarity Search, Redis-py client library docs, Redis Stack documentation, and Redis client list.
aiocache
Aiocache is an asyncio cache library that supports multiple backends such as memory, redis, and memcached. It provides a simple interface for functions like add, get, set, multi_get, multi_set, exists, increment, delete, clear, and raw. Users can easily install and use the library for caching data in Python applications. Aiocache allows for easy instantiation of caches and setup of cache aliases for reusing configurations. It also provides support for backends, serializers, and plugins to customize cache operations. The library offers detailed documentation and examples for different use cases and configurations.
aio-scrapy
Aio-scrapy is an asyncio-based web crawling and web scraping framework inspired by Scrapy. It supports distributed crawling/scraping, implements compatibility with scrapyd, and provides options for using redis queue and rabbitmq queue. The framework is designed for fast extraction of structured data from websites. Aio-scrapy requires Python 3.9+ and is compatible with Linux, Windows, macOS, and BSD systems.
ai-on-openshift
AI on OpenShift is a site providing installation recipes, patterns, and demos for AI/ML tools and applications used in Data Science and Data Engineering projects running on OpenShift. It serves as a comprehensive resource for developers looking to deploy AI solutions on the OpenShift platform.
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
redis-vl-python
The Python Redis Vector Library (RedisVL) is a tailor-made client for AI applications leveraging Redis. It enhances applications with Redis' speed, flexibility, and reliability, incorporating capabilities like vector-based semantic search, full-text search, and geo-spatial search. The library bridges the gap between the emerging AI-native developer ecosystem and the capabilities of Redis by providing a lightweight, elegant, and intuitive interface. It abstracts the features of Redis into a grammar that is more aligned to the needs of today's AI/ML Engineers or Data Scientists.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
DistServe
DistServe improves the performance of large language models serving by disaggregating the prefill and decoding computation. It allows setting parallelism configs and scheduling strategies for the two phases independently, handling KV-Cache communication and memory management automatically. Utilizes a high-performance C++ Transformer inference library SwiftTransformer with features like model/pipeline parallelism, FlashAttention, Continuous Batching, and PagedAttention. Supports GPT-2, OPT, and LLaMA2 models.

quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.
bee
Bee is an easy and high efficiency ORM framework that simplifies database operations by providing a simple interface and eliminating the need to write separate DAO code. It supports various features such as automatic filtering of properties, partial field queries, native statement pagination, JSON format results, sharding, multiple database support, and more. Bee also offers powerful functionalities like dynamic query conditions, transactions, complex queries, MongoDB ORM, cache management, and additional tools for generating distributed primary keys, reading Excel files, and more. The newest versions introduce enhancements like placeholder precompilation, default date sharding, ElasticSearch ORM support, and improved query capabilities.
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.

ClickHouse
ClickHouse is an open-source column-oriented database management system that allows generating analytical data reports in real-time. It offers quick high-level overview, tutorials, documentation, video content, real-time chat support, and various events for users. The tool is designed for real-time analytics and data reporting tasks, providing a scalable and efficient solution for managing analytical data.

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.
naas
Naas (Notebooks as a service) is an open source platform that enables users to create powerful data engines combining automation, analytics, and AI from Jupyter notebooks. It offers features like templates for automated data jobs and reports, drivers for data connectivity, and production-ready environment with scheduling and notifications. Naas aims to provide an alternative to Google Colab with enhanced low-code layers.

LakeSoul
LakeSoul is a cloud-native Lakehouse framework that supports scalable metadata management, ACID transactions, efficient and flexible upsert operation, schema evolution, and unified streaming & batch processing. It supports multiple computing engines like Spark, Flink, Presto, and PyTorch, and computing modes such as batch, stream, MPP, and AI. LakeSoul scales metadata management and achieves ACID control by using PostgreSQL. It provides features like automatic compaction, table lifecycle maintenance, redundant data cleaning, and permission isolation for metadata.
ezdata
Ezdata is a data processing and task scheduling system developed based on Python backend and Vue3 frontend. It supports managing multiple data sources, abstracting various data sources into a unified data model, integrating chatgpt for data question and answer functionality, enabling low-code data integration and visualization processing, scheduling single and dag tasks, and integrating a low-code data visualization dashboard system.
airflow-diagrams
Auto-generated Diagrams from Airflow DAGs. This project aims to easily visualize Airflow DAGs on a service level from providers like AWS, GCP, Azure, etc. via diagrams. It connects to your Airflow installation to retrieve all DAGs and tasks, processes them using Fuzzy String Matching, and renders the results into a Python file for diagram generation. Contributions are welcome.
airflint
Airflint is a tool designed to enforce best practices for all your Airflow Directed Acyclic Graphs (DAGs). It is currently in the alpha stage and aims to help users adhere to recommended practices when working with Airflow. Users can install Airflint from PyPI and integrate it into their existing Airflow environment to improve DAG quality. The tool provides rules for function-level imports and jinja template syntax usage, among others, to enhance the development process of Airflow DAGs.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.
ai-dev-2024-ml-workshop
The 'ai-dev-2024-ml-workshop' repository contains materials for the Deploy and Monitor ML Pipelines workshop at the AI_dev 2024 conference in Paris, focusing on deployment designs of machine learning pipelines using open-source applications and free-tier tools. It demonstrates automating data refresh and forecasting using GitHub Actions and Docker, monitoring with MLflow and YData Profiling, and setting up a monitoring dashboard with Quarto doc on GitHub Pages.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
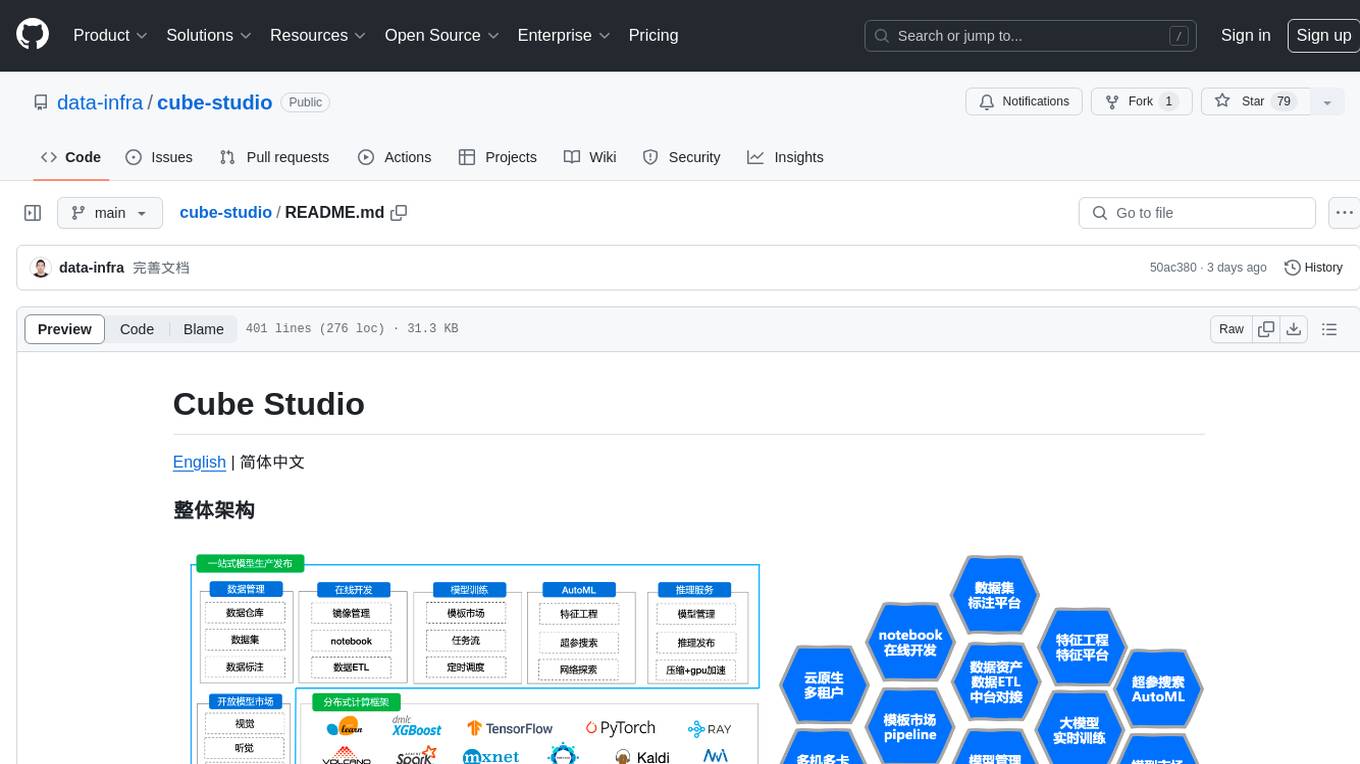
cube-studio
Cube Studio is an open-source all-in-one cloud-native machine learning platform that provides various functionalities such as project group management, network configuration, user management, role management, billing functions, SSO single sign-on, support for multiple computing power types, support for multiple resource groups and clusters, edge cluster support, serverless cluster mode support, database storage support, machine resource management, storage disk management, internationalization capabilities, data map management, data calculation, ETL orchestration, data set management, data annotation, image/audio/text dataset support, feature processing, traditional machine learning algorithms, distributed deep learning frameworks, distributed acceleration frameworks, model evaluation, model format conversion, model registration, model deployment, distributed media processing, custom operators, automatic learning, custom training images, automatic parameter tuning, TensorBoard jobs, internal services, model management, inference services, monitoring, model application management, model marketplace, model development, model fine-tuning, web model deployment, automated annotation, dataset SDK, notebook SDK, pipeline training SDK, inference service SDK, large model distributed training, large model inference, large model fine-tuning, intelligent conversation, private knowledge base, model deployment for WeChat public accounts, enterprise WeChat group chatbot integration, DingTalk group chatbot integration, and more. Cube Studio offers template-based functionality for data import/export, data processing, feature processing, machine learning frameworks, machine learning algorithms, deep learning frameworks, model processing, model serving, monitoring, and more.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
aws-reference-architecture-pulumi
The Pinecone AWS Reference Architecture with Pulumi is a distributed system designed for vector-database-enabled semantic search over Postgres records. It serves as a starting point for specific use cases or as a learning resource. The architecture is permissively licensed and supported by Pinecone's open-source team, facilitating the setup of high-scale use cases for Pinecone's scalable vector database.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.
aiodynamo
AsyncIO DynamoDB is an asynchronous pythonic client for DynamoDB, designed for asynchronous apps. It is two times faster than aiobotocore, botocore, or boto3 for operations like query or scan. The library provides a pythonic API with modern Python features, automatically depaginates paginated APIs using asynchronous iterators. The source code is legible and hand-written, allowing for easy inspection and understanding. It offers a pluggable HTTP client, enabling integration with existing asynchronous HTTP clients without additional dependencies or dependency resolution issues.
ask-astro
Ask Astro is an open-source reference implementation of Andreessen Horowitz's LLM Application Architecture built by Astronomer. It provides an end-to-end example of a Q&A LLM application used to answer questions about Apache Airflow® and Astronomer. Ask Astro includes Airflow DAGs for data ingestion, an API for business logic, a Slack bot, a public UI, and DAGs for processing user feedback. The tool is divided into data retrieval & embedding, prompt orchestration, and feedback loops.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

Toolio
Toolio is an OpenAI-like HTTP server API implementation that supports structured LLM response generation, making it conform to a JSON schema. It is useful for reliable tool calling and agentic workflows based on schema-driven output. Toolio is based on the MLX framework for Apple Silicon, specifically M1/M2/M3/M4 Macs. It allows users to host MLX-format LLMs for structured output queries and provides a command line client for easier usage of tools. The tool also supports multiple tool calls and the creation of custom tools for specific tasks.
aiobotocore
aiobotocore is an async client for Amazon services using botocore and aiohttp/asyncio. It provides a mostly full-featured asynchronous version of botocore, allowing users to interact with various AWS services asynchronously. The library supports operations such as uploading objects to S3, getting object properties, listing objects, and deleting objects. It also offers context manager examples for managing resources efficiently. aiobotocore supports multiple AWS services like S3, DynamoDB, SNS, SQS, CloudFormation, and Kinesis, with basic methods tested for each service. Users can run tests using moto for mocked tests or against personal Amazon keys. Additionally, the tool enables type checking and code completion for better development experience.
edge2ai-workshop
The edge2ai-workshop repository provides a hands-on workshop for building an IoT Predictive Maintenance workflow. It includes lab exercises for setting up components like NiFi, Streams Processing, Data Visualization, and more on a single host. The repository also covers use cases such as credit card fraud detection. Users can follow detailed instructions, prerequisites, and connectivity guidelines to connect to their cluster and explore various services. Additionally, troubleshooting tips are provided for common issues like MiNiFi not sending messages or CEM not picking up new NARs.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.
fastserve-ai
FastServe-AI is a machine learning serving tool focused on GenAI & LLMs with simplicity as the top priority. It allows users to easily serve custom models by implementing the 'handle' method for 'FastServe'. The tool provides a FastAPI server for custom models and can be deployed using Lightning AI Studio. Users can install FastServe-AI via pip and run it to serve their own GPT-like LLM models in minutes.
trex
Trex is a tool that transforms unstructured data into structured data by specifying a regex or context-free grammar. It intelligently restructures data to conform to the defined schema. It offers a Python client for installation and requires an API key obtained by signing up at automorphic.ai. The tool supports generating structured JSON objects based on user-defined schemas and prompts. Trex aims to provide significant speed improvements, structured custom CFG and regex generation, and generation from JSON schema. Future plans include auto-prompt generation for unstructured ETL and more intelligent models.
airflow-client-python
The Apache Airflow Python Client provides a range of REST API endpoints for managing Airflow metadata objects. It supports CRUD operations for resources, with endpoints accepting and returning JSON. Users can create, read, update, and delete resources. The API design follows conventions with consistent naming and field formats. Update mask is available for patch endpoints to specify fields for update. API versioning is not synchronized with Airflow releases, and changes go through a deprecation phase. The tool supports various authentication methods and error responses follow RFC 7807 format.
aigcbilibili
Aigcbilibili is a project that mimics the microservices of Bilibili, providing functionalities such as video uploading, viewing, liking, commenting, collecting, danmaku, user profile management, login methods, private messaging, intelligent PPT generation, dynamic updates, search aggregation, database operations with MyBatis-Plus, file management with MinIO, asynchronous tasks with CompletableFuture, JSON handling with FastJson, Gson, and Jackson, exception handling, logging management, file transfer, configuration management with Nacos, routing management with Gateway, authentication and authorization with Security + JWT, multiple login methods, caching with Redis, messaging with RocketMQ, search engine integration with Elasticsearch, data synchronization with XXL-Job, Redis, RocketMQ, Elasticsearch, cache implementation, real-time communication with WebSocket, distributed tracing with Sleuth + Zipkin, documentation and monitoring with Swagger, Druid, and intelligent content generation with Xunfei Xinghuo.
datachain
DataChain is an open-source Python library for processing and curating unstructured data at scale. It supports AI-driven data curation using local ML models and LLM APIs, handles large datasets, and is Python-friendly with Pydantic objects. It excels at optimizing batch operations and is designed for offline data processing, curation, and ETL. Typical use cases include Computer Vision data curation, LLM analytics, and validation.
data-prep-kit
Data Prep Kit is a community project aimed at democratizing and speeding up unstructured data preparation for LLM app developers. It provides high-level APIs and modules for transforming data (code, language, speech, visual) to optimize LLM performance across different use cases. The toolkit supports Python, Ray, Spark, and Kubeflow Pipelines runtimes, offering scalability from laptop to datacenter-scale processing. Developers can contribute new custom modules and leverage the data processing library for building data pipelines. Automation features include workflow automation with Kubeflow Pipelines for transform execution.
neo4j-runway
Neo4j Runway is a Python library that simplifies the process of migrating relational data into a graph. It provides tools to abstract communication with OpenAI for data discovery, generate data models, ingestion code, and load data into a Neo4j instance. The library leverages OpenAI LLMs for insights, Instructor Python library for modeling, and PyIngest for data loading. Users can visualize data models using graphviz and benefit from a seamless integration with Neo4j for efficient data migration.
DataEngineeringPilipinas
DataEngineeringPilipinas is a repository dedicated to data engineering resources in the Philippines. It serves as a platform for data engineering professionals to contribute and access high-quality content related to data engineering. The repository provides guidelines for contributing, including forking the repository, making changes, and submitting contributions. It emphasizes the importance of quality, relevance, and respect in the contributions made to the project. By following the guidelines and contributing to the repository, users can help build a valuable resource for the data engineering community in the Philippines and beyond.
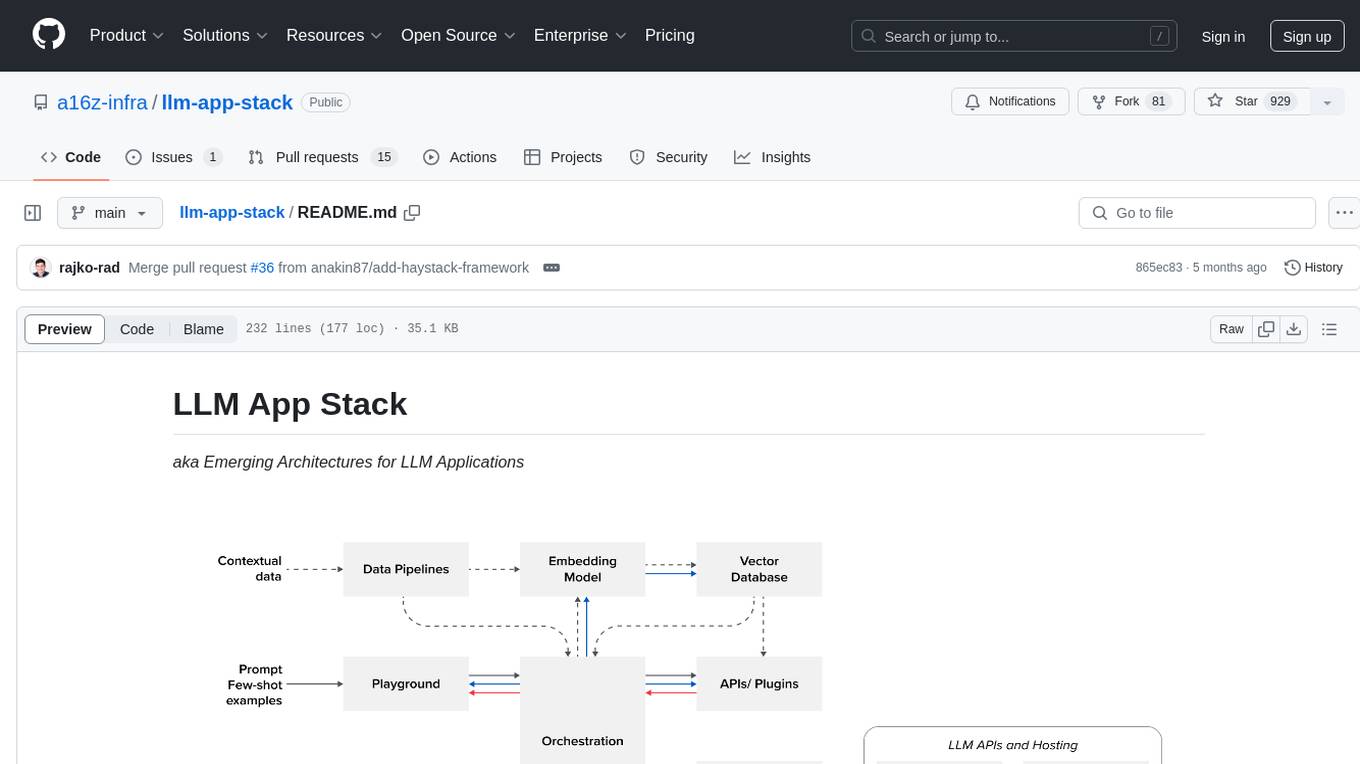
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
airflow-code-editor
The Airflow Code Editor Plugin is a tool designed for Apache Airflow users to edit Directed Acyclic Graphs (DAGs) directly within their browser. It offers a user-friendly file management interface for effortless editing, uploading, and downloading of files. With Git support enabled, users can store DAGs in a Git repository, explore Git history, review local modifications, and commit changes. The plugin enhances workflow efficiency by providing seamless DAG management capabilities.
neo4j-genai-python
This repository contains the official Neo4j GenAI features for Python. The purpose of this package is to provide a first-party package to developers, where Neo4j can guarantee long-term commitment and maintenance as well as being fast to ship new features and high-performing patterns and methods.
csghub-server
CSGHub Server is a part of the open source and reliable large model assets management platform - CSGHub. It focuses on management of models, datasets, and other LLM assets through REST API. Key features include creation and management of users and organizations, auto-tagging of model and dataset labels, search functionality, online preview of dataset files, content moderation for text and image, download of individual files, tracking of model and dataset activity data. The tool is extensible and customizable, supporting different git servers, flexible LFS storage system configuration, and content moderation options. The roadmap includes support for more Git servers, Git LFS, dataset online viewer, model/dataset auto-tag, S3 protocol support, model format conversion, and model one-click deploy. The project is licensed under Apache 2.0 and welcomes contributions.
aiomqtt
aiomqtt is an idiomatic asyncio MQTT client that allows users to interact with MQTT brokers using asyncio in Python. It eliminates the need for callbacks and return codes, providing a more streamlined experience. The tool supports MQTT versions 5.0, 3.1.1, and 3.1, and offers graceful disconnection handling. It is fully type-hinted, making it easier to work with. Users can publish and subscribe to MQTT topics with ease, making it a versatile tool for MQTT communication in Python.
postgres-new
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.
psychic
Finic is an open source python-based integration platform designed to simplify integration workflows for both business users and developers. It offers a drag-and-drop UI, a dedicated Python environment for each workflow, and generative AI features to streamline transformation tasks. With a focus on decoupling integration from product code, Finic aims to provide faster and more flexible integrations by supporting custom connectors. The tool is open source and allows deployment to users' own cloud environments with minimal legal friction.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.
sql-explorer
SQL Explorer is a Django-based application that simplifies the flow of data between users by providing a user-friendly SQL editor to write and share queries. It supports multiple database connections, AI-powered SQL assistant, schema information access, query snapshots, in-browser statistics, parameterized queries, ad-hoc query running, email query results, and more. Users can upload and query JSON or CSV files, and the tool can connect to various SQL databases supported by Django. It aims for simplicity, stability, and ease of use, offering features like autocomplete, pivot tables, and query history logs.
aiosql
aiosql is a Python module that allows you to organize SQL statements in .sql files and load them into your Python application as methods to call. It supports various database drivers like SQLite, PostgreSQL, MySQL, MariaDB, and DuckDB. The project is an implementation of Kris Jenkins' yesql library to the Python ecosystem, allowing users to easily reuse SQL code in SQL GUIs or CLI tools. With aiosql, you can write, version control, comment, and run SQL code using files without losing the ability to use them as you would any other SQL file. It provides support for PEP 249 and asyncio based drivers, enabling users to execute parametric SQL queries from Python methods.
finic
Finic is an open source python-based integration platform designed for business users to create v1 integrations with minimal code, while also being flexible for developers to build complex integrations directly in python. It offers a low-code web UI, a dedicated Python environment for each workflow, and generative AI features. Finic decouples integration from product code, supports custom connectors, and is open source. It is not an ETL tool but focuses on integrating functionality between applications via APIs or SFTP, and it is not a workflow automation tool optimized for complex use cases.
ryoma
Ryoma is an AI Powered Data Agent framework that offers a comprehensive solution for data analysis, engineering, and visualization. It leverages cutting-edge technologies like Langchain, Reflex, Apache Arrow, Jupyter Ai Magics, Amundsen, Ibis, and Feast to provide seamless integration of language models, build interactive web applications, handle in-memory data efficiently, work with AI models, and manage machine learning features in production. Ryoma also supports various data sources like Snowflake, Sqlite, BigQuery, Postgres, MySQL, and different engines like Apache Spark and Apache Flink. The tool enables users to connect to databases, run SQL queries, and interact with data and AI models through a user-friendly UI called Ryoma Lab.
olah
Olah is a self-hosted lightweight Huggingface mirror service that implements mirroring feature for Huggingface resources at file block level, enhancing download speeds and saving bandwidth. It offers cache control policies and allows administrators to configure accessible repositories. Users can install Olah with pip or from source, set up the mirror site, and download models and datasets using huggingface-cli. Olah provides additional configurations through a configuration file for basic setup and accessibility restrictions. Future work includes implementing an administrator and user system, OOS backend support, and mirror update schedule task. Olah is released under the MIT License.
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
opik
Comet Opik is a repository containing two main services: a frontend and a backend. It provides a Python SDK for easy installation. Users can run the full application locally with minikube, following specific installation prerequisites. The repository structure includes directories for applications like Opik backend, with detailed instructions available in the README files. Users can manage the installation using simple k8s commands and interact with the application via URLs for checking the running application and API documentation. The repository aims to facilitate local development and testing of Opik using Kubernetes technology.
genai-workshop
The Neo4j GenAI Workshop repository contains notebooks for a workshop focusing on building a Neo4j Graph, text embedding, and providing demos for content generation. The workshop includes data staging, loading, and exploration using Cypher queries. It also covers improvements in LLM response quality, GPT-4 usage, and vector search speed. The repository has undergone multiple updates to enhance course quality, simplify content, and provide better explainers and examples.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.
Awesome-LLM-Quantization
Awesome-LLM-Quantization is a curated list of resources related to quantization techniques for Large Language Models (LLMs). Quantization is a crucial step in deploying LLMs on resource-constrained devices, such as mobile phones or edge devices, by reducing the model's size and computational requirements.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.
Awesome-AI-Data-GitHub-Repos
Awesome AI & Data GitHub-Repos is a curated list of essential GitHub repositories covering the AI & ML landscape. It includes resources for Natural Language Processing, Large Language Models, Computer Vision, Data Science, Machine Learning, MLOps, Data Engineering, SQL & Database, and Statistics. The repository aims to provide a comprehensive collection of projects and resources for individuals studying or working in the field of AI and data science.
zipnn
ZipNN is a lossless and near-lossless compression library optimized for numbers/tensors in the Foundation Models environment. It automatically prepares data for compression based on its type, allowing users to focus on core tasks without worrying about compression complexities. The library delivers effective compression techniques for different data types and structures, achieving high compression ratios and rates. ZipNN supports various compression methods like ZSTD, lz4, and snappy, and provides ready-made scripts for file compression/decompression. Users can also manually import the package to compress and decompress data. The library offers advanced configuration options for customization and validation tests for different input and compression types.
lantern
Lantern is an open-source PostgreSQL database extension designed to store vector data, generate embeddings, and handle vector search operations efficiently. It introduces a new index type called 'lantern_hnsw' for vector columns, which speeds up 'ORDER BY ... LIMIT' queries. Lantern utilizes the state-of-the-art HNSW implementation called usearch. Users can easily install Lantern using Docker, Homebrew, or precompiled binaries. The tool supports various distance functions, index construction parameters, and operator classes for efficient querying. Lantern offers features like embedding generation, interoperability with pgvector, parallel index creation, and external index graph generation. It aims to provide superior performance metrics compared to other similar tools and has a roadmap for future enhancements such as cloud-hosted version, hardware-accelerated distance metrics, industry-specific application templates, and support for version control and A/B testing of embeddings.
sail
Sail is a tool designed to unify stream processing, batch processing, and compute-intensive workloads, serving as a drop-in replacement for Spark SQL and the Spark DataFrame API in single-process settings. It aims to streamline data processing tasks and facilitate AI workloads.
celery-aio-pool
Celery AsyncIO Pool is a free software tool licensed under GNU Affero General Public License v3+. It provides an AsyncIO worker pool for Celery, enabling users to leverage the power of AsyncIO in their Celery applications. The tool allows for easy installation using Poetry, pip, or directly from GitHub. Users can configure Celery to use the AsyncIO pool provided by celery-aio-pool, or they can wait for the upcoming support for out-of-tree worker pools in Celery 5.3. The tool is actively maintained and welcomes contributions from the community.
ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project facilitates sharing and exchanging technologies related to large model semantic cache through open-source collaboration.
niledatabase
Nile is a serverless Postgres database designed for modern SaaS applications. It virtualizes tenants/customers/organizations into Postgres to enable native tenant data isolation, performance isolation, per-tenant backups, and tenant placement on shared or dedicated compute globally. With Nile, you can manage multiple tenants effortlessly, without complex permissions or buggy scripts. Additionally, it offers opt-in user management capabilities, customer-specific vector embeddings, and instant tenant admin dashboards. Built for the cloud, Nile provides a true serverless experience with effortless scaling.
VectorETL
VectorETL is a lightweight ETL framework designed to assist Data & AI engineers in processing data for AI applications quickly. It streamlines the conversion of diverse data sources into vector embeddings and storage in various vector databases. The framework supports multiple data sources, embedding models, and vector database targets, simplifying the creation and management of vector search systems for semantic search, recommendation systems, and other vector-based operations.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.
csghub
CSGHub is an open source platform for managing large model assets, including datasets, model files, and codes. It offers functionalities similar to a privatized Huggingface, managing assets in a manner akin to how OpenStack Glance manages virtual machine images. Users can perform operations such as uploading, downloading, storing, verifying, and distributing assets through various interfaces. The platform provides microservice submodules and standardized OpenAPIs for easy integration with users' systems. CSGHub is designed for large models and can be deployed On-Premise for offline operation.
Awesome-RoadMaps-and-Interviews
Awesome RoadMaps and Interviews is a comprehensive repository that aims to provide guidance for technical interviews and career development in the ITCS field. It covers a wide range of topics including interview strategies, technical knowledge, and practical insights gained from years of interviewing experience. The repository emphasizes the importance of combining theoretical knowledge with practical application, and encourages users to expand their interview preparation beyond just algorithms. It also offers resources for enhancing knowledge breadth, depth, and programming skills through curated roadmaps, mind maps, cheat sheets, and coding snippets. The content is structured to help individuals navigate various technical roles and technologies, fostering continuous learning and professional growth.
dbt-airflow
A Python package that helps Data and Analytics engineers render dbt projects in Apache Airflow DAGs. It enables teams to automatically render their dbt projects in a granular level, creating individual Airflow tasks for every model, seed, snapshot, and test within the dbt project. This allows for full control at the task-level, improving visibility and management of data models within the team.
llama_deploy
llama_deploy is an async-first framework for deploying, scaling, and productionizing agentic multi-service systems based on workflows from llama_index. It allows building workflows in llama_index and deploying them seamlessly with minimal changes to code. The system includes services endlessly processing tasks, a control plane managing state and services, an orchestrator deciding task handling, and fault tolerance mechanisms. It is designed for high-concurrency scenarios, enabling real-time and high-throughput applications.
databend
Databend is an open-source cloud data warehouse built in Rust, offering fast query execution and data ingestion for complex analysis of large datasets. It integrates with major cloud platforms, provides high performance with AI-powered analytics, supports multiple data formats, ensures data integrity with ACID transactions, offers flexible indexing options, and features community-driven development. Users can try Databend through a serverless cloud or Docker installation, and perform tasks such as data import/export, querying semi-structured data, managing users/databases/tables, and utilizing AI functions.
cli-agent
Pieces CLI for Developers is a comprehensive command-line interface (CLI) tool designed to interact seamlessly with Pieces OS. It provides functionalities such as asset management, application interaction, and integration with various Pieces OS features. The tool is compatible with Windows 10 or greater, Mac, and Windows operating systems. Users can install the tool by running 'pip install pieces-cli' or 'brew install pieces-cli'. After installation, users can access the tool's functionalities through the terminal by using the 'pieces' command followed by subcommands and options. The tool supports various commands, which can be found in the documentation. Developers can contribute to the project by forking and cloning the repository, setting up a virtual environment, installing dependencies with poetry, and running test cases with pytest and coverage.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.
db2rest
DB2Rest is a modern low code REST DATA API platform that enables the rapid development of intelligent applications by combining databases, language models, and vector stores. It facilitates context-aware, reasoning applications without vendor lock-in. The tool accelerates application delivery, fosters faster innovation with AI, serves as a secure database gateway, and simplifies integration. It supports various databases like PostgreSQL, MySQL, MS SQL Server, Oracle, MongoDB, and more, with planned support for additional databases. Users can connect on Discord for support and contact [email protected] for inquiries.
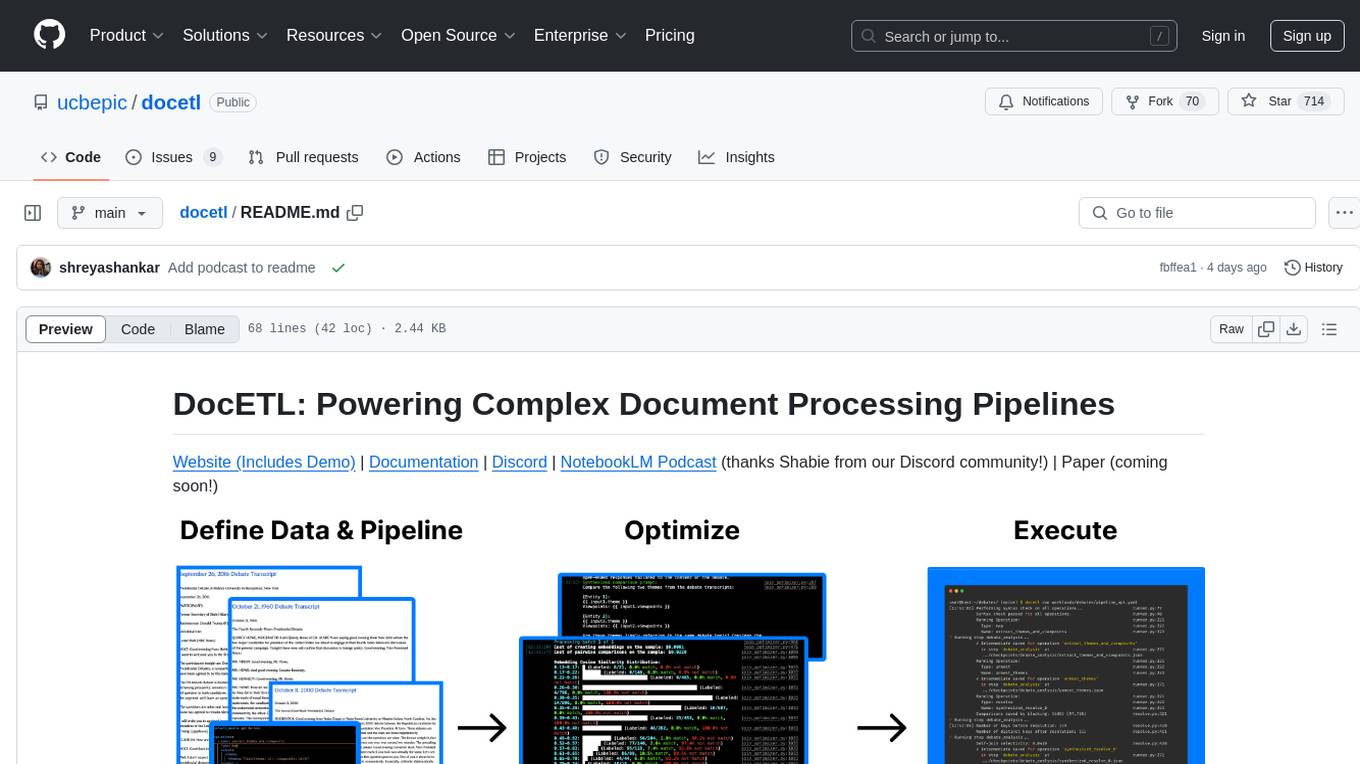
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
litlytics
LitLytics is an affordable analytics platform leveraging LLMs for automated data analysis. It simplifies analytics for teams without data scientists, generates custom pipelines, and allows customization. Cost-efficient with low data processing costs. Scalable and flexible, works with CSV, PDF, and plain text data formats.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.
vecs
vecs is a Python client for managing and querying vector stores in PostgreSQL with the pgvector extension. It allows users to create collections of vectors with associated metadata, index the collections for fast search performance, and query the collections based on specified filters. The tool simplifies the process of working with vector data in a PostgreSQL database, making it easier to store, retrieve, and analyze vector information.
dataengineering-roadmap
A repository providing basic concepts, technical challenges, and resources on data engineering in Spanish. It is a curated list of free, Spanish-language materials found on the internet to facilitate the study of data engineering enthusiasts. The repository covers programming fundamentals, programming languages like Python, version control with Git, database fundamentals, SQL, design concepts, Big Data, analytics, cloud computing, data processing, and job search tips in the IT field.
GenAIComps
GenAIComps is an initiative aimed at building enterprise-grade Generative AI applications using a microservice architecture. It simplifies the scaling and deployment process for production, abstracting away infrastructure complexities. GenAIComps provides a suite of containerized microservices that can be assembled into a mega-service tailored for real-world Enterprise AI applications. The modular approach of microservices allows for independent development, deployment, and scaling of individual components, promoting modularity, flexibility, and scalability. The mega-service orchestrates multiple microservices to deliver comprehensive solutions, encapsulating complex business logic and workflow orchestration. The gateway serves as the interface for users to access the mega-service, providing customized access based on user requirements.
airflow-provider-great-expectations
The 'airflow-provider-great-expectations' repository contains a set of Airflow operators for Great Expectations, a Python library used for testing and validating data. The operators enable users to run Great Expectations validations and checks within Apache Airflow workflows. The package requires Airflow 2.1.0+ and Great Expectations >=v0.13.9. It provides functionalities to work with Great Expectations V3 Batch Request API, Checkpoints, and allows passing kwargs to Checkpoints at runtime. The repository includes modules for a base operator and examples of DAGs with sample tasks demonstrating the operator's functionality.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
zero-true
Zero-True is a Python and SQL reactive computational notebook designed for building and collaborating on data-driven applications. It offers an integrated and simple environment with transparent updates, dynamic and interactive UI rendering, fast prototyping capabilities, and open-source community contributions. Users can create rich, reactive apps with ease and publish them confidently. Zero-True aims to improve data accessibility and foster collaboration among users.
datahub
DataHub is an open-source data catalog designed for the modern data stack. It provides a platform for managing metadata, enabling users to discover, understand, and collaborate on data assets within their organization. DataHub offers features such as data lineage tracking, data quality monitoring, and integration with various data sources. It is built with contributions from Acryl Data and LinkedIn, aiming to streamline data management processes and enhance data discoverability across different teams and departments.

Bodo
Bodo is a high-performance Python compute engine designed for large-scale data processing and AI workloads. It utilizes an auto-parallelizing just-in-time compiler to optimize Python programs, making them 20x to 240x faster compared to alternatives. Bodo seamlessly integrates with native Python APIs like Pandas and NumPy, eliminates runtime overheads using MPI for distributed execution, and provides exceptional performance and scalability for data workloads. It is easy to use, interoperable with the Python ecosystem, and integrates with modern data platforms like Apache Iceberg and Snowflake. Bodo focuses on data-intensive and computationally heavy workloads in data engineering, data science, and AI/ML, offering automatic optimization and parallelization, linear scalability, advanced I/O support, and a high-performance SQL engine.
swarmauri-sdk
Swarmauri SDK is a repository containing core interfaces, standard ABCs, and standard concrete references of the SwarmaURI Framework. It provides a set of tools and functionalities for developers to work with the SwarmaURI ecosystem. The SDK aims to streamline the development process and enhance the interoperability of applications within the framework. Developers can easily integrate SwarmaURI features into their projects by leveraging the resources available in this repository.

trafilatura
Trafilatura is a Python package and command-line tool for gathering text on the Web and simplifying the process of turning raw HTML into structured, meaningful data. It includes components for web crawling, downloads, scraping, and extraction of main texts, metadata, and comments. The tool aims to focus on actual content, avoid noise, and make sense of data and metadata. It is robust, fast, and widely used by companies and institutions. Trafilatura outperforms other libraries in text extraction benchmarks and offers various features like support for sitemaps, parallel processing, configurable extraction of key elements, multiple output formats, and optional add-ons. The tool is actively maintained with regular updates and comprehensive documentation.

minefield
BitBom Minefield is a tool that uses roaring bit maps to graph Software Bill of Materials (SBOMs) with a focus on speed, air-gapped operation, scalability, and customizability. It is optimized for rapid data processing, operates securely in isolated environments, supports millions of nodes effortlessly, and allows users to extend the project without relying on upstream changes. The tool enables users to manage and explore software dependencies within isolated environments by offline processing and analyzing SBOMs.
data-engineering-zoomcamp
Data Engineering Zoomcamp is a comprehensive course covering various aspects of data engineering, including data ingestion, workflow orchestration, data warehouse, analytics engineering, batch processing, and stream processing. The course provides hands-on experience with tools like Python, Rust, Terraform, Airflow, BigQuery, dbt, PySpark, Kafka, and more. Students will learn how to work with different data technologies to build scalable and efficient data pipelines for analytics and processing. The course is designed for individuals looking to enhance their data engineering skills and gain practical experience in working with big data technologies.

cloudberry
Apache Cloudberry (Incubating) is an advanced and mature open-source Massively Parallel Processing (MPP) database, evolving from the open-source version of the Pivotal Greenplum Database®️. It features a newer PostgreSQL kernel and advanced enterprise capabilities, serving as a data warehouse for large-scale analytics and AI/ML workloads. The main repository includes ecosystem repositories for the website, extensions, connectors, adapters, and utilities.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.
awesome-ai4db-paper
The 'awesome-ai4db-paper' repository is a curated paper list focusing on AI for database (AI4DB) theory, frameworks, resources, and tools for data engineers. It includes a collection of research papers related to learning-based query optimization, training data set preparation, cardinality estimation, query-driven approaches, data-driven techniques, hybrid methods, pretraining models, plan hints, cost models, SQL embedding, join order optimization, query rewriting, end-to-end systems, text-to-SQL conversion, traditional database technologies, storage solutions, learning-based index design, and a learning-based configuration advisor. The repository aims to provide a comprehensive resource for individuals interested in AI applications in the field of database management.
Agentarium
Agentarium is a powerful Python framework for managing and orchestrating AI agents with ease. It provides a flexible and intuitive way to create, manage, and coordinate interactions between multiple AI agents in various environments. The framework offers advanced agent management, robust interaction management, a checkpoint system for saving and restoring agent states, data generation through agent interactions, performance optimization, flexible environment configuration, and an extensible architecture for customization.

spiceai
Spice is a portable runtime written in Rust that offers developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake. It connects, fuses, and delivers data to applications, machine-learning models, and AI-backends, functioning as an application-specific, tier-optimized Database CDN. Built with industry-leading technologies such as Apache DataFusion, Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB. Spice makes it fast and easy to query data from one or more sources using SQL, co-locating a managed dataset with applications or machine learning models, and accelerating it with Arrow in-memory, SQLite/DuckDB, or attached PostgreSQL for fast, high-concurrency, low-latency queries.

preswald
Preswald is a full-stack platform for building, deploying, and managing interactive data applications in Python. It simplifies the process by combining ingestion, storage, transformation, and visualization into one lightweight SDK. With Preswald, users can connect to various data sources, customize app themes, and easily deploy apps locally. The platform focuses on code-first simplicity, end-to-end coverage, and efficiency by design, making it suitable for prototyping internal tools or deploying production-grade apps with reduced complexity and cost.
FinalRip
FinalRip is a distributed video processing tool based on FFmpeg and VapourSynth. It cuts the original video into multiple clips, processes each clip in parallel, and merges them into the final video. Users can deploy the system in a distributed way, configure settings via environment variables or remote config files, and develop/test scripts in the vs-playground environment. It supports Nvidia GPU, AMD GPU with ROCm support, and provides a dashboard for selecting compatible scripts to process videos.

letsql
LETSQL is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It is currently in development and does not have a stable release. Users can install LETSQL from PyPI and use it to connect to data sources, read data, filter, group, and aggregate data for analysis. Contributions to the project are welcome, and the library is actively maintained with support available for any issues. LETSQL heavily relies on Ibis and DataFusion for its functionality.
buster
Buster is a modern analytics platform designed with AI in mind, focusing on self-serve experiences powered by Large Language Models. It addresses pain points in existing tools by advocating for AI-centric app development, cost-effective data warehousing, improved CI/CD processes, and empowering data teams to create powerful, user-friendly data experiences. The platform aims to revolutionize AI analytics by enabling data teams to build deep integrations and own their entire analytics stack.
treds
Treds is a Radix Trie based data structure server that stores keys in sorted order, ensuring fast and efficient retrieval. It offers various commands for key/value store, sorted maps store, list store, set store, hash store, and more. Treds provides unique features like optimized querying for keys with common prefixes, sorted key/value pairs, and new commands like DELPREFIX, LNGPREFIX, and PPUBLISH. It is designed for high performance with single-threaded architecture and event loop, utilizing modified Radix trees and Doubly Linked Lists for quick lookup. Treds also supports PubSub functionality and vector store operations for vector search using HNSW algorithm.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.
BESSER
BESSER is a low-modeling low-code open-source platform funded by an FNR Pearl grant. It is built on B-UML, a Python-based interpretation of a 'Universal Modeling Language'. Users can specify their software application using B-UML and generate executable code for various applications like Django models or SQLAlchemy-compatible database structures. BESSER is available on PyPi and can be installed with pip. It supports popular Python IDEs and encourages contributions from the community.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.
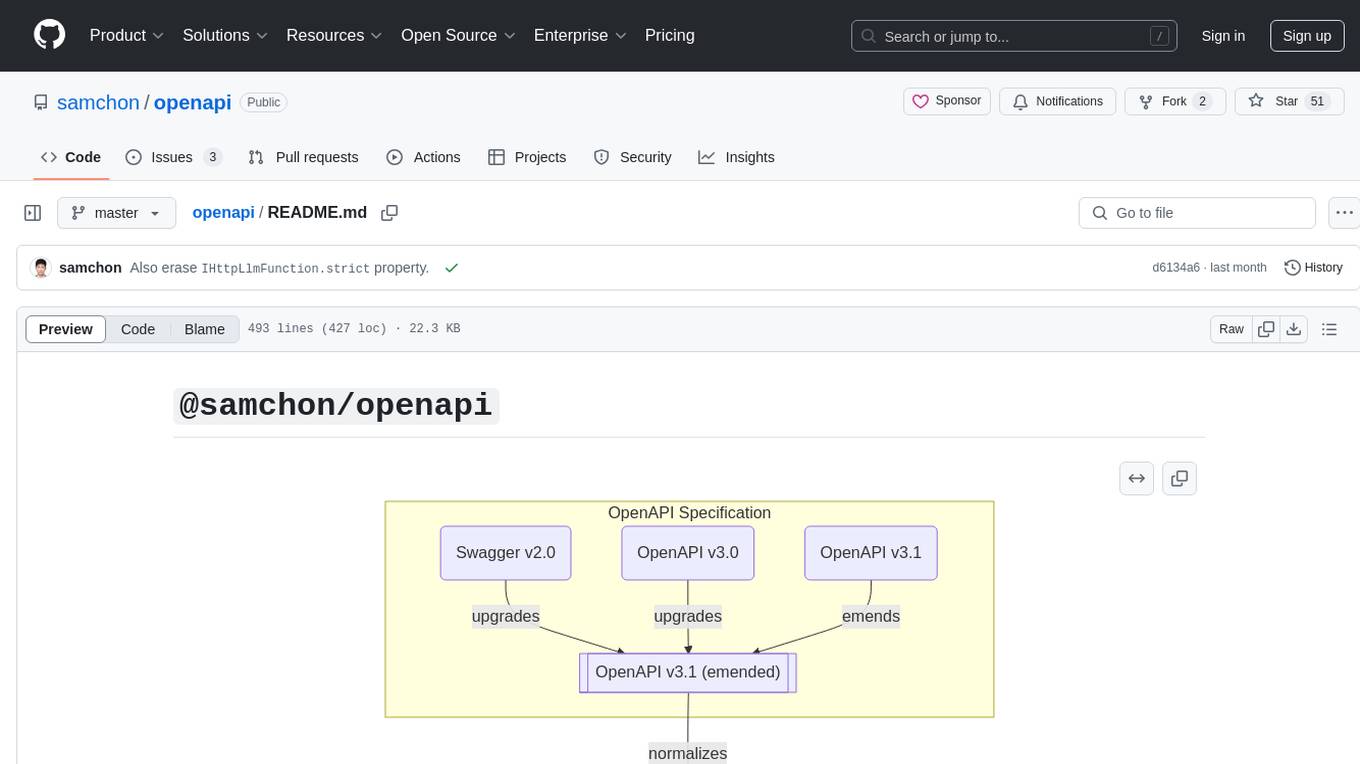
openapi
The `@samchon/openapi` repository is a collection of OpenAPI types and converters for various versions of OpenAPI specifications. It includes an 'emended' OpenAPI v3.1 specification that enhances clarity by removing ambiguous and duplicated expressions. The repository also provides an application composer for LLM (Large Language Model) function calling from OpenAPI documents, allowing users to easily perform LLM function calls based on the Swagger document. Conversions to different versions of OpenAPI documents are also supported, all based on the emended OpenAPI v3.1 specification. Users can validate their OpenAPI documents using the `typia` library with `@samchon/openapi` types, ensuring compliance with standard specifications.
metaflow-service
Metaflow Service is a metadata service implementation for Metaflow, providing a thin wrapper around a database to keep track of metadata associated with Flows, Runs, Steps, Tasks, and Artifacts. It includes features for managing DB migrations, launching compatible versions of the metadata service, and executing flows locally. The service can be run using Docker or as a standalone service, with options for testing and running unit/integration tests. Users can interact with the service via API endpoints or utility CLI tools.

airweave
Airweave is an open-core tool that simplifies the process of making data searchable by unifying apps, APIs, and databases into a vector database with minimal configuration. It offers over 120 integrations, simplicity in syncing data from diverse sources, extensibility through 'sources', 'destinations', and 'embedders', and an async-first approach for large-scale data synchronization. With features like no-code setup, white-labeled multi-tenant support, chunk generators, automated sync, versioning & hashing, multi-source support, and scalability, Airweave provides a comprehensive solution for building applications that require semantic search.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
Roadmap-Docs
This repository provides comprehensive roadmaps for various roles in the Data Analytics, Data Science, and Artificial Intelligence industry. It aims to guide individuals, whether students or professionals, in understanding the required skills and timeline for different roles, helping them focus on learning the necessary skills to secure a job. The repository includes detailed guides for roles such as Data Analyst, Data Engineer, Data Scientist, AI Engineer, Computer Vision Engineer, Generative AI Engineer, Machine Learning Engineer, NLP Engineer, and Domain-Specific ML Topics for Researchers.
yek
Yek is a fast Rust-based tool designed to read text-based files in a repository or directory, chunk them, and serialize them for Large Language Models (LLM) consumption. It utilizes .gitignore rules to skip unwanted files, Git history to infer important files, and additional ignore patterns. Yek splits content into chunks based on token count or byte size, supports processing multiple directories, and can stream content when output is piped. It is configurable via a 'yek.toml' file and prioritizes important files at the end of the output.
aps-toolkit
APS Toolkit is a powerful tool for developers, software engineers, and AI engineers to explore Autodesk Platform Services (APS). It allows users to read, download, and write data from APS, as well as export data to various formats like CSV, Excel, JSON, and XML. The toolkit is built on top of Autodesk.Forge and Newtonsoft.Json, offering features such as reading SVF models, querying properties database, exporting data, and more.
pandas-ai
PandaAI is a Python platform that enables users to interact with their data in natural language, catering to both non-technical and technical users. It simplifies data querying and analysis, offering conversational data analytics capabilities with minimal code. Users can ask questions, visualize charts, and compare dataframes effortlessly. The tool aims to streamline data exploration and decision-making processes by providing a user-friendly interface for data manipulation and analysis.
xorq
Xorq (formerly LETSQL) is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It provides a flexible and powerful tool for processing and analyzing data from various sources, enabling users to create complex data pipelines and perform advanced data transformations.
morph
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.

feast
Feast is an open source feature store for machine learning, providing a fast path to manage infrastructure for productionizing analytic data. It allows ML platform teams to make features consistently available, avoid data leakage, and decouple ML from data infrastructure. Feast abstracts feature storage from retrieval, ensuring portability across different model training and serving scenarios.
AIDE-unipi
AIDE @ unipi is a repository containing students' material for the course in Artificial Intelligence and Data Engineering at University of Pisa. It includes slides, students' notes, information about exams methods, oral questions, past exams, and links to past students' projects. The material is unofficial and created by students for students, checked only by students. Contributions are welcome through pull requests, issues, or contacting maintainers. The repository aims to provide non-profit resources for the course, with the opportunity for contributors to be acknowledged and credited. It also offers links to Telegram and WhatsApp groups for further interaction and a Google Drive folder with additional resources for AIDE published by past students.
greenmask
Greenmask is a powerful open-source utility designed for logical database backup dumping, anonymization, synthetic data generation, and restoration. It is highly customizable, stateless, and backward-compatible with existing PostgreSQL utilities. Greenmask supports advanced subset systems, deterministic transformers, dynamic parameters, transformation conditions, and more. It is cross-platform, database type safe, extensible, and supports parallel execution and various storage options. Ideal for backup and restoration tasks, anonymization, transformation, and data masking.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.

cog-comfyui
Cog-ComfyUI is a tool designed to run ComfyUI workflows on Replicate. It allows users to easily integrate their own workflows into their app or website using the Replicate API. The tool includes popular model weights and custom nodes, with the option to request more custom nodes or models. Users can get their API JSON, gather input files, and use custom LoRAs from CivitAI or HuggingFace. Additionally, users can run their workflows and set up their own dedicated instances for better performance and control. The tool provides options for private deployments, forking using Cog, or creating new models from the train tab on Replicate. It also offers guidance on developing locally and running the Web UI from a Cog container.
mcp-go
MCP Go is a Go implementation of the Model Context Protocol (MCP), facilitating seamless integration between LLM applications and external data sources and tools. It handles complex protocol details and server management, allowing developers to focus on building tools. The tool is designed to be fast, simple, and complete, aiming to provide a high-level and easy-to-use interface for developing MCP servers. MCP Go is currently under active development, with core features working and advanced capabilities in progress.

dlio_benchmark
DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.

trainer
Kubeflow Trainer is a Kubernetes-native project for fine-tuning large language models (LLMs) and enabling scalable, distributed training of machine learning (ML) models across various frameworks. It allows integration with ML libraries like HuggingFace, DeepSpeed, or Megatron-LM to orchestrate ML training on Kubernetes. Develop LLMs effortlessly with the Kubeflow Python SDK and build Kubernetes-native Training Runtimes with Kubernetes Custom Resources APIs.
build-an-agentic-llm-assistant
This repository provides a hands-on workshop for developers and solution builders to build a real-life serverless LLM application using foundation models (FMs) through Amazon Bedrock and advanced design patterns such as Reason and Act (ReAct) Agent, text-to-SQL, and Retrieval Augmented Generation (RAG). It guides users through labs to explore common and advanced LLM application design patterns, helping them build a complex Agentic LLM assistant capable of answering retrieval and analytical questions on internal knowledge bases. The repository includes labs on IaC with AWS CDK, building serverless LLM assistants with AWS Lambda and Amazon Bedrock, refactoring LLM assistants into custom agents, extending agents with semantic retrieval, and querying SQL databases. Users need to set up AWS Cloud9, configure model access on Amazon Bedrock, and use Amazon SageMaker Studio environment to run data-pipelines notebooks.
gateway
CentralMind Gateway is an AI-first data gateway that securely connects any data source and automatically generates secure, LLM-optimized APIs. It filters out sensitive data, adds traceability, and optimizes for AI workloads. Suitable for companies deploying AI agents for customer support and analytics.
azure-health-data-and-ai-samples
The Azure Health Data and AI Samples Repo is a collection of sample apps and code to help users start with Azure Health Data and AI services, learn product usage, and speed up implementations. It includes samples for various health data workflows, such as data ingestion, analytics, machine learning, SMART on FHIR, patient services, FHIR service integration, Azure AD B2C access, DICOM service, MedTech service, and healthcare data solutions in Microsoft Fabric. These samples are simplified scenarios for testing purposes only.
aioreactive
Aioreactive is a Python library that brings ReactiveX functionality to asyncio using async and await. It is built on the Expression functional library and aims to provide a simple, clean, and async-based approach to reactive programming in Python. The library supports Python 3.10+ and focuses on using plain old functions for operators, running on the asyncio event loop, and providing implicit synchronous back-pressure for event processing.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.
interaqt
Interaqt is a project that aims to separate application business logic from its specific implementation by providing a structured data model and tools to automatically decide and implement software architecture. It liberates individuals and teams from implementation specifics, performance requirements, and cost demands, allowing them to focus on articulating business logic. The approach is considered optimal in the era of large language models (LLMs) as it eliminates uncertainty in generated systems and enables independence from engineering involvement unless specific capabilities are required.

agent
Xata Agent is an open source tool designed to monitor PostgreSQL databases, identify issues, and provide recommendations for improvements. It acts as an AI expert, offering proactive suggestions for configuration tuning, troubleshooting performance issues, and common database problems. The tool is extensible, supports monitoring from cloud services like RDS & Aurora, and uses preset SQL commands to ensure database safety. Xata Agent can run troubleshooting statements, notify users of issues via Slack, and supports multiple AI models for enhanced functionality. It is actively used by the Xata team to manage Postgres databases efficiently.
data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.
InfiniStore
InfiniStore is an open-source high-performance KV store designed to support LLM Inference clusters. It provides high-performance and low-latency KV cache transfer and reuse among inference nodes. In addition to inference clusters, it can be used as a standalone KV store for integration with LLM training or inference services. InfiniStore is currently integrated with vLLM via LMCache and is in progress for integration with SGLang and other inference engines.

duckdb-airport-extension
The 'duckdb-airport-extension' is a tool that enables the use of Arrow Flight with DuckDB. It provides functions to list available Arrow Flights at a specific endpoint and to retrieve the contents of an Arrow Flight. The extension also supports creating secrets for authentication purposes. It includes features for serializing filters and optimizing projections to enhance data transmission efficiency. The tool is built on top of gRPC and the Arrow IPC format, offering high-performance data services for data processing and retrieval.
cocoindex
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental updates specialized for data indexing. Users declare the transformation, CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. It provides a Python library for data indexing with features like text embedding, code embedding, PDF parsing, and more. The tool is designed to simplify the process of indexing data for semantic search and structured information extraction.
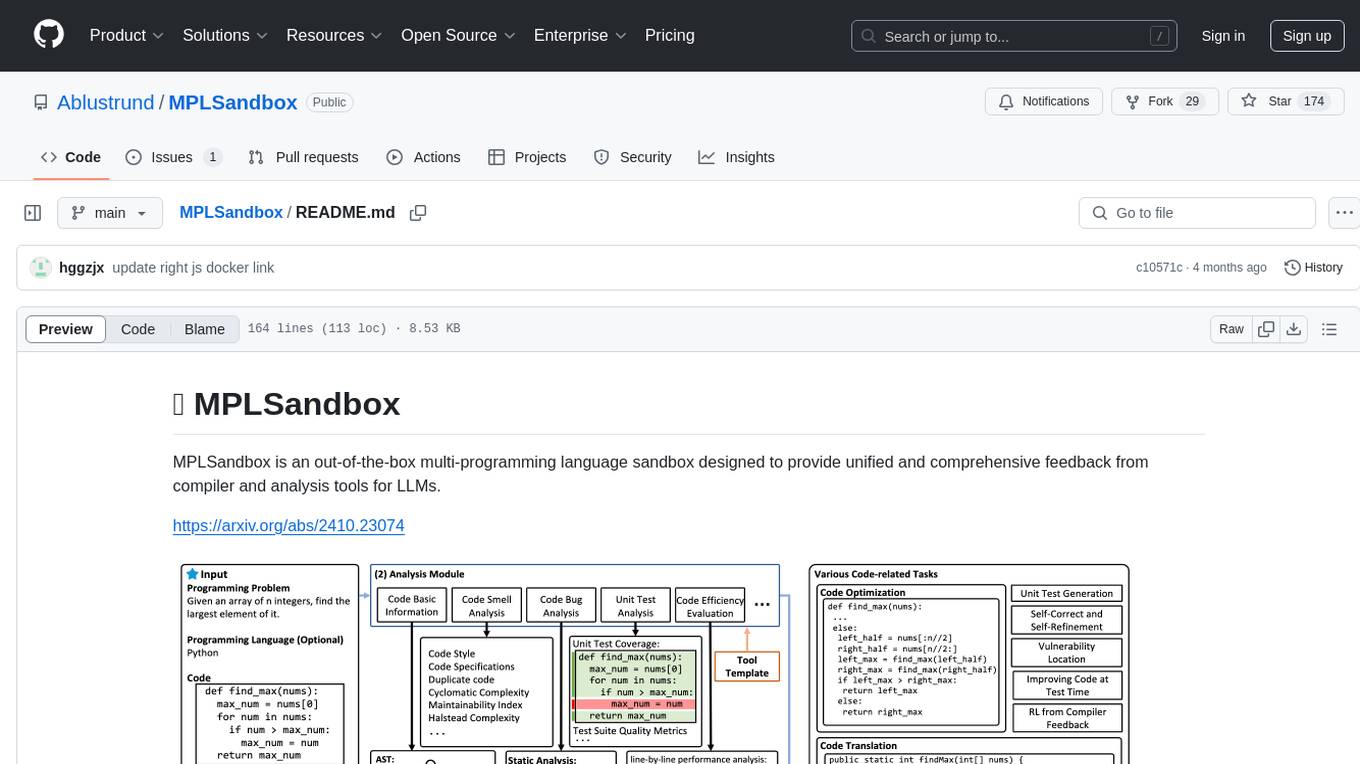
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.
AgentIQ
AgentIQ is a flexible library designed to seamlessly integrate enterprise agents with various data sources and tools. It enables true composability by treating agents, tools, and workflows as simple function calls. With features like framework agnosticism, reusability, rapid development, profiling, observability, evaluation system, user interface, and MCP compatibility, AgentIQ empowers developers to move quickly, experiment freely, and ensure reliability across agent-driven projects.
pipeshub-ai
Pipeshub-ai is a versatile tool for automating data pipelines in AI projects. It provides a user-friendly interface to design, deploy, and monitor complex data workflows, enabling seamless integration of various AI models and data sources. With Pipeshub-ai, users can easily create end-to-end pipelines for tasks such as data preprocessing, model training, and inference, streamlining the AI development process and improving productivity. The tool supports integration with popular AI frameworks and cloud services, making it suitable for both beginners and experienced AI practitioners.
ipex-llm
The `ipex-llm` repository is an LLM acceleration library designed for Intel GPU, NPU, and CPU. It provides seamless integration with various models and tools like llama.cpp, Ollama, HuggingFace transformers, LangChain, LlamaIndex, vLLM, Text-Generation-WebUI, DeepSpeed-AutoTP, FastChat, Axolotl, and more. The library offers optimizations for over 70 models, XPU acceleration, and support for low-bit (FP8/FP6/FP4/INT4) operations. Users can run different models on Intel GPUs, NPU, and CPUs with support for various features like finetuning, inference, serving, and benchmarking.
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.

terraform-provider-airbyte
Programatically control Airbyte Cloud through an API. Developers can create an API Key within the Developer Portal to make API requests. The provider allows for integration building by showing network request information and API usage details. It offers resources and data sources for various destinations and sources, enabling users to manage data flow between different services.

dingo
Dingo is a data quality evaluation tool that automatically detects data quality issues in datasets. It provides built-in rules and model evaluation methods, supports text and multimodal datasets, and offers local CLI and SDK usage. Dingo is designed for easy integration into evaluation platforms like OpenCompass.

airflow-ai-sdk
This repository contains an SDK for working with LLMs from Apache Airflow, based on Pydantic AI. It allows users to call LLMs and orchestrate agent calls directly within their Airflow pipelines using decorator-based tasks. The SDK leverages the familiar Airflow `@task` syntax with extensions like `@task.llm`, `@task.llm_branch`, and `@task.agent`. Users can define tasks that call language models, orchestrate multi-step AI reasoning, change the control flow of a DAG based on LLM output, and support various models in the Pydantic AI library. The SDK is designed to integrate LLM workflows into Airflow pipelines, from simple LLM calls to complex agentic workflows.
aiologic
aiologic is a locking library for tasks synchronization and their communication. It provides primitives that are both async-aware and thread-aware, and can be used for interaction between async codes (async <-> async) in one thread as regular async primitives, async codes (async <-> async) in multiple threads, async code and sync one (async <-> sync) in one thread, async code and sync one (async <-> sync) in multiple threads, sync codes (sync <-> sync) in one thread as regular sync primitives, sync codes (sync <-> sync) in multiple threads as regular sync primitives. It offers synchronization primitives like events, barriers, semaphores, capacity limiters, locks, readers-writer locks, condition variables, communication primitives like queues, non-blocking primitives like flags and resource guards, and supports various concurrency libraries like asyncio, curio, trio, anyio, eventlet, gevent, and threading. aiologic is implemented entirely on effectively atomic operations, providing incredible speedup on PyPy compared to alternatives from the threading module. It works in free-threaded mode and ensures atomic operations even with GIL.
qsv
qsv is a command line program for querying, slicing, indexing, analyzing, filtering, enriching, transforming, sorting, validating, joining, formatting & converting tabular data (CSV, spreadsheets, DBs, parquet, etc). Commands are simple, composable & 'blazing fast'. It is a blazing-fast data-wrangling toolkit with a focus on speed, processing very large files, and being a complete data-wrangling toolkit. It is designed to be portable, easy to use, secure, and easy to contribute to. qsv follows the RFC 4180 CSV standard, requires UTF-8 encoding, and supports various file formats. It has extensive shell completion support, automatic compression/decompression using Snappy, and supports environment variables and dotenv files. qsv has a comprehensive test suite and is dual-licensed under MIT or the UNLICENSE.

kestra
Kestra is an open-source event-driven orchestration platform that simplifies building scheduled and event-driven workflows. It offers Infrastructure as Code best practices for data, process, and microservice orchestration, allowing users to create reliable workflows using YAML configuration. Key features include everything as code with Git integration, event-driven and scheduled workflows, rich plugin ecosystem for data extraction and script running, intuitive UI with syntax highlighting, scalability for millions of workflows, version control friendly, and various features for structure and resilience. Kestra ensures declarative orchestration logic management even when workflows are modified via UI, API calls, or other methods.
cohort_structure
The Machine Learning (ML) Flipped Cohort is a 12-week structured program designed for beginners to gain foundational to intermediate ML knowledge. Participants consume pre-recorded content during the week and engage in weekly community discussions. The program covers topics such as Python, data science foundations, databases, math for ML, text processing, linear regression, non-linear modeling, deep learning basics, and more. Participants work on capstone projects and are assessed through Google Forms. Certification requires minimum attendance, assessment scores, and participation in the final project. The cohort provides a supportive learning environment with mentorship and community interaction.

brokk
Brokk is a code assistant tool named after the Norse god of the forge. It is designed to understand code semantically, enabling LLMs to work effectively on large codebases. Users can sign up at Brokk.ai, install jbang, and follow instructions to run Brokk. The tool uses Gradle with Scala support and requires JDK 21 or newer for building. Brokk aims to enhance code comprehension and productivity by providing semantic understanding of code.
jsonrepair
Jsonrepair is a Python library that provides functionalities to repair and validate JSON files. It helps users to fix common issues in JSON data such as missing commas, incorrect data types, and structural errors. With jsonrepair, users can easily clean up and standardize their JSON files, ensuring they are well-formed and error-free.

Curator
NeMo Curator is a Python library designed for fast and scalable data processing and curation for generative AI use cases. It accelerates data processing by leveraging GPUs with Dask and RAPIDS, providing customizable pipelines for text and image curation. The library offers pre-built pipelines for synthetic data generation, enabling users to train and customize generative AI models such as LLMs, VLMs, and WFMs.

axolotl
Axolotl is a lightweight and efficient tool for managing and analyzing large datasets. It provides a user-friendly interface for data manipulation, visualization, and statistical analysis. With Axolotl, users can easily import, clean, and explore data to gain valuable insights and make informed decisions. The tool supports various data formats and offers a wide range of functions for data processing and modeling. Whether you are a data scientist, researcher, or business analyst, Axolotl can help streamline your data workflows and enhance your data analysis capabilities.
arkflow
ArkFlow is a high-performance Rust stream processing engine that seamlessly integrates AI capabilities, providing powerful real-time data processing and intelligent analysis. It supports multiple input/output sources and processors, enabling easy loading and execution of machine learning models for streaming data and inference, anomaly detection, and complex event processing. The tool is built on Rust and Tokio async runtime, offering excellent performance and low latency. It features built-in SQL queries, Python script, JSON processing, Protobuf encoding/decoding, and batch processing capabilities. ArkFlow is extensible with a modular design, making it easy to extend with new components.
llms
LLMs is a universal LLM API transformation server designed to standardize requests and responses between different LLM providers such as Anthropic, Gemini, and Deepseek. It uses a modular transformer system to handle provider-specific API formats, supporting real-time streaming responses and converting data into standardized formats. The server transforms requests and responses to and from unified formats, enabling seamless communication between various LLM providers.
yams
YAMS (Yet Another Memory System) is a persistent memory system designed for Large Language Models (LLMs) and applications. It provides content-addressed storage with features such as deduplication, compression, full-text search, and vector search. The system is built with SHA-256 content-addressed store, block-level deduplication, full-text search using SQLite FTS5, semantic search with embeddings, WAL-backed durability, high-throughput I/O, and thread-safe operations. YAMS supports Linux x86_64/ARM64 and macOS x86_64/ARM64 platforms. It is recommended to build using Conan for managing dependencies and ensuring proper installation. Users can interact with YAMS through a command-line interface for tasks like initialization, adding content, searching, and retrieving data. Additionally, YAMS provides LLM-friendly patterns for caching web content, storing code diffs, and integrating with other systems through an API in C++. Troubleshooting tips include creating a default Conan profile and handling PDF support issues during the build process. The project is licensed under Apache-2.0.
gonzo
Gonzo is a powerful, real-time log analysis terminal UI tool inspired by k9s. It allows users to analyze log streams with beautiful charts, AI-powered insights, and advanced filtering directly from the terminal. The tool provides features like live streaming log processing, OTLP support, interactive dashboard with real-time charts, advanced filtering options including regex support, and AI-powered insights such as pattern detection, anomaly analysis, and root cause suggestions. Users can also configure AI models from providers like OpenAI, LM Studio, and Ollama for intelligent log analysis. Gonzo is built with Bubble Tea, Lipgloss, Cobra, Viper, and OpenTelemetry, following a clean architecture with separate modules for TUI, log analysis, frequency tracking, OTLP handling, and AI integration.

AngelSlim
AngelSlim is a comprehensive and efficient large model compression toolkit designed to be user-friendly. It integrates mainstream compression algorithms for easy one-click access, continuously innovates compression algorithms, and optimizes end-to-end performance in model compression and deployment. It supports various models for quantization and speculative sampling, with a focus on performance optimization and ease of use.

ROGRAG
ROGRAG is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for exploring and manipulating datasets, making it ideal for researchers, data scientists, and analysts. With ROGRAG, users can easily import, clean, analyze, and visualize data to gain valuable insights and make informed decisions. The tool supports a wide range of data formats and offers a variety of statistical and visualization tools to help users uncover patterns, trends, and relationships in their data. Whether you are working on exploratory data analysis, statistical modeling, or data visualization, ROGRAG is a versatile tool that can streamline your workflow and enhance your data analysis capabilities.
python-utcp
The Universal Tool Calling Protocol (UTCP) is a secure and scalable standard for defining and interacting with tools across various communication protocols. UTCP emphasizes scalability, extensibility, interoperability, and ease of use. It offers a modular core with a plugin-based architecture, making it extensible, testable, and easy to package. The repository contains the complete UTCP Python implementation with core components and protocol-specific plugins for HTTP, CLI, Model Context Protocol, file-based tools, and more.
arconia
Arconia is a powerful open-source tool for managing and visualizing data in a user-friendly way. It provides a seamless experience for data analysts and scientists to explore, clean, and analyze datasets efficiently. With its intuitive interface and robust features, Arconia simplifies the process of data manipulation and visualization, making it an essential tool for anyone working with data.
hashbrown
Hashbrown is a lightweight and efficient hashing library for Python, designed to provide easy-to-use cryptographic hashing functions for secure data storage and transmission. It supports a variety of hashing algorithms, including MD5, SHA-1, SHA-256, and SHA-512, allowing users to generate hash values for strings, files, and other data types. With Hashbrown, developers can quickly implement data integrity checks, password hashing, digital signatures, and other security features in their Python applications.

DashAI
DashAI is a powerful tool for building interactive web applications with Python. It allows users to create data visualization dashboards and deploy machine learning models with ease. The tool provides a simple and intuitive way to design and customize web apps without the need for extensive front-end development knowledge. With DashAI, users can easily showcase their data analysis results and predictive models in a user-friendly and interactive manner, making it ideal for data scientists, developers, and business professionals looking to share insights and predictions with stakeholders.
Disciplined-AI-Software-Development
Disciplined AI Software Development is a comprehensive repository that provides guidelines and best practices for developing AI software in a disciplined manner. It covers topics such as project organization, code structure, documentation, testing, and deployment strategies to ensure the reliability, scalability, and maintainability of AI applications. The repository aims to help developers and teams navigate the complexities of AI development by offering practical advice and examples to follow.
dbt-mcp
The dbt MCP Server is a Model Context Protocol server that provides tools to interact with dbt. It allows users to provide AI agents with context of their project in dbt Core, dbt Fusion, and dbt Platform. The server architecture enables agents to connect to various tools, and users can refer to the documentation for more details on its capabilities. Users can also contribute to the project by following the instructions in the CONTRIBUTING.md file.

robustmq
RobustMQ is a next-generation, high-performance, multi-protocol message queue built in Rust. It aims to create a unified messaging infrastructure tailored for modern cloud-native and AI systems. With features like high performance, distributed architecture, multi-protocol support, pluggable storage, cloud-native readiness, multi-tenancy, security features, observability, and user-friendliness, RobustMQ is designed to be production-ready and become a top-level Apache project in the message queue ecosystem by the second half of 2025.

context7
Context7 is a powerful tool for analyzing and visualizing data in various formats. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With advanced features such as data filtering, aggregation, and customization, Context7 is suitable for both beginners and experienced data analysts. The tool supports a wide range of data sources and formats, making it versatile for different use cases. Whether you are working on exploratory data analysis, data visualization, or data storytelling, Context7 can help you uncover valuable insights and communicate your findings effectively.
seatunnel
SeaTunnel is a high-performance, distributed data integration tool trusted by numerous companies for synchronizing vast amounts of data daily. It addresses common data integration challenges by seamlessly integrating with diverse data sources, supporting multimodal data integration, complex synchronization scenarios, resource efficiency, and quality monitoring. With over 100 connectors, SeaTunnel offers batch-stream integration, distributed snapshot algorithm, multi-engine support, JDBC multiplexing, and log parsing. It provides high throughput, low latency, real-time monitoring, and supports two job development methods. Users can configure jobs, select execution engines, and parallelize data using source connectors. SeaTunnel also supports multimodal data integration, Apache SeaTunnel tools, real-world use cases, and visual management of jobs through the SeaTunnel Web Project.
AI-Expert-Roadmap
AI Expert Roadmap is a comprehensive guide to becoming an Artificial Intelligence Expert in 2022. It provides detailed charts and paths for individuals interested in data science, machine learning, and AI. The roadmap covers fundamental concepts, data science, machine learning, deep learning, data engineering, and big data engineering. Created by AMAI GmbH, this resource aims to help individuals navigate the AI landscape and make informed decisions about their learning path. The interactive version with links is available at i.am.ai/roadmap. Stay updated by starring and watching the GitHub repo for new content.
vts
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
mcp-victoriametrics
The VictoriaMetrics MCP Server is an implementation of Model Context Protocol (MCP) server for VictoriaMetrics. It provides access to your VictoriaMetrics instance and seamless integration with VictoriaMetrics APIs and documentation. The server allows you to use almost all read-only APIs of VictoriaMetrics, enabling monitoring, observability, and debugging tasks related to your VictoriaMetrics instances. It also contains embedded up-to-date documentation and tools for exploring metrics, labels, alerts, and more. The server can be used for advanced automation and interaction capabilities for engineers and tools.
NeMo-Agent-Toolkit
NVIDIA NeMo Agent toolkit is a flexible, lightweight, and unifying library that allows you to easily connect existing enterprise agents to data sources and tools across any framework. It is framework agnostic, promotes reusability, enables rapid development, provides profiling capabilities, offers observability features, includes an evaluation system, features a user interface for interaction, and supports the Model Context Protocol (MCP). With NeMo Agent toolkit, users can move quickly, experiment freely, and ensure reliability across all agent-driven projects.
ai-platform-engineering
The AI Platform Engineering repository provides a collection of tools and resources for building and deploying AI models. It includes libraries for data preprocessing, model training, and model serving. The repository also contains example code and tutorials to help users get started with AI development. Whether you are a beginner or an experienced AI engineer, this repository offers valuable insights and best practices to streamline your AI projects.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
emqx
EMQX is a highly scalable and reliable MQTT platform designed for IoT data infrastructure. It supports various protocols like MQTT 5.0, 3.1.1, and 3.1, as well as MQTT-SN, CoAP, LwM2M, and MQTT over QUIC. EMQX allows connecting millions of IoT devices, processing messages in real time, and integrating with backend data systems. It is suitable for applications in AI, IoT, IIoT, connected vehicles, smart cities, and more. The tool offers features like massive scalability, powerful rule engine, flow designer, AI processing, robust security, observability, management, extensibility, and a unified experience with the Business Source License (BSL) 1.1.
MCP-PostgreSQL-Ops
MCP-PostgreSQL-Ops is a repository containing scripts and tools for managing and optimizing PostgreSQL databases. It provides a set of utilities to automate common database administration tasks, such as backup and restore, performance tuning, and monitoring. The scripts are designed to simplify the operational aspects of running PostgreSQL databases, making it easier for administrators to maintain and optimize their database instances. With MCP-PostgreSQL-Ops, users can streamline their database management processes and improve the overall performance and reliability of their PostgreSQL deployments.
flink-agents
Apache Flink Agents is an Agentic AI framework based on Apache Flink. It provides a platform for building and deploying AI agents using Flink's capabilities. The framework supports both Java and Python development, allowing users to leverage the power of Flink for AI applications. With a focus on agent-based AI systems, Flink Agents offers a flexible and scalable solution for developing intelligent agents that can interact with their environment and make decisions autonomously. The framework includes tools for building, training, and deploying AI agents, making it suitable for a wide range of AI applications.
clewdr
Clewdr is a collaborative platform for data analysis and visualization. It allows users to upload datasets, perform various data analysis tasks, and create interactive visualizations. The platform supports multiple users working on the same project simultaneously, enabling real-time collaboration and sharing of insights. Clewdr is designed to streamline the data analysis process and facilitate communication among team members. With its user-friendly interface and powerful features, Clewdr is suitable for data scientists, analysts, researchers, and anyone working with data to gain valuable insights and make informed decisions.
aiorwlock
Read write lock for asyncio. A RWLock maintains a pair of associated locks, one for read-only operations and one for writing. The read lock may be held simultaneously by multiple reader tasks, so long as there are no writers. The write lock is exclusive. Whether or not a read-write lock will improve performance over the use of a mutual exclusion lock depends on the frequency that the data is read compared to being modified. For example, a collection that is initially populated with data and thereafter infrequently modified, while being frequently searched is an ideal candidate for the use of a read-write lock. However, if updates become frequent then the data spends most of its time being exclusively locked and there is little, if any increase in concurrency. Note: a task that acquires the lock should be used for releasing it. Locking from one task and releasing from another one generates RuntimeError. Implementation is almost direct port from a patch.
agents-towards-production
Agents Towards Production is an open-source playbook for building production-ready GenAI agents that scale from prototype to enterprise. Tutorials cover stateful workflows, vector memory, real-time web search APIs, Docker deployment, FastAPI endpoints, security guardrails, GPU scaling, browser automation, fine-tuning, multi-agent coordination, observability, evaluation, and UI development.
mcp-apache-spark-history-server
The MCP Server for Apache Spark History Server is a tool that connects AI agents to Apache Spark History Server for intelligent job analysis and performance monitoring. It enables AI agents to analyze job performance, identify bottlenecks, and provide insights from Spark History Server data. The server bridges AI agents with existing Apache Spark infrastructure, allowing users to query job details, analyze performance metrics, compare multiple jobs, investigate failures, and generate insights from historical execution data.

volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.
aiocron
aiocron is a Python library that provides crontab functionality for asyncio. It allows users to schedule functions to run at specific times using a decorator or as an object. Users can also await a crontab, use it as a sleep coroutine, and customize functions without decorator magic. aiocron has switched from croniter to cronsim for cron expression parsing since Dec 31, 2024.
bigtop-manager
Apache Bigtop Manager is a modern, AI-driven web application designed to simplify the complexity of bigdata cluster management. It provides an easy deployment solution not only for Apache Bigtop components, but also other community version bigdata components. The platform aims to streamline the management of bigdata clusters by leveraging AI technology and user-friendly interfaces.
rill
Rill delivers rapid, self-service dashboards for data engineers and analysts directly on raw data lakes, ensuring reliable, fast-loading dashboards with accurate, real-time metrics. It comes with an embedded in-memory database for lightning-fast performance and supports bringing your own OLAP engine. Rill implements BI-as-code through SQL-based definitions, YAML configuration, Git integration, and CLI tools. Its metrics layer provides a unified way to define, compute, and serve business metrics, while AI agents can access fresh metrics instantly for precise decision-making and intelligent automation.
flyte-sdk
Flyte 2 SDK is a pure Python tool for type-safe, distributed orchestration of agents, ML pipelines, and more. It allows users to write data pipelines, ML training jobs, and distributed compute in Python without any DSL constraints. With features like async-first parallelism and fine-grained observability, Flyte 2 offers a seamless workflow experience. Users can leverage core concepts like TaskEnvironments for container configuration, pure Python workflows for flexibility, and async parallelism for distributed execution. Advanced features include sub-task observability with tracing and remote task execution. The tool also provides native Jupyter integration for running and monitoring workflows directly from notebooks. Configuration and deployment are made easy with configuration files and commands for deploying and running workflows. Flyte 2 is licensed under the Apache 2.0 License.

proton
Proton is the fastest SQL pipeline engine in a single C++ binary, designed for stream processing, analytics, observability, and AI. It provides a simple, fast, and efficient alternative to ksqlDB and Apache Flink, powered by ClickHouse engine. Proton offers native source/sink support for various databases, streaming ingestion, multi-stream JOINs, incremental materialized views, alerting, tasks, and UDF in Python/JS. It is lightweight, with no JVM or dependencies, and offers high performance through SIMD optimization. Proton is ideal for real-time analytics ETL/pipeline, telemetry pipeline and alerting, real-time feature pipeline for AI/ML, and more.
axonhub
AxonHub is an all-in-one AI development platform that serves as an AI gateway allowing users to switch between model providers without changing any code. It provides features like vendor lock-in prevention, integration simplification, observability enhancement, and cost control. Users can access any model using any SDK with zero code changes. The platform offers full request tracing, enterprise RBAC, smart load balancing, and real-time cost tracking. AxonHub supports multiple databases, provides a unified API gateway, and offers flexible model management and API key creation for authentication. It also integrates with various AI coding tools and SDKs for seamless usage.
llm-metadata
LLM Metadata is a lightweight static API designed for discovering and integrating LLM metadata. It provides a high-throughput friendly, static-by-default interface that serves static JSON via GitHub Pages. The sources for the metadata include models.dev/api.json and contributions from the basellm community. The tool allows for easy rebuilding on change and offers various scripts for compiling TypeScript, building the API, and managing the project. It also supports internationalization for both documentation and API, enabling users to add new languages and localize capability labels and descriptions. The tool follows an auto-update policy based on a configuration file and allows for directory-based overrides for providers and models, facilitating customization and localization of metadata.
mcp-devtools
MCP DevTools is a high-performance server written in Go that replaces multiple Node.js and Python-based servers. It provides access to essential developer tools through a unified, modular interface. The server is efficient, with minimal memory footprint and fast response times. It offers a comprehensive tool suite for agentic coding, including 20+ essential developer agent tools. The tool registry allows for easy addition of new tools. The server supports multiple transport modes, including STDIO, HTTP, and SSE. It includes a security framework for multi-layered protection and a plugin system for adding new tools.
MemMachine
MemMachine is an open-source long-term memory layer designed for AI agents and LLM-powered applications. It enables AI to learn, store, and recall information from past sessions, transforming stateless chatbots into personalized, context-aware assistants. With capabilities like episodic memory, profile memory, working memory, and agent memory persistence, MemMachine offers a developer-friendly API, flexible storage options, and seamless integration with various AI frameworks. It is suitable for developers, researchers, and teams needing persistent, cross-session memory for their LLM applications.
json-io
json-io is a powerful and lightweight Java library that simplifies JSON5, JSON, and TOON serialization and deserialization while handling complex object graphs with ease. It preserves object references, handles polymorphic types, and maintains cyclic relationships in data structures. It offers full JSON5 support, TOON read/write capabilities, and is compatible with JDK 1.8 through JDK 24. The library is built with a focus on correctness over speed, providing extensive configuration options and two modes for data representation. json-io is designed for developers who require advanced serialization features and support for various Java types without external dependencies.

matrixone
MatrixOne is the industry's first database to bring Git-style version control to data, combined with MySQL compatibility, AI-native capabilities, and cloud-native architecture. It is a HTAP (Hybrid Transactional/Analytical Processing) database with a hyper-converged HSTAP engine that seamlessly handles transactional, analytical, full-text search, and vector search workloads in a single unified system—no data movement, no ETL, no compromises. Manage your database like code with features like instant snapshots, time travel, branch & merge, instant rollback, and complete audit trail. Built for the AI era, MatrixOne is MySQL-compatible, AI-native, and cloud-native, offering storage-compute separation, elastic scaling, and Kubernetes-native deployment. It serves as one database for everything, replacing multiple databases and ETL jobs with native OLTP, OLAP, full-text search, and vector search capabilities.
everything-claude-code
The 'Everything Claude Code' repository is a comprehensive collection of production-ready agents, skills, hooks, commands, rules, and MCP configurations developed over 10+ months. It includes guides for setup, foundations, and philosophy, as well as detailed explanations of various topics such as token optimization, memory persistence, continuous learning, verification loops, parallelization, and subagent orchestration. The repository also provides updates on bug fixes, multi-language rules, installation wizard, PM2 support, OpenCode plugin integration, unified commands and skills, and cross-platform support. It offers a quick start guide for installation, ecosystem tools like Skill Creator and Continuous Learning v2, requirements for CLI version compatibility, key concepts like agents, skills, hooks, and rules, running tests, contributing guidelines, OpenCode support, background information, important notes on context window management and customization, star history chart, and relevant links.

ai-dev-kit
The AI Dev Kit is a comprehensive toolkit designed to enhance AI-driven development on Databricks. It provides trusted sources for AI coding assistants like Claude Code and Cursor to build faster and smarter on Databricks. The kit includes features such as Spark Declarative Pipelines, Databricks Jobs, AI/BI Dashboards, Unity Catalog, Genie Spaces, Knowledge Assistants, MLflow Experiments, Model Serving, Databricks Apps, and more. Users can choose from different adventures like installing the kit, using the visual builder app, teaching AI assistants Databricks patterns, executing Databricks actions, or building custom integrations with the core library. The kit also includes components like databricks-tools-core, databricks-mcp-server, databricks-skills, databricks-builder-app, and ai-dev-project.
materialize
Materialize is a real-time data integration platform that creates and continually updates consistent views of transactional data from across your organization. Its SQL interface democratizes the ability to serve and access live data. Materialize can be deployed anywhere your infrastructure runs. Use Materialize to deliver fresh context for AI/RAG pipelines, power operational dashboards, and create more dynamic customer experiences without building time-consuming custom data pipelines. Materialize focuses on providing correct and consistent answers with minimal latency, and does not ask you to accept either approximate answers or eventual consistency. Materialize answers a query with the correct result on a specific version of your data. Materialize recasts SQL queries as dataflows, which can react efficiently to changes in your data as they happen. Materialize supports a large fraction of PostgreSQL features and is actively expanding support for more built-in PostgreSQL functions. Materialize can read data directly from PostgreSQL or MySQL replication stream, from Kafka, or from SaaS applications via webhooks. Once data is in, define views and perform reads via the PostgreSQL protocol. Materialize supports a comprehensive variety of SQL features, all using the PostgreSQL dialect and protocol. Materialize can incrementally maintain views in the presence of arbitrary inserts, updates, and deletes. Materialize supports recursion that enables incrementally updating tree and graph structures. Materialize is primarily written in Rust.
datachain
DataChain is a Python-based AI-data warehouse for transforming and analyzing unstructured data like images, audio, videos, text, and PDFs. It integrates with external storage to process data efficiently without duplication and manages metadata for easy querying. Use cases include ETL, analytics, versioning, and incremental processing. Key features include multimodal dataset versioning, Python-friendly operations, data enrichment, and processing. The tool allows for generating metadata using AI models, filtering, joining, and grouping datasets, and performing high-performance vectorized operations.

mini-sglang
Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
logfire
Pydantic Logfire is an observability platform that provides simple and powerful dashboard, Python-centric insights, SQL querying, OpenTelemetry integration, and Pydantic validation analytics. It offers unparalleled visibility into Python applications' behavior and allows querying data using standard SQL. Logfire is an opinionated wrapper around OpenTelemetry, supporting traces, metrics, and logs. The Python SDK for logfire is open source, while the server application for recording and displaying data is closed source.
pup
Pup is a Go-based command-line wrapper designed for easy interaction with Datadog APIs. It provides a fast, cross-platform binary with support for OAuth2 authentication and traditional API key authentication. The tool offers simple commands for common Datadog operations, structured JSON output for parsing and automation, and dynamic client registration with unique OAuth credentials per installation. Pup currently implements 38 out of 85+ available Datadog APIs, covering core observability, monitoring & alerting, security & compliance, infrastructure & cloud, incident & operations, CI/CD & development, organization & access, and platform & configuration domains. Users can easily install Pup via Homebrew, Go Install, or manual download, and authenticate using OAuth2 or API key methods. The tool supports various commands for tasks such as testing connection, managing monitors, querying metrics, handling dashboards, working with SLOs, and handling incidents.
sdg_hub
sdg_hub is a modular Python framework designed for building synthetic data generation pipelines using composable blocks and flows. Users can mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows. The toolkit offers features such as modular composability, async performance, built-in validation, auto-discovery, rich monitoring, dataset schema discovery, and easy extensibility. sdg_hub provides detailed documentation and supports high-throughput processing with error handling. It simplifies the process of transforming datasets by allowing users to chain blocks together in YAML-configured flows, enabling the creation of complex data generation pipelines.
superglue
superglue is an AI-powered tool builder that abstracts away authentication, documentation handling, and data mapping between systems. It self-heals tools by auto-repairing failures due to API changes. Users can build lightweight data syncing tools, migrate SQL procedures to REST API calls, and create enterprise GPT tools. Interfaces include a web application, superglue SDK for CRUD functionality, and MCP Server for discoverability and execution of pre-built tools. Detailed documentation is available at docs.superglue.cloud.
torch-rechub
Torch-RecHub is a lightweight, efficient, and user-friendly PyTorch recommendation system framework. It provides easy-to-use solutions for industrial-level recommendation systems, with features such as generative recommendation models, modular design for adding new models and datasets, PyTorch-based implementation for GPU acceleration, a rich library of 30+ classic and cutting-edge recommendation algorithms, standardized data loading, training, and evaluation processes, easy configuration through files or command-line parameters, reproducibility of experimental results, ONNX model export for production deployment, cross-engine data processing with PySpark support, and experiment visualization and tracking with integrated tools like WandB, SwanLab, and TensorBoardX.
dreamfactory
DreamFactory is a self-hosted platform that provides governed API access to any data source for enterprise apps and local LLMs. It is a secure enterprise data access platform built on top of the Laravel framework, offering role-based access control, identity passthrough, and customization of API behavior using PHP, Python, and NodeJS scripting languages. DreamFactory allows users to generate powerful APIs for SQL and NoSQL databases, files, email, and push notifications in seconds, while ensuring security with features like user management, SSO authentication, OAuth, and Active Directory integration.
57 - OpenAI Gpts
Data Dynamo
A friendly data science coach offering practical, useful, and accurate advice.

NoSQL Code Helper
Assists with NoSQL programming by providing code examples, debugging tips, and best practices.

DataKitchen DataOps and Data Observability GPT
A specialist in DataOps and Data Observability, aiding in data management and monitoring.

DataQualityGuardian
A GPT-powered assistant specializing in data validation and quality checks for various datasets.

Supabase Sensei
Supabase expert also supports query generation and Flutter code generation
Nimbus Navigator
Cloud Engineer Expert, guiding in cloud tech, projects, career, and industry trends.

KQL Query Helper
The KQL Query Helper GPT is tailored specifically for assisting users with Kusto Query Language (KQL) queries. It leverages extensive knowledge from Azure Data Explorer documentation to aid users in understanding, reviewing, and creating new KQL queries based on their prompts.

Connector Data Expert
Big data analyst for connectors, offering insights and technical guidance.

Kafka Expert
I will help you to integrate the popular distributed event streaming platform Apache Kafka into your own cloud solutions.
Data Engineer
A Data Engineer assistant offering advice on data pipelines and data-related tasks.
Squeaky Data Cleaner
Clean and structure your raw data with automatic file output for your Custom GPT knowledge.
City of Toronto Data Assistant
Data specialist for Toronto Government Data Platform insights
D.A.A. | Data Action Assistant
Advanced assistant for data publication and subscription guidance, with enhanced contextual understanding and technical integration.

Data Governance Advisor
Ensures data accuracy, consistency, and security across organization.

Data Analysis Prompt Engineer
Specializes in creating, refining, and testing data analysis prompts based on user queries.
Tech Guru
Meet Tech Guru, your go-to AI for data engineering, coding expertise, and graph databases. Combining humor, reliability, and approachability to simplify tech with a personal touch.

Data Engineer Consultant
Guides in data engineering tasks with a focus on practical solutions.
AI Implementation Guide for Sensitive/Private Data
Guide on AI implementation for secure data, with a focus on best practices and tools.
Power Query Assistant
Expert in Power Query and DAX for Power BI, offering in-depth guidance and insights

Table to JSON
我們經常在看 REST API 參考文件,文件中呈現 Request/Response 參數通常都是用表格的形式,開發人員都要手動轉換成 JSON 結構,有點小麻煩,但透過這個 GPT 只要上傳截圖就可以自動產生 JSON 範例與 JSON Schema 結構。

Data Analytics Specialist
Leading Big Data Analytics tool, blending advanced technology with OpenAI's expertise.
Data Strategy Sage
Market-leading datafication strategist, excelling in analysis and problem-solving, powered by OpenAI.

GCP-BigQueryGPT
BigQueryGPT aids in mastering BigQuery SQL with concise, practical examples. Tailored for all skill levels, it simplifies complex queries, offering clear explanations and optimized solutions for efficient learning and query troubleshooting.




Snowflake Copilot
Your personal Snowflake assistant and copilot with a focus on efficient, secure, and scalable data warehousing. Trained with the latest knowledge and docs.