
opendataeditor
No-code application to explore and publish all kinds of data: datasets, tables, charts, maps, stories, and more. Forever free and open source project powered by open standards and generative AI.
Stars: 148
The Open Data Editor (ODE) is a no-code application to explore, validate and publish data in a simple way. It is an open source project powered by the Frictionless Framework. The ODE is currently available for download and testing in beta.
README:

The Open Data Editor (ODE) is a no-code application to explore, validate and publish data in a simple way. Forever free and open source project powered by the Frictionless Framework.
📩 Send us feedback/Report a problem (email) 🪲 Create an issue on GitHub 🤔 Suggest a new feature
🔵 Open Data Editor Concept Note
🔵 Open Data Editor User Guide and Project Documentation
🔵 For all contributions: Code of conduct
📍Note: the ODE is currently available for download and testing in beta. We are working on a stable version. Updates will be announced throughout the year.
Go to RELEASES
- For Windows:Download the most recent EXE file.
- For MacOS:Download the most recent DMG file.
- For Linux:Download the most recent AppImage or DEB file.
Open Data Editor (beta) for early adopters has been released on Oct 2, 2023
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for opendataeditor
Similar Open Source Tools
opendataeditor
The Open Data Editor (ODE) is a no-code application to explore, validate and publish data in a simple way. It is an open source project powered by the Frictionless Framework. The ODE is currently available for download and testing in beta.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
OpenAnalyst
OpenAnalyst is an open-source VS Code AI agent specialized in data analytics and general coding tasks. It merges features from KiloCode, Roo Code, and Cline, offering code generation from natural language, data analytics mode, self-checking, terminal command running, browser automation, latest AI models, and API keys option. It supports multi-mode operation for roles like Data Analyst, Code, Ask, and Debug. OpenAnalyst is a fork of KiloCode, combining the best features from Cline, Roo Code, and KiloCode, with enhancements like MCP Server Marketplace, automated refactoring, and support for latest AI models.
app
WebDB is a comprehensive and free database Integrated Development Environment (IDE) designed to maximize efficiency in database development and management. It simplifies and enhances database operations with features like DBMS discovery, query editor, time machine, NoSQL structure inferring, modern ERD visualization, and intelligent data generator. Developed with robust web technologies, WebDB is suitable for both novice and experienced database professionals.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.
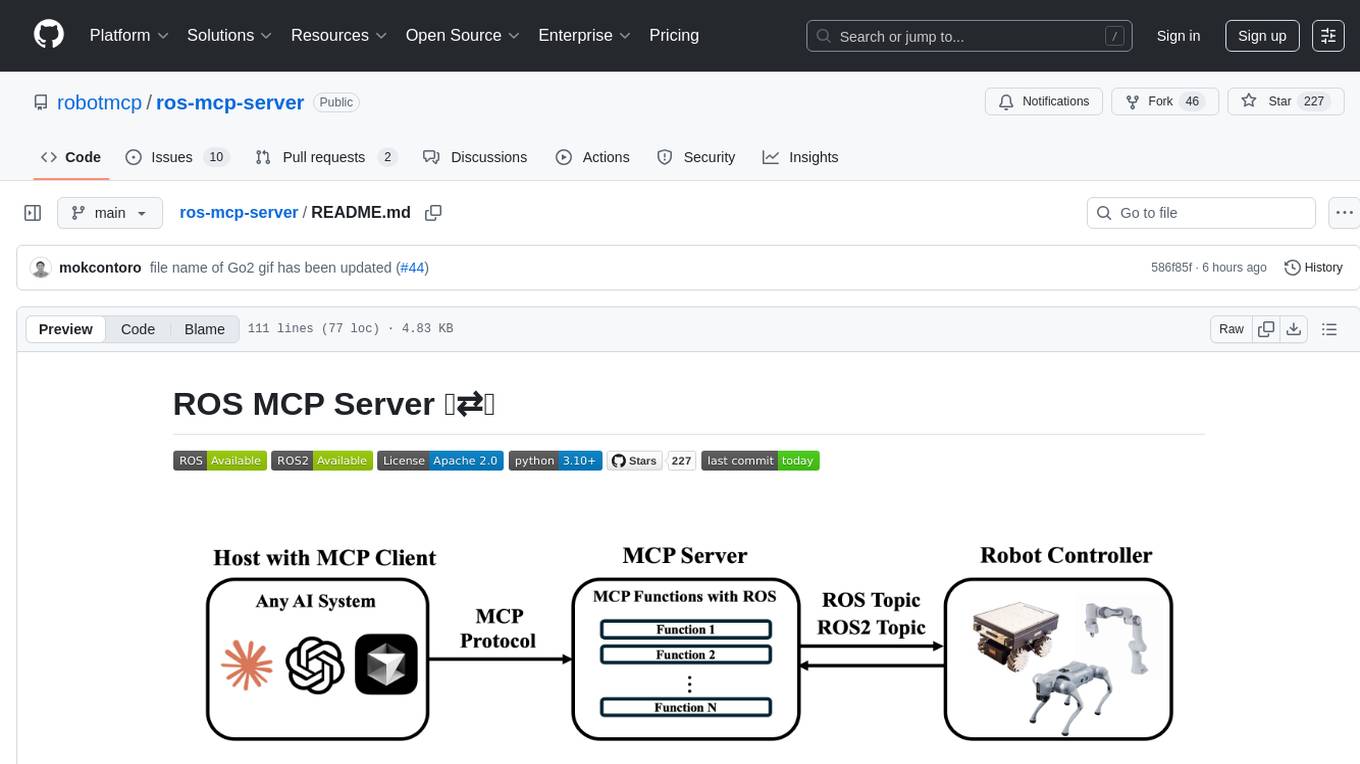
ros-mcp-server
The ros-mcp-server repository contains a ROS (Robot Operating System) package that provides a server for Multi-Contact Planning (MCP) in robotics. The server facilitates the planning of multiple contacts between a robot and its environment, enabling complex manipulation tasks. It includes functionalities for collision checking, motion planning, and contact stability analysis. This tool is designed to enhance the capabilities of robotic systems by enabling them to perform tasks that involve multiple points of contact with the environment. The repository includes documentation and examples to help users integrate the MCP server into their robotic applications.
replexica
Replexica is an i18n toolkit for React, to ship multi-language apps fast. It doesn't require extracting text into JSON files, and uses AI-powered API for content processing. It comes in two parts: 1. Replexica Compiler - an open-source compiler plugin for React; 2. Replexica API - an i18n API in the cloud that performs translations using LLMs. (Usage based, has a free tier.) Replexica supports several i18n formats: 1. JSON-free Replexica compiler format; 2. .md files for Markdown content; 3. Legacy JSON and YAML-based formats.

Mira
Mira is an agentic AI library designed for automating company research by gathering information from various sources like company websites, LinkedIn profiles, and Google Search. It utilizes a multi-agent architecture to collect and merge data points into a structured profile with confidence scores and clear source attribution. The core library is framework-agnostic and can be integrated into applications, pipelines, or custom workflows. Mira offers features such as real-time progress events, confidence scoring, company criteria matching, and built-in services for data gathering. The tool is suitable for users looking to streamline company research processes and enhance data collection efficiency.
Open-WebUI-Functions
Open-WebUI-Functions is a collection of Python-based functions that extend Open WebUI with custom pipelines, filters, and integrations. Users can interact with AI models, process data efficiently, and customize the Open WebUI experience. It includes features like custom pipelines, data processing filters, Azure AI support, N8N workflow integration, flexible configuration, secure API key management, and support for both streaming and non-streaming processing. The functions require an active Open WebUI instance, may need external AI services like Azure AI, and admin access for installation. Security features include automatic encryption of sensitive information like API keys. Pipelines include Azure AI Foundry, N8N, Infomaniak, and Google Gemini. Filters like Time Token Tracker measure response time and token usage. Integrations with Azure AI, N8N, Infomaniak, and Google are supported. Contributions are welcome, and the project is licensed under Apache License 2.0.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
kelivo
Kelivo is a Flutter LLM Chat Client with modern design, dark mode, multi-language support, multi-provider support, custom assistants, multimodal input, markdown rendering, voice functionality, MCP support, web search integration, prompt variables, QR code sharing, data backup, and custom requests. It is built with Flutter and Dart, utilizes Provider for state management, Hive for local data storage, and supports dynamic theming and Markdown rendering. Kelivo is a versatile tool for creating and managing personalized AI assistants, supporting various input formats, and integrating with multiple search engines and AI providers.
chatnio
Chat Nio is a next-generation AIGC one-stop business solution that combines the advantages of frontend-oriented lightweight deployment projects with powerful API distribution systems. It offers rich model support, beautiful UI design, complete Markdown support, multi-theme support, internationalization support, text-to-image support, powerful conversation sync, model market & preset system, rich file parsing, full model internet search, Progressive Web App (PWA) support, comprehensive backend management, multiple billing methods, innovative model caching, and additional features. The project aims to address limitations in conversation synchronization, billing, file parsing, conversation URL sharing, channel management, and API call support found in existing AIGC commercial sites, while also providing a user-friendly interface design and C-end features.
accelerated-intelligent-document-processing-on-aws
Accelerated Intelligent Document Processing on AWS is a scalable, serverless solution for automated document processing and information extraction using AWS services. It combines OCR capabilities with generative AI to convert unstructured documents into structured data at scale. The solution features a serverless architecture built on AWS technologies, modular processing patterns, advanced classification support, few-shot example support, custom business logic integration, high throughput processing, built-in resilience, cost optimization, comprehensive monitoring, web user interface, human-in-the-loop integration, AI-powered evaluation, extraction confidence assessment, and document knowledge base query. The architecture uses nested CloudFormation stacks to support multiple document processing patterns while maintaining common infrastructure for queueing, tracking, and monitoring.
awesome-ai-coding
Awesome-AI-Coding is a curated list of AI coding topics, projects, datasets, LLM models, embedding models, papers, blogs, products, startups, and peer awesome lists related to artificial intelligence in coding. It includes tools for code completion, code generation, code documentation, and code search, as well as AI models and techniques for improving developer productivity. The repository also features information on various AI-powered developer tools, copilots, and related resources in the AI coding domain.
For similar tasks
opendataeditor
The Open Data Editor (ODE) is a no-code application to explore, validate and publish data in a simple way. It is an open source project powered by the Frictionless Framework. The ODE is currently available for download and testing in beta.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
Streamline-Analyst
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.
2021-13th-ironman
This repository is a part of the 13th iT Help Ironman competition, focusing on exploring explainable artificial intelligence (XAI) in machine learning and deep learning. The content covers the basics of XAI, its applications, cases, challenges, and future directions. It also includes practical machine learning algorithms, model deployment, and integration concepts. The author aims to provide detailed resources on AI and share knowledge with the audience through this competition.
crazyai-ml
The 'crazyai-ml' repository is a collection of resources related to machine learning, specifically focusing on explaining artificial intelligence models. It includes articles, code snippets, and tutorials covering various machine learning algorithms, data analysis, model training, and deployment. The content aims to provide a comprehensive guide for beginners in the field of AI, offering practical implementations and insights into popular machine learning packages and model tuning techniques. The repository also addresses the integration of AI models and frontend-backend concepts, making it a valuable resource for individuals interested in AI applications.

ProX
ProX is a lm-based data refinement framework that automates the process of cleaning and improving data used in pre-training large language models. It offers better performance, domain flexibility, efficiency, and cost-effectiveness compared to traditional methods. The framework has been shown to improve model performance by over 2% and boost accuracy by up to 20% in tasks like math. ProX is designed to refine data at scale without the need for manual adjustments, making it a valuable tool for data preprocessing in natural language processing tasks.
LLM4DB
LLM4DB is a repository focused on the intersection of Large Language Models (LLMs) and Database technologies. It covers various aspects such as data processing, data analysis, database optimization, and data management for LLMs. The repository includes research papers, tools, and techniques related to leveraging LLMs for tasks like data cleaning, entity matching, schema matching, data discovery, NL2SQL, data exploration, data visualization, knob tuning, query optimization, and database diagnosis.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.