
sematic
An open-source ML pipeline development platform
Stars: 979

Sematic is an open-source ML development platform that allows ML Engineers and Data Scientists to write complex end-to-end pipelines with Python. It can be executed locally, on a cloud VM, or on a Kubernetes cluster. Sematic enables chaining data processing jobs with model training into reproducible pipelines that can be monitored and visualized in a web dashboard. It offers features like easy onboarding, local-to-cloud parity, end-to-end traceability, access to heterogeneous compute resources, and reproducibility.
README:
![]()

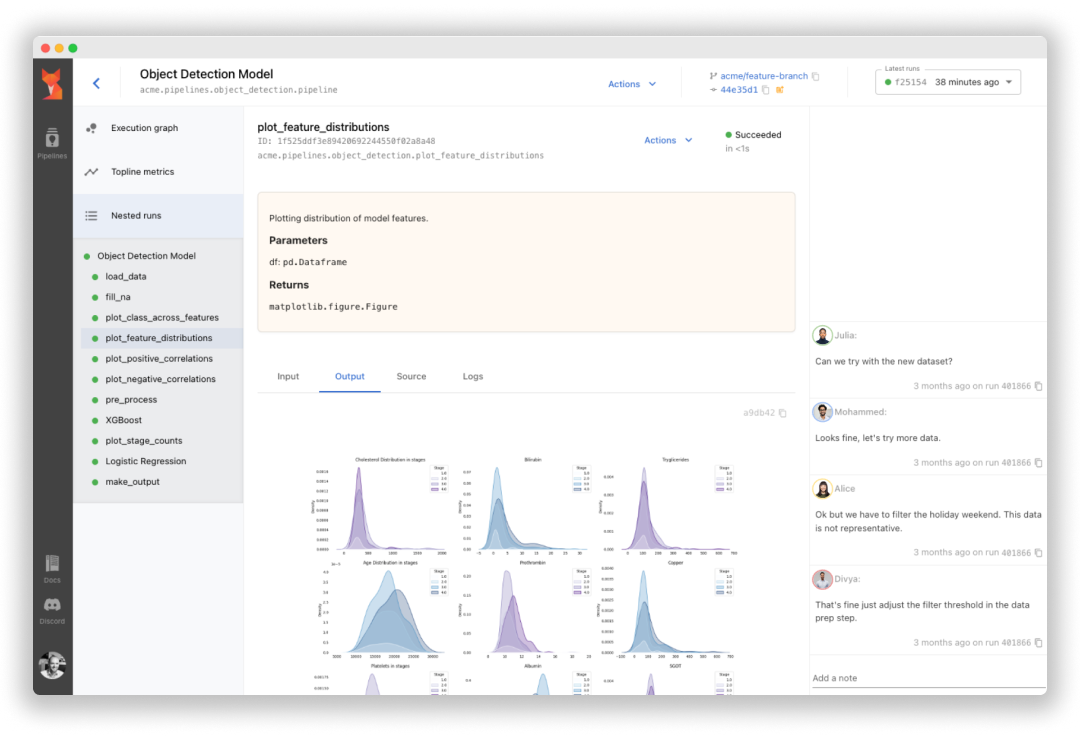
Sematic is an open-source ML development platform. It lets ML Engineers and Data Scientists write arbitrarily complex end-to-end pipelines with simple Python and execute them on their local machine, in a cloud VM, or on a Kubernetes cluster to leverage cloud resources.
Sematic is based on learnings gathered at top self-driving car companies. It enables chaining data processing jobs (e.g. Apache Spark) with model training (e.g. PyTorch, Tensorflow), or any other arbitrary Python business logic into type-safe, traceable, reproducible end-to-end pipelines that can be monitored and visualized in a modern web dashboard.
Read our documentation and join our Discord channel.
- Easy onboarding – no deployment or infrastructure needed to get started, simply install Sematic locally and start exploring.
- Local-to-cloud parity – run the same code on your local laptop and on your Kubernetes cluster.
- End-to-end traceability – all pipeline artifacts are persisted, tracked, and visualizable in a web dashboard.
- Access heterogeneous compute – customize required resources for each pipeline step to optimize your performance and cloud footprint (CPUs, memory, GPUs, Spark cluster, etc.)
- Reproducibility – rerun your pipelines from the UI with guaranteed reproducibility of results
To get started locally, simply install Sematic in your Python environment:
$ pip install sematicStart the local web dashboard:
$ sematic startRun an example pipeline:
$ sematic run examples/mnist/pytorchCreate a new boilerplate project:
$ sematic new my_new_projectOr from an existing example:
$ sematic new my_new_project --from examples/mnist/pytorchThen run it with:
$ python3 -m my_new_projectTo deploy Sematic to Kubernetes and leverage cloud resources, see our documentation.
- Lightweight Python SDK – define arbitrarily complex end-to-end pipelines
- Pipeline nesting – arbitrarily nest pipelines into larger pipelines
- Dynamic graphs – Python-defined graphs allow for iterations, conditional branching, etc.
- Lineage tracking – all inputs and outputs of all steps are persisted and tracked
- Runtime type-checking – fail early with run-time type checking
- Web dashboard – Monitor, track, and visualize pipelines in a modern web UI
- Artifact visualization – visualize all inputs and outputs of all steps in the web dashboard
- Local execution – run pipelines on your local machine without any deployment necessary
- Cloud orchestration – run pipelines on Kubernetes to access GPUs and other cloud resources
- Heterogeneous compute resources – run different steps on different machines (e.g. CPUs, memory, GPU, Spark, etc.)
- Helm chart deployment – install Sematic on your Kubernetes cluster
- Pipeline reruns – rerun pipelines from the UI from an arbitrary point in the graph
- Step caching – cache expensive pipeline steps for faster iteration
- Step retry – recover from transient failures with step retries
- Metadata and collaboration – Tags, source code visualization, docstrings, notes, etc.
- Numerous integrations – See below
- Apache Spark – on-demand in-cluster Spark cluster
- Ray – on-demand Ray in-cluster Ray resources
- Snowflake – easily query your data warehouse (other warehouses supported too)
- Plotly, Matplotlib – visualize plot artifacts in the web dashboard
- Pandas – visualize dataframe artifacts in the dashboard
- Grafana – embed Grafana panels in the web dashboard
- Bazel – integrate with your Bazel build system
- Helm chart – deploy to Kubernetes with our Helm chart
- Git – track git information in the web dashboard
Learn more about Sematic and get in touch with the following resources:
To contribute to Sematic, check out open issues tagged "good first issue", and get in touch with us on Discord. You can find instructions on how to get your development environment set up in our developer docs. If you'd like to add an example, you may also find this guide helpful.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sematic
Similar Open Source Tools
sematic
Sematic is an open-source ML development platform that allows ML Engineers and Data Scientists to write complex end-to-end pipelines with Python. It can be executed locally, on a cloud VM, or on a Kubernetes cluster. Sematic enables chaining data processing jobs with model training into reproducible pipelines that can be monitored and visualized in a web dashboard. It offers features like easy onboarding, local-to-cloud parity, end-to-end traceability, access to heterogeneous compute resources, and reproducibility.
rocketnotes
Rocketnotes is a web-based Markdown note taking app with LLM-powered text completion, chat and semantic search. It utilizes a 100% serverless RAG pipeline build with langchain, sentence-transformers, faiss and OpenAI or Anthropic API.
refact
This repository contains Refact WebUI for fine-tuning and self-hosting of code models, which can be used inside Refact plugins for code completion and chat. Users can fine-tune open-source code models, self-host them, download and upload Lloras, use models for code completion and chat inside Refact plugins, shard models, host multiple small models on one GPU, and connect GPT-models for chat using OpenAI and Anthropic keys. The repository provides a Docker container for running the self-hosted server and supports various models for completion, chat, and fine-tuning. Refact is free for individuals and small teams under the BSD-3-Clause license, with custom installation options available for GPU support. The community and support include contributing guidelines, GitHub issues for bugs, a community forum, Discord for chatting, and Twitter for product news and updates.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!

kestra
Kestra is an open-source event-driven orchestration platform that simplifies building scheduled and event-driven workflows. It offers Infrastructure as Code best practices for data, process, and microservice orchestration, allowing users to create reliable workflows using YAML configuration. Key features include everything as code with Git integration, event-driven and scheduled workflows, rich plugin ecosystem for data extraction and script running, intuitive UI with syntax highlighting, scalability for millions of workflows, version control friendly, and various features for structure and resilience. Kestra ensures declarative orchestration logic management even when workflows are modified via UI, API calls, or other methods.
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.
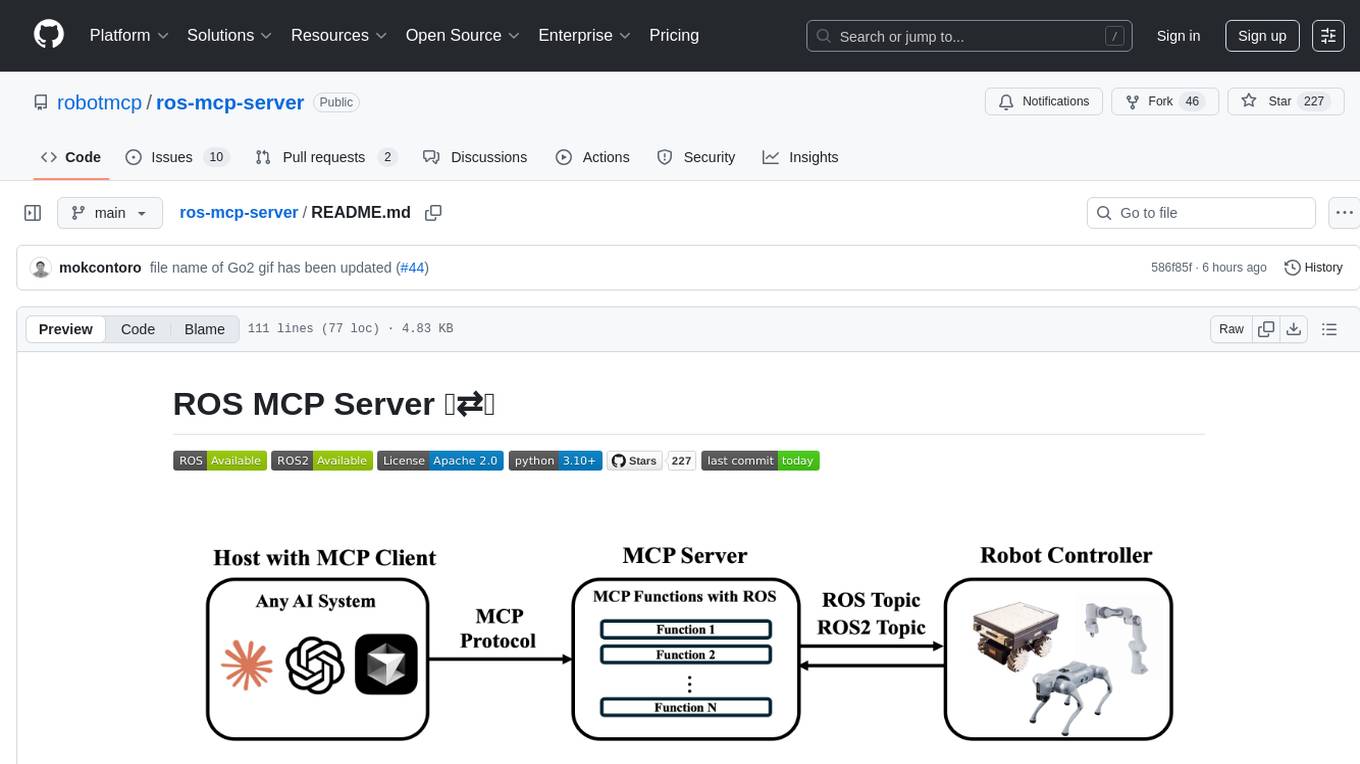
ros-mcp-server
The ros-mcp-server repository contains a ROS (Robot Operating System) package that provides a server for Multi-Contact Planning (MCP) in robotics. The server facilitates the planning of multiple contacts between a robot and its environment, enabling complex manipulation tasks. It includes functionalities for collision checking, motion planning, and contact stability analysis. This tool is designed to enhance the capabilities of robotic systems by enabling them to perform tasks that involve multiple points of contact with the environment. The repository includes documentation and examples to help users integrate the MCP server into their robotic applications.

ai-flow
AI Flow is an open-source, user-friendly UI application that empowers you to seamlessly connect multiple AI models together, specifically leveraging the capabilities of multiples AI APIs such as OpenAI, StabilityAI and Replicate. In a nutshell, AI Flow provides a visual platform for crafting and managing AI-driven workflows, thereby facilitating diverse and dynamic AI interactions.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.

openops
OpenOps is a No-Code FinOps automation platform designed to help organizations reduce cloud costs and streamline financial operations. It offers customizable workflows for automating key FinOps processes, comes with its own Excel-like database and visualization system, and enables collaboration between different teams. OpenOps integrates seamlessly with major cloud providers, third-party FinOps tools, communication platforms, and project management tools, providing a comprehensive solution for efficient cost-saving measures implementation.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
replexica
Replexica is an i18n toolkit for React, to ship multi-language apps fast. It doesn't require extracting text into JSON files, and uses AI-powered API for content processing. It comes in two parts: 1. Replexica Compiler - an open-source compiler plugin for React; 2. Replexica API - an i18n API in the cloud that performs translations using LLMs. (Usage based, has a free tier.) Replexica supports several i18n formats: 1. JSON-free Replexica compiler format; 2. .md files for Markdown content; 3. Legacy JSON and YAML-based formats.

logto
Logto is a modern, open-source authentication infrastructure designed for SaaS and AI applications. It simplifies OIDC and OAuth 2.1 implementation, enabling secure, production-ready authentication with features like multi-tenancy, enterprise SSO, and RBAC. Logto offers pre-built sign-in flows, customizable UIs, and SDKs for various frameworks, supporting protocols like OIDC, OAuth 2.1, and SAML. It is suitable for teams scaling SaaS, AI, and agent-based platforms without authentication complexities.
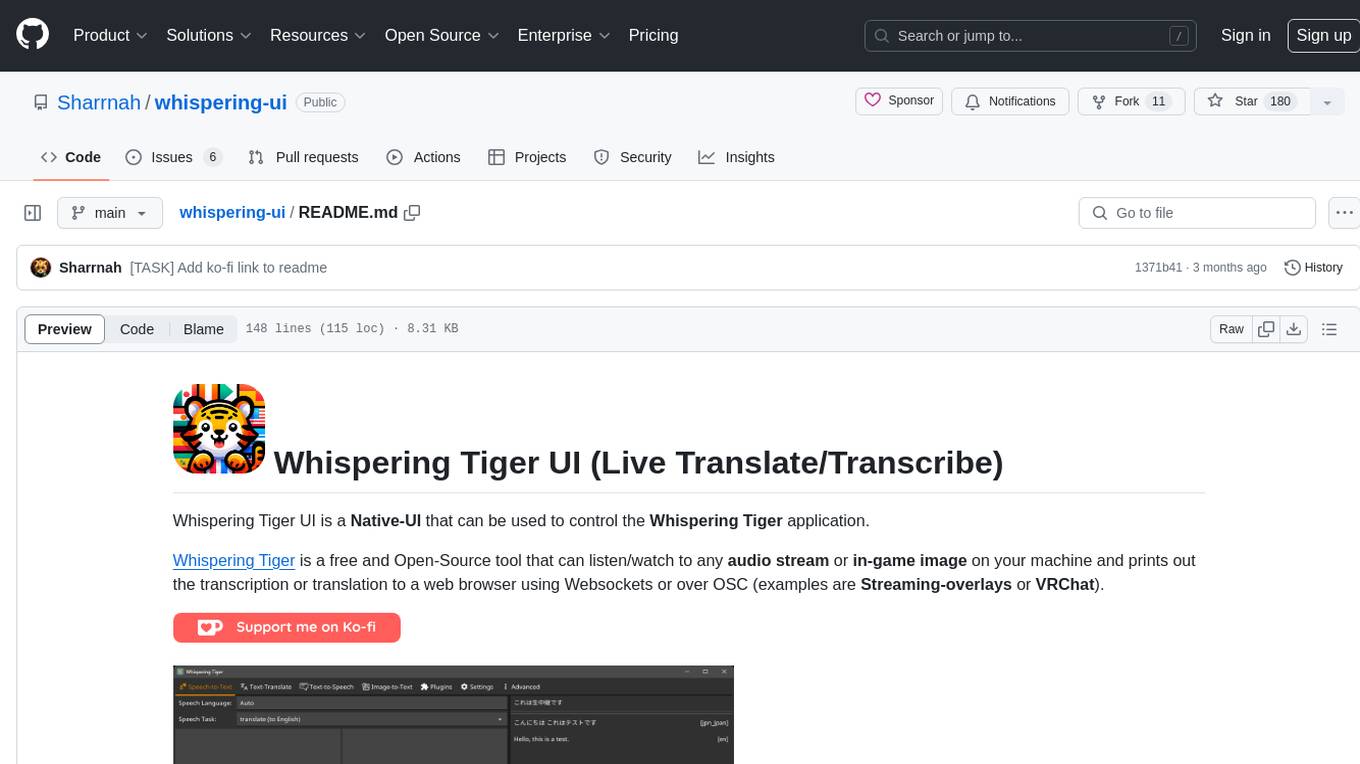
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.
For similar tasks

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
ai-on-openshift
AI on OpenShift is a site providing installation recipes, patterns, and demos for AI/ML tools and applications used in Data Science and Data Engineering projects running on OpenShift. It serves as a comprehensive resource for developers looking to deploy AI solutions on the OpenShift platform.
sematic
Sematic is an open-source ML development platform that allows ML Engineers and Data Scientists to write complex end-to-end pipelines with Python. It can be executed locally, on a cloud VM, or on a Kubernetes cluster. Sematic enables chaining data processing jobs with model training into reproducible pipelines that can be monitored and visualized in a web dashboard. It offers features like easy onboarding, local-to-cloud parity, end-to-end traceability, access to heterogeneous compute resources, and reproducibility.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

ZetaForge
ZetaForge is an open-source AI platform designed for rapid development of advanced AI and AGI pipelines. It allows users to assemble reusable, customizable, and containerized Blocks into highly visual AI Pipelines, enabling rapid experimentation and collaboration. With ZetaForge, users can work with AI technologies in any programming language, easily modify and update AI pipelines, dive into the code whenever needed, utilize community-driven blocks and pipelines, and share their own creations. The platform aims to accelerate the development and deployment of advanced AI solutions through its user-friendly interface and community support.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.
data-prep-kit
Data Prep Kit is a community project aimed at democratizing and speeding up unstructured data preparation for LLM app developers. It provides high-level APIs and modules for transforming data (code, language, speech, visual) to optimize LLM performance across different use cases. The toolkit supports Python, Ray, Spark, and Kubeflow Pipelines runtimes, offering scalability from laptop to datacenter-scale processing. Developers can contribute new custom modules and leverage the data processing library for building data pipelines. Automation features include workflow automation with Kubeflow Pipelines for transform execution.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.