
SuperKnowa
Build Enterprise RAG (Retriver Augmented Generation) Pipelines to tackle various Generative AI use cases with LLM's by simply plugging componants like Lego pieces. This repo is intended for IBM Ecosystem partners.
Stars: 98

SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
README:
Fast Framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale - powered by watsonx
Welcome to the SuperKnowa GitHub repository! SuperKnowa framework accelerates your Enterprise Generative AI applications to get prod-ready solutions quickly on your private data. Here, you will find a diverse collection of pluggable components designed to tackle various Generative AI use cases using Large Language Models (LLMs). Think of these components as building blocks, much like Lego pieces, that you can assemble to address a wide range of challenges in the realm of AI-driven text generation. These are battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
The overall pipeline of the SuperKnowa RAG framework & key building blocks:
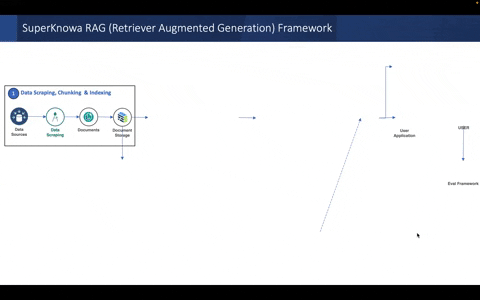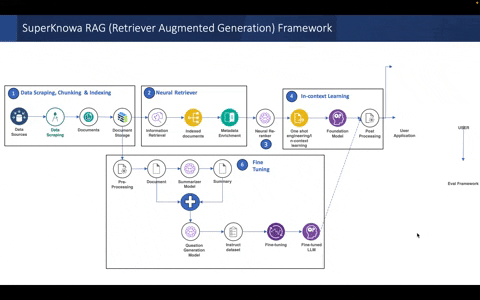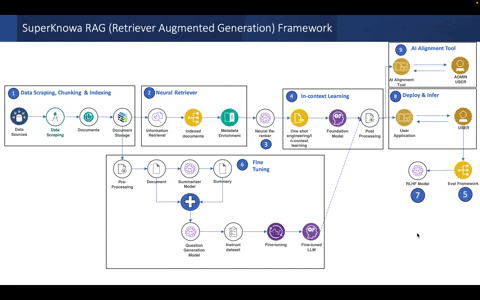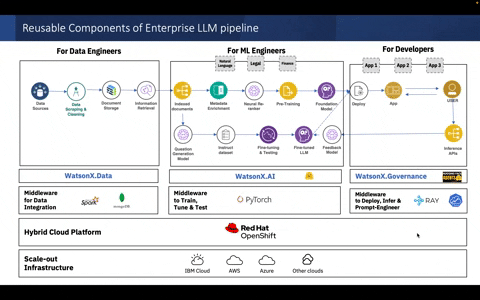
Configurable components for the SuperKnowa RAG pipeline using a single file:
SuperKnowa is a powerful framework developed using watsonx (watch the video on watsonx.ai here) that harnesses the capabilities of Large Language Models (LLMs) to offer a range of advanced Generative AI use cases. This repository introduces you to the various use cases covered by SuperKnowa.
📖 Learn more about SuperKnowa in our insightful blog post:
Cover Blog - SuperKnowa: Building Enterprise RAG Solutions at Scale https://medium.com/towards-generative-ai/superknowa-simplest-framework-yet-to-swiftly-build-enterprise-rag-solutions-at-scale-ca90b49be28a
Try the SuperKnowa framework with a live application built on the private knowledge base of 1M diverse docs:
https://superknowa.tsglwatson.buildlab.cloud/
(In case you don't have IBM ID, please get it here - https://www.ibm.com/account/reg/us-en/signup?formid=urx-19776)
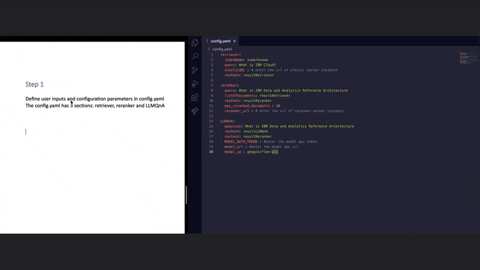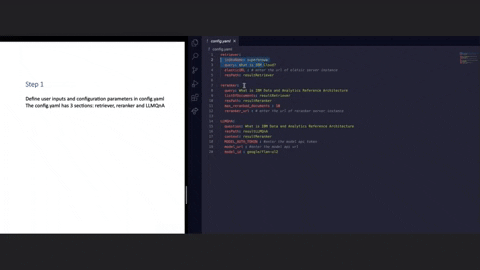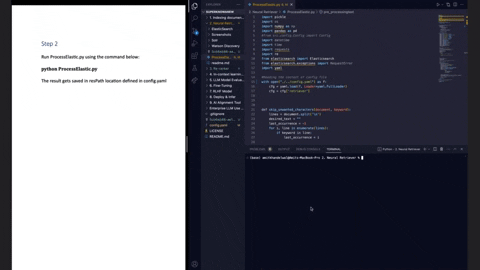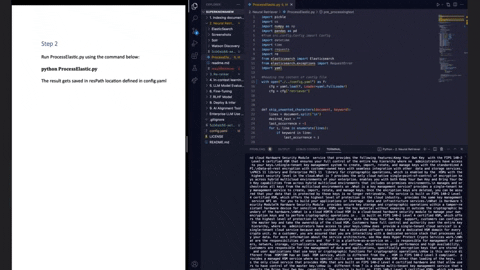
You can get started by updating the config.yaml file and run the LLMQnA.py script for quickly configuring your RAG pipeline:
retriever:
indexName: superknowa
query: What is IBM Cloud?
....
reranker:
query: What is IBM Data and Analytics Reference Architecture?
...
LLMQnA:
question: What is IBM Data and Analytics Reference Architecture?
...
To explore SuperKnowa's features and capabilities, refer to the blog series, code examples, and resources provided in this repository.
For detailed instructions and examples, navigate to each component's directory. Unleash the potential of Large Language Models in your projects using SuperKnowa's Generative AI Lego Components!
Let's unlock the potential of Generative AI with SuperKnowa and shape the future of AI-powered knowledge processing!
-
-
Watson Discovery
-
-
Fine Tuning LLAMA2 7B using QLORA
-
- Capture Human Feedback
- Admin Dashboard for AI Alignment Results
Measure the alignment of AI models on the metrics of helpfulness, harmfulness and accuracy by capturing human inputs.
Build your various online & offline experiments for evaluations and compare the AI alignment results using an interactive dashboard.
The Eval_Package is a tool designed to evaluate the performance of the LLM (Language Model) on a dataset containing questions, context, and ideal answers. It allows you to run evaluations on various datasets and assess how well the Model generates the answer on dozens of statistical metrics like BLUE, ROUGE, etc.
- Evaluate LLM Model on custom datasets: Use the Eval_Package to assess the performance of your Model on datasets of your choice.
- Measure model accuracy: The package provides metrics to gauge the accuracy of the model-generated answers against the ideal answers.
The MLflow_Package is a comprehensive toolkit designed to integrate the results from the Eval_Package and efficiently track and manage experiments. It also enables you to create a leaderboard for evaluation comparisons and visualize metrics through a dashboard.
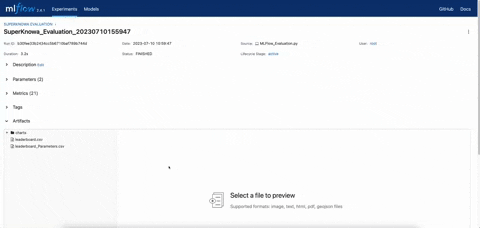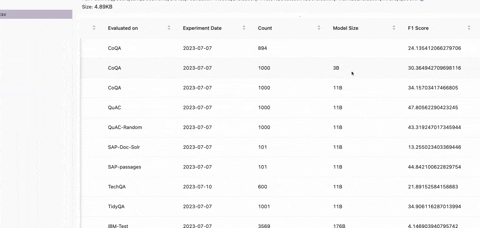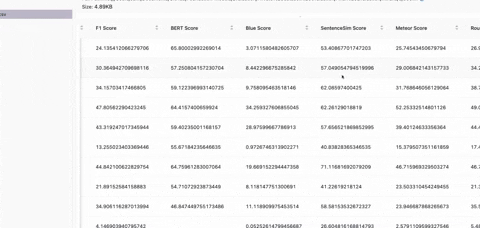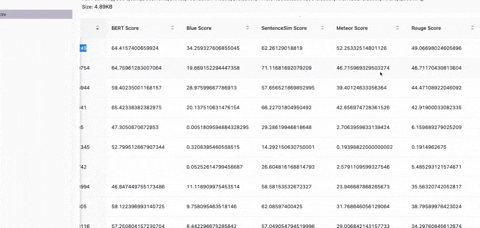
- Statistical Metrics Supported are BLEU, METEOR, ROUGE, SentenceSim Score, SimHash Score, Perplexity Score, BLEURT Score, F1 Score and BERT score.
- Experiment tracking: Utilize MLflow to keep a record of experiments, including parameters, metrics, and model artifacts generated during evaluations.
- Leaderboard creation: The package allows you to create a leaderboard, making it easy to compare the performance of different Models across multiple datasets.
- Metric visualization: Generate insightful charts and graphs through the dashboard, allowing you to visualize and analyze evaluation metrics easily.
Below is a list of Generative AI use cases built using the SuperKnowa framework.
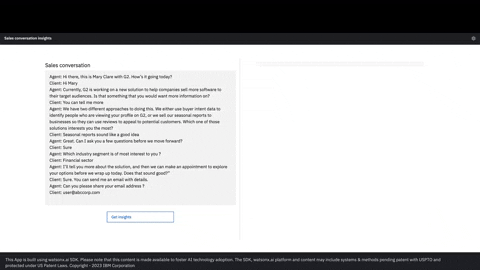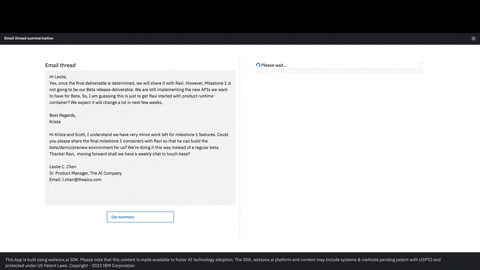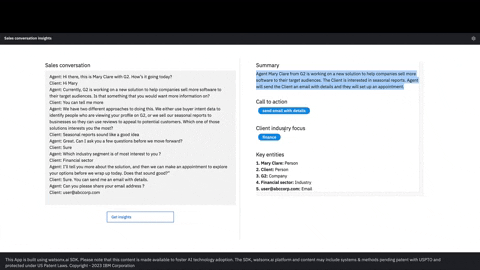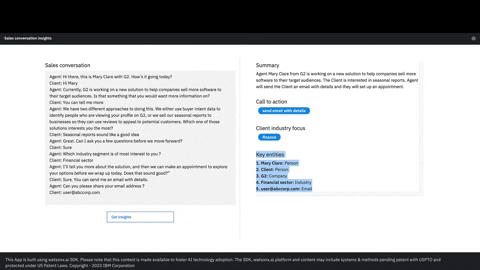
Engage in natural language conversations with SuperKnowa's conversational Question & Answer (Q&A) system. Ask questions based on the private enterprise knowledge base, and receive detailed, context-aware responses.

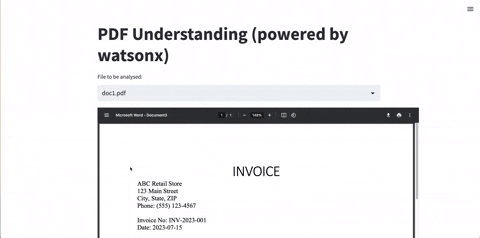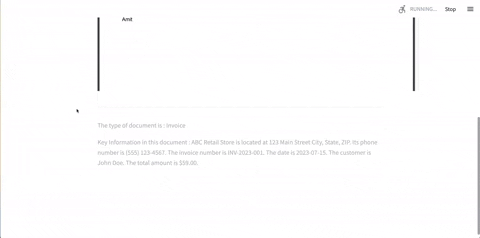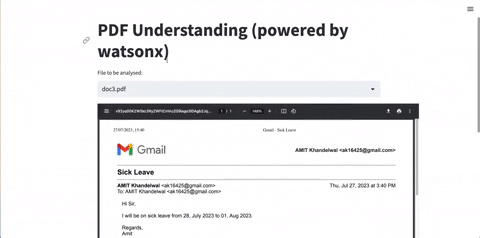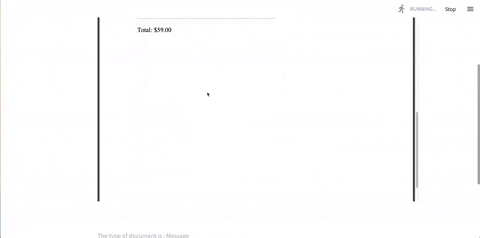
Leverage SuperKnowa's "Ask your documents" feature to unlock the potential of your PDFs and text documents. SuperKnowa can help you extract relevant information, answer specific questions, and assist in information retrieval.
Effortlessly generate coherent and informative summaries with SuperKnowa's summarization feature across large text corpus using FlanT5 and UL2. Extract the main points and essential details from articles, reports, and other texts, allowing for efficient content comprehension.
SuperKnowa's abstractive summarisation feature goes beyond simple extraction using FlanUL2, and LLAMA2. It can analyze lengthy PDF documents and generate concise abstractive summaries, capturing the essence of the content. Additionally, SuperKnowa identifies key points, making it easier to comprehend and communicate complex information.
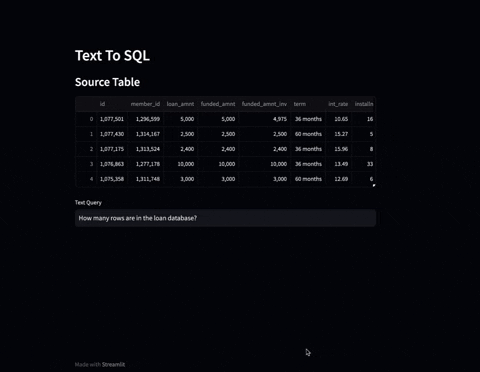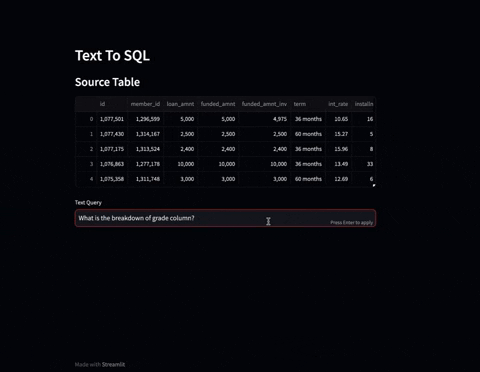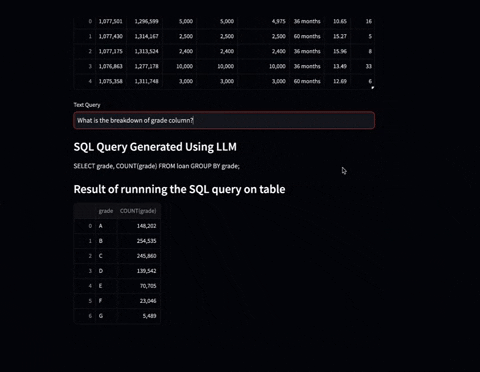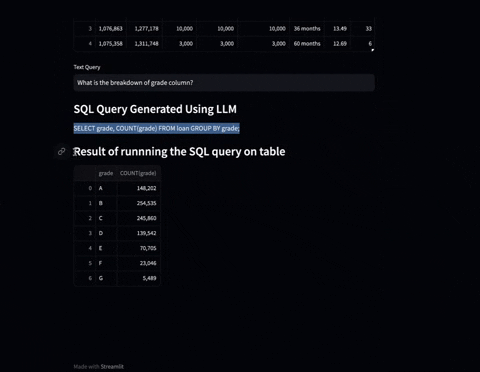
Experience the power of SuperKnowa's Text-to-SQL capability, which transforms natural language queries into structured SQL queries. Interact with databases using plain language, eliminating the need for expertise in SQL.
Created & Architected By
- Kunal Sawarkar, Chief Data Scientist
Builders
- Shivam Solanki, Senior Advisory Data Scientist
- Michael Spriggs, Principal Architect
- Kevin Huang, Sr. ML-Ops Engineer
- Abhilasha Mangal, Senior Data Scientist
- Sahil Desai, Data Scientist
- Amit Khandelwal- Senior Data Scientist
- Himadri Talukder - Senior Software Engineer
- Tyler Benson- Data Scientist
This framework is developed by Build Lab, IBM Ecosystem. Please note that this content is made available to foster Embeddable AI technology adoption and serve ecosystem partners. The content may include systems & methods pending patent with the USPTO and protected under US Patent Laws. SuperKnowa is not a product but a framework built on the top of IBM watsonx along with other products like LLAMA models from Meta & ML Flow from Databricks. Using SuperKnowa implicitly requires agreeing to the Terms and conditions of those products. This framework is made available on an as-is basis to accelerate Enterprise GenAI applications development. In case of any questions, please reach out to [email protected].
Copyright @ 2023 IBM Corporation.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SuperKnowa
Similar Open Source Tools
SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.

GrAIdient
GrAIdient is a framework designed to enable the development of deep learning models using the internal GPU of a Mac. It provides access to the graph of layers, allowing for unique model design with greater understanding, control, and reproducibility. The goal is to challenge the understanding of deep learning models, transitioning from black box to white box models. Key features include direct access to layers, native Mac GPU support, Swift language implementation, gradient checking, PyTorch interoperability, and more. The documentation covers main concepts, architecture, and examples. GrAIdient is MIT licensed.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
btp-cap-genai-rag
This GitHub repository provides support for developers, partners, and customers to create advanced GenAI solutions on SAP Business Technology Platform (SAP BTP) following the Reference Architecture. It includes examples on integrating Foundation Models and Large Language Models via Generative AI Hub, using LangChain in CAP, and implementing advanced techniques like Retrieval Augmented Generation (RAG) through embeddings and SAP HANA Cloud's Vector Engine for enhanced value in customer support scenarios.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on multi-agent collaborative patterns, integrating domain experience to help agents solve problems in various fields. The framework includes pattern components like PEER and DOE for event interpretation, industry analysis, and financial report generation. It offers features for agent construction, multi-agent collaboration, and domain expertise integration, aiming to create intelligent applications with professional know-how.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.

onnx
Open Neural Network Exchange (ONNX) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types. Currently, we focus on the capabilities needed for inferencing (scoring). ONNX is widely supported and can be found in many frameworks, tools, and hardware, enabling interoperability between different frameworks and streamlining the path from research to production to increase the speed of innovation in the AI community. Join us to further evolve ONNX.
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
motleycrew
Motleycrew is an ultimate framework for building multi-agent AI systems, allowing users to mix and match AI agents and tools from popular frameworks, design advanced workflows, and leverage dynamic knowledge graphs with simplicity and elegance. It acts as a conductor orchestrating a symphony of AI agents and tools, providing building blocks for creating AI systems and enabling users to focus on high-level design while taking care of the rest. The framework offers integration with various tools, flexibility in providing agents with tools or other agents, advanced flow design capabilities, and built-in observability and caching features.
For similar tasks

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
ai-on-openshift
AI on OpenShift is a site providing installation recipes, patterns, and demos for AI/ML tools and applications used in Data Science and Data Engineering projects running on OpenShift. It serves as a comprehensive resource for developers looking to deploy AI solutions on the OpenShift platform.

sematic
Sematic is an open-source ML development platform that allows ML Engineers and Data Scientists to write complex end-to-end pipelines with Python. It can be executed locally, on a cloud VM, or on a Kubernetes cluster. Sematic enables chaining data processing jobs with model training into reproducible pipelines that can be monitored and visualized in a web dashboard. It offers features like easy onboarding, local-to-cloud parity, end-to-end traceability, access to heterogeneous compute resources, and reproducibility.
SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

ZetaForge
ZetaForge is an open-source AI platform designed for rapid development of advanced AI and AGI pipelines. It allows users to assemble reusable, customizable, and containerized Blocks into highly visual AI Pipelines, enabling rapid experimentation and collaboration. With ZetaForge, users can work with AI technologies in any programming language, easily modify and update AI pipelines, dive into the code whenever needed, utilize community-driven blocks and pipelines, and share their own creations. The platform aims to accelerate the development and deployment of advanced AI solutions through its user-friendly interface and community support.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.
data-prep-kit
Data Prep Kit is a community project aimed at democratizing and speeding up unstructured data preparation for LLM app developers. It provides high-level APIs and modules for transforming data (code, language, speech, visual) to optimize LLM performance across different use cases. The toolkit supports Python, Ray, Spark, and Kubeflow Pipelines runtimes, offering scalability from laptop to datacenter-scale processing. Developers can contribute new custom modules and leverage the data processing library for building data pipelines. Automation features include workflow automation with Kubeflow Pipelines for transform execution.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.