Best AI tools for< Nlp Engineer >
Infographic
20 - AI tool Sites
UBIAI
UBIAI is a powerful text annotation tool that helps businesses accelerate their data labeling process. With UBIAI, businesses can annotate any type of document, including PDFs, images, and text. UBIAI also offers a variety of features to make the annotation process easier and more efficient, such as auto-labeling, multi-lingual annotation, and team collaboration. With UBIAI, businesses can save time and money on their data labeling projects.
AI Jobs Platform
The website is a platform that focuses on AI-related jobs and opportunities. It provides a comprehensive list of job openings in the field of artificial intelligence, including positions such as software engineers, machine learning engineers, NLP engineers, and more. Users can search for jobs based on location, role, and specific tags. The platform also features information about various AI startups and their open positions, aiming to connect job seekers with opportunities in the AI industry.
OpenVoiceOS
OpenVoiceOS is a community-driven, open-source voice AI platform for creating custom voice-controlled interfaces across devices with NLP, a customizable UI, and a focus on privacy and security. OpenVoiceOS is designed to provide users with a seamless and intuitive voice interface for controlling their smart home devices, playing music, setting reminders, and much more. OpenVoiceOS is open to all developers and contributors wanting to support a specific device or a platform. OpenVoiceOS is the platform to throw your ideas at if you have an experimental feature you want users to experience before landing them into any of the Linux-based open-source voice assistant projects upstream.
Kovil.AI
Kovil.AI is an AI-powered platform that connects businesses with top AI talents from India's largest network. The platform offers a vetting process to match businesses with hand-picked Indian developers, covering a wide range of expertise in AI, machine learning, data science, and more. Kovil.AI aims to empower ambitious businesses by providing access to specialized, high-caliber AI professionals, accelerating the hiring process, and reducing costs. The platform also offers managed services and products, ensuring flexibility, adaptability, and a competitive advantage for businesses seeking top talent.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Folio3.Ai
Folio3.Ai is an end-to-end AI development company specializing in machine learning and artificial intelligence solutions for startups and enterprises. With over 15 years of experience, Folio3 offers services such as generative AI development, computer vision technology, large language models, natural language processing, predictive analytics, and more. The company empowers businesses across diverse industries with custom AI solutions and pre-built models, enabling them to innovate and thrive in today's dynamic landscape.
Prompt Engineering
Prompt Engineering is a discipline focused on developing and optimizing prompts to efficiently utilize language models (LMs) for various applications and research topics. It involves skills to understand the capabilities and limitations of large language models, improving their performance on tasks like question answering and arithmetic reasoning. Prompt engineering is essential for designing robust prompting techniques that interact with LLMs and other tools, enhancing safety and building new capabilities by augmenting LLMs with domain knowledge and external tools.
Keytalk AI
Keytalk AI is a company that specializes in prompt engineering, which is the process of creating prompts that can be used to generate text, images, and other types of content using artificial intelligence (AI) models. Keytalk AI's mission is to make AI more accessible and user-friendly by providing tools and resources that make it easy for people to create and use AI-generated content. The company's flagship product is Keytalk Prompts, a library of pre-written prompts that can be used to generate content on a variety of topics. Keytalk AI also offers a range of other services, including consulting, training, and support.
Explosion
Explosion is a software company specializing in developer tools and tailored solutions for AI, Machine Learning, and Natural Language Processing (NLP). They are the makers of spaCy, one of the leading open-source libraries for advanced NLP. The company offers consulting services and builds developer tools for various AI-related tasks, such as coreference resolution, dependency parsing, image classification, named entity recognition, and more.
Datasaur
Datasaur is an advanced text and audio data labeling platform that offers customizable solutions for various industries such as LegalTech, Healthcare, Financial, Media, e-Commerce, and Government. It provides features like configurable annotation, quality control automation, and workforce management to enhance the efficiency of NLP and LLM projects. Datasaur prioritizes data security with military-grade practices and offers seamless integrations with AWS and other technologies. The platform aims to streamline the data labeling process, allowing engineers to focus on creating high-quality models.
Answer.AI
Answer.AI is an AI tool developed by Benjamin Clavié, focusing on NLP&IR with a special interest in developing smaller models to power LLM-based applications. The tool includes models like answerai-colbert-small-v1 and JaColBERTv2.5🇯🇵, offering efficient pooling tricks and optimizing retrieval training for lower-resource languages. Benjamin Clavié shares insights and thoughts on ML/NLP/IR ecosystem through blog posts on the website.
Langtail
Langtail is a platform that helps developers build, test, and deploy AI-powered applications. It provides a suite of tools to help developers debug prompts, run tests, and monitor the performance of their AI models. Langtail also offers a community forum where developers can share tips and tricks, and get help from other users.
Mixpeek Solutions
Mixpeek Solutions offers a Multimodal Data Warehouse for Developers, providing a Developer-First API for AI-native Content Understanding. The platform allows users to search, monitor, classify, and cluster unstructured data like video, audio, images, and documents. Mixpeek Solutions offers a range of features including Unified Search, Automated Classification, Unsupervised Clustering, Feature Extractors for Every Data Type, and various specialized extraction models for different data types. The platform caters to a wide range of industries and provides seamless model upgrades, cross-model compatibility, A/B testing infrastructure, and simplified model management.
Next AI Jobs
Next AI Jobs is an AI-powered platform that specializes in connecting professionals with job opportunities in the fields of Artificial Intelligence (AI), Machine Learning (ML), Natural Language Processing (NLP), and Data Science. The platform utilizes advanced algorithms to match candidates with relevant job listings, streamlining the recruitment process for both employers and job seekers. Next AI Jobs provides a user-friendly interface where users can create profiles, upload resumes, and apply for jobs with ease. With a focus on the rapidly growing AI industry, Next AI Jobs aims to bridge the gap between talented individuals and top-tier companies seeking AI expertise.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
ABBYY
ABBYY is an intelligent automation company that offers purpose-built AI document processing solutions for efficient business process automation. Their products include ABBYY Vantage, ABBYY Timeline, ABBYY Cloud OCR SDK, and ABBYY FlexiCapture Cloud Platform. ABBYY provides tools for document input, classification, splitting, data extraction, validation, quality analytics, OCR/ICR, and IDP analytics. They also offer solutions for process understanding, optimization, monitoring, prediction, and simulation. ABBYY Marketplace offers pre-trained AI extraction models for limitless automation. The company caters to various industries like financial services, public sector, insurance, transportation & logistics, and offers solutions for accounts payable automation, enterprise automation, process intelligence, and customer onboarding.
DeepRec.ai
DeepRec.ai is a specialized recruitment platform focusing on AI and ML professionals. The platform offers hiring services for various AI specialisms such as Research GenAI, Machine Learning, Computer Vision, AI Infrastructure, Quantum Computing, Robotics & Embodied AI, and AI4Science. DeepRec.ai provides hiring solutions like Embedded Hiring, Retained Search, Contingent Contract & Flexible Resource, tailored to scale with businesses and address high-volume hiring challenges. The platform boasts positive feedback from both clients and candidates, emphasizing the quality of communication, candidate selection, and support throughout the recruitment process.

Derwen
Derwen is an open-source integration platform for production machine learning in enterprise, specializing in natural language processing, graph technologies, and decision support. It offers expertise in developing knowledge graph applications and domain-specific authoring. Derwen collaborates closely with Hugging Face and provides strong data privacy guarantees, low carbon footprint, and no cloud vendor involvement. The platform aims to empower AI engineers and domain experts with quality, time-to-value, and ownership since 2017.

GPT CLI
GPT CLI is an all-in-one AI tool that allows users to build their own AI command-line interface tools using ChatGPT. It provides various plugins such as AI Commit, AI Command, AI Translate, and more, enabling users to streamline their workflow and automate tasks through natural language commands. With GPT CLI, users can easily generate Git commit messages, execute commands, translate text, and perform various other AI-powered tasks directly from the command line.
FutureSmart AI
FutureSmart AI is a platform that provides custom Natural Language Processing (NLP) solutions. The platform focuses on integrating Mem0 with LangChain to enhance AI Assistants with Intelligent Memory. It offers tutorials, guides, and practical tips for building applications with large language models (LLMs) to create sophisticated and interactive systems. FutureSmart AI also features internship journeys and practical guides for mastering RAG with LangChain, catering to developers and enthusiasts in the realm of NLP and AI.
177 - Open Source Tools

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
alignment-handbook
The Alignment Handbook provides robust training recipes for continuing pretraining and aligning language models with human and AI preferences. It includes techniques such as continued pretraining, supervised fine-tuning, reward modeling, rejection sampling, and direct preference optimization (DPO). The handbook aims to fill the gap in public resources on training these models, collecting data, and measuring metrics for optimal downstream performance.
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.
ai-clone-whatsapp
This repository provides a tool to create an AI chatbot clone of yourself using your WhatsApp chats as training data. It utilizes the Torchtune library for finetuning and inference. The code includes preprocessing of WhatsApp chats, finetuning models, and chatting with the AI clone via a command-line interface. Supported models are Llama3-8B-Instruct and Mistral-7B-Instruct-v0.2. Hardware requirements include approximately 16 GB vRAM for QLoRa Llama3 finetuning with a 4k context length. The repository addresses common issues like adjusting parameters for training and preprocessing non-English chats.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

Large-Language-Model-Notebooks-Course
This practical free hands-on course focuses on Large Language models and their applications, providing a hands-on experience using models from OpenAI and the Hugging Face library. The course is divided into three major sections: Techniques and Libraries, Projects, and Enterprise Solutions. It covers topics such as Chatbots, Code Generation, Vector databases, LangChain, Fine Tuning, PEFT Fine Tuning, Soft Prompt tuning, LoRA, QLoRA, Evaluate Models, Knowledge Distillation, and more. Each section contains chapters with lessons supported by notebooks and articles. The course aims to help users build projects and explore enterprise solutions using Large Language Models.
llm-swarm
llm-swarm is a tool designed to manage scalable open LLM inference endpoints in Slurm clusters. It allows users to generate synthetic datasets for pretraining or fine-tuning using local LLMs or Inference Endpoints on the Hugging Face Hub. The tool integrates with huggingface/text-generation-inference and vLLM to generate text at scale. It manages inference endpoint lifetime by automatically spinning up instances via `sbatch`, checking if they are created or connected, performing the generation job, and auto-terminating the inference endpoints to prevent idling. Additionally, it provides load balancing between multiple endpoints using a simple nginx docker for scalability. Users can create slurm files based on default configurations and inspect logs for further analysis. For users without a Slurm cluster, hosted inference endpoints are available for testing with usage limits based on registration status.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
typechat.net
TypeChat.NET is a framework that provides cross-platform libraries for building natural language interfaces with language models using strong types, type validation, and simple type-safe programs. It translates user intent into strongly typed objects and JSON programs, with support for schema export, extensibility, and common scenarios. The framework is actively developed with frequent updates, evolving based on exploration and feedback. It consists of assemblies for translating user intent, synthesizing JSON programs, and integrating with Microsoft Semantic Kernel. TypeChat.NET requires familiarity with and access to OpenAI language models for its examples and scenarios.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.
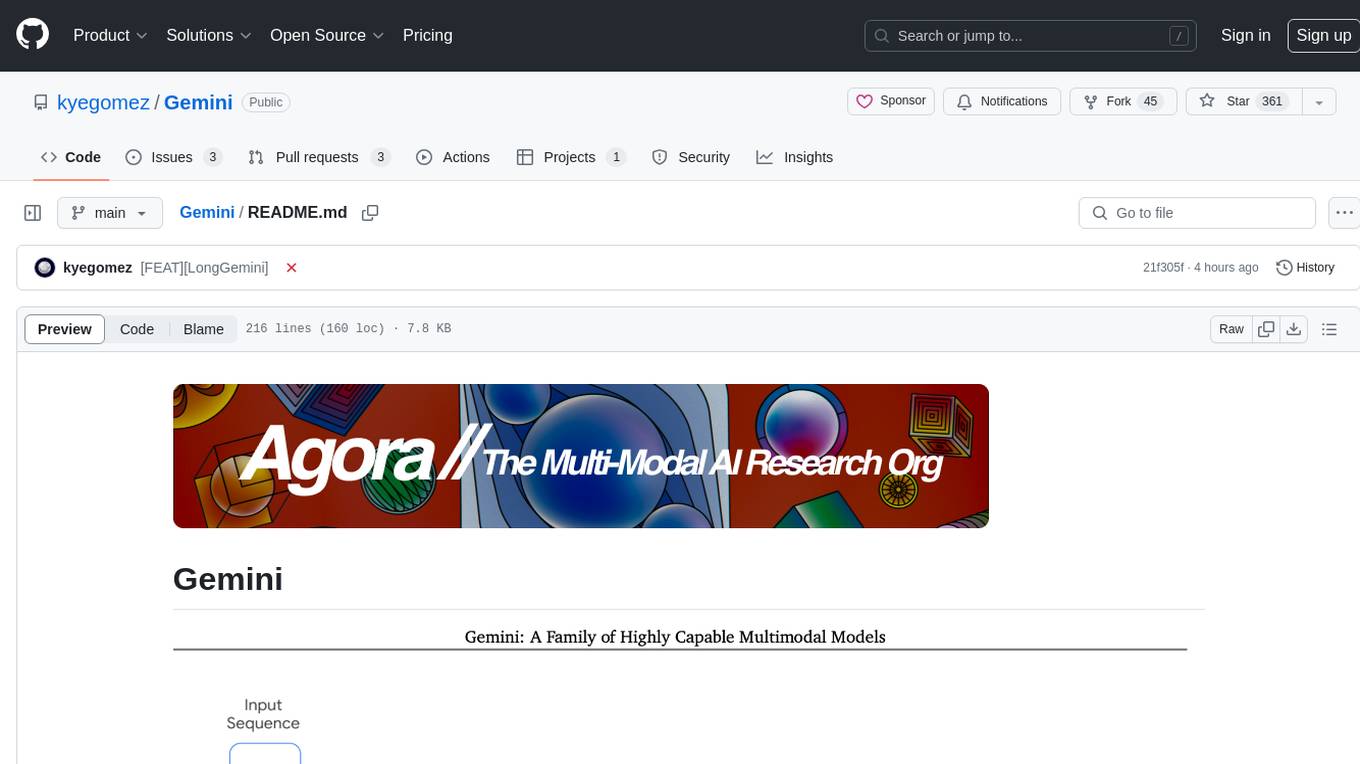
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.

oreilly-hands-on-gpt-llm
This repository contains code for the O'Reilly Live Online Training for Deploying GPT & LLMs. Learn how to use GPT-4, ChatGPT, OpenAI embeddings, and other large language models to build applications for experimenting and production. Gain practical experience in building applications like text generation, summarization, question answering, and more. Explore alternative generative models such as Cohere and GPT-J. Understand prompt engineering, context stuffing, and few-shot learning to maximize the potential of GPT-like models. Focus on deploying models in production with best practices and debugging techniques. By the end of the training, you will have the skills to start building applications with GPT and other large language models.

kairon
Kairon is an open-source conversational digital transformation platform that helps build LLM-based digital assistants at scale. It provides a no-coding web interface for adapting, training, testing, and maintaining AI assistants. Kairon focuses on pre-processing data for chatbots, including question augmentation, knowledge graph generation, and post-processing metrics. It offers end-to-end lifecycle management, low-code/no-code interface, secure script injection, telemetry monitoring, chat client designer, analytics module, and real-time struggle analytics. Kairon is suitable for teams and individuals looking for an easy interface to create, train, test, and deploy digital assistants.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.
Anima
Anima is the first open-source 33B Chinese large language model based on QLoRA, supporting DPO alignment training and open-sourcing a 100k context window model. The latest update includes AirLLM, a library that enables inference of 70B LLM from a single GPU with just 4GB memory. The tool optimizes memory usage for inference, allowing large language models to run on a single 4GB GPU without the need for quantization or other compression techniques. Anima aims to democratize AI by making advanced models accessible to everyone and contributing to the historical process of AI democratization.
keras-llm-robot
The Keras-llm-robot Web UI project is an open-source tool designed for offline deployment and testing of various open-source models from the Hugging Face website. It allows users to combine multiple models through configuration to achieve functionalities like multimodal, RAG, Agent, and more. The project consists of three main interfaces: chat interface for language models, configuration interface for loading models, and tools & agent interface for auxiliary models. Users can interact with the language model through text, voice, and image inputs, and the tool supports features like model loading, quantization, fine-tuning, role-playing, code interpretation, speech recognition, image recognition, network search engine, and function calling.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
tock
Tock is an open conversational AI platform for building bots. It offers a natural language processing open source stack compatible with various tools, a user interface for building stories and analytics, a conversational DSL for different programming languages, built-in connectors for text/voice channels, toolkits for custom web/mobile integration, and the ability to deploy anywhere in the cloud or on-premise with Docker.

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.
Tokenizer
This repository contains implementations of byte pair encoding (BPE) tokenizer in Typescript and C# for OpenAI LLMs. The implementations are based on an open-sourced rust implementation in the OpenAI tiktoken. These implementations are valuable for prompt tokenization in Nodejs and .NET environments before feeding prompts into a LLM.
langdrive
LangDrive is an open-source AI library that simplifies training, deploying, and querying open-source large language models (LLMs) using private data. It supports data ingestion, fine-tuning, and deployment via a command-line interface, YAML file, or API, with a quick, easy setup. Users can build AI applications such as question/answering systems, chatbots, AI agents, and content generators. The library provides features like data connectors for ingestion, fine-tuning of LLMs, deployment to Hugging Face hub, inference querying, data utilities for CRUD operations, and APIs for model access. LangDrive is designed to streamline the process of working with LLMs and making AI development more accessible.
discollama
Discollama is a Discord bot powered by a local large language model backed by Ollama. It allows users to interact with the bot in Discord by mentioning it in a message to start a new conversation or in a reply to a previous response to continue an ongoing conversation. The bot requires Docker and Docker Compose to run, and users need to set up a Discord Bot and environment variable DISCORD_TOKEN before using discollama.py. Additionally, an Ollama server is needed, and users can customize the bot's personality by creating a custom model using Modelfile and running 'ollama create'.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

WildBench
WildBench is a tool designed for benchmarking Large Language Models (LLMs) with challenging tasks sourced from real users in the wild. It provides a platform for evaluating the performance of various models on a range of tasks. Users can easily add new models to the benchmark by following the provided guidelines. The tool supports models from Hugging Face and other APIs, allowing for comprehensive evaluation and comparison. WildBench facilitates running inference and evaluation scripts, enabling users to contribute to the benchmark and collaborate on improving model performance.
Gensokyo-llm
Gensokyo-llm is a tool designed for Gensokyo and Onebotv11, providing a one-click solution for large models. It supports various Onebotv11 standard frameworks, HTTP-API, and reverse WS. The tool is lightweight, with built-in SQLite for context maintenance and proxy support. It allows easy integration with the Gensokyo framework by configuring reverse HTTP and forward HTTP addresses. Users can set system settings, role cards, and context length. Additionally, it offers an openai original flavor API with automatic context. The tool can be used as an API or integrated with QQ channel robots. It supports converting GPT's SSE type and ensures memory safety in concurrent SSE environments. The tool also supports multiple users simultaneously transmitting SSE bidirectionally.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.
simpletransformers
Simple Transformers is a library based on the Transformers library by HuggingFace, allowing users to quickly train and evaluate Transformer models with only 3 lines of code. It supports various tasks such as Information Retrieval, Language Models, Encoder Model Training, Sequence Classification, Token Classification, Question Answering, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification, and Conversational AI.
langserve_ollama
LangServe Ollama is a tool that allows users to fine-tune Korean language models for local hosting, including RAG. Users can load HuggingFace gguf files, create model chains, and monitor GPU usage. The tool provides a seamless workflow for customizing and deploying language models in a local environment.

long-llms-learning
A repository sharing the panorama of the methodology literature on Transformer architecture upgrades in Large Language Models for handling extensive context windows, with real-time updating the newest published works. It includes a survey on advancing Transformer architecture in long-context large language models, flash-ReRoPE implementation, latest news on data engineering, lightning attention, Kimi AI assistant, chatglm-6b-128k, gpt-4-turbo-preview, benchmarks like InfiniteBench and LongBench, long-LLMs-evals for evaluating methods for enhancing long-context capabilities, and LLMs-learning for learning technologies and applicated tasks about Large Language Models.
langflow
Langflow is an open-source Python-powered visual framework designed for building multi-agent and RAG applications. It is fully customizable, language model agnostic, and vector store agnostic. Users can easily create flows by dragging components onto the canvas, connect them, and export the flow as a JSON file. Langflow also provides a command-line interface (CLI) for easy management and configuration, allowing users to customize the behavior of Langflow for development or specialized deployment scenarios. The tool can be deployed on various platforms such as Google Cloud Platform, Railway, and Render. Contributors are welcome to enhance the project on GitHub by following the contributing guidelines.
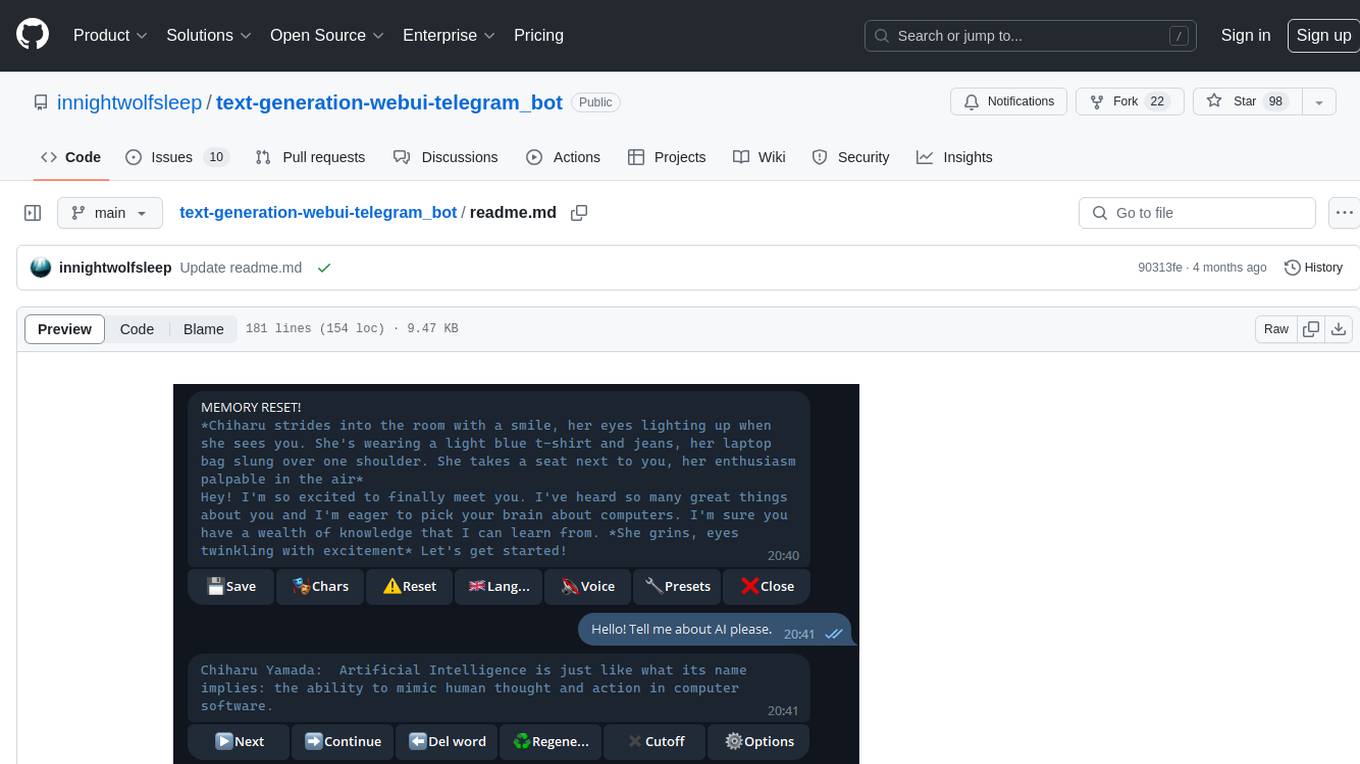
text-generation-webui-telegram_bot
The text-generation-webui-telegram_bot is a wrapper and extension for llama.cpp, exllama, or transformers, providing additional functionality for the oobabooga/text-generation-webui tool. It enhances Telegram chat with features like buttons, prefixes, and voice/image generation. Users can easily install and run the tool as a standalone app or in extension mode, enabling seamless integration with the text-generation-webui tool. The tool offers various features such as chat templates, session history, character loading, model switching during conversation, voice generation, auto-translate, and more. It supports different bot modes for personalized interactions and includes configurations for running in different environments like Google Colab. Additionally, users can customize settings, manage permissions, and utilize various prefixes to enhance the chat experience.
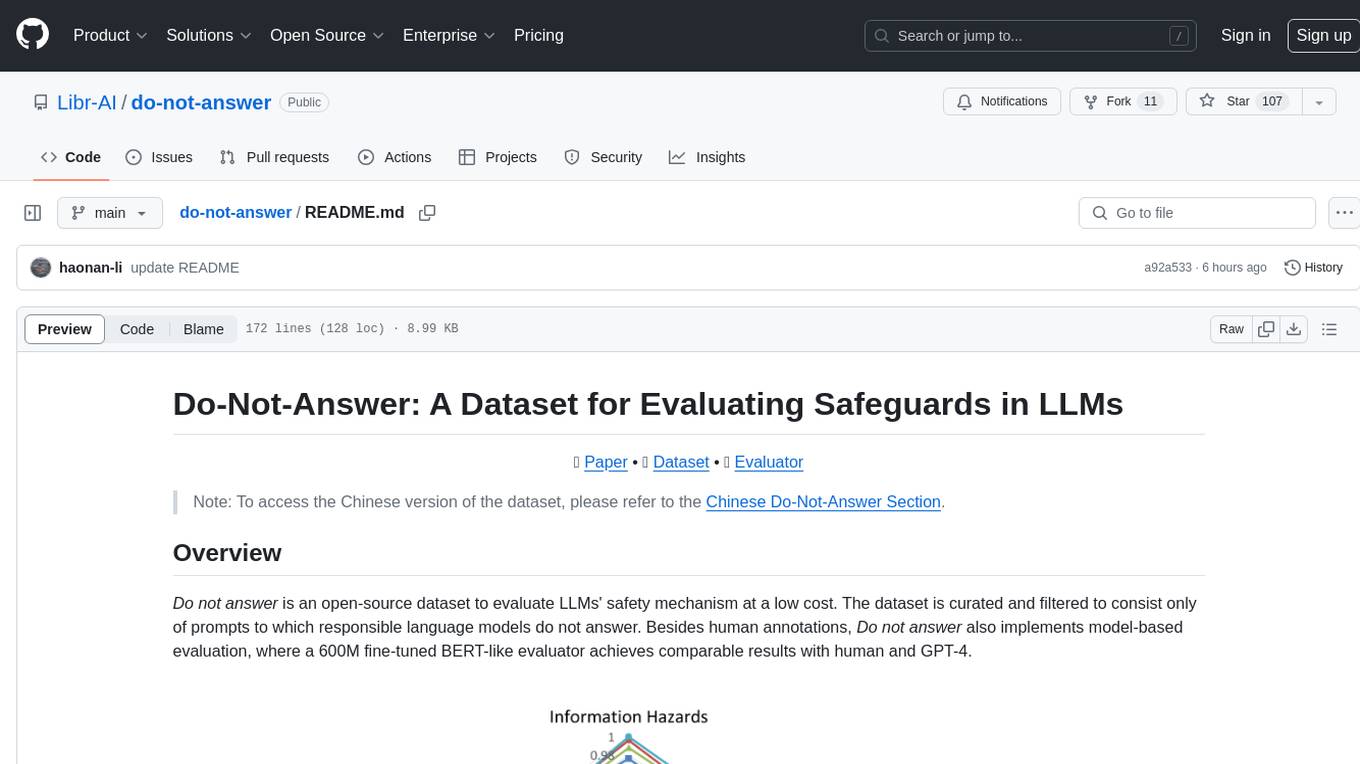
do-not-answer
Do-Not-Answer is an open-source dataset curated to evaluate Large Language Models' safety mechanisms at a low cost. It consists of prompts to which responsible language models do not answer. The dataset includes human annotations and model-based evaluation using a fine-tuned BERT-like evaluator. The dataset covers 61 specific harms and collects 939 instructions across five risk areas and 12 harm types. Response assessment is done for six models, categorizing responses into harmfulness and action categories. Both human and automatic evaluations show the safety of models across different risk areas. The dataset also includes a Chinese version with 1,014 questions for evaluating Chinese LLMs' risk perception and sensitivity to specific words and phrases.
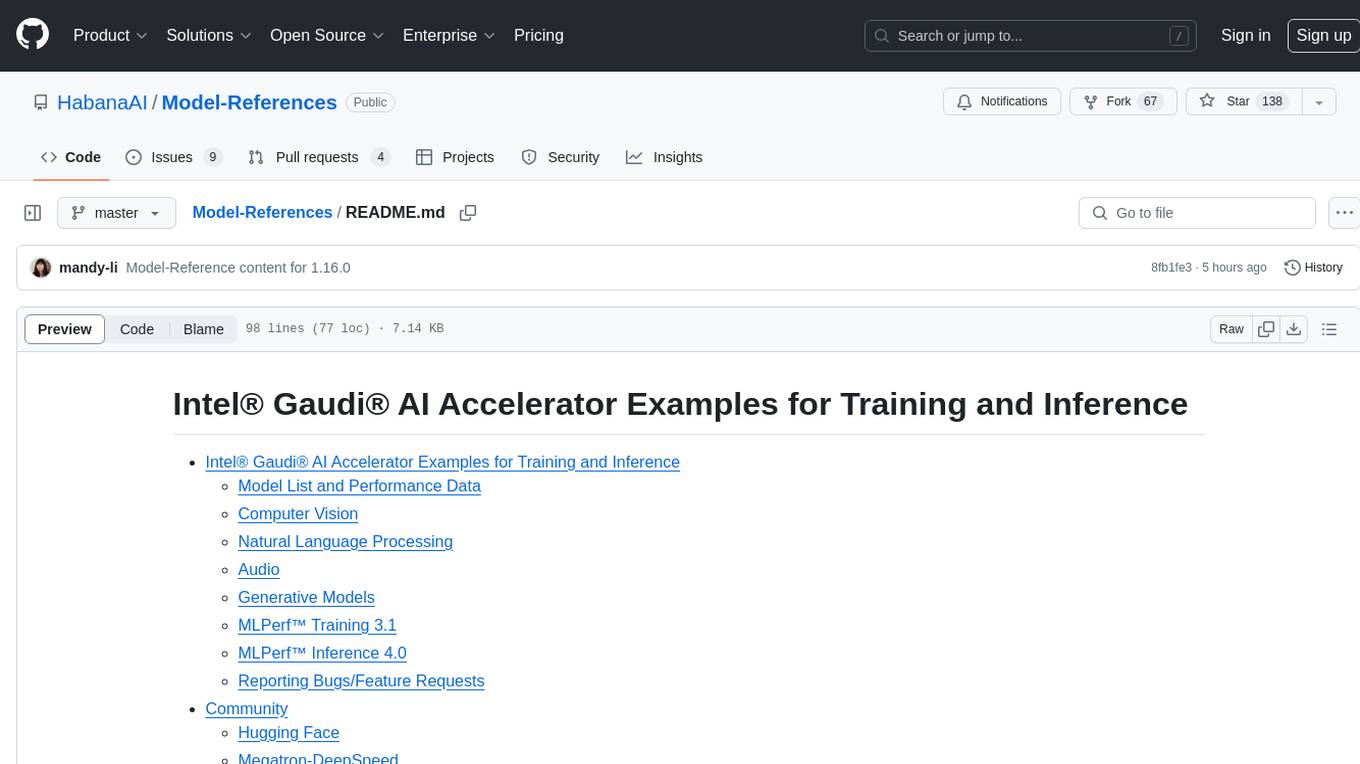
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.
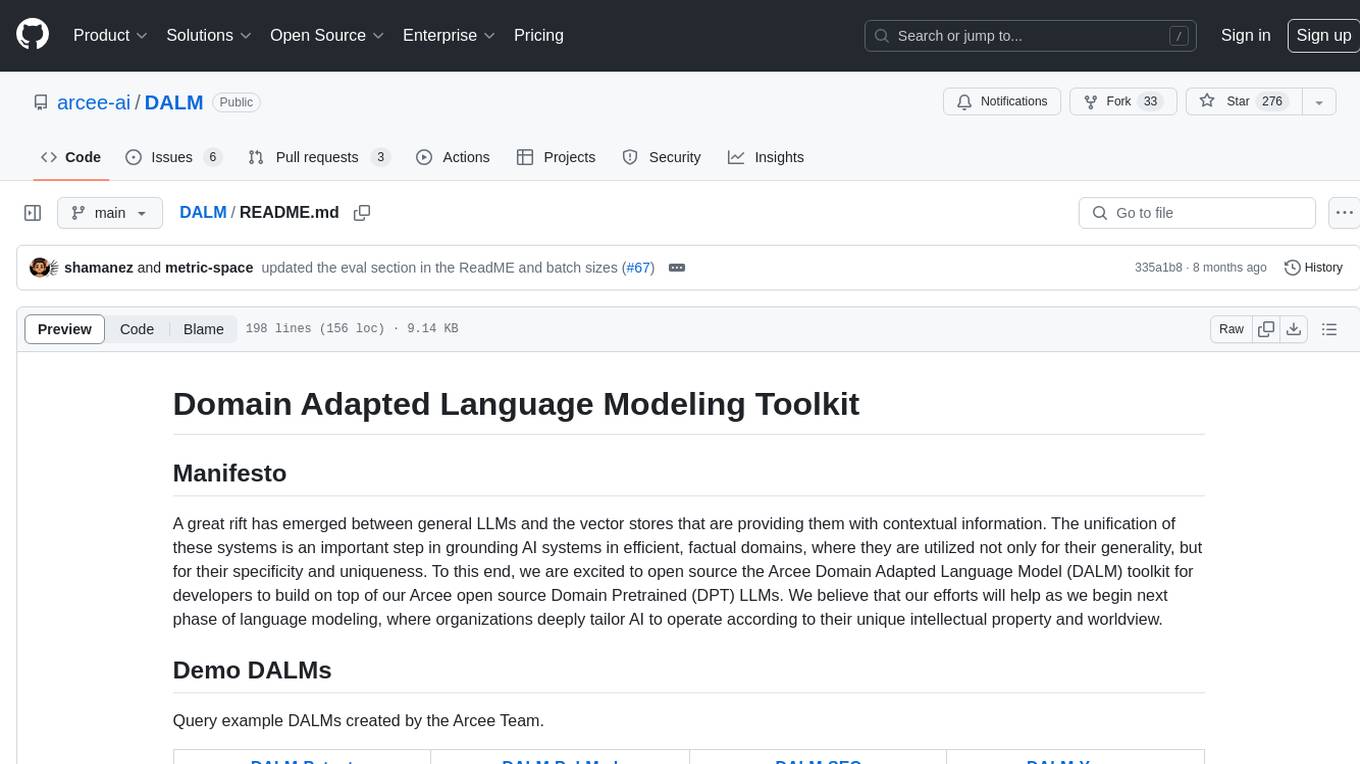
DALM
The DALM (Domain Adapted Language Modeling) toolkit is designed to unify general LLMs with vector stores to ground AI systems in efficient, factual domains. It provides developers with tools to build on top of Arcee's open source Domain Pretrained LLMs, enabling organizations to deeply tailor AI according to their unique intellectual property and worldview. The toolkit contains code for fine-tuning a fully differential Retrieval Augmented Generation (RAG-end2end) architecture, incorporating in-batch negative concept alongside RAG's marginalization for efficiency. It includes training scripts for both retriever and generator models, evaluation scripts, data processing codes, and synthetic data generation code.
meet-libai
The 'meet-libai' project aims to promote and popularize the cultural heritage of the Chinese poet Li Bai by constructing a knowledge graph of Li Bai and training a professional AI intelligent body using large models. The project includes features such as data preprocessing, knowledge graph construction, question-answering system development, and visualization exploration of the graph structure. It also provides code implementations for large models and RAG retrieval enhancement.
llm-cookbook
LLM Cookbook is a developer-oriented comprehensive guide focusing on LLM for Chinese developers. It covers various aspects from Prompt Engineering to RAG development and model fine-tuning, providing guidance on how to learn and get started with LLM projects in a way suitable for Chinese learners. The project translates and reproduces 11 courses from Professor Andrew Ng's large model series, categorizing them for beginners to systematically learn essential skills and concepts before exploring specific interests. It encourages developers to contribute by replicating unreproduced courses following the format and submitting PRs for review and merging. The project aims to help developers grasp a wide range of skills and concepts related to LLM development, offering both online reading and PDF versions for easy access and learning.
LLM-from-scratch
This repository contains notes on re-implementing some LLM models from scratch. It includes steps to pre-train a super mini LLaMA 3 model, implement LoRA from scratch using PyTorch, and work on implementing the 'generate' method.
LLaMa2lang
LLaMa2lang is a repository containing convenience scripts to finetune LLaMa3-8B (or any other foundation model) for chat towards any language that isn't English. The repository aims to improve the performance of LLaMa3 for non-English languages by combining fine-tuning with RAG. Users can translate datasets, extract threads, turn threads into prompts, and finetune models using QLoRA and PEFT. Additionally, the repository supports translation models like OPUS, M2M, MADLAD, and base datasets like OASST1 and OASST2. The process involves loading datasets, translating them, combining checkpoints, and running inference using the newly trained model. The repository also provides benchmarking scripts to choose the right translation model for a target language.

fastc
Fastc is a tool focused on CPU execution, using efficient models for embedding generation and cosine similarity classification. It allows for efficient multi-classifier execution without extra overhead. Users can easily train text classifiers, export models, publish to HuggingFace, load existing models, make class predictions, use instruct templates, and launch an inference server. The tool provides an HTTP API for text classification with JSON payloads and supports multiple languages for language identification.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.
Langchain-Projects-LLM
Langchain-Projects-LLM is a repository containing various projects utilizing Large Language Models such as GPT and LLAMA from HuggingFace and OpenAI. Users need the OpenAI API to run these models.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.
ChatPilot
ChatPilot is a chat agent tool that enables AgentChat conversations, supports Google search, URL conversation (RAG), and code interpreter functionality, replicates Kimi Chat (file, drag and drop; URL, send out), and supports OpenAI/Azure API. It is based on LangChain and implements ReAct and OpenAI Function Call for agent Q&A dialogue. The tool supports various automatic tools such as online search using Google Search API, URL parsing tool, Python code interpreter, and enhanced RAG file Q&A with query rewriting support. It also allows front-end and back-end service separation using Svelte and FastAPI, respectively. Additionally, it supports voice input/output, image generation, user management, permission control, and chat record import/export.
awesome-llm-unlearning
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
wechat-bot
WeChat Bot is a simple and easy-to-use WeChat robot based on chatgpt and wechaty. It can help you automatically reply to WeChat messages or manage WeChat groups/friends. The tool requires configuration of AI services such as Xunfei, Kimi, or ChatGPT. Users can customize the tool to automatically reply to group or private chat messages based on predefined conditions. The tool supports running in Docker for easy deployment and provides a convenient way to interact with various AI services for WeChat automation.
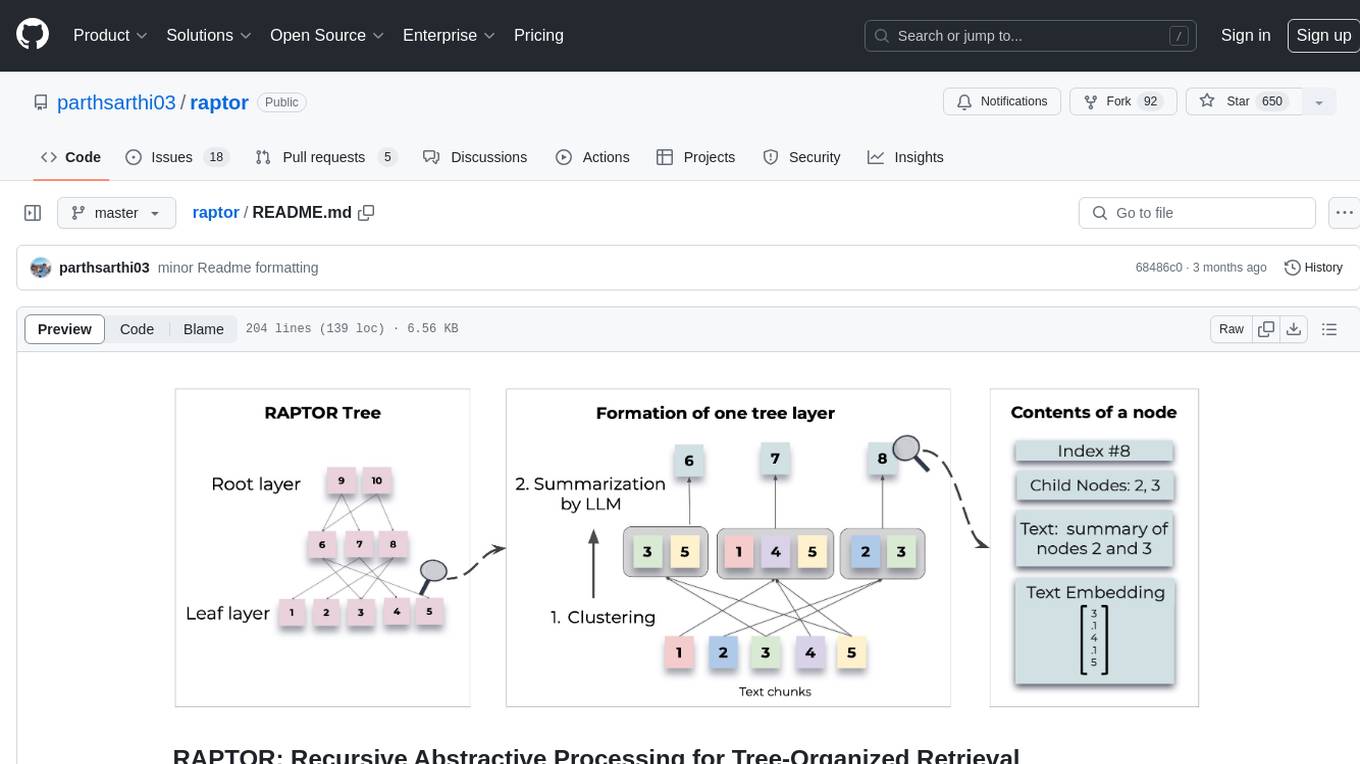
raptor
RAPTOR introduces a novel approach to retrieval-augmented language models by constructing a recursive tree structure from documents. This allows for more efficient and context-aware information retrieval across large texts, addressing common limitations in traditional language models. Users can add documents to the tree, answer questions based on indexed documents, save and load the tree, and extend RAPTOR with custom summarization, question-answering, and embedding models. The tool is designed to be flexible and customizable for various NLP tasks.
bonito
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.
ERNIE-SDK
ERNIE SDK repository contains two projects: ERNIE Bot Agent and ERNIE Bot. ERNIE Bot Agent is a large model intelligent agent development framework based on the Wenxin large model orchestration capability introduced by Baidu PaddlePaddle, combined with the rich preset platform functions of the PaddlePaddle Star River community. ERNIE Bot provides developers with convenient interfaces to easily call the Wenxin large model for text creation, general conversation, semantic vectors, and AI drawing basic functions.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.
langrila
Langrila is a library that provides an easy way to use API-based LLM (Large Language Models) with an emphasis on simple architecture for readability. It supports various AI models for chat and embedding tasks, as well as retrieval functionalities using Qdrant, Chroma, and Usearch. Langrila also includes modules for function calling, conversation memory management, and prompt templates. It enforces coding policies for simplicity, responsibility independence, and minimum module implementation. The library requires Python version 3.10 to 3.13 and additional dependencies like OpenAI, Gemini, Qdrant, Chroma, and Usearch for specific functionalities.
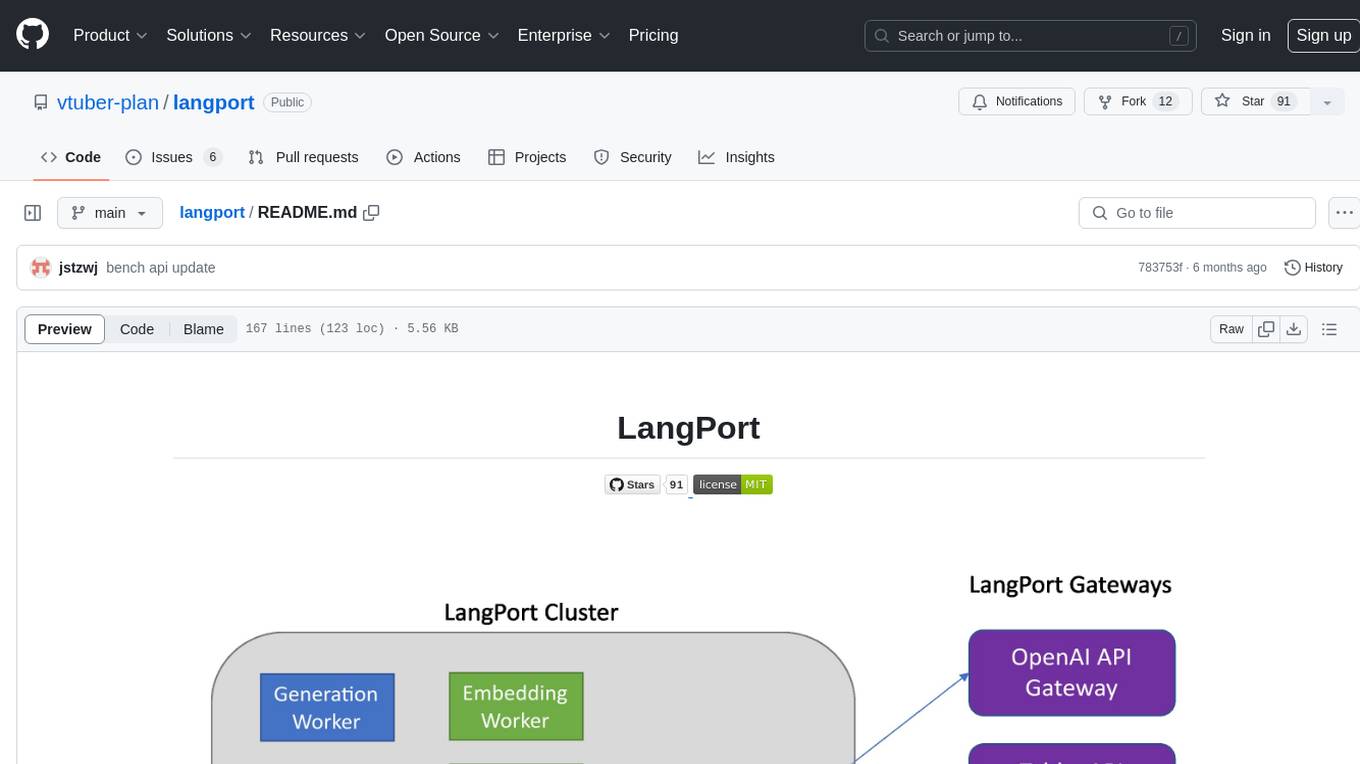
langport
LangPort is an open-source platform for serving large language models. It aims to provide a super fast LLM inference service with core features including Huggingface transformers support, distributed serving system, streaming generation, batch inference, and support for various model architectures. It offers compatibility with OpenAI, FauxPilot, HuggingFace, and Tabby APIs. The project supports model architectures like LLaMa, GLM, GPT2, and GPT Neo, and has been tested with models such as NingYu, Vicuna, ChatGLM, and WizardLM. LangPort also provides features like dynamic batch inference, int4 quantization, and generation logprobs parameter.
langchain-decoded
LangChain Decoded is an open-source framework designed to facilitate the development of applications utilizing large language models (LLMs). It can be applied to tasks such as chatbots, text summarization, data generation, code understanding, question answering, and evaluation. The framework consists of various modules like Models, Embeddings, Prompts, Indexes, Memory, Chains, Agents, and Callbacks, each explored in separate Python notebooks. Users can follow the blog post series to understand and utilize LangChain for their projects.
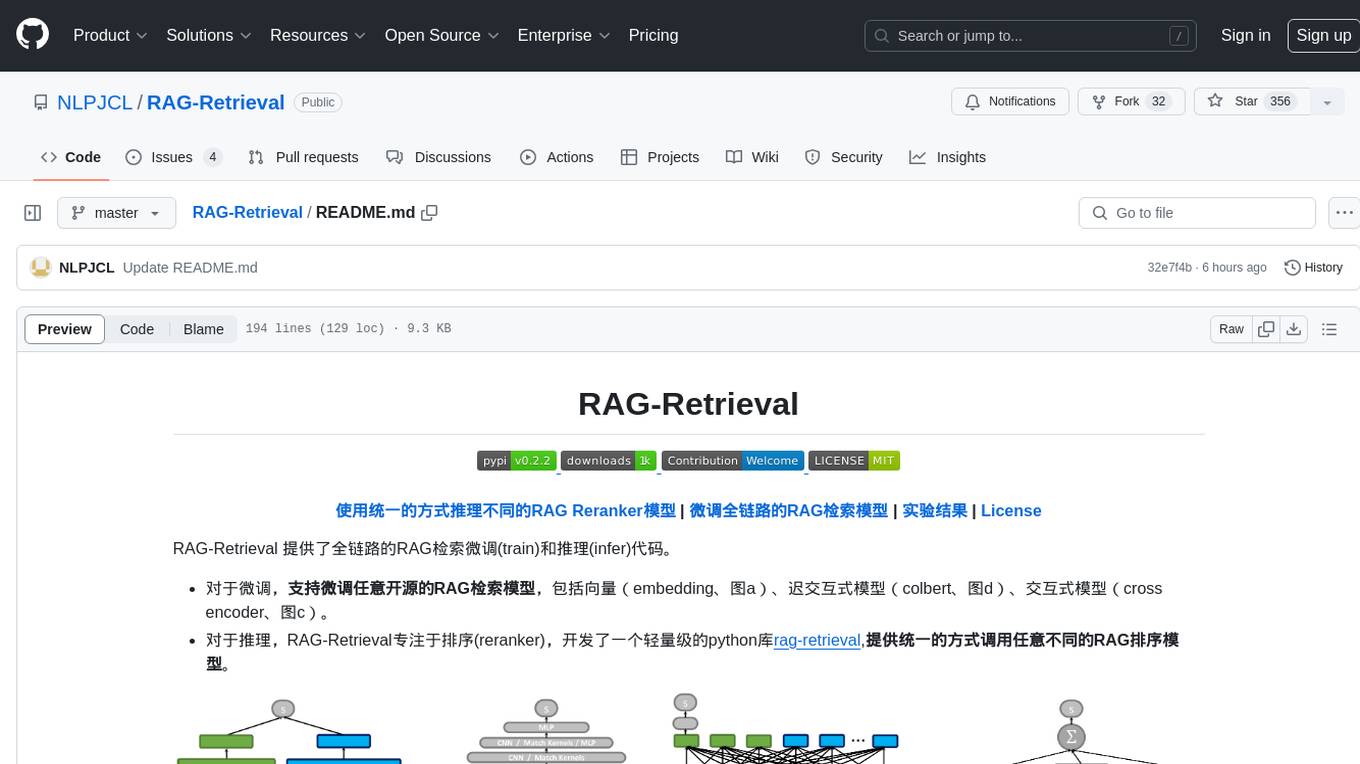
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
oreilly_live_training_llm_apps
This repository provides resources and notebooks for building text-based applications using the ChatGPT API and Langchain. It includes guides on prompt engineering, fine-tuning ChatGPT, using LangChain, and creating applications like a quiz generator and notes summarizer. The repository aims to help users understand and implement various natural language processing tasks with pre-trained language models.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
shared_colab_notebooks
This repository serves as a collection of Google Colaboratory Notebooks for various tasks in Natural Language Processing (NLP), Natural Language Generation (NLG), Computer Vision, Generative Adversarial Networks (GANs), Streamlit applications, tutorials, UI/UX experiments, and other miscellaneous projects. It includes a wide range of pre-trained models, fine-tuning examples, and demos for tasks such as text generation, image processing, and more. The notebooks cover topics like self-attention, language model finetuning, emotion detection, image inpainting, and streamlit app creation. Users can explore different models, datasets, and techniques through these shared notebooks.
whatsapp-chatgpt
This repository contains a WhatsApp bot that utilizes OpenAI's GPT and DALL-E 2 to respond to user inputs. Users can interact with the bot through voice messages, which are transcribed and responded to. The bot requires Node.js, npm, an OpenAI API key, and a WhatsApp account. It uses Puppeteer to run a real instance of Whatsapp Web to avoid being blocked. However, there is a risk of being blocked by WhatsApp as it does not allow bots or unofficial clients on its platform. The bot is not free to use, and users will be charged by OpenAI for each request made.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.
ChatPDF
ChatPDF is a knowledge question and answer retrieval tool based on local LLM. It supports various open-source LLM models like ChatGLM3-6b, Chinese-LLaMA-Alpaca-2, Baichuan, YI, and multiple file formats including PDF, docx, markdown, txt. The tool optimizes RAG accuracy, Chinese chunk segmentation, embedding using text2vec's sentence embedding, retrieval matching with rank_BM25, and introduces reranker module for reranking candidate sets. It also enhances candidate chunk extension context, supports custom RAG models, and provides a Gradio-based RAG conversation page for seamless dialogue.
UnionLLM
UnionLLM is a lightweight open-source Python toolkit that provides a unified way to access various domestic and foreign large language models and Agent orchestration tools compatible with OpenAI. It aims to connect various large language models in a unified and easily extensible way, making it more convenient to use multiple large language models. UnionLLM currently supports various domestic large language models and Agent orchestration tools, as well as over 100 models through LiteLLM, including models from major overseas language model developers and cloud service providers. It simplifies the process of calling different models by providing a consistent interface and expanding the returned information to include context for knowledge base retrieval.
Prompt4ReasoningPapers
Prompt4ReasoningPapers is a repository dedicated to reasoning with language model prompting. It provides a comprehensive survey of cutting-edge research on reasoning abilities with language models. The repository includes papers, methods, analysis, resources, and tools related to reasoning tasks. It aims to support various real-world applications such as medical diagnosis, negotiation, etc.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.
EasyLM
EasyLM is a one-stop solution for pre-training, fine-tuning, evaluating, and serving large language models in JAX/Flax. It simplifies the process by leveraging JAX's pjit functionality to scale up training to multiple TPU/GPU accelerators. Built on top of Huggingface's transformers and datasets, EasyLM offers an easy-to-use and customizable codebase for training large language models without the complexity found in other frameworks. It supports sharding model weights and training data across multiple accelerators, enabling multi-TPU/GPU training on a single host or across multiple hosts on Google Cloud TPU Pods. EasyLM currently supports models like LLaMA, LLaMA 2, and LLaMA 3.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.
awesome-khmer-language
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.
SuperAdapters
SuperAdapters is a tool designed to finetune Large Language Models (LLMs) with various adapters on different platforms. It supports models like Bloom, LLaMA, ChatGLM, Qwen, Baichuan, Mixtral, Phi, and more. Users can finetune LLMs on Windows, Linux, and Mac M1/2, handle train/test data with Terminal, File, or DataBase, and perform tasks like CausalLM and SequenceClassification. The tool provides detailed instructions on how to use different models with specific adapters for tasks like finetuning and inference. It also includes requirements for CentOS, Ubuntu, and MacOS, along with information on LLM downloads and data formats. Additionally, it offers parameters for finetuning and inference, as well as options for web and API-based inference.
IntelliQ
IntelliQ is an open-source project aimed at providing a multi-turn question-answering system based on a large language model (LLM). The system combines advanced intent recognition and slot filling technology to enhance the depth of understanding and accuracy of responses in conversation systems. It offers a flexible and efficient solution for developers to build and optimize various conversational applications. The system features multi-turn dialogue management, intent recognition, slot filling, interface slot technology for real-time data retrieval and processing, adaptive learning for improving response accuracy and speed, and easy integration with detailed API documentation supporting multiple programming languages and platforms.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.
step_into_llm
The 'step_into_llm' repository is dedicated to the 昇思MindSpore technology open class, which focuses on exploring cutting-edge technologies, combining theory with practical applications, expert interpretations, open sharing, and empowering competitions. The repository contains course materials, including slides and code, for the ongoing second phase of the course. It covers various topics related to large language models (LLMs) such as Transformer, BERT, GPT, GPT2, and more. The course aims to guide developers interested in LLMs from theory to practical implementation, with a special emphasis on the development and application of large models.
chatgpt-webui
ChatGPT WebUI is a user-friendly web graphical interface for various LLMs like ChatGPT, providing simplified features such as core ChatGPT conversation and document retrieval dialogues. It has been optimized for better RAG retrieval accuracy and supports various search engines. Users can deploy local language models easily and interact with different LLMs like GPT-4, Azure OpenAI, and more. The tool offers powerful functionalities like GPT4 API configuration, system prompt setup for role-playing, and basic conversation features. It also provides a history of conversations, customization options, and a seamless user experience with themes, dark mode, and PWA installation support.
llm-playground
llm-playground is a repository for experimenting with Llama2, a language model. Users can download the Ollama tool and fetch different Llama2 models to conduct experiments and tests. The repository is maintained by a 10x-React-Engineer.
build_MiniLLM_from_scratch
This repository aims to build a low-parameter LLM model through pretraining, fine-tuning, model rewarding, and reinforcement learning stages to create a chat model capable of simple conversation tasks. It features using the bert4torch training framework, seamless integration with transformers package for inference, optimized file reading during training to reduce memory usage, providing complete training logs for reproducibility, and the ability to customize robot attributes. The chat model supports multi-turn conversations. The trained model currently only supports basic chat functionality due to limitations in corpus size, model scale, SFT corpus size, and quality.
matmulfreellm
MatMul-Free LM is a language model architecture that eliminates the need for Matrix Multiplication (MatMul) operations. This repository provides an implementation of MatMul-Free LM that is compatible with the 🤗 Transformers library. It evaluates how the scaling law fits to different parameter models and compares the efficiency of the architecture in leveraging additional compute to improve performance. The repo includes pre-trained models, model implementations compatible with 🤗 Transformers library, and generation examples for text using the 🤗 text generation APIs.
nlp-zero-to-hero
This repository provides a comprehensive guide to Natural Language Processing (NLP), covering topics from Tokenization to Transformer Architecture. It aims to equip users with a solid understanding of NLP concepts, evolution, and core intuition. The repository includes practical examples and hands-on experience to facilitate learning and exploration in the field of NLP.
awesome-llm-courses
Awesome LLM Courses is a curated list of online courses focused on Large Language Models (LLMs). The repository aims to provide a comprehensive collection of free available courses covering various aspects of LLMs, including fundamentals, engineering, and applications. The courses are suitable for individuals interested in natural language processing, AI development, and machine learning. The list includes courses from reputable platforms such as Hugging Face, Udacity, DeepLearning.AI, Cohere, DataCamp, and more, offering a wide range of topics from pretraining LLMs to building AI applications with LLMs. Whether you are a beginner looking to understand the basics of LLMs or an intermediate developer interested in advanced topics like prompt engineering and generative AI, this repository has something for everyone.
ragoon
RAGoon is a high-level library designed for batched embeddings generation, fast web-based RAG (Retrieval-Augmented Generation) processing, and quantized indexes processing. It provides NLP utilities for multi-model embedding production, high-dimensional vector visualization, and enhancing language model performance through search-based querying, web scraping, and data augmentation techniques.
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
END-TO-END-GENERATIVE-AI-PROJECTS
The 'END TO END GENERATIVE AI PROJECTS' repository is a collection of awesome industry projects utilizing Large Language Models (LLM) for various tasks such as chat applications with PDFs, image to speech generation, video transcribing and summarizing, resume tracking, text to SQL conversion, invoice extraction, medical chatbot, financial stock analysis, and more. The projects showcase the deployment of LLM models like Google Gemini Pro, HuggingFace Models, OpenAI GPT, and technologies such as Langchain, Streamlit, LLaMA2, LLaMAindex, and more. The repository aims to provide end-to-end solutions for different AI applications.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.
AI-Competition-Collections
AI-Competition-Collections is a repository that collects and curates various experiences and tips from AI competitions. It includes posts on competition experiences in computer vision, NLP, speech, and other AI-related fields. The repository aims to provide valuable insights and techniques for individuals participating in AI competitions, covering topics such as image classification, object detection, OCR, adversarial attacks, and more.
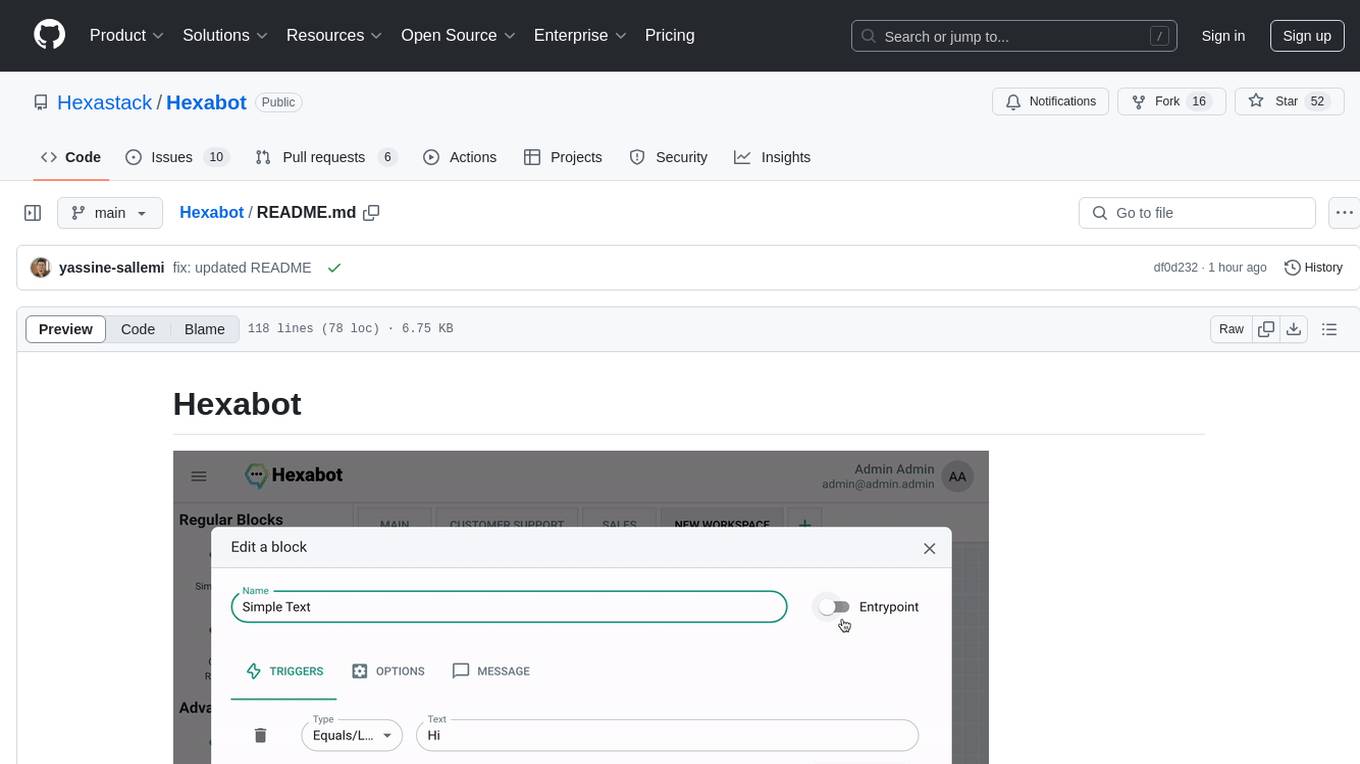
Hexabot
Hexabot Community Edition is an open-source chatbot solution designed for flexibility and customization, offering powerful text-to-action capabilities. It allows users to create and manage AI-powered, multi-channel, and multilingual chatbots with ease. The platform features an analytics dashboard, multi-channel support, visual editor, plugin system, NLP/NLU management, multi-lingual support, CMS integration, user roles & permissions, contextual data, subscribers & labels, and inbox & handover functionalities. The directory structure includes frontend, API, widget, NLU, and docker components. Prerequisites for running Hexabot include Docker and Node.js. The installation process involves cloning the repository, setting up the environment, and running the application. Users can access the UI admin panel and live chat widget for interaction. Various commands are available for managing the Docker services. Detailed documentation and contribution guidelines are provided for users interested in contributing to the project.
GenAI_Agents
GenAI Agents is a comprehensive repository for developing and implementing Generative AI (GenAI) agents, ranging from simple conversational bots to complex multi-agent systems. It serves as a valuable resource for learning, building, and sharing GenAI agents, offering tutorials, implementations, and a platform for showcasing innovative agent creations. The repository covers a wide range of agent architectures and applications, providing step-by-step tutorials, ready-to-use implementations, and regular updates on advancements in GenAI technology.
Hands-On-LLM-Applications-Development
Hands-On-LLM-Applications-Development is a repository focused on developing applications using Large Language Models (LLMs). The repository provides hands-on tutorials, guides, and resources for building various applications such as LangChain for LLM applications, Retrieval Augmented Generation (RAG) with LangChain, building LLM agents with LangGraph, and advanced LangChain with OpenAI. It covers topics like prompt engineering for LLMs, building applications using HuggingFace open-source models, LLM fine-tuning, and advanced RAG applications.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
azure-openai-samples
This repository provides resources to understand and utilize GPT (Generative Pre-trained Transformer) by Azure OpenAI. It includes sample solutions, use cases, and quick start guides. Users can explore various applications of GPT, such as chatbots, customer service, and content generation. The repository also offers Langchain, Semantic Kernel, and Prompt Flow samples, along with Serverless SQL GPT for natural language processing in Azure Synapse Analytics. The samples are based on GPT 3.5, with plans to update for GPT-4. Users are encouraged to contribute to keep the repository updated with the latest technologies and solutions.
intro-llm.github.io
Large Language Models (LLM) are language models built by deep neural networks containing hundreds of billions of weights, trained on a large amount of unlabeled text using self-supervised learning methods. Since 2018, companies and research institutions including Google, OpenAI, Meta, Baidu, and Huawei have released various models such as BERT, GPT, etc., which have performed well in almost all natural language processing tasks. Starting in 2021, large models have shown explosive growth, especially after the release of ChatGPT in November 2022, attracting worldwide attention. Users can interact with systems using natural language to achieve various tasks from understanding to generation, including question answering, classification, summarization, translation, and chat. Large language models demonstrate powerful knowledge of the world and understanding of language. This repository introduces the basic theory of large language models including language models, distributed model training, and reinforcement learning, and uses the Deepspeed-Chat framework as an example to introduce the implementation of large language models and ChatGPT-like systems.
evaluation-guidebook
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
LLM-Drop
LLM-Drop is an official implementation of the paper 'What Matters in Transformers? Not All Attention is Needed'. The tool investigates redundancy in transformer-based Large Language Models (LLMs) by analyzing the architecture of Blocks, Attention layers, and MLP layers. It reveals that dropping certain Attention layers can enhance computational and memory efficiency without compromising performance. The tool provides a pipeline for Block Drop and Layer Drop based on LLaMA-Factory, and implements quantization using AutoAWQ and AutoGPTQ.
bookmark-summary
The 'bookmark-summary' repository reads bookmarks from 'bookmark-collection', extracts text content using Jina Reader, and then summarizes the text using LLM. The detailed implementation can be found in 'process_changes.py'. It needs to be used together with the Github Action in 'bookmark-collection'.
BlueLM
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.
LLMLanding
LLMLanding is a repository focused on practical implementation of large models, covering topics from theory to practice. It provides a structured learning path for training large models, including specific tasks like training 1B-scale models, exploring SFT, and working on specialized tasks such as code generation, NLP tasks, and domain-specific fine-tuning. The repository emphasizes a dual learning approach: quickly applying existing tools for immediate output benefits and delving into foundational concepts for long-term understanding. It offers detailed resources and pathways for in-depth learning based on individual preferences and goals, combining theory with practical application to avoid overwhelm and ensure sustained learning progress.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.
reflex-llm-examples
A curated repository of AI Apps showcasing practical use cases of Large Language Models (LLMs) from various providers like Google, Anthropic, Open AI, and self-hosted open-source models. The collection features AI agents, RAG (Retrieval-Augmented Generation) implementations, and best practices for building scalable AI-powered solutions.
LMCache
LMCache is a serving engine extension designed to reduce time to first token (TTFT) and increase throughput, particularly in long-context scenarios. It stores key-value caches of reusable texts across different locations like GPU, CPU DRAM, and Local Disk, allowing the reuse of any text in any serving engine instance. By combining LMCache with vLLM, significant delay savings and GPU cycle reduction are achieved in various large language model (LLM) use cases, such as multi-round question answering and retrieval-augmented generation (RAG). LMCache provides integration with the latest vLLM version, offering both online serving and offline inference capabilities. It supports sharing key-value caches across multiple vLLM instances and aims to provide stable support for non-prefix key-value caches along with user and developer documentation.
PrefixQuant
PrefixQuant is an official PyTorch implementation for static quantization that outperforms dynamic quantization in Large Language Models (LLMs) by utilizing prefixed outliers. The tool provides functionalities for quantization, inference, and visualization of activation distributions. Users can fine-tune quantization settings and evaluate pre-quantized models for tasks like PIQA, ARC, Hellaswag, and Winogrande. The approach aims to improve performance and efficiency in LLMs through innovative quantization techniques.
LLMs-Zero-to-Hero
LLMs-Zero-to-Hero is a repository dedicated to training large language models (LLMs) from scratch, covering topics such as dense models, MOE models, pre-training, supervised fine-tuning, direct preference optimization, reinforcement learning from human feedback, and deploying large models. The repository provides detailed learning notes for different chapters, code implementations, and resources for training and deploying LLMs. It aims to guide users from being beginners to proficient in building and deploying large language models.
YesImBot
YesImBot, also known as Athena, is a Koishi plugin designed to allow large AI models to participate in group chat discussions. It offers easy customization of the bot's name, personality, emotions, and other messages. The plugin supports load balancing multiple API interfaces for large models, provides immersive context awareness, blocks potentially harmful messages, and automatically fetches high-quality prompts. Users can adjust various settings for the bot and customize system prompt words. The ultimate goal is to seamlessly integrate the bot into group chats without detection, with ongoing improvements and features like message recognition, emoji sending, multimodal image support, and more.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Task Decomposition, RAG, etc. It aims to be the framework used by LLMs, focusing on stripping away low-level implementation details and emphasizing high-level programming paradigms. Pocket Flow serves as a learning resource and provides a core abstraction of a nested directed graph for breaking down tasks into multiple steps.
llama-cookbook
The Llama Cookbook is the official guide for building with Llama Models, providing resources for inference, fine-tuning, and end-to-end use-cases of Llama Text and Vision models. The repository includes popular community approaches, use-cases, and recipes for working with Llama models. It covers topics such as multimodal inference, inferencing using Llama Guard, and specific tasks like Email Agent and Text to SQL. The structure includes sections for 3P Integrations, End to End Use Cases, Getting Started guides, and the source code for the original llama-recipes library.
RAGMeUp
RAG Me Up is a generic framework that enables users to perform Retrieve, Answer, Generate (RAG) on their own dataset easily. It consists of a small server and UIs for communication. The tool can run on CPU but is optimized for GPUs with at least 16GB of vRAM. Users can combine RAG with fine-tuning using the LLaMa2Lang repository. The tool provides a configurable RAG pipeline without the need for coding, utilizing indexing and inference steps to accurately answer user queries.
RAG_Techniques
Advanced RAG Techniques is a comprehensive collection of cutting-edge Retrieval-Augmented Generation (RAG) tutorials aimed at enhancing the accuracy, efficiency, and contextual richness of RAG systems. The repository serves as a hub for state-of-the-art RAG enhancements, comprehensive documentation, practical implementation guidelines, and regular updates with the latest advancements. It covers a wide range of techniques from foundational RAG methods to advanced retrieval methods, iterative and adaptive techniques, evaluation processes, explainability and transparency features, and advanced architectures integrating knowledge graphs and recursive processing.
xgen
XGen is a research release for the family of XGen models (7B) by Salesforce AI Research. It includes models with support for different sequence lengths and tokenization using the OpenAI Tiktoken package. The models can be used for auto-regressive sampling in natural language generation tasks.
UniChat
UniChat is a pipeline tool for creating online and offline chat-bots in Unity. It leverages Unity.Sentis and text vector embedding technology to enable offline mode text content search based on vector databases. The tool includes a chain toolkit for embedding LLM and Agent in games, along with middleware components for Text to Speech, Speech to Text, and Sub-classifier functionalities. UniChat also offers a tool for invoking tools based on ReActAgent workflow, allowing users to create personalized chat scenarios and character cards. The tool provides a comprehensive solution for designing flexible conversations in games while maintaining developer's ideas.
Qbot
Qbot is an open-source project designed to help users quickly build their own QQ chatbot. The bot deployed using this project has various capabilities, including intelligent sentence segmentation, intent recognition, voice and drawing replies, autonomous selection of when to play local music, and decision-making on sending emojis. Qbot leverages other open-source projects and allows users to customize triggers, system prompts, chat models, and more through configuration files. Users can modify the Qbot.py source code to tailor the bot's behavior. The project requires NTQQ and LLonebot's NTQQ plugin for deployment, along with additional configurations for triggers, system prompts, and chat models. Users can start the bot by running Qbot.py after installing necessary libraries and ensuring the NTQQ is running. Qbot also supports features like sending music from the data/smusic folder and emojis based on emotions. Local voice synthesis can be deployed for voice outputs. Qbot provides commands like #reset to clear short-term memory and addresses common issues like program crashes due to encoding format, message sending/receiving failures, voice synthesis failures, and connection issues. Users are encouraged to give the project a star if they find it useful.
KG-LLM-MDQA
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.
scaling-book
The 'scaling-book' repository contains a book that aims to demystify the art of scaling Large Language Models (LLMs) on Tensor Processing Units (TPUs). It explains how TPUs work, how LLMs run at scale, and how to choose parallelism schemes to avoid communication bottlenecks during training and inference. The book provides insights and guidance on scaling models effectively for improved performance.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.
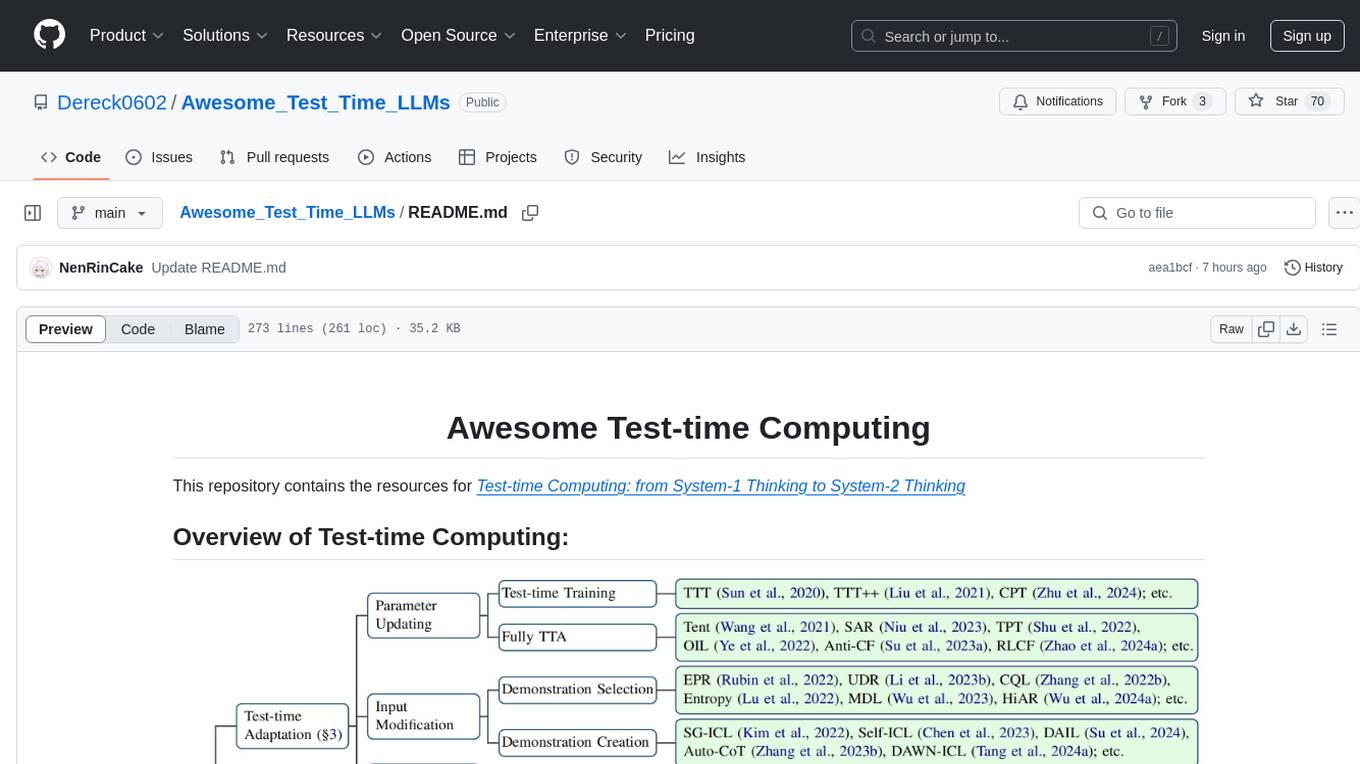
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
Awesome-LLM-Resources-List
Awesome LLM Resources is a curated collection of resources for Large Language Models (LLMs) covering various aspects such as serverless hosting, accessing off-the-shelf models via API, local inference, LLM serving frameworks, open-source LLM web chat UIs, renting GPUs for fine-tuning, fine-tuning with no-code UI, fine-tuning frameworks, OS agentic/AI workflow, AI agents, co-pilots, voice API, open-source TTS models, OS RAG frameworks, research papers on chain-of-thought prompting, CoT implementations, CoT fine-tuned models & datasets, and more.
Rankify
Rankify is a Python toolkit designed for unified retrieval, re-ranking, and retrieval-augmented generation (RAG) research. It integrates 40 pre-retrieved benchmark datasets and supports 7 retrieval techniques, 24 state-of-the-art re-ranking models, and multiple RAG methods. Rankify provides a modular and extensible framework, enabling seamless experimentation and benchmarking across retrieval pipelines. It offers comprehensive documentation, open-source implementation, and pre-built evaluation tools, making it a powerful resource for researchers and practitioners in the field.
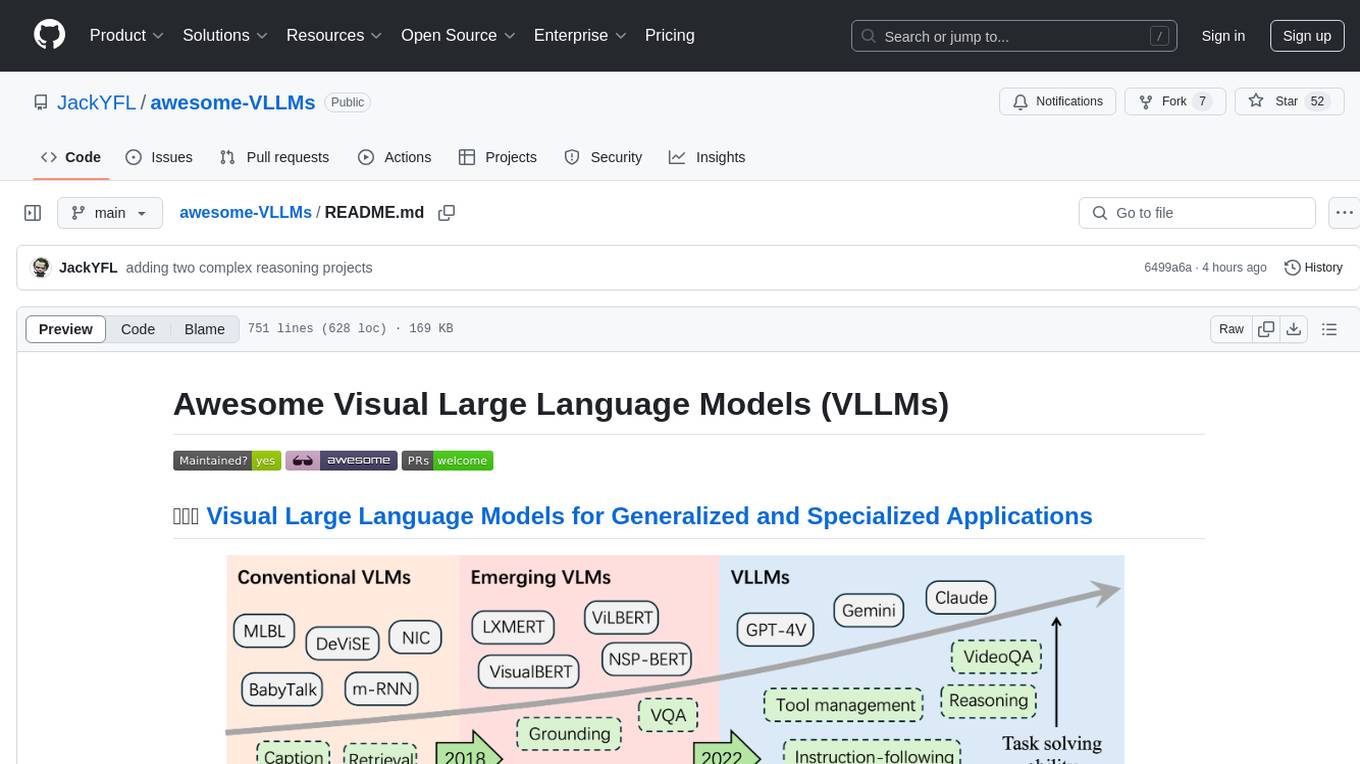
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.
hayhooks
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.
ping_pong_bench
PingPong is a benchmark designed for role-playing language models, focusing on evaluating conversational abilities through interactions with characters and test situations. The benchmark uses LLMs to emulate users in role-playing conversations, assessing criteria such as character portrayal, entertainment value, and fluency. Users can engage in dialogues with specific characters, like Kurisu, and evaluate the bot's responses based on predefined criteria. PingPong aims to provide a comprehensive evaluation method for language models, moving beyond single-turn interactions to more complex conversational scenarios.
MaiMBot
MaiMBot is an intelligent QQ group chat bot based on a large language model. It is developed using the nonebot2 framework, utilizes LLM for conversation abilities, MongoDB for data persistence, and NapCat for QQ protocol support. The bot features keyword-triggered proactive responses, dynamic prompt construction, support for images and message forwarding, typo generation, multiple replies, emotion-based emoji responses, daily schedule generation, user relationship management, knowledge base, and group impressions. Work-in-progress features include personality, group atmosphere, image handling, humor, meme functions, and Minecraft interactions. The tool is in active development with plans for GIF compatibility, mini-program link parsing, bug fixes, documentation improvements, and logic enhancements for emoji sending.
chatlas
Chatlas is a Python tool that provides a simple and unified interface across various large language model providers. It helps users prototype faster by abstracting complexity from tasks like streaming chat interfaces, tool calling, and structured output. Users can easily switch providers by changing one line of code and access provider-specific features when needed. Chatlas focuses on developer experience with typing support, rich console output, and extension points.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.
judges
The 'judges' repository is a small library designed for using and creating LLM-as-a-Judge evaluators. It offers a curated set of LLM evaluators in a low-friction format for various use cases, backed by research. Users can use these evaluators off-the-shelf or as inspiration for building custom LLM evaluators. The library provides two types of judges: Classifiers that return boolean values and Graders that return scores on a numerical or Likert scale. Users can combine multiple judges using the 'Jury' object and evaluate input-output pairs with the '.judge()' method. Additionally, the repository includes detailed instructions on picking a model, sending data to an LLM, using classifiers, combining judges, and creating custom LLM judges with 'AutoJudge'.
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.
data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.
llm-resources
llm-resources is a repository providing resources to get started with Large Language Models (LLMs). It includes videos on Neural Networks and LLMs, free courses, prompt engineering guides, explored frameworks, AI assistants, and tips on making RAG work properly. The repository also contains important links and updates related to LLMs, AWS, RAG, agents, model context protocol, and more. It aims to help individuals with a basic understanding of NLP and programming knowledge to explore and utilize LLMs effectively.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
foundations-of-gen-ai
This repository contains code for the O'Reilly Live Online Training for 'Transformer Architectures for Generative AI'. The course provides a deep understanding of transformer architectures and their impact on natural language processing (NLP) and vision tasks. Participants learn to harness transformers to tackle problems in text, image, and multimodal AI through theory and practical exercises.
graph-llm-asynchow-plan
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning is a repository containing code and datasets for the ICML-2024 paper. It includes naturalistic datasets, code for generating data, benchmarking experiments, and prototypical experiments. The repository also offers a train/test-split version of the dataset on huggingface. The paper focuses on utilizing large language models with graph enhancements for asynchronous plan reasoning.
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.

AstrBot
AstrBot is an open-source one-stop Agentic chatbot platform and development framework. It supports large model conversations, multiple messaging platforms, Agent capabilities, plugin extensions, and WebUI for visual configuration and management of the chatbot.
go-embeddings
This project provides API clients for fetching embeddings from various LLM providers. It includes implementations for OpenAI, Cohere, Google Vertex, VoyageAI, Ollama, and AWS Bedrock. Sample programs demonstrate how to use the client packages. The 'document' package offers text splitters inspired by Langchain framework. Environment variables are used to initialize API clients for each provider. Contributions are welcome.
self-learn-llms
Self Learn LLMs is a repository containing resources for self-learning about Large Language Models. It includes theoretical and practical hands-on resources to facilitate learning. The repository aims to provide a clear roadmap with milestones for proper understanding of LLMs. The owner plans to refactor the repository to remove irrelevant content, organize model zoo better, and enhance the learning experience by adding contributors and hosting notes, tutorials, and open discussions.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.
dspy.rb
DSPy.rb is a Ruby framework for building reliable LLM applications using composable, type-safe modules. It enables developers to define typed signatures and compose them into pipelines, offering a more structured approach compared to traditional prompting. The framework embraces Ruby conventions and adds innovations like CodeAct agents and enhanced production instrumentation, resulting in scalable LLM applications that are robust and efficient. DSPy.rb is actively developed, with a focus on stability and real-world feedback through the 0.x series before reaching a stable v1.0 API.
llmgateway
The llmgateway repository is a tool that provides a gateway for interacting with various LLM (Large Language Model) models. It allows users to easily access and utilize pre-trained language models for tasks such as text generation, sentiment analysis, and language translation. The tool simplifies the process of integrating LLMs into applications and workflows, enabling developers to leverage the power of state-of-the-art language models for various natural language processing tasks.

notebooks
The 'notebooks' repository contains a collection of fine-tuning notebooks for various models, including Gemma3N, Qwen3, Llama 3.2, Phi-4, Mistral v0.3, and more. These notebooks are designed for tasks such as data preparation, model training, evaluation, and model saving. Users can access guided notebooks for different types of models like Conversational, Vision, TTS, GRPO, and more. The repository also includes specific use-case notebooks for tasks like text classification, tool calling, multiple datasets, KTO, inference chat UI, conversational tasks, chatML, and text completion.
AI6127
AI6127 is a course focusing on deep neural networks for natural language processing (NLP). It covers core NLP tasks and machine learning models, emphasizing deep learning methods using libraries like Pytorch. The course aims to teach students state-of-the-art techniques for practical NLP problems, including writing, debugging, and training deep neural models. It also explores advancements in NLP such as Transformers and ChatGPT.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
sgr-deep-research
This repository contains a deep learning research project focused on natural language processing tasks. It includes implementations of various state-of-the-art models and algorithms for text classification, sentiment analysis, named entity recognition, and more. The project aims to provide a comprehensive resource for researchers and developers interested in exploring deep learning techniques for NLP applications.
npcpy
npcpy is a core library of the NPC Toolkit that enhances natural language processing pipelines and agent tooling. It provides a flexible framework for building applications and conducting research with LLMs. The tool supports various functionalities such as getting responses for agents, setting up agent teams, orchestrating jinx workflows, obtaining LLM responses, generating images, videos, audio, and more. It also includes a Flask server for deploying NPC teams, supports LiteLLM integration, and simplifies the development of NLP-based applications. The tool is versatile, supporting multiple models and providers, and offers a graphical user interface through NPC Studio and a command-line interface via NPC Shell.
Awesome-RL-for-LRMs
This repository contains a collection of awesome resources for reinforcement learning in language models. It includes tutorials, code implementations, research papers, and tools to help researchers and practitioners explore and apply reinforcement learning techniques in natural language processing tasks. Whether you are a beginner or an expert in the field, this repository aims to provide valuable insights and guidance to enhance your understanding and implementation of reinforcement learning in language models.
LangBot
LangBot is an open-source large language model native instant messaging robot development platform, aiming to provide a plug-and-play IM robot development experience, with various LLM application functions such as Agent, RAG, MCP, adapting to mainstream instant messaging platforms globally, and providing rich API interfaces to support custom development.
ctakes
Apache cTAKES is a clinical Text Analysis and Knowledge Extraction System that focuses on extracting knowledge from clinical text through Natural Language Processing (NLP) techniques. It is modular and employs rule-based and machine learning methods to extract concepts such as symptoms, procedures, diagnoses, medications, and anatomy with attributes and standard codes. cTAKES can identify temporal events, dates, and times, placing events in a patient timeline. It supports various biomedical text processing tasks and can handle different types of clinical and health-related narratives using multiple data standards. cTAKES is widely used in research initiatives and encourages contributions from professionals, researchers, doctors, and students from diverse backgrounds.
achatbot
achatbot is a factory tool that allows users to create chat bots with various functionalities such as llm (language models), asr (automatic speech recognition), tts (text-to-speech), vad (voice activity detection), ocr (optical character recognition), and object detection. The tool provides a structured project with features like chat bots for cmd, grpc, and http servers. It supports various chat bot processors, transport connectors, and AI modules for different tasks. Users can run chat bots locally or deploy them on cloud services like vercel, Cloudflare, AWS Lambda, or Docker. The tool also includes UI components for easy deployment and service architecture diagrams for reference.
bellman
Bellman is a unified interface to interact with language and embedding models, supporting various vendors like VertexAI/Gemini, OpenAI, Anthropic, VoyageAI, and Ollama. It consists of a library for direct interaction with models and a service 'bellmand' for proxying requests with one API key. Bellman simplifies switching between models, vendors, and common tasks like chat, structured data, tools, and binary input. It addresses the lack of official SDKs for major players and differences in APIs, providing a single proxy for handling different models. The library offers clients for different vendors implementing common interfaces for generating and embedding text, enabling easy interchangeability between models.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.
underthesea
Underthesea is an open-source Vietnamese Natural Language Processing toolkit that provides easy API access to pretrained NLP models for tasks such as word segmentation, part-of-speech tagging, named entity recognition, text classification, and dependency parsing. The toolkit also includes features like Conversational AI Agent for chatting with an AI assistant specialized in Vietnamese NLP. It supports various Python versions and offers tutorials for different NLP tasks like sentence segmentation, text normalization, tagging, classification, sentiment analysis, named entity recognition, language detection, translation, and text-to-speech conversion. Additionally, it provides resources for Vietnamese NLP datasets and upcoming features include Automatic Speech Recognition.
MinivLLM
A custom implementation of vLLM inference engine with attention mechanism benchmarks, based on Nano-vLLM but with self-contained paged attention and flash attention implementation. It provides benchmarking on flash attention in prefilling time and paged attention in decoding time. The tool showcases how the custom vLLM implementation handles batched text generation with memory-efficient attention.
LLM
LLM is a repository focused on providing educational courses on artificial intelligence models, specifically focusing on language and image understanding. The courses are taught by Alireza Akhavan Pour and cover topics such as generative AI models and language-image understanding. The repository also includes information on how to contact the team through Telegram channels for course updates and Q&A sessions. Participants are encouraged to add their LLM or VLM course certificates to their LinkedIn profiles and tag Alireza Akhavan Pour for recognition and resume enhancement.
Evaluator
NeMo Evaluator SDK is an open-source platform for robust, reproducible, and scalable evaluation of Large Language Models. It enables running hundreds of benchmarks across popular evaluation harnesses against any OpenAI-compatible model API. The platform ensures auditable and trustworthy results by executing evaluations in open-source Docker containers. NeMo Evaluator SDK is built on four core principles: Reproducibility by Default, Scale Anywhere, State-of-the-Art Benchmarking, and Extensible and Customizable.
oreilly_live_training_agents
This repository provides resources and notebooks for O'Reilly Live Training on getting started with LLM Agents using LangChain & LangGraph. It includes setup instructions, core learning paths, additional topics, repository structure, and additional resources for learning and deploying LangGraph agents.
20 - OpenAI Gpts
ReDev You v00400
Specialist in belief transformation using advanced NLP and visualization, now more powerful with a two-component structure.

AI Expert for Manual Creation
This prompt acts as an expert in AI and a specific field, designing educational and attractive manuals for a defined audience. He specializes in integrating advanced knowledge and NLP techniques to generate high-quality content.
Life Changer
Your guide for swift, impactful life changes via subconscious reprogramming - leveraging top NLP methods.

Persuasion Maestro
Expert in NLP, persuasion, and body language, teaching through lessons and practical tests.
💹 AI Trading Sentiment Surge
AI Trading Sentiment Surge - Dive into market trends with AI-powered sentiment analysis and NLP to guide investment strategies. 🌐📊🤖

Dr. Mind
Your personal psychological counsellor in all languages: Listening to your feelings and thoughts
Hero's GPT
Your AI ally for insightful guidance, emotional support, and personalized decision-making assistance.