
bonito
A lightweight library for generating synthetic instruction tuning datasets for your data without GPT.
Stars: 742
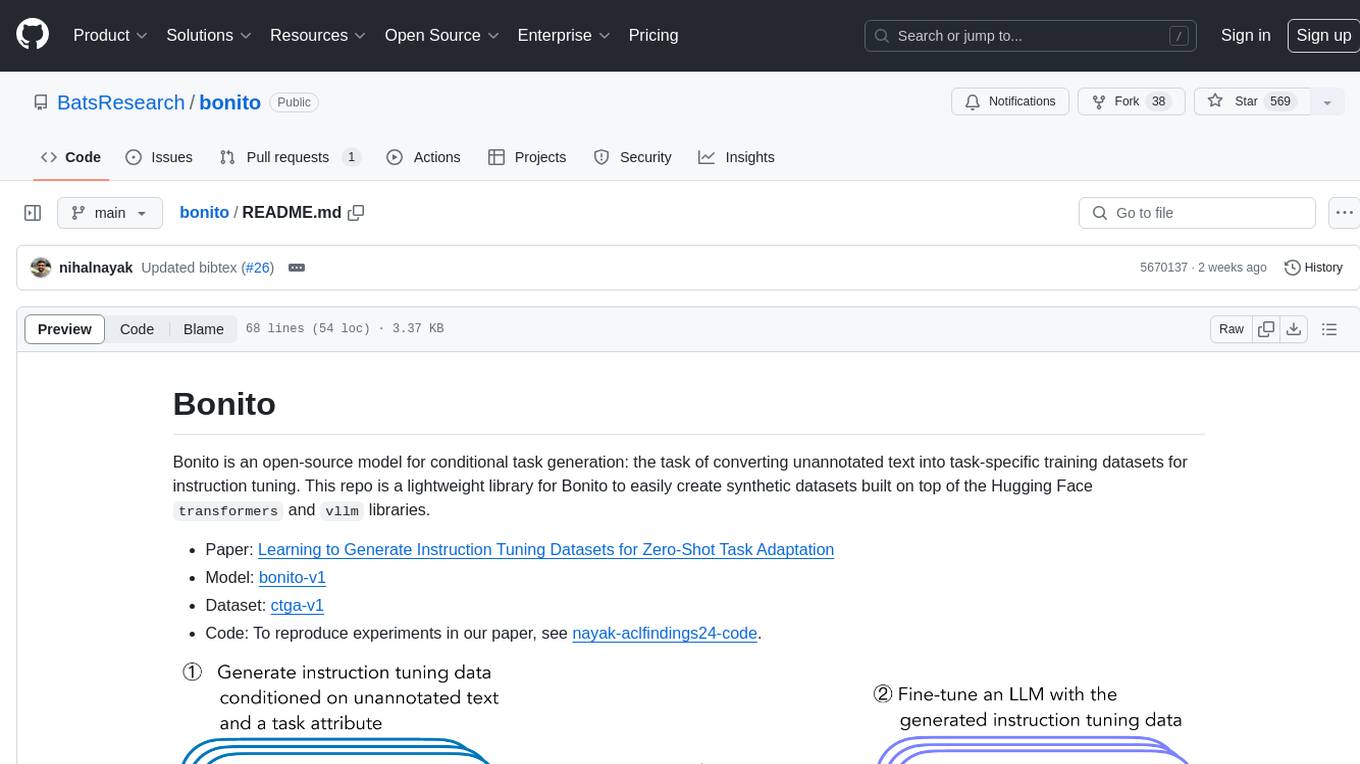
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.
README:
Bonito is an open-source model for conditional task generation: the task of converting unannotated text into task-specific training datasets for instruction tuning. This repo is a lightweight library for Bonito to easily create synthetic datasets built on top of the Hugging Face transformers and vllm libraries.
- Paper: Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
- Model: bonito-v1
- Demo: Bonito on Spaces
- Dataset: ctga-v1
- Code: To reproduce experiments in our paper, see nayak-aclfindings24-code.
- 🐠 February 2025: Uploaded
bonito-llmto PyPI. - 🐡 August 2024: Released new Bonito model with Meta Llama 3.1 as the base model.
- 🐟 June 2024: Bonito is accepted to ACL Findings 2024.
Create an environment and install the package using the following command:
pip3 install bonito-llmTo generate synthetic instruction tuning dataset using Bonito, you can use the following code:
from bonito import Bonito
from vllm import SamplingParams
from datasets import load_dataset
# Initialize the Bonito model
bonito = Bonito("BatsResearch/bonito-v1")
# load dataset with unannotated text
unannotated_text = load_dataset(
"BatsResearch/bonito-experiment",
"unannotated_contract_nli"
)["train"].select(range(10))
# Generate synthetic instruction tuning dataset
sampling_params = SamplingParams(max_tokens=256, top_p=0.95, temperature=0.5, n=1)
synthetic_dataset = bonito.generate_tasks(
unannotated_text,
context_col="input",
task_type="nli",
sampling_params=sampling_params
)Here we include the supported task types [full name (short form)]: extractive question answering (exqa), multiple-choice question answering (mcqa), question generation (qg), question answering without choices (qa), yes-no question answering (ynqa), coreference resolution (coref), paraphrase generation (paraphrase), paraphrase identification (paraphrase_id), sentence completion (sent_comp), sentiment (sentiment), summarization (summarization), text generation (text_gen), topic classification (topic_class), word sense disambiguation (wsd), textual entailment (te), natural language inference (nli)
You can use either the full name or the short form to specify the task_type in generate_tasks.
We have created a tutorial here for how to use a quantized version of the model in a Google Colab T4 instance. The quantized version was graciously contributed by user alexandreteles. We have an additional tutorial to try out the Bonito model on A100 GPU on Google Colab here.
If you use Bonito in your research, please cite the following paper:
@inproceedings{bonito:aclfindings24,
title = {Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation},
author = {Nayak, Nihal V. and Nan, Yiyang and Trost, Avi and Bach, Stephen H.},
booktitle = {Findings of the Association for Computational Linguistics: ACL 2024},
year = {2024}}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bonito
Similar Open Source Tools
bonito
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.

Hurley-AI
Hurley AI is a next-gen framework for developing intelligent agents through Retrieval-Augmented Generation. It enables easy creation of custom AI assistants and agents, supports various agent types, and includes pre-built tools for domains like finance and legal. Hurley AI integrates with LLM inference services and provides observability with Arize Phoenix. Users can create Hurley RAG tools with a single line of code and customize agents with specific instructions. The tool also offers various helper functions to connect with Hurley RAG and search tools, along with pre-built tools for tasks like summarizing text, rephrasing text, understanding memecoins, and querying databases.
godot-llm
Godot LLM is a plugin that enables the utilization of large language models (LLM) for generating content in games. It provides functionality for text generation, text embedding, multimodal text generation, and vector database management within the Godot game engine. The plugin supports features like Retrieval Augmented Generation (RAG) and integrates llama.cpp-based functionalities for text generation, embedding, and multimodal capabilities. It offers support for various platforms and allows users to experiment with LLM models in their game development projects.
receipt-scanner
The receipt-scanner repository is an AI-Powered Receipt and Invoice Scanner for Laravel that allows users to easily extract structured receipt data from images, PDFs, and emails within their Laravel application using OpenAI. It provides a light wrapper around OpenAI Chat and Completion endpoints, supports various input formats, and integrates with Textract for OCR functionality. Users can install the package via composer, publish configuration files, and use it to extract data from plain text, PDFs, images, Word documents, and web content. The scanned receipt data is parsed into a DTO structure with main classes like Receipt, Merchant, and LineItem.
aiolauncher_scripts
AIO Launcher Scripts is a collection of Lua scripts that can be used with AIO Launcher to enhance its functionality. These scripts can be used to create widget scripts, search scripts, and side menu scripts. They provide various functions such as displaying text, buttons, progress bars, charts, and interacting with app widgets. The scripts can be used to customize the appearance and behavior of the launcher, add new features, and interact with external services.

magentic
Easily integrate Large Language Models into your Python code. Simply use the `@prompt` and `@chatprompt` decorators to create functions that return structured output from the LLM. Mix LLM queries and function calling with regular Python code to create complex logic.
FinRL_DeepSeek
FinRL-DeepSeek is a project focusing on LLM-infused risk-sensitive reinforcement learning for trading agents. It provides a framework for training and evaluating trading agents in different market conditions using deep reinforcement learning techniques. The project integrates sentiment analysis and risk assessment to enhance trading strategies in both bull and bear markets. Users can preprocess financial news data, add LLM signals, and train agent-ready datasets for PPO and CPPO algorithms. The project offers specific training and evaluation environments for different agent configurations, along with detailed instructions for installation and usage.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
auto-playwright
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.

nano-graphrag
nano-GraphRAG is a simple, easy-to-hack implementation of GraphRAG that provides a smaller, faster, and cleaner version of the official implementation. It is about 800 lines of code, small yet scalable, asynchronous, and fully typed. The tool supports incremental insert, async methods, and various parameters for customization. Users can replace storage components and LLM functions as needed. It also allows for embedding function replacement and comes with pre-defined prompts for entity extraction and community reports. However, some features like covariates and global search implementation differ from the original GraphRAG. Future versions aim to address issues related to data source ID, community description truncation, and add new components.
olah
Olah is a self-hosted lightweight Huggingface mirror service that implements mirroring feature for Huggingface resources at file block level, enhancing download speeds and saving bandwidth. It offers cache control policies and allows administrators to configure accessible repositories. Users can install Olah with pip or from source, set up the mirror site, and download models and datasets using huggingface-cli. Olah provides additional configurations through a configuration file for basic setup and accessibility restrictions. Future work includes implementing an administrator and user system, OOS backend support, and mirror update schedule task. Olah is released under the MIT License.
Autono
A highly robust autonomous agent framework based on the ReAct paradigm, designed for adaptive decision making and multi-agent collaboration. It dynamically generates next actions during agent execution, enhancing robustness. Features a timely abandonment strategy and memory transfer mechanism for multi-agent collaboration. The framework allows developers to balance conservative and exploratory tendencies in agent execution strategies, improving adaptability and task execution efficiency in complex environments. Supports external tool integration, modular design, and MCP protocol compatibility for flexible action space expansion. Multi-agent collaboration mechanism enables agents to focus on specific task components, improving execution efficiency and quality.
hume-python-sdk
The Hume AI Python SDK allows users to integrate Hume APIs directly into their Python applications. Users can access complete documentation, quickstart guides, and example notebooks to get started. The SDK is designed to provide support for Hume's expressive communication platform built on scientific research. Users are encouraged to create an account at beta.hume.ai and stay updated on changes through Discord. The SDK may undergo breaking changes to improve tooling and ensure reliable releases in the future.
chatgpt-subtitle-translator
This tool utilizes the OpenAI ChatGPT API to translate text, with a focus on line-based translation, particularly for SRT subtitles. It optimizes token usage by removing SRT overhead and grouping text into batches, allowing for arbitrary length translations without excessive token consumption while maintaining a one-to-one match between line input and output.
For similar tasks
bonito
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.

OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

lima
LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.