
lima
The Libre Multilingual Analyzer, a Natural Language Processing (NLP) C++ toolkit.
Stars: 102

LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.
README:
![]()
LIMA python bindings are currently available under Linux only (x86_64).
Under Linux with python >= 3.7 and < 4, and upgraded pip:
At time of writing, the current version cannot be installed using pip because the generated Python Wheel is larger than the limit. We are waiting for a validation of our demand for a higher limit. That's why instructions below ask you to download yourself the wheel and install it from your filesystem.
# Upgrading pip is fundamental in order to obtain the correct LIMA version
$ pip install --upgrade pip
$ wget https://github.com/aymara/lima-python/releases/download/continuous/aymara-0.5.0b6-cp37-abi3-manylinux_2_28_x86_64.whl
$ pip install ./aymara-0.5.0b6-cp37-abi3-manylinux_2_28_x86_64.whl
$ lima_models.py -l eng
# Either simply use the lima command to produce an analysis of a file in CoNLLU format:
$ lima <path to the file to analyse>
# Or use the python API:
$ python
>>> import aymara.lima
>>> nlp = aymara.lima.Lima("ud-eng")
>>> doc = nlp('Hello, World!')
>>> print(doc[0].lemma)
hello
>>> print(repr(doc))
1 Hello hello INTJ _ _ 0 root _ Pos=0|Len=5
2 , , PUNCT _ _ 1 punct _ Pos=5|Len=1
3 World World PROPN _ Number:Sing 1 vocative _ Pos=7|Len=5
4 ! ! PUNCT _ _ 1 punct _ Pos=12|Len=1LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory (French acronym for Text and Image Semantic Analysis Laboratory). LIMA is Free Software, available under the MIT license.
LIMA has state of the art performance for more than 60 languages thanks to its recent deep learning (neural network) based modules. But it includes also a very powerful rules based mechanism called ModEx allowing to quickly extract information (entities, relations, events…) in new domains where annotated data does not exist.
For more information, installation instructions and documentation, please refer to the LIMA Wiki.

![]()
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lima
Similar Open Source Tools
lima
LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.

chromem-go
chromem-go is an embeddable vector database for Go with a Chroma-like interface and zero third-party dependencies. It enables retrieval augmented generation (RAG) and similar embeddings-based features in Go apps without the need for a separate database. The focus is on simplicity and performance for common use cases, allowing querying of documents with minimal memory allocations. The project is in beta and may introduce breaking changes before v1.0.0.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
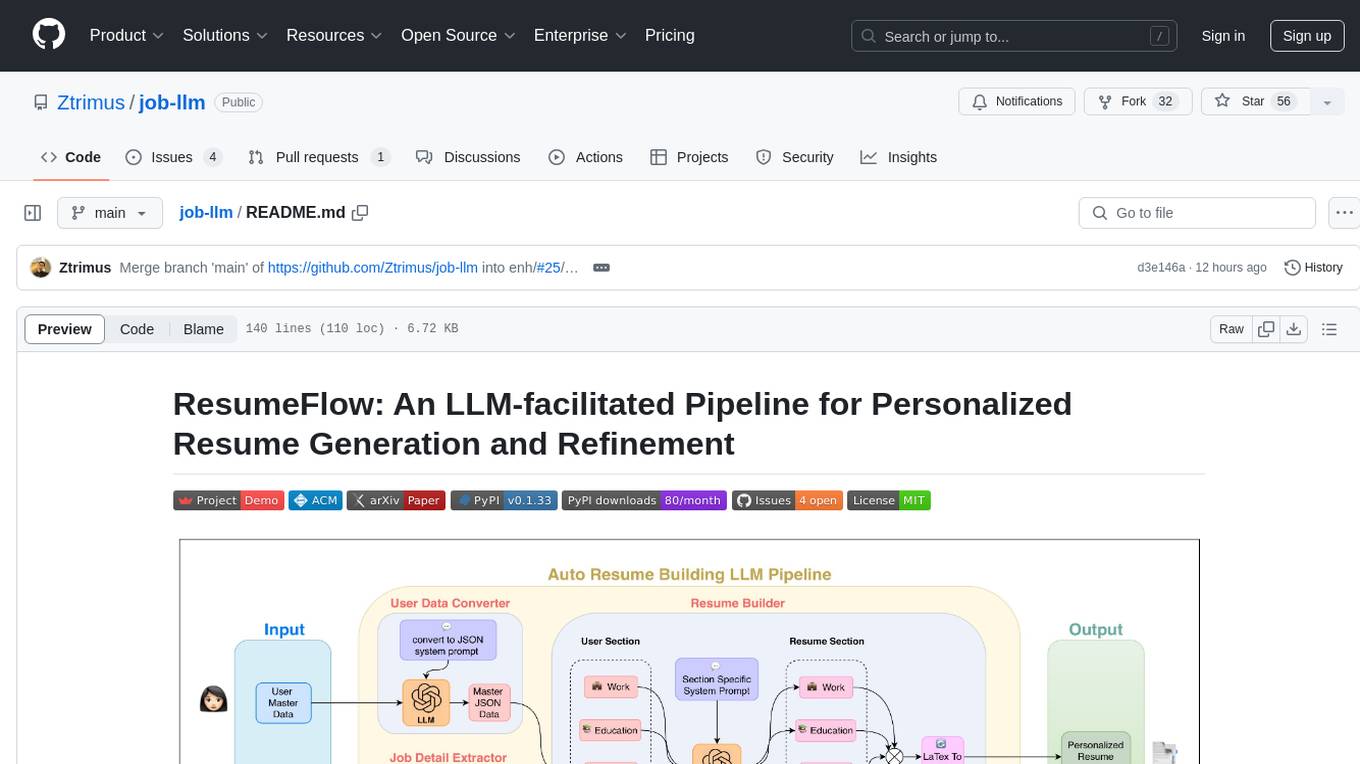
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐
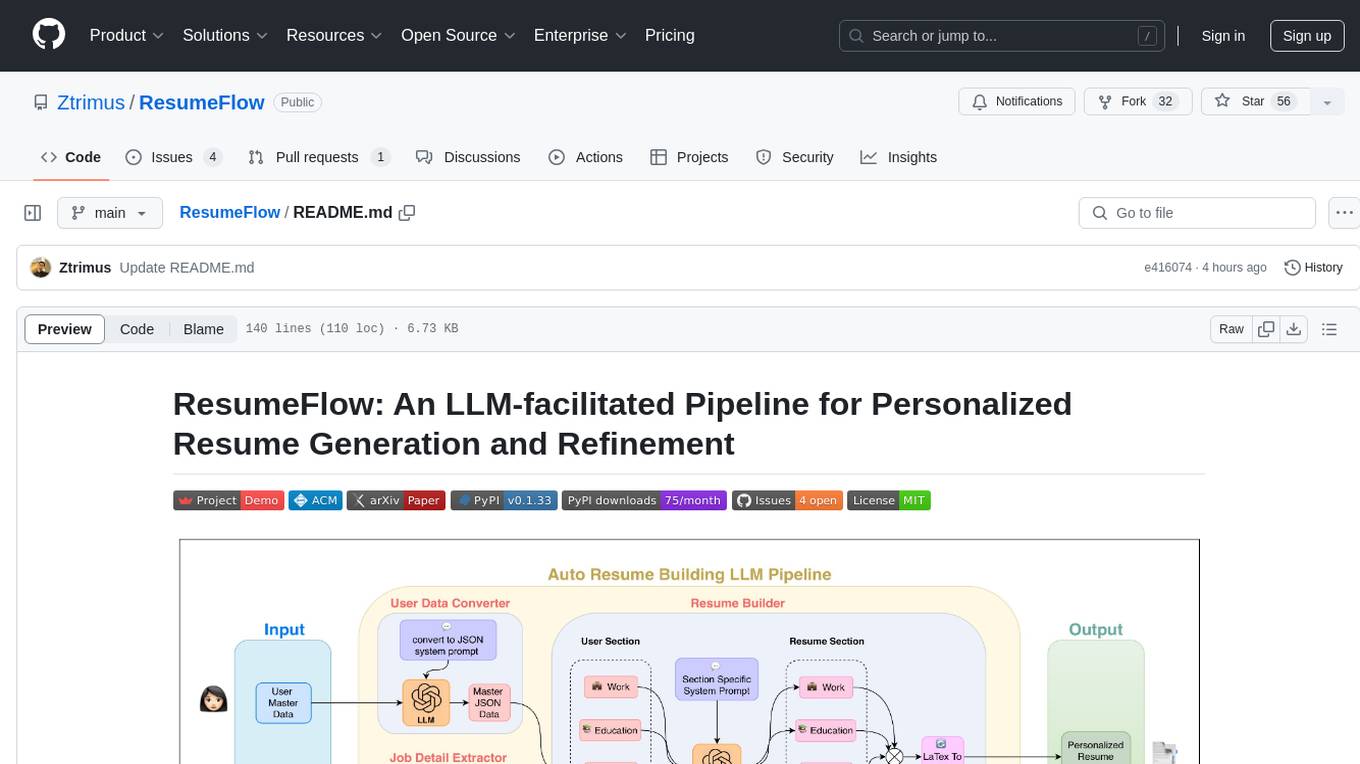
ResumeFlow
ResumeFlow is an automated system that leverages Large Language Models (LLMs) to streamline the job application process. By integrating LLM technology, the tool aims to automate various stages of job hunting, making it easier for users to apply for jobs. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code from GitHub. The tool requires Python 3.11.6 or above and an LLM API key from OpenAI or Gemini Pro for usage. ResumeFlow offers functionalities such as generating curated resumes and cover letters based on job URLs and user's master resume data.

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.
vertex-ai-mlops
Vertex AI is a platform for end-to-end model development. It consist of core components that make the processes of MLOps possible for design patterns of all types.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.
SciPIP
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
chatlas
Chatlas is a Python tool that provides a simple and unified interface across various large language model providers. It helps users prototype faster by abstracting complexity from tasks like streaming chat interfaces, tool calling, and structured output. Users can easily switch providers by changing one line of code and access provider-specific features when needed. Chatlas focuses on developer experience with typing support, rich console output, and extension points.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.
allchat
ALLCHAT is a Node.js backend and React MUI frontend for an application that interacts with the Gemini Pro 1.5 (and others), with history, image generating/recognition, PDF/Word/Excel upload, code run, model function calls and markdown support. It is a comprehensive tool that allows users to connect models to the world with Web Tools, run locally, deploy using Docker, configure Nginx, and monitor the application using a dockerized monitoring solution (Loki+Grafana).
For similar tasks

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.

OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.
lima
LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.