
Eco2AI
eco2AI is a python library which accumulates statistics about power consumption and CO2 emission during running code.
Stars: 245
Eco2AI is a python library for CO2 emission tracking that monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions based on regional emission coefficients. Users can easily integrate Eco2AI into their Python scripts by adding a few lines of code. The library records emissions data and device information in a local file, providing detailed session logs with project names, experiment descriptions, start times, durations, power consumption, CO2 emissions, CPU and GPU names, operating systems, and countries.
README:




![]()
The Eco2AI is a python library for CO2 emission tracking. It monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions taking into account the regional emission coefficient. The Eco2AI is applicable to all python scripts and all you need is to add the couple of strings to your code. All emissions data and information about your devices are recorded in a local file.
Every single run of Tracker() accompanies by a session description added to the log file, including the following elements:
- project_name
- experiment_description
- start_time
- duration(s)
- power_consumption(kWTh)
- CO2_emissions(kg)
- CPU_name
- GPU_name
- OS
- country
To install the eco2AI library, run the following command:
pip install eco2ai
Example usage eco2AI
You can also find eco2AI tutorial on youtube

The eco2AI interface is quite simple. Here is the simplest usage example:
import eco2ai
tracker = eco2ai.Tracker(project_name="YourProjectName", experiment_description="training the <your model> model")
tracker.start()
<your gpu &(or) cpu calculations>
tracker.stop()The eco2AI also supports decorators. As soon as the decorated function is executed, the information about the emissions will be written to the emission.csv file:
from eco2ai import track
@track
def train_func(model, dataset, optimizer, epochs):
...
train_func(your_model, your_dataset, your_optimizer, your_epochs)For your convenience, every time you instantiate the Tracker object with your custom parameters, these settings will be saved until the library is deleted. Each new tracker will be created with your custom settings (if you create a tracker with new parameters, they will be saved instead of the old ones). For example:
import eco2ai
tracker = eco2ai.Tracker(
project_name="YourProjectName",
experiment_description="training <your model> model",
file_name="emission.csv"
)
tracker.start()
<your gpu &(or) cpu calculations>
tracker.stop()
...
# now, we want to create a new tracker for new calculations
tracker = eco2ai.Tracker()
# now, it's equivalent to:
# tracker = eco2ai.Tracker(
# project_name="YourProjectName",
# experiment_description="training the <your model> model",
# file_name="emission.csv"
# )
tracker.start()
<your gpu &(or) cpu calculations>
tracker.stop()You can also set parameters using the set_params() function, as in the example below:
from eco2ai import set_params, Tracker
set_params(
project_name="My_default_project_name",
experiment_description="We trained...",
file_name="my_emission_file.csv"
)
tracker = Tracker()
# now, it's equivelent to:
# tracker = Tracker(
# project_name="My_default_project_name",
# experiment_description="We trained...",
# file_name="my_emission_file.csv"
# )
tracker.start()
<your code>
tracker.stop()If for some reasons it is not possible to define country, then emission coefficient is set to 436.529kg/MWh, which is global average. Global Electricity Review
For proper calculation of gpu and cpu power consumption, you should create a "Tracker" before any gpu or CPU usage.
Create a new “Tracker” for every new calculation.
An example of using the library is given in the publication. It the paper we presented experiments of tracking equivalent CO2 emissions using eco2AI while training ruDALL-E models with with 1.3 billion (Malevich, ruDALL-E XL 1.3B) and 12 billion parameters (Kandinsky, ruDALL-E XL 12B). These are multimodal pre-trained transformers that learn the conditional distribution of images with by some string of text capable of generating arbitrary images from a russian text prompt that describes the desired result. Properly accounted carbon emissions and power consumption Malevich and Kandinsky fine-tuning Malevich and Kandinsky on the Emojis dataset is given in the table below.
| Model | Train time | Power, kWh | CO2, kg | GPU | CPU | Batch Size |
|---|---|---|---|---|---|---|
| Malevich | 4h 19m | 1.37 | 0.33 | A100 Graphics, 1 | AMD EPYC 7742 64-Core | 4 |
| Kandinsky | 9h 45m | 24.50 | 5.89 | A100 Graphics, 8 | AMD EPYC 7742 64-Core | 12 |
Also we presented results for training of Malevich with optimized variation of GELU activation function. Training of the Malevich with the 8-bit version of GELU allows us to spent about 10% less energy and, consequently, produce less equivalent CO2 emissions.
The Eco2AI is licensed under a Apache licence 2.0.
Please consider citing the following paper in any research manuscript using the Eco2AI library:
@article{eco2AI,
title={eco2AI: Carbon Emissions Tracking of Machine Learning Models as the First Step Towards Sustainable AI},
url={https://doi.org/10.1134/S1064562422060230}, DOI={10.1134/S1064562422060230},
journal={Doklady Mathematics},
author={Budennyy, S. A. and Lazarev, V. D. and Zakharenko, N. N. and Korovin, A. N. and Plosskaya, O. A. and Dimitrov, D. V. and Akhripkin, V. S. and Pavlov, I. V. and Oseledets, I. V. and Barsola, I. S. and Egorov, I. V. and Kosterina, A. A. and Zhukov, L. E.}, year={2023}, month=jan, language={en}}
.png)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Eco2AI
Similar Open Source Tools
Eco2AI
Eco2AI is a python library for CO2 emission tracking that monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions based on regional emission coefficients. Users can easily integrate Eco2AI into their Python scripts by adding a few lines of code. The library records emissions data and device information in a local file, providing detailed session logs with project names, experiment descriptions, start times, durations, power consumption, CO2 emissions, CPU and GPU names, operating systems, and countries.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
llmware
LLMWare is a framework for quickly developing LLM-based applications including Retrieval Augmented Generation (RAG) and Multi-Step Orchestration of Agent Workflows. This project provides a comprehensive set of tools that anyone can use - from a beginner to the most sophisticated AI developer - to rapidly build industrial-grade, knowledge-based enterprise LLM applications. Our specific focus is on making it easy to integrate open source small specialized models and connecting enterprise knowledge safely and securely.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking
lance
Lance is a modern columnar data format optimized for ML workflows and datasets. It offers high-performance random access, vector search, zero-copy automatic versioning, and ecosystem integrations with Apache Arrow, Pandas, Polars, and DuckDB. Lance is designed to address the challenges of the ML development cycle, providing a unified data format for collection, exploration, analytics, feature engineering, training, evaluation, deployment, and monitoring. It aims to reduce data silos and streamline the ML development process.

cleanlab
Cleanlab helps you **clean** data and **lab** els by automatically detecting issues in a ML dataset. To facilitate **machine learning with messy, real-world data** , this data-centric AI package uses your _existing_ models to estimate dataset problems that can be fixed to train even _better_ models.

CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.
TileRT
TileRT is a project designed to serve large language models (LLMs) in ultra-low-latency scenarios. It aims to push the latency limits of LLMs without compromising model size or quality, enabling models with hundreds of billions of parameters to achieve millisecond-level time per output token. TileRT prioritizes responsiveness for applications like high-frequency trading, interactive AI, real-time decision-making, long-running agents, and AI-assisted coding. It introduces a tile-level runtime engine that dynamically reschedules computation, I/O, and communication across multiple devices to minimize idle time and improve hardware utilization. The project is actively evolving, with compiler techniques gradually shared with the community through TileLang and TileScale.
mobius
Mobius is an AI infra platform including realtime computing and training. It is built on Ray, a distributed computing framework, and provides a number of features that make it well-suited for online machine learning tasks. These features include: * **Cross Language**: Mobius can run in multiple languages (only Python and Java are supported currently) with high efficiency. You can implement your operator in different languages and run them in one job. * **Single Node Failover**: Mobius has a special failover mechanism that only needs to rollback the failed node itself, in most cases, to recover the job. This is a huge benefit if your job is sensitive about failure recovery time. * **AutoScaling**: Mobius can generate a new graph with different configurations in runtime without stopping the job. * **Fusion Training**: Mobius can combine TensorFlow/Pytorch and streaming, then building an e2e online machine learning pipeline. Mobius is still under development, but it has already been used to power a number of real-world applications, including: * A real-time recommendation system for a major e-commerce company * A fraud detection system for a large financial institution * A personalized news feed for a major news organization If you are interested in using Mobius for your own online machine learning projects, you can find more information in the documentation.

catalyst
Catalyst is a C# Natural Language Processing library designed for speed, inspired by spaCy's design. It provides pre-trained models, support for training word and document embeddings, and flexible entity recognition models. The library is fast, modern, and pure-C#, supporting .NET standard 2.0. It is cross-platform, running on Windows, Linux, macOS, and ARM. Catalyst offers non-destructive tokenization, named entity recognition, part-of-speech tagging, language detection, and efficient binary serialization. It includes pre-built models for language packages and lemmatization. Users can store and load models using streams. Getting started with Catalyst involves installing its NuGet Package and setting the storage to use the online repository. The library supports lazy loading of models from disk or online. Users can take advantage of C# lazy evaluation and native multi-threading support to process documents in parallel. Training a new FastText word2vec embedding model is straightforward, and Catalyst also provides algorithms for fast embedding search and dimensionality reduction.
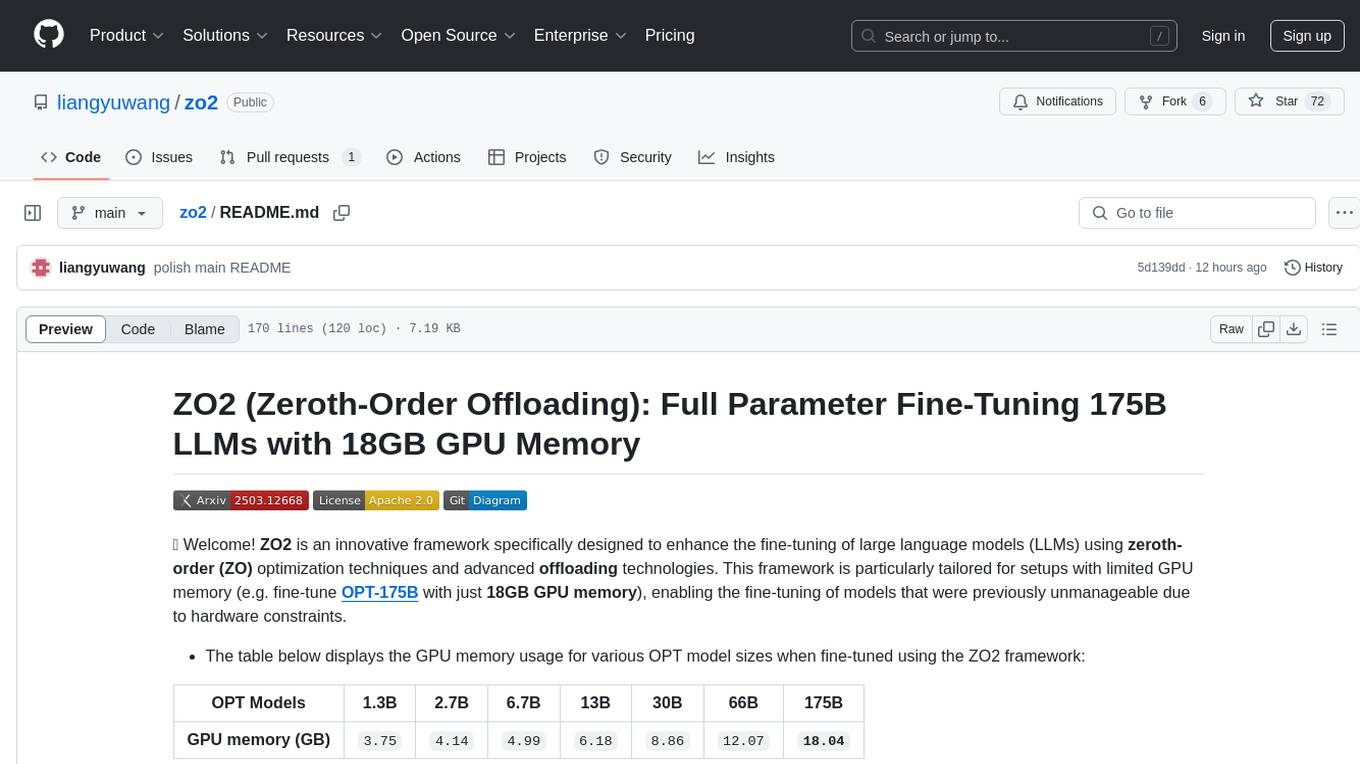
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.
bee-agent-framework
The Bee Agent Framework is an open-source tool for building, deploying, and serving powerful agentic workflows at scale. It provides AI agents, tools for creating workflows in Javascript/Python, a code interpreter, memory optimization strategies, serialization for pausing/resuming workflows, traceability features, production-level control, and upcoming features like model-agnostic support and a chat UI. The framework offers various modules for agents, llms, memory, tools, caching, errors, adapters, logging, serialization, and more, with a roadmap including MLFlow integration, JSON support, structured outputs, chat client, base agent improvements, guardrails, and evaluation.
For similar tasks
awesome-green-ai
Awesome Green AI is a curated list of resources and tools aimed at reducing the environmental impacts of using and deploying AI. It addresses the carbon footprint of the ICT sector, emphasizing the importance of AI in reducing environmental impacts beyond GHG emissions and electricity consumption. The tools listed cover code-based tools for measuring environmental impacts, monitoring tools for power consumption, optimization tools for energy efficiency, and calculation tools for estimating environmental impacts of algorithms and models. The repository also includes leaderboards, papers, survey papers, and reports related to green AI and environmental sustainability in the AI sector.
Eco2AI
Eco2AI is a python library for CO2 emission tracking that monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions based on regional emission coefficients. Users can easily integrate Eco2AI into their Python scripts by adding a few lines of code. The library records emissions data and device information in a local file, providing detailed session logs with project names, experiment descriptions, start times, durations, power consumption, CO2 emissions, CPU and GPU names, operating systems, and countries.
aioshelly
Aioshelly is an asynchronous library designed to control Shelly devices. It is currently under development and requires Python version 3.11 or higher, along with dependencies like bluetooth-data-tools, aiohttp, and orjson. The library provides examples for interacting with Gen1 devices using CoAP protocol and Gen2/Gen3 devices using RPC and WebSocket protocols. Users can easily connect to Shelly devices, retrieve status information, and perform various actions through the provided APIs. The repository also includes example scripts for quick testing and usage guidelines for contributors to maintain consistency with the Shelly API.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.