
beyondllm
Build, evaluate and observe LLM apps
Stars: 254

Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.
README:


Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems, simplifying the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs, ultimately aiming to reduce LLM hallucination risks and enhance reliability.
👉 Join our Discord community!Try out a quick demo on Google Colab:
pip install beyondllmIn this quick start guide, we'll demonstrate how to create a Chat with YouTube video RAG application using Beyond LLM with less than 8 lines of code. This 8 lines of code includes:
- Getting custom data source
- Retrieving documents
- Generating LLM responses
- Evaluating embeddings
- Evaluating LLM responses
Build customised RAG in less than 5 lines of code using Beyond LLM.
from beyondllm import source,retrieve,generator
import os
os.environ['GOOGLE_API_KEY'] = "Your Google API Key:"
data = source.fit("https://www.youtube.com/watch?v=oJJyTztI_6g",dtype="youtube",chunk_size=512,chunk_overlap=50)
retriever = retrieve.auto_retriever(data,type="normal",top_k=3)
pipeline = generator.Generate(question="what tool is video mentioning about?",retriever=retriever)
print(pipeline.call())Beyond LLM support various Embeddings and LLMs that are two very important components in Retrieval Augmented Generation.
from beyondllm import source,retrieve,embeddings,llms,generator
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass("Your OpenAI API Key:")
data = source.fit("https://www.youtube.com/watch?v=oJJyTztI_6g",dtype="youtube",chunk_size=1024,chunk_overlap=0)
embed_model = embeddings.OpenAIEmbeddings()
retriever = retrieve.auto_retriever(data,embed_model,type="normal",top_k=4)
llm = llms.ChatOpenAIModel()
pipeline = generator.Generate(question="what tool is video mentioning about?",retriever=retriever,llm=llm)
print(pipeline.call()) #AI response
print(retriever.evaluate(llm=llm)) #evaluate embeddings
print(pipeline.get_rag_triad_evals()) #evaluate LLM responseThe tool mentioned in the context is called Jupiter, which is an AI Guru designed to simplify the learning of complex data science topics. Users can access Jupiter by logging into AI Planet, accessing any course for free, and then requesting explanations of topics from Jupiter in various styles, such as in the form of a movie plot. Jupiter aims to make AI education more accessible and interactive for everyone.
Hit_rate:1.0
MRR:1.0
Context relevancy Score: 8.0
Answer relevancy Score: 7.0
Groundness score: 7.666666666666667Observability helps to keep track of the closed source models on the latency and the cost monitor tracking. BeyondLLM provides Observer that currently monitors the OpenAI LLM model performance.
from beyondllm import source,retrieve,generator, llms, embeddings
from beyondllm.observe import Observer
import os
os.environ['OPENAI_API_KEY'] = 'sk-****'
Observe = Observer()
Observe.run()
llm=llms.ChatOpenAIModel()
embed_model = embeddings.OpenAIEmbeddings()
data = source.fit("https://www.youtube.com/watch?v=oJJyTztI_6g",dtype="youtube",chunk_size=512,chunk_overlap=50)
retriever = retrieve.auto_retriever(data,embed_model,type="normal",top_k=4)
pipeline = generator.Generate(question="what tool is video mentioning about?",retriever=retriever, llm=llm)
pipeline = generator.Generate(question="What is the tool used for?",retriever=retriever, llm=llm)
pipeline = generator.Generate(question="How can i use the tool for my own use?",retriever=retriever, llm=llm)See the beyondllm.aiplanet.com for complete documentation.
Beyond LLM thrives in the rapidly evolving landscape of open-source projects. We wholeheartedly welcome contributions in various capacities, be it through innovative features, enhanced infrastructure, or refined documentation.
See Contributing guide for more information on contributing to the BeyondLLM library.
and the entire OpenSource community.
The contents of this repository are licensed under the Apache License, version 2.0.
You can schedule a 1:1 meeting with our Team to get started with GenAI Stack, OpenAGI, AI Planet Open Source LLMs(Buddhi, effi and Panda Coder) and Beyond LLM. Schedule the call here: https://calendly.com/jaintarun
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for beyondllm
Similar Open Source Tools
beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
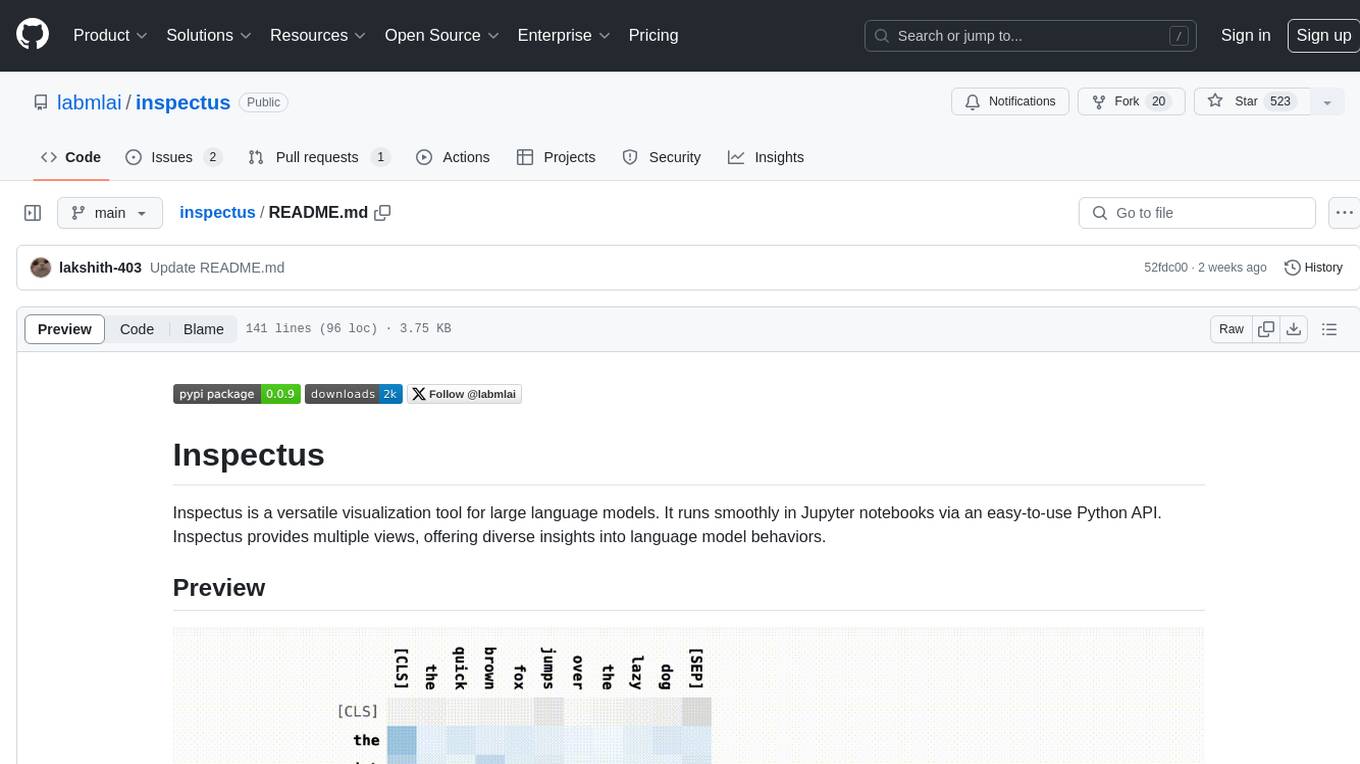
inspectus
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.

AgentFly
AgentFly is an extensible framework for building LLM agents with reinforcement learning. It supports multi-turn training by adapting traditional RL methods with token-level masking. It features a decorator-based interface for defining tools and reward functions, enabling seamless extension and ease of use. To support high-throughput training, it implemented asynchronous execution of tool calls and reward computations, and designed a centralized resource management system for scalable environment coordination. A suite of prebuilt tools and environments are provided.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.
AIQC
AIQC is an open source Python package that provides a declarative API for end-to-end MLOps in order to make deep learning more accessible to researchers. It utilizes a SQLite object-relational model for machine learning objects and stacks standardized workflows for various analyses, data types, and libraries. The benefits include a 90% reduction in data wrangling, reproducibility, and no need to install and maintain application and database servers for experiment tracking. AIQC is pip-installable and provides a Dash-Plotly UI for real-time experiment tracking.

MineStudio
MineStudio is a simple and efficient Minecraft development kit for AI research. It contains tools and APIs for developing Minecraft AI agents, including a customizable simulator, trajectory data structure, policy models, offline and online training pipelines, inference framework, and benchmarking automation. The repository is under development and welcomes contributions and suggestions.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.

catalyst
Catalyst is a C# Natural Language Processing library designed for speed, inspired by spaCy's design. It provides pre-trained models, support for training word and document embeddings, and flexible entity recognition models. The library is fast, modern, and pure-C#, supporting .NET standard 2.0. It is cross-platform, running on Windows, Linux, macOS, and ARM. Catalyst offers non-destructive tokenization, named entity recognition, part-of-speech tagging, language detection, and efficient binary serialization. It includes pre-built models for language packages and lemmatization. Users can store and load models using streams. Getting started with Catalyst involves installing its NuGet Package and setting the storage to use the online repository. The library supports lazy loading of models from disk or online. Users can take advantage of C# lazy evaluation and native multi-threading support to process documents in parallel. Training a new FastText word2vec embedding model is straightforward, and Catalyst also provides algorithms for fast embedding search and dimensionality reduction.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
For similar tasks
beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.
unsloth
Unsloth is a tool that allows users to fine-tune large language models (LLMs) 2-5x faster with 80% less memory. It is a free and open-source tool that can be used to fine-tune LLMs such as Gemma, Mistral, Llama 2-5, TinyLlama, and CodeLlama 34b. Unsloth supports 4-bit and 16-bit QLoRA / LoRA fine-tuning via bitsandbytes. It also supports DPO (Direct Preference Optimization), PPO, and Reward Modelling. Unsloth is compatible with Hugging Face's TRL, Trainer, Seq2SeqTrainer, and Pytorch code. It is also compatible with NVIDIA GPUs since 2018+ (minimum CUDA Capability 7.0).
aiwechat-vercel
aiwechat-vercel is a tool that integrates AI capabilities into WeChat public accounts using Vercel functions. It requires minimal server setup, low entry barriers, and only needs a domain name that can be bound to Vercel, with almost zero cost. The tool supports various AI models, continuous Q&A sessions, chat functionality, system prompts, and custom commands. It aims to provide a platform for learning and experimentation with AI integration in WeChat public accounts.
hugging-chat-api
Unofficial HuggingChat Python API for creating chatbots, supporting features like image generation, web search, memorizing context, and changing LLMs. Users can log in, chat with the ChatBot, perform web searches, create new conversations, manage conversations, switch models, get conversation info, use assistants, and delete conversations. The API also includes a CLI mode with various commands for interacting with the tool. Users are advised not to use the application for high-stakes decisions or advice and to avoid high-frequency requests to preserve server resources.
microchain
Microchain is a function calling-based LLM agents tool with no bloat. It allows users to define LLM and templates, use various functions like Sum and Product, and create LLM agents for specific tasks. The tool provides a simple and efficient way to interact with OpenAI models and create conversational agents for various applications.
embedchain
Embedchain is an Open Source Framework for personalizing LLM responses. It simplifies the creation and deployment of personalized AI applications by efficiently managing unstructured data, generating relevant embeddings, and storing them in a vector database. With diverse APIs, users can extract contextual information, find precise answers, and engage in interactive chat conversations tailored to their data. The framework follows the design principle of being 'Conventional but Configurable' to cater to both software engineers and machine learning engineers.
OpenAssistantGPT
OpenAssistantGPT is an open source platform for building chatbot assistants using OpenAI's Assistant. It offers features like easy website integration, low cost, and an open source codebase available on GitHub. Users can build their chatbot with minimal coding required, and OpenAssistantGPT supports direct billing through OpenAI without extra charges. The platform is user-friendly and cost-effective, appealing to those seeking to integrate AI chatbot functionalities into their websites.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.