
GraphRAG-SDK
Build fast and accurate GenAI apps with GraphRAG SDK at scale.
Stars: 444

Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
README:



Simplify the development of your next GenAI application with GraphRAG-SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows.
Or use on premise with Docker:
docker run -p 6379:6379 -p 3000:3000 -it --rm -v ./data:/data falkordb/falkordb:latestpip install graphrag_sdkConfigure Credentials. See .env for examples.
-
LiteLLM: A framework supporting inference of large language models, allowing flexibility in deployment and use cases.
To choose vendor use the prefix "specific_vendor/your_model", for example "openai/gpt-4.1". -
OpenAI Recommended model:
gpt-4.1 -
Google Recommended model:
gemini-2.0-flash -
Azure-OpenAI Recommended model:
gpt-4.1 -
Ollama Available only to the Q&A step. Recommended models:
llama3. Ollama models are suitable for the Q&A step only (after the knowledge graph (KG) created).
Before using the SDK, configure your environment variables:
# FalkorDB Connection (defaults are for on-premises)
export FALKORDB_HOST="localhost"
export FALKORDB_PORT=6379
export FALKORDB_USERNAME="your-username" # optional for on-premises
export FALKORDB_PASSWORD="your-password" # optional for on-premises
# LLM Provider (choose one)
export OPENAI_API_KEY="your-key" # or GOOGLE_API_KEY, GROQ_API_KEY, etc.If you already have a knowledge graph in FalkorDB, you can quickly set up GraphRAG by extracting the ontology from your existing graph:
import os
from falkordb import FalkorDB
from graphrag_sdk import KnowledgeGraph
from graphrag_sdk.ontology import Ontology
from graphrag_sdk.models.litellm import LiteModel
from graphrag_sdk.model_config import KnowledgeGraphModelConfig
graph_name = "my_existing_graph"
# Connect to FalkorDB using environment variables
db = FalkorDB(
host=os.getenv("FALKORDB_HOST", "localhost"),
port=int(os.getenv("FALKORDB_PORT", 6379)),
username=os.getenv("FALKORDB_USERNAME"), # optional for on-premises
password=os.getenv("FALKORDB_PASSWORD") # optional for on-premises
)
# Select graph
graph = db.select_graph(graph_name)
# Extract ontology from existing knowledge graph
ontology = Ontology.from_kg_graph(graph)
# Configure model and create GraphRAG instance
model = LiteModel() # Default is OpenAI GPT-4.1, can specify different model
model_config = KnowledgeGraphModelConfig.with_model(model)
# Create KnowledgeGraph instance
kg = KnowledgeGraph(
name=graph_name,
model_config=model_config,
ontology=ontology,
host=os.getenv("FALKORDB_HOST", "localhost"),
port=int(os.getenv("FALKORDB_PORT", 6379)),
username=os.getenv("FALKORDB_USERNAME"),
password=os.getenv("FALKORDB_PASSWORD")
)
# Start chat session
chat = kg.chat_session()
# Ask questions
response = chat.send_message("What products are available?")
print(response["response"])
# Ask follow-up questions
response = chat.send_message("Tell me which one of them is the most expensive")
print(response["response"])Automate ontology creation from unstructured data or define it manually - See example
from dotenv import load_dotenv
import json
from graphrag_sdk.source import URL
from graphrag_sdk import KnowledgeGraph, Ontology
from graphrag_sdk.models.litellm import LiteModel
from graphrag_sdk.model_config import KnowledgeGraphModelConfig
load_dotenv()
# Import Data
urls = ["https://www.rottentomatoes.com/m/side_by_side_2012",
"https://www.rottentomatoes.com/m/matrix",
"https://www.rottentomatoes.com/m/matrix_revolutions",
"https://www.rottentomatoes.com/m/matrix_reloaded",
"https://www.rottentomatoes.com/m/speed_1994",
"https://www.rottentomatoes.com/m/john_wick_chapter_4"]
sources = [URL(url) for url in urls]
# Model - vendor: openai, model: gpt-4.1 -> openai/gpt-4.1
model = LiteModel(model_name="openai/gpt-4.1")
# Ontology Auto-Detection
ontology = Ontology.from_sources(
sources=sources,
model=model,
)
# Save the ontology to the disk as a json file.
with open("ontology.json", "w", encoding="utf-8") as file:
file.write(json.dumps(ontology.to_json(), indent=2))Build, query, and manage knowledge graphs optimized for retrieval and augmentation tasks. Leverages FalkorDB for high-performance graph querying and multi-tenancy.
# After approving the ontology, load it from disk.
ontology_file = "ontology.json"
with open(ontology_file, "r", encoding="utf-8") as file:
ontology = Ontology.from_json(json.loads(file.read()))
kg = KnowledgeGraph(
name="kg_name",
model_config=KnowledgeGraphModelConfig.with_model(model),
ontology=ontology,
host="127.0.0.1",
port=6379,
# username=falkor_username, # optional
# password=falkor_password # optional
)
kg.process_sources(sources)At this point, you have a Knowledge Graph that can be queried using this SDK. Use the method chat_session for start a conversation.
# Conversation
chat = kg.chat_session()
response = chat.send_message("Who is the director of the movie The Matrix?")
print(response)
response = chat.send_message("How this director connected to Keanu Reeves?")
print(response)With these 3 steps now completed, you're ready to interact and query your knowledge graph. Here are suggestions for use cases:

Need help with your use case? let's talk
Ollama models are suitable for the Q&A step only (after the knowledge graph has been created).
from graphrag_sdk.models.ollama import OllamaGenerativeModel
# Local Ollama (default: http://localhost:11434)
qa_model = OllamaGenerativeModel(model_name="llama3:8b")
# Remote Ollama
qa_model = OllamaGenerativeModel(
model_name="llama3:8b",
api_base="http://remote-host:11434"
)The GraphRAG-SDK supports Knowledge Graph-based agents. Each agent is an expert in his domain, and the orchestrator orchestrates the agents.
Check out the example:
See the Step 1 section to understand how to create Knowledge Graph objects for the agents.
# Define the model
model = LiteModel(model_name="openai/gpt-4.1")
# Create the Knowledge Graph from the predefined ontology.
# In this example, we will use the restaurants agent and the attractions agent.
restaurants_kg = KnowledgeGraph(
name="restaurants",
ontology=restaurants_ontology,
model_config=KnowledgeGraphModelConfig.with_model(model),
host="127.0.0.1",
port=6379,
# username=falkor_username, # optional
# password=falkor_password # optional
)
attractions_kg = KnowledgeGraph(
name="attractions",
ontology=attractions_ontology,
model_config=KnowledgeGraphModelConfig.with_model(model),
host="127.0.0.1",
port=6379,
# username=falkor_username, # optional
# password=falkor_password # optional
)
# The following agent is specialized in finding restaurants.
restaurants_agent = KGAgent(
agent_id="restaurants_agent",
kg=restaurants_kg,
introduction="I'm a restaurant agent, specialized in finding the best restaurants for you.",
)
# The following agent is specialized in finding tourist attractions.
attractions_agent = KGAgent(
agent_id="attractions_agent",
kg=attractions_kg,
introduction="I'm an attractions agent, specialized in finding the best tourist attractions for you.",
)The orchestrator manages the usage of agents and handles questioning.
# Initialize the orchestrator while giving it the backstory.
orchestrator = Orchestrator(
model,
backstory="You are a trip planner, and you want to provide the best possible itinerary for your clients.",
)
# Register the agents that we created above.
orchestrator.register_agent(restaurants_agent)
orchestrator.register_agent(attractions_agent)
# Query the orchestrator.
runner = orchestrator.ask("Create a two-day itinerary for a trip to Rome. Please don't ask me any questions; just provide the best itinerary you can.")
print(runner.output)Have questions or feedback? Reach out via:
- GitHub Issues
- Join our Discord
⭐️ If you find this repository helpful, please consider giving it a star!
When creating your Knowledge Graph (KG) agent, you can customize the prompts to tailor its behavior.
💡 This step is optional but can enhance functionality.
There are five types of prompts:
-
cypher_system_instruction- System instructions for the Cypher generation step.
-
Note: Ensure your prompt includes
{ontology}.
-
qa_system_instruction- System instructions for the Q&A step.
-
cypher_gen_prompt- The prompt used during the Cypher generation step.
-
Note: Include
{question}in your prompt.
-
cypher_gen_prompt_history- The prompt for Cypher generation when history needs to be considered.
-
Note: Include
{question}and{last_answer}in your prompt.
-
qa_prompt- The prompt used during the Q&A step.
-
Note: Include
{question},{context}, and{cypher}in your prompt.
Here’s an example configuration:
kg = KnowledgeGraph(
name="kg_name",
model_config=KnowledgeGraphModelConfig.with_model(model),
ontology=ontology,
cypher_system_instruction=cypher_system_instruction,
qa_system_instruction=qa_system_instruction,
cypher_gen_prompt=cypher_gen_prompt,
cypher_gen_prompt_history=cypher_gen_prompt_history,
qa_prompt=qa_prompt
host="127.0.0.1",
port=6379,
# username=falkor_username, # optional
# password=falkor_password # optional
)Which databases are supported?
GraphRAG-SDK is optimized for FalkorDB. Other backends may require adapters.
How scalable is the SDK?
GraphRAG-SDK is designed for multi-tenancy and large-scale applications. Performance depends on FalkorDB deployment configuration.
How does this SDK improve retrieval-augmented generation?
By leveraging knowledge graphs, GraphRAG-SDK enables semantic relationships and ontology-driven queries that go beyond standard vector similarity.
Which file formats does the SDK support?
Supported formats include PDF, JSONL, CSV, HTML, TEXT, and URLs.
How does the SDK handle latency?
The SDK is optimized for low-latency operations through FalkorDB, using techniques like query optimization and in-memory processing.
Does the SDK support multi-graph querying?
Yes. Multi-graph querying is supported with APIs designed for cross-domain and hierarchical graph exploration.
This project is licensed under the MIT License. See the LICENSE file for details.
Keywords: RAG, graphrag, Retrieval-Augmented Generation, NLP, AI, Information Retrieval, Natural Language Processing, LLM, Embeddings, Semantic Search
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for GraphRAG-SDK
Similar Open Source Tools
GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.

semantic-kernel
Semantic Kernel is an SDK that integrates Large Language Models (LLMs) like OpenAI, Azure OpenAI, and Hugging Face with conventional programming languages like C#, Python, and Java. Semantic Kernel achieves this by allowing you to define plugins that can be chained together in just a few lines of code. What makes Semantic Kernel _special_ , however, is its ability to _automatically_ orchestrate plugins with AI. With Semantic Kernel planners, you can ask an LLM to generate a plan that achieves a user's unique goal. Afterwards, Semantic Kernel will execute the plan for the user.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.
mcp-agent
mcp-agent is a simple, composable framework designed to build agents using the Model Context Protocol. It handles the lifecycle of MCP server connections and implements patterns for building production-ready AI agents in a composable way. The framework also includes OpenAI's Swarm pattern for multi-agent orchestration in a model-agnostic manner, making it the simplest way to build robust agent applications. It is purpose-built for the shared protocol MCP, lightweight, and closer to an agent pattern library than a framework. mcp-agent allows developers to focus on the core business logic of their AI applications by handling mechanics such as server connections, working with LLMs, and supporting external signals like human input.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

AgentFly
AgentFly is an extensible framework for building LLM agents with reinforcement learning. It supports multi-turn training by adapting traditional RL methods with token-level masking. It features a decorator-based interface for defining tools and reward functions, enabling seamless extension and ease of use. To support high-throughput training, it implemented asynchronous execution of tool calls and reward computations, and designed a centralized resource management system for scalable environment coordination. A suite of prebuilt tools and environments are provided.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.

LightAgent
LightAgent is a lightweight, open-source Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex task handling, and multi-model support. It also features a streaming API, tool generator, agent self-learning, adaptive tool mechanism, and more. LightAgent is designed for intelligent customer service, data analysis, automated tools, and educational assistance.
LightAgent
LightAgent is a lightweight, open-source active Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex goals, and multi-model support. It enables simpler self-learning agents, seamless integration with major chat frameworks, and quick tool generation. LightAgent also supports memory modules, tool integration, tree of thought planning, multi-agent collaboration, streaming API, agent self-learning, Langfuse log tracking, and agent assessment. It is compatible with various large models and offers features like intelligent customer service, data analysis, automated tools, and educational assistance.
ai-microcore
MicroCore is a collection of python adapters for Large Language Models and Vector Databases / Semantic Search APIs. It allows convenient communication with these services, easy switching between models & services, and separation of business logic from implementation details. Users can keep applications simple and try various models & services without changing application code. MicroCore connects MCP tools to language models easily, supports text completion and chat completion models, and provides features for configuring, installing vendor-specific packages, and using vector databases.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.
For similar tasks
GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
ai-commits-intellij-plugin
AI Commits is a plugin for IntelliJ-based IDEs and Android Studio that generates commit messages using git diff and OpenAI. It offers features such as generating commit messages from diff using OpenAI API, computing diff only from selected files and lines in the commit dialog, creating custom prompts for commit message generation, using predefined variables and hints to customize prompts, choosing any of the models available in OpenAI API, setting OpenAI network proxy, and setting custom OpenAI compatible API endpoint.
gen.nvim
gen.nvim is a tool that allows users to generate text using Language Models (LLMs) with customizable prompts. It requires Ollama with models like `llama3`, `mistral`, or `zephyr`, along with Curl for installation. Users can use the `Gen` command to generate text based on predefined or custom prompts. The tool provides key maps for easy invocation and allows for follow-up questions during conversations. Additionally, users can select a model from a list of installed models and customize prompts as needed.
llm-document-ocr
LLM Document OCR is a Node.js tool that utilizes GPT4 and Claude3 for OCR and data extraction. It converts PDFs into PNGs, crops white-space, cleans up JSON strings, and supports various image formats. Users can customize prompts for data extraction. The tool is sponsored by Mercoa, offering API for BillPay and Invoicing.
talemate
Talemate is a roleplay tool that allows users to interact with AI agents for dialogue, narration, summarization, direction, editing, world state management, character/scenario creation, text-to-speech, and visual generation. It supports multiple AI clients and APIs, offers long-term memory using ChromaDB, and provides tools for managing NPCs, AI-assisted character creation, and scenario creation. Users can customize prompts using Jinja2 templates and benefit from a modern, responsive UI. The tool also integrates with Runpod for enhanced functionality.
dialog
Dialog is an API-focused tool designed to simplify the deployment of Large Language Models (LLMs) for programmers interested in AI. It allows users to deploy any LLM based on the structure provided by dialog-lib, enabling them to spend less time coding and more time training their models. The tool aims to humanize Retrieval-Augmented Generative Models (RAGs) and offers features for better RAG deployment and maintenance. Dialog requires a knowledge base in CSV format and a prompt configuration in TOML format to function effectively. It provides functionalities for loading data into the database, processing conversations, and connecting to the LLM, with options to customize prompts and parameters. The tool also requires specific environment variables for setup and configuration.
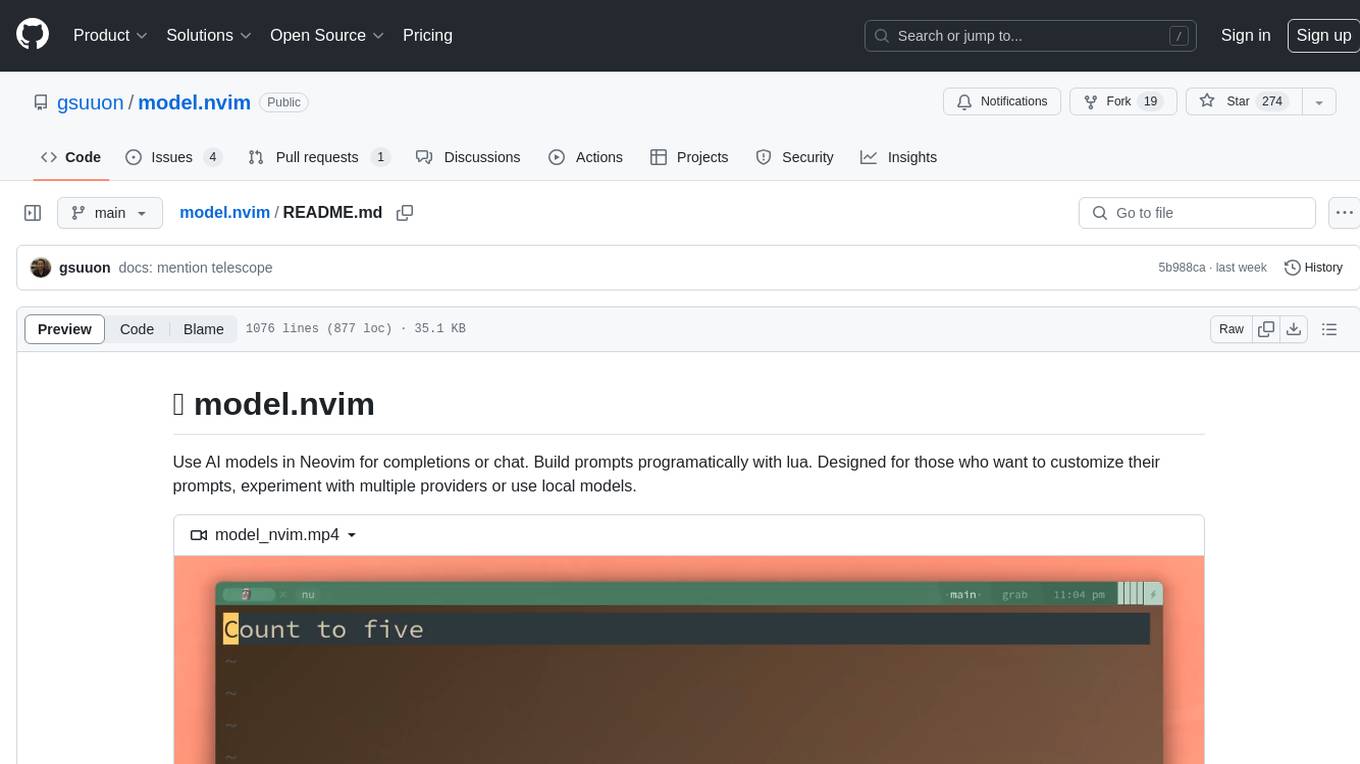
model.nvim
model.nvim is a tool designed for Neovim users who want to utilize AI models for completions or chat within their text editor. It allows users to build prompts programmatically with Lua, customize prompts, experiment with multiple providers, and use both hosted and local models. The tool supports features like provider agnosticism, programmatic prompts in Lua, async and multistep prompts, streaming completions, and chat functionality in 'mchat' filetype buffer. Users can customize prompts, manage responses, and context, and utilize various providers like OpenAI ChatGPT, Google PaLM, llama.cpp, ollama, and more. The tool also supports treesitter highlights and folds for chat buffers.
RSSbrew
RSSBrew is a self-hosted RSS tool designed for aggregating multiple RSS feeds, applying custom filters, and generating AI summaries. It allows users to control content through custom filters based on Link, Title, and Description, with various match types and relationship operators. Users can easily combine multiple feeds into a single processed feed and use AI for article summarization and digest creation. The tool supports Docker deployment and regular installation, with ongoing documentation and development. Licensed under AGPL-3.0, RSSBrew is a versatile tool for managing and summarizing RSS content.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.