
aigverse
A Python library for working with logic networks, synthesis, and optimization.
Stars: 73
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
README:





[!Important] This project is still in the early stages of development. The API is subject to change, and some features may not be fully implemented. I appreciate your patience and understanding as work to improve the library continues.
aigverse is a Python infrastructure framework designed to bridge the gap between logic synthesis and AI/ML
applications. It allows you to represent and manipulate logic circuits efficiently, making it easier to integrate logic
synthesis and optimization tasks into machine learning pipelines. aigverse is built directly upon the
powerful EPFL Logic Synthesis Libraries, particularly
mockturtle, providing a high-level Python interface to state-of-the-art
algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware
design, and optimization tasks.
- Efficient Logic Representation: Use And-Inverter Graphs (AIGs) to model and manipulate logic circuits in Python.
- File Format Support: Read and write AIGER, Verilog, Bench, PLA, ... files for interoperability with other logic synthesis tools.
- C++ Backend: Leverage the performance of the EPFL Logic Synthesis Libraries for fast logic synthesis and optimization.
- High-Level API: Simplify logic synthesis tasks with a Pythonic interface for AIG manipulation and optimization.
- Integration with Machine Learning: Convenient integration with popular data science libraries.
As AI and machine learning (ML) increasingly impact hardware design automation, there's a growing need for tools that
integrate logic synthesis with ML workflows. aigverse provides a Python-friendly interface for logic synthesis, making
it easier to develop applications that blend both AI/ML and traditional circuit synthesis techniques. By building upon
the robust foundation of the EPFL Logic Synthesis Libraries, aigverse delivers powerful logic manipulation
capabilities while maintaining accessibility through its Python interface. With aigverse, you can parse, manipulate,
and optimize logic circuits directly from Python. We aim to provide seamless integration with popular ML
libraries, enabling the development of novel AI-driven synthesis and optimization tools.
aigverse is built using the EPFL Logic Synthesis Libraries with pybind11.
It is available via PyPI for all major operating systems and supports Python 3.10 to 3.14 (with
optional free-threading for 3.13 and 3.14).
pip install aigverseTo keep the core library lightweight, machine learning integration adapters are not installed by default. These adapters
enable seamless conversion of AIGs to graph and array formats for use with ML and data science libraries (such as
NetworkX, NumPy, etc.). To install aigverse with the adapters extra,
use:
pip install "aigverse[adapters]"This will install additional dependencies required for ML workflows. See the documentation for more details.
The following gives a shallow overview on aigverse. Detailed documentation and examples are available at
ReadTheDocs.
In aigverse, you can create a simple And-Inverter Graph (AIG) and manipulate it using various logic operations.
from aigverse import Aig
# Create a new AIG network
aig = Aig()
# Create primary inputs
x1 = aig.create_pi()
x2 = aig.create_pi()
# Create logic gates
f_and = aig.create_and(x1, x2) # AND gate
f_or = aig.create_or(x1, x2) # OR gate
# Create primary outputs
aig.create_po(f_and)
aig.create_po(f_or)
# Print the size of the AIG network
print(f"AIG Size: {aig.size()}")Note that all primary inputs (PIs) must be created before any logic gates.
You can iterate over all nodes in the AIG, or specific subsets like the primary inputs or only logic nodes (gates).
# Iterate over all nodes in the AIG
for node in aig.nodes():
print(f"Node: {node}")
# Iterate only over primary inputs
for pi in aig.pis():
print(f"Primary Input: {pi}")
# Iterate only over logic nodes (gates)
for gate in aig.gates():
print(f"Gate: {gate}")
# Iterate over the fanins of a node
n_and = aig.get_node(f_and)
for fanin in aig.fanins(n_and):
print(f"Fanin of {n_and}: {fanin}")Named AIGs allow you to assign human-readable names to the network, inputs, outputs, and internal signals.
from aigverse import NamedAig
# Create a named AIG
named_aig = NamedAig()
named_aig.set_network_name("full_adder")
# Create named primary inputs and logic
a = named_aig.create_pi("a")
b = named_aig.create_pi("b")
cin = named_aig.create_pi("cin")
sum = named_aig.create_xor3(a, b, cin)
carry = named_aig.create_maj(a, b, cin)
# Assign names to signals and create named outputs
named_aig.set_name(sum, "sum")
named_aig.create_po(carry, "carry_output")
# Retrieve names
print(f"Network: {named_aig.get_network_name()}")
print(f"Signal: {named_aig.get_name(sum)}")Named AIGs are automatically created when reading Verilog or AIGER files with naming information.
You can compute the depth of the AIG network and the level of each node. Depth information is useful for estimating the critical path delay of a respective circuit.
from aigverse import DepthAig
depth_aig = DepthAig(aig)
print(f"Depth: {depth_aig.num_levels()}")
for node in aig.nodes():
print(f"Level of {node}: {depth_aig.level(node)}")If needed, you can retrieve the fanouts of AIG nodes as well:
from aigverse import FanoutAig
fanout_aig = FanoutAig(aig)
n_and = aig.get_node(f_and)
# Iterate over the fanouts of a node
for fanout in fanout_aig.fanouts(n_and):
print(f"Fanout of node {n_and}: {fanout}")aigverse also supports sequential AIGs, which are AIGs with registers.
from aigverse import SequentialAig
seq_aig = SequentialAig()
x1 = seq_aig.create_pi() # Regular PI
x2 = seq_aig.create_ro() # Register output (sequential PI)
f_and = seq_aig.create_and(x1, x2) # AND gate
seq_aig.create_ri(f_and) # Register input (sequential PO)
print(seq_aig.registers()) # Prints the association of registersIt is to be noted that the construction of sequential AIGs comes with some caveats:
- All register outputs (ROs) must be created after all primary inputs (PIs).
- All register inputs (RIs) must be created after all primary outputs (POs).
- As for regular AIGs, all PIs and ROs must be created before any logic gates.
You can optimize AIGs using various algorithms. For example, you can perform resubstitution to simplify logic using shared divisors. Similarly, refactoring collapses maximal fanout-free cones (MFFCs) into truth tables and resynthesizes them into new structures. Cut rewriting optimizes the AIG by replacing cuts with improved ones from a pre-computed NPN database. Finally, balancing performs (E)SOP factoring to minimize the number of levels in the AIG.
from aigverse import aig_resubstitution, sop_refactoring, aig_cut_rewriting, balancing
# Clone the AIG network for size comparison
aig_clone = aig.clone()
# Optimize the AIG with several optimization algorithms
for optimization in [aig_resubstitution, sop_refactoring, aig_cut_rewriting, balancing]:
optimization(aig)
# Print the size of the unoptimized and optimized AIGs
print(f"Original AIG Size: {aig_clone.size()}")
print(f"Optimized AIG Size: {aig.size()}")Equivalence of AIGs (e.g., after optimization) can be checked using SAT-based equivalence checking.
from aigverse import equivalence_checking
# Perform equivalence checking
equiv = equivalence_checking(aig1, aig2)
if equiv:
print("AIGs are equivalent!")
else:
print("AIGs are NOT equivalent!")You can read and write AIGs in various file formats, including (ASCII) AIGER, gate-level Verilog and PLA.
from aigverse import write_aiger, write_verilog, write_dot
# Write an AIG network to an AIGER file
write_aiger(aig, "example.aig")
# Write an AIG network to a Verilog file
write_verilog(aig, "example.v")
# Write an AIG network to a DOT file
write_dot(aig, "example.dot")from aigverse import (
read_aiger_into_aig,
read_ascii_aiger_into_aig,
read_verilog_into_aig,
read_pla_into_aig,
)
# Read AIGER files into AIG networks
aig1 = read_aiger_into_aig("example.aig")
aig2 = read_ascii_aiger_into_aig("example.aag")
# Read a Verilog file into an AIG network
aig3 = read_verilog_into_aig("example.v")
# Read a PLA file into an AIG network
aig4 = read_pla_into_aig("example.pla")Additionally, you can read AIGER files into sequential AIGs using read_aiger_into_sequential_aig and
read_ascii_aiger_into_sequential_aig.
AIGs support Python's pickle protocol, allowing you to serialize and deserialize AIG objects for persistent storage or
interface with data science or machine learning workflows.
import pickle
with open("aig.pkl", "wb") as f:
pickle.dump(aig, f)
with open("aig.pkl", "rb") as f:
unpickled_aig = pickle.load(f)You can also pickle multiple AIGs at once by storing them in a tuple or list.
With the adapters extra, you can convert an AIG to a NetworkX directed graph, enabling
visualization and use with graph-based ML tools:
import aigverse.adapters
G = aig.to_networkx(levels=True, fanouts=True, node_tts=True)Graph, node, and edge attributes provide logic, level, fanout, and function information for downstream ML or visualization tasks.
For more details and examples, see the machine learning integration documentation.
Small Boolean functions can be efficiently represented using truth tables. aigverse enables the creation and
manipulation of truth tables by wrapping a portion of the kitty library.
from aigverse import TruthTable
# Initialize a truth table with 3 variables
tt = TruthTable(3)
# Create a truth table from a hex string representing the MAJ function
tt.create_from_hex_string("e8")# Flip each bit in the truth table
for i in range(tt.num_bits()):
print(f"Flipping bit {int(tt.get_bit(i))}")
tt.flip_bit(i)
# Print a binary string representation of the truth table
print(tt.to_binary())
# Clear the truth table
tt.clear()
# Check if the truth table is constant 0
print(tt.is_const0())from aigverse import simulate, simulate_nodes
# Obtain the truth table of each AIG output
tts = simulate(aig)
# Print the truth tables
for i, tt in enumerate(tts):
print(f"PO{i}: {tt.to_binary()}")
# Obtain the truth tables of each node in the AIG
n_to_tt = simulate_nodes(aig)
# Print the truth tables of each node
for node, tt in n_to_tt.items():
print(f"Node {node}: {tt.to_binary()}")For machine learning applications, it is often useful to convert truth tables into standard data structures like Python
lists or NumPy arrays. Since TruthTable objects are iterable, conversion is straightforward.
import numpy as np
# Export to a list
tt_list = list(tt)
# Export to NumPy arrays
tt_np_bool = np.array(tt)
tt_np_int = np.array(tt, dtype=np.int32)
tt_np_float = np.array(tt, dtype=np.float64)Truth tables also support Python's pickle protocol, allowing you to serialize and deserialize them.
import pickle
with open("tt.pkl", "wb") as f:
pickle.dump(tt, f)
with open("tt.pkl", "rb") as f:
unpickled_tt = pickle.load(f)For a deeper dive into the vision and technical details behind aigverse, check out the presentation from the
Free Silicon Conference (FSiC) 2025:
"aigverse: Toward machine learning-driven logic synthesis" 📄 Slides available on the FSiC wiki
This talk covers the motivation, architecture, and future directions of aigverse as an infrastructure project for
bringing machine learning to logic synthesis.
Contributions are welcome! If you'd like to contribute to aigverse, please see the
contribution guide. I appreciate feedback and suggestions
for improving the library.
aigverse is and will always be a free, open-source library. If you or your organization require dedicated support,
specific new features, or integration of aigverse into your projects, professional consulting services are available.
This is a great way to get the features you need while also supporting the ongoing maintenance and development of the
library.
For inquiries, please reach out to @marcelwa. More information can be found in the documentation.
aigverse is available under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aigverse
Similar Open Source Tools
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.
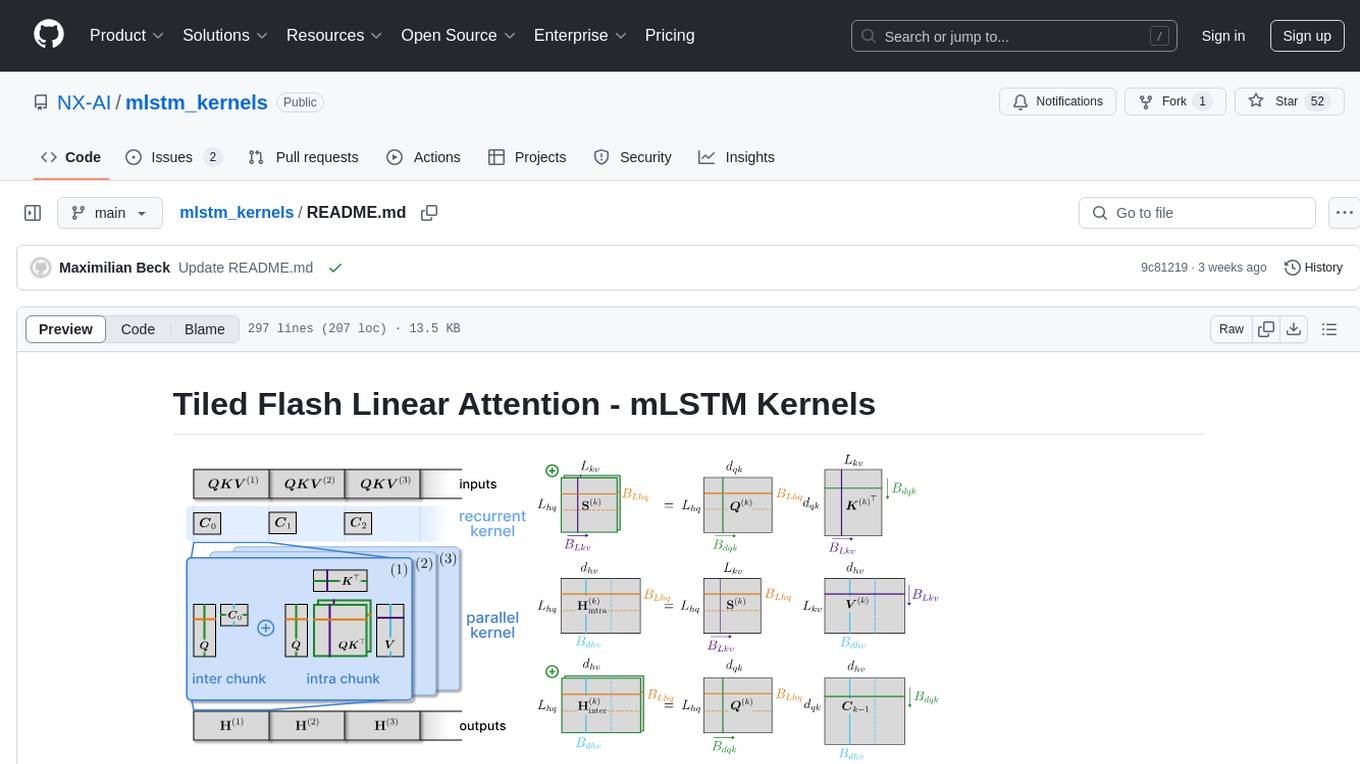
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
neural-speed
Neural Speed is an innovative library designed to support the efficient inference of large language models (LLMs) on Intel platforms through the state-of-the-art (SOTA) low-bit quantization powered by Intel Neural Compressor. The work is inspired by llama.cpp and further optimized for Intel platforms with our innovations in NeurIPS' 2023
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
inspectus
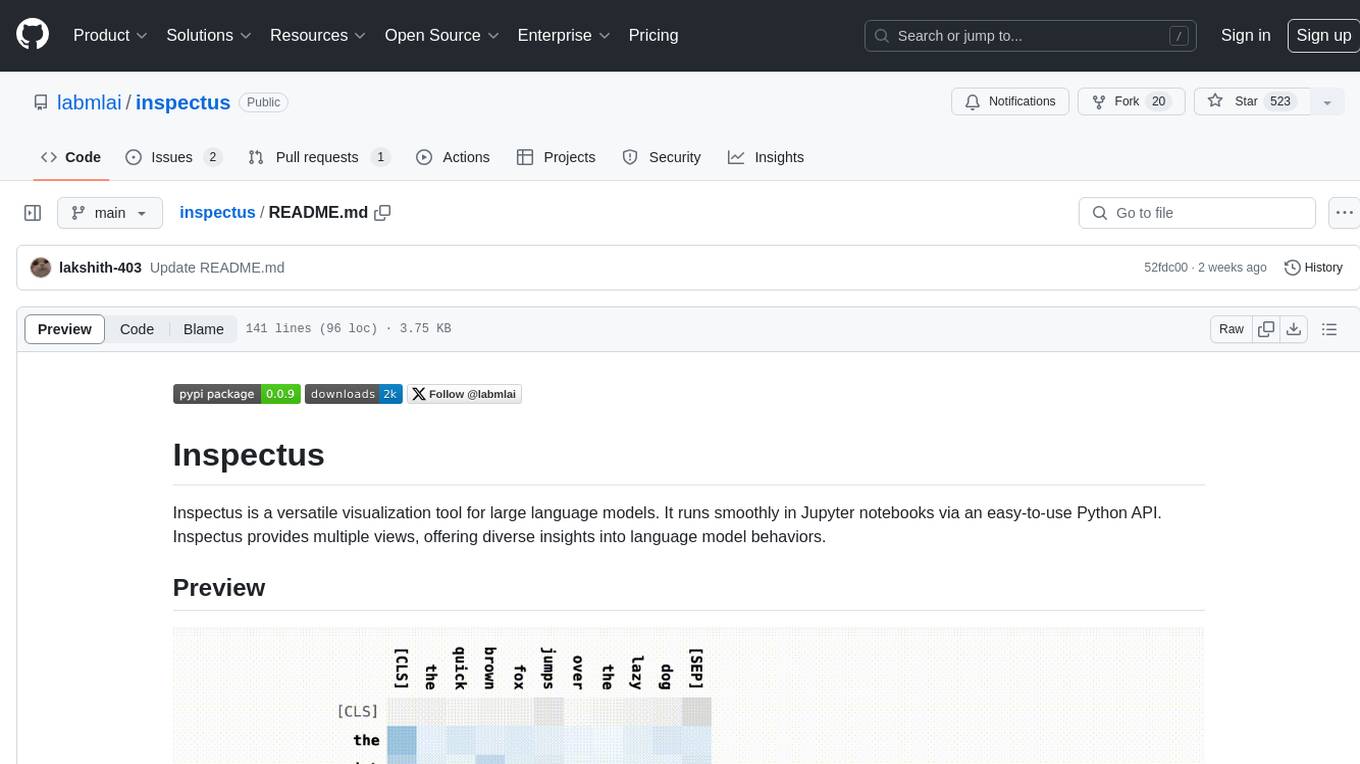
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.
For similar tasks
neo
The neo is an open source robotics research platform powered by a OnePlus 3 smartphone and an STM32F205-based CAN interface board, housed in a 3d-printed casing with active cooling. It includes NEOS, a stripped down Android ROM, and offers a modern Linux environment for development. The platform leverages the high performance embedded processor and sensor capabilities of modern smartphones at a low cost. A detailed guide is available for easy construction, requiring online shopping and soldering skills. The total cost for building a neo is approximately $700.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
For similar jobs
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.