
topicGPT
TopicGPT: A Prompt-Based Framework for Topic Modeling (NAACL'24)
Stars: 269
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.
README:
This repository contains scripts and prompts for our paper "TopicGPT: Topic Modeling by Prompting Large Language Models" (NAACL'24). Our topicgpt_python package consists of five main functions:
-
generate_topic_lvl1generates high-level and generalizable topics. -
generate_topic_lvl2generates low-level and specific topics to each high-level topic. -
refine_topicsrefines the generated topics by merging similar topics and removing irrelevant topics. -
assign_topicsassigns the generated topics to the input text, along with a quote that supports the assignment. -
correct_topicscorrects the generated topics by reprompting the model so that the final topic assignment is grounded in the topic list.

- [11/09/24] Python package
topicgpt_pythonis released! You can install it viapip install topicgpt_python. We support OpenAI API, VertexAI, Azure API, Gemini API, and vLLM (requires GPUs for inference). See PyPI. - [11/18/23] Second-level topic generation code and refinement code are uploaded.
- [11/11/23] Basic pipeline is uploaded. Refinement and second-level topic generation code are coming soon.
- Make a new Python 3.9+ environment using virtualenv or conda.
- Install the required packages:
pip install topicgpt_python
- Set your API key:
# Run in shell # Needed only for the OpenAI API deployment export OPENAI_API_KEY={your_openai_api_key} # Needed only for the Vertex AI deployment export VERTEX_PROJECT={your_vertex_project} # e.g. my-project export VERTEX_LOCATION={your_vertex_location} # e.g. us-central1 # Needed only for Gemini deployment export GEMINI_API_KEY={your_gemini_api_key} # Needed only for the Azure API deployment export AZURE_OPENAI_API_KEY={your_azure_api_key} export AZURE_OPENAI_ENDPOINT={your_azure_endpoint} - Refer to https://openai.com/pricing/ for OpenAI API pricing or to https://cloud.google.com/vertex-ai/pricing for Vertex API pricing.
- Prepare your
.jsonldata file in the following format:{ "id": "IDs (optional)", "text": "Documents", "label": "Ground-truth labels (optional)" } - Put your data file in
data/input. There is also a sample data filedata/input/sample.jsonlto debug the code. - Raw dataset used in the paper (Bills and Wiki): [link].
Check out demo.ipynb for a complete pipeline and more detailed instructions. We advise you to try running on a subset with cheaper (or open-source) models first before scaling up to the entire dataset.
-
(Optional) Define I/O paths in
config.ymland load using:import yaml with open("config.yml", "r") as f: config = yaml.safe_load(f)
-
Load the package:
from topicgpt_python import *
-
Generate high-level topics:
generate_topic_lvl1(api, model, data, prompt_file, seed_file, out_file, topic_file, verbose)
-
Generate low-level topics (optional)
generate_topic_lvl2(api, model, seed_file, data, prompt_file, out_file, topic_file, verbose)
-
Refine the generated topics by merging near duplicates and removing topics with low frequency (optional):
refine_topics(api, model, prompt_file, generation_file, topic_file, out_file, updated_file, verbose, remove, mapping_file)
-
Assign and correct the topics, usually with a weaker model if using paid APIs to save cost:
assign_topics( api, model, data, prompt_file, out_file, topic_file, verbose )
correct_topics( api, model, data_path, prompt_path, topic_path, output_path, verbose ) -
Check out the
data/outputfolder for sample outputs. -
We also offer metric calculation functions in
topicgpt_python.metricsto evaluate the alignment between the generated topics and the ground-truth labels (Adjusted Rand Index, Harmonic Purity, and Normalized Mutual Information).
@misc{pham2023topicgpt,
title={TopicGPT: A Prompt-based Topic Modeling Framework},
author={Chau Minh Pham and Alexander Hoyle and Simeng Sun and Mohit Iyyer},
year={2023},
eprint={2311.01449},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for topicGPT
Similar Open Source Tools
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.
raptor
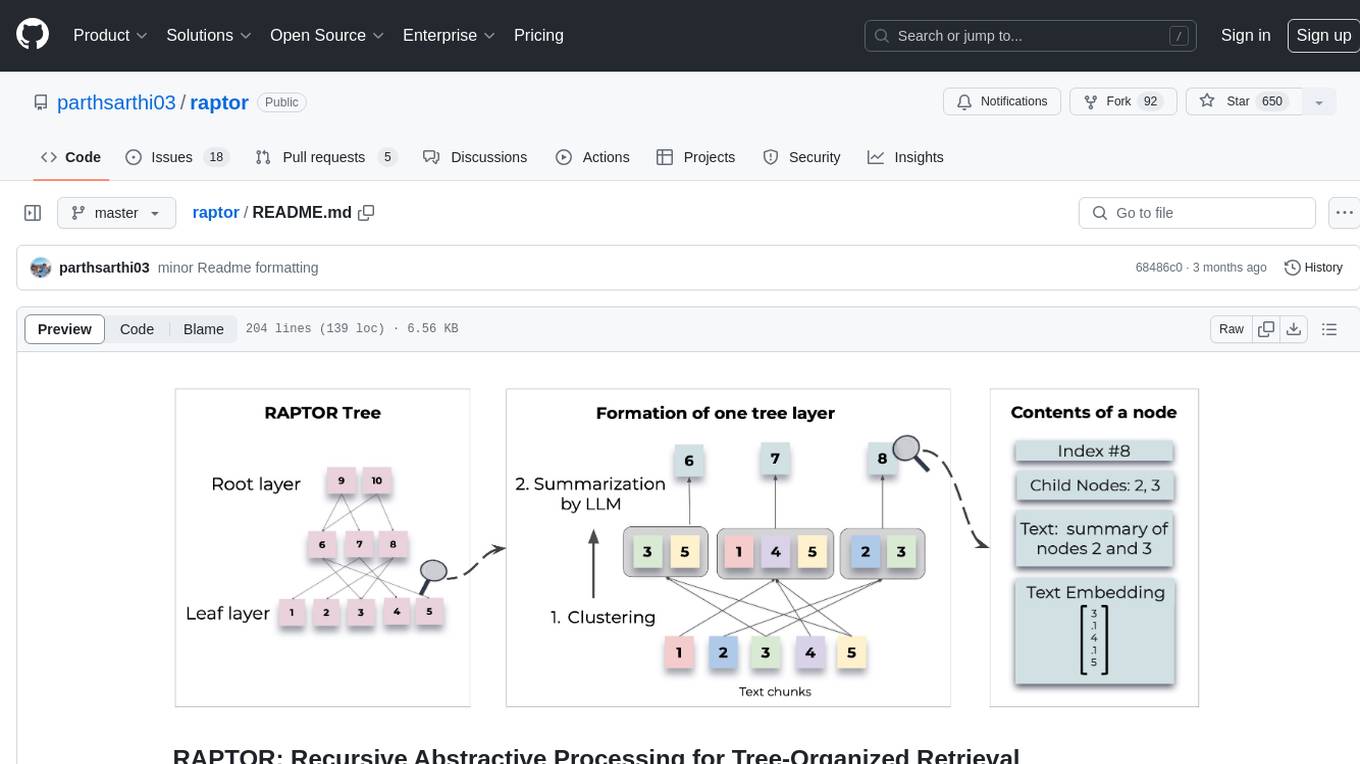
RAPTOR introduces a novel approach to retrieval-augmented language models by constructing a recursive tree structure from documents. This allows for more efficient and context-aware information retrieval across large texts, addressing common limitations in traditional language models. Users can add documents to the tree, answer questions based on indexed documents, save and load the tree, and extend RAPTOR with custom summarization, question-answering, and embedding models. The tool is designed to be flexible and customizable for various NLP tasks.
openai-agents-python
The OpenAI Agents SDK is a lightweight framework for building multi-agent workflows. It includes concepts like Agents, Handoffs, Guardrails, and Tracing to facilitate the creation and management of agents. The SDK is compatible with any model providers supporting the OpenAI Chat Completions API format. It offers flexibility in modeling various LLM workflows and provides automatic tracing for easy tracking and debugging of agent behavior. The SDK is designed for developers to create deterministic flows, iterative loops, and more complex workflows.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
llmgraph
llmgraph is a tool that enables users to create knowledge graphs in GraphML, GEXF, and HTML formats by extracting world knowledge from large language models (LLMs) like ChatGPT. It supports various entity types and relationships, offers cache support for efficient graph growth, and provides insights into LLM costs. Users can customize the model used and interact with different LLM providers. The tool allows users to generate interactive graphs based on a specified entity type and Wikipedia link, making it a valuable resource for knowledge graph creation and exploration.
POPPER
Popper is an agentic framework for automated validation of free-form hypotheses using Large Language Models (LLMs). It follows Karl Popper's principle of falsification and designs falsification experiments to validate hypotheses. Popper ensures strict Type-I error control and actively gathers evidence from diverse observations. It delivers robust error control, high power, and scalability across various domains like biology, economics, and sociology. Compared to human scientists, Popper achieves comparable performance in validating complex biological hypotheses while reducing time by 10 folds, providing a scalable, rigorous solution for hypothesis validation.
KVCache-Factory
KVCache-Factory is a unified framework for KV Cache compression of diverse models. It supports multi-GPUs inference with big LLMs and various attention implementations. The tool enables KV cache compression without Flash Attention v2, multi-GPU inference, and specific models like Mistral. It also provides functions for KV cache budget allocation and batch inference. The visualization tools help in understanding the attention patterns of models.
For similar tasks
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.
For similar jobs

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.
mslearn-ai-fundamentals
This repository contains materials for the Microsoft Learn AI Fundamentals module. It covers the basics of artificial intelligence, machine learning, and data science. The content includes hands-on labs, interactive learning modules, and assessments to help learners understand key concepts and techniques in AI. Whether you are new to AI or looking to expand your knowledge, this module provides a comprehensive introduction to the fundamentals of AI.

awesome-ai-tools
Awesome AI Tools is a curated list of popular tools and resources for artificial intelligence enthusiasts. It includes a wide range of tools such as machine learning libraries, deep learning frameworks, data visualization tools, and natural language processing resources. Whether you are a beginner or an experienced AI practitioner, this repository aims to provide you with a comprehensive collection of tools to enhance your AI projects and research. Explore the list to discover new tools, stay updated with the latest advancements in AI technology, and find the right resources to support your AI endeavors.
go2coding.github.io
The go2coding.github.io repository is a collection of resources for AI enthusiasts, providing information on AI products, open-source projects, AI learning websites, and AI learning frameworks. It aims to help users stay updated on industry trends, learn from community projects, access learning resources, and understand and choose AI frameworks. The repository also includes instructions for local and external deployment of the project as a static website, with details on domain registration, hosting services, uploading static web pages, configuring domain resolution, and a visual guide to the AI tool navigation website. Additionally, it offers a platform for AI knowledge exchange through a QQ group and promotes AI tools through a WeChat public account.
AI-Notes
AI-Notes is a repository dedicated to practical applications of artificial intelligence and deep learning. It covers concepts such as data mining, machine learning, natural language processing, and AI. The repository contains Jupyter Notebook examples for hands-on learning and experimentation. It explores the development stages of AI, from narrow artificial intelligence to general artificial intelligence and superintelligence. The content delves into machine learning algorithms, deep learning techniques, and the impact of AI on various industries like autonomous driving and healthcare. The repository aims to provide a comprehensive understanding of AI technologies and their real-world applications.
promptpanel
Prompt Panel is a tool designed to accelerate the adoption of AI agents by providing a platform where users can run large language models across any inference provider, create custom agent plugins, and use their own data safely. The tool allows users to break free from walled-gardens and have full control over their models, conversations, and logic. With Prompt Panel, users can pair their data with any language model, online or offline, and customize the system to meet their unique business needs without any restrictions.
ai-demos
The 'ai-demos' repository is a collection of example code from presentations focusing on building with AI and LLMs. It serves as a resource for developers looking to explore practical applications of artificial intelligence in their projects. The code snippets showcase various techniques and approaches to leverage AI technologies effectively. The repository aims to inspire and educate developers on integrating AI solutions into their applications.
ai_summer
AI Summer is a repository focused on providing workshops and resources for developing foundational skills in generative AI models and transformer models. The repository offers practical applications for inferencing and training, with a specific emphasis on understanding and utilizing advanced AI chat models like BingGPT. Participants are encouraged to engage in interactive programming environments, decide on projects to work on, and actively participate in discussions and breakout rooms. The workshops cover topics such as generative AI models, retrieval-augmented generation, building AI solutions, and fine-tuning models. The goal is to equip individuals with the necessary skills to work with AI technologies effectively and securely, both locally and in the cloud.