
raft
RAFT contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
Stars: 984
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
README:

- Useful Resources
- What is RAFT?
- Use cases
- Is RAFT right for me?
- Getting Started
- Installing RAFT
- Codebase structure and contents
- Contributing
- References
- RAFT Reference Documentation: API Documentation.
- RAFT Getting Started: Getting started with RAFT.
- Build and Install RAFT: Instructions for installing and building RAFT.
- RAPIDS Community: Get help, contribute, and collaborate.
- GitHub repository: Download the RAFT source code.
- Issue tracker: Report issues or request features.
RAFT contains fundamental widely-used algorithms and primitives for machine learning and data mining. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
By taking a primitives-based approach to algorithm development, RAFT
- accelerates algorithm construction time
- reduces the maintenance burden by maximizing reuse across projects, and
- centralizes core reusable computations, allowing future optimizations to benefit all algorithms that use them.
While not exhaustive, the following general categories help summarize the accelerated functions in RAFT:
| Category | Accelerated Functions in RAFT |
|---|---|
| Data Formats | sparse & dense, conversions, data generation |
| Dense Operations | linear algebra, matrix and vector operations, reductions, slicing, norms, factorization, least squares, svd & eigenvalue problems |
| Sparse Operations | linear algebra, eigenvalue problems, slicing, norms, reductions, factorization, symmetrization, components & labeling |
| Solvers | combinatorial optimization, iterative solvers |
| Statistics | sampling, moments and summary statistics, metrics, model evaluation |
| Tools & Utilities | common tools and utilities for developing CUDA applications, multi-node multi-gpu infrastructure |
RAFT is a C++ header-only template library with an optional shared library that
- can speed up compile times for common template types, and
- provides host-accessible "runtime" APIs, which don't require a CUDA compiler to use
In addition being a C++ library, RAFT also provides 2 Python libraries:
-
pylibraft- lightweight Python wrappers around RAFT's host-accessible "runtime" APIs. -
raft-dask- multi-node multi-GPU communicator infrastructure for building distributed algorithms on the GPU with Dask.

RAFT contains low-level primitives for accelerating applications and workflows. Data source providers and application developers may find specific tools very useful. RAFT is not intended to be used directly by data scientists for discovery and experimentation. For data science tools, please see the RAPIDS website.
RAFT relies heavily on RMM which eases the burden of configuring different allocation strategies globally across the libraries that use it.
The APIs in RAFT accept the mdspan multi-dimensional array view for representing data in higher dimensions similar to the ndarray in the Numpy Python library. RAFT also contains the corresponding owning mdarray structure, which simplifies the allocation and management of multi-dimensional data in both host and device (GPU) memory.
The mdarray forms a convenience layer over RMM and can be constructed in RAFT using a number of different helper functions:
#include <raft/core/device_mdarray.hpp>
int n_rows = 10;
int n_cols = 10;
auto scalar = raft::make_device_scalar<float>(handle, 1.0);
auto vector = raft::make_device_vector<float>(handle, n_cols);
auto matrix = raft::make_device_matrix<float>(handle, n_rows, n_cols);Most of the primitives in RAFT accept a raft::device_resources object for the management of resources which are expensive to create, such CUDA streams, stream pools, and handles to other CUDA libraries like cublas and cusolver.
The example below demonstrates creating a RAFT handle and using it with device_matrix and device_vector to allocate memory, generating random clusters, and computing
pairwise Euclidean distances with the NVIDIA cuVS library:
#include <raft/core/device_resources.hpp>
#include <raft/core/device_mdspan.hpp>
#include <raft/random/make_blobs.cuh>
#include <cuvs/distance/distance.hpp>
raft::device_resources handle;
int n_samples = 5000;
int n_features = 50;
float *input;
int *labels;
float *output;
...
// Allocate input, labels, and output pointers
...
auto input_view = raft::make_device_matrix_view(input, n_samples, n_features);
auto labels_view = raft::make_device_vector_view(labels, n_samples);
auto output_view = raft::make_device_matrix_view(output, n_samples, n_samples);
raft::random::make_blobs(handle, input_view, labels_view);
auto metric = cuvs::distance::DistanceType::L2SqrtExpanded;
cuvs::distance::pairwise_distance(handle, input_view, input_view, output_view, metric);The pylibraft package contains a Python API for RAFT algorithms and primitives. pylibraft integrates nicely into other libraries by being very lightweight with minimal dependencies and accepting any object that supports the __cuda_array_interface__, such as CuPy's ndarray. The number of RAFT algorithms exposed in this package is continuing to grow from release to release.
The example below demonstrates computing the pairwise Euclidean distances between CuPy arrays using the NVIDIA cuVS library. Note that CuPy is not a required dependency for pylibraft.
import cupy as cp
from cuvs.distance import pairwise_distance
n_samples = 5000
n_features = 50
in1 = cp.random.random_sample((n_samples, n_features), dtype=cp.float32)
in2 = cp.random.random_sample((n_samples, n_features), dtype=cp.float32)
output = pairwise_distance(in1, in2, metric="euclidean")The output array in the above example is of type raft.common.device_ndarray, which supports cuda_array_interface making it interoperable with other libraries like CuPy, Numba, PyTorch and RAPIDS cuDF that also support it. CuPy supports DLPack, which also enables zero-copy conversion from raft.common.device_ndarray to JAX and Tensorflow.
Below is an example of converting the output pylibraft.device_ndarray to a CuPy array:
cupy_array = cp.asarray(output)And converting to a PyTorch tensor:
import torch
torch_tensor = torch.as_tensor(output, device='cuda')Or converting to a RAPIDS cuDF dataframe:
cudf_dataframe = cudf.DataFrame(output)When the corresponding library has been installed and available in your environment, this conversion can also be done automatically by all RAFT compute APIs by setting a global configuration option:
import pylibraft.config
pylibraft.config.set_output_as("cupy") # All compute APIs will return cupy arrays
pylibraft.config.set_output_as("torch") # All compute APIs will return torch tensorsYou can also specify a callable that accepts a pylibraft.common.device_ndarray and performs a custom conversion. The following example converts all output to numpy arrays:
pylibraft.config.set_output_as(lambda device_ndarray: return device_ndarray.copy_to_host())pylibraft also supports writing to a pre-allocated output array so any __cuda_array_interface__ supported array can be written to in-place:
import cupy as cp
from cuvs.distance import pairwise_distance
n_samples = 5000
n_features = 50
in1 = cp.random.random_sample((n_samples, n_features), dtype=cp.float32)
in2 = cp.random.random_sample((n_samples, n_features), dtype=cp.float32)
output = cp.empty((n_samples, n_samples), dtype=cp.float32)
pairwise_distance(in1, in2, out=output, metric="euclidean")RAFT's C++ and Python libraries can both be installed through Conda and the Python libraries through Pip.
The easiest way to install RAFT is through conda and several packages are provided.
-
libraft-headersC++ headers -
pylibraft(optional) Python library -
raft-dask(optional) Python library for deployment of multi-node multi-GPU algorithms that use the RAFTraft::commsabstraction layer in Dask clusters.
Use the following command, depending on your CUDA version, to install all of the RAFT packages with conda (replace rapidsai with rapidsai-nightly to install more up-to-date but less stable nightly packages). mamba is preferred over the conda command.
# CUDA 13
mamba install -c rapidsai -c conda-forge raft-dask pylibraft cuda-version=13.1
# CUDA 12
mamba install -c rapidsai -c conda-forge raft-dask pylibraft cuda-version=12.9Note that the above commands will also install libraft-headers and libraft.
You can also install the conda packages individually using the mamba command above. For example, if you'd like to install RAFT's headers and pre-compiled shared library to use in your project:
# CUDA 13
mamba install -c rapidsai -c conda-forge libraft libraft-headers cuda-version=13.1
# CUDA 12
mamba install -c rapidsai -c conda-forge libraft libraft-headers cuda-version=12.9pylibraft and raft-dask both have experimental packages that can be installed through pip:
# CUDA 13
pip install pylibraft-cu13
pip install raft-dask-cu13
# CUDA 12
pip install pylibraft-cu12
pip install raft-dask-cu12These packages statically build RAFT's pre-compiled instantiations and so the C++ headers won't be readily available to use in your code.
The build instructions contain more details on building RAFT from source and including it in downstream projects. You can also find a more comprehensive version of the above CPM code snippet the Building RAFT C++ and Python from source section of the build instructions.
If you are interested in contributing to the RAFT project, please read our Contributing guidelines. Refer to the Developer Guide for details on the developer guidelines, workflows, and principals.
When citing RAFT generally, please consider referencing this Github project.
@misc{rapidsai,
title={Rapidsai/raft: RAFT contains fundamental widely-used algorithms and primitives for data science, Graph and machine learning.},
url={https://github.com/rapidsai/raft},
journal={GitHub},
publisher={NVIDIA RAPIDS},
author={Rapidsai},
year={2022}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for raft
Similar Open Source Tools
raft
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
lantern
Lantern is an open-source PostgreSQL database extension designed to store vector data, generate embeddings, and handle vector search operations efficiently. It introduces a new index type called 'lantern_hnsw' for vector columns, which speeds up 'ORDER BY ... LIMIT' queries. Lantern utilizes the state-of-the-art HNSW implementation called usearch. Users can easily install Lantern using Docker, Homebrew, or precompiled binaries. The tool supports various distance functions, index construction parameters, and operator classes for efficient querying. Lantern offers features like embedding generation, interoperability with pgvector, parallel index creation, and external index graph generation. It aims to provide superior performance metrics compared to other similar tools and has a roadmap for future enhancements such as cloud-hosted version, hardware-accelerated distance metrics, industry-specific application templates, and support for version control and A/B testing of embeddings.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.
torchtitan
Torchtitan is a PyTorch native platform designed for rapid experimentation and large-scale training of generative AI models. It provides a flexible foundation for developers to build upon with extension points for creating custom extensions. The tool showcases PyTorch's latest distributed training features and supports pretraining Llama 3.1 LLMs of various sizes. It offers key features like multi-dimensional parallelisms, FSDP2 with per-parameter sharding, Tensor Parallel, Pipeline Parallel, and more. Users can contribute to the tool through the experiments folder and core contributions guidelines. Installation can be done from source, nightly builds, or stable releases. The tool also supports training Llama 3.1 models and provides guidance on starting a training run and multi-node training. Citation information is available for referencing the tool in academic work, and the source code is under a BSD 3 license.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.

debug-gym
debug-gym is a text-based interactive debugging framework designed for debugging Python programs. It provides an environment where agents can interact with code repositories, use various tools like pdb and grep to investigate and fix bugs, and propose code patches. The framework supports different LLM backends such as OpenAI, Azure OpenAI, and Anthropic. Users can customize tools, manage environment states, and run agents to debug code effectively. debug-gym is modular, extensible, and suitable for interactive debugging tasks in a text-based environment.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.
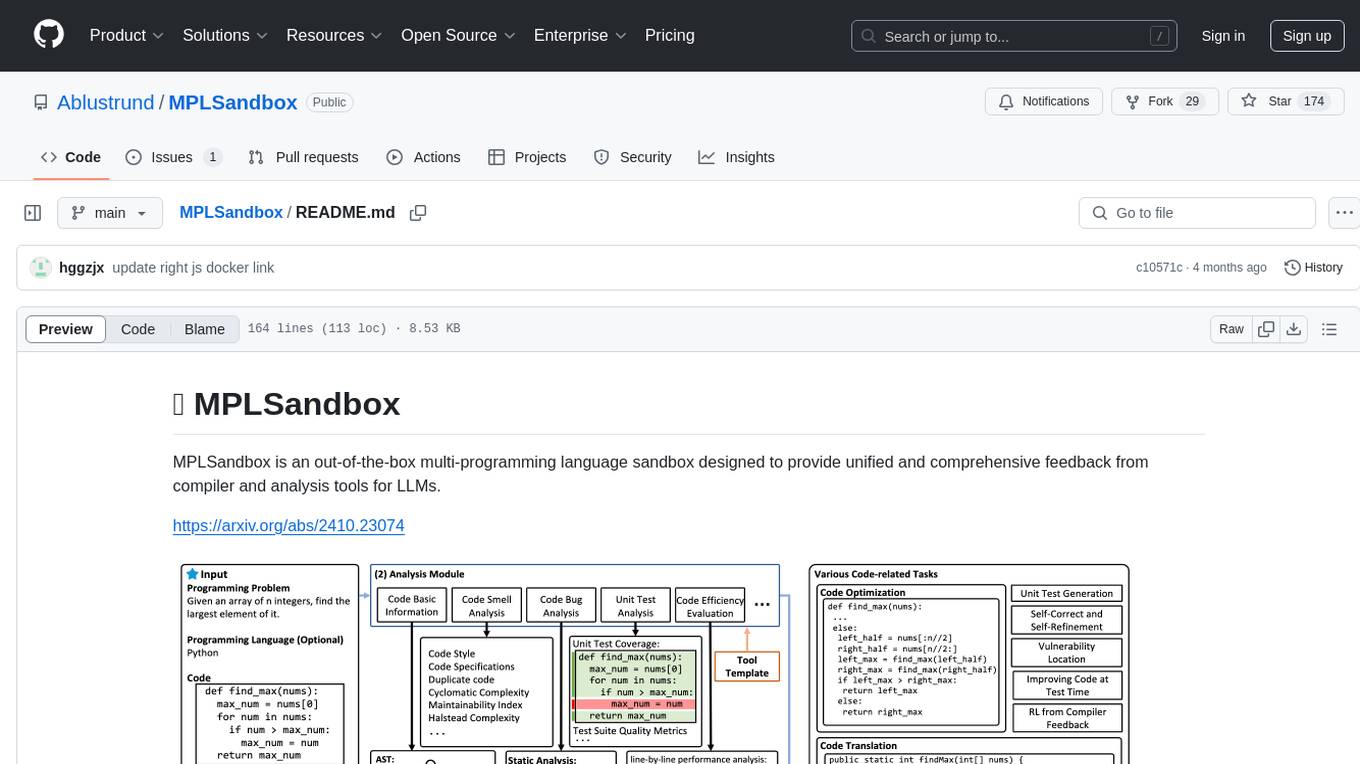
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.
fsdp_qlora
The fsdp_qlora repository provides a script for training Large Language Models (LLMs) with Quantized LoRA and Fully Sharded Data Parallelism (FSDP). It integrates FSDP+QLoRA into the Axolotl platform and offers installation instructions for dependencies like llama-recipes, fastcore, and PyTorch. Users can finetune Llama-2 70B on Dual 24GB GPUs using the provided command. The script supports various training options including full params fine-tuning, LoRA fine-tuning, custom LoRA fine-tuning, quantized LoRA fine-tuning, and more. It also discusses low memory loading, mixed precision training, and comparisons to existing trainers. The repository addresses limitations and provides examples for training with different configurations, including BnB QLoRA and HQQ QLoRA. Additionally, it offers SLURM training support and instructions for adding support for a new model.
For similar tasks
raft
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
vectordb-recipes
This repository contains examples, applications, starter code, & tutorials to help you kickstart your GenAI projects. * These are built using LanceDB, a free, open-source, serverless vectorDB that **requires no setup**. * It **integrates into python data ecosystem** so you can simply start using these in your existing data pipelines in pandas, arrow, pydantic etc. * LanceDB has **native Typescript SDK** using which you can **run vector search** in serverless functions! This repository is divided into 3 sections: - Examples - Get right into the code with minimal introduction, aimed at getting you from an idea to PoC within minutes! - Applications - Ready to use Python and web apps using applied LLMs, VectorDB and GenAI tools - Tutorials - A curated list of tutorials, blogs, Colabs and courses to get you started with GenAI in greater depth.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.
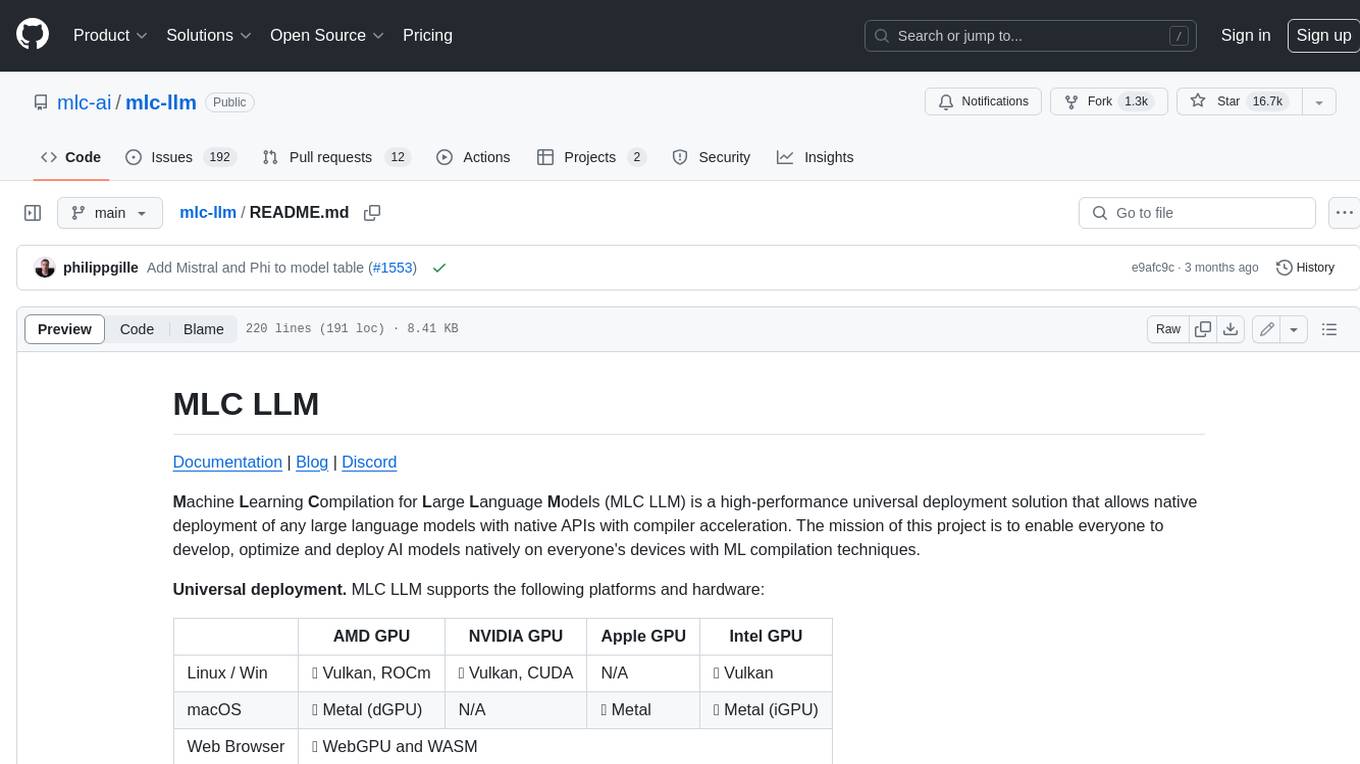
mlc-llm
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.
DataFrame
DataFrame is a C++ analytical library designed for data analysis similar to libraries in Python and R. It allows you to slice, join, merge, group-by, and perform various statistical, summarization, financial, and ML algorithms on your data. DataFrame also includes a large collection of analytical algorithms in form of visitors, ranging from basic stats to more involved analysis. You can easily add your own algorithms as well. DataFrame employs extensive multithreading in almost all its APIs, making it suitable for analyzing large datasets. Key principles followed in the library include supporting any type without needing new code, avoiding pointer chasing, having all column data in contiguous memory space, minimizing space usage, avoiding data copying, using multi-threading judiciously, and not protecting the user against garbage in, garbage out.
Awesome-LLM-Long-Context-Modeling
This repository includes papers and blogs about Efficient Transformers, Length Extrapolation, Long Term Memory, Retrieval Augmented Generation(RAG), and Evaluation for Long Context Modeling.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.