
telemetry-airflow
Airflow configuration for Telemetry
Stars: 185

This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)
README:
Apache Airflow is a platform to programmatically author, schedule and monitor workflows.
- Telemetry-Airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow".
Some links relevant to users and developers of WTMO:
- The
dagsdirectory in this repository contains some custom DAG definitions - Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl
- The Data SRE team maintains a WTMO Developer Guide (behind SSO)
Forking workflow is required ONLY for contributors without write access.
This repo enforces Conventional Commit style via the Github action Semantic PRs.
See the Airflow's Best Practices guide to help you write DAGs.
⚠ Warning: Do not import resources from the dags directory in DAGs definition files ⚠
As an example, if you have dags/dag_a.py and dags/dag_b.py and want to use a helper
function in both DAG definition files, define the helper function in the utils directory
such as:
utils/helper.py
def helper_function():
return "Help"dags/dag_a.py
from airflow import DAG
from utils.helper import helper_function
with DAG("dag_a", ...):
...dags/dag_b.py
from airflow import DAG
from utils.helper import helper_function
with DAG("dag_b", ...):
...WTMO deployments use git-sync sidecars to synchronize DAG files from multiple repositories via telemetry-airflow-dags using git submodules. Git-sync sidecar pattern results in the following directory structure once deployed.
airflow
├─ dags
│ └── repo
│ └── telemetry-airflow-dags
│ ├── <submodule repo_a>
│ │ └── dags
│ │ └── <dag files>
│ ├── <submodule repo_b>
│ │ └── dags
│ │ └── <dag files>
│ └── <submodule repo_c>
│ └── dags
│ └── <dag files>
├─ utils
│ └── ...
└─ plugins
└── ...
Hence, defining helper_function() in dags/dag_a.py and
importing the function in dags/dag_b.py as from dags.dag_a import helper_function
will not work after deployment because of the directory structured required for
git-sync sidecars.
This app is built and deployed with
docker and
docker-compose.
Dependencies are managed with
pip-tools pip-compile.
You'll also need to install PostgreSQL to build the database container.
⚠ Make sure you use the right Python version. Refer to Dockerfile for current supported Python Version ⚠
You can install the project dependencies locally to run tests with Pytest. We use the official Airflow constraints file to simplify Airflow dependency management. Install dependencies locally using the following command:
make pip-install-localAdd new Python dependencies into requirements.in or requirements-dev.in then execute the following commands:
make pip-compile
make pip-install-localBuild Airflow image with
make buildAssuming you're using Docker for Docker Desktop for macOS, start the docker service, click the docker icon in the menu bar, click on preferences and change the available memory to 4GB.
To deploy the Airflow container on the docker engine, with its required dependencies, run:
make build
make upTasks often require credentials to access external credentials. For example, one may choose to store API keys in an Airflow connection or variable. These variables are sure to exist in production but are often not mirrored locally for logistical reasons. Providing a dummy variable is the preferred way to keep the local development environment up to date.
Update the resources/dev_variables.env and resources/dev_connections.env with appropriate strings to
prevent broken workflows.
You can now connect to your local Airflow web console at
http://localhost:8080/.
All DAGs are paused by default for local instances and our staging instance of Airflow. In order to submit a DAG via the UI, you'll need to toggle the DAG from "Off" to "On". You'll likely want to toggle the DAG back to "Off" as soon as your desired task starts running.
See https://go.corp.mozilla.com/wtmodev for more details.
make build && make up
make gke
When done:
make clean-gke
From there, connect to Airflow and enable your job.
Dataproc jobs run on a self-contained Dataproc cluster, created by Airflow.
To test these, jobs, you'll need a sandbox account and corresponding service account. For information on creating that, see "Testing GKE Jobs". Your service account will need Dataproc and GCS permissions (and BigQuery, if you're connecting to it). Note: Dataproc requires "Dataproc/Dataproc Worker" as well as Compute Admin permissions. You'll need to ensure that the Dataproc API is enabled in your sandbox project.
Ensure that your dataproc job has a configurable project to write to.
Set the project in the DAG entry to be configured based on development environment;
see the ltv.py job for an example of that.
From there, run the following:
make build && make up
./bin/add_gcp_creds $GOOGLE_APPLICATION_CREDENTIALS google_cloud_airflow_dataprocYou can then connect to Airflow locally. Enable your DAG and see that it runs correctly.
Some useful docker tricks for development and debugging:
make clean
# Remove any leftover docker volumes:
docker volume rm $(docker volume ls -qf dangling=true)
# Purge docker volumes (helps with postgres container failing to start)
# Careful, as this will purge all local volumes not used by at least one container.
docker volume pruneThis repository was structured to be deployed using the offical Airflow Helm Chart. See the Production Guide for best practices.
Production deployments are automatically triggered for every commit merged in the main branch.
Docker images are tagged using the git commit short SHA and automatically deployed.
Refer to the CI configuration for more details!
Non-production deployments are automatically triggered for every commit merged in the main branch.
Dev and Stage deployments use the latest image tag for deployments.
It is also possible to manually trigger the image building and pushing workflow manual-publish
by manually tagging a commit. This can be achieved using git on your local machine, or by creating a
pre-release GitHub Release with a tag
prefixed by dev- on a non-main branch commit.
Refer to the CI configuration and deployment repository for more details!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for telemetry-airflow
Similar Open Source Tools
telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.

honcho
Honcho is a platform for creating personalized AI agents and LLM powered applications for end users. The repository is a monorepo containing the server/API for managing database interactions and storing application state, along with a Python SDK. It utilizes FastAPI for user context management and Poetry for dependency management. The API can be run using Docker or manually by setting environment variables. The client SDK can be installed using pip or Poetry. The project is open source and welcomes contributions, following a fork and PR workflow. Honcho is licensed under the AGPL-3.0 License.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.
AgentIQ
AgentIQ is a flexible library designed to seamlessly integrate enterprise agents with various data sources and tools. It enables true composability by treating agents, tools, and workflows as simple function calls. With features like framework agnosticism, reusability, rapid development, profiling, observability, evaluation system, user interface, and MCP compatibility, AgentIQ empowers developers to move quickly, experiment freely, and ensure reliability across agent-driven projects.
frontend
Nuclia frontend apps and libraries repository contains various frontend applications and libraries for the Nuclia platform. It includes components such as Dashboard, Widget, SDK, Sistema (design system), NucliaDB admin, CI/CD Deployment, and Maintenance page. The repository provides detailed instructions on installation, dependencies, and usage of these components for both Nuclia employees and external developers. It also covers deployment processes for different components and tools like ArgoCD for monitoring deployments and logs. The repository aims to facilitate the development, testing, and deployment of frontend applications within the Nuclia ecosystem.
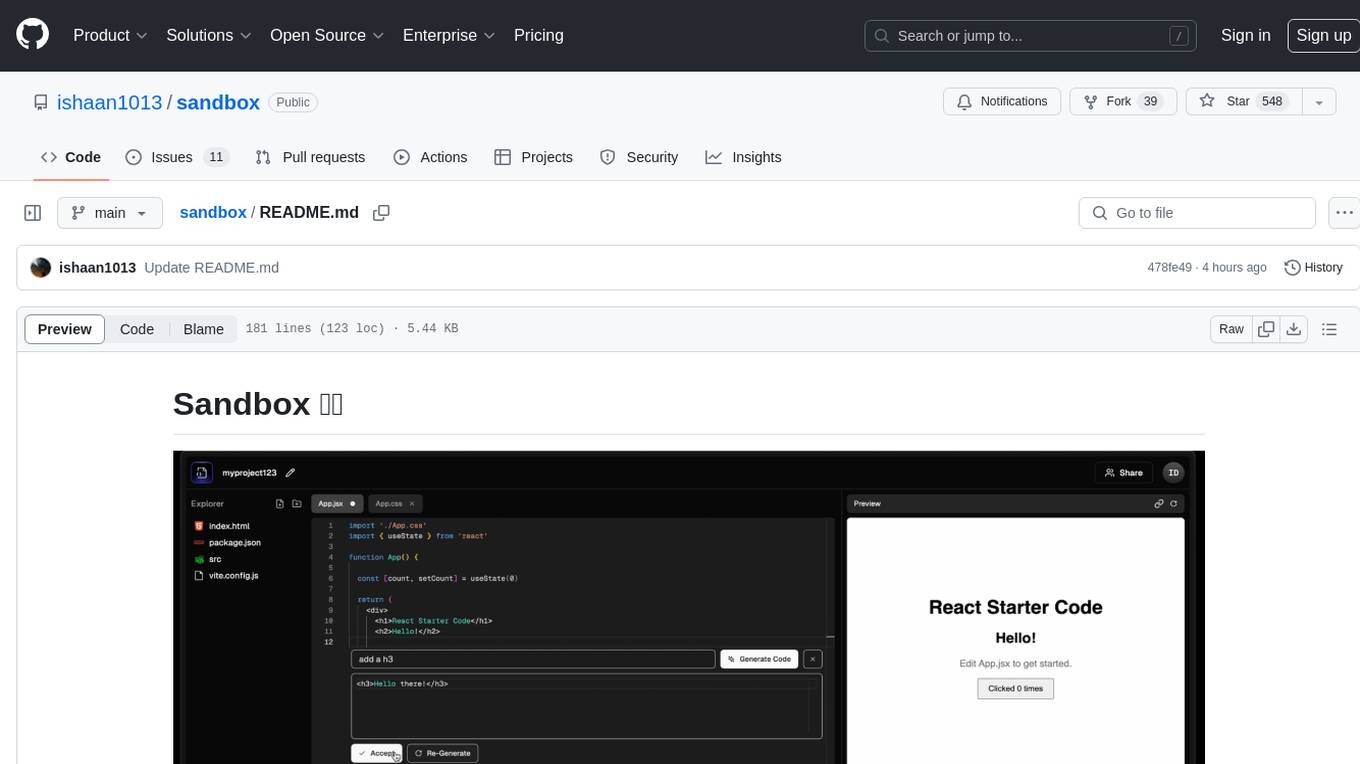
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
starter-monorepo
Starter Monorepo is a template repository for setting up a monorepo structure in your project. It provides a basic setup with configurations for managing multiple packages within a single repository. This template includes tools for package management, versioning, testing, and deployment. By using this template, you can streamline your development process, improve code sharing, and simplify dependency management across your project. Whether you are working on a small project or a large-scale application, Starter Monorepo can help you organize your codebase efficiently and enhance collaboration among team members.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.
generative-ai-application-builder-on-aws
The Generative AI Application Builder on AWS (GAAB) is a solution that provides a web-based management dashboard for deploying customizable Generative AI (Gen AI) use cases. Users can experiment with and compare different combinations of Large Language Model (LLM) use cases, configure and optimize their use cases, and integrate them into their applications for production. The solution is targeted at novice to experienced users who want to experiment and productionize different Gen AI use cases. It uses LangChain open-source software to configure connections to Large Language Models (LLMs) for various use cases, with the ability to deploy chat use cases that allow querying over users' enterprise data in a chatbot-style User Interface (UI) and support custom end-user implementations through an API.

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.
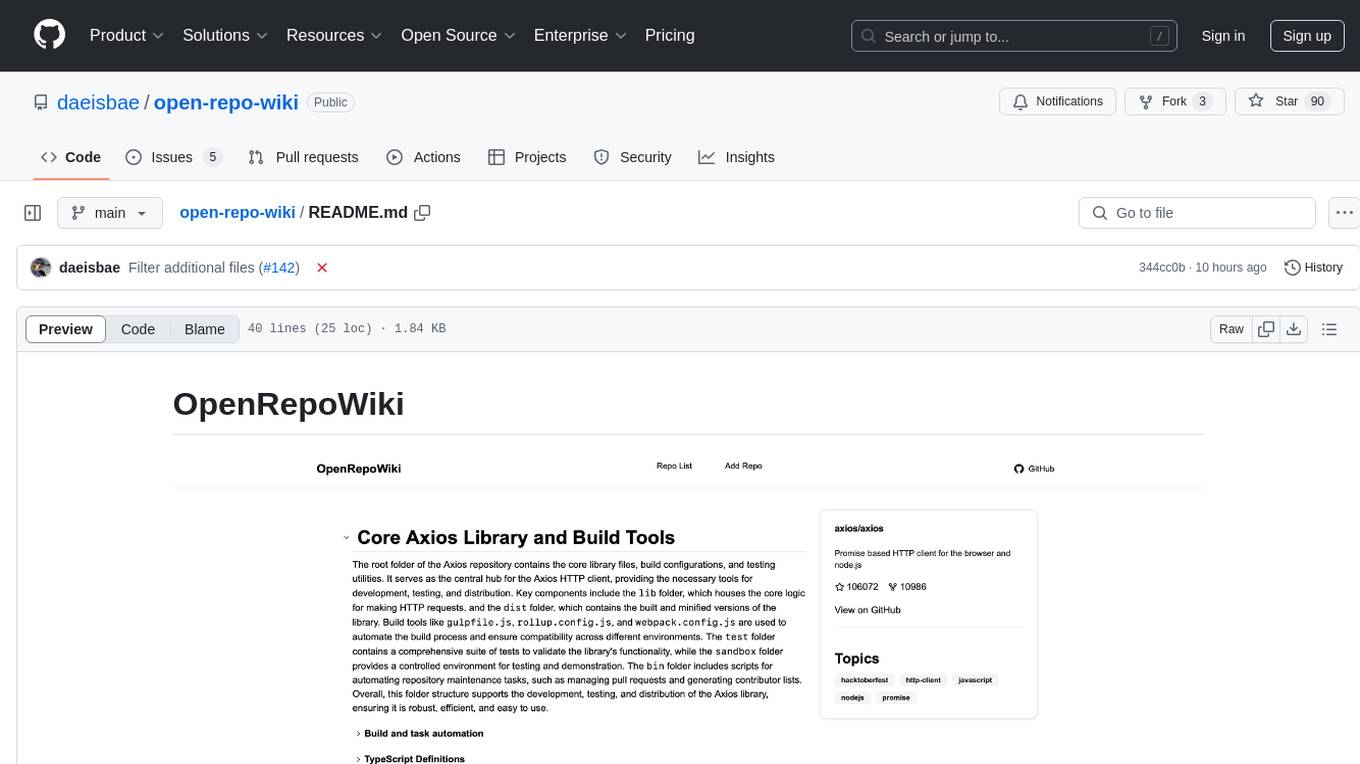
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.
desktop
ComfyUI Desktop is a packaged desktop application that allows users to easily use ComfyUI with bundled features like ComfyUI source code, ComfyUI-Manager, and uv. It automatically installs necessary Python dependencies and updates with stable releases. The app comes with Electron, Chromium binaries, and node modules. Users can store ComfyUI files in a specified location and manage model paths. The tool requires Python 3.12+ and Visual Studio with Desktop C++ workload for Windows. It uses nvm to manage node versions and yarn as the package manager. Users can install ComfyUI and dependencies using comfy-cli, download uv, and build/launch the code. Troubleshooting steps include rebuilding modules and installing missing libraries. The tool supports debugging in VSCode and provides utility scripts for cleanup. Crash reports can be sent to help debug issues, but no personal data is included.
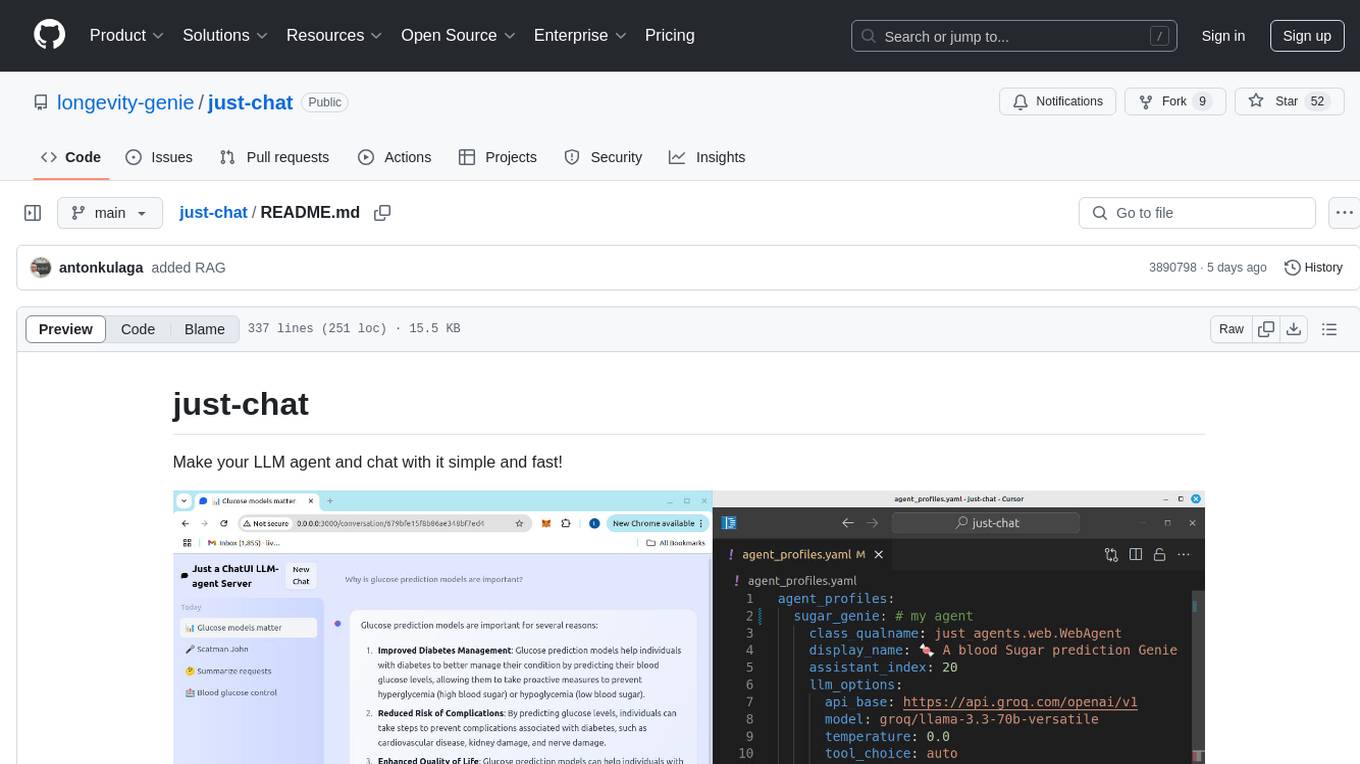
just-chat
Just-Chat is a containerized application that allows users to easily set up and chat with their AI agent. Users can customize their AI assistant using a YAML file, add new capabilities with Python tools, and interact with the agent through a chat web interface. The tool supports various modern models like DeepSeek Reasoner, ChatGPT, LLAMA3.3, etc. Users can also use semantic search capabilities with MeiliSearch to find and reference relevant information based on meaning. Just-Chat requires Docker or Podman for operation and provides detailed installation instructions for both Linux and Windows users.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.
telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.