
airbyte
The leading data integration platform for ETL / ELT data pipelines from APIs, databases & files to data warehouses, data lakes & data lakehouses. Both self-hosted and Cloud-hosted.
Stars: 20731

Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.
README:
Data integration platform for ELT pipelines from APIs, databases & files to databases, warehouses & lakes






We believe that only an open-source solution to data movement can cover the long tail of data sources while empowering data engineers to customize existing connectors. Our ultimate vision is to help you move data from any source to any destination. Airbyte provides a catalog of 600+ connectors for APIs, databases, data warehouses, and data lakes.
Screenshot taken from Airbyte Cloud.
- Deploy Airbyte Open Source or set up Airbyte Cloud to start centralizing your data.
- Create connectors in minutes with our no-code Connector Builder or low-code CDK.
- Explore popular use cases in our tutorials.
- Orchestrate Airbyte syncs with Airflow, Prefect, Dagster, Kestra, or the Airbyte API.
Try it out yourself with our demo app, visit our full documentation, and learn more about recent announcements. See our registry for a full list of connectors already available in Airbyte or Airbyte Cloud.
The Airbyte community can be found in the Airbyte Community Slack, where you can ask questions and voice ideas. You can also ask for help in our Airbyte Forum. Airbyte's roadmap is publicly viewable on GitHub.
For videos and blogs on data engineering and building your data stack, check out Airbyte's Content Hub, YouTube, and sign up for our newsletter.
If you've found a problem with Airbyte, please open a GitHub issue. To contribute to Airbyte and see our Code of Conduct, please see the contributing guide. We have a list of good first issues that contain bugs that have a relatively limited scope. This is a great place to get started, gain experience, and get familiar with our contribution process.
When submitting a pull request, please ensure that Airbyte maintainers have write access to your branch. This allows us to apply formatting fixes and dependency updates directly, significantly speeding up the review and approval process.
To enable write access on your PR from Airbyte maintainers, please check the "Allow edits from maintainers" box when submitting from your PR. You must also create your PR from a fork in your personal GitHub account rather than an organization account, or else you will not see this option. The requirement to create from your personal fork is based on GitHub's additional security restrictions for PRs created from organization forks. For more information about the GitHub security model, please see the GitHub documentation page regarding PRs from forks.
For more details on contribution requirements, please see our contribution workflow documentation.
Airbyte takes security issues very seriously. Please do not file GitHub issues or post on our public forum for security vulnerabilities. Email [email protected] if you believe you have uncovered a vulnerability. In the message, try to provide a description of the issue and ideally a way of reproducing it. The security team will get back to you as soon as possible.
Airbyte Enterprise also offers additional security features (among others) on top of Airbyte open-source.
See the LICENSE file for licensing information, and our FAQ for any questions you may have on that topic.
Airbyte would not be possible without the support and assistance of other open-source tools and companies! Visit our thank you page to learn more about how we build Airbyte.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for airbyte
Similar Open Source Tools
airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.
posthog
PostHog is an all-in-one, open source platform for building successful products. It provides tools for product analytics, web analytics, session replays, feature flags, experiments, error tracking, surveys, data warehouse, data pipelines, LLM analytics, and workflows. Users can get started with a generous free tier, self-host the platform, or use PostHog Cloud. The platform supports various SDKs and libraries for popular languages and frameworks, making it versatile and easy to integrate. PostHog is suitable for teams looking to understand user behavior, improve product performance, and automate actions or messages to users.
xyne
Xyne is an AI-first Search & Answer Engine for work, serving as an OSS alternative to Glean, Gemini, and MS Copilot. It securely indexes data from various applications like Google Workspace, Atlassian suite, Slack, and Github, providing a Google + ChatGPT-like experience to find information and get up-to-date answers. Users can easily locate files, triage issues, inquire about customers/deals/features/tickets, and discover relevant contacts. Xyne enhances AI models by providing contextual information in a secure, private, and responsible manner, making it the most secure and future-proof solution for integrating AI into work environments.
AppFlowy
AppFlowy.IO is an open-source alternative to Notion, providing users with control over their data and customizations. It aims to offer functionality, data security, and cross-platform native experience to individuals, as well as building blocks and collaboration infra services to enterprises and hackers. The tool is built with Flutter and Rust, supporting multiple platforms and emphasizing long-term maintainability. AppFlowy prioritizes data privacy, reliable native experience, and community-driven extensibility, aiming to democratize the creation of complex workplace management tools.

aiid
The Artificial Intelligence Incident Database (AIID) is a collection of incidents involving the development and use of artificial intelligence (AI). The database is designed to help researchers, policymakers, and the public understand the potential risks and benefits of AI, and to inform the development of policies and practices to mitigate the risks and promote the benefits of AI. The AIID is a collaborative project involving researchers from the University of California, Berkeley, the University of Washington, and the University of Toronto.
mastra
Mastra is an opinionated Typescript framework designed to help users quickly build AI applications and features. It provides primitives such as workflows, agents, RAG, integrations, syncs, and evals. Users can run Mastra locally or deploy it to a serverless cloud. The framework supports various LLM providers, offers tools for building language models, workflows, and accessing knowledge bases. It includes features like durable graph-based state machines, retrieval-augmented generation, integrations, syncs, and automated tests for evaluating LLM outputs.
csghub
CSGHub is an open source platform for managing large model assets, including datasets, model files, and codes. It offers functionalities similar to a privatized Huggingface, managing assets in a manner akin to how OpenStack Glance manages virtual machine images. Users can perform operations such as uploading, downloading, storing, verifying, and distributing assets through various interfaces. The platform provides microservice submodules and standardized OpenAPIs for easy integration with users' systems. CSGHub is designed for large models and can be deployed On-Premise for offline operation.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.
digma
Digma is a Continuous Feedback platform that provides code-level insights related to performance, errors, and usage during development. It empowers developers to own their code all the way to production, improving code quality and preventing critical issues. Digma integrates with OpenTelemetry traces and metrics to generate insights in the IDE, helping developers analyze code scalability, bottlenecks, errors, and usage patterns.
OpenHands
OpenHands is a community focused on AI-driven development, offering a Software Agent SDK, CLI, Local GUI, Cloud deployment, and Enterprise solutions. The SDK is a Python library for defining and running agents, the CLI provides an easy way to start using OpenHands, the Local GUI allows running agents on a laptop with REST API, the Cloud deployment offers hosted infrastructure with integrations, and the Enterprise solution enables self-hosting via Kubernetes with extended support and access to the research team. OpenHands is available under the MIT license.
void
Void is an open-source Cursor alternative, providing a full source code for users to build and develop. It is a fork of the vscode repository, offering a waitlist for the official release. Users can contribute by checking the Project board and following the guidelines in CONTRIBUTING.md. Support is available through Discord or email.
chat-with-your-data-solution-accelerator
Chat with your data using OpenAI and AI Search. This solution accelerator uses an Azure OpenAI GPT model and an Azure AI Search index generated from your data, which is integrated into a web application to provide a natural language interface, including speech-to-text functionality, for search queries. Users can drag and drop files, point to storage, and take care of technical setup to transform documents. There is a web app that users can create in their own subscription with security and authentication.

NaLLM
The NaLLM project repository explores the synergies between Neo4j and Large Language Models (LLMs) through three primary use cases: Natural Language Interface to a Knowledge Graph, Creating a Knowledge Graph from Unstructured Data, and Generating a Report using static and LLM data. The repository contains backend and frontend code organized for easy navigation. It includes blog posts, a demo database, instructions for running demos, and guidelines for contributing. The project aims to showcase the potential of Neo4j and LLMs in various applications.
Rapid
Rapid is a web-based modern editor for OpenStreetMap. It integrates advanced mapping tools, authoritative geospatial open data, and cutting-edge technology to empower mappers at all levels to get started quickly, making accurate and fresh edits to maps. Rapid is enhanced with authoritative open data sources and AI-generated roads from the Facebook Map With AI service + buildings from Microsoft open buildings dataset to make adding and editing roads, buildings, and more quick and simple. Rapid also includes data integrity checks to ensure that new map edits are consistent and accurate.

Warp
Warp is a blazingly-fast modern Rust based GPU-accelerated terminal built to make you and your team more productive. It is available for macOS and Linux users, with plans to support Windows and the Web (WASM) in the future. Warp has a community search page where you can find solutions to common issues, and you can file issue requests in the repo if you can't find a solution. Warp is open-source, and the team is planning to first open-source their Rust UI framework, and then parts and potentially all of their client codebase.
For similar tasks

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.
airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.
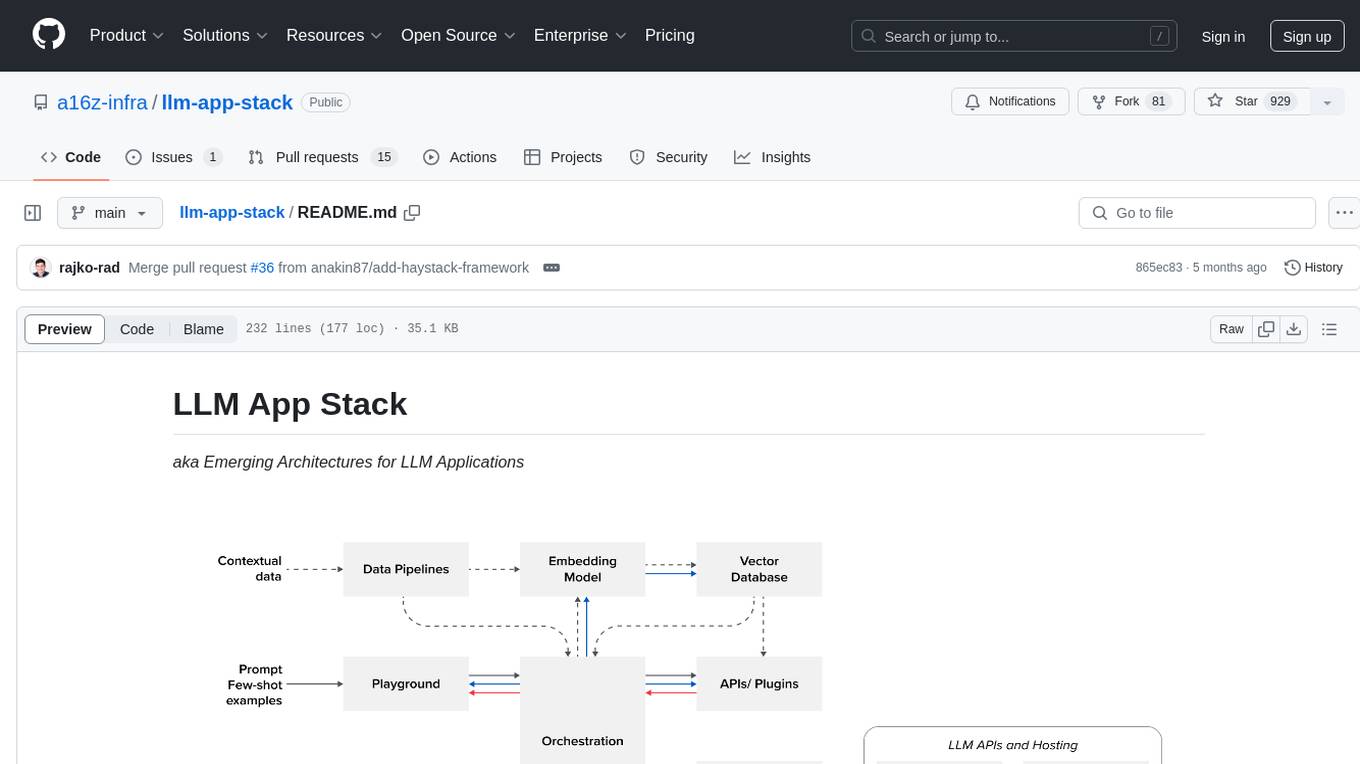
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
dataengineering-roadmap
A repository providing basic concepts, technical challenges, and resources on data engineering in Spanish. It is a curated list of free, Spanish-language materials found on the internet to facilitate the study of data engineering enthusiasts. The repository covers programming fundamentals, programming languages like Python, version control with Git, database fundamentals, SQL, design concepts, Big Data, analytics, cloud computing, data processing, and job search tips in the IT field.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

terraform-provider-airbyte
Programatically control Airbyte Cloud through an API. Developers can create an API Key within the Developer Portal to make API requests. The provider allows for integration building by showing network request information and API usage details. It offers resources and data sources for various destinations and sources, enabling users to manage data flow between different services.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.