
cube
📊 Cube’s universal semantic layer platform is the next evolution of OLAP technology for AI, BI, spreadsheets, and embedded analytics
Stars: 18897

Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.
README:
![]()
Website • Getting Started • Docs • Examples • Blog • Slack • X
![]()

Cube is the universal semantic layer for modern data applications. Born in the cloud era, Cube represents the next evolution of OLAP technology, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application.
Learn more about connecting Cube to data sources and analytics & visualization tools.
Cube was designed to work with all SQL-enabled data sources, including cloud data warehouses like Snowflake or Google BigQuery, query engines like Presto or Amazon Athena, and application databases like Postgres. Cube has a built-in relational caching engine to provide sub-second latency and high concurrency for API requests.
For more details, see the introduction page in our documentation.
As data infrastructure evolved from traditional relational databases to cloud data platforms, OLAP capabilities that once lived in specialized servers like SQL Server Analysis Services and Oracle Essbase were left behind. Today's organizations face several challenges:
-
Analytics Modeling and Multidimensionality. Modern cloud data platforms excel at processing large volumes of data but lack native support for multidimensional analysis and modeling. Cube brings OLAP-style analytics to these platforms, enabling consistent metric definitions and multidimensional analysis.
-
Performance Optimization. While cloud data warehouses have improved query performance through column-oriented storage and distributed processing, they still struggle with complex analytical workloads. Cube provides intelligent caching and pre-aggregation strategies that dramatically improve query response times.
-
Access Control and Governance. Securing and governing access to data across all consuming applications remains critical. Cube offers robust access control to ensure consistent security across your entire data ecosystem.
-
API Flexibility. Legacy OLAP tools were limited in how they exposed data. Cube provides modern REST, GraphQL, and SQL APIs along with support for traditional MDX and DAX interfaces, making it a truly universal semantic layer.
Cube is the missing OLAP engine for the cloud data platform era that provides the necessary infrastructure and features to implement efficient data modeling, access control, and performance optimizations without duplicating analytics modeling, data, or security permissions across different tools.

Cube Cloud is the fastest way to get started with Cube. It provides managed infrastructure as well as an instant and free access for development projects and proofs of concept.

For a step-by-step guide on Cube Cloud, see the docs.
Alternatively, you can get started with Cube locally or self-host it with Docker.
Once Docker is installed, in a new folder for your project, run the following command:
docker run -p 4000:4000 \
-p 15432:15432 \
-v ${PWD}:/cube/conf \
-e CUBEJS_DEV_MODE=true \
cubejs/cubeThen, open http://localhost:4000 in your browser to continue setup.
For a step-by-step guide on Docker, see the docs.
There are many ways you can contribute to Cube! Here are a few possibilities:
- Star this repo and follow us on X.
- Add Cube to your stack on Stackshare.
- Upvote issues with 👍 reaction so we know what's the demand for particular issue to prioritize it within road map.
- Create issues every time you feel something is missing or goes wrong.
- Ask questions on Stack Overflow with cube.js tag if others can have these questions as well.
- Provide pull requests for all open issues and especially for those with help wanted and good first issue labels.
All sort of contributions are welcome and extremely helpful 🙌 Please refer to the contribution guide for more information.
Cube Client is MIT licensed.
Cube Backend is Apache 2.0 licensed.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cube
Similar Open Source Tools
cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
AgentUp
AgentUp is an active development tool that provides a developer-first agent framework for creating AI agents with enterprise-grade infrastructure. It allows developers to define agents with configuration, ensuring consistent behavior across environments. The tool offers secure design, configuration-driven architecture, extensible ecosystem for customizations, agent-to-agent discovery, asynchronous task architecture, deterministic routing, and MCP support. It supports multiple agent types like reactive agents and iterative agents, making it suitable for chatbots, interactive applications, research tasks, and more. AgentUp is built by experienced engineers from top tech companies and is designed to make AI agents production-ready, secure, and reliable.
data-formulator
Data Formulator is an AI-powered tool developed by Microsoft Research to help data analysts create rich visualizations iteratively. It combines user interface interactions with natural language inputs to simplify the process of describing chart designs while delegating data transformation to AI. Users can utilize features like blended UI and NL inputs, data threads for history navigation, and code inspection to create impressive visualizations. The tool supports local installation for customization and Codespaces for quick setup. Developers can build new data analysis tools on top of Data Formulator, and research papers are available for further reading.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.
moon
Moon is a monitoring and alerting platform suitable for multiple domains, supporting various application scenarios such as cloud-native, Internet of Things (IoT), and Artificial Intelligence (AI). It simplifies operational work of cloud-native monitoring, boasts strong IoT and AI support capabilities, and meets diverse monitoring needs across industries. Capable of real-time data monitoring, intelligent alerts, and fault response for various fields.
llama-github
Llama-github is a powerful tool that helps retrieve relevant code snippets, issues, and repository information from GitHub based on queries. It empowers AI agents and developers to solve coding tasks efficiently. With features like intelligent GitHub retrieval, repository pool caching, LLM-powered question analysis, and comprehensive context generation, llama-github excels at providing valuable knowledge context for development needs. It supports asynchronous processing, flexible LLM integration, robust authentication options, and logging/error handling for smooth operations and troubleshooting. The vision is to seamlessly integrate with GitHub for AI-driven development solutions, while the roadmap focuses on empowering LLMs to automatically resolve complex coding tasks.
psychic
Finic is an open source python-based integration platform designed to simplify integration workflows for both business users and developers. It offers a drag-and-drop UI, a dedicated Python environment for each workflow, and generative AI features to streamline transformation tasks. With a focus on decoupling integration from product code, Finic aims to provide faster and more flexible integrations by supporting custom connectors. The tool is open source and allows deployment to users' own cloud environments with minimal legal friction.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.
bytechef
ByteChef is an open-source, low-code, extendable API integration and workflow automation platform. It provides an intuitive UI Workflow Editor, event-driven & scheduled workflows, multiple flow controls, built-in code editor supporting Java, JavaScript, Python, and Ruby, rich component ecosystem, extendable with custom connectors, AI-ready with built-in AI components, developer-ready to expose workflows as APIs, version control friendly, self-hosted, scalable, and resilient. It allows users to build and visualize workflows, automate tasks across SaaS apps, internal APIs, and databases, and handle millions of workflows with high availability and fault tolerance.
csghub
CSGHub is an open source platform for managing large model assets, including datasets, model files, and codes. It offers functionalities similar to a privatized Huggingface, managing assets in a manner akin to how OpenStack Glance manages virtual machine images. Users can perform operations such as uploading, downloading, storing, verifying, and distributing assets through various interfaces. The platform provides microservice submodules and standardized OpenAPIs for easy integration with users' systems. CSGHub is designed for large models and can be deployed On-Premise for offline operation.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.
kweaver
KWeaver is an open-source cognitive intelligence development framework that provides data scientists, application developers, and domain experts with the ability for rapid development, comprehensive openness, and high-performance knowledge network generation and cognitive intelligence large model framework. It offers features such as automated and visual knowledge graph construction, visualization and analysis of knowledge graph data, knowledge graph integration, knowledge graph resource management, large model prompt engineering and debugging, and visual configuration for large model access.
honey
Bee is an ORM framework that provides easy and high-efficiency database operations, allowing developers to focus on business logic development. It supports various databases and features like automatic filtering, partial field queries, pagination, and JSON format results. Bee also offers advanced functionalities like sharding, transactions, complex queries, and MongoDB ORM. The tool is designed for rapid application development in Java, offering faster development for Java Web and Spring Cloud microservices. The Enterprise Edition provides additional features like financial computing support, automatic value insertion, desensitization, dictionary value conversion, multi-tenancy, and more.
moxin
Moxin is an AI LLM client written in Rust to demonstrate the functionality of the Robius framework for multi-platform application development. It is currently in early stages of development and not fully functional. The tool supports building and running on macOS and Linux systems, with packaging options available for distribution. Users can install the required WasmEdge WASM runtime and dependencies to build and run Moxin. Packaging for distribution includes generating `.deb` Debian packages, AppImage, and pacman installation packages for Linux, as well as `.app` bundles and `.dmg` disk images for macOS. The macOS app is not signed, leading to a warning on installation, which can be resolved by removing the quarantine attribute from the installed app.

choco-builder
ChocoBuilder (aka Chocolate Factory) is an open-source LLM application development framework designed to help you easily create powerful software development SDLC + LLM generation assistants. It provides modules for integration into JVM projects, usage with RAGScript, and local deployment examples. ChocoBuilder follows a Domain Driven Problem-Solving design philosophy with key concepts like ProblemClarifier, ProblemAnalyzer, SolutionDesigner, SolutionReviewer, and SolutionExecutor. It offers use cases for desktop/IDE, server, and Android applications, with examples for frontend design, semantic code search, testcase generation, and code interpretation.
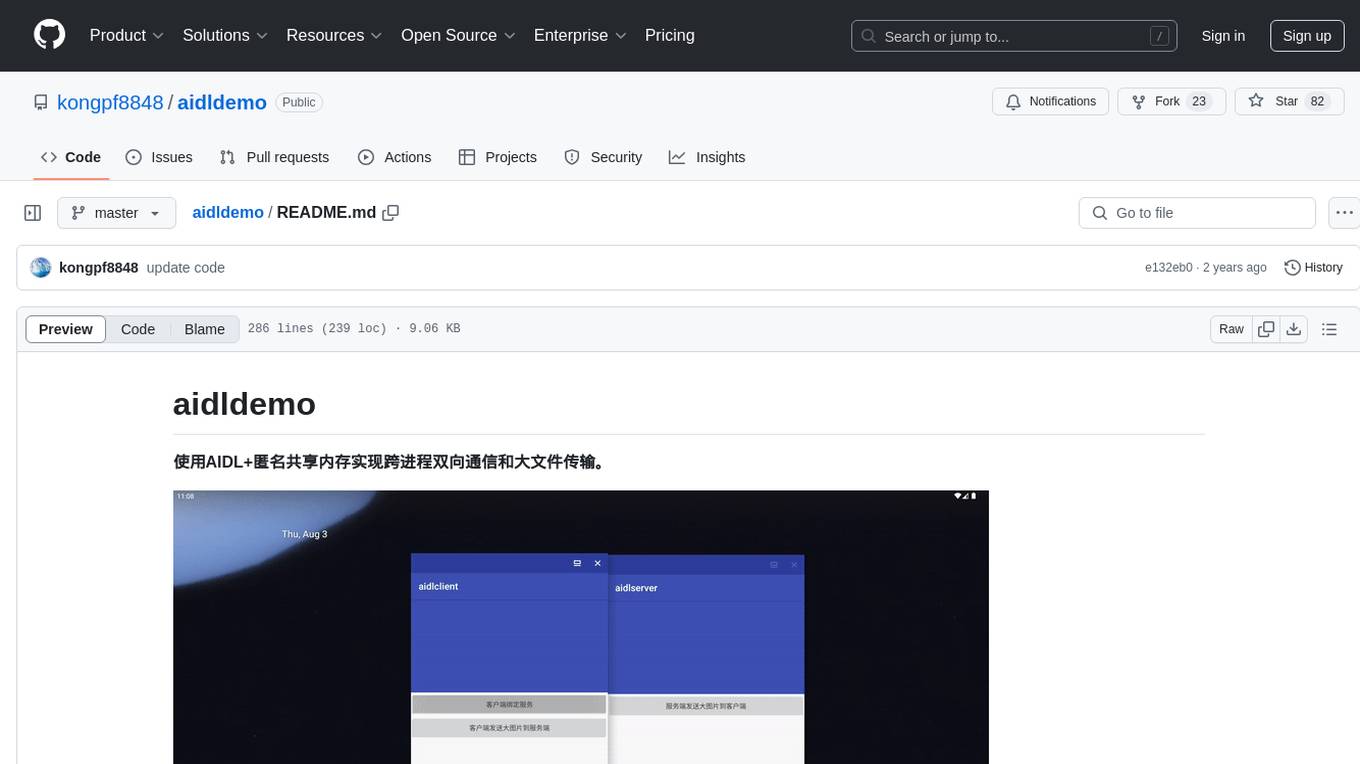
aidldemo
This repository demonstrates how to achieve cross-process bidirectional communication and large file transfer using AIDL and anonymous shared memory. AIDL is a way to implement Inter-Process Communication in Android, based on Binder. To overcome the data size limit of Binder, anonymous shared memory is used for large file transfer. Shared memory allows processes to share memory by mapping a common memory area into their respective process spaces. While efficient for transferring large data between processes, shared memory lacks synchronization mechanisms, requiring additional mechanisms like semaphores. Android's anonymous shared memory (Ashmem) is based on Linux shared memory and facilitates shared memory transfer using Binder and FileDescriptor. The repository provides practical examples of bidirectional communication and large file transfer between client and server using AIDL interfaces and MemoryFile in Android.
cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.