
embedJs
A NodeJS RAG framework to easily work with LLMs and embeddings
Stars: 352

EmbedJs is a NodeJS framework that simplifies RAG application development by efficiently processing unstructured data. It segments data, creates relevant embeddings, and stores them in a vector database for quick retrieval.
README:
![]()
EmbedJs is an Open Source Framework for personalizing LLM responses. An ultimate toolkit for building powerful Retrieval-Augmented Generation (RAG) and Large Language Model (LLM) applications with ease in Node.js.
It segments data into manageable chunks, generates relevant embeddings, and stores them in a vector database for optimized retrieval. It enables users to extract contextual information, find precise answers, or engage in interactive chat conversations, all tailored to their own data.
Comprehensive guides and API documentation are available to help you get the most out of EmbedJs:
Contributions are welcome! Please check out the issues on the repository, and feel free to open a pull request. For more information, please see the contributing guidelines.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for embedJs
Similar Open Source Tools
embedJs
EmbedJs is a NodeJS framework that simplifies RAG application development by efficiently processing unstructured data. It segments data, creates relevant embeddings, and stores them in a vector database for quick retrieval.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
llm-search
pyLLMSearch is an advanced RAG system that offers a convenient question-answering system with a simple YAML-based configuration. It enables interaction with multiple collections of local documents, with improvements in document parsing, hybrid search, chat history, deep linking, re-ranking, customizable embeddings, and more. The package is designed to work with custom Large Language Models (LLMs) from OpenAI or installed locally. It supports various document formats, incremental embedding updates, dense and sparse embeddings, multiple embedding models, 'Retrieve and Re-rank' strategy, HyDE (Hypothetical Document Embeddings), multi-querying, chat history, and interaction with embedded documents using different models. It also offers simple CLI and web interfaces, deep linking, offline response saving, and an experimental API.
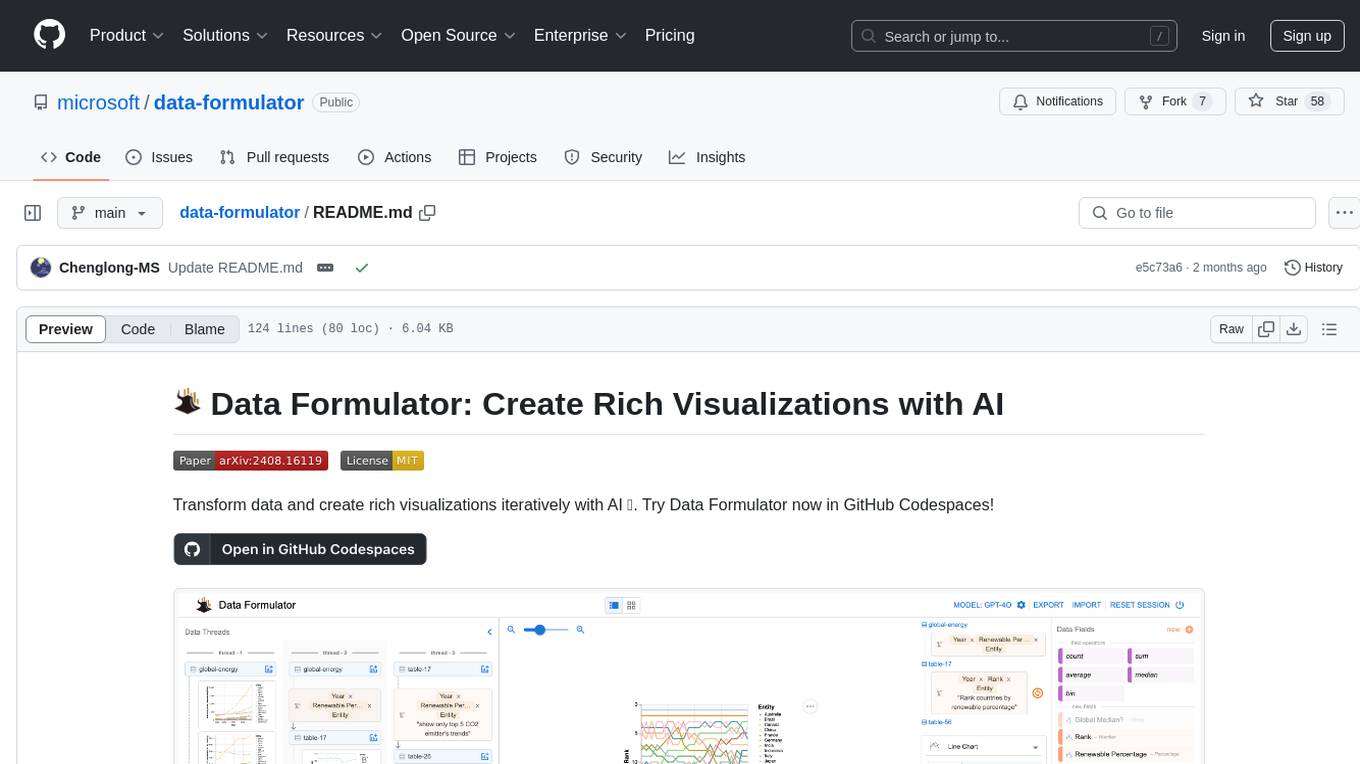
data-formulator
Data Formulator is an AI-powered tool developed by Microsoft Research to help data analysts create rich visualizations iteratively. It combines user interface interactions with natural language inputs to simplify the process of describing chart designs while delegating data transformation to AI. Users can utilize features like blended UI and NL inputs, data threads for history navigation, and code inspection to create impressive visualizations. The tool supports local installation for customization and Codespaces for quick setup. Developers can build new data analysis tools on top of Data Formulator, and research papers are available for further reading.
langchain4j
LangChain for Java simplifies integrating Large Language Models (LLMs) into Java applications by offering unified APIs for various LLM providers and embedding stores. It provides a comprehensive toolbox with tools for prompt templating, chat memory management, function calling, and high-level patterns like Agents and RAG. The library supports 15+ popular LLM providers and 15+ embedding stores, offering numerous examples to help users quickly start building LLM-powered applications. LangChain4j is a fusion of ideas from various projects and actively incorporates new techniques and integrations to keep users up-to-date. The project is under active development, with core functionality already in place for users to start building LLM-powered apps.


CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.
btp-cap-genai-rag
This GitHub repository provides support for developers, partners, and customers to create advanced GenAI solutions on SAP Business Technology Platform (SAP BTP) following the Reference Architecture. It includes examples on integrating Foundation Models and Large Language Models via Generative AI Hub, using LangChain in CAP, and implementing advanced techniques like Retrieval Augmented Generation (RAG) through embeddings and SAP HANA Cloud's Vector Engine for enhanced value in customer support scenarios.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
For similar tasks
embedJs
EmbedJs is a NodeJS framework that simplifies RAG application development by efficiently processing unstructured data. It segments data, creates relevant embeddings, and stores them in a vector database for quick retrieval.
mistral-ai-kmp
Mistral AI SDK for Kotlin Multiplatform (KMP) allows communication with Mistral API to get AI models, start a chat with the assistant, and create embeddings. The library is based on Mistral API documentation and built with Kotlin Multiplatform and Ktor client library. Sample projects like ZeChat showcase the capabilities of Mistral AI SDK. Users can interact with different Mistral AI models through ZeChat apps on Android, Desktop, and Web platforms. The library is not yet published on Maven, but users can fork the project and use it as a module dependency in their apps.

pgai
pgai simplifies the process of building search and Retrieval Augmented Generation (RAG) AI applications with PostgreSQL. It brings embedding and generation AI models closer to the database, allowing users to create embeddings, retrieve LLM chat completions, reason over data for classification, summarization, and data enrichment directly from within PostgreSQL in a SQL query. The tool requires an OpenAI API key and a PostgreSQL client to enable AI functionality in the database. Users can install pgai from source, run it in a pre-built Docker container, or enable it in a Timescale Cloud service. The tool provides functions to handle API keys using psql or Python, and offers various AI functionalities like tokenizing, detokenizing, embedding, chat completion, and content moderation.

azure-functions-openai-extension
Azure Functions OpenAI Extension is a project that adds support for OpenAI LLM (GPT-3.5-turbo, GPT-4) bindings in Azure Functions. It provides NuGet packages for various functionalities like text completions, chat completions, assistants, embeddings generators, and semantic search. The project requires .NET 6 SDK or greater, Azure Functions Core Tools v4.x, and specific settings in Azure Function or local settings for development. It offers features like text completions, chat completion, assistants with custom skills, embeddings generators for text relatedness, and semantic search using vector databases. The project also includes examples in C# and Python for different functionalities.
openai-kit
OpenAIKit is a Swift package designed to facilitate communication with the OpenAI API. It provides methods to interact with various OpenAI services such as chat, models, completions, edits, images, embeddings, files, moderations, and speech to text. The package encourages the use of environment variables to securely inject the OpenAI API key and organization details. It also offers error handling for API requests through the `OpenAIKit.APIErrorResponse`.
VectorETL
VectorETL is a lightweight ETL framework designed to assist Data & AI engineers in processing data for AI applications quickly. It streamlines the conversion of diverse data sources into vector embeddings and storage in various vector databases. The framework supports multiple data sources, embedding models, and vector database targets, simplifying the creation and management of vector search systems for semantic search, recommendation systems, and other vector-based operations.

LLamaWorker
LLamaWorker is a HTTP API server developed to provide an OpenAI-compatible API for integrating Large Language Models (LLM) into applications. It supports multi-model configuration, streaming responses, text embedding, chat templates, automatic model release, function calls, API key authentication, and test UI. Users can switch models, complete chats and prompts, manage chat history, and generate tokens through the test UI. Additionally, LLamaWorker offers a Vulkan compiled version for download and provides function call templates for testing. The tool supports various backends and provides API endpoints for chat completion, prompt completion, embeddings, model information, model configuration, and model switching. A Gradio UI demo is also available for testing.
openai-scala-client
This is a no-nonsense async Scala client for OpenAI API supporting all the available endpoints and params including streaming, chat completion, vision, and voice routines. It provides a single service called OpenAIService that supports various calls such as Models, Completions, Chat Completions, Edits, Images, Embeddings, Batches, Audio, Files, Fine-tunes, Moderations, Assistants, Threads, Thread Messages, Runs, Run Steps, Vector Stores, Vector Store Files, and Vector Store File Batches. The library aims to be self-contained with minimal dependencies and supports API-compatible providers like Azure OpenAI, Azure AI, Anthropic, Google Vertex AI, Groq, Grok, Fireworks AI, OctoAI, TogetherAI, Cerebras, Mistral, Deepseek, Ollama, FastChat, and more.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.