
mage-ai
🧙 Build, run, and manage data pipelines for integrating and transforming data.
Stars: 7824

Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.
README:

🧙 A modern replacement for Airflow.
Documentation 🌪️ Get a 5 min overview 🌊 Play with live tool 🔥 Get instant help






Integrate and synchronize data from 3rd party sources
Build real-time and batch pipelines to transform data using Python, SQL, and R
Run, monitor, and orchestrate thousands of pipelines without losing sleep
1️⃣ 🏗️
Have you met anyone who said they loved developing in Airflow?
That’s why we designed an easy developer experience that you’ll enjoy.
|
Easy developer experience Start developing locally with a single command or launch a dev environment in your cloud using Terraform. Language of choice Write code in Python, SQL, or R in the same data pipeline for ultimate flexibility. Engineering best practices built-in Each step in your pipeline is a standalone file containing modular code that’s reusable and testable with data validations. No more DAGs with spaghetti code. |
 |
↓
2️⃣ 🔮
Stop wasting time waiting around for your DAGs to finish testing.
Get instant feedback from your code each time you run it.
|
Interactive code Immediately see results from your code’s output with an interactive notebook UI. Data is a first-class citizen Each block of code in your pipeline produces data that can be versioned, partitioned, and cataloged for future use. Collaborate on cloud Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment. |
 |
↓
3️⃣ 🚀
Don’t have a large team dedicated to Airflow?
Mage makes it easy for a single developer or small team to scale up and manage thousands of pipelines.
|
Fast deploy Deploy Mage to AWS, GCP, or Azure with only 2 commands using maintained Terraform templates. Scaling made simple Transform very large datasets directly in your data warehouse or through a native integration with Spark. Observability Operationalize your pipelines with built-in monitoring, alerting, and observability through an intuitive UI. |
 |
Mage is an open-source data pipeline tool for transforming and integrating data.
The recommended way to install the latest version of Mage is through Docker with the following command:
docker pull mageai/mageai:latestYou can also install Mage using pip or conda, though this may cause dependency issues without the proper environment.
pip install mage-aiconda install -c conda-forge mage-aiLooking for help? The fastest way to get started is by checking out our documentation here.
Looking for quick examples? Open a demo project right in your browser or check out our guides.
Build and run a data pipeline with our demo app.
WARNING
The live demo is public to everyone, please don’t save anything sensitive (e.g. passwords, secrets, etc).

Click the image to play video
- Load data from API, transform it, and export it to PostgreSQL
- Integrate Mage into an existing Airflow project
- Train model on Titanic dataset
- Set up dbt models and orchestrate dbt runs

🔮 Features
| 🎶 | Orchestration | Schedule and manage data pipelines with observability. |
| 📓 | Notebook | Interactive Python, SQL, & R editor for coding data pipelines. |
| 🏗️ | Data integrations | Synchronize data from 3rd party sources to your internal destinations. |
| 🚰 | Streaming pipelines | Ingest and transform real-time data. |
| ❎ | dbt | Build, run, and manage your dbt models with Mage. |
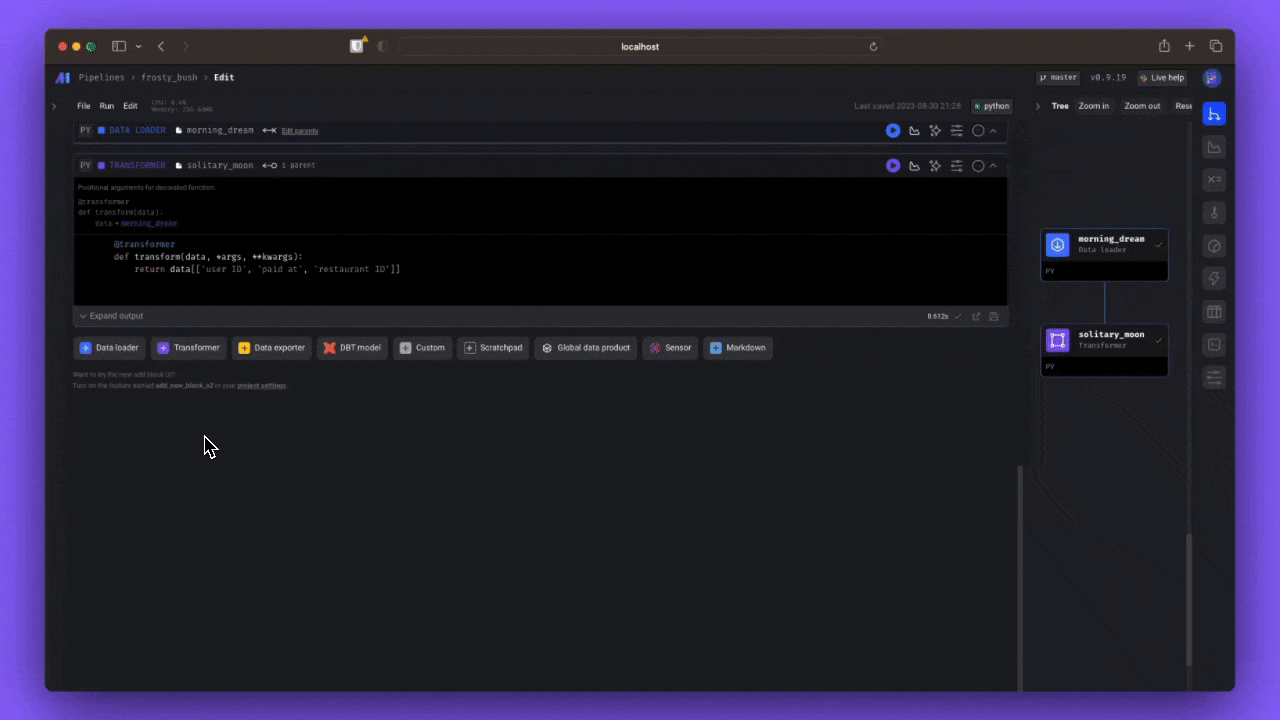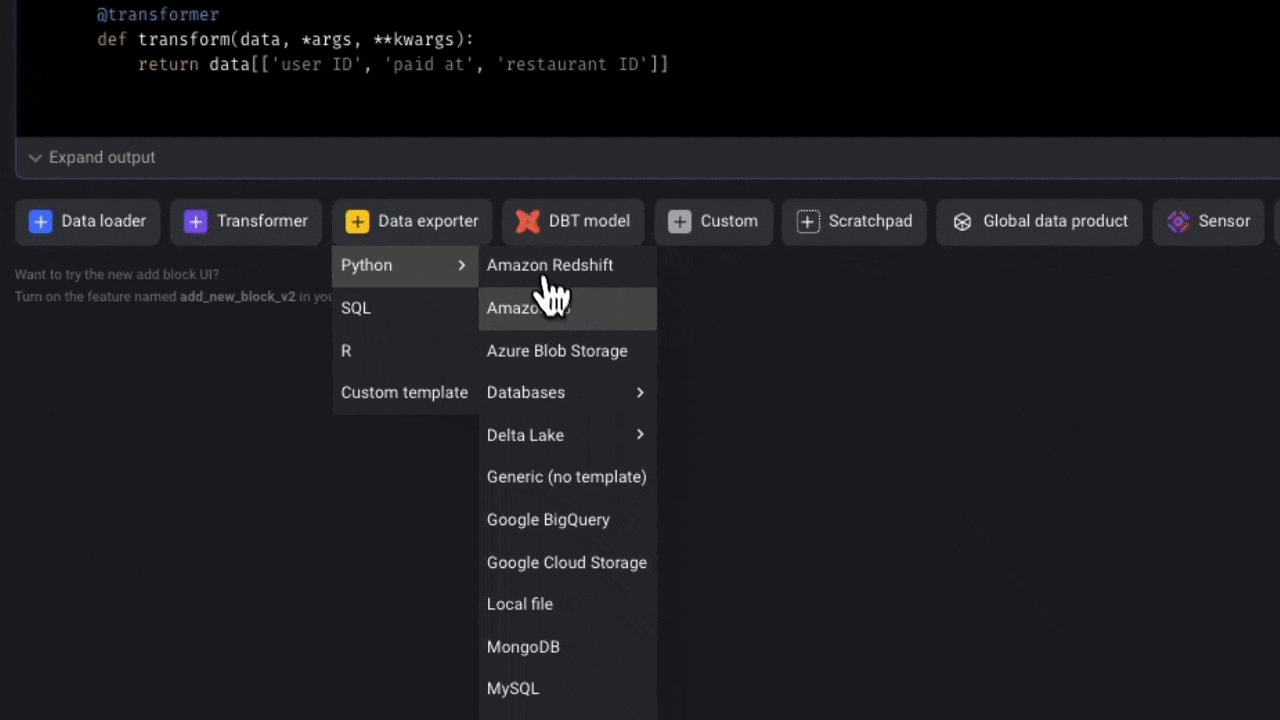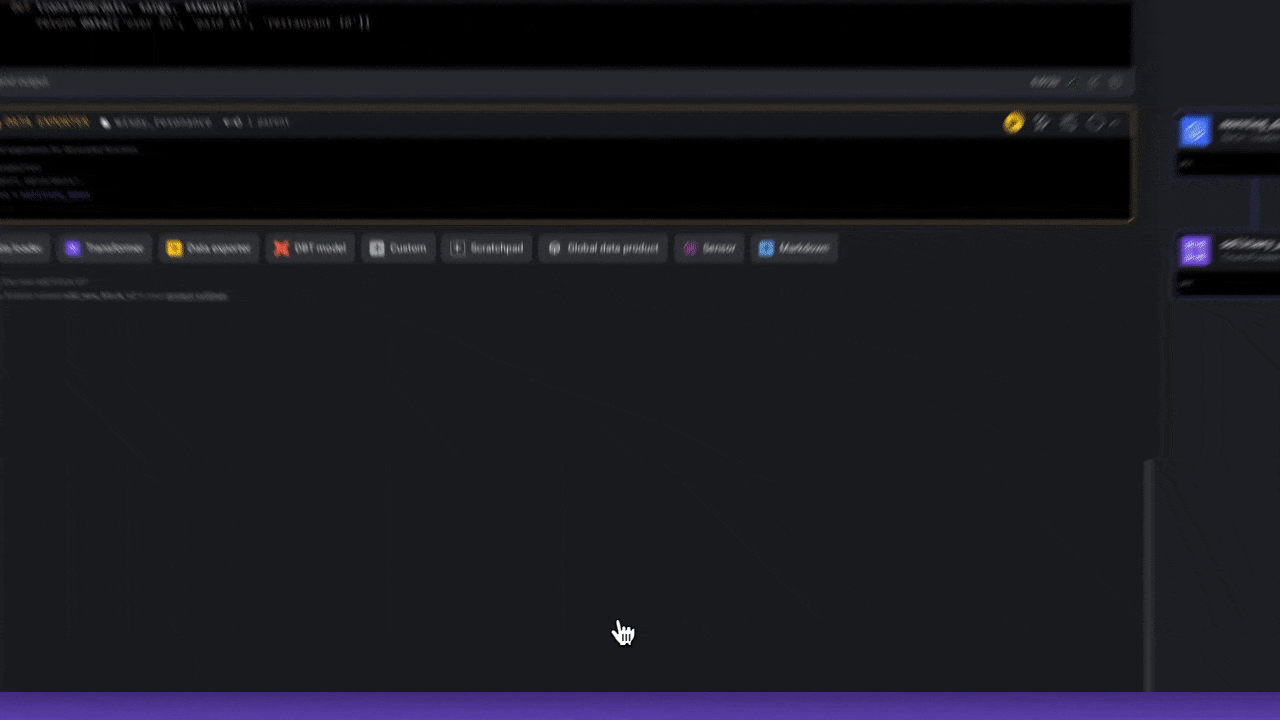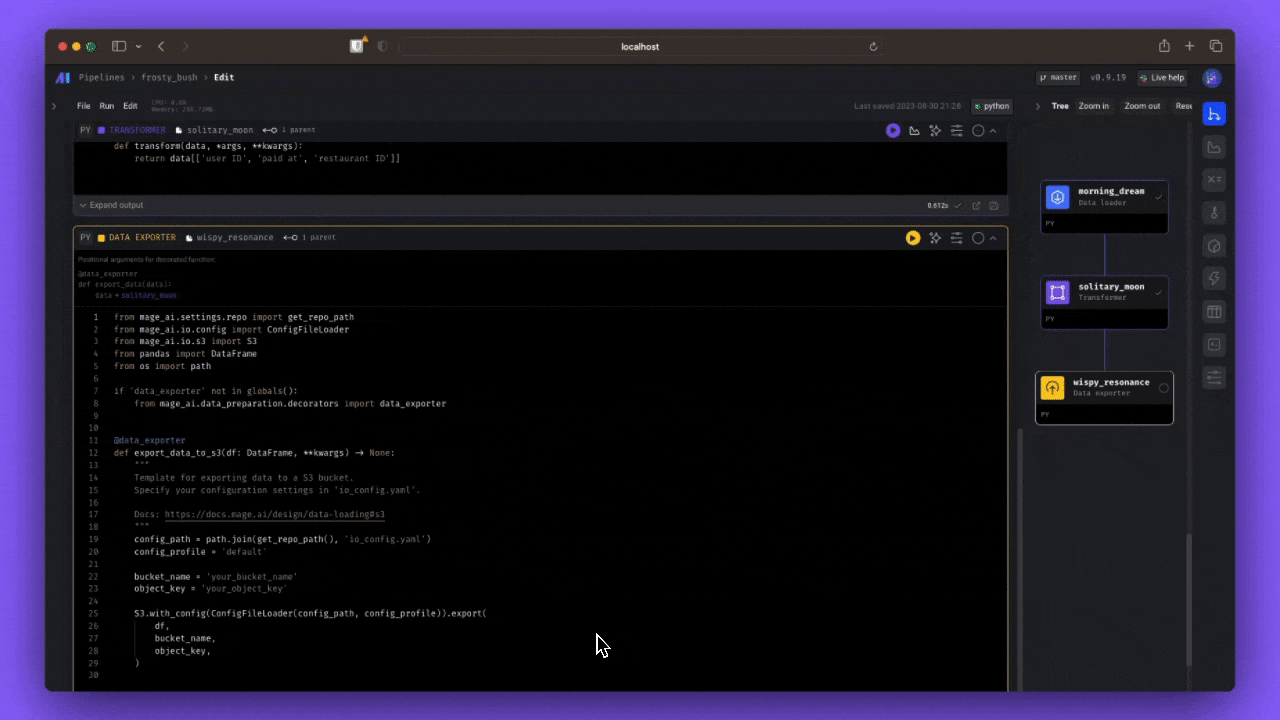
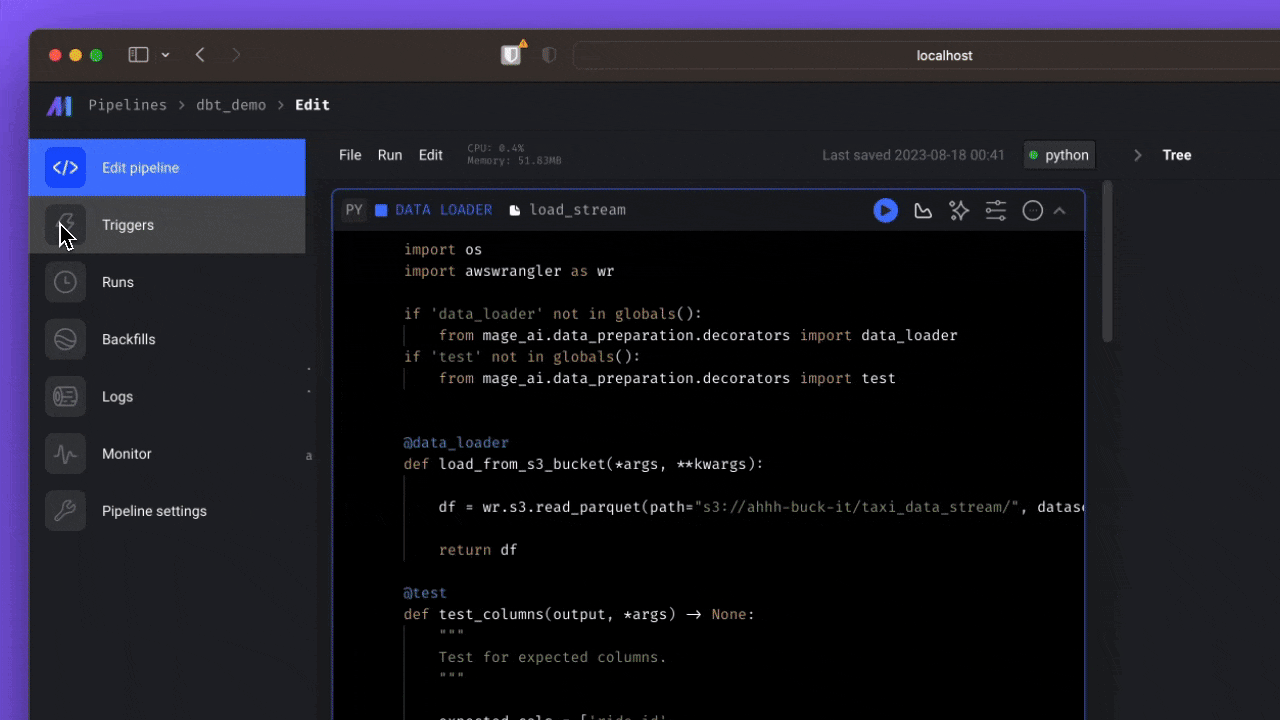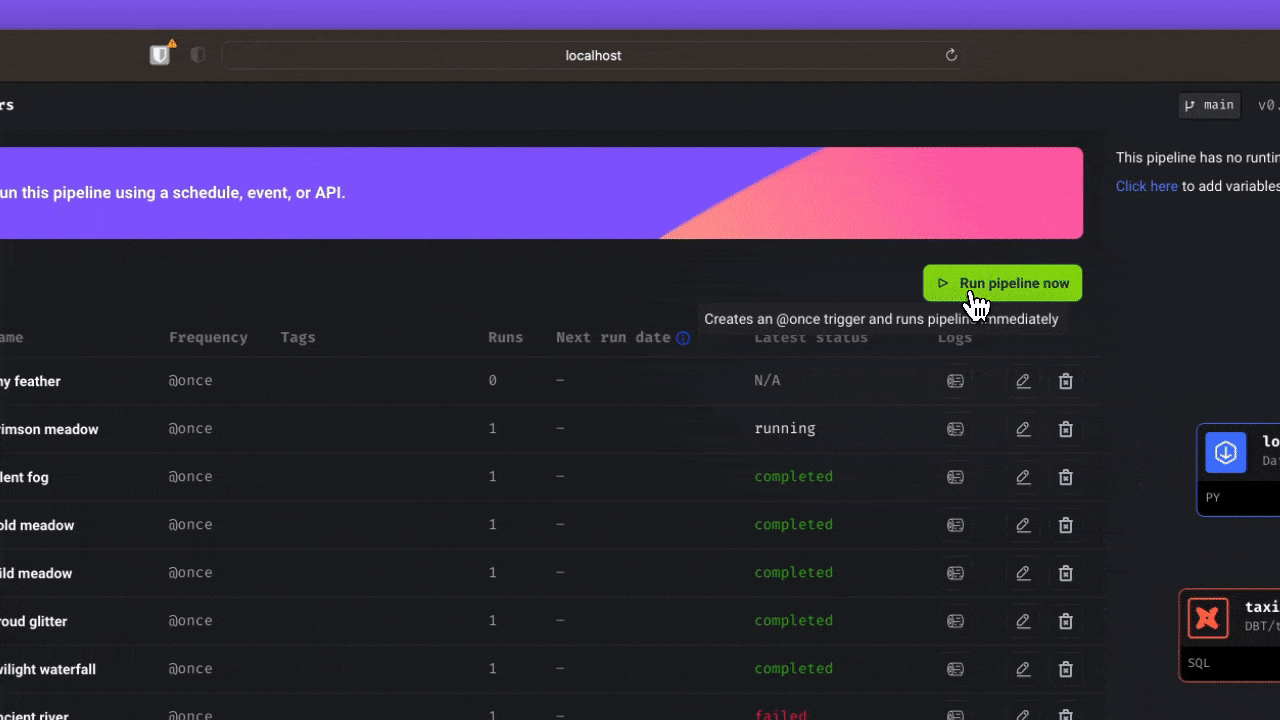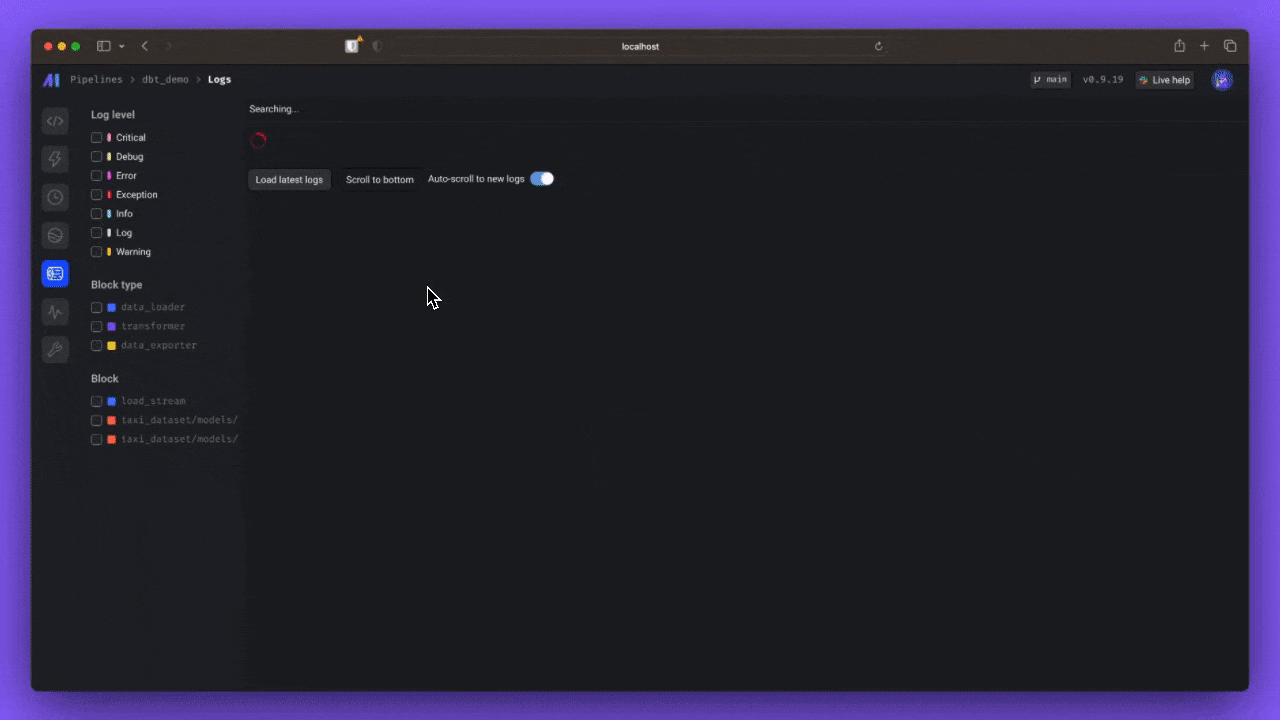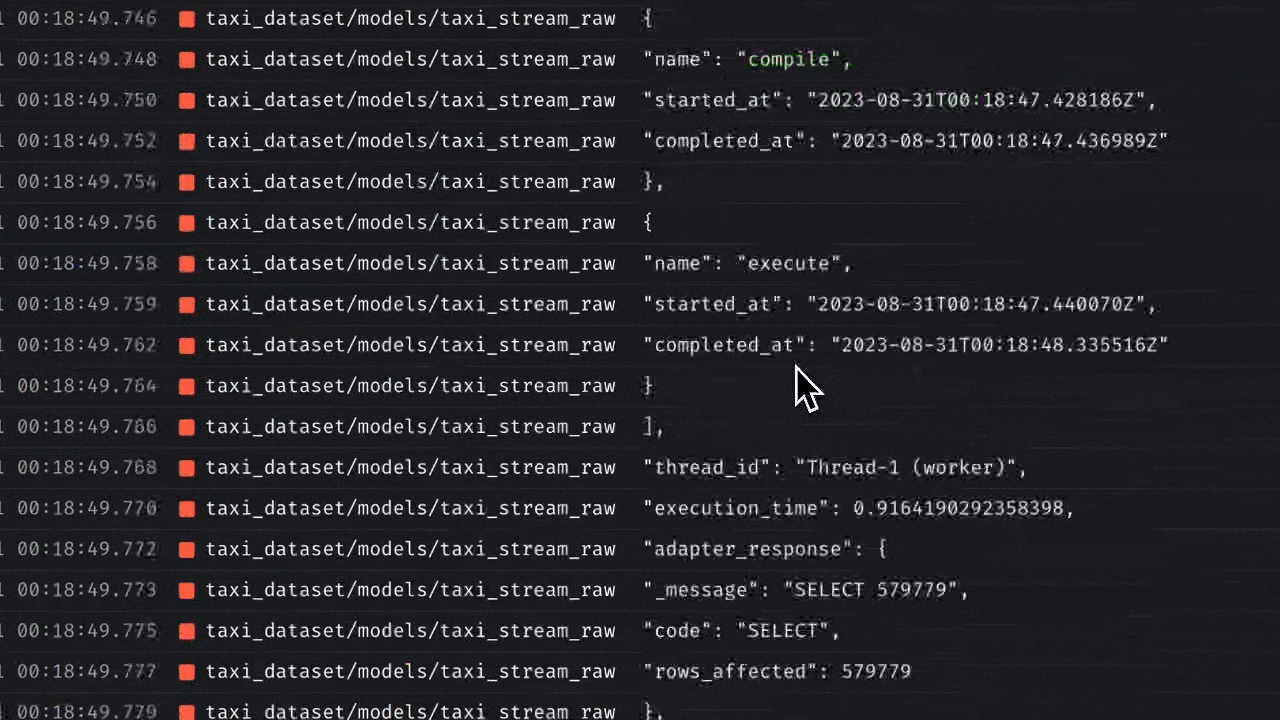
A sample data pipeline defined across 3 files ➝
- Load data ➝
@data_loader def load_csv_from_file(): return pd.read_csv('default_repo/titanic.csv')
- Transform data ➝
@transformer def select_columns_from_df(df, *args): return df[['Age', 'Fare', 'Survived']]
- Export data ➝
@data_exporter def export_titanic_data_to_disk(df) -> None: df.to_csv('default_repo/titanic_transformed.csv')
What the data pipeline looks like in the UI ➝
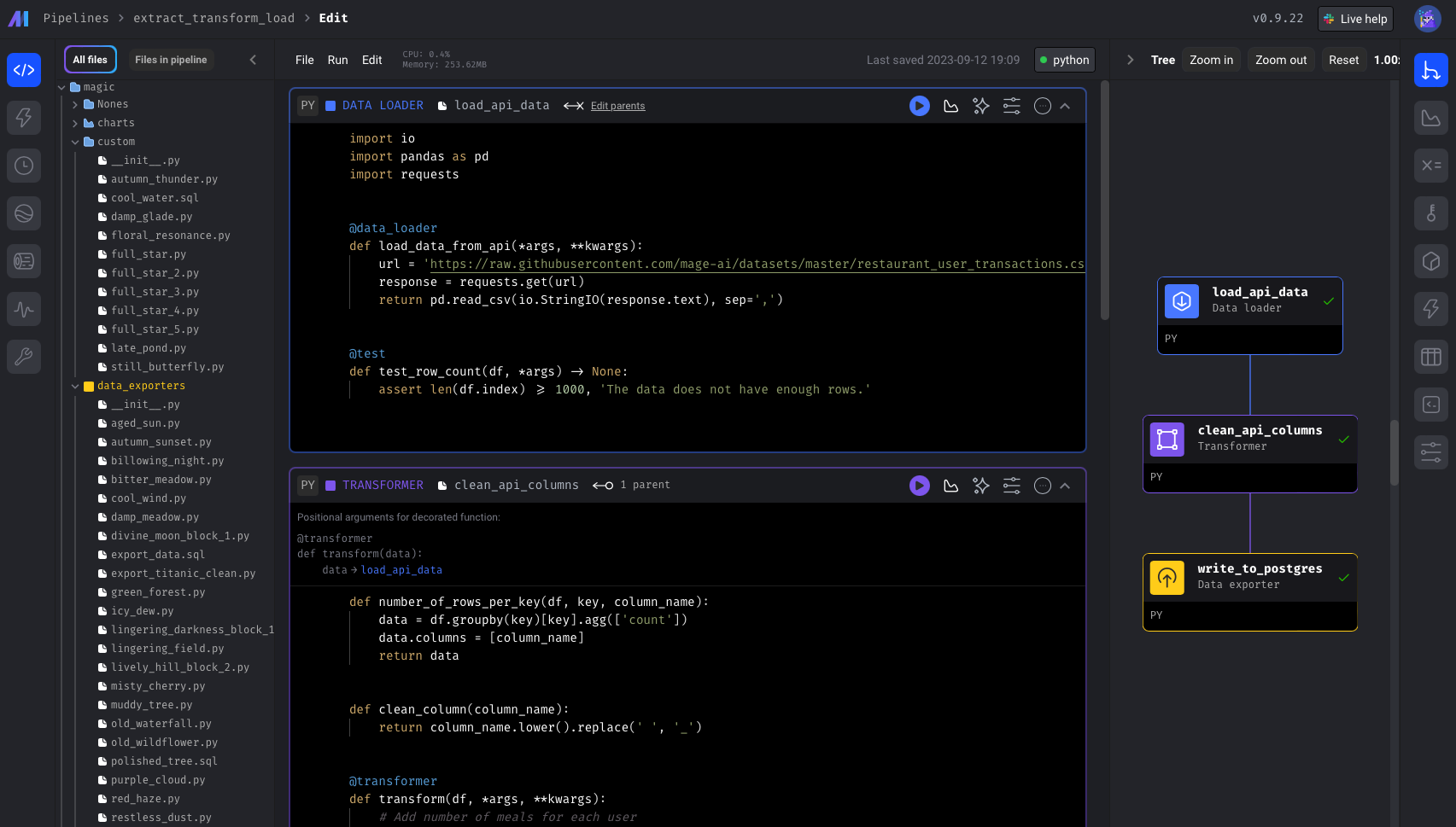
New? We recommend reading about blocks and learning from a hands-on tutorial.
Every user experience and technical design decision adheres to these principles.
| 💻 | Easy developer experience | Open-source engine that comes with a custom notebook UI for building data pipelines. |
| 🚢 | Engineering best practices built-in | Build and deploy data pipelines using modular code. No more writing throwaway code or trying to turn notebooks into scripts. |
| 💳 | Data is a first-class citizen | Designed from the ground up specifically for running data-intensive workflows. |
| 🪐 | Scaling is made simple | Analyze and process large data quickly for rapid iteration. |
These are the fundamental concepts that Mage uses to operate.
| Project | Like a repository on GitHub; this is where you write all your code. |
| Pipeline | Contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code. |
| Block | A file with code that can be executed independently or within a pipeline. |
| Data product | Every block produces data after it's been executed. These are called data products in Mage. |
| Trigger | A set of instructions that determine when or how a pipeline should run. |
| Run | Stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc. |
Add features and instantly improve the experience for everyone.
Check out the contributing guide to set up your development environment and start building.
Individually, we’re a mage.
🧙 Mage
Magic is indistinguishable from advanced technology. A mage is someone who uses magic (aka advanced technology). Together, we’re Magers!
🧙♂️🧙 Magers (
/ˈmājər/)A group of mages who help each other realize their full potential! Let’s hang out and chat together ➝
For real-time news, fun memes, data engineering topics, and more, join us on ➝
| GitHub | |
| Slack |
Check out our FAQ page to find answers to some of our most asked questions.
See the LICENSE file for licensing information.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mage-ai
Similar Open Source Tools
mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

EvoAgentX
EvoAgentX is an open-source framework for building, evaluating, and evolving LLM-based agents or agentic workflows in an automated, modular, and goal-driven manner. It enables developers and researchers to move beyond static prompt chaining or manual workflow orchestration by introducing a self-evolving agent ecosystem. The framework includes features such as agent workflow autoconstruction, built-in evaluation, self-evolution engine, plug-and-play compatibility, comprehensive built-in tools, memory module support, and human-in-the-loop interactions.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.
holmesgpt
HolmesGPT is an AI agent designed for troubleshooting and investigating issues in cloud environments. It utilizes AI models to analyze data from various sources, identify root causes, and provide remediation suggestions. The tool offers integrations with popular cloud providers, observability tools, and on-call systems, enabling users to streamline the troubleshooting process. HolmesGPT can automate the investigation of alerts and tickets from external systems, providing insights back to the source or communication platforms like Slack. It supports end-to-end automation and offers a CLI for interacting with the AI agent. Users can customize HolmesGPT by adding custom data sources and runbooks to enhance investigation capabilities. The tool prioritizes data privacy, ensuring read-only access and respecting RBAC permissions. HolmesGPT is a CNCF Sandbox Project and is distributed under the Apache 2.0 License.

openlit
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just **a single line of code**. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.
Vision-Agents
Vision Agents is an open-source project by Stream that provides building blocks for creating intelligent, low-latency video experiences powered by custom models and infrastructure. It offers multi-modal AI agents that watch, listen, and understand video in real-time. The project includes SDKs for various platforms and integrates with popular AI services like Gemini and OpenAI. Vision Agents can be used for tasks such as sports coaching, security camera systems with package theft detection, and building invisible assistants for various applications. The project aims to simplify the development of real-time vision AI applications by providing a range of processors, integrations, and out-of-the-box features.
off-grid-mobile
Off Grid is a complete offline AI suite that allows users to perform various tasks such as text generation, image generation, vision AI, voice transcription, and document analysis on their mobile devices without sending any data out. The tool offers high performance on flagship devices and supports a wide range of models for different tasks. Users can easily install the tool on Android by downloading the APK from GitHub Releases or build it from source with Node.js and JDK. The documentation provides detailed information on the system architecture, codebase, design system, visual hierarchy, test flows, and more. Contributions are welcome, and the tool is built with a focus on user privacy and data security, ensuring no cloud, subscription, or data harvesting.

openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.
Open-Interface
Open Interface is a self-driving software that automates computer tasks by sending user requests to a language model backend (e.g., GPT-4V) and simulating keyboard and mouse inputs to execute the steps. It course-corrects by sending current screenshots to the language models. The tool supports MacOS, Linux, and Windows, and requires setting up the OpenAI API key for access to GPT-4V. It can automate tasks like creating meal plans, setting up custom language model backends, and more. Open Interface is currently not efficient in accurate spatial reasoning, tracking itself in tabular contexts, and navigating complex GUI-rich applications. Future improvements aim to enhance the tool's capabilities with better models trained on video walkthroughs. The tool is cost-effective, with user requests priced between $0.05 - $0.20, and offers features like interrupting the app and primary display visibility in multi-monitor setups.
runtime
Exosphere is a lightweight runtime designed to make AI agents resilient to failure and enable infinite scaling across distributed compute. It provides a powerful foundation for building and orchestrating AI applications with features such as lightweight runtime, inbuilt failure handling, infinite parallel agents, dynamic execution graphs, native state persistence, and observability. Whether you're working on data pipelines, AI agents, or complex workflow orchestrations, Exosphere offers the infrastructure backbone to make your AI applications production-ready and scalable.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.
Generative-AI-for-beginners-dotnet
Generative AI for Beginners .NET is a hands-on course designed for .NET developers to learn how to build Generative AI applications. The repository focuses on real-world applications and live coding, providing fully functional code samples and integration with tools like GitHub Codespaces and GitHub Models. Lessons cover topics such as generative models, text generation, multimodal capabilities, and responsible use of Generative AI in .NET apps. The course aims to simplify the journey of implementing Generative AI into .NET projects, offering practical guidance and references for deeper theoretical understanding.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
For similar tasks
mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
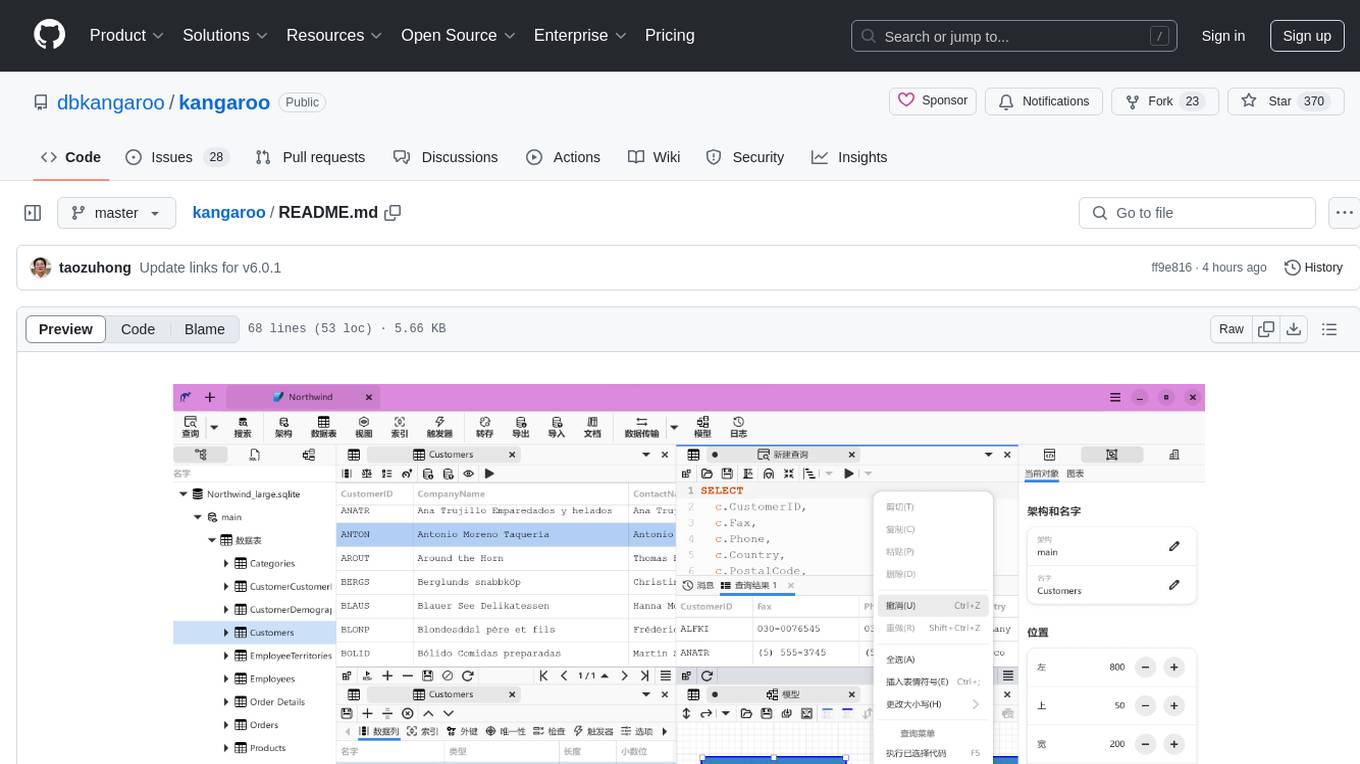
kangaroo
Kangaroo is an AI-powered SQL client and admin tool for popular databases like SQLite, MySQL, PostgreSQL, etc. It supports various functionalities such as table design, query, model, sync, export/import, and more. The tool is designed to be comfortable, fun, and developer-friendly, with features like code intellisense and autocomplete. Kangaroo aims to provide a seamless experience for database management across different operating systems.
emdash
Emdash is an AI-powered tool designed to help users organize text snippets for better retention and learning. It utilizes on-device AI analysis to identify passages with similar ideas from different authors, offers instant semantic search capabilities, allows users to tag, rate, note, and reflect on content, and enables exporting to epub format for e-reader review. Users can also discover forgotten ideas through random exploration, rephrase concepts using metaphors, and import highlights from Kindle or other sources. Emdash is open-source, offline-first, and supports various data formats for import and export.
pennywiseai-tracker
PennyWise AI Tracker is a free and open-source expense tracker that uses on-device AI to turn bank SMS into a clean and searchable money timeline. It offers smart SMS parsing, clear insights, subscription tracking, on-device AI assistant, auto-categorization, data export, and supports major Indian banks. All processing happens on the user's device for privacy. The tool is designed for Android users in India who want automatic expense tracking from bank SMS, with clean categories, subscription detection, and clear insights.

litegraph
LiteGraph is a property graph database designed for knowledge and artificial intelligence applications. It supports graph relationships, tags, labels, metadata, data, and vectors. LiteGraph can be used in-process with LiteGraphClient or as a standalone RESTful server with LiteGraph.Server. The latest version includes major internal refactor, batch APIs, enumeration APIs, statistics APIs, database caching, vector search enhancements, and bug fixes. LiteGraph allows for simple embedding into applications without user configuration. Users can create tenants, graphs, nodes, edges, and perform operations like finding routes and exporting to GEXF file. It also provides features for working with object labels, tags, data, and vectors, enabling filtering and searching based on various criteria. LiteGraph offers REST API deployment with LiteGraph.Server and Docker support with a Docker image available on Docker Hub.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.
mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.