
labelbox-python
The data factory for next gen AI
Stars: 135

Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.
README:
![]()

![]()




With Labelbox, enterprises can easily curate and annotate data, generate high-quality human feedback data for computer vision and language models, evaluate and improve model performance, and automate tasks by seamlessly combining AI and human-centric workflows. The academic and research community also relies on Labelbox for cutting-edge AI research and experimentation.
Visit Labelbox for more information.
If you haven't already, create a free account at Labelbox.
Log into Labelbox and navigate to Account > API Keys to generate an API key.
To install the SDK, run the following command.
pip install labelboxIf you'd like to install the SDK with enhanced functionality, which additional optional capabilities surrounding data processing, run the following command.
pip install "labelbox[data]"Please note that if you prefer to build and install your own version of the SDK, it is important to be aware that only tagged commits have been thoroughly tested. Building from the head of develop branch carries some level of risk.
After installing the SDK and getting an API Key, it's time to validate them both.
import labelbox as lb
client = lb.Client(API_KEY) # API_KEY = API Key generated from labelbox.com
dataset = client.create_dataset(name="Test Dataset")
data_rows = [{"row_data": "My First Data Row", "global_key": "first-data-row"}]
task = dataset.create_data_rows(data_rows)
task.wait_till_done()You should be set! Running the snippet above should create a dataset called Test Dataset with its content being My First Data Row. You can log into Labelbox to verify this. If you have any issues please file a Github Issue or contact Labelbox Support directly. For more advanced examples and information on the SDK, see Documentation below.
We encourage anyone to contribute to this repository to help improve it. Please refer to Contributing Guide for detailed information on how to contribute. This guide also includes instructions for how to build and run the SDK locally.
The SDK is well-documented to help developers get started quickly and use the SDK effectively. Here are links to that documentation:
We have samples in the examples directory to help you get started with the SDK.
Make sure your notebook will use your source code:
ipython profile create-
ipython locate- will show where the config file is. This is the config file used by the Jupyter server, since it runs via ipython - Open the file (this should be ipython_config.py and it is usually located in ~/.ipython/profile_default) and add the following line of code:
c.InteractiveShellApp.exec_lines = [
'import sys; sys.path.insert(0, "<labelbox-python root folder>")'
]
- Go to the root of your project and run
jupyter notebookto start the server.
To enhance the software supply chain security of Labelbox's users, as of v.3.72.2, every Labelbox SDK release contains a SLSA Level 3 Provenance document.
This document provides detailed information about the build process, including the repository and branch from which the package was generated.
By using the SLSA framework's official verifier, you can verify the provenance document to ensure that the package is from a trusted source. Verifying the provenance helps confirm that the package has not been tampered with and was built in a secure environment.
Example of usage for the v.3.72.2 release wheel:
export VERSION=3.72.2 # sdk release version
export TAG=v.3.72.2 # github tag
pip download --no-deps labelbox==${VERSION}
curl --location -O \
https://github.com/Labelbox/labelbox-python/releases/download/${TAG}/multiple.intoto.jsonl
slsa-verifier verify-artifact --source-branch develop --builder-id 'https://github.com/slsa-framework/slsa-github-generator/.github/workflows/generator_generic_slsa3.yml@refs/tags/v2.0.0' --source-uri "git+https://github.com/Labelbox/labelbox-python" --provenance-path multiple.intoto.jsonl ./labelbox-${VERSION}-py3-none-any.whl
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for labelbox-python
Similar Open Source Tools
labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.
superflows
Superflows is an open-source alternative to OpenAI's Assistant API. It allows developers to easily add an AI assistant to their software products, enabling users to ask questions in natural language and receive answers or have tasks completed by making API calls. Superflows can analyze data, create plots, answer questions based on static knowledge, and even write code. It features a developer dashboard for configuration and testing, stateful streaming API, UI components, and support for multiple LLMs. Superflows can be set up in the cloud or self-hosted, and it provides comprehensive documentation and support.
cover-agent
CodiumAI Cover Agent is a tool designed to help increase code coverage by automatically generating qualified tests to enhance existing test suites. It utilizes Generative AI to streamline development workflows and is part of a suite of utilities aimed at automating the creation of unit tests for software projects. The system includes components like Test Runner, Coverage Parser, Prompt Builder, and AI Caller to simplify and expedite the testing process, ensuring high-quality software development. Cover Agent can be run via a terminal and is planned to be integrated into popular CI platforms. The tool outputs debug files locally, such as generated_prompt.md, run.log, and test_results.html, providing detailed information on generated tests and their status. It supports multiple LLMs and allows users to specify the model to use for test generation.
gpt-engineer
GPT-Engineer is a tool that allows you to specify a software in natural language, sit back and watch as an AI writes and executes the code, and ask the AI to implement improvements.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
linkedin-api
The Linkedin API for Python allows users to programmatically search profiles, send messages, and find jobs using a regular Linkedin user account. It does not require 'official' API access, just a valid Linkedin account. However, it is important to note that this library is not officially supported by LinkedIn and using it may violate LinkedIn's Terms of Service. Users can authenticate using any Linkedin account credentials and access features like getting profiles, profile contact info, and connections. The library also provides commercial alternatives for extracting data, scraping public profiles, and accessing a full LinkedIn API. It is not endorsed or supported by LinkedIn and is intended for educational purposes and personal use only.
langdrive
LangDrive is an open-source AI library that simplifies training, deploying, and querying open-source large language models (LLMs) using private data. It supports data ingestion, fine-tuning, and deployment via a command-line interface, YAML file, or API, with a quick, easy setup. Users can build AI applications such as question/answering systems, chatbots, AI agents, and content generators. The library provides features like data connectors for ingestion, fine-tuning of LLMs, deployment to Hugging Face hub, inference querying, data utilities for CRUD operations, and APIs for model access. LangDrive is designed to streamline the process of working with LLMs and making AI development more accessible.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.
AutoNode
AutoNode is a self-operating computer system designed to automate web interactions and data extraction processes. It leverages advanced technologies like OCR (Optical Character Recognition), YOLO (You Only Look Once) models for object detection, and a custom site-graph to navigate and interact with web pages programmatically. Users can define objectives, create site-graphs, and utilize AutoNode via API to automate tasks on websites. The tool also supports training custom YOLO models for object detection and OCR for text recognition on web pages. AutoNode can be used for tasks such as extracting product details, automating web interactions, and more.

olmocr
olmOCR is a toolkit designed for training language models to work with PDF documents in real-world scenarios. It includes various components such as a prompting strategy for natural text parsing, an evaluation toolkit for comparing pipeline versions, filtering by language and SEO spam removal, finetuning code for specific models, processing PDFs through a finetuned model, and viewing documents created from PDFs. The toolkit requires a recent NVIDIA GPU with at least 20 GB of RAM and 30GB of free disk space. Users can install dependencies, set up a conda environment, and utilize olmOCR for tasks like converting single or multiple PDFs, viewing extracted text, and running batch inference pipelines.
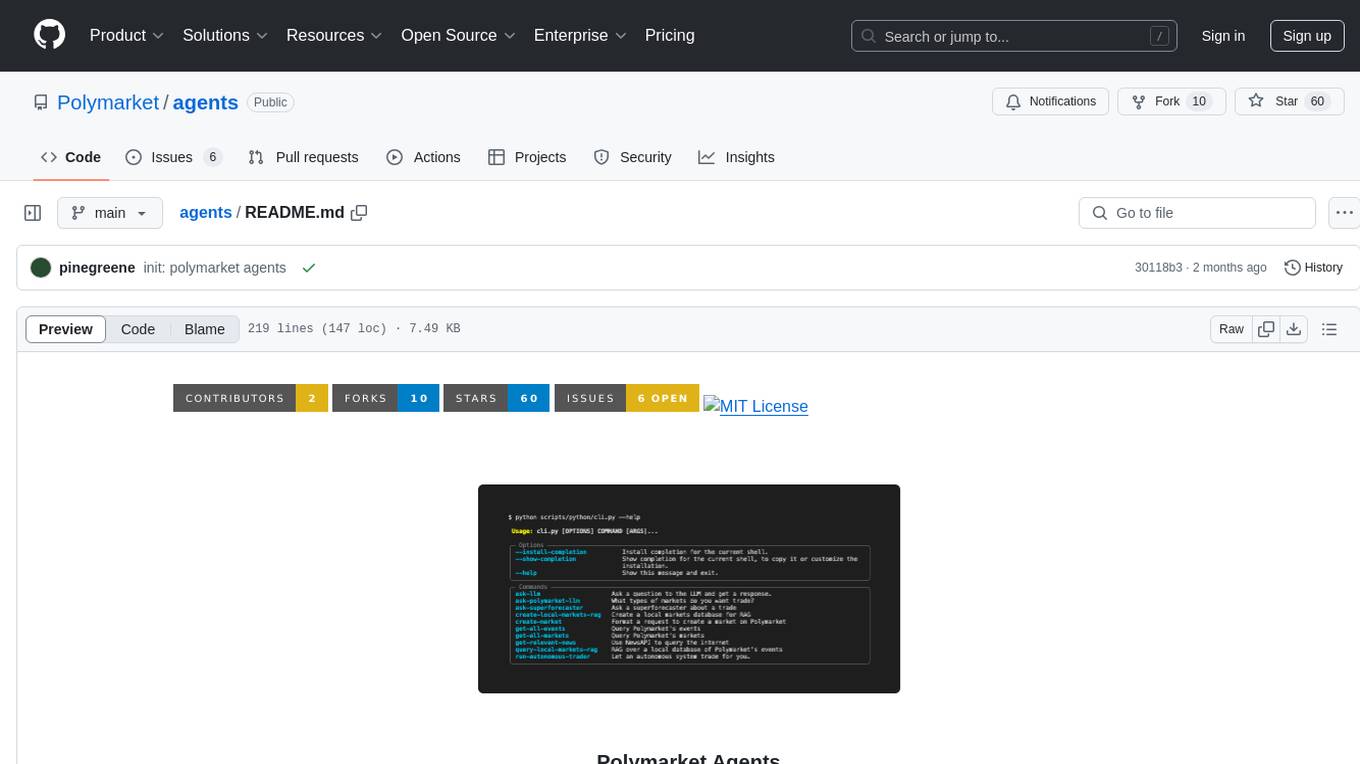
agents
Polymarket Agents is a developer framework and set of utilities for building AI agents to trade autonomously on Polymarket. It integrates with Polymarket API, provides AI agent utilities for prediction markets, supports local and remote RAG, sources data from various services, and offers comprehensive LLM tools for prompt engineering. The architecture features modular components like APIs and scripts for managing local environments, server set-up, and CLI for end-user commands.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.
labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.