Best AI tools for< Train Models >
73 - AI tool Sites
Lobe
Lobe is a free easy-to-use tool for Mac and PC that helps you train machine learning models and ship them to any platform you choose. It provides a user-friendly interface for training machine learning models without requiring extensive coding knowledge. Lobe supports various tasks related to machine learning, such as creating image-based datasets, working with Python toolsets, and deploying models on different platforms.
micro1
micro1 is an AI recruitment engine designed to hire top global talent efficiently. It utilizes human data produced by subject matter experts to provide end-to-end post-training services. The platform offers a Zara AI recruiter agent to identify and hire the best talent on earth, catering to various industries such as tech startups, staffing agencies, and enterprises. With features like sourcing and vetting candidates, seamless onboarding, and high-quality data training, micro1 aims to streamline the recruitment process and save time and costs for businesses. The platform also provides resources for companies and talent, including case studies, cost savings calculators, and interview preparation tools.
Anote
Anote is a human-centered AI company that provides a suite of products and services to help businesses improve their data quality and build better AI models. Anote's products include a data labeler, a private chatbot, a model inference API, and a lead generation tool. Anote's services include data annotation, model training, and consulting.
Playform
Playform is an AI art generator platform that offers a suite of AI tools for artists, creators, and curious minds. It provides intuitive tools for sketching, face swapping, image generation, and model training. Playform allows users to create visual art in various styles and scales, all while ensuring privacy and creative control. The platform caters to professional artists, content creators, and casual users looking to explore visual AI without prompt fatigue.
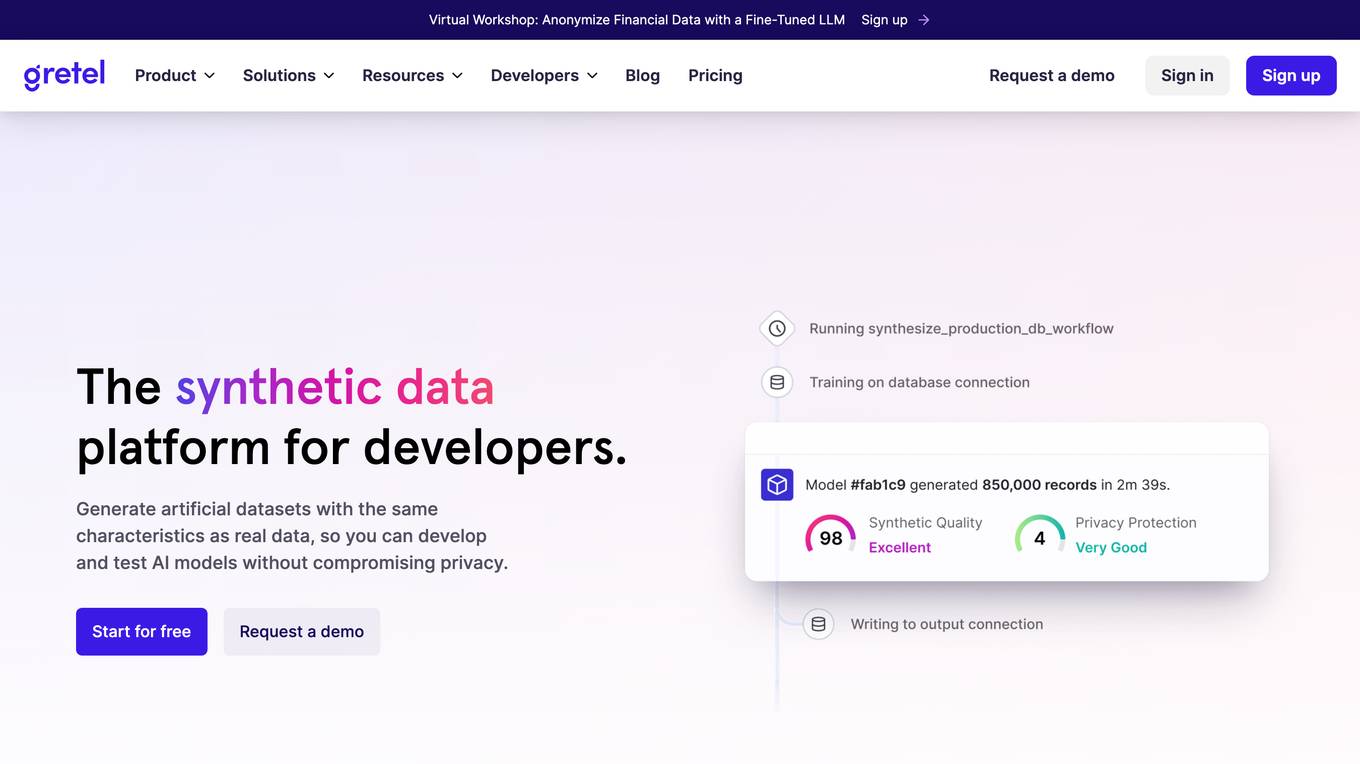
Gretel.ai
Gretel.ai is a synthetic data platform purpose-built for AI applications. It allows users to generate artificial, synthetic datasets with the same characteristics as real data, enabling the improvement of AI models without compromising privacy. The platform offers APIs for generating anonymized and safe synthetic data, training generative AI models, and validating models with quality and privacy scores. Users can deploy Gretel for enterprise use cases and run it on various cloud platforms or in their own environment.
OpenArt
OpenArt is an AI-powered art platform that offers a free AI image generator and editor. It allows users to create images using pre-built models or by training their own models. The platform provides an intuitive AI drawing tool and editing suite to transform artistic concepts into reality. OpenArt stands out for its boundary-free AI drawing, advanced AI art tools, diverse artistic styles, and the ability to train custom AI models. It caters to both amateur and professional artists, offering high-quality art creation and comprehensive support. Users can experiment with various styles, receive detailed feedback, and collaborate on artistic projects through the platform.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
GPUX
GPUX is a cloud platform that provides access to GPUs for running AI workloads. It offers a variety of features to make it easy to deploy and run AI models, including a user-friendly interface, pre-built templates, and support for a variety of programming languages. GPUX is also committed to providing a sustainable and ethical platform, and it has partnered with organizations such as the Climate Leadership Council to reduce its carbon footprint.
UBIAI
UBIAI is a powerful text annotation tool that helps businesses accelerate their data labeling process. With UBIAI, businesses can annotate any type of document, including PDFs, images, and text. UBIAI also offers a variety of features to make the annotation process easier and more efficient, such as auto-labeling, multi-lingual annotation, and team collaboration. With UBIAI, businesses can save time and money on their data labeling projects.
Anthropic
Anthropic is an AI safety and research company based in San Francisco. Our interdisciplinary team has experience across ML, physics, policy, and product. Together, we generate research and create reliable, beneficial AI systems.

Cogniroot
Cogniroot is an AI-powered platform that helps businesses automate their data annotation and data labeling processes. It provides a suite of tools and services that make it easy for businesses to train their machine learning models with high-quality data. Cogniroot's platform is designed to be scalable, efficient, and cost-effective, making it a valuable tool for businesses of all sizes.

DeepVinci
DeepVinci is an AI-powered platform that helps businesses automate their workflows and make better decisions. It offers a range of features, including data annotation, model training, and predictive analytics.
AI Jobs
AI Jobs is a curated list of the best AI jobs for developers, designers and marketers. It provides a platform for companies to post their AI-related job openings and for job seekers to find their dream AI job. The website also includes a blog with articles on the latest AI trends and technologies.
AI Community
This website is a community forum for discussing all things AI. Members can ask questions, share resources, and collaborate on projects. The site also features a directory of AI tools and services.

Phind AI
Phind AI is a cost-effective alternative to other AI search engines, making AI search accessible to everyone, regardless of location. It offers a comprehensive search experience with a user-friendly interface and advanced features.
Google Colab
Google Colab, short for Google Colaboratory, is a free cloud service that supports Python programming and machine learning. It's a dynamic tool that enables users to write and execute Python code through a web-based interface, providing access to powerful computing resources without the need for local setup. Google Colab is particularly useful for data scientists, researchers, and students who require a convenient and accessible platform for developing and experimenting with machine learning models.
Proscia
Proscia is a leading provider of digital pathology solutions for the modern laboratory. Its flagship product, Concentriq, is an enterprise pathology platform that enables anatomic pathology laboratories to achieve 100% digitization and deliver faster, more precise results. Proscia also offers a range of AI applications that can be used to automate tasks, improve diagnostic accuracy, and accelerate research. The company's mission is to perfect cancer diagnosis with intelligent software that changes the way the world practices pathology.
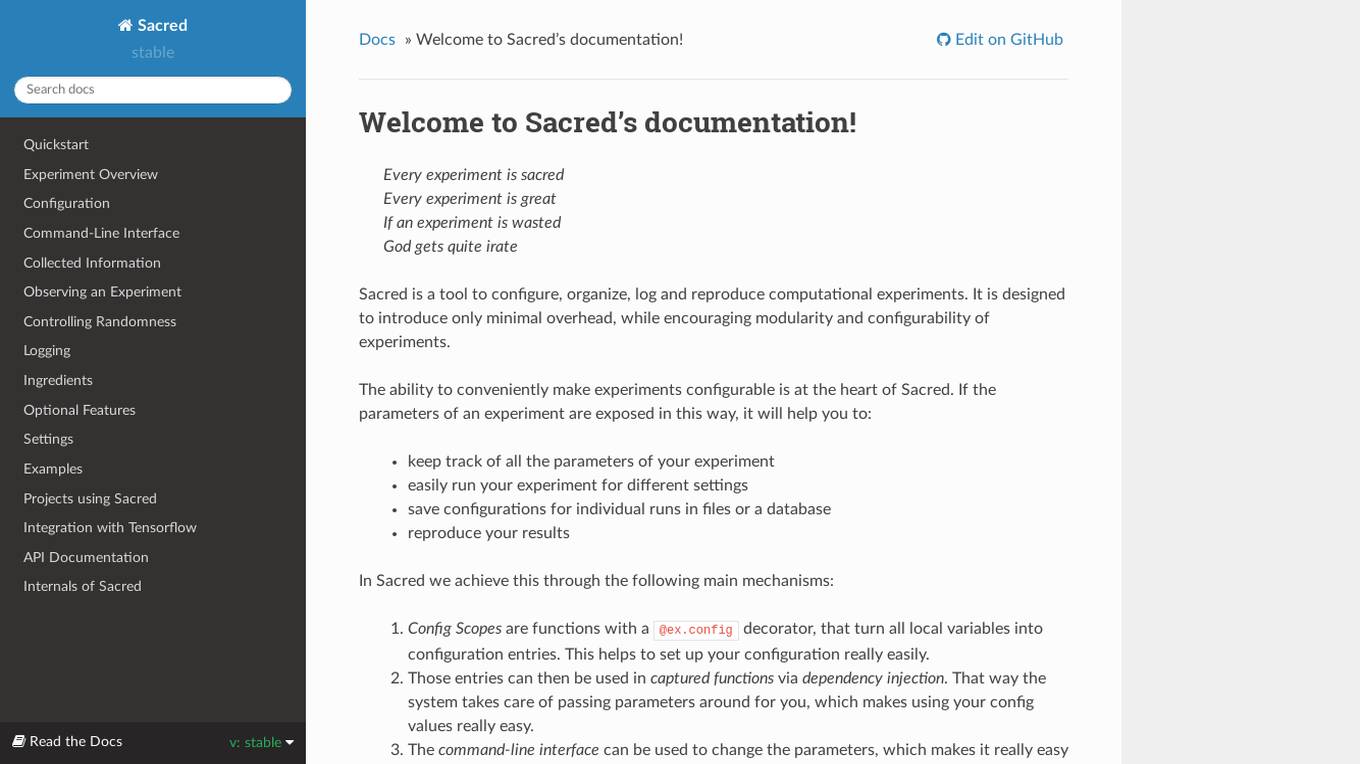
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
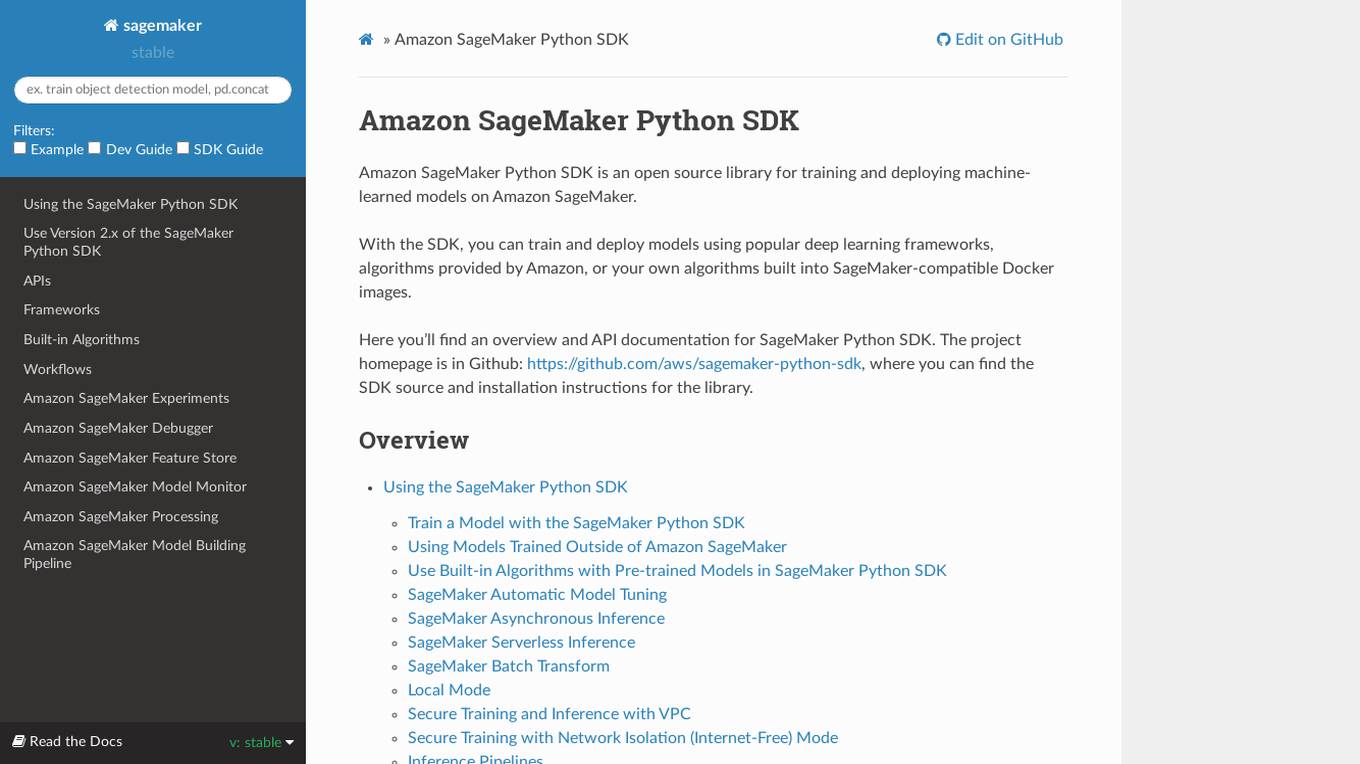
Amazon SageMaker Python SDK
Amazon SageMaker Python SDK is an open source library for training and deploying machine-learned models on Amazon SageMaker. With the SDK, you can train and deploy models using popular deep learning frameworks, algorithms provided by Amazon, or your own algorithms built into SageMaker-compatible Docker images.
ClearML
ClearML is an open-source, end-to-end platform for continuous machine learning (ML). It provides a unified platform for data management, experiment tracking, model training, deployment, and monitoring. ClearML is designed to make it easy for teams to collaborate on ML projects and to ensure that models are deployed and maintained in a reliable and scalable way.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
Metaflow
Metaflow is an open-source framework for building and managing real-life ML, AI, and data science projects. It makes it easy to use any Python libraries for models and business logic, deploy workflows to production with a single command, track and store variables inside the flow automatically for easy experiment tracking and debugging, and create robust workflows in plain Python. Metaflow is used by hundreds of companies, including Netflix, 23andMe, and Realtor.com.
V7
V7 is an AI data engine for computer vision and generative AI. It provides a multimodal automation tool that helps users label data 10x faster, power AI products via API, build AI + human workflows, and reach 99% AI accuracy. V7's platform includes features such as automated annotation, DICOM annotation, dataset management, model management, image annotation, video annotation, document processing, and labeling services.
PyTorch
PyTorch is an open-source machine learning library based on the Torch library. It is used for applications such as computer vision, natural language processing, and reinforcement learning. PyTorch is known for its flexibility and ease of use, making it a popular choice for researchers and developers in the field of artificial intelligence.

Kubeflow
Kubeflow is an open-source machine learning (ML) toolkit that makes deploying ML workflows on Kubernetes simple, portable, and scalable. It provides a unified interface for model training, serving, and hyperparameter tuning, and supports a variety of popular ML frameworks including PyTorch, TensorFlow, and XGBoost. Kubeflow is designed to be used with Kubernetes, a container orchestration system that automates the deployment, management, and scaling of containerized applications.
Apache MXNet
Apache MXNet is a flexible and efficient deep learning library designed for research, prototyping, and production. It features a hybrid front-end that seamlessly transitions between imperative and symbolic modes, enabling both flexibility and speed. MXNet also supports distributed training and performance optimization through Parameter Server and Horovod. With bindings for multiple languages, including Python, Scala, Julia, Clojure, Java, C++, R, and Perl, MXNet offers wide accessibility. Additionally, it boasts a thriving ecosystem of tools and libraries that extend its capabilities in computer vision, NLP, time series, and more.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.
Practical Deep Learning for Coders
Practical Deep Learning for Coders is a free course designed for individuals with some coding experience who want to learn how to apply deep learning and machine learning to practical problems. The course covers topics such as building and training deep learning models for computer vision, natural language processing, tabular analysis, and collaborative filtering problems. It is based on a 5-star rated book and does not require any special hardware or software. The course is led by Jeremy Howard, a renowned expert in machine learning and the President and Chief Scientist of Kaggle.
Innodata Inc.
Innodata Inc. is a global data engineering company that delivers AI-enabled software platforms and managed services for AI data collection/annotation, AI digital transformation, and industry-specific business processes. They provide a full-suite of services and products to power data-centric AI initiatives using artificial intelligence and human expertise. With a 30+ year legacy, they offer the highest quality data and outstanding service to their customers.
DMLR
DMLR (Data-centric Machine Learning Research) is an AI tool that focuses on advancing research in data-centric machine learning. It organizes workshops, research retreats, maintains a journal, and runs a working group to support infrastructure projects. The platform covers topics such as data collection, governance, bias, and drifts, as well as data-centric explainable AI and AI alignment. DMLR encourages submissions around the theme of AI for Science, using AI to tackle scientific challenges and accelerate discoveries.
Prem AI
Prem is an AI platform that empowers developers and businesses to build and fine-tune generative AI models with ease. It offers a user-friendly development platform for developers to create AI solutions effortlessly. For businesses, Prem provides tailored model fine-tuning and training to meet unique requirements, ensuring data sovereignty and ownership. Trusted by global companies, Prem accelerates the advent of sovereign generative AI by simplifying complex AI tasks and enabling full control over intellectual capital. With a suite of foundational open-source SLMs, Prem supercharges business applications with cutting-edge research and customization options.
Cartesia Sonic Team Blog Research Playground
Cartesia Sonic Team Blog Research Playground is an AI application that offers real-time multimodal intelligence for every device. The application aims to build the next generation of AI by providing ubiquitous, interactive intelligence that can run on any device. It features the fastest, ultra-realistic generative voice API and is backed by research on simple linear attention language models and state-space models. The founding team, who met at the Stanford AI Lab, has invented State Space Models (SSMs) and scaled it up to achieve state-of-the-art results in various modalities such as text, audio, video, images, and time-series data.
Image Bear AI
Image Bear AI is an advanced image recognition tool that utilizes artificial intelligence to analyze and identify objects within images. The application is designed to assist users in various industries such as e-commerce, security, and healthcare by providing accurate and efficient image analysis capabilities. With its cutting-edge technology, Image Bear AI offers a user-friendly interface and fast processing speeds, making it a valuable tool for businesses looking to streamline their image recognition processes.
PyAI
PyAI is an advanced AI tool designed for developers and data scientists to streamline their workflow and enhance productivity. It offers a wide range of AI capabilities, including machine learning algorithms, natural language processing, computer vision, and more. With PyAI, users can easily build, train, and deploy AI models for various applications, such as predictive analytics, image recognition, and text classification. The tool provides a user-friendly interface and comprehensive documentation to support users at every stage of their AI projects.

GrapixAI
GrapixAI is a leading provider of low-cost cloud GPU rental services and AI server solutions. The company's focus on flexibility, scalability, and cutting-edge technology enables a variety of AI applications in both local and cloud environments. GrapixAI offers the lowest prices for on-demand GPUs such as RTX4090, RTX 3090, RTX A6000, RTX A5000, and A40. The platform provides Docker-based container ecosystem for quick software setup, powerful GPU search console, customizable pricing options, various security levels, GUI and CLI interfaces, real-time bidding system, and personalized customer support.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.

Moreh
Moreh is an AI platform that aims to make hyperscale AI infrastructure more accessible for scaling any AI model and application. It provides a full-stack infrastructure software from PyTorch to GPUs for the LLM era, enabling users to train large language models efficiently and effectively.

madebymachines
madebymachines is an AI tool designed to assist users in various stages of the machine learning workflow, from data preparation to model development. The tool offers services such as data collection, data labeling, model training, hyperparameter tuning, and transfer learning. With a user-friendly interface and efficient algorithms, madebymachines aims to streamline the process of building machine learning models for both beginners and experienced users.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.
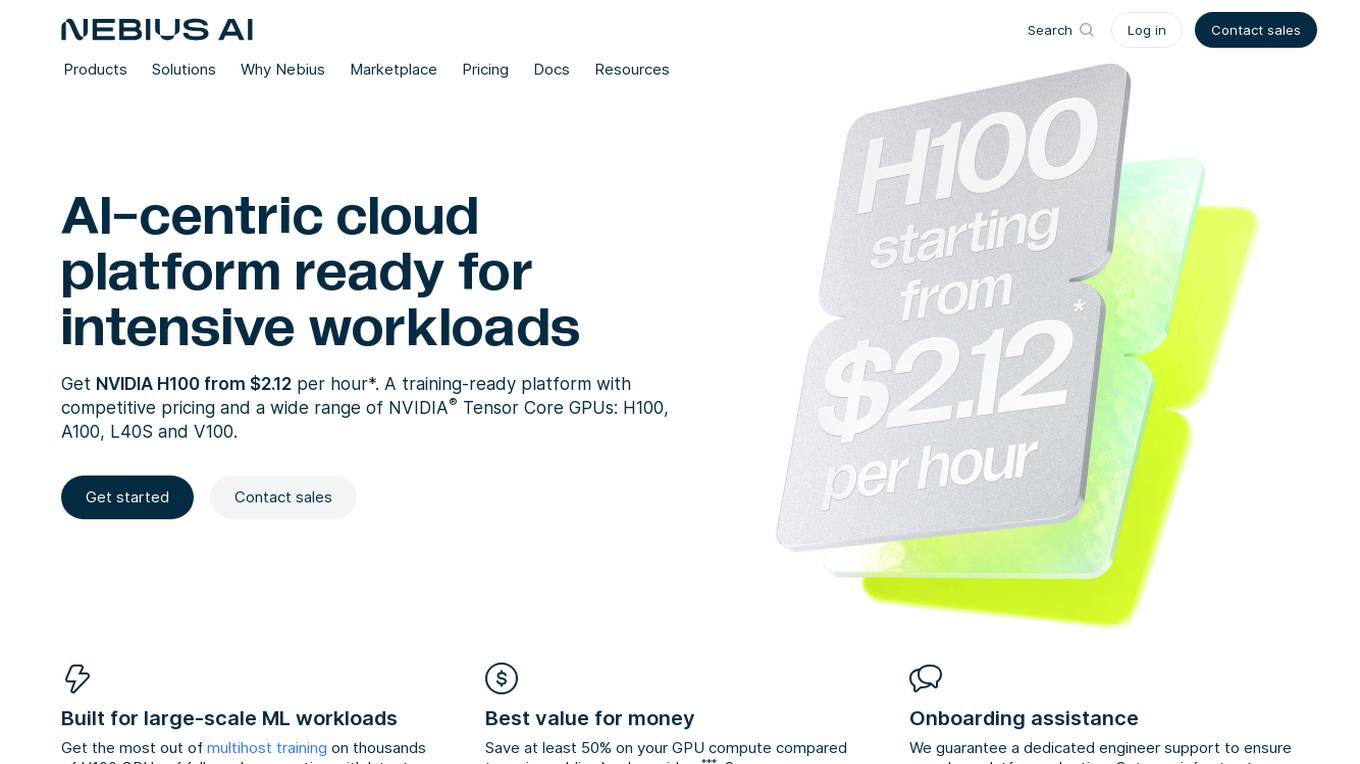
Nebius AI
Nebius AI is an AI-centric cloud platform designed to handle intensive workloads efficiently. It offers a range of advanced features to support various AI applications and projects. The platform ensures high performance and security for users, enabling them to leverage AI technology effectively in their work. With Nebius AI, users can access cutting-edge AI tools and resources to enhance their projects and streamline their workflows.
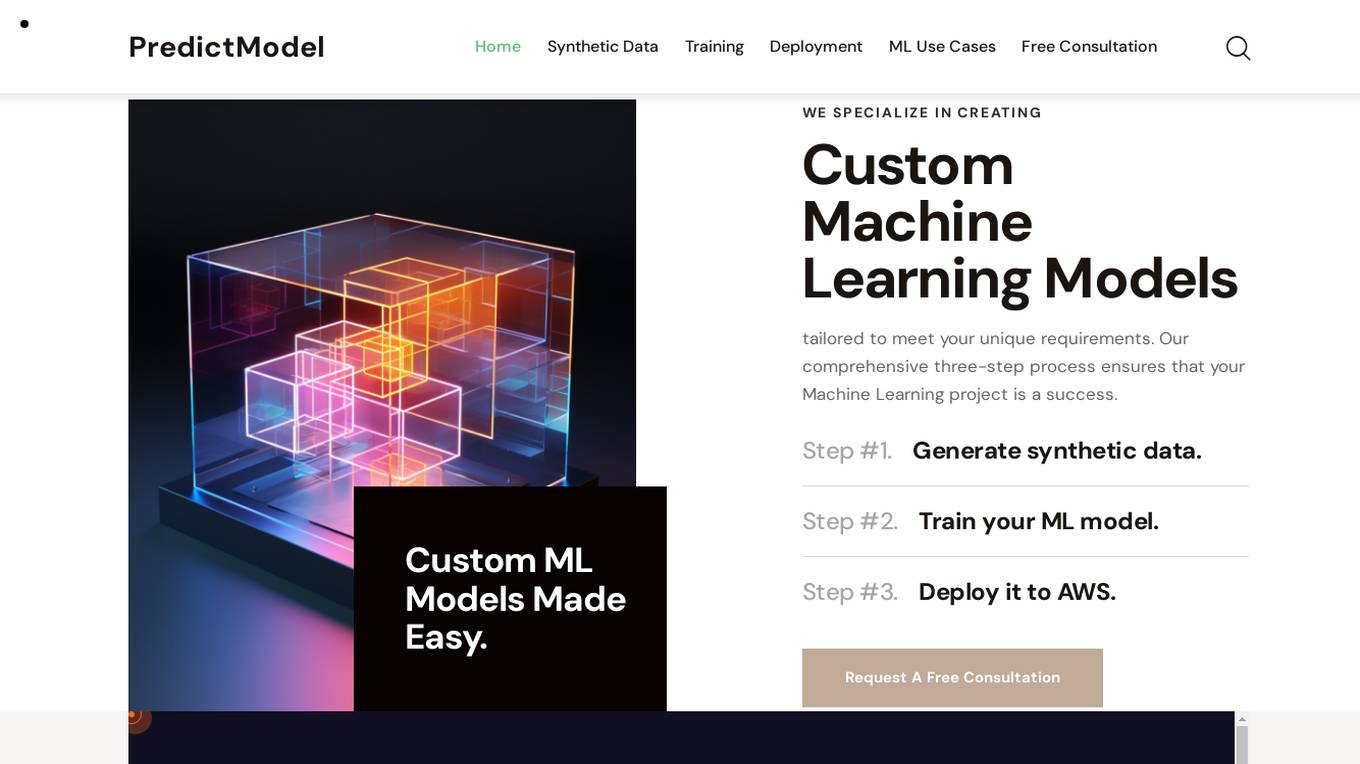
PredictModel
PredictModel is an AI tool that specializes in creating custom Machine Learning models tailored to meet unique requirements. The platform offers a comprehensive three-step process, including generating synthetic data, training ML models, and deploying them to AWS. PredictModel helps businesses streamline processes, improve customer segmentation, enhance client interaction, and boost overall business performance. The tool maximizes accuracy through customized synthetic data generation and saves time and money by providing expert ML engineers. With a focus on automated lead prioritization, fraud detection, cost optimization, and planning, PredictModel aims to stay ahead of the curve in the ML industry.
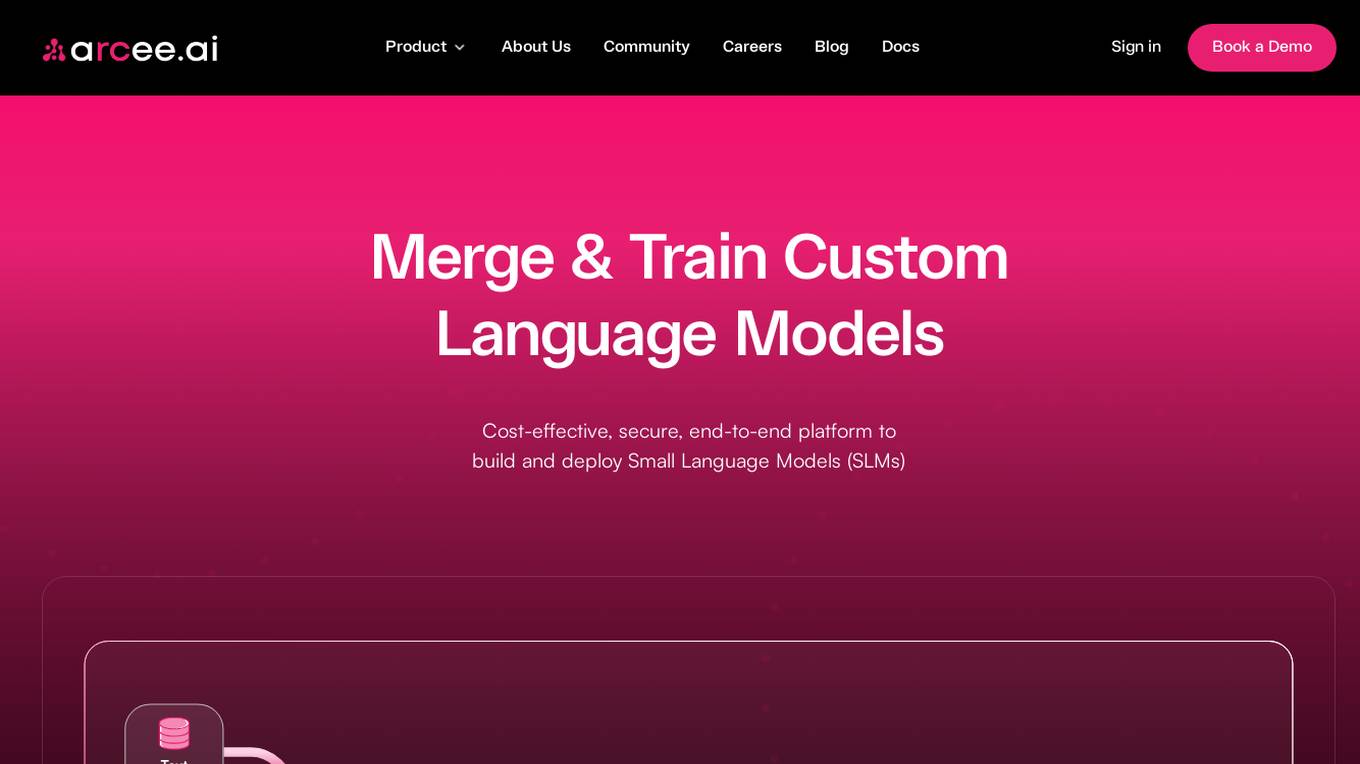
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.

BuildAi
BuildAi is an AI tool designed to provide the lowest cost GPU cloud for AI training on the market. The platform is powered with renewable energy, enabling companies to train AI models at a significantly reduced cost. BuildAi offers interruptible pricing, short term reserved capacity, and high uptime pricing options. The application focuses on optimizing infrastructure for training and fine-tuning machine learning models, not inference, and aims to decrease the impact of computing on the planet. With features like data transfer support, SSH access, and monitoring tools, BuildAi offers a comprehensive solution for ML teams.
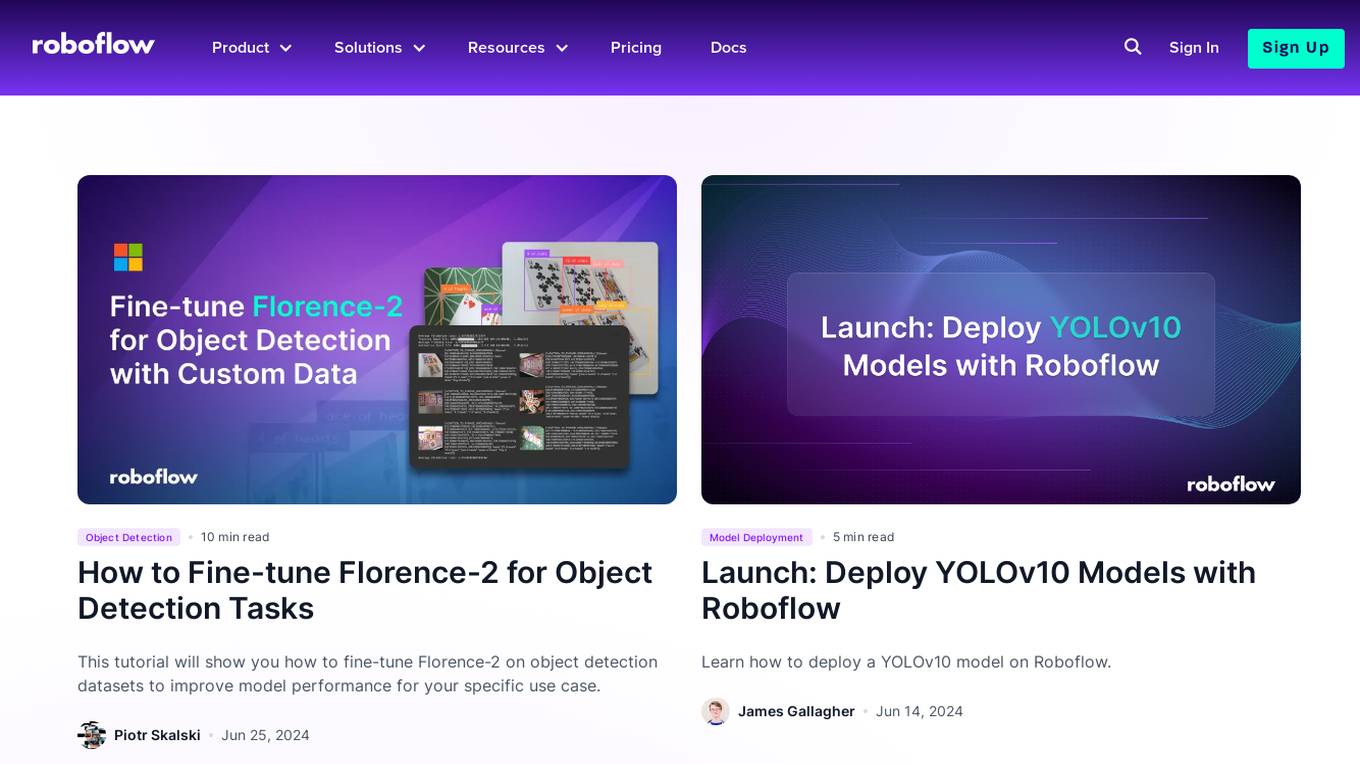
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
Exa
Exa is a web API designed to provide AI applications with powerful access to the web by organizing and retrieving the best content using embeddings. It offers features like semantic search, similarity search, content scraping, and powerful filters to help developers and companies gather and process data for AI training and analysis. Exa is trusted by thousands of developers and companies for its speed, quality, and ability to provide up-to-date information from various sources on the web.
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.
Voxel51
Voxel51 is an AI tool that provides open-source computer vision tools for machine learning. It offers solutions for various industries such as agriculture, aviation, driving, healthcare, manufacturing, retail, robotics, and security. Voxel51's main product, FiftyOne, helps users explore, visualize, and curate visual data to improve model performance and accelerate the development of visual AI applications. The platform is trusted by thousands of users and companies, offering both open-source and enterprise-ready solutions to manage and refine data and models for visual AI.
Edge Impulse
Edge Impulse is a leading edge AI platform that enables users to build datasets, train models, and optimize libraries to run directly on any edge device. It offers sensor datasets, feature engineering, model optimization, algorithms, and NVIDIA integrations. The platform is designed for product leaders, AI practitioners, embedded engineers, and OEMs across various industries and applications. Edge Impulse helps users unlock sensor data value, build high-quality sensor datasets, advance algorithm development, optimize edge AI models, and achieve measurable results. It allows for future-proofing workflows by generating models and algorithms that perform efficiently on any edge hardware.
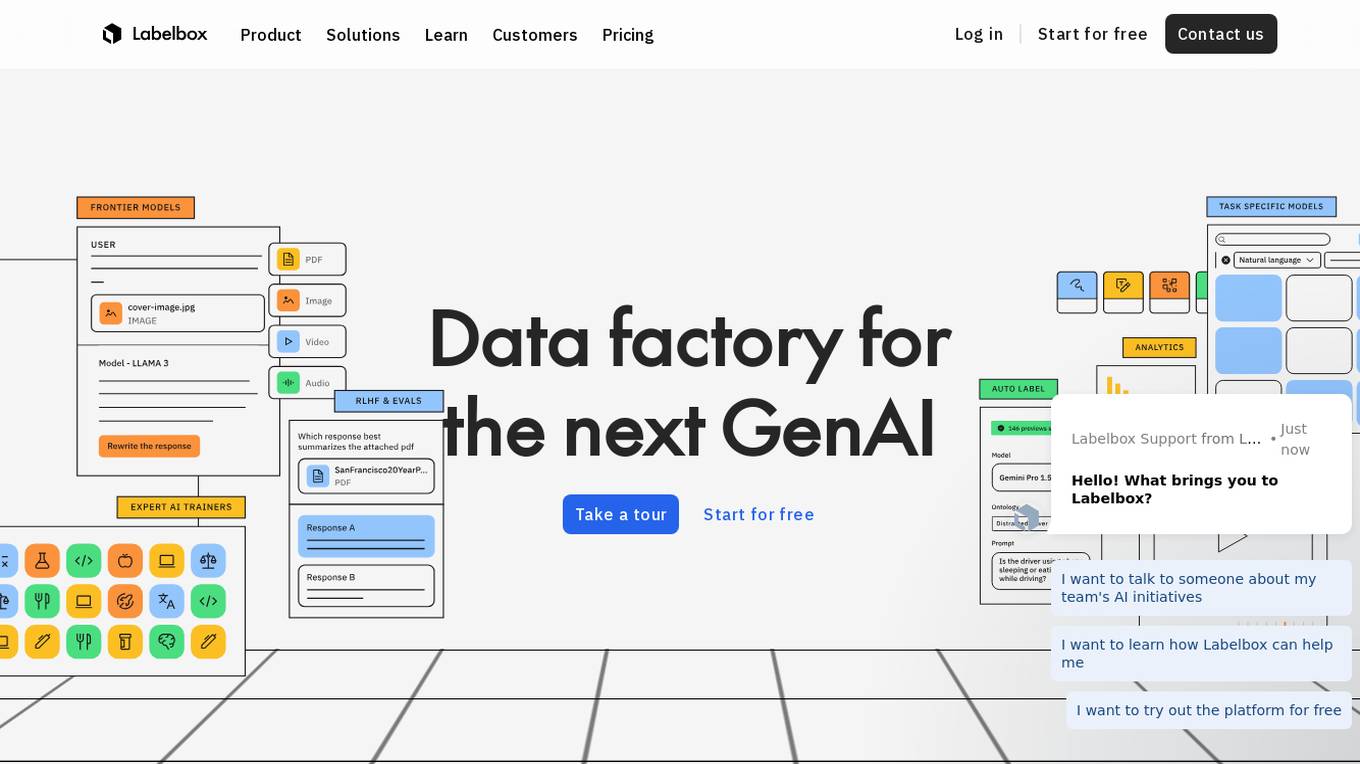
Labelbox
Labelbox is a data factory platform that empowers AI teams to manage data labeling, train models, and create better data with internet scale RLHF platform. It offers an all-in-one solution comprising tooling and services powered by a global community of domain experts. Labelbox operates a global data labeling infrastructure and operations for AI workloads, providing expert human network for data labeling in various domains. The platform also includes AI-assisted alignment for maximum efficiency, data curation, model training, and labeling services. Customers achieve breakthroughs with high-quality data through Labelbox.
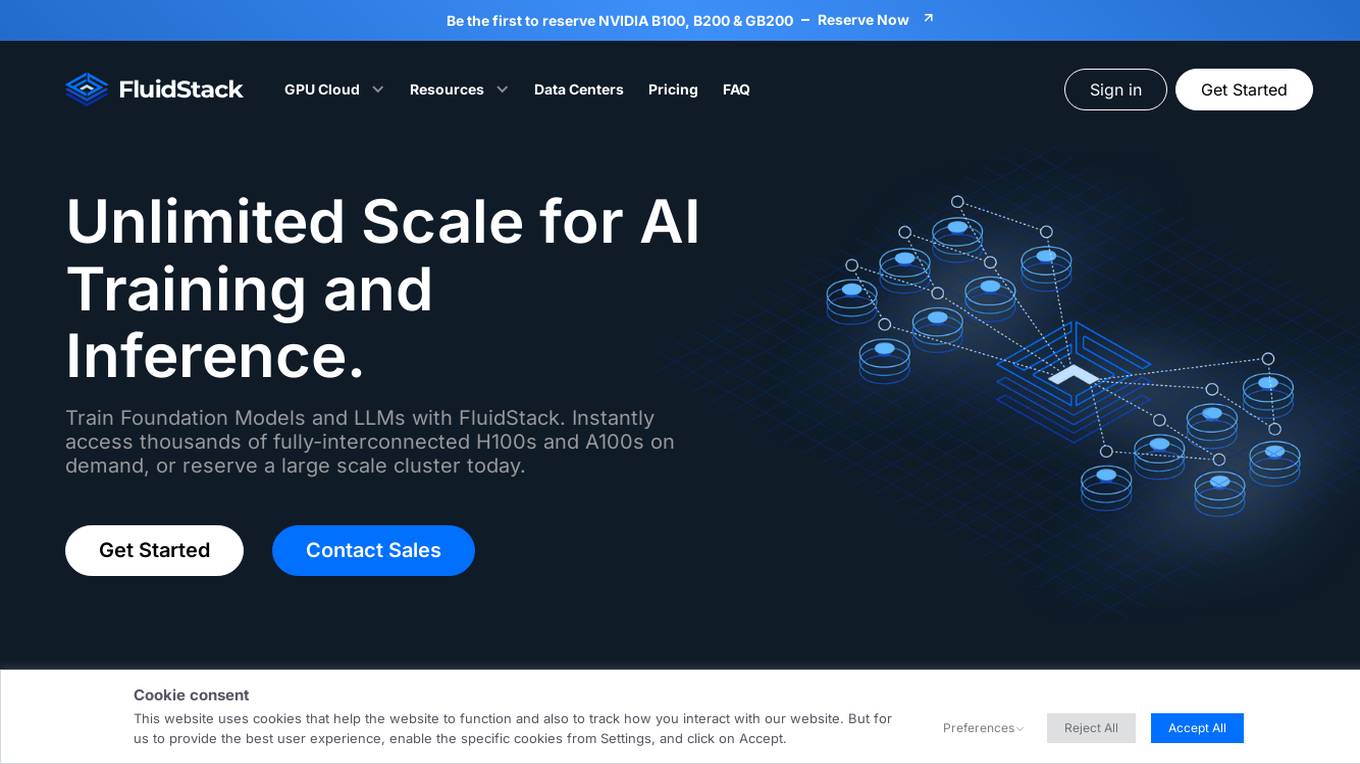
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.

LuckyRobots
LuckyRobots is an AI tool designed to make robotics accessible to software engineers by providing a simulation platform for deploying end-to-end AI models. The platform allows users to interact with robots using natural language commands, explore virtual environments, test robot models in realistic scenarios, and receive camera feeds for monitoring. LuckyRobots aims to train AI models on real-world simulations and respond to natural language inputs, offering a user-friendly and innovative approach to robotics development.
Datacog
Datacog is an AI application that offers a comprehensive solution for efficient data warehouse management, application integration, and machine learning. It enables organizations to leverage the complete capabilities of their data assets through intuitive data organization and model training features. With zero configuration, instant deployment, scalability, and real-time monitoring, Datacog simplifies model training and streamlines decision-making. Join the ranks of industry leaders who have harnessed the power of organized data and automation with Datacog.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.
Massed Compute
Massed Compute is an AI tool that provides cloud GPU services for VFX rendering, machine learning, high-performance computing, scientific simulations, and data analytics & visualization. The platform offers flexible and affordable plans, cutting-edge technology infrastructure, and timely creative problem-solving. As an NVIDIA Preferred Partner, Massed Compute ensures reliable and future-proof Tier III Data Center servers for various computing needs. Users can launch AI instances, scale machine learning projects, and access high-performance GPUs on-demand.

AIxBlock
AIxBlock is an AI tool that empowers users to unleash their AI initiatives on the Blockchain. The platform offers a comprehensive suite of features for building, deploying, and monitoring AI models, including AI data engine, multimodal-powered data crawler, auto annotation, consensus-driven labeling, MLOps platform, decentralized marketplaces, and more. By harnessing the power of blockchain technology, AIxBlock provides cost-efficient solutions for AI builders, compute suppliers, and freelancers to collaborate and benefit from decentralized supercomputing, P2P transactions, and consensus mechanisms.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
SentiSight.ai
SentiSight.ai is a machine learning platform for image recognition solutions, offering services such as object detection, image segmentation, image classification, image similarity search, image annotation, computer vision consulting, and intelligent automation consulting. Users can access pre-trained models, background removal, NSFW detection, text recognition, and image recognition API. The platform provides tools for image labeling, project management, and training tutorials for various image recognition models. SentiSight.ai aims to streamline the image annotation process, empower users to build and train their own models, and deploy them for online or offline use.
Bifrost AI
Bifrost AI is a data generation engine designed for AI and robotics applications. It enables users to train and validate AI models faster by generating physically accurate synthetic datasets in 3D simulations, eliminating the need for real-world data. The platform offers pixel-perfect labels, scenario metadata, and a simulated 3D world to enhance AI understanding. Bifrost AI empowers users to create new scenarios and datasets rapidly, stress test AI perception, and improve model performance. It is built for teams at every stage of AI development, offering features like automated labeling, class imbalance correction, and performance enhancement.
Cerebras
Cerebras is a leading AI tool and application provider that offers cutting-edge AI supercomputers, model services, and cloud solutions for various industries. The platform specializes in high-performance computing, large language models, and AI model training, catering to sectors such as health, energy, government, and financial services. Cerebras empowers developers and researchers with access to advanced AI models, open-source resources, and innovative hardware and software development kits.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.
AppsInAi Private Limited
AppsInAi Private Limited is a leading AI app development company trusted by top brands for innovative solutions driving real results in digital evolution. They offer a wide range of services including AI and ML development, machine learning, generative AI, chatGPT development, object recognition, recommendation engine, robotic process automation, NFT development, data analytics, web scraping, mobile app development, web development, IoT development, CRM and CMS software development, blockchain development, and UI/UX design.
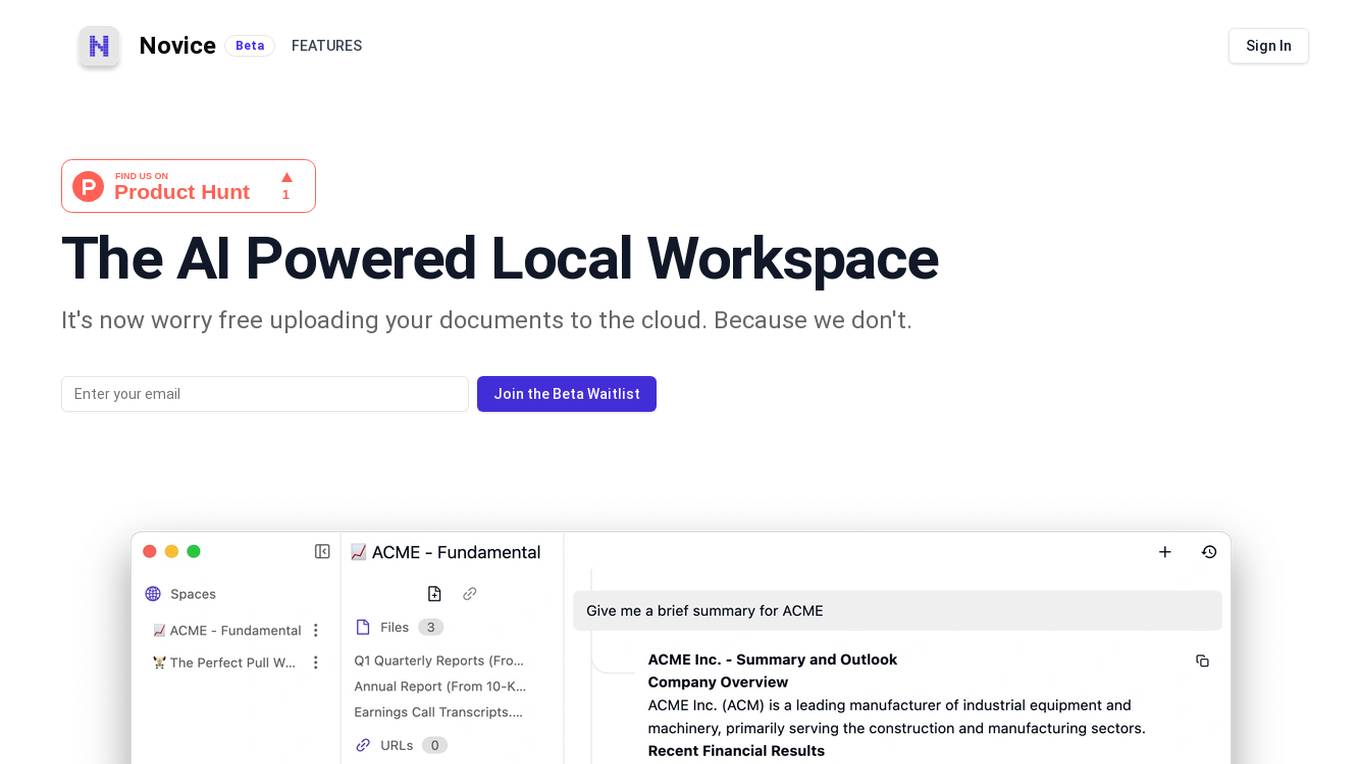
Novice
Novice is an AI-powered local workspace that allows users to access a wide range of models, including Open Source LLM models, without the need for complex setups. It ensures data confidentiality by enabling users to process data directly on their own computer. Novice eliminates the hassle of uploading files to the cloud and offers a cost-effective solution for utilizing AI technologies.
Scenario
Scenario is an AI tool designed to empower creators and marketers by providing unparalleled control over AI workflows. It allows users to generate production-ready visuals faster and more efficiently, streamlining workflows and enhancing creativity. With advanced features like custom AI model training, seamless integration, and full control over outputs, Scenario revolutionizes the process of asset ideation and creation. The tool is API-first and can be easily integrated into diverse workflows, design software, and game engines, making it a versatile solution for various industries.
Kiln
Kiln is an AI tool designed for fine-tuning LLM models, generating synthetic data, and facilitating collaboration on datasets. It offers intuitive desktop apps, zero-code fine-tuning for various models, interactive visual tools for data generation, Git-based version control for datasets, and the ability to generate various prompts from data. Kiln supports a wide range of models and providers, provides an open-source library and API, prioritizes privacy, and allows structured data tasks in JSON format. The tool is free to use and focuses on rapid AI prototyping and dataset collaboration.
TractoAI
TractoAI is an advanced AI platform that offers deep learning solutions for various industries. It provides Batch Inference with no rate limits, DeepSeek offline inference, and helps in training open source AI models. TractoAI simplifies training infrastructure setup, accelerates workflows with GPUs, and automates deployment and scaling for tasks like ML training and big data processing. The platform supports fine-tuning models, sandboxed code execution, and building custom AI models with distributed training launcher. It is developer-friendly, scalable, and efficient, offering a solution library and expert guidance for AI projects.
Ultralytics
Ultralytics is an AI tool that revolutionizes the world of Vision AI by enabling users to easily turn images into AI to get useful insights without writing any code. It offers a drag-and-drop interface for data input, model training, and deployment, making it accessible for startups, enterprises, data scientists, ML engineers, hobbyists, researchers, and academics. Ultralytics YOLO, the flagship tool, allows users to train machine learning models in seconds, select from pre-built models, test models on mobile devices, and deploy custom models to various formats. The tool is powered by Ultralytics Python package and is open-source, with a focus on computer vision, object detection, and image classification.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
DeepfakeVFX.com
DeepfakeVFX.com is an AI tool designed for the deepfake community, providing forums, guides, tutorials, and downloads for users interested in creating deepfake videos. The platform offers comprehensive resources for learning how to deepfake, including step-by-step tutorials and pretrained models. Users can engage in discussions, share knowledge, and access a variety of tools and settings to enhance their deepfake creations.

Machine Translation Research Hub
This website is a comprehensive resource for research in statistical and neural machine translation. It provides information, tools, and datasets related to the translation of text from one human language to another using computer algorithms trained on vast amounts of translated text.
Nscale
Nscale is a full-stack, scalable, and sustainable AI cloud platform that offers a wide range of AI services and solutions. It provides services for developing, training, tuning, and deploying AI models using on-demand services. Nscale also offers serverless inference API endpoints, fine-tuning capabilities, private cloud solutions, and various GPU clusters engineered for AI. The platform aims to simplify the journey from AI model development to production, offering a marketplace for AI/ML tools and resources. Nscale's infrastructure includes data centers powered by renewable energy, high-performance GPU nodes, and optimized networking and storage solutions.
250 - Open Source AI Tools

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).

deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.
nitrain
Nitrain is a framework for medical imaging AI that provides tools for sampling and augmenting medical images, training models on medical imaging datasets, and visualizing model results in a medical imaging context. It supports using pytorch, keras, and tensorflow.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.
vertex-ai-samples
The Google Cloud Vertex AI sample repository contains notebooks and community content that demonstrate how to develop and manage ML workflows using Google Cloud Vertex AI.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.
argilla
Argilla is a collaboration platform for AI engineers and domain experts that require high-quality outputs, full data ownership, and overall efficiency. It helps users improve AI output quality through data quality, take control of their data and models, and improve efficiency by quickly iterating on the right data and models. Argilla is an open-source community-driven project that provides tools for achieving and maintaining high-quality data standards, with a focus on NLP and LLMs. It is used by AI teams from companies like the Red Cross, Loris.ai, and Prolific to improve the quality and efficiency of AI projects.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

LLM-And-More
LLM-And-More is a one-stop solution for training and applying large models, covering the entire process from data processing to model evaluation, from training to deployment, and from idea to service. In this project, users can easily train models through this project and generate the required product services with one click.
MoonshotAI-Cookbook
The MoonshotAI-Cookbook provides example code and guides for accomplishing common tasks with the MoonshotAI API. To run these examples, you'll need an MoonshotAI account and associated API key. Most code examples are written in Python, though the concepts can be applied in any language.
effort
Effort is an example implementation of the bucketMul algorithm, which allows for real-time adjustment of the number of calculations performed during inference of an LLM model. At 50% effort, it performs as fast as regular matrix multiplications on Apple Silicon chips; at 25% effort, it is twice as fast while still retaining most of the quality. Additionally, users have the option to skip loading the least important weights.
mobius
Mobius is an AI infra platform including realtime computing and training. It is built on Ray, a distributed computing framework, and provides a number of features that make it well-suited for online machine learning tasks. These features include: * **Cross Language**: Mobius can run in multiple languages (only Python and Java are supported currently) with high efficiency. You can implement your operator in different languages and run them in one job. * **Single Node Failover**: Mobius has a special failover mechanism that only needs to rollback the failed node itself, in most cases, to recover the job. This is a huge benefit if your job is sensitive about failure recovery time. * **AutoScaling**: Mobius can generate a new graph with different configurations in runtime without stopping the job. * **Fusion Training**: Mobius can combine TensorFlow/Pytorch and streaming, then building an e2e online machine learning pipeline. Mobius is still under development, but it has already been used to power a number of real-world applications, including: * A real-time recommendation system for a major e-commerce company * A fraud detection system for a large financial institution * A personalized news feed for a major news organization If you are interested in using Mobius for your own online machine learning projects, you can find more information in the documentation.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
AI-Horde
The AI Horde is an enterprise-level ML-Ops crowdsourced distributed inference cluster for AI Models. This middleware can support both Image and Text generation. It is infinitely scalable and supports seamless drop-in/drop-out of compute resources. The Public version allows people without a powerful GPU to use Stable Diffusion or Large Language Models like Pygmalion/Llama by relying on spare/idle resources provided by the community and also allows non-python clients, such as games and apps, to use AI-provided generations.

BitMat
BitMat is a Python package designed to optimize matrix multiplication operations by utilizing custom kernels written in Triton. It leverages the principles outlined in the "1bit-LLM Era" paper, specifically utilizing packed int8 data to enhance computational efficiency and performance in deep learning and numerical computing tasks.
LLM-GenAI-Transformers-Notebooks
This repository is a collection of LLM notebooks with tutorials and projects. It covers topics such as Transformers tutorials, LLM notebooks and their applications, tools and technologies of GenAI, courses in GenAI, and Generative AI blogs/articles. Contributions are welcome.

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.
google-research
This repository contains code released by Google Research. All datasets in this repository are released under the CC BY 4.0 International license, which can be found here: https://creativecommons.org/licenses/by/4.0/legalcode. All source files in this repository are released under the Apache 2.0 license, the text of which can be found in the LICENSE file.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
FedML
FedML is a unified and scalable machine learning library for running training and deployment anywhere at any scale. It is highly integrated with FEDML Nexus AI, a next-gen cloud service for LLMs & Generative AI. FEDML Nexus AI provides holistic support of three interconnected AI infrastructure layers: user-friendly MLOps, a well-managed scheduler, and high-performance ML libraries for running any AI jobs across GPU Clouds.
cloudberrydb
Cloudberry Database (CBDB or CloudberryDB) is a next-generation unified database for analytics and AI. It is created by a bunch of original Greenplum Database developers and ASF committers. Cloudberry Database aims to bring modern computing capabilities to the traditional distributed MPP database to support Analytics and AI/ML workloads in one platform.
cookbook
This repository contains community-driven practical examples of building AI applications and solving various tasks with AI using open-source tools and models. Everyone is welcome to contribute, and we value everybody's contribution! There are several ways you can contribute to the Open-Source AI Cookbook: Submit an idea for a desired example/guide via GitHub Issues. Contribute a new notebook with a practical example. Improve existing examples by fixing issues/typos. Before contributing, check currently open issues and pull requests to avoid working on something that someone else is already working on.
ort
Ort is an unofficial ONNX Runtime 1.17 wrapper for Rust based on the now inactive onnxruntime-rs. ONNX Runtime accelerates ML inference on both CPU and GPU.

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
applied-ai-engineering-samples
The Google Cloud Applied AI Engineering repository provides reference guides, blueprints, code samples, and hands-on labs developed by the Google Cloud Applied AI Engineering team. It contains resources for Generative AI on Vertex AI, including code samples and hands-on labs demonstrating the use of Generative AI models and tools in Vertex AI. Additionally, it offers reference guides and blueprints that compile best practices and prescriptive guidance for running large-scale AI/ML workloads on Google Cloud AI/ML infrastructure.
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.
awesome-ruby-ai
Awesome Ruby AI is a curated list of awesome AI projects built in Ruby. It includes open source API libraries, vector database clients, bot platforms, composability frameworks, and i18n tools. These tools can be used for a variety of tasks, such as natural language processing, computer vision, and machine learning.
vasttools
This repository contains a collection of tools that can be used with vastai. The tools are free to use, modify and distribute. If you find this useful and wish to donate your welcome to send your donations to the following wallets. BTC 15qkQSYXP2BvpqJkbj2qsNFb6nd7FyVcou XMR 897VkA8sG6gh7yvrKrtvWningikPteojfSgGff3JAUs3cu7jxPDjhiAZRdcQSYPE2VGFVHAdirHqRZEpZsWyPiNK6XPQKAg RVN RSgWs9Co8nQeyPqQAAqHkHhc5ykXyoMDUp USDT(ETH ERC20) 0xa5955cf9fe7af53bcaa1d2404e2b17a1f28aac4f Paypal PayPal.Me/cryptolabsZA
vertex-ai-mlops
Vertex AI is a platform for end-to-end model development. It consist of core components that make the processes of MLOps possible for design patterns of all types.
AHU-AI-Repository
This repository is dedicated to the learning and exchange of resources for the School of Artificial Intelligence at Anhui University. Notes will be published on this website first: https://www.aoaoaoao.cn and will be synchronized to the repository regularly. You can also contact me at [email protected].
gaussian-painters
This tool is a fork of the 3D Gaussian Splatting code. It allows users to create a dataset ready to be trained with the Gaussian Splatting code. The dataset can be used for various experiments, such as creating orthogonal images, steganography, and lenticular effects. The tool also includes a visualizer that allows users to visualize the "painting" process during the Gaussian Splatting optimization.
PythonPark
PythonPark is a paradise for learning Python, providing babysitter-level tutorials on AI labs, treasure videos, data structures, study guides, machine learning practicals, deep learning practicals, Python basics, web scraping, big company interview experiences, programming life, and resource sharing. Original articles are published at least twice a week, with the latest articles being first released on WeChat and videos on Bilibili. Join the WeChat group for technical discussions or to provide feedback. Continuously improving and outputting content!
modern_ai_for_beginners
This repository provides a comprehensive guide to modern AI for beginners, covering both theoretical foundations and practical implementation. It emphasizes the importance of understanding both the mathematical principles and the code implementation of AI models. The repository includes resources on PyTorch, deep learning fundamentals, mathematical foundations, transformer-based LLMs, diffusion models, software engineering, and full-stack development. It also features tutorials on natural language processing with transformers, reinforcement learning, and practical deep learning for coders.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.
MeloTTS
MeloTTS is a high-quality multi-lingual text-to-speech library by MyShell.ai. It supports various languages including English (American, British, Indian, Australian), Spanish, French, Chinese, Japanese, and Korean. The Chinese speaker also supports mixed Chinese and English. The library is fast enough for CPU real-time inference and offers features like using without installation, local installation, and training on custom datasets. The Python API and model cards are available in the repository and on HuggingFace. The community can join the Discord channel for discussions and collaboration opportunities. Contributions are welcome, and the library is under the MIT License. MeloTTS is based on TTS, VITS, VITS2, and Bert-VITS2.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
bittensor
Bittensor is an internet-scale neural network that incentivizes computers to provide access to machine learning models in a decentralized and censorship-resistant manner. It operates through a token-based mechanism where miners host, train, and procure machine learning systems to fulfill verification problems defined by validators. The network rewards miners and validators for their contributions, ensuring continuous improvement in knowledge output. Bittensor allows anyone to participate, extract value, and govern the network without centralized control. It supports tasks such as generating text, audio, images, and extracting numerical representations.

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.

awesome-llm
Awesome LLM is a curated list of resources related to Large Language Models (LLMs), including models, projects, datasets, benchmarks, materials, papers, posts, GitHub repositories, HuggingFace repositories, and reading materials. It provides detailed information on various LLMs, their parameter sizes, announcement dates, and contributors. The repository covers a wide range of LLM-related topics and serves as a valuable resource for researchers, developers, and enthusiasts interested in the field of natural language processing and artificial intelligence.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.
OpenAGI
OpenAGI is an AI agent creation package designed for researchers and developers to create intelligent agents using advanced machine learning techniques. The package provides tools and resources for building and training AI models, enabling users to develop sophisticated AI applications. With a focus on collaboration and community engagement, OpenAGI aims to facilitate the integration of AI technologies into various domains, fostering innovation and knowledge sharing among experts and enthusiasts.
hopsworks
Hopsworks is a data platform for ML with a Python-centric Feature Store and MLOps capabilities. It provides collaboration for ML teams, offering a secure, governed platform for developing, managing, and sharing ML assets. Hopsworks supports project-based multi-tenancy, team collaboration, development tools for Data Science, and is available on any platform including managed cloud services and on-premise installations. The platform enables end-to-end responsibility from raw data to managed features and models, supports versioning, lineage, and provenance, and facilitates the complete MLOps life cycle.
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.

pipeline
Pipeline is a Python library designed for constructing computational flows for AI/ML models. It supports both development and production environments, offering capabilities for inference, training, and finetuning. The library serves as an interface to Mystic, enabling the execution of pipelines at scale and on enterprise GPUs. Users can also utilize this SDK with Pipeline Core on a private hosted cluster. The syntax for defining AI/ML pipelines is reminiscent of sessions in Tensorflow v1 and Flows in Prefect.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.
Midori-AI
Midori AI is a cutting-edge initiative dedicated to advancing the field of artificial intelligence through research, development, and community engagement. They focus on creating innovative AI solutions, exploring novel approaches, and empowering users to harness the power of AI. Key areas of focus include cluster-based AI, AI setup assistance, AI development for Discord bots, model serving and hosting, novel AI memory architectures, and Carly - a fully simulated human with advanced AI capabilities. They have also developed the Midori AI Subsystem to streamline AI workloads by providing simplified deployment, standardized configurations, isolation for AI systems, and a growing library of backends and tools.
AI-Notes
AI-Notes is a repository dedicated to practical applications of artificial intelligence and deep learning. It covers concepts such as data mining, machine learning, natural language processing, and AI. The repository contains Jupyter Notebook examples for hands-on learning and experimentation. It explores the development stages of AI, from narrow artificial intelligence to general artificial intelligence and superintelligence. The content delves into machine learning algorithms, deep learning techniques, and the impact of AI on various industries like autonomous driving and healthcare. The repository aims to provide a comprehensive understanding of AI technologies and their real-world applications.
instruct-ner
Instruct NER is a solution for complex Named Entity Recognition tasks, including Nested NER, based on modern Large Language Models (LLMs). It provides tools for dataset creation, training, automatic metric calculation, inference, error analysis, and model implementation. Users can create instructions for LLM, build dictionaries with labels, and generate model input templates. The tool supports various entity types and datasets, such as RuDReC, NEREL-BIO, CoNLL-2003, and MultiCoNER II. It offers training scripts for LLMs and metric calculation functions. Instruct NER models like Llama, Mistral, T5, and RWKV are implemented, with HuggingFace models available for adaptation and merging.
awesome-ml
Awesome ML is a curated list of resources and tools related to machine learning, covering a wide range of topics such as large language models, image models, video models, audio models, and marketing data science. It includes open LLM models, tools, GUIs, backends, voice assistants, code generation, libraries, fine tuning, data sets, research, image and video models, audio tasks like compression, speech recognition, and music generation, as well as resources for marketing data science. The repository aims to provide a comprehensive collection of resources for individuals interested in machine learning and its applications.

co-llm
Co-LLM (Collaborative Language Models) is a tool for learning to decode collaboratively with multiple language models. It provides a method for data processing, training, and inference using a collaborative approach. The tool involves steps such as formatting/tokenization, scoring logits, initializing Z vector, deferral training, and generating results using multiple models. Co-LLM supports training with different collaboration pairs and provides baseline training scripts for various models. In inference, it uses 'vllm' services to orchestrate models and generate results through API-like services. The tool is inspired by allenai/open-instruct and aims to improve decoding performance through collaborative learning.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.
forust
Forust is a lightweight package for building gradient boosted decision tree ensembles. The algorithm code is written in Rust with a Python wrapper. It implements the same algorithm as XGBoost and provides nearly identical results. The package was developed to better understand XGBoost, as a fun project in Rust, and to experiment with adding new features to the algorithm in a simpler codebase. Forust allows training gradient boosted decision tree ensembles with multiple objective functions, predicting on datasets, inspecting model structures, calculating feature importance, and saving/loading trained boosters.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

GrAIdient
GrAIdient is a framework designed to enable the development of deep learning models using the internal GPU of a Mac. It provides access to the graph of layers, allowing for unique model design with greater understanding, control, and reproducibility. The goal is to challenge the understanding of deep learning models, transitioning from black box to white box models. Key features include direct access to layers, native Mac GPU support, Swift language implementation, gradient checking, PyTorch interoperability, and more. The documentation covers main concepts, architecture, and examples. GrAIdient is MIT licensed.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.
intel-extension-for-tensorflow
Intel® Extension for TensorFlow* is a high performance deep learning extension plugin based on TensorFlow PluggableDevice interface. It aims to accelerate AI workloads by allowing users to plug Intel CPU or GPU devices into TensorFlow on-demand, exposing the computing power inside Intel's hardware. The extension provides XPU specific implementation, kernels & operators, graph optimizer, device runtime, XPU configuration management, XPU backend selection, and options for turning on/off advanced features.
ibm-generative-ai
IBM Generative AI Python SDK is a tool designed for the Tech Preview program for IBM Foundation Models Studio. It brings IBM Generative AI (GenAI) into Python programs, offering various operations and types. Users can start a trial version or request a demo via the provided link. The SDK was recently rewritten and released under V2 in 2024, with a migration guide available. Contributors are welcome to participate in the open-source project by contributing documentation, tests, bug fixes, and new functionality.
amazon-sagemaker-generativeai
Repository for training and deploying Generative AI models, including text-text, text-to-image generation, prompt engineering playground and chain of thought examples using SageMaker Studio. The tool provides a platform for users to experiment with generative AI techniques, enabling them to create text and image outputs based on input data. It offers a range of functionalities for training and deploying models, as well as exploring different generative AI applications.
SPAG
This repository contains the implementation of Self-Play of Adversarial Language Game (SPAG) as described in the paper 'Self-playing Adversarial Language Game Enhances LLM Reasoning'. The SPAG involves training Language Models (LLMs) in an adversarial language game called Adversarial Taboo. The repository provides tools for imitation learning, self-play episode collection, and reinforcement learning on game episodes to enhance LLM reasoning abilities. The process involves training models using GPUs, launching imitation learning, conducting self-play episodes, assigning rewards based on outcomes, and learning the SPAG model through reinforcement learning. Continuous improvements on reasoning benchmarks can be observed by repeating the episode-collection and SPAG-learning processes.
Vodalus-Expert-LLM-Forge
Vodalus Expert LLM Forge is a tool designed for crafting datasets and efficiently fine-tuning models using free open-source tools. It includes components for data generation, LLM interaction, RAG engine integration, model training, fine-tuning, and quantization. The tool is suitable for users at all levels and is accompanied by comprehensive documentation. Users can generate synthetic data, interact with LLMs, train models, and optimize performance for local execution. The tool provides detailed guides and instructions for setup, usage, and customization.
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
langdrive
LangDrive is an open-source AI library that simplifies training, deploying, and querying open-source large language models (LLMs) using private data. It supports data ingestion, fine-tuning, and deployment via a command-line interface, YAML file, or API, with a quick, easy setup. Users can build AI applications such as question/answering systems, chatbots, AI agents, and content generators. The library provides features like data connectors for ingestion, fine-tuning of LLMs, deployment to Hugging Face hub, inference querying, data utilities for CRUD operations, and APIs for model access. LangDrive is designed to streamline the process of working with LLMs and making AI development more accessible.
2024-AICS-EXP
This repository contains the complete archive of the 2024 version of the 'Intelligent Computing System' experiment at the University of Chinese Academy of Sciences. The experiment content for 2024 has undergone extensive adjustments to the knowledge system and experimental topics, including the transition from TensorFlow to PyTorch, significant modifications to previous code, and the addition of experiments with large models. The project is continuously updated in line with the course progress, currently up to the seventh experiment. Updates include the addition of experiments like YOLOv5 in Experiment 5-3, updates to theoretical teaching materials, and fixes for bugs in Experiment 6 code. The repository also includes experiment manuals, questions, and answers for various experiments, with some data sets hosted on Baidu Cloud due to size limitations on GitHub.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.
llmfarm_core.swift
LLMFarm_core.swift is a Swift library designed to work with large language models (LLM). It enables users to load different LLMs with specific parameters. The library supports MacOS (13+) and iOS (16+), offering various inferences and sampling methods. It includes features such as Metal support (not compatible with Intel Mac), model setting templates, LoRA adapters support, and LoRA train support. The library is based on ggml and llama.cpp by Georgi Gerganov, with additional sources from rwkv.cpp by saharNooby and Mia by byroneverson.
ML-AI-2-LT
ML-AI-2-LT is a repository that serves as a glossary for machine learning and deep learning concepts. It contains translations and explanations of various terms related to artificial intelligence, including definitions and notes. Users can contribute by filling issues for unclear concepts or by submitting pull requests with suggestions or additions. The repository aims to provide a comprehensive resource for understanding key terminology in the field of AI and machine learning.
AI-For-Beginners
AI-For-Beginners is a comprehensive 12-week, 24-lesson curriculum designed by experts at Microsoft to introduce beginners to the world of Artificial Intelligence (AI). The curriculum covers various topics such as Symbolic AI, Neural Networks, Computer Vision, Natural Language Processing, Genetic Algorithms, and Multi-Agent Systems. It includes hands-on lessons, quizzes, and labs using popular frameworks like TensorFlow and PyTorch. The focus is on providing a foundational understanding of AI concepts and principles, making it an ideal starting point for individuals interested in AI.
simpletransformers
Simple Transformers is a library based on the Transformers library by HuggingFace, allowing users to quickly train and evaluate Transformer models with only 3 lines of code. It supports various tasks such as Information Retrieval, Language Models, Encoder Model Training, Sequence Classification, Token Classification, Question Answering, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification, and Conversational AI.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.
moai
moai is a PyTorch-based AI Model Development Kit (MDK) designed to improve data-driven model workflows, design, and understanding. It offers modularity via monads for model building blocks, reproducibility via configuration-based design, productivity via a data-driven domain modelling language (DML), extensibility via plugins, and understanding via inter-model performance and design aggregation. The tool provides specific integrated actions like play, train, evaluate, plot, diff, and reprod to support heavy data-driven workflows with analytics, knowledge extraction, and reproduction. moai relies on PyTorch, Lightning, Hydra, TorchServe, ONNX, Visdom, HiPlot, Kornia, Albumentations, and the wider open-source community for its functionalities.

openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.
PythonAiRoad
PythonAiRoad is a repository containing classic original articles source code from the 'Algorithm Gourmet House'. It is a platform for sharing algorithms and code related to artificial intelligence. Users are encouraged to contact the author for further discussions or collaborations. The repository serves as a valuable resource for those interested in AI algorithms and implementations.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.
crystal-text-llm
This repository contains the code for the paper Fine-Tuned Language Models Generate Stable Inorganic Materials as Text. It demonstrates how finetuned LLMs can be used to generate stable materials, match or exceed the performance of domain specific models, mutate existing materials, and sample crystal structures conditioned on text descriptions. The method is distinct from CrystaLLM, which trains language models from scratch on CIF-formatted crystals.
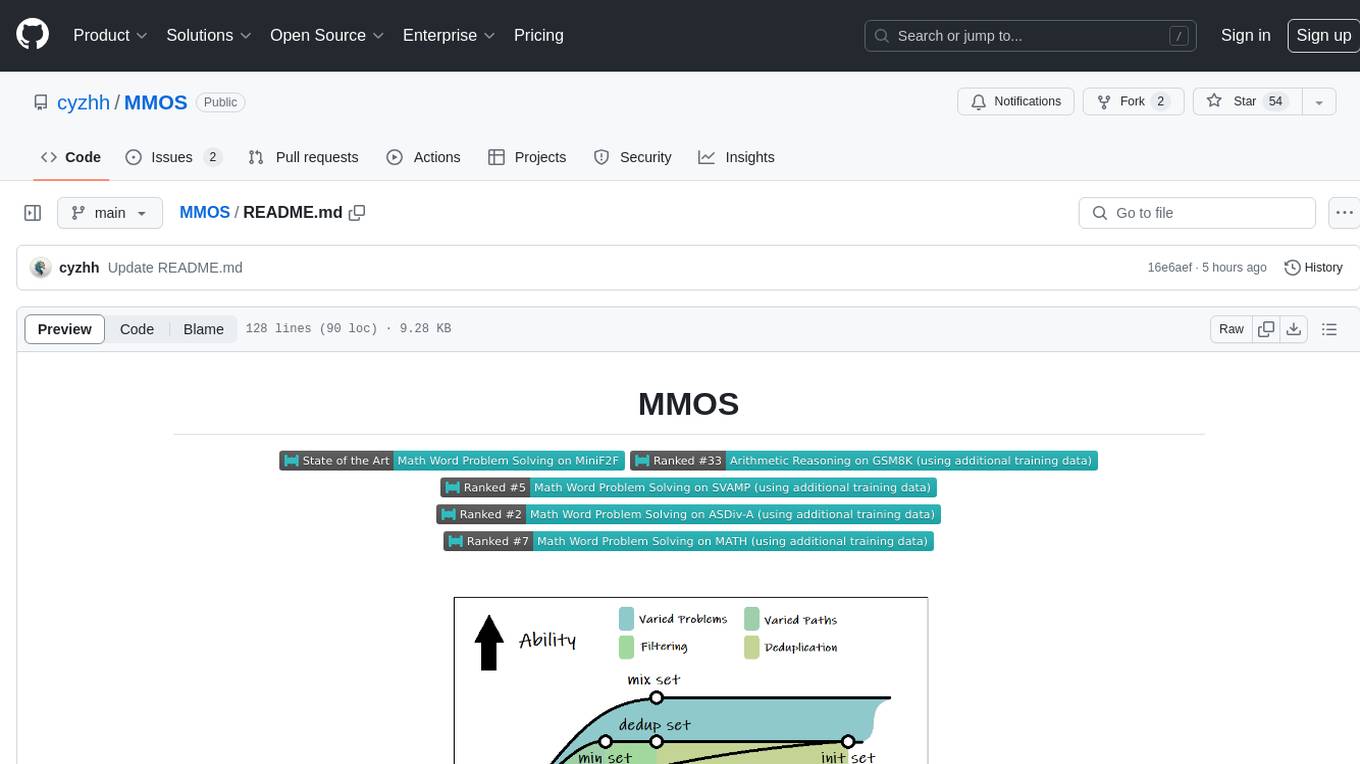
MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.
LLM_Learning_Database
LLM Learning Database is a comprehensive repository dedicated to AI large models, offering a curated collection of resources covering fundamental knowledge, cutting-edge technologies, and practical applications. It includes guides, case studies, code examples for model training, optimization, and deployment, as well as insightful articles from industry experts and scholars. Whether you are a beginner or an experienced learner in the field of AI large models, this repository aims to support your learning journey and foster continuous growth and progress.
bonito
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.
RookieAI_yolov8
RookieAI_yolov8 is an open-source project designed for developers and users interested in utilizing YOLOv8 models for object detection tasks. The project provides instructions for setting up the required libraries and Pytorch, as well as guidance on using custom or official YOLOv8 models. Users can easily train their own models and integrate them with the software. The tool offers features for packaging the code, managing model files, and organizing the necessary resources for running the software. It also includes updates and optimizations for better performance and functionality, with a focus on FPS game aimbot functionalities. The project aims to provide a comprehensive solution for object detection tasks using YOLOv8 models.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.
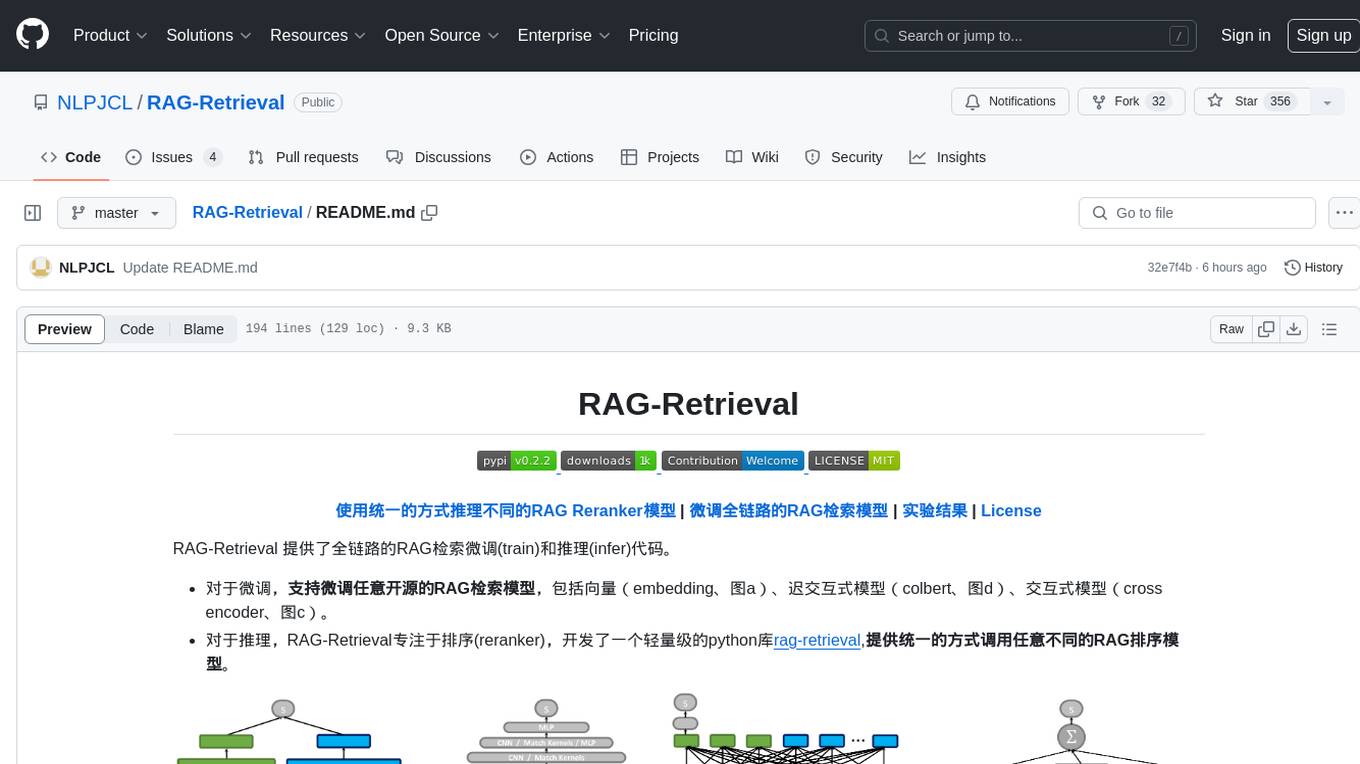
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
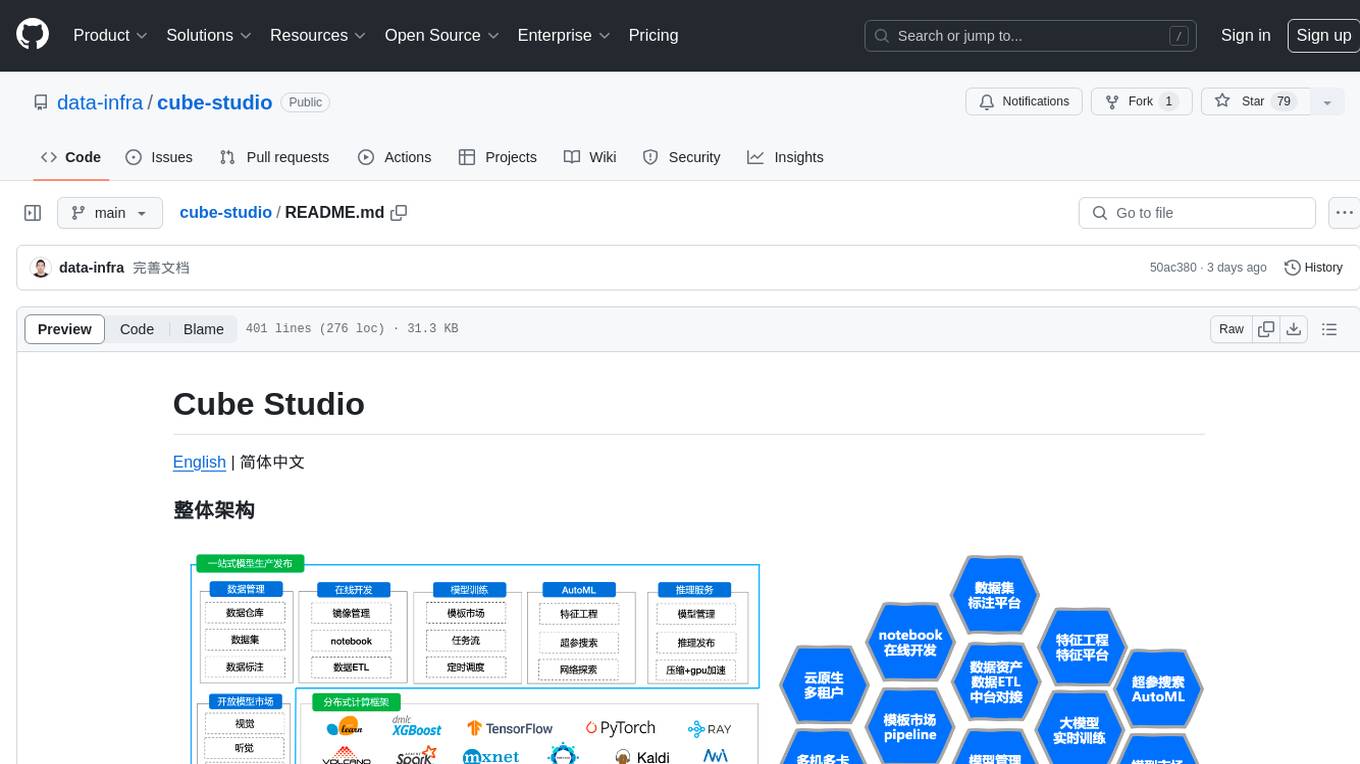
cube-studio
Cube Studio is an open-source all-in-one cloud-native machine learning platform that provides various functionalities such as project group management, network configuration, user management, role management, billing functions, SSO single sign-on, support for multiple computing power types, support for multiple resource groups and clusters, edge cluster support, serverless cluster mode support, database storage support, machine resource management, storage disk management, internationalization capabilities, data map management, data calculation, ETL orchestration, data set management, data annotation, image/audio/text dataset support, feature processing, traditional machine learning algorithms, distributed deep learning frameworks, distributed acceleration frameworks, model evaluation, model format conversion, model registration, model deployment, distributed media processing, custom operators, automatic learning, custom training images, automatic parameter tuning, TensorBoard jobs, internal services, model management, inference services, monitoring, model application management, model marketplace, model development, model fine-tuning, web model deployment, automated annotation, dataset SDK, notebook SDK, pipeline training SDK, inference service SDK, large model distributed training, large model inference, large model fine-tuning, intelligent conversation, private knowledge base, model deployment for WeChat public accounts, enterprise WeChat group chatbot integration, DingTalk group chatbot integration, and more. Cube Studio offers template-based functionality for data import/export, data processing, feature processing, machine learning frameworks, machine learning algorithms, deep learning frameworks, model processing, model serving, monitoring, and more.
NeMo-Framework-Launcher
The NeMo Framework Launcher is a cloud-native tool designed for launching end-to-end NeMo Framework training jobs. It focuses on foundation model training for generative AI models, supporting large language model pretraining with techniques like model parallelism, tensor, pipeline, sequence, distributed optimizer, mixed precision training, and more. The tool scales to thousands of GPUs and can be used for training LLMs on trillions of tokens. It simplifies launching training jobs on cloud service providers or on-prem clusters, generating submission scripts, organizing job results, and supporting various model operations like fine-tuning, evaluation, export, and deployment.
CosyVoice
CosyVoice is a tool designed for speech synthesis, offering pretrained models for zero-shot, sft, instruct inference. It provides a web demo for easy usage and supports advanced users with train and inference scripts. The tool can be deployed using grpc for service deployment. Users can download pretrained models and resources for immediate use or train their own models from scratch. CosyVoice is suitable for researchers, developers, linguists, AI engineers, and speech technology enthusiasts.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.
LL3DA
LL3DA is a Large Language 3D Assistant that responds to both visual and textual interactions within complex 3D environments. It aims to help Large Multimodal Models (LMM) comprehend, reason, and plan in diverse 3D scenes by directly taking point cloud input and responding to textual instructions and visual prompts. LL3DA achieves remarkable results in 3D Dense Captioning and 3D Question Answering, surpassing various 3D vision-language models. The code is fully released, allowing users to train customized models and work with pre-trained weights. The tool supports training with different LLM backends and provides scripts for tuning and evaluating models on various tasks.
awesome-ai-repositories
A curated list of open source repositories for AI Engineers. The repository provides a comprehensive collection of tools and frameworks for various AI-related tasks such as AI Gateway, AI Workload Manager, Copilot Development, Dataset Engineering, Evaluation, Fine Tuning, Function Calling, Graph RAG, Guardrails, Local Model Inference, LLM Agent Framework, Model Serving, Observability, Pre Training, Prompt Engineering, RAG Framework, Security, Structured Extraction, Structured Generation, Vector DB, and Voice Agent.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. It aims to replicate the best-known performance of target model/dataset combinations in optimally-configured hardware environments. The repository will be deprecated upon the publication of v3.2.0 and will no longer be maintained or published.
AI-Song-Cover-RVC
AI-Song-Cover-RVC is an all-in-one repository that provides tools for downloading YouTube WAV files, separating vocals, splitting audio, training models, and performing inference using Google Colab or Kaggle. The repository offers tutorials in Indonesian for training and inference tasks. Users can access various tools and resources for processing audio data and generating song covers. The repository aims to simplify the process of working with audio data for music-related projects.
EasyLM
EasyLM is a one-stop solution for pre-training, fine-tuning, evaluating, and serving large language models in JAX/Flax. It simplifies the process by leveraging JAX's pjit functionality to scale up training to multiple TPU/GPU accelerators. Built on top of Huggingface's transformers and datasets, EasyLM offers an easy-to-use and customizable codebase for training large language models without the complexity found in other frameworks. It supports sharding model weights and training data across multiple accelerators, enabling multi-TPU/GPU training on a single host or across multiple hosts on Google Cloud TPU Pods. EasyLM currently supports models like LLaMA, LLaMA 2, and LLaMA 3.
polaris
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.
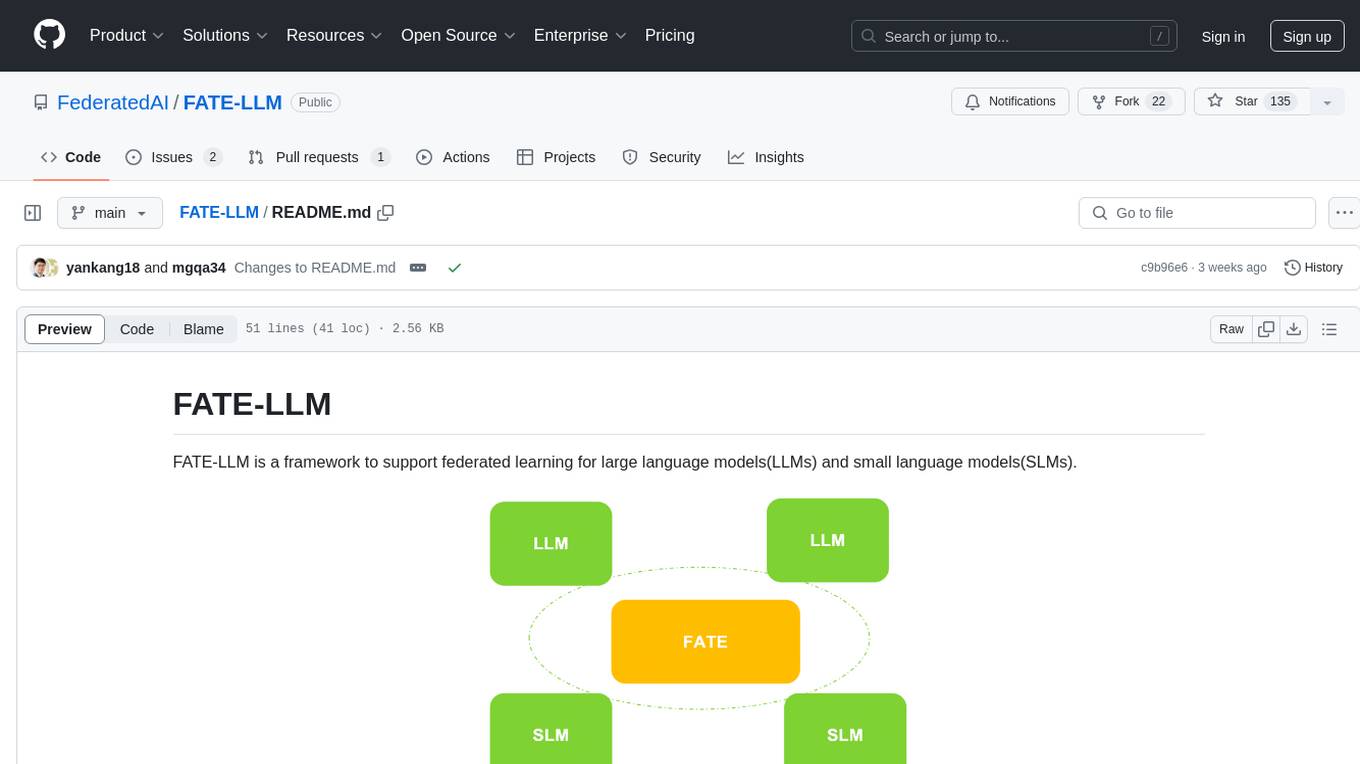
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
easyAi
EasyAi is a lightweight, beginner-friendly Java artificial intelligence algorithm framework. It can be seamlessly integrated into Java projects with Maven, requiring no additional environment configuration or dependencies. The framework provides pre-packaged modules for image object detection and AI customer service, as well as various low-level algorithm tools for deep learning, machine learning, reinforcement learning, heuristic learning, and matrix operations. Developers can easily develop custom micro-models tailored to their business needs.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
multipack_sampler
The Multipack sampler is a tool designed for padding-free distributed training of large language models. It optimizes batch processing efficiency using an approximate solution to the identical machine scheduling problem. The V2 update further enhances the packing algorithm complexity, achieving better throughput for a large number of nodes. It includes two variants for models with different attention types, aiming to balance sequence lengths and optimize packing efficiency. Users can refer to the provided benchmark for evaluating efficiency, utilization, and L^2 lag. The tool is compatible with PyTorch DataLoader and is released under the MIT license.
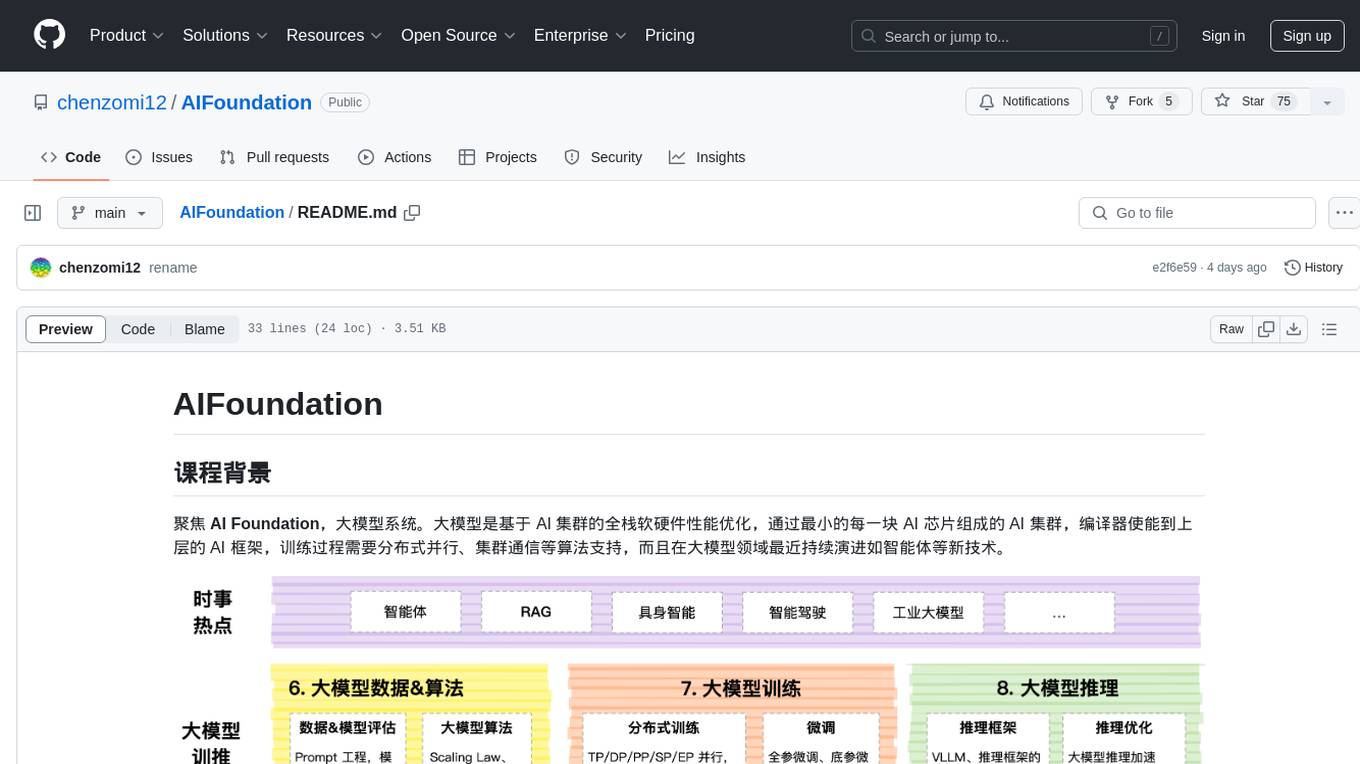
AIFoundation
AIFoundation focuses on AI Foundation, large model systems. Large models optimize the performance of full-stack hardware and software based on AI clusters. The training process requires distributed parallelism, cluster communication algorithms, and continuous evolution in the field of large models such as intelligent agents. The course covers modules like AI chip principles, communication & storage, AI clusters, computing architecture, communication architecture, large model algorithms, training, inference, and analysis of hot technologies in the large model field.

gradient-cli
Gradient CLI is a tool designed to facilitate the end-to-end MLOps process, allowing individuals and organizations to develop, train, and deploy Deep Learning models efficiently. It supports various ML/DL frameworks and provides features such as 1-click Jupyter Notebooks, scalable model training workflows, and model deployment as API endpoints. The tool can run on different infrastructures like AWS, GCP, on-premise, and Paperspace GPUs, offering automatic versioning, distributed training, hyperparameter search, and more.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
Bert-VITS2
Bert-VITS2 is a repository that provides a backbone with multilingual BERT for text-to-speech (TTS) applications. It offers an alternative to BV2/GSV projects and is inspired by the MassTTS project. Users can refer to the code to learn how to train models for TTS. The project is not maintained actively in the short term. It is not to be used for any purposes that violate the laws of the People's Republic of China, and strictly prohibits any political-related use.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.
2021-13th-ironman
This repository is a part of the 13th iT Help Ironman competition, focusing on exploring explainable artificial intelligence (XAI) in machine learning and deep learning. The content covers the basics of XAI, its applications, cases, challenges, and future directions. It also includes practical machine learning algorithms, model deployment, and integration concepts. The author aims to provide detailed resources on AI and share knowledge with the audience through this competition.
Awesome-Model-Merging-Methods-Theories-Applications
A comprehensive repository focusing on 'Model Merging in LLMs, MLLMs, and Beyond', providing an exhaustive overview of model merging methods, theories, applications, and future research directions. The repository covers various advanced methods, applications in foundation models, different machine learning subfields, and tasks like pre-merging methods, architecture transformation, weight alignment, basic merging methods, and more.
IG-LLM
IG-LLM is a framework for solving inverse-graphics problems by instruction-tuning a Large Language Model (LLM) to decode visual embeddings into graphics code. The framework demonstrates natural generalization across distribution shifts without special inductive biases. It provides training and evaluation data for various scenarios like CLEVR, 2D, SO(3), 6-DoF, and ShapeNet. The environment setup can be done using conda/micromamba or Dockerfile. Training can be initiated for each scenario with specific commands, and inference can be performed using the provided script.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
Numpy.NET
Numpy.NET is the most complete .NET binding for NumPy, empowering .NET developers with extensive functionality for scientific computing, machine learning, and AI. It provides multi-dimensional arrays, matrices, linear algebra, FFT, and more via a strong typed API. Numpy.NET does not require a local Python installation, as it uses Python.Included to package embedded Python 3.7. Multi-threading must be handled carefully to avoid deadlocks or access violation exceptions. Performance considerations include overhead when calling NumPy from C# and the efficiency of data transfer between C# and Python. Numpy.NET aims to match the completeness of the original NumPy library and is generated using CodeMinion by parsing the NumPy documentation. The project is MIT licensed and supported by JetBrains.
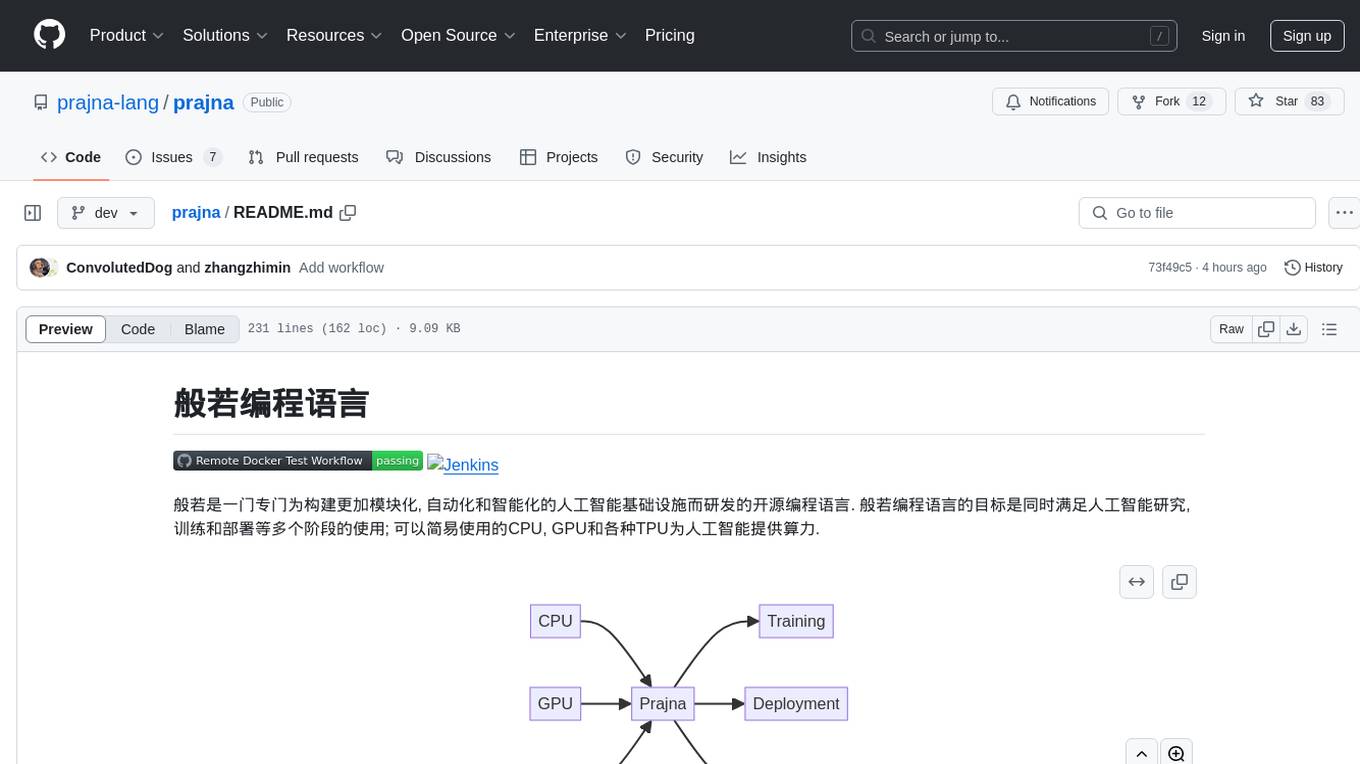
prajna
Prajna is an open-source programming language specifically developed for building more modular, automated, and intelligent artificial intelligence infrastructure. It aims to cater to various stages of AI research, training, and deployment by providing easy access to CPU, GPU, and various TPUs for AI computing. Prajna features just-in-time compilation, GPU/heterogeneous programming support, tensor computing, syntax improvements, and user-friendly interactions through main functions, Repl, and Jupyter, making it suitable for algorithm development and deployment in various scenarios.
crazyai-ml
The 'crazyai-ml' repository is a collection of resources related to machine learning, specifically focusing on explaining artificial intelligence models. It includes articles, code snippets, and tutorials covering various machine learning algorithms, data analysis, model training, and deployment. The content aims to provide a comprehensive guide for beginners in the field of AI, offering practical implementations and insights into popular machine learning packages and model tuning techniques. The repository also addresses the integration of AI models and frontend-backend concepts, making it a valuable resource for individuals interested in AI applications.
ai_agents_cookbooks
The 'ai_agents_cookbooks' repository contains cookbooks for AI agents, which are AI systems capable of using other software as tools. It provides resources for learning more about AI through events and requires Python 3.10 or higher as a prerequisite.
free-llm-api-resources
The 'Free LLM API resources' repository provides a comprehensive list of services offering free access or credits for API-based LLM usage. It includes various providers with details on model names, limits, and notes. Users can find information on legitimate services and their respective usage restrictions to leverage LLM capabilities without incurring costs. The repository aims to assist developers and researchers in accessing AI models for experimentation, development, and learning purposes.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.
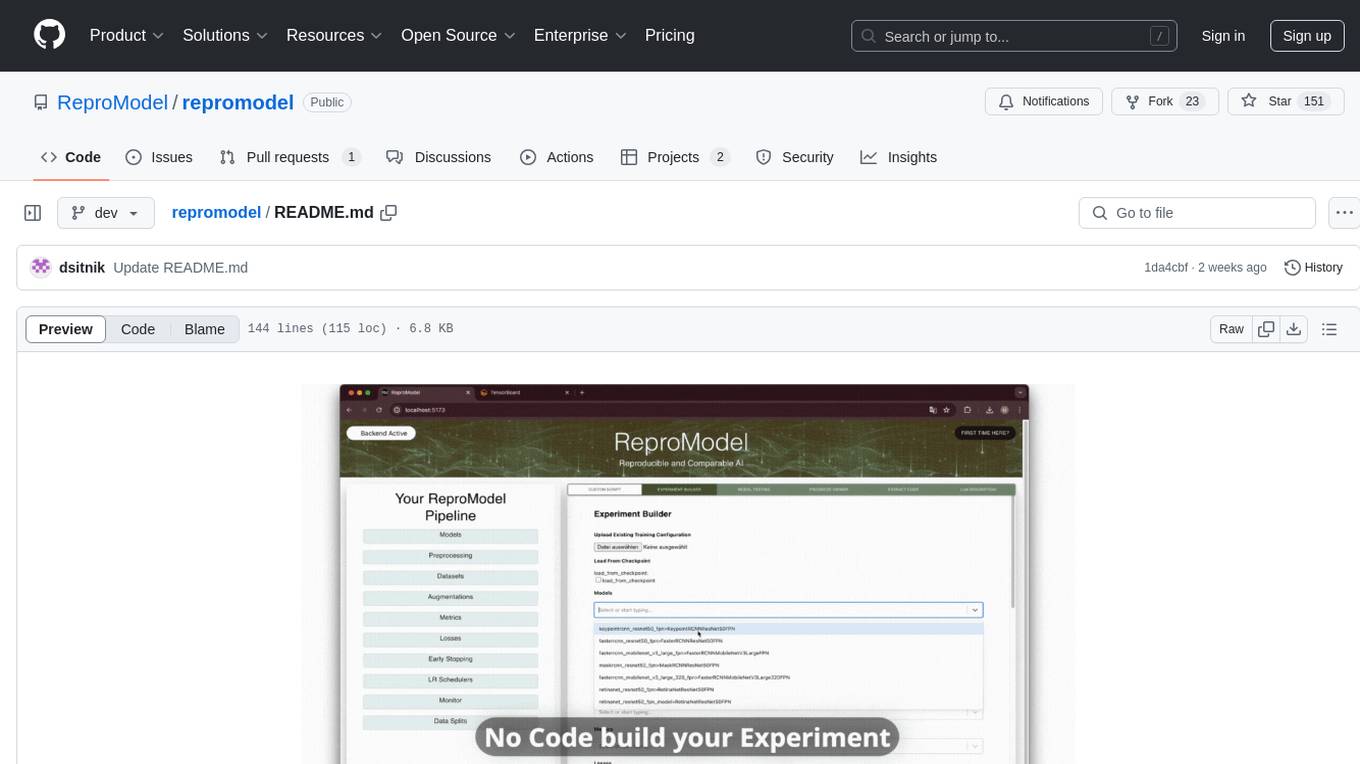
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
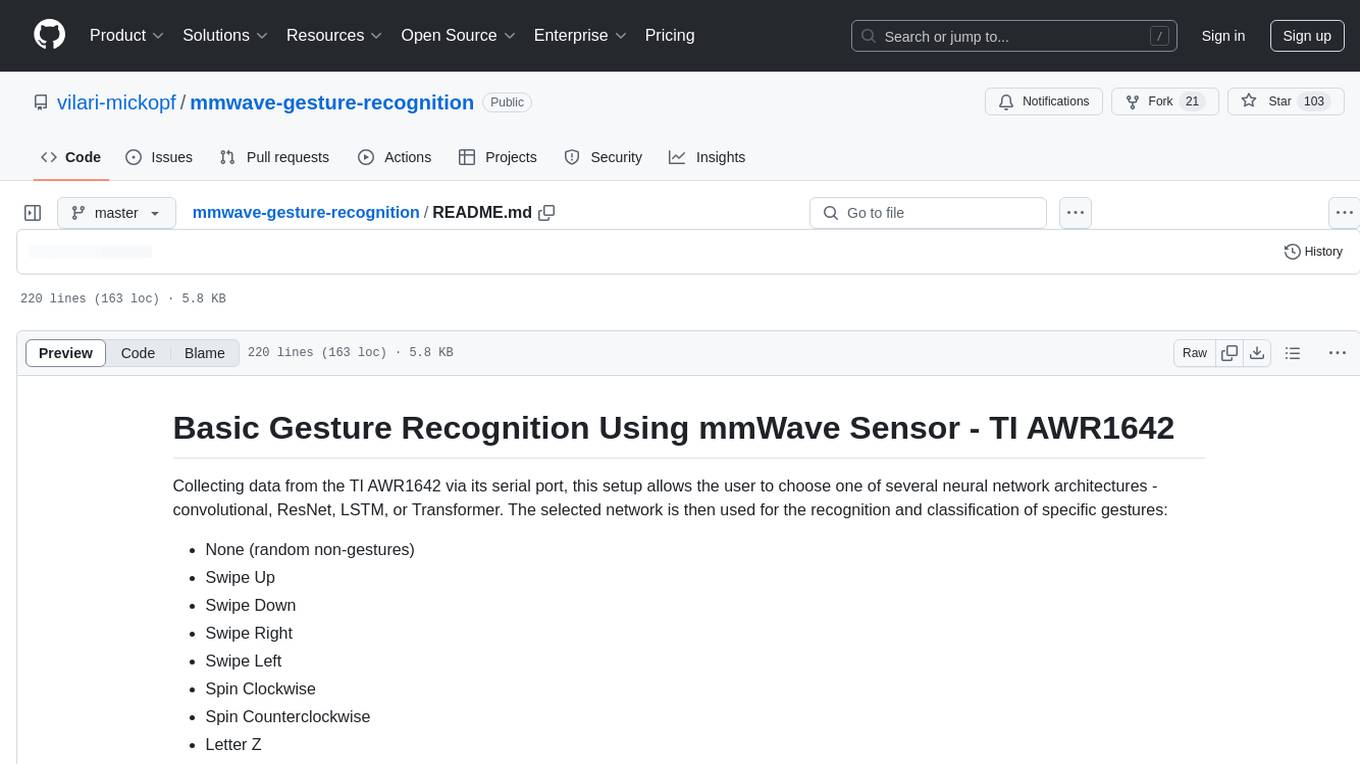
mmwave-gesture-recognition
This repository provides a setup for basic gesture recognition using the TI AWR1642 mmWave sensor. Users can collect data from the sensor and choose from various neural network architectures for gesture recognition. The supported gestures include Swipe Up, Swipe Down, Swipe Right, Swipe Left, Spin Clockwise, Spin Counterclockwise, Letter Z, Letter S, and Letter X. The repository includes data and models for training and inference, along with instructions for installation, serial permissions setup, flashing firmware, running the system, collecting data, training models, selecting different models, and accessing help documentation. The project is developed using Python and TensorFlow 2.15.

wzry_ai
This is an open-source project for playing the game King of Glory with an artificial intelligence model. The first phase of the project has been completed, and future upgrades will be built upon this foundation. The second phase of the project has started, and progress is expected to proceed according to plan. For any questions, feel free to join the QQ exchange group: 687853827. The project aims to learn artificial intelligence and strictly prohibits cheating. Detailed installation instructions are available in the doc/README.md file. Environment installation video: (bilibili) Welcome to follow, like, tip, comment, and provide your suggestions.
RAM
This repository, RAM, focuses on developing advanced algorithms and methods for Reasoning, Alignment, Memory. It contains projects related to these areas and is maintained by a team of individuals. The repository is licensed under the MIT License.
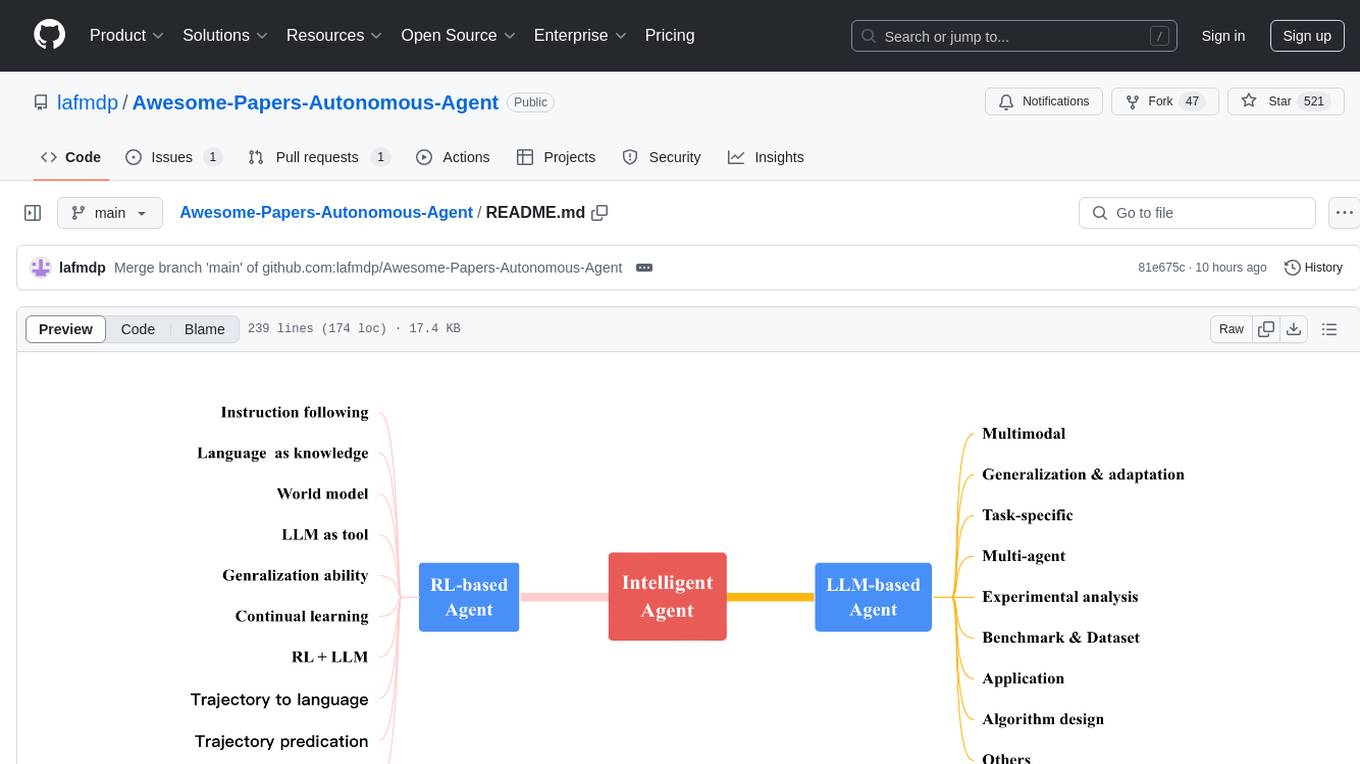
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.
ai-by-hand-excel
The 'ai-by-hand-excel' repository is a collection of AI exercises that can be implemented manually using Excel. It includes both basic and advanced topics such as Softmax, LeakyReLU, Backpropagation, Transformer, RNN, and Mamba. The repository aims to provide hands-on experience and understanding of AI concepts through practical Excel exercises.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.
ai-notebooks
ai-notebooks is a repository containing a collection of simple machine learning algorithms implemented in Python 3, TensorFlow 2, PyTorch, and Keras. The repository is designed for easy viewing on GitHub. Users can request notebook experiments by filing an issue for consideration.
RAGLAB
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

fastfit
FastFit is a Python package designed for fast and accurate few-shot classification, especially for scenarios with many semantically similar classes. It utilizes a novel approach integrating batch contrastive learning and token-level similarity score, significantly improving multi-class classification performance in speed and accuracy across various datasets. FastFit provides a convenient command-line tool for training text classification models with customizable parameters. It offers a 3-20x improvement in training speed, completing training in just a few seconds. Users can also train models with Python scripts and perform inference using pretrained models for text classification tasks.
edgeai
Embedded inference of Deep Learning models is quite challenging due to high compute requirements. TI’s Edge AI software product helps optimize and accelerate inference on TI’s embedded devices. It supports heterogeneous execution of DNNs across cortex-A based MPUs, TI’s latest generation C7x DSP, and DNN accelerator (MMA). The solution simplifies the product life cycle of DNN development and deployment by providing a rich set of tools and optimized libraries.
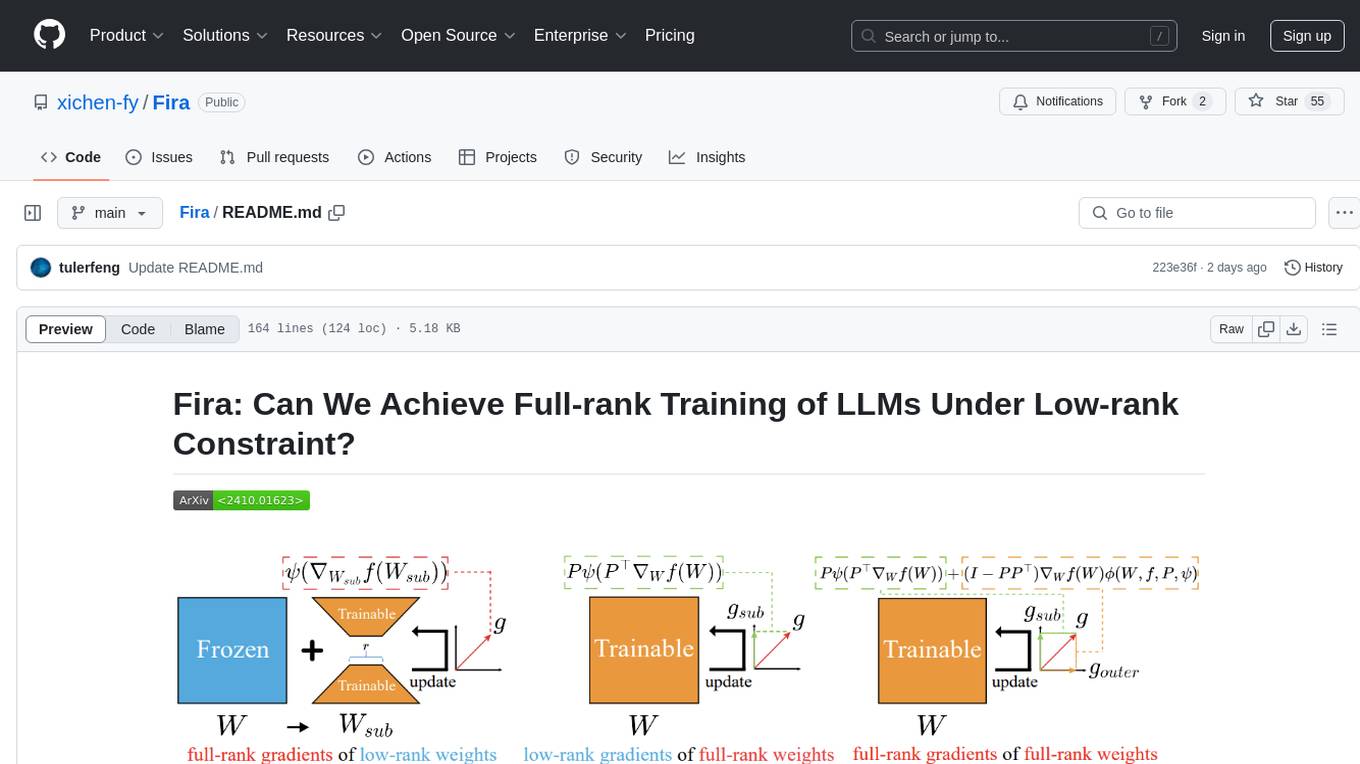
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.
animal-ai
Animal-Artificial Intelligence (Animal-AI) is an interdisciplinary research platform designed to understand human, animal, and artificial cognition. It supports AI research to unlock cognitive capabilities and explore the space of possible minds. The open-source project facilitates testing across animals, humans, and AI, providing a comprehensive AI environment with a library of 900 tasks. It offers compatibility with Windows, Linux, and macOS, supporting Python 3.6.x and above. The environment utilizes Unity3D Game Engine, Unity ML-Agents toolkit, and provides interactive elements for AI training scenarios.
2020-12th-ironman
This repository contains tutorial content for the 12th iT Help Ironman competition, focusing on machine learning algorithms and their practical applications. The tutorials cover topics such as AI model integration, API server deployment techniques, and hands-on programming exercises. The series is presented in video format and will be compiled into an e-book in the future. Suitable for those familiar with Python, interested in implementing AI prediction models, data analysis, and backend integration and deployment of AI models.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
incubator-hugegraph-ai
hugegraph-ai aims to explore the integration of HugeGraph with artificial intelligence (AI) and provide comprehensive support for developers to leverage HugeGraph's AI capabilities in their projects. It includes modules for large language models, graph machine learning, and a Python client for HugeGraph. The project aims to address challenges like timeliness, hallucination, and cost-related issues by integrating graph systems with AI technologies.
paper-reading
This repository is a collection of tools and resources for deep learning infrastructure, covering programming languages, algorithms, acceleration techniques, and engineering aspects. It provides information on various online tools for chip architecture, CPU and GPU benchmarks, and code analysis. Additionally, it includes content on AI compilers, deep learning models, high-performance computing, Docker and Kubernetes tutorials, Protobuf and gRPC guides, and programming languages such as C++, Python, and Shell. The repository aims to bridge the gap between algorithm understanding and engineering implementation in the fields of AI and deep learning.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.
LLMForEverybody
LLMForEverybody is a comprehensive repository covering various aspects of large language models (LLMs) including pre-training, architecture, optimizers, activation functions, attention mechanisms, tokenization, parallel strategies, training frameworks, deployment, fine-tuning, quantization, GPU parallelism, prompt engineering, agent design, RAG architecture, enterprise deployment challenges, evaluation metrics, and current hot topics in the field. It provides detailed explanations, tutorials, and insights into the workings and applications of LLMs, making it a valuable resource for researchers, developers, and enthusiasts interested in understanding and working with large language models.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.
teaching-boyfriend-llm
The 'teaching-boyfriend-llm' repository contains study notes on LLM (Large Language Models) for the purpose of advancing towards AGI (Artificial General Intelligence). The notes are a collaborative effort towards understanding and implementing LLM technology.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.
llm_aigc
The llm_aigc repository is a comprehensive resource for everything related to llm (Large Language Models) and aigc (AI Governance and Control). It provides detailed information, resources, and tools for individuals interested in understanding and working with large language models and AI governance and control. The repository covers a wide range of topics including model training, evaluation, deployment, ethics, and regulations in the AI field.
awesome-ai-tools
This repository contains a curated list of awesome AI tools that can be used for various machine learning and artificial intelligence projects. It includes tools for data preprocessing, model training, evaluation, and deployment. The list is regularly updated with new tools and resources to help developers and data scientists in their AI projects.
Grounded_3D-LLM
Grounded 3D-LLM is a unified generative framework that utilizes referent tokens to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It transforms 3D vision tasks into language formats through task-specific prompts, curating grounded language datasets and employing Contrastive Language-Scene Pre-training (CLASP) to bridge the gap between 3D vision and language models. The model covers tasks like 3D visual question answering, dense captioning, object detection, and language grounding.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.

ModernBERT
ModernBERT is a repository focused on modernizing BERT through architecture changes and scaling. It introduces FlexBERT, a modular approach to encoder building blocks, and heavily relies on .yaml configuration files to build models. The codebase builds upon MosaicBERT and incorporates Flash Attention 2. The repository is used for pre-training and GLUE evaluations, with a focus on reproducibility and documentation. It provides a collaboration between Answer.AI, LightOn, and friends.
ppl.llm.kernel.cuda
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.
LLMs-Zero-to-Hero
LLMs-Zero-to-Hero is a repository dedicated to training large language models (LLMs) from scratch, covering topics such as dense models, MOE models, pre-training, supervised fine-tuning, direct preference optimization, reinforcement learning from human feedback, and deploying large models. The repository provides detailed learning notes for different chapters, code implementations, and resources for training and deploying LLMs. It aims to guide users from being beginners to proficient in building and deploying large language models.
rai
This repository contains core sources related to Robotics & AI. It serves as a submodule in integrated projects, providing a minimal Ubuntu-specific build system and development tests. The code originated around 2004 in Edinburgh and has grown over the years to encompass various functionalities for Robotics, ML, and AI. Users are advised to explore example projects using this bare code for a better understanding of its capabilities.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.
LLM-Finetune
LLM-Finetune is a repository for fine-tuning language models for various NLP tasks such as text classification and named entity recognition. It provides instructions and scripts for training and inference using models like Qwen2-VL and GLM4. The repository also includes datasets for tasks like text classification, named entity recognition, and multimodal tasks. Users can easily prepare the environment, download datasets, train models, and perform inference using the provided scripts and notebooks. Additionally, the repository references SwanLab, an AI training record, analysis, and visualization tool.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
Auto-Deep-Research
Auto-Deep-Research is an open-source and cost-efficient alternative to OpenAI's Deep Research, based on the AutoAgent framework. It offers high performance, universal LLM support, flexible interaction, cost-efficiency, file support, and one-click launch. Users can seamlessly integrate with various LLMs, handle file uploads, and start instantly with a simple command. The tool aims to provide a fully-automated and personalized AI assistant at a lower cost, catering to community needs and showcasing the potential of AutoAgent for practical AI applications.

OREAL
OREAL is a reinforcement learning framework designed for mathematical reasoning tasks, aiming to achieve optimal performance through outcome reward-based learning. The framework utilizes behavior cloning, reshaping rewards, and token-level reward models to address challenges in sparse rewards and partial correctness. OREAL has achieved significant results, with a 7B model reaching 94.0 pass@1 accuracy on MATH-500 and surpassing previous 32B models. The tool provides training tutorials and Hugging Face model repositories for easy access and implementation.
simple_GRPO
simple_GRPO is a very simple implementation of the GRPO algorithm for reproducing r1-like LLM thinking. It provides a codebase that supports saving GPU memory, understanding RL processes, trying various improvements like multi-answer generation, regrouping, penalty on KL, and parameter tuning. The project focuses on simplicity, performance, and core loss calculation based on Hugging Face's trl. It offers a straightforward setup with minimal dependencies and efficient training on multiple GPUs.
photo-ai
100xPhoto is a powerful AI image platform that enables users to generate stunning images and train custom AI models. It provides an intuitive interface for creating unique AI-generated artwork and training personalized models on image datasets. The platform is built with cutting-edge technology and offers robust capabilities for AI image generation and model training.
cookiecutter-data-science
Cookiecutter Data Science (CCDS) is a tool for setting up a data science project template that incorporates best practices. It provides a logical, reasonably standardized but flexible project structure for doing and sharing data science work. The tool helps users to easily start new data science projects with a well-organized directory structure, including folders for data, models, notebooks, reports, and more. By following the project template created by CCDS, users can streamline their data science workflow and ensure consistency across projects.
Awesome-LLM-Resources-List
Awesome LLM Resources is a curated collection of resources for Large Language Models (LLMs) covering various aspects such as serverless hosting, accessing off-the-shelf models via API, local inference, LLM serving frameworks, open-source LLM web chat UIs, renting GPUs for fine-tuning, fine-tuning with no-code UI, fine-tuning frameworks, OS agentic/AI workflow, AI agents, co-pilots, voice API, open-source TTS models, OS RAG frameworks, research papers on chain-of-thought prompting, CoT implementations, CoT fine-tuned models & datasets, and more.
MachineLearning
MachineLearning is a repository focused on practical applications in various algorithm scenarios such as ship, education, and enterprise development. It covers a wide range of topics from basic machine learning and deep learning to object detection and the latest large models. The project utilizes mature third-party libraries, open-source pre-trained models, and the latest technologies from related papers to document the learning process and facilitate direct usage by a wider audience.

trainer
Kubeflow Trainer is a Kubernetes-native project for fine-tuning large language models (LLMs) and enabling scalable, distributed training of machine learning (ML) models across various frameworks. It allows integration with ML libraries like HuggingFace, DeepSpeed, or Megatron-LM to orchestrate ML training on Kubernetes. Develop LLMs effortlessly with the Kubeflow Python SDK and build Kubernetes-native Training Runtimes with Kubernetes Custom Resources APIs.
BrainX
BrainX is a tool designed for AI enthusiasts to explore and experiment with various machine learning algorithms and models. It provides a user-friendly interface for building, training, and evaluating AI models. The tool aims to simplify the process of developing AI applications and enable users to quickly prototype and test their ideas.
LLM-Engineers-Handbook
The LLM Engineer's Handbook is an official repository containing a comprehensive guide on creating an end-to-end LLM-based system using best practices. It covers data collection & generation, LLM training pipeline, a simple RAG system, production-ready AWS deployment, comprehensive monitoring, and testing and evaluation framework. The repository includes detailed instructions on setting up local and cloud dependencies, project structure, installation steps, infrastructure setup, pipelines for data processing, training, and inference, as well as QA, tests, and running the project end-to-end.
watsonx-ai-samples
Sample notebooks for IBM Watsonx.ai for IBM Cloud and IBM Watsonx.ai software product. The notebooks demonstrate capabilities such as running experiments on model building using AutoAI or Deep Learning, deploying third-party models as web services or batch jobs, monitoring deployments with OpenScale, managing model lifecycles, inferencing Watsonx.ai foundation models, and integrating LangChain with Watsonx.ai. Notebooks with Python code and the Python SDK can be found in the `python_sdk` folder. The REST API examples are organized in the `rest_api` folder.
llm_rl
llm_rl is a repository that combines llm (language model) and rl (reinforcement learning) techniques. It likely focuses on using language models in reinforcement learning tasks, such as natural language understanding and generation. The repository may contain implementations of algorithms that leverage both llm and rl to improve performance in various tasks. Developers interested in exploring the intersection of language models and reinforcement learning may find this repository useful for research and experimentation.
magma
Magma is a powerful and flexible framework for building scalable and efficient machine learning pipelines. It provides a simple interface for creating complex workflows, enabling users to easily experiment with different models and data processing techniques. With Magma, users can streamline the development and deployment of machine learning projects, saving time and resources.
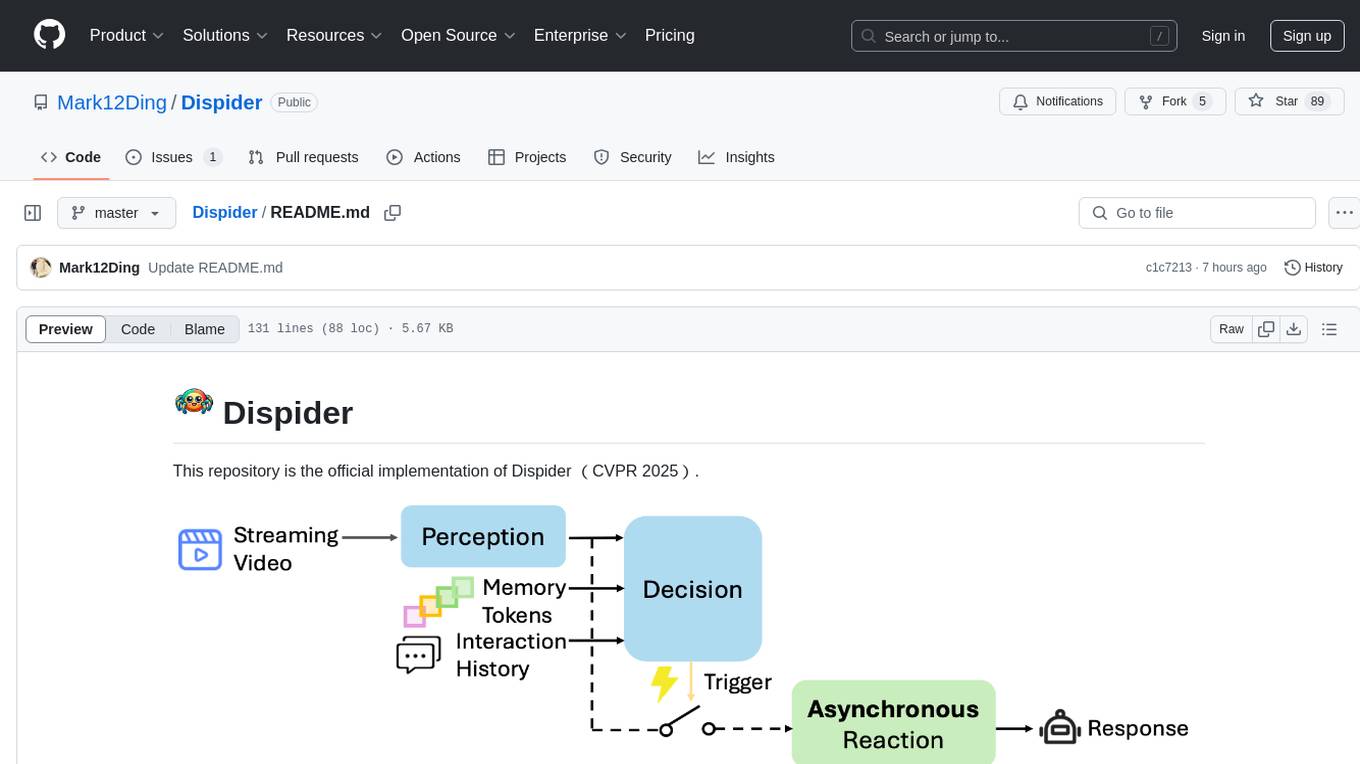
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.

LLaSA_training
LLaSA_training is a repository focused on training models for speech synthesis using a large amount of open-source speech data. The repository provides instructions for finetuning models and offers pre-trained models for multilingual speech synthesis. It includes tools for training, data downloading, and data processing using specialized tokenizers for text and speech sequences. The repository also supports direct usage on Hugging Face platform with specific codecs and collections.
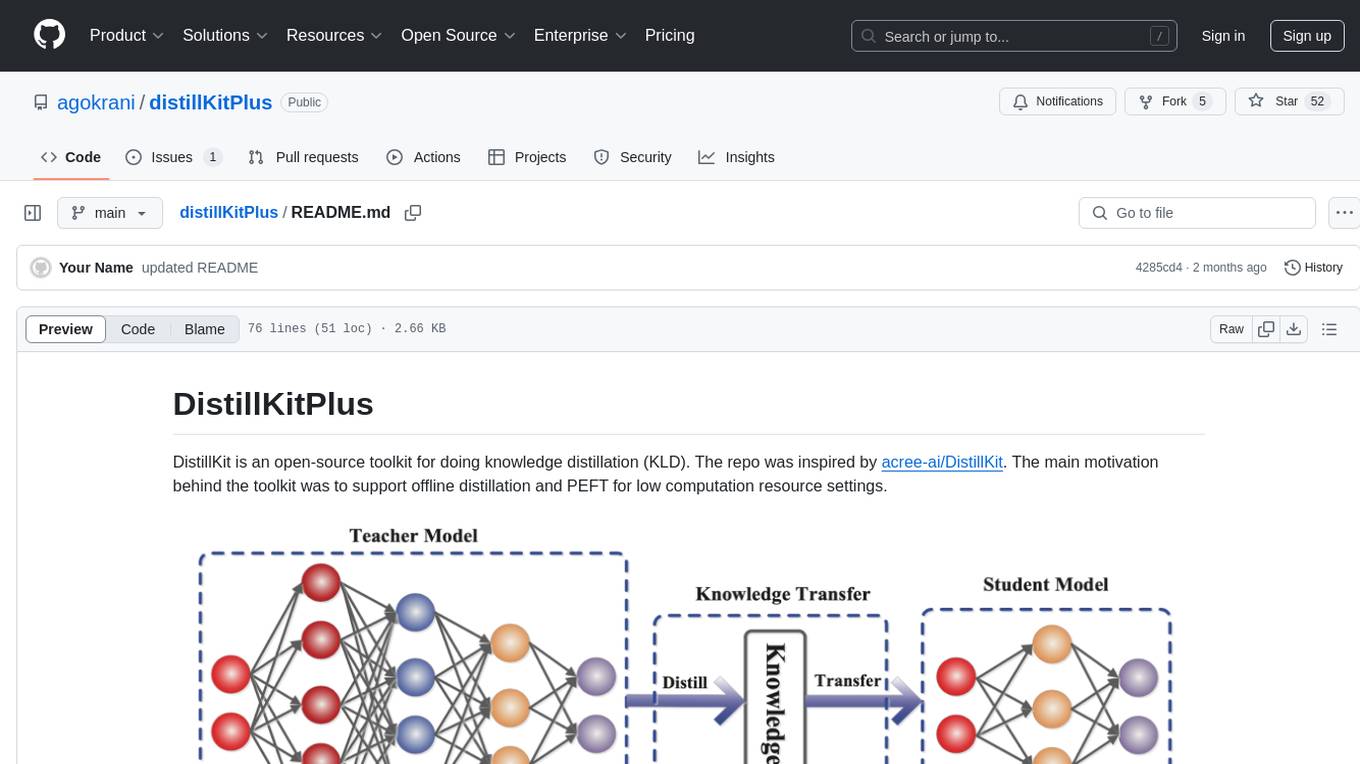
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
llm-engineer-toolkit
The LLM Engineer Toolkit is a curated repository containing over 120 LLM libraries categorized for various tasks such as training, application development, inference, serving, data extraction, data generation, agents, evaluation, monitoring, prompts, structured outputs, safety, security, embedding models, and other miscellaneous tools. It includes libraries for fine-tuning LLMs, building applications powered by LLMs, serving LLM models, extracting data, generating synthetic data, creating AI agents, evaluating LLM applications, monitoring LLM performance, optimizing prompts, handling structured outputs, ensuring safety and security, embedding models, and more. The toolkit covers a wide range of tools and frameworks to streamline the development, deployment, and optimization of large language models.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.
AmazonSageMakerCourse
Amazon SageMaker Course is a comprehensive guide for AWS Certified Machine Learning Specialty (MLS-C01) that covers training, optimizing, deploying, and integrating machine learning models in the AWS cloud. The course includes hands-on experience with AWS built-in algorithms, Bring Your Own models, and ready-to-use AI capabilities. It also provides a complete guide to AWS Certified Machine Learning – Specialty certification, along with a high-quality timed practice test. Participants will learn how to integrate trained models into their applications and receive prompt support through the course Q&A forum and private messaging.
pipeshub-ai
Pipeshub-ai is a versatile tool for automating data pipelines in AI projects. It provides a user-friendly interface to design, deploy, and monitor complex data workflows, enabling seamless integration of various AI models and data sources. With Pipeshub-ai, users can easily create end-to-end pipelines for tasks such as data preprocessing, model training, and inference, streamlining the AI development process and improving productivity. The tool supports integration with popular AI frameworks and cloud services, making it suitable for both beginners and experienced AI practitioners.
AIGC_text_detector
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.

mmf
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. It contains reference implementations of state-of-the-art vision and language models, allowing distributed training. MMF serves as a starter codebase for challenges around vision and language datasets, such as The Hateful Memes, TextVQA, TextCaps, and VQA challenges. It is scalable, fast, and un-opinionated, providing a solid foundation for vision and language multimodal research projects.
ryzen-ai-documentation
Ryzen AI Software is a tool developed by Advanced Micro Devices, Inc. for AI applications. It is licensed under the MIT License and provides information on technical inaccuracies, omissions, and typographical errors. The tool may be subject to changes due to product updates, component variations, software modifications, and security vulnerabilities. AMD disclaims any implied warranties and liabilities for inaccuracies or errors in the information provided. The tool is not warranted for use in safety-critical automotive applications without proper safety design and testing.
jsgrad
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.
llm
This repository provides practical guidance on developing real-world AI applications using LLM, covering topics from the basics of LLM architecture to creating RAG, a representative application of LLM. It explains how to tame LLM to meet application requirements, lightweight it to operate smoothly in limited computing environments, and gradually create RAG. The book also addresses challenges encountered in the operational process, advanced topics such as multimodal and agents, and essential development knowledge for the LLM era from both theoretical and practical perspectives.
brain4j
Brain4J is a lightweight, performant, and open-source machine learning framework for Java. Designed with portability and speed in mind, it is optimized for high performance and ideal for those looking to implement machine learning solutions in pure Java. The framework provides tools and functionalities to facilitate the development of machine learning models within Java applications, offering ease of use and efficiency.
slime
Slime is an LLM post-training framework for RL scaling that provides high-performance training and flexible data generation capabilities. It connects Megatron with SGLang for efficient training and enables custom data generation workflows through server-based engines. The framework includes modules for training, rollout, and data buffer management, offering a comprehensive solution for RL scaling.

notebooks
The 'notebooks' repository contains a collection of fine-tuning notebooks for various models, including Gemma3N, Qwen3, Llama 3.2, Phi-4, Mistral v0.3, and more. These notebooks are designed for tasks such as data preparation, model training, evaluation, and model saving. Users can access guided notebooks for different types of models like Conversational, Vision, TTS, GRPO, and more. The repository also includes specific use-case notebooks for tasks like text classification, tool calling, multiple datasets, KTO, inference chat UI, conversational tasks, chatML, and text completion.
AI6127
AI6127 is a course focusing on deep neural networks for natural language processing (NLP). It covers core NLP tasks and machine learning models, emphasizing deep learning methods using libraries like Pytorch. The course aims to teach students state-of-the-art techniques for practical NLP problems, including writing, debugging, and training deep neural models. It also explores advancements in NLP such as Transformers and ChatGPT.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.
model-mondays
Model Mondays is a repository dedicated to providing a collection of machine learning models implemented in Python. It aims to serve as a resource for individuals looking to explore and experiment with various machine learning algorithms and techniques. The repository includes a wide range of models, from simple linear regression to complex deep learning architectures, along with detailed documentation and examples to facilitate learning and understanding. Whether you are a beginner looking to get started with machine learning or an experienced practitioner seeking reference implementations, Model Mondays offers a valuable repository of models to study and leverage in your projects.
Disciplined-AI-Software-Development
Disciplined AI Software Development is a comprehensive repository that provides guidelines and best practices for developing AI software in a disciplined manner. It covers topics such as project organization, code structure, documentation, testing, and deployment strategies to ensure the reliability, scalability, and maintainability of AI applications. The repository aims to help developers and teams navigate the complexities of AI development by offering practical advice and examples to follow.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.

deepteam
Deepteam is a powerful open-source tool designed for deep learning projects. It provides a user-friendly interface for training, testing, and deploying deep neural networks. With Deepteam, users can easily create and manage complex models, visualize training progress, and optimize hyperparameters. The tool supports various deep learning frameworks and allows seamless integration with popular libraries like TensorFlow and PyTorch. Whether you are a beginner or an experienced deep learning practitioner, Deepteam simplifies the development process and accelerates model deployment.

cosmos-rl
Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications. It provides a toolchain for large scale RL training workload with features like parallelism, asynchronous processing, low-precision training support, and a single-controller architecture. The system architecture includes Tensor Parallelism, Sequence Parallelism, Context Parallelism, FSDP Parallelism, and Pipeline Parallelism. It also utilizes a messaging system for coordinating policy and rollout replicas, along with dynamic NCCL Process Groups for fault-tolerant and elastic large-scale RL training.
ai-platform-engineering
The AI Platform Engineering repository provides a collection of tools and resources for building and deploying AI models. It includes libraries for data preprocessing, model training, and model serving. The repository also contains example code and tutorials to help users get started with AI development. Whether you are a beginner or an experienced AI engineer, this repository offers valuable insights and best practices to streamline your AI projects.
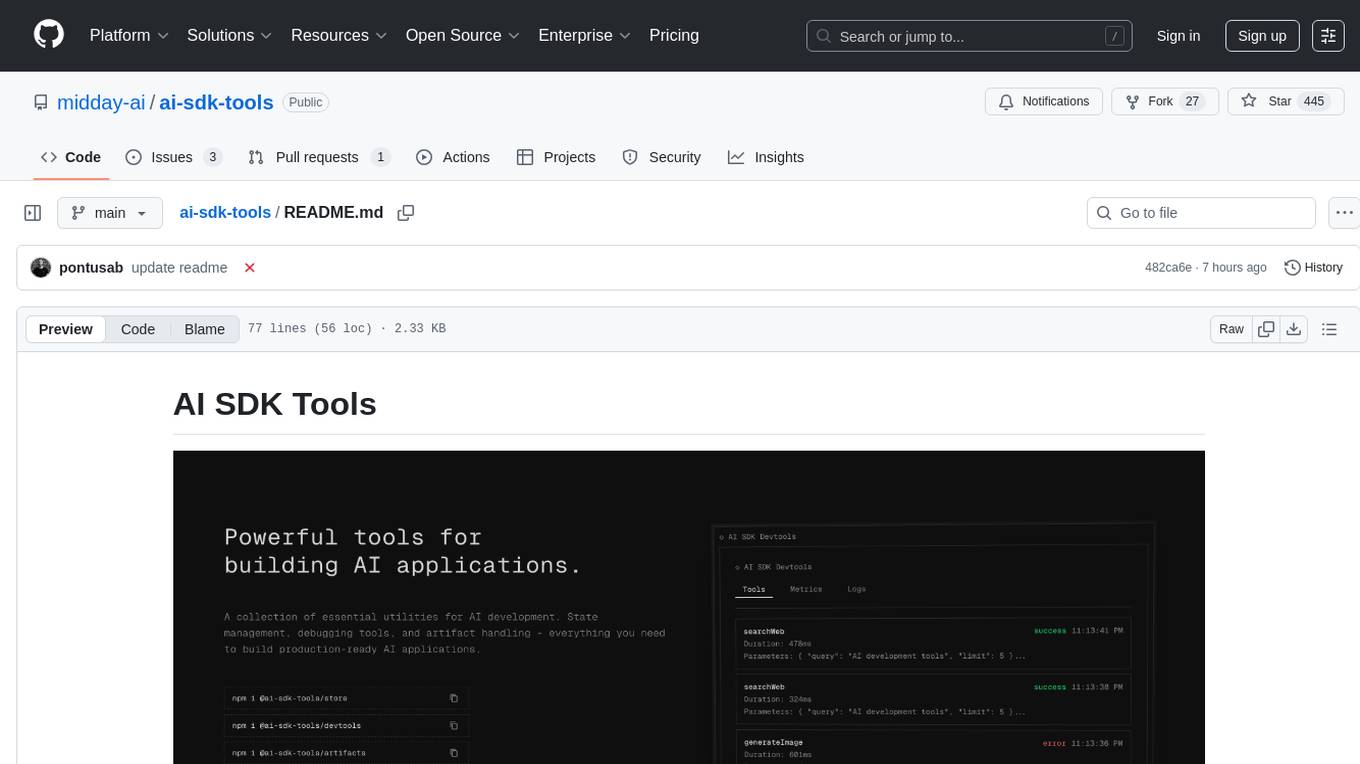
ai-sdk-tools
The ai-sdk-tools repository contains a collection of tools and utilities for developing and deploying AI models. It includes modules for data preprocessing, model training, evaluation, and deployment. The tools are designed to streamline the AI development process and improve efficiency. With a focus on usability and performance, this toolkit aims to support developers in building robust and scalable AI applications.

siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.
miles-credit
CREDIT is an open software platform for training and deploying AI atmospheric prediction models. It offers fast models with flexible configuration options for input data and neural network architecture. The user-friendly interface enables quick setup and iteration. Developed by the MILES group and NSF National Center for Atmospheric Research, CREDIT combines advanced AI/ML with atmospheric science expertise. It provides a stable release with various models, training, and deployment options, with ongoing development. Detailed documentation is available for installation, training, deployment, config file interpretation, and API usage.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.
flink-agents
Apache Flink Agents is an Agentic AI framework based on Apache Flink. It provides a platform for building and deploying AI agents using Flink's capabilities. The framework supports both Java and Python development, allowing users to leverage the power of Flink for AI applications. With a focus on agent-based AI systems, Flink Agents offers a flexible and scalable solution for developing intelligent agents that can interact with their environment and make decisions autonomously. The framework includes tools for building, training, and deploying AI agents, making it suitable for a wide range of AI applications.
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.
LLaVA-OneVision-1.5
LLaVA-OneVision 1.5 is a fully open framework for democratized multimodal training, introducing a novel family of large multimodal models achieving state-of-the-art performance at lower cost through training on native resolution images. It offers superior performance across multiple benchmarks, high-quality data at scale with concept-balanced and diverse caption data, and an ultra-efficient training framework with support for MoE, FP8, and long sequence parallelization. The framework is fully open for community access and reproducibility, providing high-quality pre-training & SFT data, complete training framework & code, training recipes & configurations, and comprehensive training logs & metrics.
EScAIP
EScAIP is an Efficiently Scaled Attention Interatomic Potential that leverages a novel multi-head self-attention formulation within graph neural networks to predict energy and forces between atoms in molecules and materials. It achieves substantial gains in efficiency, at least 10x speed up in inference time and 5x less memory usage compared to existing models. EScAIP represents a philosophy towards developing general-purpose Neural Network Interatomic Potentials that achieve better expressivity through scaling and continue to scale efficiently with increased computational resources and training data.
flyte-sdk
Flyte 2 SDK is a pure Python tool for type-safe, distributed orchestration of agents, ML pipelines, and more. It allows users to write data pipelines, ML training jobs, and distributed compute in Python without any DSL constraints. With features like async-first parallelism and fine-grained observability, Flyte 2 offers a seamless workflow experience. Users can leverage core concepts like TaskEnvironments for container configuration, pure Python workflows for flexibility, and async parallelism for distributed execution. Advanced features include sub-task observability with tracing and remote task execution. The tool also provides native Jupyter integration for running and monitoring workflows directly from notebooks. Configuration and deployment are made easy with configuration files and commands for deploying and running workflows. Flyte 2 is licensed under the Apache 2.0 License.
AI-Practices
AI-Practices is a systematic platform for learning and practicing artificial intelligence, covering a wide range of topics from foundational machine learning to advanced deep learning, reinforcement learning, generative models, large language models, multimodal learning, deployment optimization, distributed training, and agent reasoning. The platform provides a structured learning path, combining theoretical knowledge with practical implementation, following industrial code standards and including Kaggle competition solutions. It covers core algorithms in machine learning, deep learning, reinforcement learning, generative models, and large models. The platform supports popular deep learning frameworks like PyTorch, TensorFlow, and Keras, along with essential data science tools like NumPy, Pandas, and Scikit-Learn.
lm-engine
LM Engine is a research-grade, production-ready library for training large language models at scale. It provides support for multiple accelerators including NVIDIA GPUs, Google TPUs, and AWS Trainiums. Key features include multi-accelerator support, advanced distributed training, flexible model architectures, HuggingFace integration, training modes like pretraining and finetuning, custom kernels for high performance, experiment tracking, and efficient checkpointing.

tt-xla
TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.
Advanced-RVC-Inference
Advanced RVC Inference is a state-of-the-art web UI tool designed to streamline rapid and effortless inference. It includes a model downloader, a voice splitter, and training functionalities. The tool is stable and mature, focusing on security patches, dependency updates, and occasional feature improvements. Users can perform voice conversion, pitch shifting, batch processing, music separation, and more using the web interface or command line interface. The tool is suitable for tasks like voice conversion, audio processing, and model training.
torchtitan
Torchtitan is a PyTorch native platform designed for rapid experimentation and large-scale training of generative AI models. It provides a flexible foundation for developers to build upon with extension points for creating custom extensions. The tool showcases PyTorch's latest distributed training features and supports pretraining Llama 3.1 LLMs of various sizes. It offers key features like multi-dimensional parallelisms, FSDP2 with per-parameter sharding, Tensor Parallel, Pipeline Parallel, and more. Users can contribute to the tool through the experiments folder and core contributions guidelines. Installation can be done from source, nightly builds, or stable releases. The tool also supports training Llama 3.1 models and provides guidance on starting a training run and multi-node training. Citation information is available for referencing the tool in academic work, and the source code is under a BSD 3 license.
torch-rechub
Torch-RecHub is a lightweight, efficient, and user-friendly PyTorch recommendation system framework. It provides easy-to-use solutions for industrial-level recommendation systems, with features such as generative recommendation models, modular design for adding new models and datasets, PyTorch-based implementation for GPU acceleration, a rich library of 30+ classic and cutting-edge recommendation algorithms, standardized data loading, training, and evaluation processes, easy configuration through files or command-line parameters, reproducibility of experimental results, ONNX model export for production deployment, cross-engine data processing with PySpark support, and experiment visualization and tracking with integrated tools like WandB, SwanLab, and TensorBoardX.
PINNeAPPle
Pinneaple is an open-source Python platform that unifies physical data, geometry, numerical solvers, and machine learning models for Physics-Informed AI. It emphasizes physical consistency, scalability, auditability, and interoperability with CFD/CAD/scientific data formats. It provides tools for unified physical dataset representation, data pipelines, geometry and mesh operations, a model zoo, physics loss factory, solvers, synthetic data generation, training and evaluation. The platform is designed for physics AI researchers, CFD/FEA/climate ML teams, industrial R&D groups, scientific ML practitioners, and anyone building surrogates, inverse models, or hybrid solvers.
EnvScaler
EnvScaler is an automated, scalable framework that creates tool-interactive environments for training LLM agents. It consists of SkelBuilder for environment description mining and quality inspection, ScenGenerator for synthesizing multiple environment scenarios, and modules for supervised fine-tuning and reinforcement learning. The tool provides data, models, and evaluation guides for users to build, generate scenarios, collect training data, train models, and evaluate performance. Users can interact with environments, build environments from scratch, and improve LLMs' task-solving abilities in complex environments.
ReGraph
ReGraph is a decentralized AI compute marketplace that connects hardware providers with developers who need inference and training resources. It democratizes access to AI computing power by creating a global network of distributed compute nodes. It is cost-effective, decentralized, easy to integrate, supports multiple models, and offers pay-as-you-go pricing.
open-deep-research
Open Deep Research is a comprehensive repository that provides resources, tools, and information for deep learning research. It includes datasets, pre-trained models, code implementations, research papers, and tutorials to support researchers and developers in the field of deep learning. The repository aims to facilitate collaboration, knowledge sharing, and innovation in the deep learning community.
awesome-ai-agent-papers
This repository contains a curated list of papers related to artificial intelligence agents. It includes research papers, articles, and resources covering various aspects of AI agents, such as reinforcement learning, multi-agent systems, natural language processing, and more. Whether you are a researcher, student, or practitioner in the field of AI, this collection of papers can serve as a valuable reference to stay updated with the latest advancements and trends in AI agent technologies.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.
26 - OpenAI Gpts

Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.




ChatXGB
GPT chatbot that helps you with technical questions related to XGBoost algorithm and library

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

TensorFlow Oracle
I'm an expert in TensorFlow, providing detailed, accurate guidance for all skill levels.
![[latest] FastAPI GPT Screenshot](/screenshots_gpts/g-BhYCAfVXk.jpg)
[latest] FastAPI GPT
Up-to-date FastAPI coding assistant with knowledge of the latest version. Part of the [latest] GPTs family.
TonyAIDeveloperResume
Chat with my resume to see if I am a good fit for your AI related job.

Custom GPT Builder
Create personalized GPTs with my simple builder. Click the conversation starter (starting with ###) to begin.