
simple_GRPO
A very simple GRPO implement for reproducing r1-like LLM thinking.
Stars: 605
simple_GRPO is a very simple implementation of the GRPO algorithm for reproducing r1-like LLM thinking. It provides a codebase that supports saving GPU memory, understanding RL processes, trying various improvements like multi-answer generation, regrouping, penalty on KL, and parameter tuning. The project focuses on simplicity, performance, and core loss calculation based on Hugging Face's trl. It offers a straightforward setup with minimal dependencies and efficient training on multiple GPUs.
README:
A very simple GRPO implement for reproducing r1-like LLM thinking. This is a simple open source implementation that utilizes the core loss calculation formula referenced from Hugging Face's trl. We make the simplest codebase to support:
- Save the GPU memory to make a feasible and efficient training.
- Quickly understand RL processes such as GRPO from a teaching perspective.
- Quickly try a lot of things, such as improved multi-answer generation, regrouping, penalty on KL, and parameter tuning.
- "Aha moment" is observed during the early stages of model training.
- 2025/02/19: Added a loss triton implementation, which has a little speedup, but you can choose not to use it. See simple_grpo_v1 fold
- 2025/02/19: Added regroup version, implemented sampling of generated data on ref_server. See regroup_ver fold
- 2025/02/27: Added vllm package to accelerate the inference.
The project code is simple, with only about 200 lines of code spread across 2 files. It only depends on standard libraries such as deepspeed and torch, without requiring dependencies like ray. It is designed to allow for more complex interventions.
The reference model part is decoupled, which allows it to be run on different GPUs (even on a different machine with 4090). This avoids having the reference model and the training model on the same GPU, preventing multiple copies created by torch’s multiprocessing, and enabling training of a 7B model on 80G A800.
Training completed in under 1 hour on 1*A800 GPUs. Both Qwen2.5-7B and Qwen2.5-3B exhibited an "Aha moment" within the first 30 optimization steps.
The loss calculation formula is based on Hugging Face's trl. We extend our gratitude to Hugging Face for their contribution.
The runtime environment is in the requirements.txt so you can
pip install -r requirements.txtAt least two GPUs are needed.
Run the following command:
CUDA_VISIBLE_DEVICES=7 python ref_server.pyThis just uses one GPU to collect and run the reference model.
In grpo_vllm_one.py, set the generation device index relative to the visible devices in next step:
gen_device = 1Then, open another bash:
CUDA_VISIBLE_DEVICES=2,3,4,5,6 deepspeed grpo_vllm_one.py- Runtime Environment
- Hardware Setup: 2×A800 (80GB) GPUs
- Configuration:
- Training: 1 GPU with Zero-Stage 2 optimization
- Inference: Dedicated 1 GPU (3090/4090 compatible)
- Training Performance
| Model | Steps | Time |
|---|---|---|
| Qwen2.5-3B | 60 | 12m 34s |
| Qwen2.5-7B | 60 | 16m 40s |
2.1 Qwen2.5-3B

- Accuracy:
- Stabilizes above 60% after 5 optimization steps
- Peaks at ~70%
- Format Compliance:
- Reaches ≈100% after 30 steps
2.2 Qwen2.5-7B

- Accuracy:
- Maintains >90% throughout training
- Format Compliance:
- Achieves 100% within 30 steps
- Convergence: Both metrics show rapid convergence
- Qwen2.5-3B (Step 20)
<think>... To find out how many more eggs Camden painted than Arnold, we subtract the number of eggs painted by Arnold from the number of eggs painted by Camden. So, 21 - 28 = -7. However, this result doesn't make sense in the context of the problem, as Camden cannot have painted fewer eggs than Arnold. Let's reconsider the initial solution steps: we should verify if the initial assumption about the relationship between Camden and Sarah's eggs is correct. ...</think><answer>-7</answer>
- Qwen2.5-7B (Step 20)
<think>... Therefore, Joanne gathered 350 apples from the average trees. However, this doesn't seem right because the total should be 500 and we've already accounted for 150, leaving room only for 350 from the average trees, which contradicts the total. Let's reassess. ...</think><answer>350</answer>
- Answer generation may be invalid due to a group containing all wrong answers or all correct answers. We need group reorganization and better answer generation.
- GPU memory is still tight if it generates long cots. We have to split the groups to make the batch smaller.
We have implemented and are testing these features. They will be available soon.
This project is led by Dr. Jiaqing Liang and Professor Yanghua Xiao from KnowledgeWorks Lab, Fudan University. The core development team includes Ph.D. candidate Jinyi Han, Master's student Xinyi Wang, and other contributors. We gratefully acknowledge their dedication to this work.
If you find the code in our project useful, please consider citing our work as follows:
@misc{KW-R1,
author = {Jiaqing Liang, Jinyi Han, Xinyi Wang, Zishang Jiang, Chengyuan Xiong, Boyu Zhu, Jie Shi, Weijia Li, Tingyun Li, Yanghua Xiao},
title = {KW-R1: A Simple Implementation of the GRPO Algorithm},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/lsdefine/simple_GRPO}},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for simple_GRPO
Similar Open Source Tools
simple_GRPO
simple_GRPO is a very simple implementation of the GRPO algorithm for reproducing r1-like LLM thinking. It provides a codebase that supports saving GPU memory, understanding RL processes, trying various improvements like multi-answer generation, regrouping, penalty on KL, and parameter tuning. The project focuses on simplicity, performance, and core loss calculation based on Hugging Face's trl. It offers a straightforward setup with minimal dependencies and efficient training on multiple GPUs.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.
Aidan-Bench
Aidan Bench is a tool that rewards creativity, reliability, contextual attention, and instruction following. It is weakly correlated with Lmsys, has no score ceiling, and aligns with real-world open-ended use. The tool involves giving LLMs open-ended questions and evaluating their answers based on novelty scores. Users can set up the tool by installing required libraries and setting up API keys. The project allows users to run benchmarks for different models and provides flexibility in threading options.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.
For similar tasks

kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.
quick-start-connectors
Cohere's Build-Your-Own-Connector framework allows integration of Cohere's Command LLM via the Chat API endpoint to any datastore/software holding text information with a search endpoint. Enables user queries grounded in proprietary information. Use-cases include question/answering, knowledge working, comms summary, and research. Repository provides code for popular datastores and a template connector. Requires Python 3.11+ and Poetry. Connectors can be built and deployed using Docker. Environment variables set authorization values. Pre-commits for linting. Connectors tailored to integrate with Cohere's Chat API for creating chatbots. Connectors return documents as JSON objects for Cohere's API to generate answers with citations.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.
RAGMeUp
RAG Me Up is a generic framework that enables users to perform Retrieve and Generate (RAG) on their own dataset easily. It consists of a small server and UIs for communication. Best run on GPU with 16GB vRAM. Users can combine RAG with fine-tuning using LLaMa2Lang repository. The tool allows configuration for LLM, data, LLM parameters, prompt, and document splitting. Funding is sought to democratize AI and advance its applications.
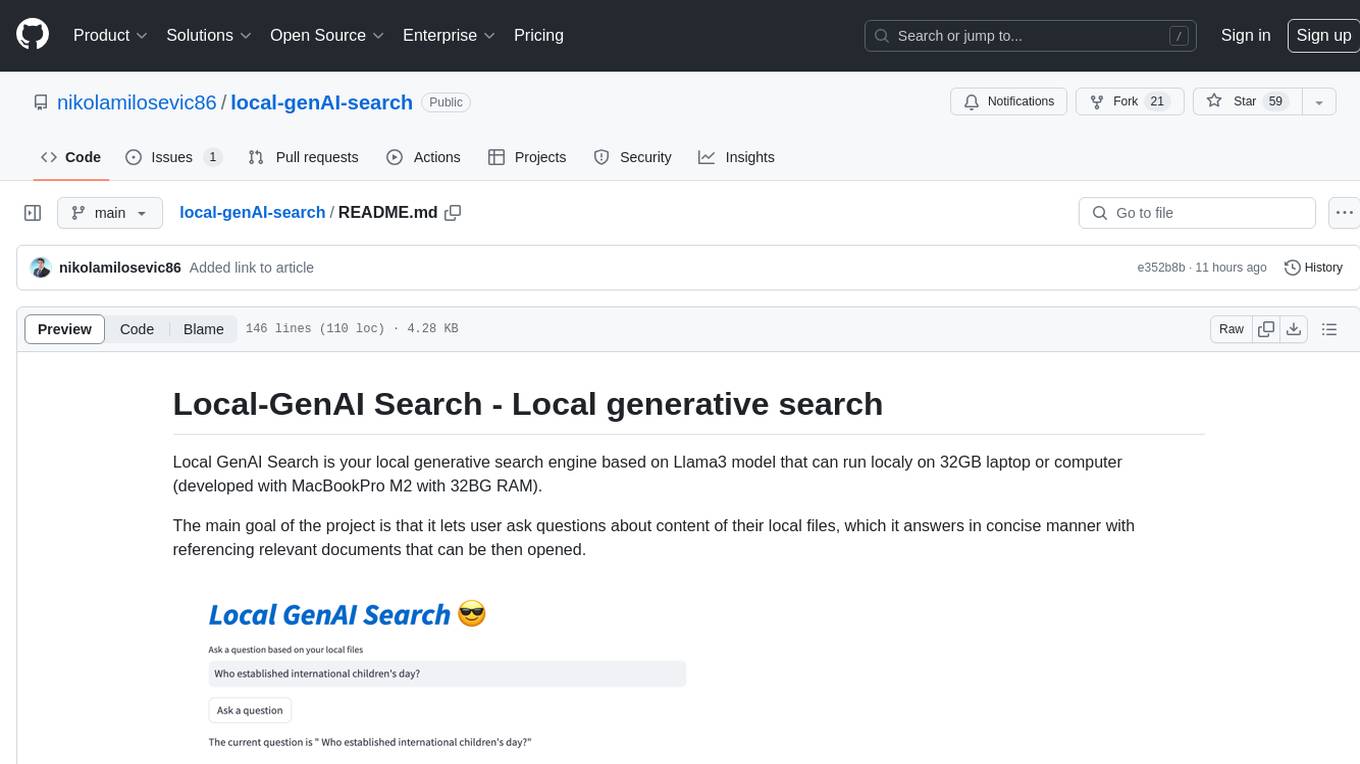
local-genAI-search
Local-GenAI Search is a local generative search engine powered by the Llama3 model, allowing users to ask questions about their local files and receive concise answers with relevant document references. It utilizes MS MARCO embeddings for semantic search and can run locally on a 32GB laptop or computer. The tool can be used to index local documents, search for information, and provide generative search services through a user interface.
nanoPerplexityAI
nanoPerplexityAI is an open-source implementation of a large language model service that fetches information from Google. It involves a simple architecture where the user query is checked by the language model, reformulated for Google search, and an answer is generated and saved in a markdown file. The tool requires minimal setup and is designed for easy visualization of answers.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.