
local-genAI-search
Local-GenAI-Search is a generative search engine based on Llama 3, langchain and qdrant that answers questions based on your local files
Stars: 59
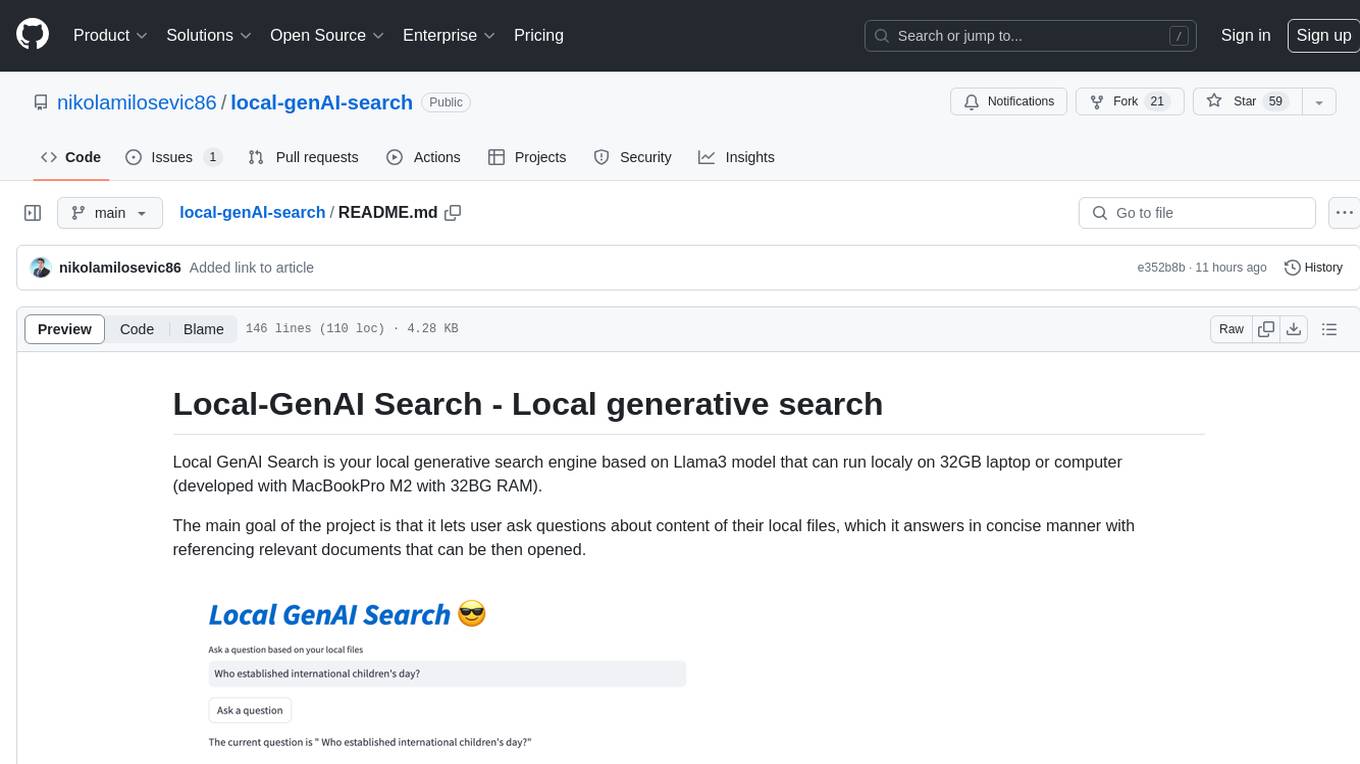
Local-GenAI Search is a local generative search engine powered by the Llama3 model, allowing users to ask questions about their local files and receive concise answers with relevant document references. It utilizes MS MARCO embeddings for semantic search and can run locally on a 32GB laptop or computer. The tool can be used to index local documents, search for information, and provide generative search services through a user interface.
README:
Local GenAI Search is your local generative search engine based on Llama3 model that can run localy on 32GB laptop or computer (developed with MacBookPro M2 with 32BG RAM).
The main goal of the project is that it lets user ask questions about content of their local files, which it answers in concise manner with referencing relevant documents that can be then opened.

The engine is using MS MARCO embeddings for semantic search, with top documents being passed to Llama 3 model.
By default, it would work with NVIDIA API, and use 70B parameter Llama 3 model. However, if you used all your NVIDIA API credits or do not want to use API for searching your local documents, it can also run locally, using 8B parameter model.
In order to run your Local Generative AI Search (given you have sufficiently string machine to run Llama3), you need to download the repository:
git clone https://github.com/nikolamilosevic86/local-gen-search.git
You will need to install all the requirements:
pip install -r requirements.txt
You need to create a file called environment_var.py, and put there
your HuggingFace API key. The file should look like this:
import os
hf_token = "hf_you_api_key"
nvidia_key = "nvapi-your_nvidia_nim_api_key"API key for HuggingFace can be retrieved at https://huggingface.co/settings/tokens.
In order to run generative component, you need to request
access to Llama3 model at https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
API key for Nvidia NIM API Endpoint can be retrieved at https://build.nvidia.com/explore/discover
The next step is to index a folder and its subfolders containing
documents that you would like to search. You can do it using
the index.py file. Run
python index.py path/to/folder
As example, you can run it with TestFolder provided:
python index.py TestFolder
This will create a qdrant client index locally and index all the files
in this folder and its subfolders with extensions .pdf,.txt,.docx,.pptx
The next step would be to run the generative search service. For this you can run:
python uvicorn_start.py
This will start a local server, that you can query using postman, or send POST requests. Loading of models (including downloading from Huggingface, may take few minutes, especially for the first time). There are two interfaces:
http://127.0.0.1:8000/search
http://127.0.0.1:8000/ask_localai
Both interfaces need body in a format:
{"query":"What are knowledge graphs?"}
and headers for Accept and Content-Type set to application/json.
Here is a code example:
import requests
import json
url = "http://127.0.0.1:8000/ask_localai"
payload = json.dumps({
"query": "What are knowledge graphs?"
})
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Finally, streamlit user interface can be started in the following way:
streamlit run user_interface.py
Now you can use the user interface and ask question that will be answered based on the files on your file system.
- Llama3 8B
- NVIDIA NIM API Endpoints (For Llama 3 70B)
- Langchain
- Transformers
- MSMarco IR embedding models
- PyPDF2
If you want to see more details on development of this tool, you can read How to Build a Generative Search Engine for Your Local Files Using Llama 3 | Towards Data Science
Also, you can check the following papers:
@article{kovsprdic2024verif,
title={Verif.ai: Towards an Open-Source Scientific Generative Question-Answering System with Referenced and Verifiable Answers},
author={Ko{\v{s}}prdi{\'c}, Milo{\v{s}} and Ljaji{\'c}, Adela and Ba{\v{s}}aragin, Bojana and Medvecki, Darija and Milo{\v{s}}evi{\'c}, Nikola},
journal={arXiv preprint arXiv:2402.18589},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for local-genAI-search
Similar Open Source Tools
local-genAI-search
Local-GenAI Search is a local generative search engine powered by the Llama3 model, allowing users to ask questions about their local files and receive concise answers with relevant document references. It utilizes MS MARCO embeddings for semantic search and can run locally on a 32GB laptop or computer. The tool can be used to index local documents, search for information, and provide generative search services through a user interface.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.

qb
QANTA is a system and dataset for question answering tasks. It provides a script to download datasets, preprocesses questions, and matches them with Wikipedia pages. The system includes various datasets, training, dev, and test data in JSON and SQLite formats. Dependencies include Python 3.6, `click`, and NLTK models. Elastic Search 5.6 is needed for the Guesser component. Configuration is managed through environment variables and YAML files. QANTA supports multiple guesser implementations that can be enabled/disabled. Running QANTA involves using `cli.py` and Luigi pipelines. The system accesses raw Wikipedia dumps for data processing. The QANTA ID numbering scheme categorizes datasets based on events and competitions.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.

aisuite
Aisuite is a simple, unified interface to multiple Generative AI providers. It allows developers to easily interact with various Language Model (LLM) providers like OpenAI, Anthropic, Azure, Google, AWS, and more through a standardized interface. The library focuses on chat completions and provides a thin wrapper around python client libraries, enabling creators to test responses from different LLM providers without changing their code. Aisuite maximizes stability by using HTTP endpoints or SDKs for making calls to the providers. Users can install the base package or specific provider packages, set up API keys, and utilize the library to generate chat completion responses from different models.
leptonai
A Pythonic framework to simplify AI service building. The LeptonAI Python library allows you to build an AI service from Python code with ease. Key features include a Pythonic abstraction Photon, simple abstractions to launch models like those on HuggingFace, prebuilt examples for common models, AI tailored batteries, a client to automatically call your service like native Python functions, and Pythonic configuration specs to be readily shipped in a cloud environment.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

OlympicArena
OlympicArena is a comprehensive benchmark designed to evaluate advanced AI capabilities across various disciplines. It aims to push AI towards superintelligence by tackling complex challenges in science and beyond. The repository provides detailed data for different disciplines, allows users to run inference and evaluation locally, and offers a submission platform for testing models on the test set. Additionally, it includes an annotation interface and encourages users to cite their paper if they find the code or dataset helpful.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
sql-eval
This repository contains the code that Defog uses for the evaluation of generated SQL. It's based off the schema from the Spider, but with a new set of hand-selected questions and queries grouped by query category. The testing procedure involves generating a SQL query, running both the 'gold' query and the generated query on their respective database to obtain dataframes with the results, comparing the dataframes using an 'exact' and a 'subset' match, logging these alongside other metrics of interest, and aggregating the results for reporting. The repository provides comprehensive instructions for installing dependencies, starting a Postgres instance, importing data into Postgres, importing data into Snowflake, using private data, implementing a query generator, and running the test with different runners.
PolyMind
PolyMind is a multimodal, function calling powered LLM webui designed for various tasks such as internet searching, image generation, port scanning, Wolfram Alpha integration, Python interpretation, and semantic search. It offers a plugin system for adding extra functions and supports different models and endpoints. The tool allows users to interact via function calling and provides features like image input, image generation, and text file search. The application's configuration is stored in a `config.json` file with options for backend selection, compatibility mode, IP address settings, API key, and enabled features.
aws-ai-stack
AWS AI Stack is a full-stack boilerplate project designed for building serverless AI applications on AWS. It provides a trusted AWS foundation for AI apps with access to powerful LLM models via Bedrock. The architecture is serverless, ensuring cost-efficiency by only paying for usage. The project includes features like AI Chat & Streaming Responses, Multiple AI Models & Data Privacy, Custom Domain Names, API & Event-Driven architecture, Built-In Authentication, Multi-Environment support, and CI/CD with Github Actions. Users can easily create AI Chat bots, authentication services, business logic, and async workers using AWS Lambda, API Gateway, DynamoDB, and EventBridge.

MultiPL-E
MultiPL-E is a system for translating unit test-driven neural code generation benchmarks to new languages. It is part of the BigCode Code Generation LM Harness and allows for evaluating Code LLMs using various benchmarks. The tool supports multiple versions with improvements and new language additions, providing a scalable and polyglot approach to benchmarking neural code generation. Users can access a tutorial for direct usage and explore the dataset of translated prompts on the Hugging Face Hub.
hal9
Hal9 is a tool that allows users to create and deploy generative applications such as chatbots and APIs quickly. It is open, intuitive, scalable, and powerful, enabling users to use various models and libraries without the need to learn complex app frameworks. With a focus on AI tasks like RAG, fine-tuning, alignment, and training, Hal9 simplifies the development process by skipping engineering tasks like frontend development, backend integration, deployment, and operations.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.
curate-gpt
CurateGPT is a prototype web application and framework for performing general purpose AI-guided curation and curation-related operations over collections of objects. It allows users to load JSON, YAML, or CSV data, build vector database indexes for ontologies, and interact with various data sources like GitHub, Google Drives, Google Sheets, and more. The tool supports ontology curation, knowledge base querying, term autocompletion, and all-by-all comparisons for objects in a collection.
For similar tasks

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
chat-ollama
ChatOllama is an open-source chatbot based on LLMs (Large Language Models). It supports a wide range of language models, including Ollama served models, OpenAI, Azure OpenAI, and Anthropic. ChatOllama supports multiple types of chat, including free chat with LLMs and chat with LLMs based on a knowledge base. Key features of ChatOllama include Ollama models management, knowledge bases management, chat, and commercial LLMs API keys management.
ChatIDE
ChatIDE is an AI assistant that integrates with your IDE, allowing you to converse with OpenAI's ChatGPT or Anthropic's Claude within your development environment. It provides a seamless way to access AI-powered assistance while coding, enabling you to get real-time help, generate code snippets, debug errors, and brainstorm ideas without leaving your IDE.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
xiaogpt
xiaogpt is a tool that allows you to play ChatGPT and other LLMs with Xiaomi AI Speaker. It supports ChatGPT, New Bing, ChatGLM, Gemini, Doubao, and Tongyi Qianwen. You can use it to ask questions, get answers, and have conversations with AI assistants. xiaogpt is easy to use and can be set up in a few minutes. It is a great way to experience the power of AI and have fun with your Xiaomi AI Speaker.

googlegpt
GoogleGPT is a browser extension that brings the power of ChatGPT to Google Search. With GoogleGPT, you can ask ChatGPT questions and get answers directly in your search results. You can also use GoogleGPT to generate text, translate languages, and more. GoogleGPT is compatible with all major browsers, including Chrome, Firefox, Edge, and Safari.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.