
hal9
Hal9 — Create and Share Generative Apps
Stars: 173
Hal9 is a tool that allows users to create and deploy generative applications such as chatbots and APIs quickly. It is open, intuitive, scalable, and powerful, enabling users to use various models and libraries without the need to learn complex app frameworks. With a focus on AI tasks like RAG, fine-tuning, alignment, and training, Hal9 simplifies the development process by skipping engineering tasks like frontend development, backend integration, deployment, and operations.
README:
Hal9: Create and Share AI Apps


Hal9 is a company on a mission to help people profit from AI, starting with startup founders. Hal9's Startup Plan builds AI-powered MVPs for founders in 30 days, including Hal9 Onboarding (design, development, infrastructure, and maintenance) and Hal9 Platform (compute, storage, LLMs). Additionally, the Hal9 Platform offers free and developer plans, with all code designed to run on any compute infrastructure, ensuring your applications remain free from vendor lock-in.
Hal9 Platform is purpose-built for generative AI, enabling you to create and deploy generative (LLMs and diffusers) applications (chatbots, agents, APIs, and apps). Key features:
- Flexible: Use any library (LangChain, DSPy), and any model (OpenAI, Llama, Groq, MidJourney).
-
Intuitive: No need to learn app frameworks (Flask), simply use
input()andprint(), or write file to disk. - Scalable: Designed to integrate your app with scalable technologies (Docker, Kubernetes, etc).
- Powerful: Support for long-running agents, multiple programming languages, complex system dependencies, and running arbitrary code in a secure Kubernetes pods.
- Open: The code behind hal9, is also open source and open for contributions under at apps/hal9.
Focus on AI (RAG, fine-tuning, alignment, training) and skip engineering tasks (frontend development, backend integration, deployment, operations).
Create and share a chatbot in seconds as follows:
pip install hal9
hal9 create chatbot
hal9 deploy chatbotNotice that deploy needs a HAL9_TOKEN environment variable with an API token you can get from hal9.com/devs. You can use this token to deploy from your local computer, a notebook or automate from GitHub.
HAL9_TOKEN=H9YOURTOKEN hal9 deploy chatbot --name my_first_chatbotAs easy as that you have created your first chatbot!

The code inside /chatbot/app.py contains a "Hello World" chatbot that reads the user prompt and echos the result back:
prompt = input()
print(f"Echo: {prompt}")We designed this package with simplicity in mind, the job of the code is to read input and write output, that's about it. That said, you can create chatbots that use LLMs, generate images, or even use tools that connect to databases, or even build websites and games!
By default hal9 create defaults to the --template echo template, but you can choose different ones as follows:
hal9 create chatbot-openai --template openai
hal9 create chatbot-groq --template groqA template provides ready to use code with specific technologies and use cases. Is very popular to use OpenAI's ChatGPT-like template with --template openai, the code generated will look as follows:
import hal9 as h9
from openai import OpenAI
messages = h9.load("messages", [])
prompt = h9.input(messages = messages)
completions = OpenAI().chat.completions.create(model = "gpt-4", messages = messages, stream = True)
h9.complete(completions, messages = messages)
h9.save("messages", messages, hidden = True)The learn code section explains in detail how this code works, but will provide a quick overview. The hal9 package contains a helper functions to simplify your generative AI code. You can choose to not use hal9 at all and use input() and print() statements yourself, or even sue tools like langchain. The h9.load() and h9.save() functions load and save data across chat sessions, our platform is stateless by default. The h9.input() function is a slim wrapper over input() that also stores the user input in the messages. Then h9.complete() is a helper function to help parse the completion results and save the result in messages. That's about it!
To make changes to your project, open chatbot/ in your IDE and modify chatbot/app.py.
You can then run your project as follows:
hal9 run chatbotIf you customized your template with --template make sure to set the correct key, for example, if you are using the OpenAI template use for Linux or macOS:
export OPENAI_KEY=YOUR_OPENAI_KEY.For Windows use:
set OPENAI_KEY=YOUR_OPENAI_KEY.For more information on obtaining and using your OpenAI API key, please refer to the OpenAI API Key documentation.
You can then run your application locally with:
hal9 run chatbotThis command is just a convenience wrapper to running the code yourself with something like python app.py.
The deploy command will prepare for deployment your generative app.
For example, you can prepare deployment as a generative app. We have plans to also provide deployment to Docker and the open source community can expand this even further.
hal9 deploy chatbot --target hal9Each command is tasked with preparing the deployment of your project folder. For example, --target docker should create a Dockerfile file that gets this project ready to run in cloud containers.
For personal use, --target hal9 supports a free tier at hal9.com; enterprise support is also available to deploy with --target hal9 --url hal9.yourcompany.com
Apart from deploying your apps directly on hal9.com/platform, you can collaborate with our community by contributing new ones to the /apps directory in this repository. Additionally, you can improve Hal9 AI’s core capabilities by refining the code in the apps/hal9 folder.
The hal9 Python package is located in the /python directory, while the documentation website resides under /website. We encourage contributors to focus on enhancing apps first before proposing more complex changes.
Keep in mind that the philosophy of the hal9 package is to remain a lightweight wrapper around input() and print(). The Python community already offers many excellent frameworks, and we aim to encourage their use rather than creating another one.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hal9
Similar Open Source Tools
hal9
Hal9 is a tool that allows users to create and deploy generative applications such as chatbots and APIs quickly. It is open, intuitive, scalable, and powerful, enabling users to use various models and libraries without the need to learn complex app frameworks. With a focus on AI tasks like RAG, fine-tuning, alignment, and training, Hal9 simplifies the development process by skipping engineering tasks like frontend development, backend integration, deployment, and operations.

aisuite
Aisuite is a simple, unified interface to multiple Generative AI providers. It allows developers to easily interact with various Language Model (LLM) providers like OpenAI, Anthropic, Azure, Google, AWS, and more through a standardized interface. The library focuses on chat completions and provides a thin wrapper around python client libraries, enabling creators to test responses from different LLM providers without changing their code. Aisuite maximizes stability by using HTTP endpoints or SDKs for making calls to the providers. Users can install the base package or specific provider packages, set up API keys, and utilize the library to generate chat completion responses from different models.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

agentok
Agentok Studio is a visual tool built for AutoGen, a cutting-edge agent framework from Microsoft and various contributors. It offers intuitive visual tools to simplify the construction and management of complex agent-based workflows. Users can create workflows visually as graphs, chat with agents, and share flow templates. The tool is designed to streamline the development process for creators and developers working on next-generation Multi-Agent Applications.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.
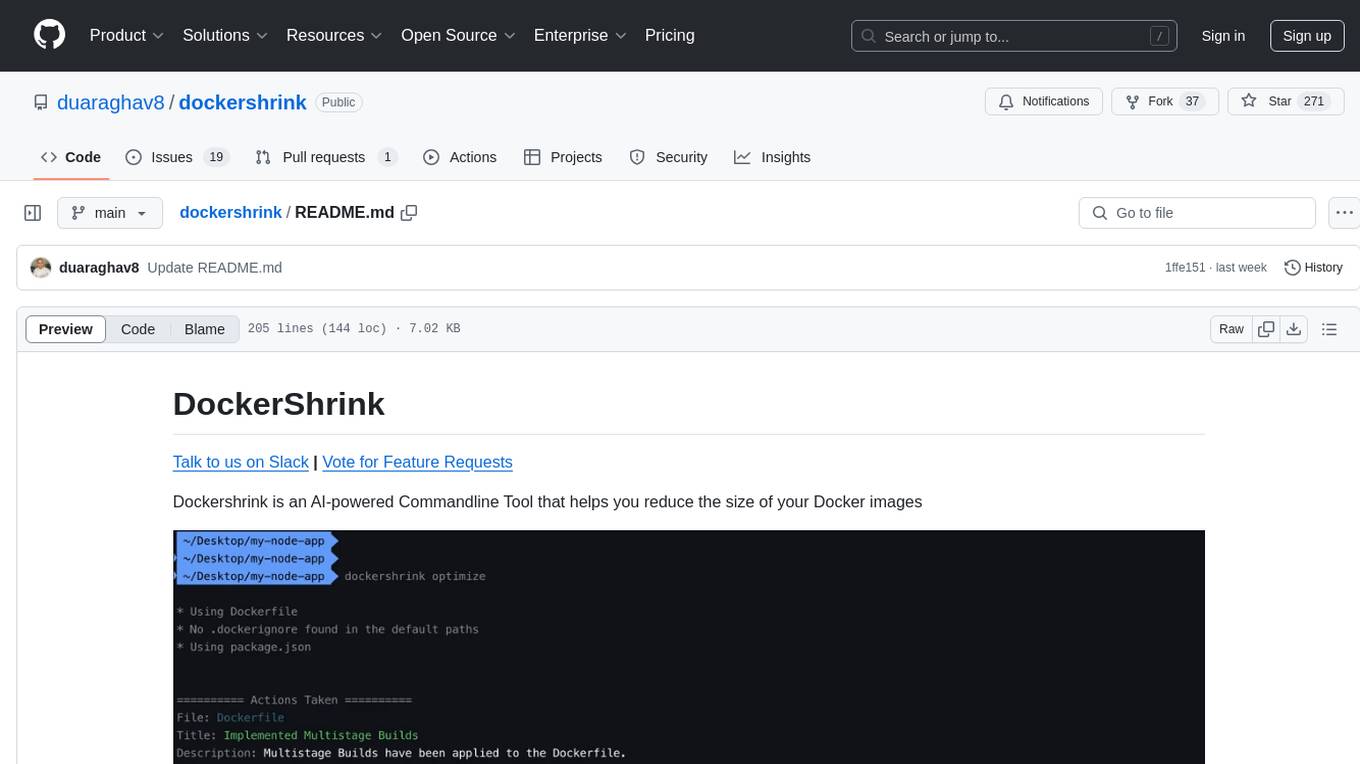
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
polis
Polis is an AI powered sentiment gathering platform that offers a more organic approach than surveys and requires less effort than focus groups. It provides a comprehensive wiki, main deployment at https://pol.is, discussions, issue tracking, and project board for users. Polis can be set up using Docker infrastructure and offers various commands for building and running containers. Users can test their instance, update the system, and deploy Polis for production. The tool also provides developer conveniences for code reloading, type checking, and database connections. Additionally, Polis supports end-to-end browser testing using Cypress and offers troubleshooting tips for common Docker and npm issues.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.
BentoDiffusion
BentoDiffusion is a BentoML example project that demonstrates how to serve and deploy diffusion models in the Stable Diffusion (SD) family. These models are specialized in generating and manipulating images based on text prompts. The project provides a guide on using SDXL Turbo as an example, along with instructions on prerequisites, installing dependencies, running the BentoML service, and deploying to BentoCloud. Users can interact with the deployed service using Swagger UI or other methods. Additionally, the project offers the option to choose from various diffusion models available in the repository for deployment.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
minimal-llm-ui
This minimalistic UI serves as a simple interface for Ollama models, enabling real-time interaction with Local Language Models (LLMs). Users can chat with models, switch between different LLMs, save conversations, and create parameter-driven prompt templates. The tool is built using React, Next.js, and Tailwind CSS, with seamless integration with LangchainJs and Ollama for efficient model switching and context storage.
devika
Devika is an advanced AI software engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika utilizes large language models, planning and reasoning algorithms, and web browsing abilities to intelligently develop software. Devika aims to revolutionize the way we build software by providing an AI pair programmer who can take on complex coding tasks with minimal human guidance. Whether you need to create a new feature, fix a bug, or develop an entire project from scratch, Devika is here to assist you.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
For similar tasks

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.
unsloth
Unsloth is a tool that allows users to fine-tune large language models (LLMs) 2-5x faster with 80% less memory. It is a free and open-source tool that can be used to fine-tune LLMs such as Gemma, Mistral, Llama 2-5, TinyLlama, and CodeLlama 34b. Unsloth supports 4-bit and 16-bit QLoRA / LoRA fine-tuning via bitsandbytes. It also supports DPO (Direct Preference Optimization), PPO, and Reward Modelling. Unsloth is compatible with Hugging Face's TRL, Trainer, Seq2SeqTrainer, and Pytorch code. It is also compatible with NVIDIA GPUs since 2018+ (minimum CUDA Capability 7.0).

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.
aiwechat-vercel
aiwechat-vercel is a tool that integrates AI capabilities into WeChat public accounts using Vercel functions. It requires minimal server setup, low entry barriers, and only needs a domain name that can be bound to Vercel, with almost zero cost. The tool supports various AI models, continuous Q&A sessions, chat functionality, system prompts, and custom commands. It aims to provide a platform for learning and experimentation with AI integration in WeChat public accounts.
hugging-chat-api
Unofficial HuggingChat Python API for creating chatbots, supporting features like image generation, web search, memorizing context, and changing LLMs. Users can log in, chat with the ChatBot, perform web searches, create new conversations, manage conversations, switch models, get conversation info, use assistants, and delete conversations. The API also includes a CLI mode with various commands for interacting with the tool. Users are advised not to use the application for high-stakes decisions or advice and to avoid high-frequency requests to preserve server resources.
microchain
Microchain is a function calling-based LLM agents tool with no bloat. It allows users to define LLM and templates, use various functions like Sum and Product, and create LLM agents for specific tasks. The tool provides a simple and efficient way to interact with OpenAI models and create conversational agents for various applications.
embedchain
Embedchain is an Open Source Framework for personalizing LLM responses. It simplifies the creation and deployment of personalized AI applications by efficiently managing unstructured data, generating relevant embeddings, and storing them in a vector database. With diverse APIs, users can extract contextual information, find precise answers, and engage in interactive chat conversations tailored to their data. The framework follows the design principle of being 'Conventional but Configurable' to cater to both software engineers and machine learning engineers.
OpenAssistantGPT
OpenAssistantGPT is an open source platform for building chatbot assistants using OpenAI's Assistant. It offers features like easy website integration, low cost, and an open source codebase available on GitHub. Users can build their chatbot with minimal coding required, and OpenAssistantGPT supports direct billing through OpenAI without extra charges. The platform is user-friendly and cost-effective, appealing to those seeking to integrate AI chatbot functionalities into their websites.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.