
PolyMind
A multimodal, function calling powered LLM webui.
Stars: 204
PolyMind is a multimodal, function calling powered LLM webui designed for various tasks such as internet searching, image generation, port scanning, Wolfram Alpha integration, Python interpretation, and semantic search. It offers a plugin system for adding extra functions and supports different models and endpoints. The tool allows users to interact via function calling and provides features like image input, image generation, and text file search. The application's configuration is stored in a `config.json` file with options for backend selection, compatibility mode, IP address settings, API key, and enabled features.
README:
PolyMind is a multimodal, function calling powered LLM webui. It's designed to be used with Mixtral 8x7B-Instruct/Mistral-7B-Instruct-v0.2 + TabbyAPI, but can be used with other models and/or with llama.cpp's included server and, when using the compatiblity mode + tabbyAPI mode, any endpoint with /v1/completions support, and offers a wide range of features including:
- Internet searching with DuckDuckGo and web scraping capabilities.
- Image generation using comfyui along with optional, function calling controlled, automatic background removal using RMBG-1.4 and experimental img2img with uploaded images.
- Image input with sharegpt4v (Over llama.cpp's server)/moondream on CPU, OCR, and Yolo.
- Port scanning with nmap.
- Wolfram Alpha integration.
- A Python interpreter.
- RAG with semantic search for PDF and miscellaneous text files.
- Plugin system to easily add extra functions that are able to be called by the model.
90% of the web parts (HTML, JS, CSS, and Flask) are written entirely by Mixtral.
Note: The python interpreter is intentionally delayed by 5 seconds to make it easy to check the code before its ran.
Note: When making multiple function calls simultaneously, only one image can be returned at a time. For instance, if you request to generate an image of a dog using comfyui and plot a sine wave using matplotlib, only one of them will be displayed.
Note: When using RAG, make it clear that you are requesting information according to the file you've uploaded.
- Clone the repository:
git clone https://github.com/itsme2417/PolyMind.git && cd PolyMind - Install the required dependencies:
pip install -r requirements.txt - Install the required node modules:
cd static && npm install - Copy
config.example.jsonasconfig.jsonand fill in required settings.
For the ComfyUI stablefast workflow, make sure to have ComfyUI_stable_fast installed. For the img2img workflow, make sure to have comfyui-base64-to-image installed.
To use PolyMind, run the following command in the project directory:
python main.pyThere are no "commands" or similar as everything is done via function calling. Clearing the context can be done by asking the model to do so, along with the Enabled features which can be disabled or enabled temporarily in the same way.
For plugins check The plugins directory
For an example on how to use polymind as a basic API Server check Examples
The application's configuration is stored in the config.json file. Here's a description of each option:
-
Backend: The backend that runs the LLM. Options:tabbyapiorllama.cpp. -
compatibility_mode,compat_tokenizer_model: When set to true and a tokenizer model specified, will use a local tokenizer instead of one provided by the API server. To be used with endpoints without tokenization support, such asKoboldCPPor similar. -
HOSTandPORT: The IP address and port of the backend. -
admin_ip: The IP address of the admin/trusted user. Necessary to use the Python interpreter and change settings. -
listen: Whether to allow other hosts in the network to access the webui. -
api_key: The API key for the Tabby backend. -
max_seq_len: The maximum context length. -
reserve_space: Reserves an amount of tokens equivalent tomax_new_tokensin the context if set to true. -
LLM_parameters: Should be self-explanatory, parameters will be overridden by known working ones for now. -
Enabled_features,image_input,imagegeneration,wolframalpha: URIs for llama.cpp running a multimodal model, comfyui, and the app_id for Wolfram Alpha respectively. -
runpythoncode/depth: Specifies the maximum number of attempts GateKeeper can make to debug non-running code. To disable this feature, set it to 0. -
imagegeneration/checkpoint_name: Specifies the filename of the SD checkpoint for comfyui. -
file_input/chunk_size: Specifies the token count per segment for text chunking. Equivalent to amount of context used per RAG message. -
file_input/raw_input: If set to true, the user's message is used as the query for the semantic search, otherwise an LLM generated query is used. -
file_input/retrieval_count: Number of chunks to use from the RAG results. -
image_input/backend: If set tomoondream, will use the moondream model on cpu, if set tollama.cppwill use the llama.cpp server running atURI. -
Plugins: A list containing the name of enabled plugins, Names should match the folder names inpluginsandmodule_namefrom theirmanifest.json.
Patreon: https://www.patreon.com/llama990
LTC: Le23XWF6bh4ZAzMRK8C9bXcEzjn5xdfVgP
XMR: 46nkUDLzVDrBWUWQE2ujkQVCbWUPGR9rbSc6wYvLbpYbVvWMxSjWymhS8maYdZYk8mh25sJ2c7S93VshGAij3YJhPztvbTb
If you want to mess around with my llm discord bot or join for whatever reason, heres a discord server: https://discord.gg/zxPCKn859r






For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for PolyMind
Similar Open Source Tools
PolyMind
PolyMind is a multimodal, function calling powered LLM webui designed for various tasks such as internet searching, image generation, port scanning, Wolfram Alpha integration, Python interpretation, and semantic search. It offers a plugin system for adding extra functions and supports different models and endpoints. The tool allows users to interact via function calling and provides features like image input, image generation, and text file search. The application's configuration is stored in a `config.json` file with options for backend selection, compatibility mode, IP address settings, API key, and enabled features.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
ai-town
AI Town is a virtual town where AI characters live, chat, and socialize. This project provides a deployable starter kit for building and customizing your own version of AI Town. It features a game engine, database, vector search, auth, text model, deployment, pixel art generation, background music generation, and local inference. You can customize your own simulation by creating characters and stories, updating spritesheets, changing the background, and modifying the background music.
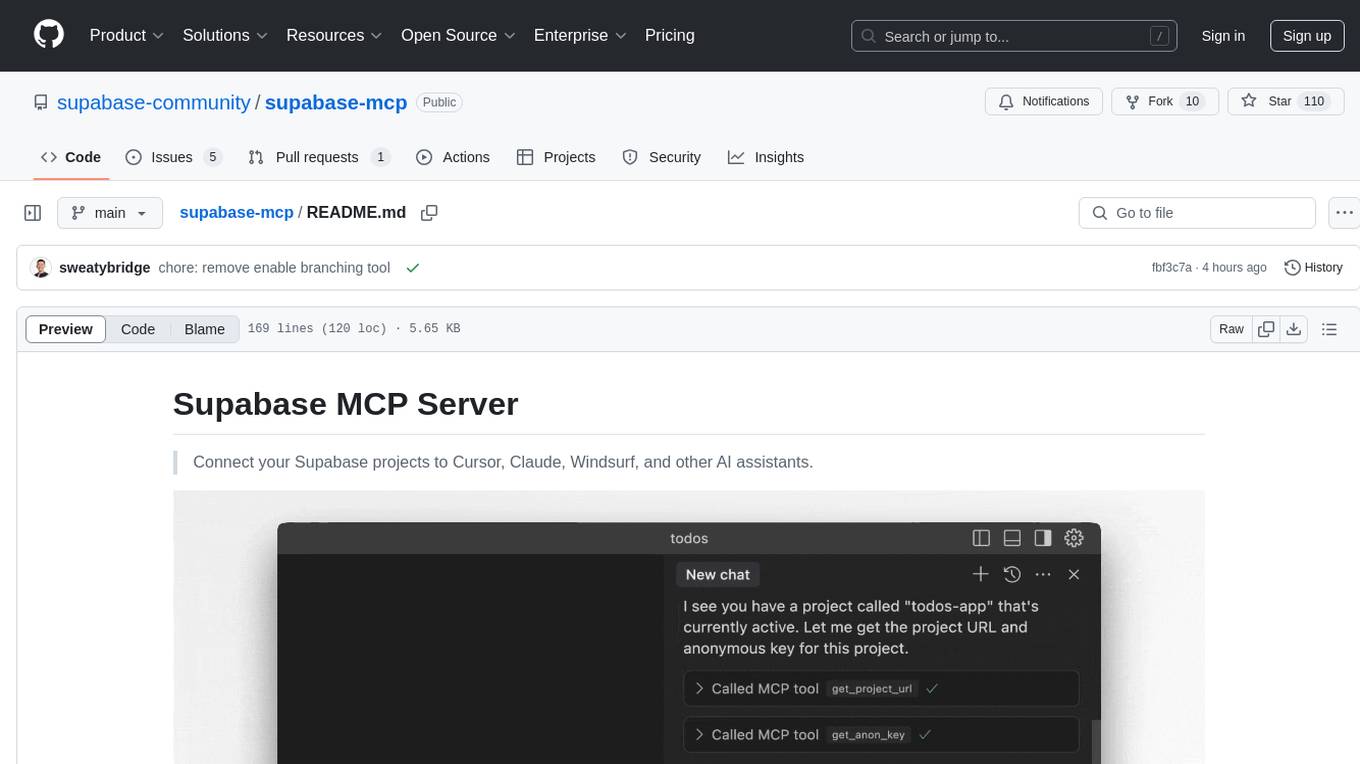
supabase-mcp
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.
starter-monorepo
Starter Monorepo is a template repository for setting up a monorepo structure in your project. It provides a basic setup with configurations for managing multiple packages within a single repository. This template includes tools for package management, versioning, testing, and deployment. By using this template, you can streamline your development process, improve code sharing, and simplify dependency management across your project. Whether you are working on a small project or a large-scale application, Starter Monorepo can help you organize your codebase efficiently and enhance collaboration among team members.
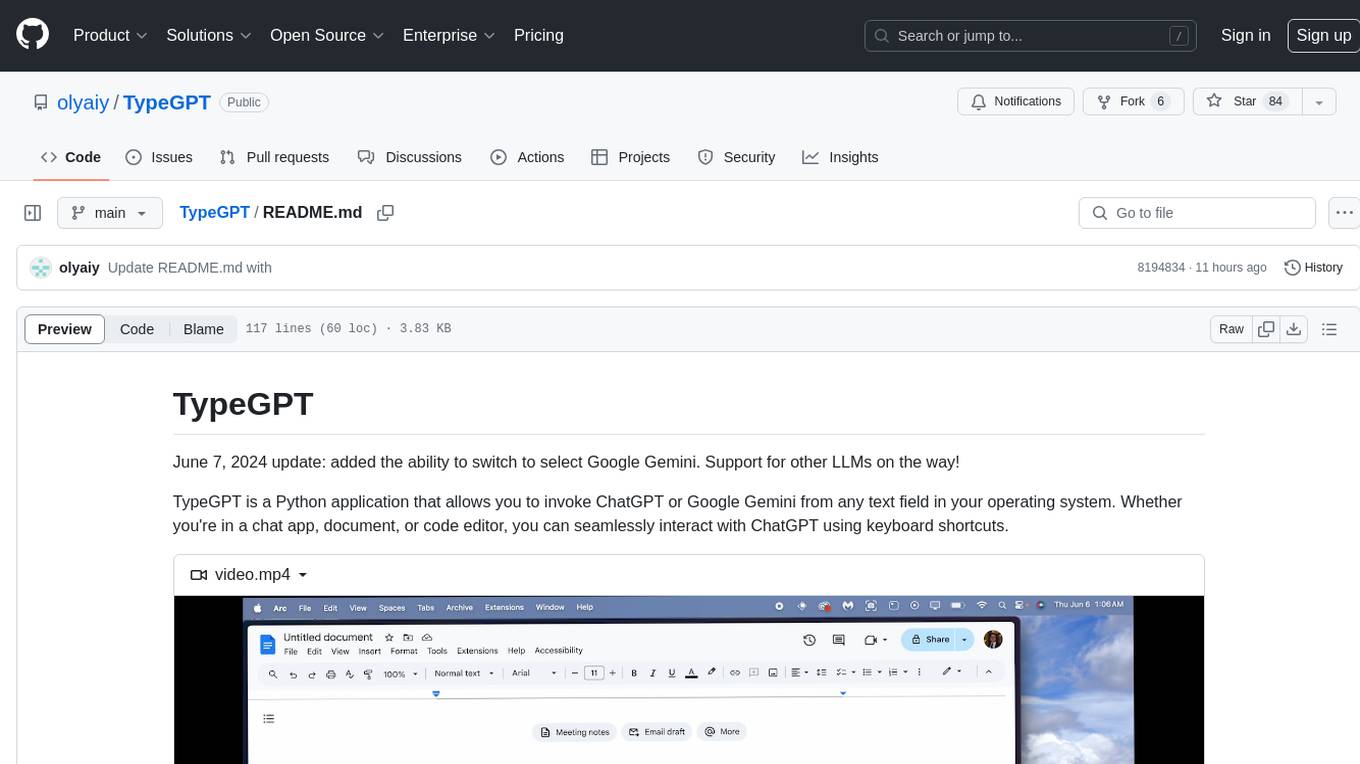
TypeGPT
TypeGPT is a Python application that enables users to interact with ChatGPT or Google Gemini from any text field in their operating system using keyboard shortcuts. It provides global accessibility, keyboard shortcuts for communication, and clipboard integration for larger text inputs. Users need to have Python 3.x installed along with specific packages and API keys from OpenAI for ChatGPT access. The tool allows users to run the program normally or in the background, manage processes, and stop the program. Users can use keyboard shortcuts like `/ask`, `/see`, `/stop`, `/chatgpt`, `/gemini`, `/check`, and `Shift + Cmd + Enter` to interact with the application in any text field. Customization options are available by modifying files like `keys.txt` and `system_prompt.txt`. Contributions are welcome, and future plans include adding support for other APIs and a user-friendly GUI.

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.
hugescm
HugeSCM is a cloud-based version control system designed to address R&D repository size issues. It effectively manages large repositories and individual large files by separating data storage and utilizing advanced algorithms and data structures. It aims for optimal performance in handling version control operations of large-scale repositories, making it suitable for single large library R&D, AI model development, and game or driver development.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.
2p-kt
2P-Kt is a Kotlin-based and multi-platform reboot of tuProlog (2P), a multi-paradigm logic programming framework written in Java. It consists of an open ecosystem for Symbolic Artificial Intelligence (AI) with modules supporting logic terms, unification, indexing, resolution of logic queries, probabilistic logic programming, binary decision diagrams, OR-concurrent resolution, DSL for logic programming, parsing modules, serialisation modules, command-line interface, and graphical user interface. The tool is designed to support knowledge representation and automatic reasoning through logic programming in an extensible and flexible way, encouraging extensions towards other symbolic AI systems than Prolog. It is a pure, multi-platform Kotlin project supporting JVM, JS, Android, and Native platforms, with a lightweight library leveraging the Kotlin common library.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and fostering collaboration. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, configuration management, training job monitoring, media upload, and prediction. The repository also includes tutorial-style Jupyter notebooks demonstrating SDK usage.
For similar tasks

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
freeGPT
freeGPT provides free access to text and image generation models. It supports various models, including gpt3, gpt4, alpaca_7b, falcon_40b, prodia, and pollinations. The tool offers both asynchronous and non-asynchronous interfaces for text completion and image generation. It also features an interactive Discord bot that provides access to all the models in the repository. The tool is easy to use and can be integrated into various applications.
generative-ai-go
The Google AI Go SDK enables developers to use Google's state-of-the-art generative AI models (like Gemini) to build AI-powered features and applications. It supports use cases like generating text from text-only input, generating text from text-and-images input (multimodal), building multi-turn conversations (chat), and embedding.

ai-flow
AI Flow is an open-source, user-friendly UI application that empowers you to seamlessly connect multiple AI models together, specifically leveraging the capabilities of multiples AI APIs such as OpenAI, StabilityAI and Replicate. In a nutshell, AI Flow provides a visual platform for crafting and managing AI-driven workflows, thereby facilitating diverse and dynamic AI interactions.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
OpenAI-DotNet
OpenAI-DotNet is a simple C# .NET client library for OpenAI to use through their RESTful API. It is independently developed and not an official library affiliated with OpenAI. Users need an OpenAI API account to utilize this library. The library targets .NET 6.0 and above, working across various platforms like console apps, winforms, wpf, asp.net, etc., and on Windows, Linux, and Mac. It provides functionalities for authentication, interacting with models, assistants, threads, chat, audio, images, files, fine-tuning, embeddings, and moderations.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.