
Open-LLM-VTuber
Talk to any LLM with hands-free voice interaction, voice interruption, and Live2D taking face running locally across platforms
Stars: 1903

Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
README:


<- (Clickable links)
(QQ群: 792615362)<- way more active than Discord group with over 700 population and majority of the contributors
常见问题 Common Issues doc (Written in Chinese): https://docs.qq.com/doc/DTHR6WkZ3aU9JcXpy
User Survey: https://forms.gle/w6Y6PiHTZr1nzbtWA
调查问卷(中文)(现在不用登入了): https://wj.qq.com/s2/16150415/f50a/
⚠️ This project is in its early stages and is currently under active development. Features are unstable, code is messy, and breaking changes will occur. The main goal of this stage is to build a minimum viable prototype using technologies that are easy to integrate.
⚠️ This project is NOT easy to install. Join the Discord server or QQ group if you need help or to get updates about this project.
⚠️ If you want to run this program on a server and access it remotely on your laptop, the microphone on the front end will only launch in a secure context (a.k.a. https or localhost). See MDN Web Doc. Therefore, you should configure https with a reverse proxy to access the page on a remote machine (non-localhost).
You are right if you think this README and the docs are super duper messy! A complete refactoring of the documentation is planned. In the meantime, you can watch the installation videos if you speak Chinese.
This project is currently under a major refactoring, which involves breaking changes in configurations, architectual changes in the backend, a complete rewritten frontend, and many more. You can check out the progress and roadmap here.
The refactored version, which is planned to release in version v1.0.0, is being worked on the superb-refactoring branch. The changes in superb-refactoring branch will be merged to main branch once we are ready to release v1.0.0. The new frontend is in the Open-LLM-VTuber-Web repository (on the dev branch).
If you want to contribute to this project, please do the modifications based on the newest superb-refactoring branch. You can talk to me via discord or qq or email something else and make sure we are on the same page.
This project is the first open source project I have that involves real human opening PRs to my repo. I really love and appreciate all the work from the community and I want to make this project awesome and accessible for others to achieve what they want, but it takes time (and my hairs) for me to learn and start doing things right.
Open-LLM-VTuber allows you to talk to (and interrupt!) any LLM locally by voice (hands-free) with a Live2D talking face. The LLM inference backend, speech recognition, and speech synthesizer are all designed to be swappable. This project can be configured to run offline on macOS, Linux, and Windows. Online LLM/ASR/TTS options are also supported.
Long-term memory with MemGPT can be configured to achieve perpetual chat, infinite* context length, and external data source.
This project started as an attempt to recreate the closed-source AI VTuber neuro-sama with open-source alternatives that can run offline on platforms other than Windows.
English demo:
https://github.com/user-attachments/assets/f13b2f8e-160c-4e59-9bdb-9cfb6e57aca9
English Demo: YouTube
中文 demo:
- It works on macOS
- Many existing solutions display Live2D models with VTube Studio and achieve lip sync by routing desktop internal audio into VTube Studio and controlling the lips with that. On macOS, however, there is no easy way to let VTuber Studio listen to internal audio on the desktop.
- Many existing solutions lack support for GPU acceleration on macOS, which makes them run slow on Mac.
- This project supports MemGPT for perpetual chat. The chatbot remembers what you've said.
- No data leaves your computer if you wish to
- You can choose local LLM/voice recognition/speech synthesis solutions; everything works offline. Tested on macOS.
- You can interrupt the LLM anytime with your voice without wearing headphones.
- [x] Chat with any LLM by voice
- [x] Interrupt LLM with voice at any time
- [x] Choose your own LLM backend
- [x] Choose your own Speech Recognition & Text to Speech provider
- [x] Long-term memory
- [x] Live2D frontend
- macOS
- Linux
- Windows
Check out the GitHub Release for updated notes.
- Talk to LLM with voice. Offline.
-
RAG on chat history(temporarily removed)
Currently supported LLM backend
- Any OpenAI-API-compatible backend, such as Ollama, Groq, LM Studio, OpenAI, and more.
- Claude
- llama.cpp local inference within this project
- MemGPT (broken)
- Mem0 (not great)
Currently supported Speech recognition backend
-
FunASR, which support SenseVoiceSmall and many other models. (
LocalCurrently requires an internet connection for loading. Compute locally) - Faster-Whisper (Local)
- Whisper-CPP using the python binding pywhispercpp (Local, mac GPU acceleration can be configured)
- Whisper (local)
- Groq Whisper (API Key required). This is a hosted Whisper endpoint. It's fast and has a generous free limit every day.
- Azure Speech Recognition (API Key required)
- sherpa-onnx (Local, fast, supports various models including transducer, Paraformer, NeMo CTC, WeNet CTC, Whisper, TDNN CTC, and SenseVoice models.)
Currently supported Text to Speech backend
- py3-tts (Local, it uses your system's default TTS engine)
- meloTTS (Local, fast)
- Coqui-TTS (Local, speed depends on the model you run.)
- bark (Local, very resource-consuming)
- CosyVoice (Local, very resource-consuming)
- xTTSv2 (Local, very resource-consuming)
- Edge TTS (online, no API key required)
- Azure Text-to-Speech (online, API Key required)
- sherpa-onnx (Local, fast, supports various models. For English, piper models are recommended. For pure Chinese, consider using sherpa-onnx-vits-zh-ll.tar.bz2. For a mix of Chinese and English, vits-melo-tts-zh_en.tar.bz2 can be used, though the English pronunciation might not be ideal.)
- GPT-SoVITS (checkout doc here)
Fast Text Synthesis
- Synthesize sentences as soon as they arrive, so there is no need to wait for the entire LLM response.
- Producer-consumer model with multithreading: Audio will be continuously synthesized in the background. They will be played one by one whenever the new audio is ready. The audio player will not block the audio synthesizer.
Live2D Talking face
- Change Live2D model with
config.yaml(model needs to be listed in model_dict.json) - Load local Live2D models. Check
doc/live2d.mdfor documentation. - Uses expression keywords in LLM response to control facial expression, so there is no additional model for emotion detection. The expression keywords are automatically loaded into the system prompt and excluded from the speech synthesis output.
live2d technical details
- Uses guansss/pixi-live2d-display to display live2d models in browser
- Uses WebSocket to control facial expressions and talking state between the server and the front end
- All the required packages are locally available, so the front end works offline.
- You can load live2d models from a URL or the one stored locally in the
live2d-modelsdirectory. The defaultshizuku-localis stored locally and works offline. If the URL property of the model in the model_dict.json is a URL rather than a path starting with/live2d-models, they will need to be fetched from the specified URL whenever the front end is opened. Readdoc/live2d.mdfor documentation on loading your live2D model from local. - Run the
server.pyto run the WebSocket communication server, open theindex.htmlin the./staticfolder to open the front end, and runlaunch.pymain.pyto run the backend for LLM/ASR/TTS processing.
If you speak Chinese, there are two installation videos for you.
- (preferred 🎉)
v0.4.3Complete Tutorial with auto-install script for Windows users -
v0.2.4manual installation tutorial on macOS
If you don't speak Chinese, good luck. Let me know if you create on in other languages so I can put it here.
New installation instruction is being created here
A new quick start script (experimental) was added in v0.4.0.
This script allows you to get this project running without worrying (too much) about the dependencies.
The only thing you need for this script is Python, a good internet connection, and enough disk space.
This script will do the following:
- download miniconda in the project directory
- create a conda environment in the project directory
- install all the dependencies you need for the configuration of
FunASR+edgeTTS(you still need to get an ollama or some OpenAI compatible backend) - run this project inside the conda environment
Run the script with python start_webui.py. Note that you should always use start_webui.py as the entry point if you decide to use the auto-installation script because server.py doesn't start the conda environment for you.
Also note that if you want to install other dependencies, you need to enter the auto-configured conda environment first by running python activate_conda.py
In general, there are 4 steps involved in getting this project running:
- basic setup
- Get the LLM (large language model)
- Get the TTS (text-to-speech)
- Get the ASR (speech recognition)
- ffmpeg
- Python >= 3.10, < 3.13 (3.13 doesn't work for now)
Clone this repository.
Virtual Python environment like conda or venv is strongly recommended! (because the dependencies are a mess!).
Run the following in the terminal to install the basic dependencies.
pip install -r requirements.txt # Run this in the project directory
# Install Speech recognition dependencies and text-to-speech dependencies according to the instructions belowEdit the conf.yaml for configurations. You can follow the configuration used in the demo video.
Once the live2D model appears on the screen, it's ready to talk to you.
~~If you don't want the live2d, you can run main.py with Python for cli mode. ~~ (CLI mode is deprecated now and will be removed in v1.0.0. If some still want the cli mode, maybe we can make a cli client in the future, but the current architecture will be refactored very soon)
Some models will be downloaded on your first launch, which may require an internet connection and may take a while.
🎉 A new experimental update script was added in v0.3.0. Run python upgrade.py to update to the latest version.
Back up the configuration files conf.yaml if you've edited them, and then update the repo.
Or just clone the repo again and make sure to transfer your configurations. The configuration file will sometimes change because this project is still in its early stages. Be cautious when updating the program.
Put ollama into LLM_PROVIDER option in conf.yaml and fill the settings.
If you use the official OpenAI API, the base_url is https://api.openai.com/v1.
Claude support was added in v0.3.1 in https://github.com/t41372/Open-LLM-VTuber/pull/35
Change the LLM_PROVIDER to claude and complete the settings under claude
Provides a way to run LLM within this project without any external tools like ollama. A .gguf model file is all you need.
According to the project repo
Requirements:
- Python 3.8+
- C compiler
- Linux: gcc or clang
- Windows: Visual Studio or MinGW
- MacOS: Xcode
This will also build llama.cpp from the source and install it alongside this Python package.
If this fails, add --verbose to the pip install see the full cmake build log.
Find the pip install llama-cpp-python command for your platform here.
For example:
if you use an Nvidia GPU, run this.
CMAKE_ARGS="-DGGML_CUDA=on" pip install llama-cpp-python
If you use an apple silicon Mac (like I do), do this:
CMAKE_ARGS="-DGGML_METAL=on" pip install llama-cpp-python
If you use an AMD GPU that supports ROCm:
CMAKE_ARGS="-DGGML_HIPBLAS=on" pip install llama-cpp-python
If you want to use CPU (OpenBlas):
CMAKE_ARGS="-DGGML_BLAS=ON -DGGML_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
For more options, check here.
⚠️ MemGPT was renamed to Letta, and they changed their API. Currently, the integration of MemGPT in this project has not been updated with the latest changes, so the integration is broken. It probably won't get fixed because MemGPT (or Letta now) is quite slow and unstable for local LLMs. A new long-term memory solution is planned.
However, you can still get the old version of MemGPT and try it out. Here is the documentation.
MemGPT integration is very experimental and requires quite a lot of setup. In addition, MemGPT requires a powerful LLM (larger than 7b and quantization above Q5) with a lot of token footprint, which means it's a lot slower. MemGPT does have its own LLM endpoint for free, though. You can test things with it. Check their docs.
This project can use MemGPT as its LLM backend. MemGPT enables LLM with long-term memory.
To use MemGPT, you need to have the MemGPT server configured and running. You can install it using pip or docker or run it on a different machine. Check their GitHub repo and official documentation.
⚠️ I recommend you install MemGPT either in a separate Python virtual environment or in docker because there is currently a dependency conflict between this project and MemGPT (on fast API, it seems). You can check this issue Can you please upgrade typer version in your dependancies #1382.
Here is a checklist:
- Install memgpt
- Configure memgpt
- Run
memgptusingmemgpt servercommand. Remember to have the server running before launching Open-LLM-VTuber. - Set up an agent either through its cli or web UI. Add your system prompt with the Live2D Expression Prompt and the expression keywords you want to use (find them in
model_dict.json) into MemGPT - Copy the
server admin passwordand theAgent idinto./llm/memgpt_config.yaml. By the way,agent idis not the agent's name. - Set the
LLM_PROVIDERtomemgptinconf.yaml. - Remember, if you use
memgpt, all LLM-related configurations inconf.yamlwill be ignored becausememgptdoesn't work that way.
Another long-term memory solution. Still in development. Highly experimental.
Pro
- It's easier to set up compared to MemGPT
- It's a bit faster than MemGPT (but still would take quite a lot more LLM tokens to process)
Cons
- It remembers your preferences and thoughts, nothing else. It doesn't remember what the LLM said.
- It doesn't always put stuff into memory.
- It sometimes remembers wrong stuff
- It requires an LLM with very good function calling capability, which is quite difficult for smaller models
Edit the ASR_MODEL settings in the conf.yaml to change the provider.
Here are the options you have for speech recognition:
sherpa-onnx (local, runs very fast) (added in v0.5.0-alpha.1 in https://github.com/t41372/Open-LLM-VTuber/pull/50)
- Install with
pip install sherpa-onnx. (~20MB) - Download your desired model from sherpa-onnx ASR models.
- Refer to
config_altsin the repository for configuration examples and modify the model path in yourconf.yamlaccordingly. - It offers great performance and is significantly lighter than FunASR.
FunASR (local) (Runs very fast even on CPU. Not sure how they did it)
- FunASR is a Fundamental End-to-End Speech Recognition Toolkit from ModelScope that runs many ASR models. The result and speed are pretty good with the SenseVoiceSmall from FunAudioLLM at Alibaba Group.
- Install with
pip install -U funasr modelscope huggingface_hub. Also, ensure you have torch (torch>=1.13) and torchaudio. Install them withpip install torch torchaudio onnx(FunASR now requiresonnxas well) - It requires an internet connection on launch even if the models are locally available. See https://github.com/modelscope/FunASR/issues/1897
Faster-Whisper (local)
- Whisper, but faster. On macOS, it runs on CPU only, which is not so fast, but it's easy to use.
- For Nvidia GPU users, to use GPU acceleration, you need the following NVIDIA libraries to be installed:
- Or if you don't need the speed, you can set the
devicesetting underFaster-Whisperinconf.yamltocputo reduce headaches.
WhisperCPP (local) (runs super fast on a Mac if configured correctly)
- If you are on a Mac, read below for instructions on setting up WhisperCPP with coreML support. If you want to use CPU or Nvidia GPU, install the package by running
pip install pywhispercpp. - The whisper cpp python binding. It can run on coreML with configuration, which makes it very fast on macOS.
- On CPU or Nvidia GPU, it's probably slower than Faster-Whisper
WhisperCPP coreML configuration:
- Uninstall the original
pywhispercppif you have already installed it. We are building the package. - Run
install_coreml_whisper.pywith Python to automatically clone and build the coreML-supportedpywhispercppfor you. - Prepare the appropriate coreML models.
- You can either convert models to coreml according to the documentation on Whisper.cpp repo
- ...or you can find some magical huggingface repo that happens to have those converted models. Just remember to decompress them. If the program fails to load the model, it will produce a segmentation fault.
- You don't need to include those weird prefixes in the model name in the
conf.yaml. For example, if the coreML model's name looks likeggml-base-encoder.mlmodelc, just putbaseinto themodel_nameunderWhisperCPPsettings in theconf.yaml.
Whisper (local)
- Original Whisper from OpenAI. Install it with
pip install -U openai-whisper - The slowest of all. Added as an experiment to see if it can utilize macOS GPU. It didn't.
GroqWhisperASR (online, API Key required)
- Whisper endpoint from Groq. It's very fast and has a lot of free usage every day. It's pre-installed. Get an API key from groq and add it into the GroqWhisper setting in the
conf.yaml. - API key and internet connection are required.
AzureASR (online, API Key required)
- Azure Speech Recognition. Install with
pip install azure-cognitiveservices-speech. - API key and internet connection are required.
⚠️ ‼️ Theapi_key.pywas deprecated inv0.2.5. Please set api keys inconf.yaml.
Install the respective package and turn it on using the TTS_MODEL option in conf.yaml.
sherpa-onnx (local) (added in v0.5.0-alpha.1 in https://github.com/t41372/Open-LLM-VTuber/pull/50)
- Install with
pip install sherpa-onnx. - Download your desired model from sherpa-onnx TTS models.
- Refer to
config_altsin the repository for configuration examples and modify the model path in yourconf.yamlaccordingly.
pyttsx3TTS (local, fast)
- Install with the command
pip install py3-tts. - This package will use the default TTS engine on your system. It uses
sapi5on Windows,nssson Mac, andespeakon other platforms. -
py3-ttsis used instead of the more famouspyttsx3becausepyttsx3seems unmaintained, and I couldn't get the latest version ofpyttsx3working.
meloTTS (local, fast)
- I recommend using
sherpa-onnxto do MeloTTS inferencing. MeloTTS implementation here is very difficult to install. - Install MeloTTS according to their documentation (don't install via docker) (A nice place to clone the repo is the submodule folder, but you can put it wherever you want). If you encounter a problem related to
mecab-python, try this fork (hasn't been merging into the main as of July 16, 2024). - It's not the best, but it's definitely better than pyttsx3TTS, and it's pretty fast on my mac. I would choose this for now if I can't access the internet (and I would use edgeTTS if I have the internet).
coquiTTS (local, can be fast or slow depending on the model you run)
- Seems easy to install
- Install with the command
pip install "coqui-tts[languages]" - Support many different TTS models. List all supported models with
tts --list_modelscommand. - The default model is an english only model.
- Use
tts_models/zh-CN/baker/tacotron2-DDC-GSTfor Chinese model. (but the consistency is weird...) - If you found some good model to use, let me know! There are too many models I don't even know where to start...
GPT_Sovits (local, medium fast) (added in v0.4.0 in https://github.com/t41372/Open-LLM-VTuber/pull/40)
- Please checkout this doc for installation instructions.
barkTTS (local, slow)
- Install the pip package with this command
pip install git+https://github.com/suno-ai/bark.gitand turn it on inconf.yaml. - The required models will be downloaded on the first launch.
cosyvoiceTTS (local, slow)
- Configure CosyVoice and launch the WebUI demo according to their documentation.
- Edit
conf.yamlto match your desired configurations. Check their WebUI and the API documentation on the WebUI to see the meaning of the configurations under the settingcosyvoiceTTSin theconf.yaml.
xTTSv2 (local, slow) (added in v0.2.4 in https://github.com/t41372/Open-LLM-VTuber/pull/23)
- Recommend to use xtts-api-server, it has clear api docs and relative easy to deploy.
edgeTTS (online, no API key required)
- Install the pip package with this command
pip install edge-ttsand turn it on inconf.yaml. - It sounds pretty good. Runs pretty fast.
- Remember to connect to the internet when using edge tts.
fishAPITTS (online, API key required) (added in v0.3.0-beta)
- Install with
pip install fish-audio-sdk - Register an account, get an API key, find a voice you want to use, and copy the reference id on Fish Audio.
- In
conf.yamlfile, set theTTS_MODELtofishAPITTS, and under thefishAPITTSsetting, set theapi_keyandreference_id.
AzureTTS (online, API key required) (This is the exact same TTS used by neuro-sama)
- Install the Azure SDK with the command'pip install azure-cognitiveservices-speech`.
- Get an API key (for text to speech) from Azure.
⚠️ ‼️ Theapi_key.pywas deprecated inv0.2.5. Please set api keys inconf.yaml.- The default setting in the
conf.yamlis the voice used by neuro-sama.
If you're using macOS, you need to enable the microphone permission of your terminal emulator (you run this program inside your terminal, right? Enable the microphone permission for your terminal). If you fail to do so, the speech recognition will not be able to hear you because it does not have permission to use your microphone.
For web interface, this project utilizes client-side Voice Activity Detection (VAD) using the ricky0123/vad-web library for efficient speech detection.
Web Interface Controls:
The following settings are available in the web interface to fine-tune the VAD:
- Speech Prob. Threshold: Controls the minimum speech probability for initial speech detection. Higher values require stronger speech input to trigger detection.
- Negative Speech Threshold: The probability threshold below which a frame is considered to not contain speech (i.e., part of a silence).
- Redemption Frames: Specifies how many consecutive frames of silence are required to end a speech segment. Higher values allow for more pause tolerance.
Tuning Tips:
Experiment with these parameters to find the optimal balance between sensitivity and accuracy for your environment and speaking style.
Translation was implemented to let the program speak in a language different from the conversation language. For example, the LLM might be thinking in English, the subtitle is in English, and you are speaking English, but the voice of the LLM is in Japanese. This is achieved by translating the sentence before it's sent for audio generation.
DeepLX is the only supported translation backend for now. You will need to deploy the deeplx service and set the configuration in conf.yaml to use it.
If you want to add more translation providers, they are in the translate directory, and the steps are very similar to adding new TTS or ASR providers.
- Set
TRANSLATE_AUDIOinconf.yamlto True - Set
DEEPLX_TARGET_LANGto your desired language. Make sure this language matches the language of the TTS speaker (for example, if theDEEPLX_TARGET_LANGis "JA", which is Japanese, the TTS should also be speaking Japanese.).
PortAudio Missing
- Install
libportaudio2to your computer via your package manager like apt
You can either build the image yourself or pull it from the docker hub.
- (but the image size is crazy large)
- The image on the docker hub might not updated as regularly as it can be. GitHub action can't build an image as big as this. I might look into other options.
Current issues:
- Large image size (~13GB) and will require more space because some models are optional and will be downloaded only when used.
- Nvidia GPU required (GPU passthrough limitation)
- Nvidia Container Toolkit needs to be configured for GPU passthrough.
- Some models will have to be downloaded again if you stop the container. (will be fixed)
- Don't build the image on an Arm machine. One of the dependencies (grpc, to be exact) will fail for some reason https://github.com/grpc/grpc/issues/34998.
- As mentioned before, you can't run it on a remote server unless the web page has https. That's because the web mic on the front end will only launch in a secure context (which means localhost or https environment only).
Most of the ASR and TTS will be pre-installed. However, bark TTS and the original OpenAI Whisper (Whisper, not WhisperCPP) are NOT included in the default build process because they are huge (~8GB, which makes the whole container about 25GB). In addition, they don't deliver the best performance either. To include bark and/or whisper in the image, add the argument --build-arg INSTALL_ORIGINAL_WHISPER=true --build-arg INSTALL_BARK=true to the image build command.
Setup guide:
-
Review
conf.yamlbefore building (currently burned into the image, I'm sorry): -
Build the image:
docker build -t open-llm-vtuber .
(Grab a drink, this will take a while)
-
Grab a
conf.yamlconfiguration file. Grab aconf.yamlfile from this repo. Or you can get it directly from this link. -
Run the container:
$(pwd)/conf.yaml should be the path of your conf.yaml file.
docker run -it --net=host --rm -v $(pwd)/conf.yaml:/app/conf.yaml -p 12393:12393 open-llm-vtuber
- Open localhost:12393 to test
ylxmf2005/LLM-Live2D-Desktop-Assitant
- Your Live2D desktop assistant powered by LLM! Available for both Windows and MacOS, it senses your screen, retrieves clipboard content, and responds to voice commands with a unique voice. Featuring voice wake-up, singing capabilities, and full computer control for seamless interaction with your favorite character.
(this project is in the active prototyping stage, so many things will change)
Some abbreviations used in this project:
- LLM: Large Language Model
- TTS: Text-to-speech, Speech Synthesis, Voice Synthesis
- ASR: Automatic Speech Recognition, Speech recognition, Speech to text, STT
- VAD: Voice Activation Detection
You can assume that the sample rate is 16000 throughout this project.
The frontend stream chunks of Float32Array with a sample rate of 16000 to the backend.
- Implement
TTSInterfacedefined intts/tts_interface.py. - Add your new TTS provider into
tts_factory: the factory to instantiate and return the tts instance. - Add configuration to
conf.yaml. The dict with the same name will be passed into the constructor of your TTSEngine as kwargs.
- Implement
ASRInterfacedefined inasr/asr_interface.py. - Add your new ASR provider into
asr_factory: the factory to instantiate and return the ASR instance. - Add configuration to
conf.yaml. The dict with the same name will be passed into the constructor of your class as kwargs.
- Implement
LLMInterfacedefined inllm/llm_interface.py. - Add your new LLM provider into
llm_factory: the factory to instantiate and return the LLM instance. - Add configuration to
conf.yaml. The dict with the same name will be passed into the constructor of your class as kwargs.
- Implement
TranslateInterfacedefined intranslate/translate_interface.py. - Add your new TTS provider into
translate_factory: the factory to instantiate and return the tts instance. - Add configuration to
conf.yaml. The dict with the same name will be passed into the constructor of your translator as kwargs.
Awesome projects I learned from
- https://github.com/dnhkng/GlaDOS
- https://github.com/SchwabischesBauernbrot/unsuperior-ai-waifu
- https://codepen.io/guansss/pen/oNzoNoz
- https://github.com/Ikaros-521/AI-Vtuber
- https://github.com/zixiiu/Digital_Life_Server
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Open-LLM-VTuber
Similar Open Source Tools
Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
whisper_dictation
Whisper Dictation is a fast, offline, privacy-focused tool for voice typing, AI voice chat, voice control, and translation. It allows hands-free operation, launching and controlling apps, and communicating with OpenAI ChatGPT or a local chat server. The tool also offers the option to speak answers out loud and draw pictures. It includes client and server versions, inspired by the Star Trek series, and is designed to keep data off the internet and confidential. The project is optimized for dictation and translation tasks, with voice control capabilities and AI image generation using stable-diffusion API.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.
claude.vim
Claude.vim is a Vim plugin that integrates Claude, an AI pair programmer, into your Vim workflow. It allows you to chat with Claude about what to build or how to debug problems, and Claude offers opinions, proposes modifications, or even writes code. The plugin provides a chat/instruction-centric interface optimized for human collaboration, with killer features like access to chat history and vimdiff interface. It can refactor code, modify or extend selected pieces of code, execute complex tasks by reading documentation, cloning git repositories, and more. Note that it is early alpha software and expected to rapidly evolve.

MultiPL-E
MultiPL-E is a system for translating unit test-driven neural code generation benchmarks to new languages. It is part of the BigCode Code Generation LM Harness and allows for evaluating Code LLMs using various benchmarks. The tool supports multiple versions with improvements and new language additions, providing a scalable and polyglot approach to benchmarking neural code generation. Users can access a tutorial for direct usage and explore the dataset of translated prompts on the Hugging Face Hub.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
polis
Polis is an AI powered sentiment gathering platform that offers a more organic approach than surveys and requires less effort than focus groups. It provides a comprehensive wiki, main deployment at https://pol.is, discussions, issue tracking, and project board for users. Polis can be set up using Docker infrastructure and offers various commands for building and running containers. Users can test their instance, update the system, and deploy Polis for production. The tool also provides developer conveniences for code reloading, type checking, and database connections. Additionally, Polis supports end-to-end browser testing using Cypress and offers troubleshooting tips for common Docker and npm issues.
ai-town
AI Town is a virtual town where AI characters live, chat, and socialize. This project provides a deployable starter kit for building and customizing your own version of AI Town. It features a game engine, database, vector search, auth, text model, deployment, pixel art generation, background music generation, and local inference. You can customize your own simulation by creating characters and stories, updating spritesheets, changing the background, and modifying the background music.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
For similar tasks

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

agents-flex
Agents-Flex is a LLM Application Framework like LangChain base on Java. It provides a set of tools and components for building LLM applications, including LLM Visit, Prompt and Prompt Template Loader, Function Calling Definer, Invoker and Running, Memory, Embedding, Vector Storage, Resource Loaders, Document, Splitter, Loader, Parser, LLMs Chain, and Agents Chain.
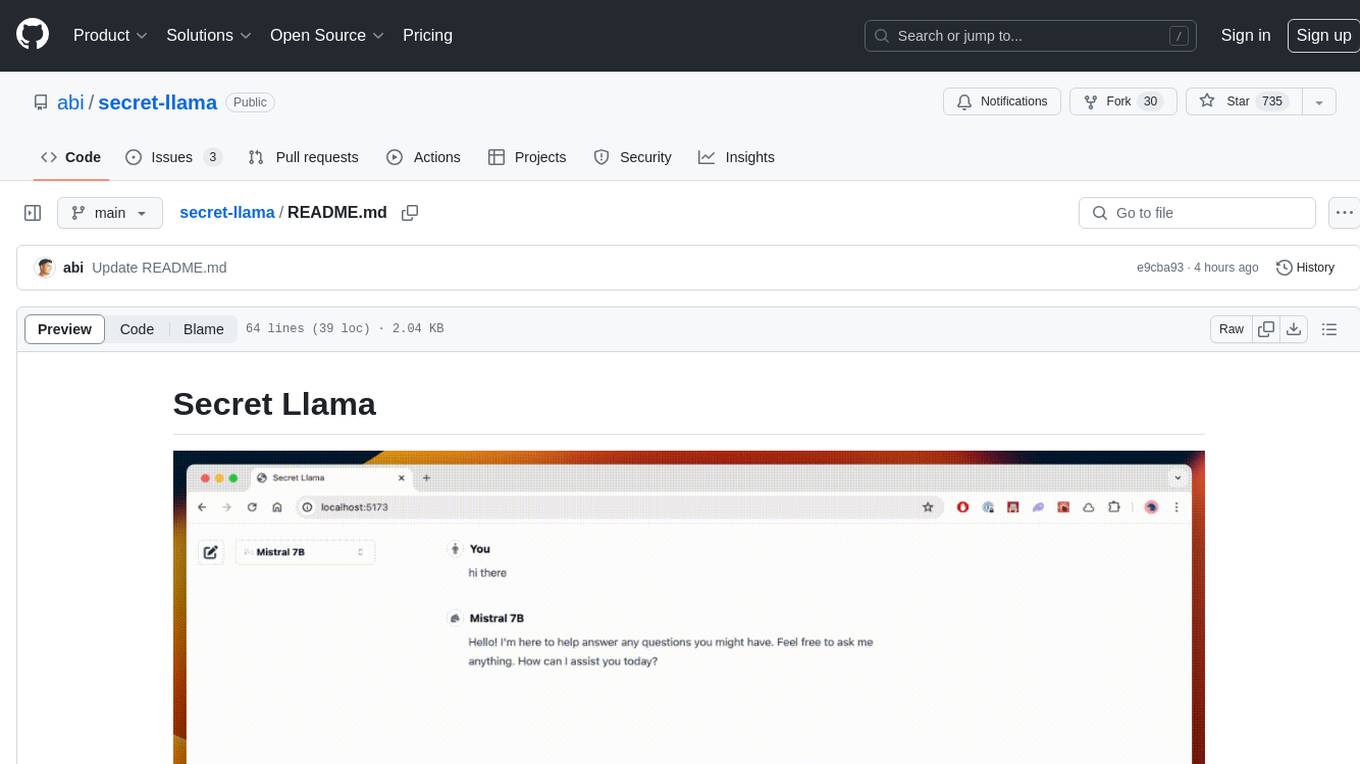
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.
Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
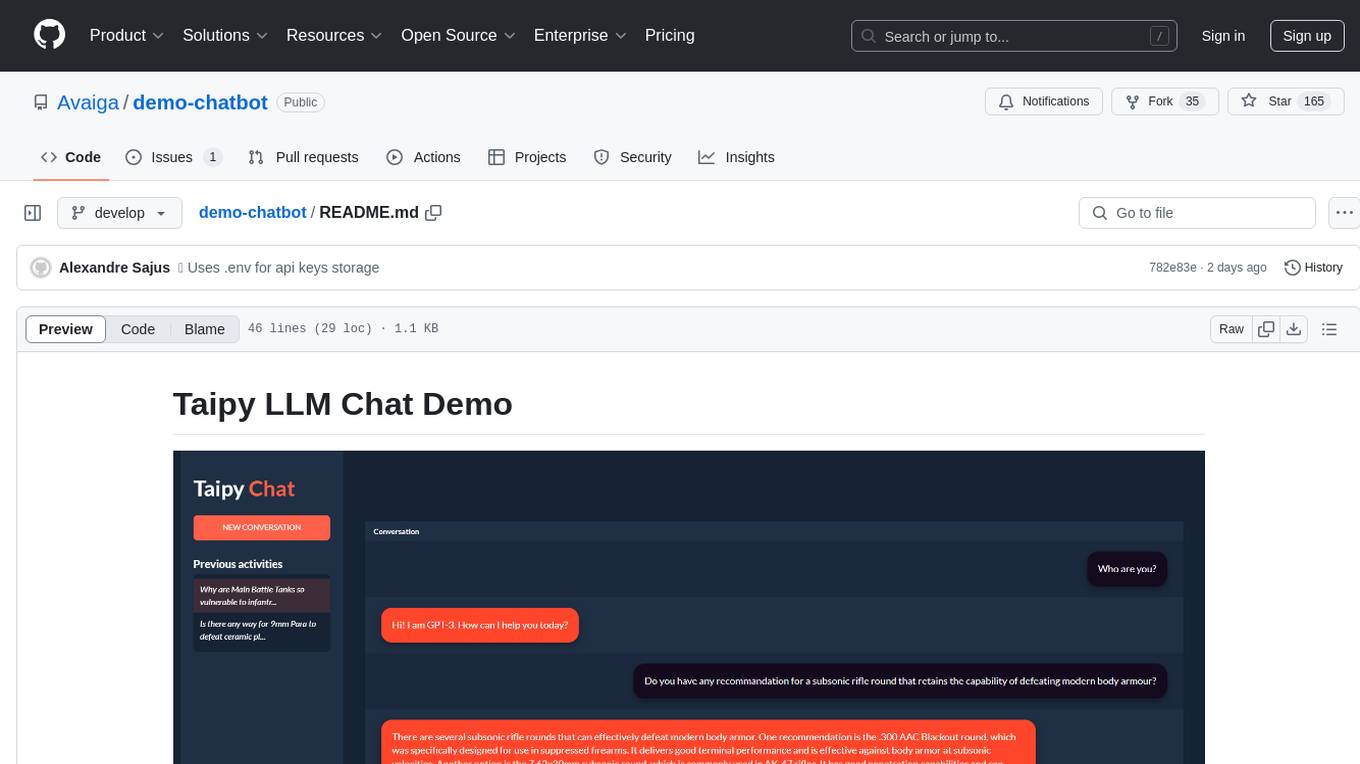
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
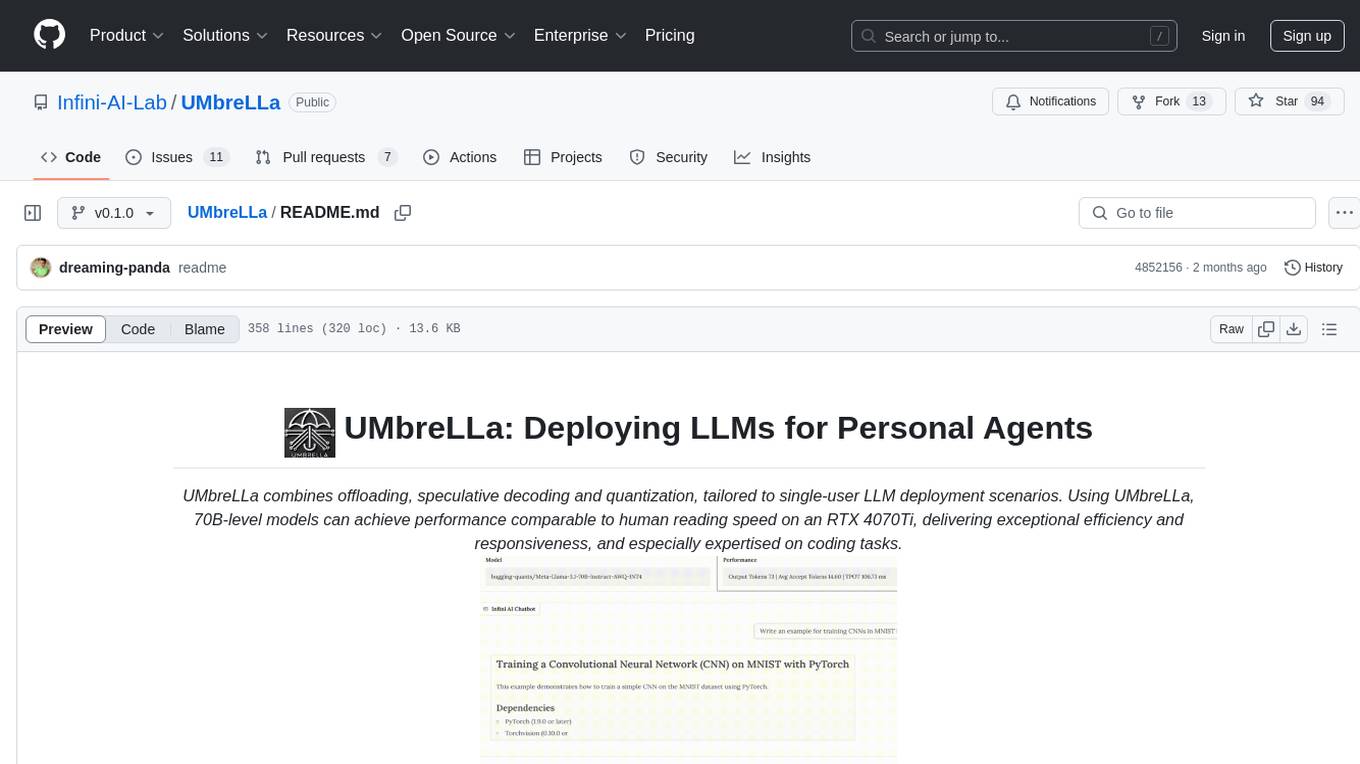
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.