
glide
🐦 A open blazing-fast simple model gateway for rapid development of production GenAI apps
Stars: 110

Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.
README:



Glide is your go-to cloud-native LLM gateway, delivering high-performance LLMOps in a lightweight, all-in-one package.
We take all problems of managing and communicating with external providers out of your applications, so you can dive into tackling your core challenges.
[!Important] Glide is under active development right now 🛠️
Give us a star⭐ to support the project and watch👀 our repositories not to miss any update. Appreciate your interest 🙏
Glide sits between your application and model providers to seamlessly handle various LLMOps tasks like model failover, caching, key management, etc.

Check out our documentation!
- Unified REST API across providers. Avoid vendor lock-in and changes in your applications when you swap model providers.
- High availability and resiliency when working with external model providers. Automatic fallbacks on provider failures, rate limits, transient errors. Smart retries to reduce communication latency.
- Support popular LLM providers.
- High performance. Performance is our priority. We want to keep Glide "invisible" for your latency-wise, while providing rich functionality.
- Production-ready observability via OpenTelemetry, emit metrics on models health, allows whitebox monitoring (coming soon)
- Straightforward and simple maintenance and configuration, centralized API key control & management & rotation, etc.
| Provider | Supported Capabilities |
|---|---|
|
|
✅ Chat ✅ Streaming Chat |
|
|
✅ Chat 🏗️ Streaming Chat (coming soon) |
|
|
✅ Chat ✅ Streaming Chat |
|
|
✅ Chat |
|
|
✅ Chat ✅ Streaming Chat |
|
|
🏗️ Chat (coming soon) |
|
|
✅ Chat |
|
|
✅ Chat |
[!Note] Windows users should follow an instruction right from the demo README file that specifies how to do the steps without the
makecommand as Windows doesn't come with it by default.
The easiest way to deploy Glide is to our demo repository and docker-compose.
git clone https://github.com/EinStack/glide-demo.gitThe demo repository comes with a basic config. Additionally, you need to init your secrets by running:
make init # from the demo rootThis will create the secrets directory with one .OPENAI_API_KEY file that you need to put your key to.
After that, just use docker compose via this command to start your demo environment:
make upSee API Reference for more details.
{
"message":
{
"role": "user",
"content": "Where was it played?"
},
"message_history": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}
]
}Finally, Glide comes with OpenAPI documentation that is accessible via http://127.0.0.1:9099/v1/swagger
That's it 🙌
Use our documentation to further learn about Glide capabilities and configs.
Other ways to install Glide are available:
brew tap einstack/tap
brew install einstack/tap/glide
snap install glideTo upgrade the already installed package, you just need to run:
snap refresh glideDetailed instruction on Snapcraft installation for different Linux distos:
- Arch
- CentOS
- Debian
- elementaryOS
- Fedora
- KDE Neon
- Kubuntu
- Manjaro
- Pop! OS
- openSUSE
- RHEL
- Ubuntu
- Raspberry Pi
Glide provides official images in our GHCR & DockerHub:
- Alpine 3.19:
docker pull ghcr.io/einstack/glide:latest-alpine - Ubuntu 22.04 LTS:
docker pull ghcr.io/einstack/glide:latest-ubuntu- Google Distroless (non-root)
docker pull ghcr.io/einstack/glide:latest-distroless- RedHat UBI 8.9 Micro
docker pull ghcr.io/einstack/glide:latest-redhatAdd the EinStack repository:
helm repo add einstack https://einstack.github.io/charts
helm repo updateBefore installing the Helm chart, you need to create a Kubernetes secret with your API keys like:
kubectl create secret generic api-keys --from-literal=OPENAI_API_KEY=sk-abcdXYZThen, you need to create a custom values.yaml file to override the secret name like:
# save as custom.values.yaml, for example
glide:
apiKeySecret: "api-keys"Finally, you should be able to install Glide's chart via:
helm upgrade glide-gateway einstack/glide --values custom.values.yaml --install
To let you work with Glide's API with ease, we are going to provide you with SDKs that fits your tech stack:
- Python (coming soon)
- NodeJS (coming soon)
Routers are a core functionality of Glide. Think of routers as a group of models with some predefined logic. For example, the resilience router allows a user to define a set of backup models should the initial model fail. Another example, would be to leverage the least-latency router to make latency sensitive LLM calls in the most efficient manner.
Detailed info on routers can be found here.
| Router | Description |
|---|---|
| Priority | When the target model fails the request is sent to the secondary model. The entire service instance keeps track of the number of failures for a specific model reducing latency upon model failure |
| Least Latency | This router selects the model with the lowest average latency over time. If the least latency model becomes unhealthy, it will pick the second the best, etc. |
| Round Robin | Split traffic equally among specified models. Great for A/B testing. |
| Weighted Round Robin | Split traffic based on weights. For example, 70% of traffic to Model A and 30% of traffic to Model B. |
- Join Discord for real-time discussion
Open an issue or start a discussion if there is a feature or an enhancement you'd like to see in Glide.
-
Maintainers
- Roman Hlushko, Software Engineer, Distributed Systems & MLOps
- Max Krueger, Data & ML Engineer
Thanks everyone for already put their effort to make Glide better and more feature-rich:
Apache 2.0

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for glide
Similar Open Source Tools
glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
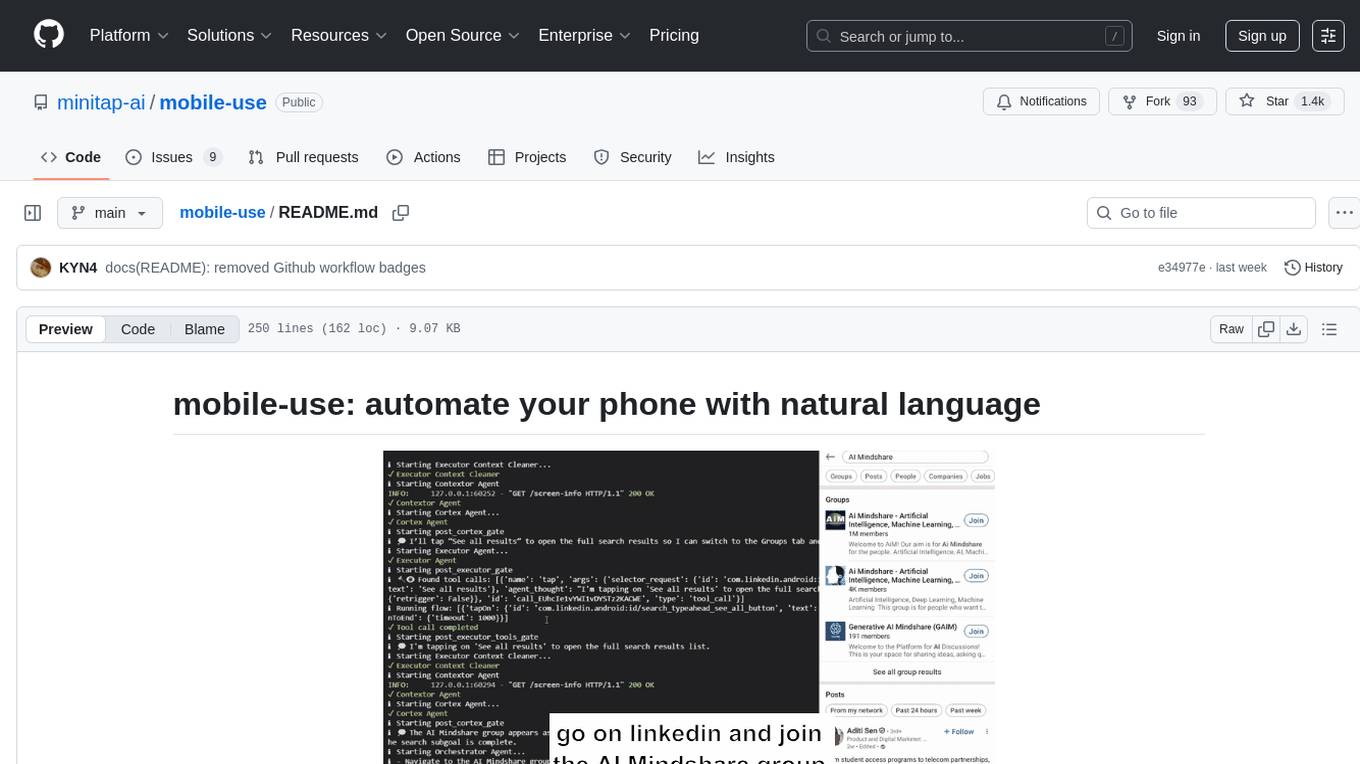
mobile-use
Mobile-use is an open-source AI agent that controls Android or IOS devices using natural language. It understands commands to perform tasks like sending messages and navigating apps. Features include natural language control, UI-aware automation, data scraping, and extensibility. Users can automate their mobile experience by setting up environment variables, customizing LLM configurations, and launching the tool via Docker or manually for development. The tool supports physical Android phones, Android simulators, and iOS simulators. Contributions are welcome, and the project is licensed under MIT.
aimeos-laravel
Aimeos Laravel is a professional, full-featured, and ultra-fast Laravel ecommerce package that can be easily integrated into existing Laravel applications. It offers a wide range of features including multi-vendor, multi-channel, and multi-warehouse support, fast performance, support for various product types, subscriptions with recurring payments, multiple payment gateways, full RTL support, flexible pricing options, admin backend, REST and GraphQL APIs, modular structure, SEO optimization, multi-language support, AI-based text translation, mobile optimization, and high-quality source code. The package is highly configurable and extensible, making it suitable for e-commerce SaaS solutions, marketplaces, and online shops with millions of vendors.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
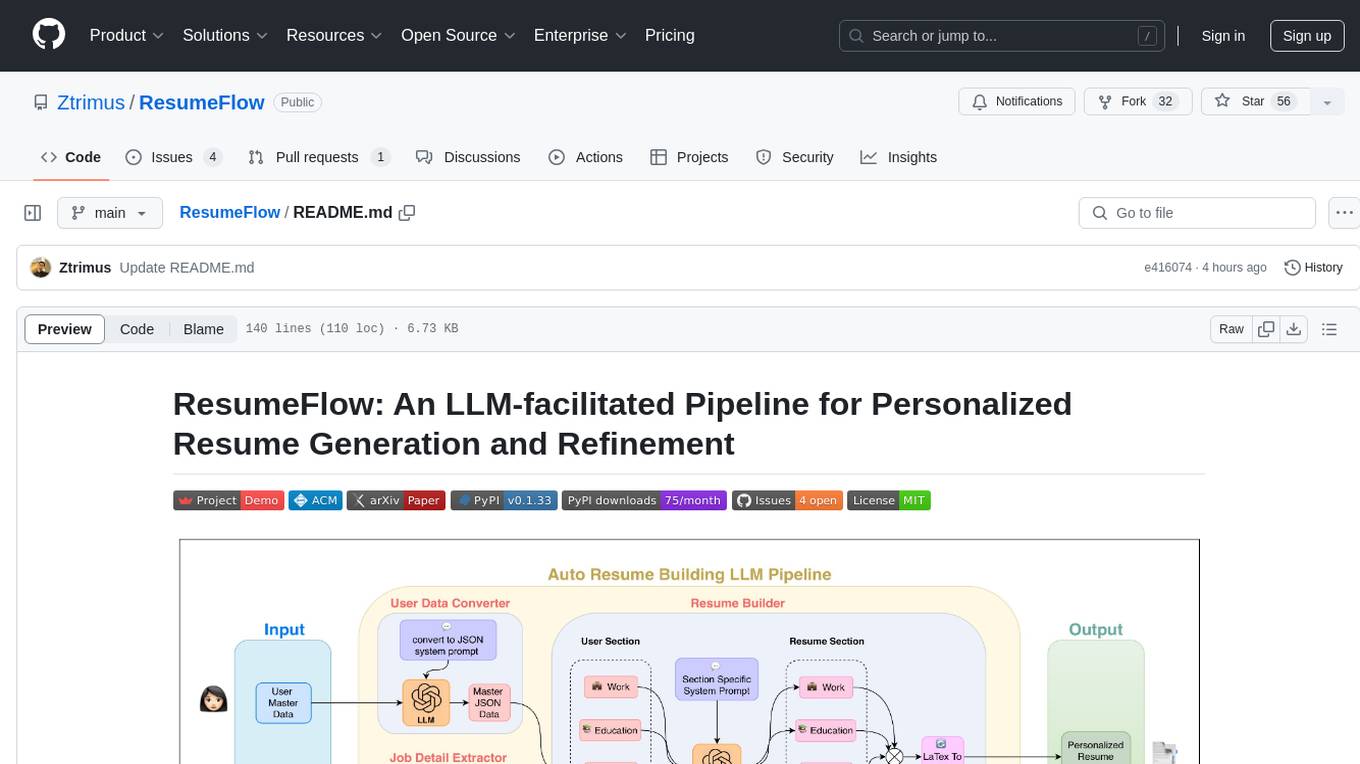
ResumeFlow
ResumeFlow is an automated system that leverages Large Language Models (LLMs) to streamline the job application process. By integrating LLM technology, the tool aims to automate various stages of job hunting, making it easier for users to apply for jobs. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code from GitHub. The tool requires Python 3.11.6 or above and an LLM API key from OpenAI or Gemini Pro for usage. ResumeFlow offers functionalities such as generating curated resumes and cover letters based on job URLs and user's master resume data.
steel-browser
Steel is an open-source browser API designed for AI agents and applications, simplifying the process of building live web agents and browser automation tools. It serves as a core building block for a production-ready, containerized browser sandbox with features like stealth capabilities, text-to-markdown session management, UI for session viewing/debugging, and full browser control through popular automation frameworks. Steel allows users to control, run, and manage a production-ready browser environment via a REST API, offering features such as full browser control, session management, proxy support, extension support, debugging tools, anti-detection mechanisms, resource management, and various browser tools. It aims to streamline complex browsing tasks programmatically, enabling users to focus on their AI applications while Steel handles the underlying complexity.
Devon
Devon is an open-source pair programmer tool designed to facilitate collaborative coding sessions. It provides features such as multi-file editing, codebase exploration, test writing, bug fixing, and architecture exploration. The tool supports Anthropic, OpenAI, and Groq APIs, with plans to add more models in the future. Devon is community-driven, with ongoing development goals including multi-model support, plugin system for tool builders, self-hostable Electron app, and setting SOTA on SWE-bench Lite. Users can contribute to the project by developing core functionality, conducting research on agent performance, providing feedback, and testing the tool.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.

preswald
Preswald is a full-stack platform for building, deploying, and managing interactive data applications in Python. It simplifies the process by combining ingestion, storage, transformation, and visualization into one lightweight SDK. With Preswald, users can connect to various data sources, customize app themes, and easily deploy apps locally. The platform focuses on code-first simplicity, end-to-end coverage, and efficiency by design, making it suitable for prototyping internal tools or deploying production-grade apps with reduced complexity and cost.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.
For similar tasks
glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

agents-flex
Agents-Flex is a LLM Application Framework like LangChain base on Java. It provides a set of tools and components for building LLM applications, including LLM Visit, Prompt and Prompt Template Loader, Function Calling Definer, Invoker and Running, Memory, Embedding, Vector Storage, Resource Loaders, Document, Splitter, Loader, Parser, LLMs Chain, and Agents Chain.
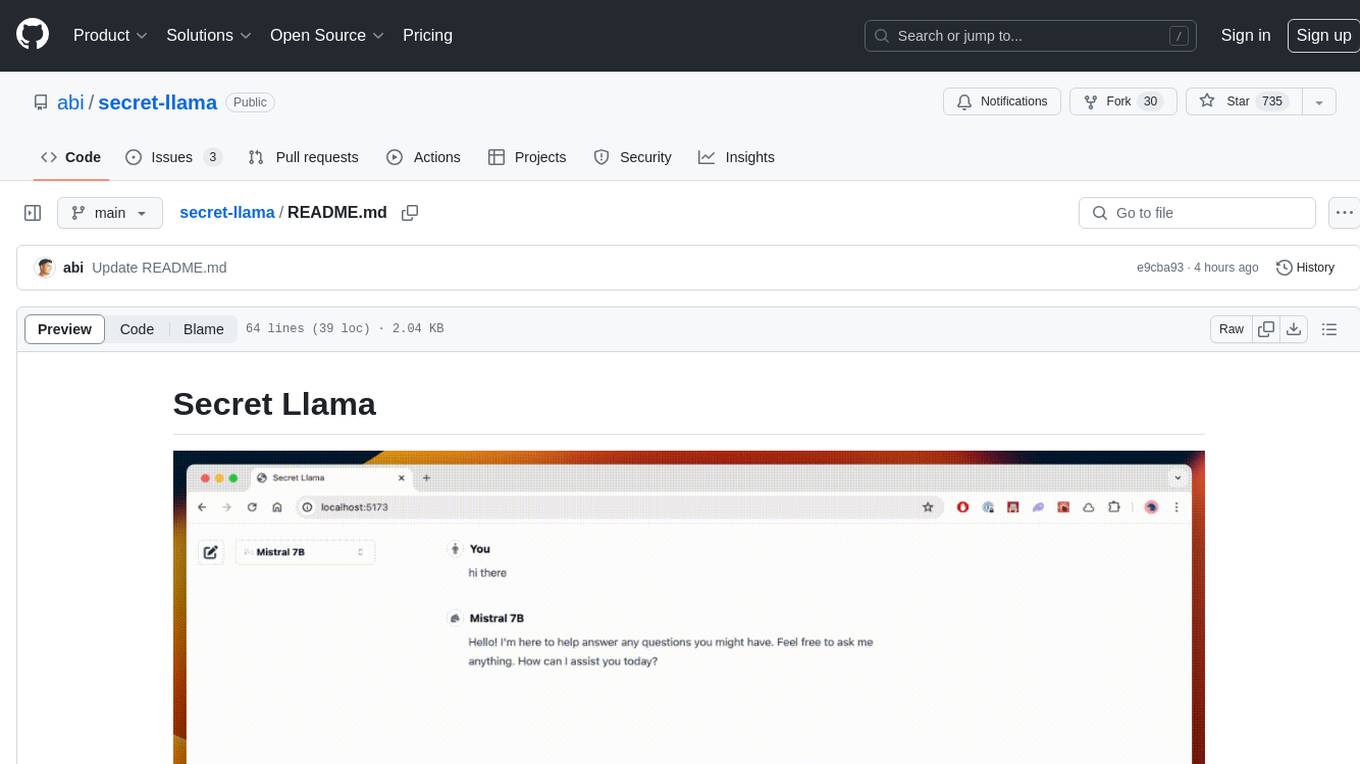
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
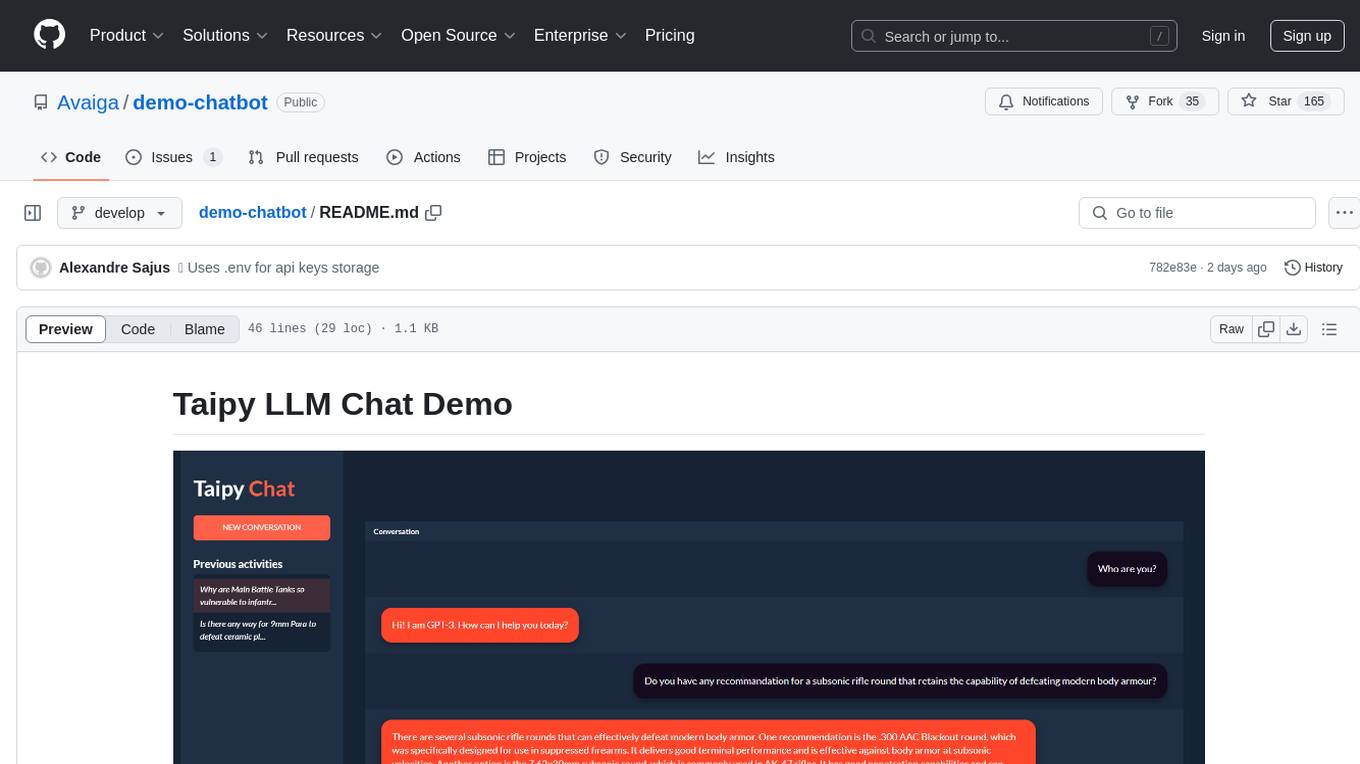
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
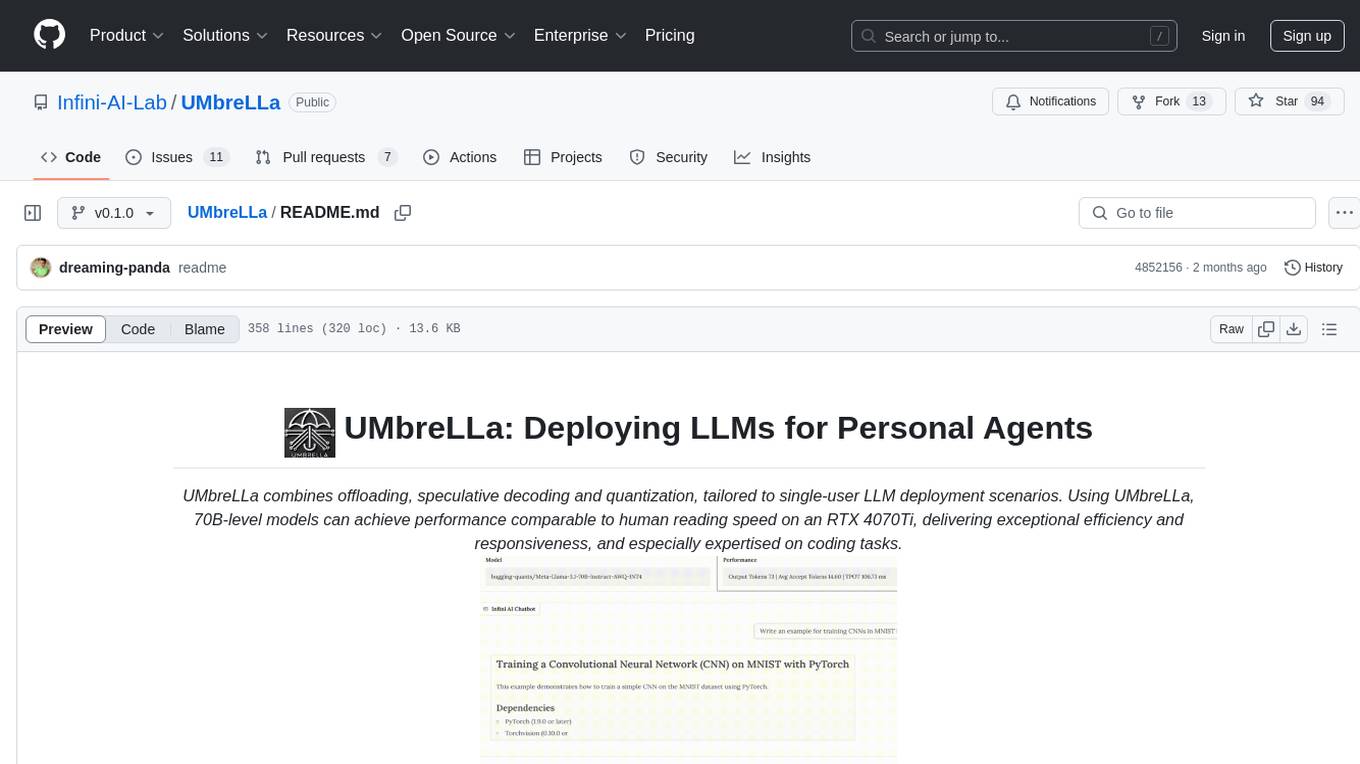
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.
glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.