
secret-llama
Fully private LLM chatbot that runs entirely with a browser with no server needed. Supports Mistral and LLama 3.
Stars: 1962
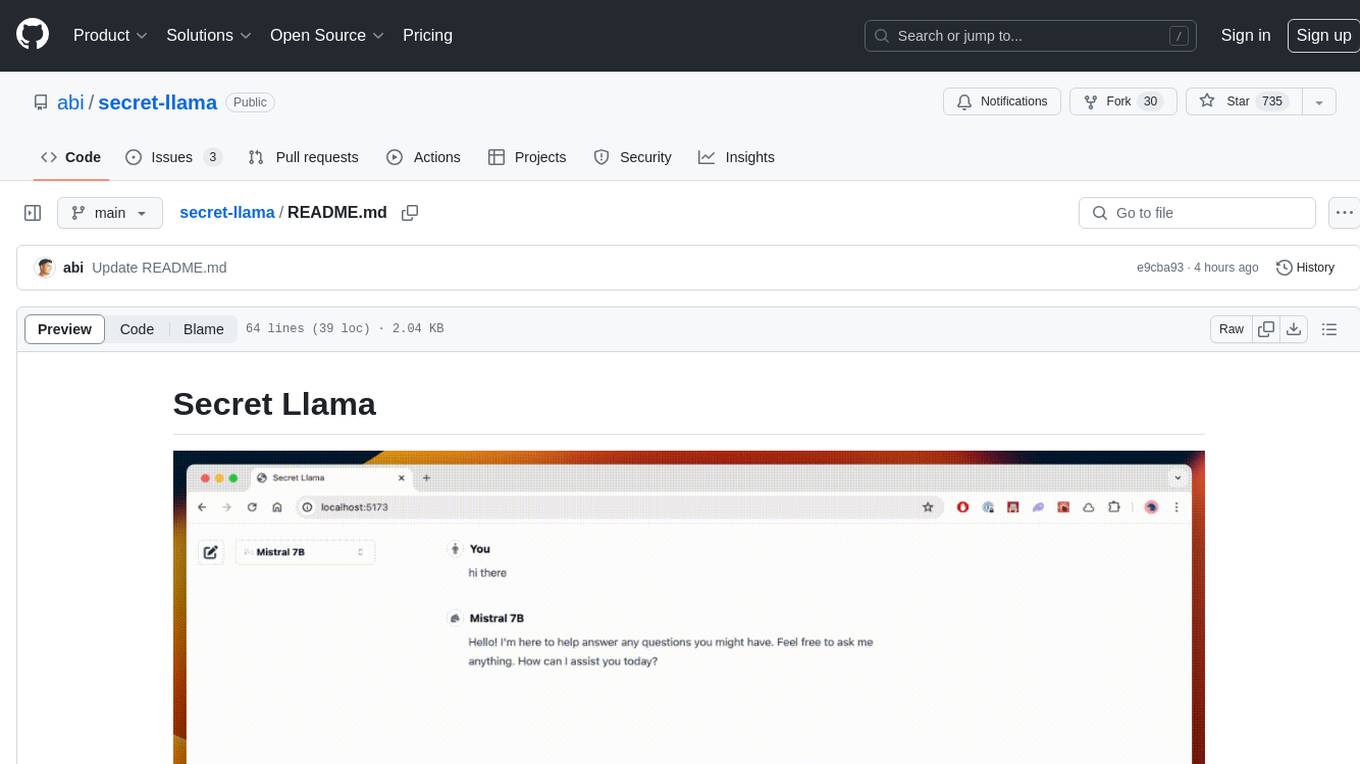
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
README:
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models.
- Fully private = No conversation data ever leaves your computer
- Runs in the browser = No server needed and no install needed!
- Works offline
- Easy-to-use interface on par with ChatGPT, but for open source LLMs
Big thanks to the inference engine provided by webllm.
Join us on Discord
To run this, you need a modern browser with support for WebGPU. According to caniuse, WebGPU is supported on:
- Google Chrome
- Microsoft Edge
It's also available in Firefox, but it needs to be enabled manually through the dom.webgpu.enabled flag. Safari on MacOS also has experimental support for WebGPU which can be enabled through the WebGPU experimental feature.
In addition to WebGPU support, various models might have specific RAM requirements.
You can try it here.
To compile the React code yourself, download the repo and then, run
yarn
yarn build-and-preview
If you're looking to make changes, run the development environment with live reload:
yarn
yarn dev
| Model | Model Size |
|---|---|
| TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k | 600MB |
| Llama-3-8B-Instruct-q4f16_1 ⭐ | 4.3GB |
| Phi1.5-q4f16_1-1k | 1.2GB |
| Mistral-7B-Instruct-v0.2-q4f16_1 ⭐ | 4GB |
We would love contributions to improve the interface, support more models, speed up initial model loading time and fix bugs.
Check out screenshot to code and Pico - AI-powered app builder
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for secret-llama
Similar Open Source Tools
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.
raycast-g4f
Raycast-G4F is a free extension that allows users to leverage powerful AI models such as GPT-4 and Llama-3 within the Raycast app without the need for an API key. The extension offers features like streaming support, diverse commands, chat interaction with AI, web search capabilities, file upload functionality, image generation, and custom AI commands. Users can easily install the extension from the source code and benefit from frequent updates and a user-friendly interface. Raycast-G4F supports various providers and models, each with different capabilities and performance ratings, ensuring a versatile AI experience for users.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

Follow
Follow is a content organization tool that creates a noise-free timeline for users, allowing them to share lists, explore collections, and browse distraction-free. It offers features like subscribing to feeds, AI-powered browsing, dynamic content support, an ownership economy with $POWER tipping, and a community-driven experience. Follow is under active development and welcomes feedback from users and developers. It can be accessed via web app or desktop client and offers installation methods for different operating systems. The tool aims to provide a customized information hub, AI-powered browsing experience, and support for various types of content, while fostering a community-driven and open-source environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.
OpenHands
OpenHands is a community focused on AI-driven development, offering a Software Agent SDK, CLI, Local GUI, Cloud deployment, and Enterprise solutions. The SDK is a Python library for defining and running agents, the CLI provides an easy way to start using OpenHands, the Local GUI allows running agents on a laptop with REST API, the Cloud deployment offers hosted infrastructure with integrations, and the Enterprise solution enables self-hosting via Kubernetes with extended support and access to the research team. OpenHands is available under the MIT license.
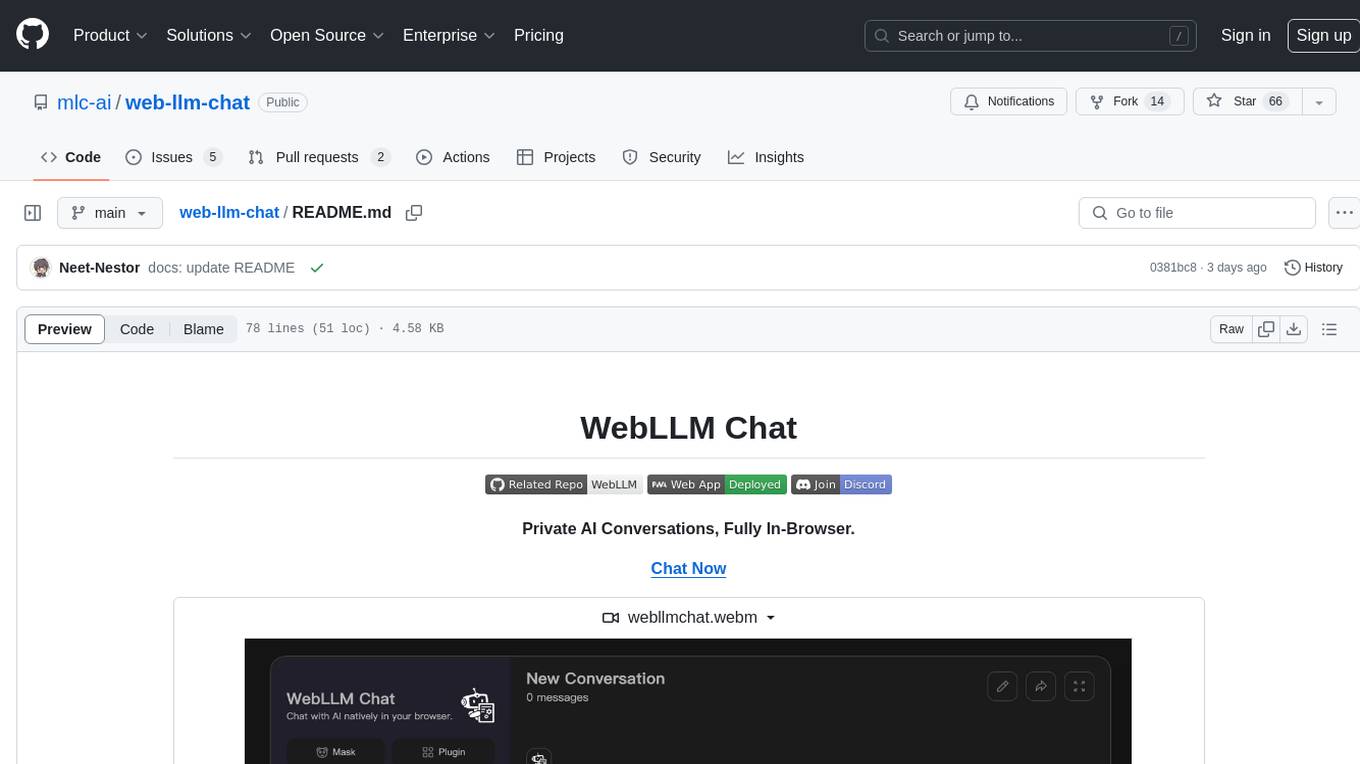
web-llm-chat
WebLLM Chat is a private AI chat interface that combines WebLLM with a user-friendly design, leveraging WebGPU to run large language models natively in your browser. It offers browser-native AI experience with WebGPU acceleration, guaranteed privacy as all data processing happens locally, offline accessibility, user-friendly interface with markdown support, and open-source customization. The project aims to democratize AI technology by making powerful tools accessible directly to end-users, enhancing the chatting experience and broadening the scope for deployment of self-hosted and customizable language models.

second-brain-ai-assistant-course
This open-source course teaches how to build an advanced RAG and LLM system using LLMOps and ML systems best practices. It helps you create an AI assistant that leverages your personal knowledge base to answer questions, summarize documents, and provide insights. The course covers topics such as LLM system architecture, pipeline orchestration, large-scale web crawling, model fine-tuning, and advanced RAG features. It is suitable for ML/AI engineers and data/software engineers & data scientists looking to level up to production AI systems. The course is free, with minimal costs for tools like OpenAI's API and Hugging Face's Dedicated Endpoints. Participants will build two separate Python applications for offline ML pipelines and online inference pipeline.
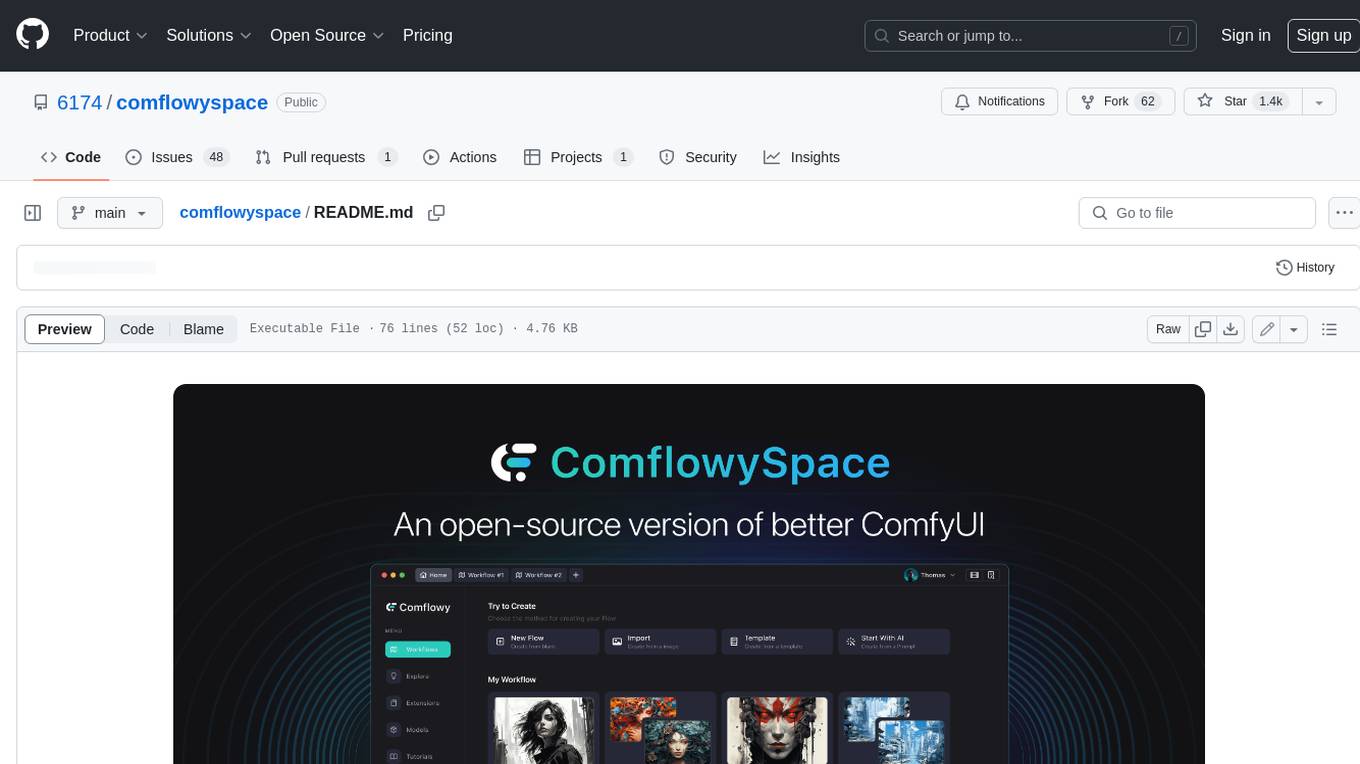
comflowyspace
Comflowyspace is an open-source AI image and video generation tool that aims to provide a more user-friendly and accessible experience than existing tools like SDWebUI and ComfyUI. It simplifies the installation, usage, and workflow management of AI image and video generation, making it easier for users to create and explore AI-generated content. Comflowyspace offers features such as one-click installation, workflow management, multi-tab functionality, workflow templates, and an improved user interface. It also provides tutorials and documentation to lower the learning curve for users. The tool is designed to make AI image and video generation more accessible and enjoyable for a wider range of users.

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.
crawlchat
CrawlChat is an open sourced AI-powered platform that transforms technical documentation into intelligent chatbots. It allows users to connect documentation from various sources and deploy AI assistants that can answer questions across multiple channels. The platform includes services like front-facing React app, Express app, Discord bot, Slack app, and more. Users can self-host the platform using Dockerfiles and set up environment variables for easy deployment. Local development is quick and easy, allowing users to contribute by starting the necessary services and making improvements or adding features.
Ollama-SwiftUI
Ollama-SwiftUI is a user-friendly interface for Ollama.ai created in Swift. It allows seamless chatting with local Large Language Models on Mac. Users can change models mid-conversation, restart conversations, send system prompts, and use multimodal models with image + text. The app supports managing models, including downloading, deleting, and duplicating them. It offers light and dark mode, multiple conversation tabs, and a localized interface in English and Arabic.
wingman-ai
Wingman-AI is a free and open-source AI coding assistant that brings high-quality AI-assisted coding right to your computer. It offers features such as code completion, interactive chat, and support for multiple AI providers, including Ollama, Hugging Face, and OpenAI. Wingman-AI is designed to enhance your coding workflow by providing real-time assistance and suggestions, making it an ideal tool for developers of all levels.
Transtation-KMP
Transtation is an easy-to-use and powerful translation software for Android/Desktop based on Kotlin Multiplatform + Compose Multiplatform. It allows users to translate one item using multiple engines simultaneously, utilize advanced Large Language Models for translation, chat with LLMs for translation, translate long text, support plugin development, image translation, and screen translation. The application is designed for Chinese users and serves as a reference for learning Jetpack Compose or Compose Multiplatform. It features Kotlin Multiplatform, Compose Multiplatform, MVVM, Kotlin Coroutine, Flow, SqlDelight, synchronized translation with multiple engines, plugin development, and makes use of Kotlin language features like lazy loading, Coroutine, sealed classes, and reflection. The application gradually adapts to Android13 with features like setting application language separately and supporting Monet icon.
For similar tasks
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

agents-flex
Agents-Flex is a LLM Application Framework like LangChain base on Java. It provides a set of tools and components for building LLM applications, including LLM Visit, Prompt and Prompt Template Loader, Function Calling Definer, Invoker and Running, Memory, Embedding, Vector Storage, Resource Loaders, Document, Splitter, Loader, Parser, LLMs Chain, and Agents Chain.
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
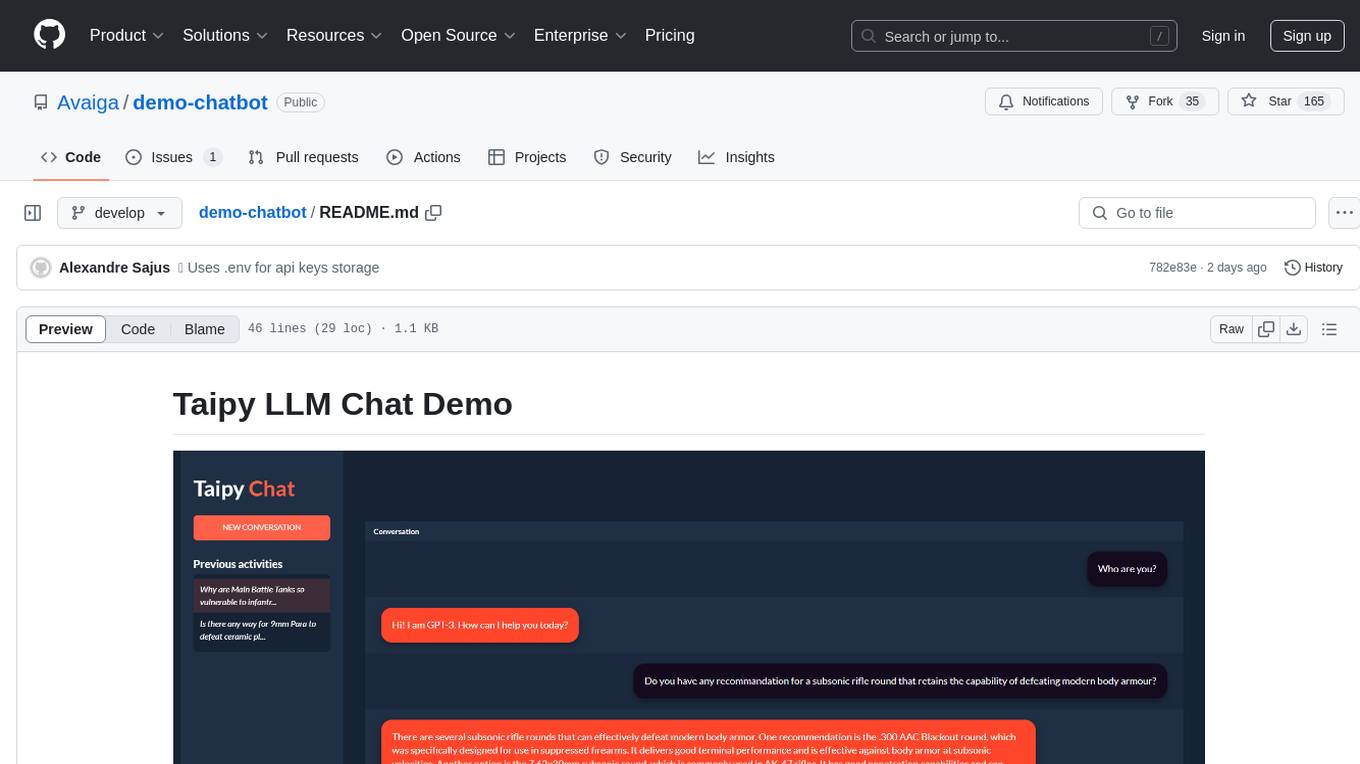
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.