
shellgpt
Chat with LLM in your terminal, be it shell generator, story teller, linux-terminal, etc.
Stars: 60
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.
README:

![]()
![]()
Chat with LLM in your terminal, be it shell generator, story teller, linux-terminal, etc.
pip install -U shgptOr install latest version
pip install --force-reinstall -U git+https://github.com/jiacai2050/shellgpt.gitThis will install two commands: sg and shellgpt, which are identical.
After install, use sg --init to create required directories(mainly ~/.shellgpt).
ShellGPT has three modes to use:
- Direct mode,
sg [question]or pipeline likeecho question | sg. - REPL mode,
sg -r, chat with LLM. - TUI mode,
sg -t, tailored for infer shell command.
By default, shellgpt uses Ollama as its language model backend, requiring installation prior to usage.
Alternatively, one can set up shellgpt to utilize OpenAI compatible API endpoints:
export SHELLGPT_API_URL=https://api.openai.com
export SHELLGPT_API_KEY=<token>
export SHELLGPT_MODEL='gpt-3.5-turbo'
# or Cloudflare Worker AI
export SHELLGPT_API_URL=https://api.cloudflare.com/client/v4/accounts/<account-id>/ai
export SHELLGPT_API_KEY=<token>
export SHELLGPT_MODEL='@cf/meta/llama-3-8b-instruct'See conf.py for more configs.
There are 3 key bindings to use in TUI:
-
ctrl+j, Infer answer -
ctrl+r, Run command -
ctrl+y, Yank command

There are some built-in system contents in shellgpt:
-
default, used for ask general questions -
typo, used for correct article typos. -
slug, used for generate URL slug. -
code, used for ask programming questions -
shell, used for infer shell command -
commit, used for generate git commit message, likegit diff | sg -c commit
Users can define their own content in ~/.shellgpt/contents.json, it a JSON map with
- key being content name and
- value being content body
Or you can just copy contents.json to play with, it's generated from Awesome ChatGPT Prompts.
$ sg -c linux-terminal pwd
/home/user
$ sg -c javascript-console 0.1 + 0.2
0.3
Users can share their customized contents in discuss section.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for shellgpt
Similar Open Source Tools
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.

termax
Termax is an LLM agent in your terminal that converts natural language to commands. It is featured by: - Personalized Experience: Optimize the command generation with RAG. - Various LLMs Support: OpenAI GPT, Anthropic Claude, Google Gemini, Mistral AI, and more. - Shell Extensions: Plugin with popular shells like `zsh`, `bash` and `fish`. - Cross Platform: Able to run on Windows, macOS, and Linux.
gpt-cli
gpt-cli is a command-line interface tool for interacting with various chat language models like ChatGPT, Claude, and others. It supports model customization, usage tracking, keyboard shortcuts, multi-line input, markdown support, predefined messages, and multiple assistants. Users can easily switch between different assistants, define custom assistants, and configure model parameters and API keys in a YAML file for easy customization and management.

debug-gym
debug-gym is a text-based interactive debugging framework designed for debugging Python programs. It provides an environment where agents can interact with code repositories, use various tools like pdb and grep to investigate and fix bugs, and propose code patches. The framework supports different LLM backends such as OpenAI, Azure OpenAI, and Anthropic. Users can customize tools, manage environment states, and run agents to debug code effectively. debug-gym is modular, extensible, and suitable for interactive debugging tasks in a text-based environment.
llm-ollama
LLM-ollama is a plugin that provides access to models running on an Ollama server. It allows users to query the Ollama server for a list of models, register them with LLM, and use them for prompting, chatting, and embedding. The plugin supports image attachments, embeddings, JSON schemas, async models, model aliases, and model options. Users can interact with Ollama models through the plugin in a seamless and efficient manner.
PolyMind
PolyMind is a multimodal, function calling powered LLM webui designed for various tasks such as internet searching, image generation, port scanning, Wolfram Alpha integration, Python interpretation, and semantic search. It offers a plugin system for adding extra functions and supports different models and endpoints. The tool allows users to interact via function calling and provides features like image input, image generation, and text file search. The application's configuration is stored in a `config.json` file with options for backend selection, compatibility mode, IP address settings, API key, and enabled features.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.
MindSearch
MindSearch is an open-source AI Search Engine Framework that mimics human minds to provide deep AI search capabilities. It allows users to deploy their own search engine using either close-source or open-source language models. MindSearch offers features such as answering any question using web knowledge, in-depth knowledge discovery, detailed solution paths, optimized UI experience, and dynamic graph construction process.

chat-ai
A Seamless Slurm-Native Solution for HPC-Based Services. This repository contains the stand-alone web interface of Chat AI, which can be set up independently to act as a wrapper for an OpenAI-compatible API endpoint. It consists of two Docker containers, 'front' and 'back', providing a ReactJS app served by ViteJS and a wrapper for message requests to prevent CORS errors. Configuration files allow setting port numbers, backend paths, models, user data, default conversation settings, and more. The 'back' service interacts with an OpenAI-compatible API endpoint using configurable attributes in 'back.json'. Customization options include creating a path for available models and setting the 'modelsPath' in 'front.json'. Acknowledgements to contributors and the Chat AI community are included.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.
qsv
qsv is a command line program for querying, slicing, indexing, analyzing, filtering, enriching, transforming, sorting, validating, joining, formatting & converting tabular data (CSV, spreadsheets, DBs, parquet, etc). Commands are simple, composable & 'blazing fast'. It is a blazing-fast data-wrangling toolkit with a focus on speed, processing very large files, and being a complete data-wrangling toolkit. It is designed to be portable, easy to use, secure, and easy to contribute to. qsv follows the RFC 4180 CSV standard, requires UTF-8 encoding, and supports various file formats. It has extensive shell completion support, automatic compression/decompression using Snappy, and supports environment variables and dotenv files. qsv has a comprehensive test suite and is dual-licensed under MIT or the UNLICENSE.
turnkeyml
TurnkeyML is a tools framework that integrates models, toolchains, and hardware backends to simplify the evaluation and actuation of deep learning models. It supports use cases like exporting ONNX files, performance validation, functional coverage measurement, stress testing, and model insights analysis. The framework consists of analysis, build, runtime, reporting tools, and a models corpus, seamlessly integrated to provide comprehensive functionality with simple commands. Extensible through plugins, it offers support for various export and optimization tools and AI runtimes. The project is actively seeking collaborators and is licensed under Apache 2.0.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
For similar tasks

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

agents-flex
Agents-Flex is a LLM Application Framework like LangChain base on Java. It provides a set of tools and components for building LLM applications, including LLM Visit, Prompt and Prompt Template Loader, Function Calling Definer, Invoker and Running, Memory, Embedding, Vector Storage, Resource Loaders, Document, Splitter, Loader, Parser, LLMs Chain, and Agents Chain.
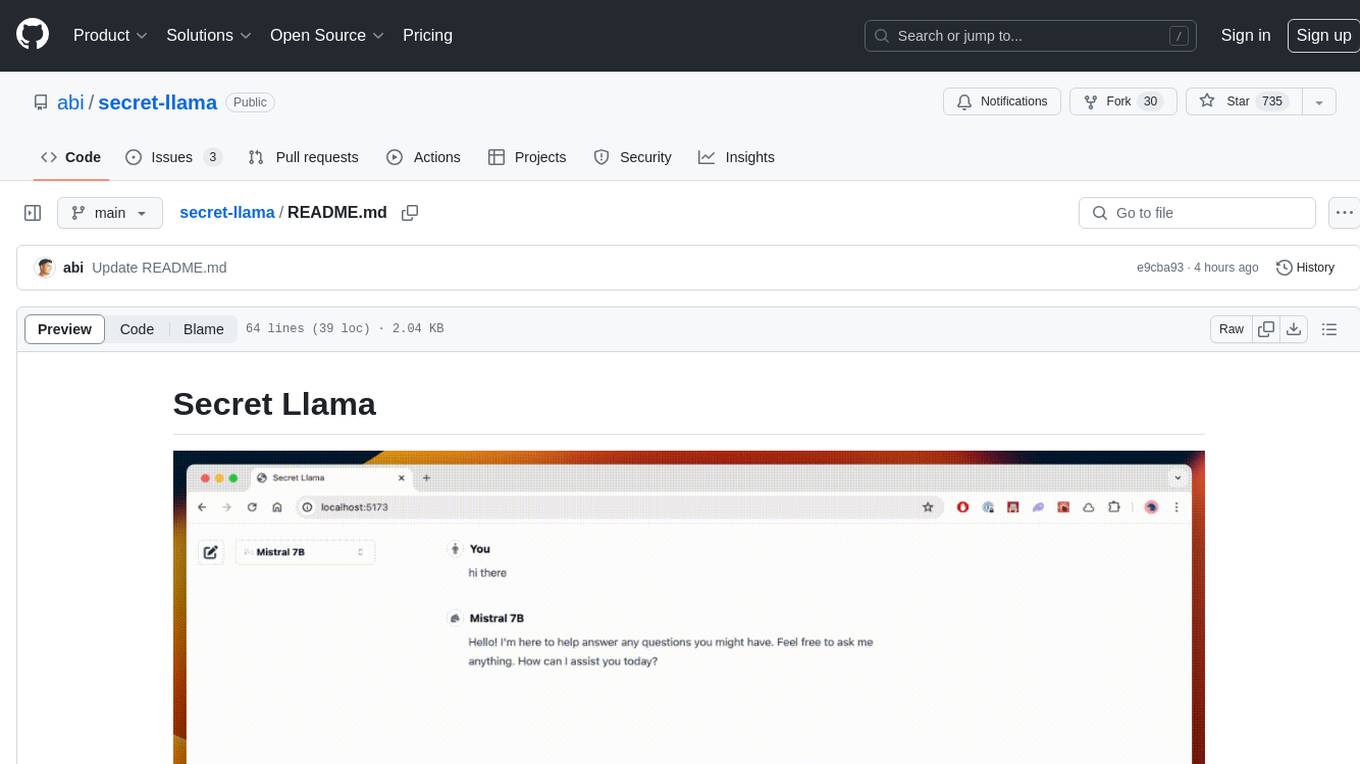
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
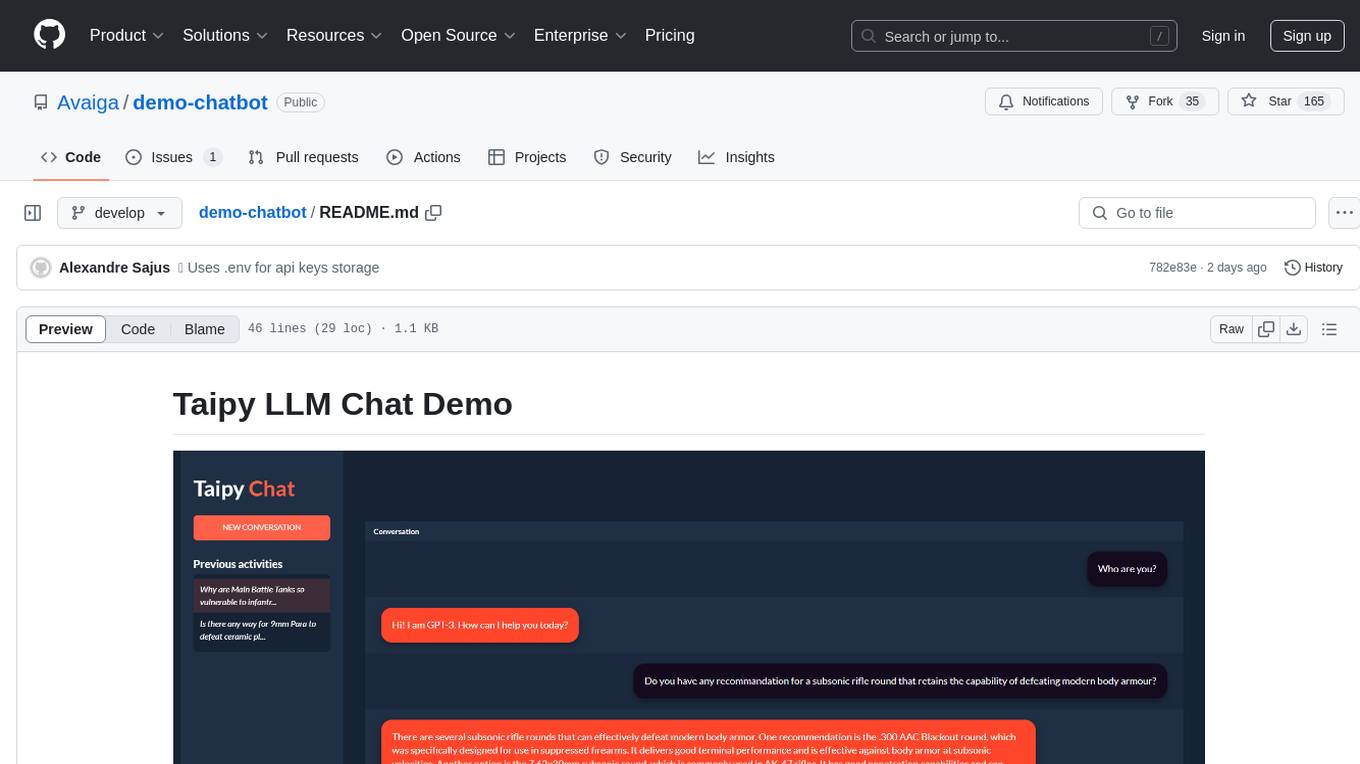
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
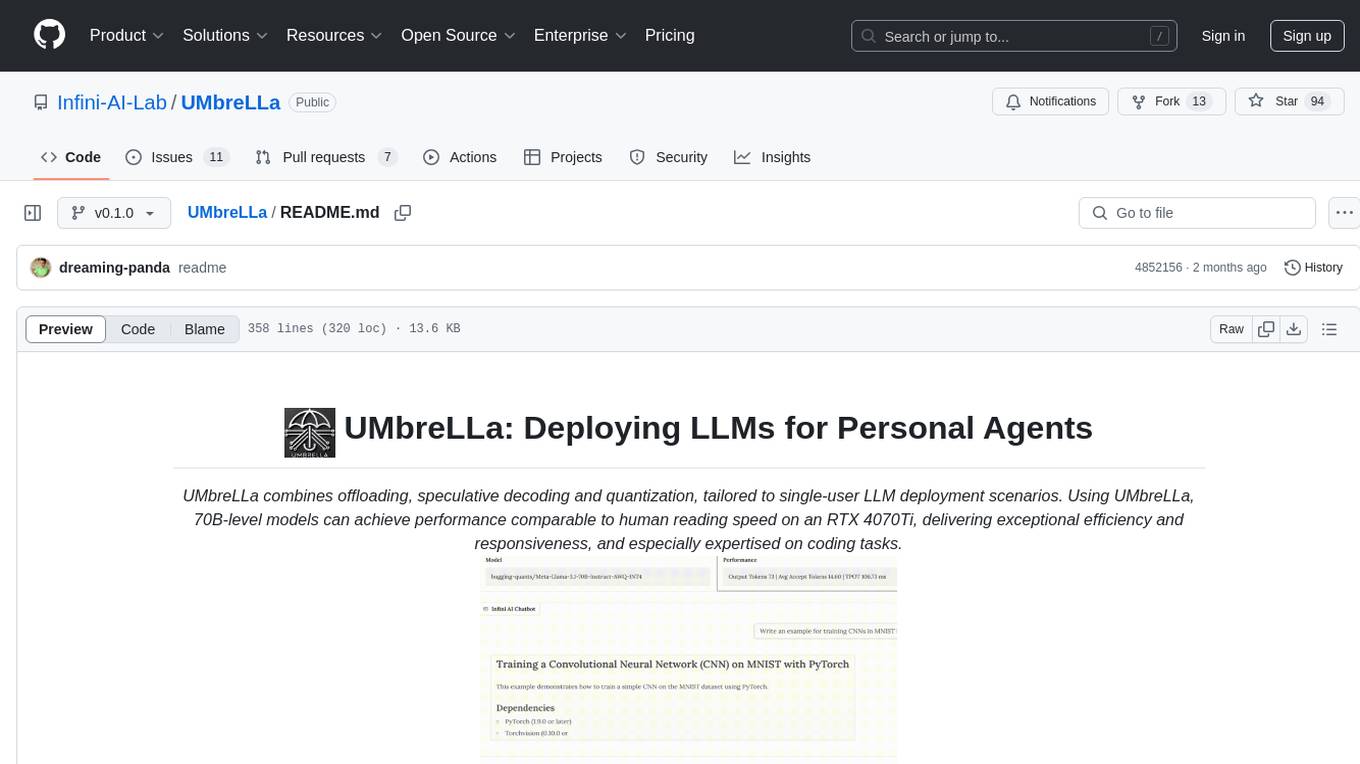
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.