
demo-chatbot
A template to create any LLM Inference Web Apps using Python only
Stars: 165
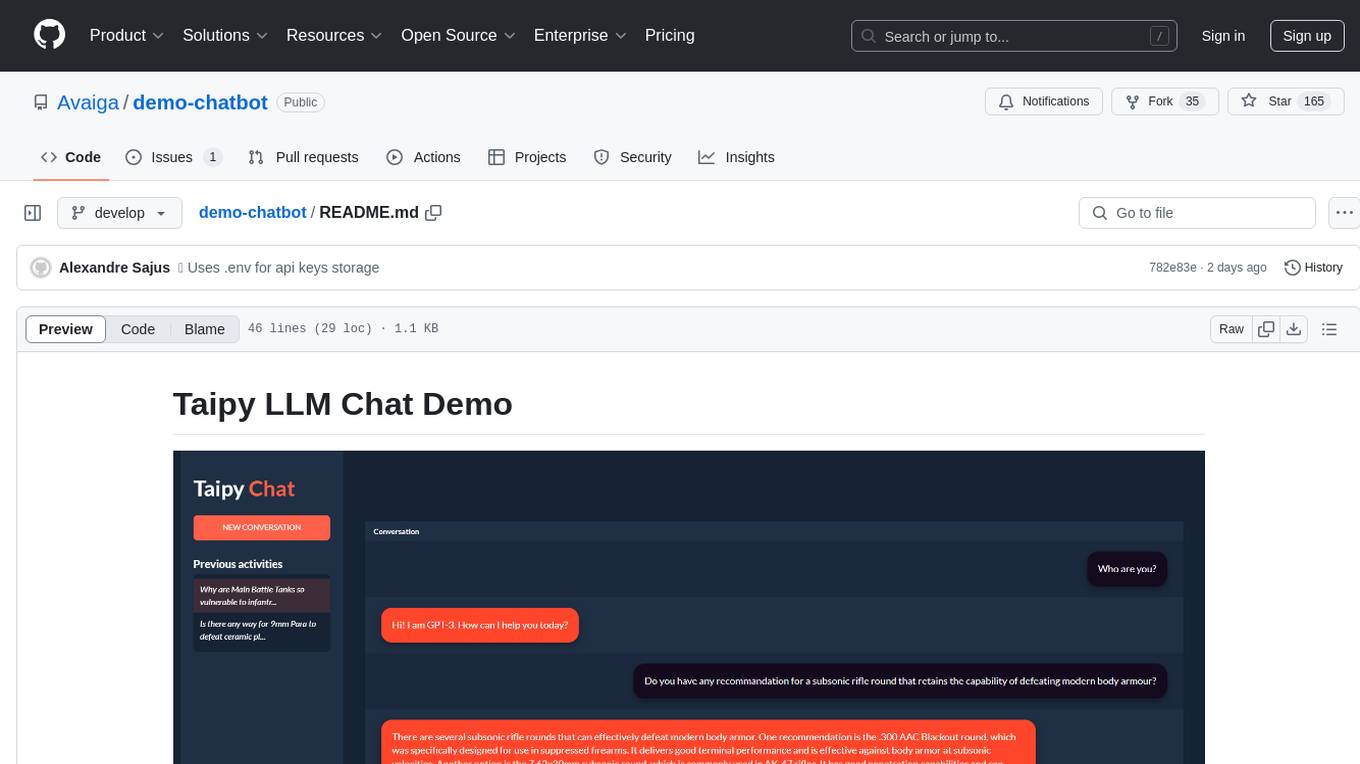
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
README:

A simple app to chat with an LLM which can be used to create any LLM Inference Web Apps using Python only.
This particular app uses OpenAI's GPT-4 API to generate responses to your messages. You can easily change the code to use any other API or model.
A tutorial on how to create this app is available in the Taipy documentation

You need an OpenAI account with an active API key
- Clone this repo:
git clone https://github.com/Avaiga/demo-llm-chat.git- Install dependencies:
pip install -r requirements.txt- Create a
.envfile in the root directory with the following content:
OPENAI_API_KEY=sk-...- Run the app:
python main.pyFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for demo-chatbot
Similar Open Source Tools
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.

dataherald
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over structured data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to: * Allow business users to get insights from the data warehouse without going through a data analyst * Enable Q+A from your production DBs inside your SaaS application * Create a ChatGPT plug-in from your proprietary data
azure-ai-foundry-baseline
This repository serves as a reference implementation for running a chat application and an AI orchestration layer using Azure AI Foundry Agent service and OpenAI foundation models. It covers common generative AI chat application characteristics such as creating agents, querying data stores, chat memory database, orchestration logic, and calling language models. The implementation also includes production requirements like network isolation, Azure AI Foundry Agent Service dependencies, availability zone reliability, and limiting egress network traffic with Azure Firewall.
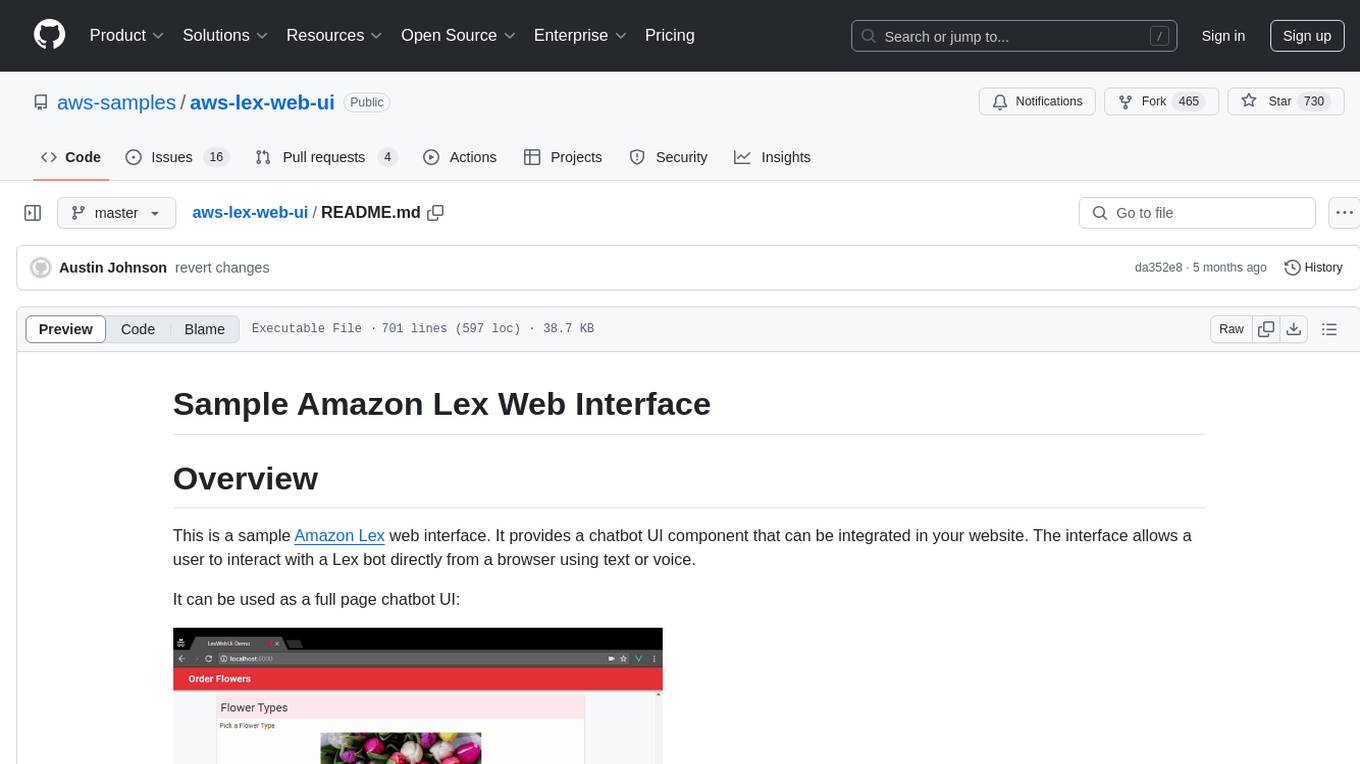
aws-lex-web-ui
The AWS Lex Web UI is a sample Amazon Lex web interface that provides a chatbot UI component for integration into websites. It supports voice and text interactions, Lex response cards, and programmable configuration using JavaScript. The interface can be used as a full-page chatbot UI or embedded as a widget. It offers mobile-ready responsive UI, seamless voice-text switching, and interactive messaging support. The project includes CloudFormation templates for easy deployment and customization. Users can modify configurations, integrate the UI into existing sites, and deploy using various methods like CloudFormation, pre-built libraries, or npm installation.
github-pr-summary
github-pr-summary is a bot designed to summarize GitHub Pull Requests, helping open source contributors make faster decisions. It automatically summarizes commits and changed files in PRs, triggered by new commits or a magic trigger phrase. Users can deploy their own code review bot in 3 steps: create a bot from their GitHub repo, configure it to review PRs, and connect to GitHub for access to the target repo. The bot runs on flows.network using Rust and WasmEdge Runtimes. It utilizes ChatGPT/4 to review and summarize PR content, posting the result back as a comment on the PR. The bot can be used on multiple repos by creating new flows and importing the source code repo, specifying the target repo using flow config. Users can also change the magic phrase to trigger a review from a PR comment.
characterfile
The Characterfile project aims to create a simple format for generating and transmitting character files, compatible with Eliza and other LLM agents. Users can convert their Twitter archive into a character file using the provided scripts. The project also includes examples, JSON schema, and TypeScript types for the character file. Scripts like tweets2character, folder2knowledge, and knowledge2character facilitate the conversion of tweets, documents, and knowledge files into character files for use with AI agents.
obsidian-ollama-chat
Obsidian Ollama Chat is a plugin that enables users to interact with their local LLM (Large Language Model) to ask questions about their own notes. The plugin facilitates running a lightweight python server for indexing notes, allowing users to set a model URL, index files on startup and modification, and open a modal to ask questions. Future plans include text streaming for querying, a chat window for communication, and commands for quick queries like summarizing notes or topics.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.
aws-ai-stack
AWS AI Stack is a full-stack boilerplate project designed for building serverless AI applications on AWS. It provides a trusted AWS foundation for AI apps with access to powerful LLM models via Bedrock. The architecture is serverless, ensuring cost-efficiency by only paying for usage. The project includes features like AI Chat & Streaming Responses, Multiple AI Models & Data Privacy, Custom Domain Names, API & Event-Driven architecture, Built-In Authentication, Multi-Environment support, and CI/CD with Github Actions. Users can easily create AI Chat bots, authentication services, business logic, and async workers using AWS Lambda, API Gateway, DynamoDB, and EventBridge.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.
agents-js
LiveKit Agents for Node.js is a framework designed for building realtime, programmable voice agents that can see, hear, and understand. It includes support for OpenAI Realtime API, allowing for ultra-low latency WebRTC transport between GPT-4o and users' devices. The framework provides concepts like Agents, Workers, and Plugins to create complex tasks. It offers a CLI interface for running agents and a versatile web frontend called 'playground' for building and testing agents. The framework is suitable for developers looking to create conversational voice agents with advanced capabilities.
alexa-skill-llm-intent
An Alexa Skill template that provides a ready-to-use skill for starting a conversation with an AI. Users can ask questions and receive answers in Alexa's voice, powered by ChatGPT or other llm. The template includes setup instructions for configuring the AI provider API and model, as well as usage commands for interacting with the skill. It serves as a starting point for creating custom Alexa Skills and should be used at the user's own risk.
langgraph-studio
LangGraph Studio is a specialized agent IDE that enables visualization, interaction, and debugging of complex agentic applications. It offers visual graphs and state editing to better understand agent workflows and iterate faster. Users can collaborate with teammates using LangSmith to debug failure modes. The tool integrates with LangSmith and requires Docker installed. Users can create and edit threads, configure graph runs, add interrupts, and support human-in-the-loop workflows. LangGraph Studio allows interactive modification of project config and graph code, with live sync to the interactive graph for easier iteration on long-running agents.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
For similar tasks

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

agents-flex
Agents-Flex is a LLM Application Framework like LangChain base on Java. It provides a set of tools and components for building LLM applications, including LLM Visit, Prompt and Prompt Template Loader, Function Calling Definer, Invoker and Running, Memory, Embedding, Vector Storage, Resource Loaders, Document, Splitter, Loader, Parser, LLMs Chain, and Agents Chain.
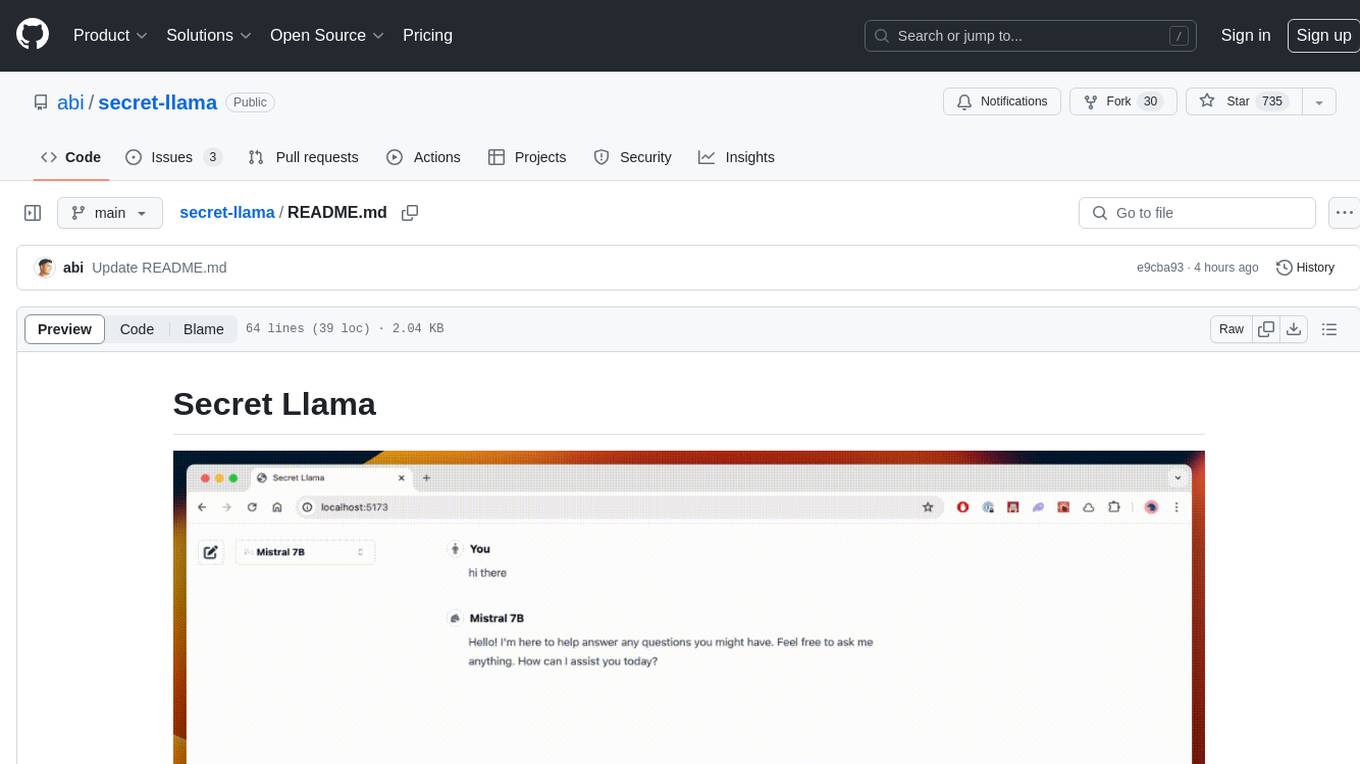
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
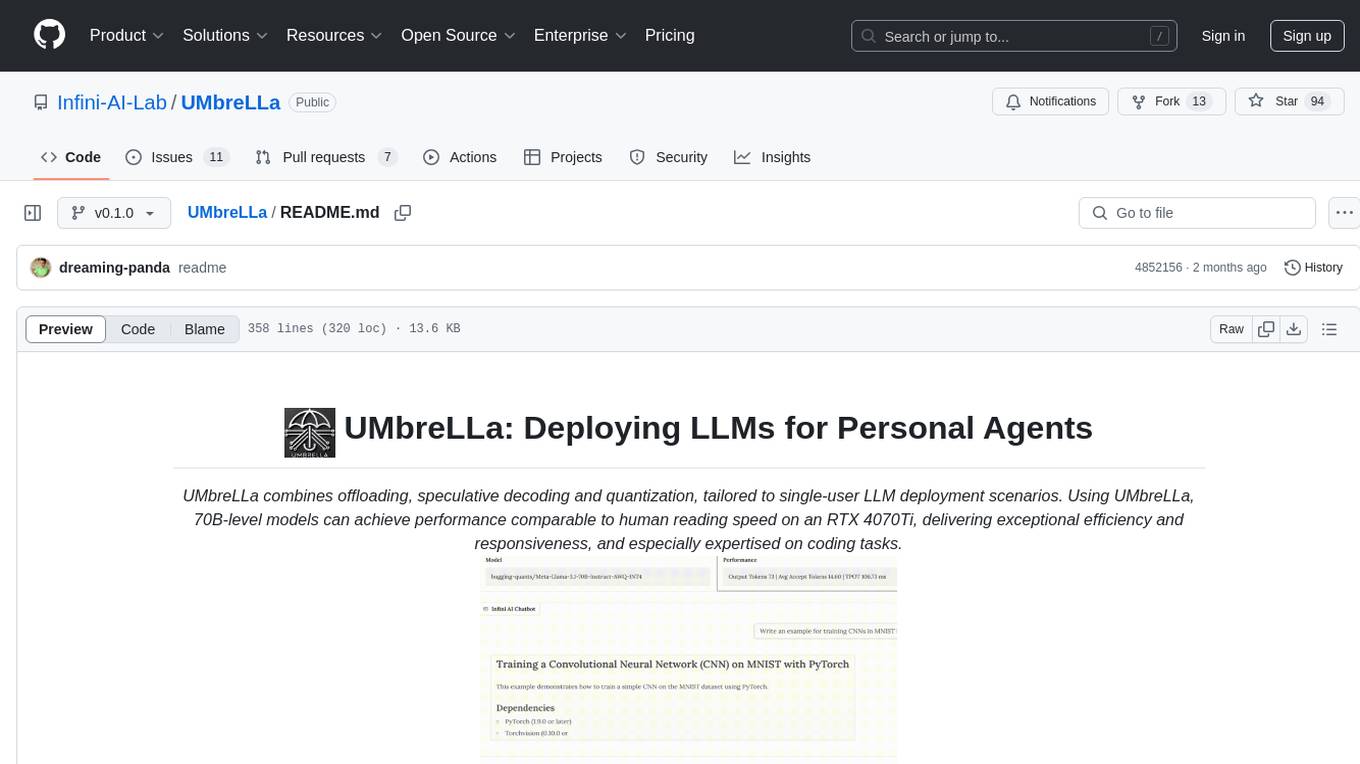
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.