
aws-bedrock-with-rag-and-react
Prototyping Generative AI Use Cases with Amazon Bedrock and Langchain
Stars: 67
This solution provides a low-code ReactJS application to prototype and vet business use cases for GenAI using Retrieval Augmented Generation (RAG). It includes a backend Flask application that uses LangChain to provide PDF data as embeddings to a text-gen model via Amazon Bedrock and a vector database with FAISS or Kendra Index. The solution utilizes Amazon Bedrock as the only cost-generating AWS service.
README:
Use this solution to quickly and inexpensively begin prototyping and vetting business use cases for GenAI using a custom corpus of knowledge with Retrieval Augmented Generation (RAG) in a low-code ReactJS application.
This solution contains a backend Flask application which uses LangChain to provide PDF data as embeddings to your choice of text-gen foundational model via Amazon Web Services (AWS) new, managed LLM-provider service, Amazon Bedrock and your choice of vector database with FAISS or a Kendra Index.


- AWS CDK
- Node.js & npm
- Python 3.8 or higher
- AWS CLI configured with appropriate permissions
-
Clone the repository and navigate to the project directory.
-
Install the Python dependencies for the CDK Deployment:
pip install -r requirements.txt -
Bootstrap CDK (if not already done): If this is your first time using CDK in this AWS account and region, you need to bootstrap CDK. This command deploys a CDK toolkit stack to your account that helps with asset management:
cdk bootstrap aws://YOUR_ACCOUNT_NUMBER/YOUR_REGIONReplace
YOUR_ACCOUNT_NUMBERwith your AWS account number andYOUR_REGIONwith your desired AWS region. -
Deploy the Backend CDK stack.
cdk deploy BedrockDemo-BackendStack -
Redeploy the frontend stack to update the proxy URL:
cdk deploy BedrockDemo-FrontendStack
Your application should now be accessible at the frontend URL provided by the CDK output.
Once you confirm that the app(s) are running, you can begin prototyping.
PDF data is read from ./backend/flask/output and stored in an in-memory vector database using FAISS when the Flask app is started. If you add or remove PDF data from the ./backend/flask/output directory, you'll need to restart the Flask application for the changes to take effect.
Alternatively, you can use the database button in the lower right corner of the application to add or remove PDF documents manually or from S3 and subsequently reinstantiate the in-memory vector database, or instantiate a connection to a Kendra index.
Use the </> button just above the database button to update the Prompt Template: explicit instructions for how a text-gen model should respond.
Foundational Models are trained in specific ways to interact with prompts. Check out the Claude Documentation Page to learn best practices and find examples of pre-engineered prompts.
This library is licensed under the MIT-0 License. See the LICENSE file.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aws-bedrock-with-rag-and-react
Similar Open Source Tools
aws-bedrock-with-rag-and-react
This solution provides a low-code ReactJS application to prototype and vet business use cases for GenAI using Retrieval Augmented Generation (RAG). It includes a backend Flask application that uses LangChain to provide PDF data as embeddings to a text-gen model via Amazon Bedrock and a vector database with FAISS or Kendra Index. The solution utilizes Amazon Bedrock as the only cost-generating AWS service.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.

conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
vertex-ai-creative-studio
GenMedia Creative Studio is an application showcasing the capabilities of Google Cloud Vertex AI generative AI creative APIs. It includes features like Gemini for prompt rewriting and multimodal evaluation of generated images. The app is built with Mesop, a Python-based UI framework, enabling rapid development of web and internal apps. The Experimental folder contains stand-alone applications and upcoming features demonstrating cutting-edge generative AI capabilities, such as image generation, prompting techniques, and audio/video tools.
cluster-toolkit
Cluster Toolkit is an open-source software by Google Cloud for deploying AI/ML and HPC environments on Google Cloud. It allows easy deployment following best practices, with high customization and extensibility. The toolkit includes tutorials, examples, and documentation for various modules designed for AI/ML and HPC use cases.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.

raggenie
RAGGENIE is a low-code RAG builder tool designed to simplify the creation of conversational AI applications. It offers out-of-the-box plugins for connecting to various data sources and building conversational AI on top of them, including integration with pre-built agents for actions. The tool is open-source under the MIT license, with a current focus on making it easy to build RAG applications and future plans for maintenance, monitoring, and transitioning applications from pilots to production.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
genai-for-marketing
This repository provides a deployment guide for utilizing Google Cloud's Generative AI tools in marketing scenarios. It includes step-by-step instructions, examples of crafting marketing materials, and supplementary Jupyter notebooks. The demos cover marketing insights, audience analysis, trendspotting, content search, content generation, and workspace integration. Users can access and visualize marketing data, analyze trends, improve search experience, and generate compelling content. The repository structure includes backend APIs, frontend code, sample notebooks, templates, and installation scripts.
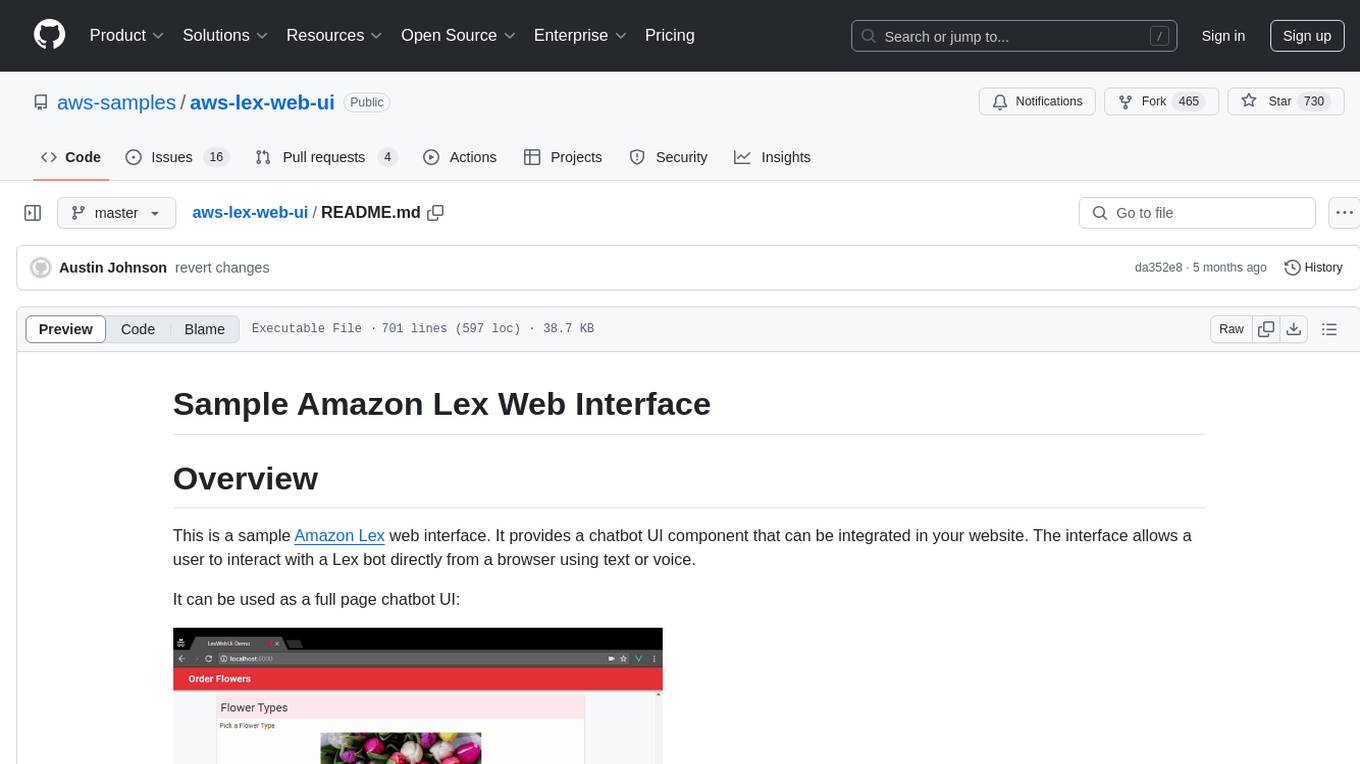
aws-lex-web-ui
The AWS Lex Web UI is a sample Amazon Lex web interface that provides a chatbot UI component for integration into websites. It supports voice and text interactions, Lex response cards, and programmable configuration using JavaScript. The interface can be used as a full-page chatbot UI or embedded as a widget. It offers mobile-ready responsive UI, seamless voice-text switching, and interactive messaging support. The project includes CloudFormation templates for easy deployment and customization. Users can modify configurations, integrate the UI into existing sites, and deploy using various methods like CloudFormation, pre-built libraries, or npm installation.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.
create-tsi
Create TSI is a generative AI RAG toolkit that simplifies the process of creating AI Applications using LlamaIndex with low code. The toolkit leverages LLMs hosted by T-Systems on Open Telekom Cloud to generate bots, write agents, and customize them for specific use cases. It provides a Next.js-powered front-end for a chat interface, a Python FastAPI backend powered by llama-index package, and the ability to ingest and index user-supplied data for answering questions.
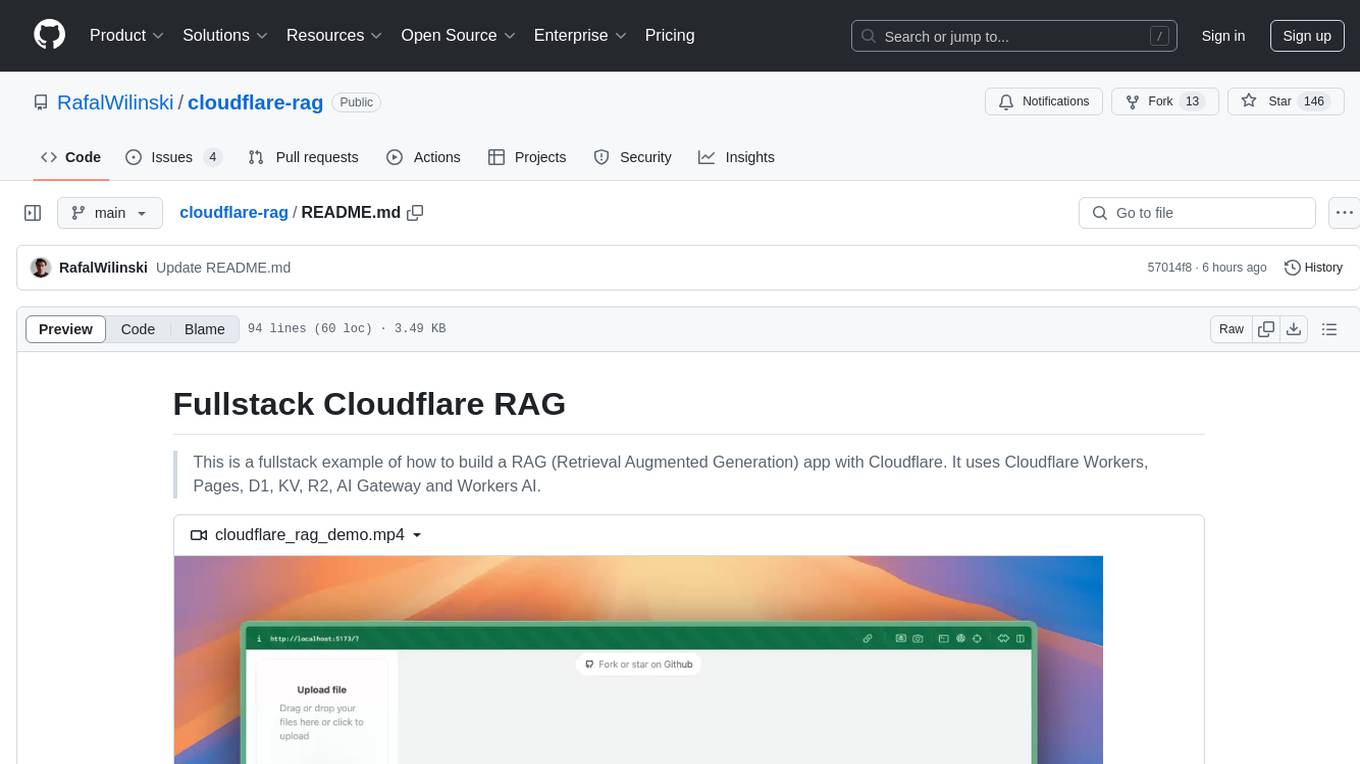
cloudflare-rag
This repository provides a fullstack example of building a Retrieval Augmented Generation (RAG) app with Cloudflare. It utilizes Cloudflare Workers, Pages, D1, KV, R2, AI Gateway, and Workers AI. The app features streaming interactions to the UI, hybrid RAG with Full-Text Search and Vector Search, switchable providers using AI Gateway, per-IP rate limiting with Cloudflare's KV, OCR within Cloudflare Worker, and Smart Placement for workload optimization. The development setup requires Node, pnpm, and wrangler CLI, along with setting up necessary primitives and API keys. Deployment involves setting up secrets and deploying the app to Cloudflare Pages. The project implements a Hybrid Search RAG approach combining Full Text Search against D1 and Hybrid Search with embeddings against Vectorize to enhance context for the LLM.
shipstation
ShipStation is an AI-based website and agents generation platform that optimizes landing page websites and generic connect-anything-to-anything services. It enables seamless communication between service providers and integration partners, offering features like user authentication, project management, code editing, payment integration, and real-time progress tracking. The project architecture includes server-side (Node.js) and client-side (React with Vite) components. Prerequisites include Node.js, npm or yarn, Anthropic API key, Supabase account, Tavily API key, and Razorpay account. Setup instructions involve cloning the repository, setting up Supabase, configuring environment variables, and starting the backend and frontend servers. Users can access the application through the browser, sign up or log in, create landing pages or portfolios, and get websites stored in an S3 bucket. Deployment to Heroku involves building the client project, committing changes, and pushing to the main branch. Contributions to the project are encouraged, and the license encourages doing good.

coral-cloud
Coral Cloud Resorts is a sample hospitality application that showcases Data Cloud, Agents, and Prompts. It provides highly personalized guest experiences through smart automation, content generation, and summarization. The app requires licenses for Data Cloud, Agents, Prompt Builder, and Einstein for Sales. Users can activate features, deploy metadata, assign permission sets, import sample data, and troubleshoot common issues. Additionally, the repository offers integration with modern web development tools like Prettier, ESLint, and pre-commit hooks for code formatting and linting.
For similar tasks
aws-bedrock-with-rag-and-react
This solution provides a low-code ReactJS application to prototype and vet business use cases for GenAI using Retrieval Augmented Generation (RAG). It includes a backend Flask application that uses LangChain to provide PDF data as embeddings to a text-gen model via Amazon Bedrock and a vector database with FAISS or Kendra Index. The solution utilizes Amazon Bedrock as the only cost-generating AWS service.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.