
airbroke
🔥 Airbroke: Lightweight, Airbrake-compatible, PostgreSQL-based Open Source Error Catcher
Stars: 179

Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.
README:
![]()

Airbroke is currently in active development! Using it in production environments is at your own discretion. We appreciate your feedback and support as we work towards a stable release.
- 💾 Based on PostgreSQL
- 🌐 Airbrake(tm)-compatible HTTP collector endpoint
- 💻 Modern, React-based frontend for error management
- 🚀 Designed with simplicity at its core
- 🔧 Maintains small database footprint even under heavy data ingestion
- 🤖 Ask AI about issues
- 📋 Provide cURL command to reproduce HTTP exceptions
▶️ Replay HTTP exceptions- 🔑 Supports multiple OAuth providers for secure user authentication
- 📊 Occurrence charts
- 🔖 Save and manage bookmarks for important occurrences
- Node.js 20/22+ compatible environment
- Minimum of 300MB RAM
- At least 1000 millicores, equivalent to 1 CPU core
- PostgreSQL 15+ database
- 8+ free database connections slots per instance
Airbroke provides flexibility in deployment options. You can either deploy it from the built source code or use a multiarch Docker image. For Kubernetes deployments, a Helm chart is provided. As Airbroke is a Next.js 15 application, it can be deployed wherever a Node.js server is supported. This includes managed environments such as Vercel, Netlify, and Heroku.
For a production build, you can run:
cp .env.dist .envThen edit the .env file to set your own values.
yarn install
yarn buildThis will generate a build folder that you can deploy to your server, but please refer to the Dockerfile to learn more about what to do after that because you might need to copy over some assets.
You can also run yarn start to test the production build locally on port 3000.
We publish images for both amd64 and arm64 architectures on ghcr.io but in case you want to build your own image you can do so.
You can build the Docker image with:
docker build --no-cache -t icoretech/airbroke:latest .You can then run the image locally with:
docker run -p 3000:3000 icoretech/airbroke:latestWhile testing on Vercel has not been conducted, Airbroke should be fully compatible.
It's important to keep the following points in mind:
- For optimal performance, ensure your database is located in the same region.
- The endpoints under
/api/*will be converted into serverless functions, which may introduce potential cold boot time. - Due to the nature of serverless functions, your database connections will need to pass through a data proxy.
- When deploying with Vercel, migrations will need to be executed during the build step. Use the
prisma migrate deploycommand to apply migrations before Vercel proceeds with the deployment of serverless functions.
Detailed instructions for this process can also be found in the Prisma deployment guide for Vercel.

You can deploy Airbroke to Kubernetes using the dedicated Helm chart.
The Helm chart includes a values.yaml file with some default values that you can override with your own. It also includes a pgBouncer chart as optional dependency.
When using Helm we recommend using a GitOps approach to deploy your application(s), such as Flux.
Please find more information about the Helm chart in the dedicated repository: icoretech/charts
For users who prefer Docker Compose for managing multi-container Docker applications, a docker-compose.yml file is provided at the root of the repository.
To get started, make sure you have Docker and Docker Compose installed on your system. Then, you can start the application using the following command in the terminal:
make build
make runYou can override the default values in the docker-compose.yml file by creating a docker-compose.override.yml file in the same directory. This file is ignored by Git and will not be committed to the repository.
Please view all the available configuration variables in the .env.dist file.
Airbroke requires some environment variables set at runtime, DATABASE_URL and DIRECT_URL are mandatory, some examples:
# Example Connection to Prisma Data Proxy
DATABASE_URL="prisma://__HOST__/?api_key=__KEY__"
# Example Connection to PostgreSQL
DATABASE_URL="postgresql://__USER__:__PASSWORD__@__HOST__:__PORT__/__DATABASE__?connection_limit=20&pool_timeout=10&application_name=airbroke"
# Direct connection to the database, used for migrations
DIRECT_URL="postgresql://__USER__:__PASSWORD__@__HOST__:__PORT__/__DATABASE__"The optimal connection pool size without pgBouncer (connection_limit) can be calculated using the following formula:
connection_limit = (num_physical_cpus * 2 + 1) ÷ number_of_application_instancesFor a system with 8 CPU cores and 3 application instances, the calculation would proceed as follows:
connection_limit = (8 * 2 + 1) ÷ 3
connection_limit = (16 + 1) ÷ 3
connection_limit = 17 ÷ 3
connection_limit ≈ 5.67Since connection_limit must be an integer, it should be rounded down to the nearest whole number. In this scenario, each of the 3 application instances should have a connection_limit of 5.
This limit can be set in your connection strings.
After deployment, you should be able to access your ingress (preferably secured with HTTPS) and start adding projects. This process will generate an API key that you can use with your Airbrake-compatible clients. This key, along with other essential information, will be provided to you.
To optimize your experience with Airbroke, as well as with Postgres overall, we advise integrating PgBouncer 1.24.0+ into your tech stack in transaction mode. For more comprehensive information, we recommend reviewing Prisma's Connection Management documentation, which provides insights on external connection poolers.
We recommend not setting pgbouncer=true in the database connection string if you're using PgBouncer 1.21.0 or later (source).
The DIRECT_URL environment variable should be configured to establish a direct connection to the database. This is particularly crucial when using PgBouncer, as it enables migrations that cannot be executed through a data proxy. You can find more detailed information about this subject in the Prisma's guide on configuring pgBouncer.
The Airbroke frontend provides a user-friendly interface for managing and analyzing error reports. It utilizes a modern tech stack, including React, Tailwind CSS, and Next.js, to deliver a seamless user experience. The frontend leverages server-rendering capabilities to optimize initial page load times and ensure fast and responsive navigation.
To optimize performance, the frontend may implement caching strategies to reduce the number of database queries and enhance overall responsiveness. This ensures that you can efficiently navigate through error reports and analyze critical information without experiencing unnecessary delays.
The Data Collection API is a core component of Airbroke responsible for handling the ingestion of error reports. It serves as the endpoint where clients can send error reports, enabling efficient data collection for error management.
To ensure simplicity and performance, the Data Collection API sidesteps the use of queue systems and performs parsing and transactions in-band. This means that parsing and processing of error reports happen synchronously within the API request cycle. Despite this approach, the Data Collection API demonstrates robust request-per-minute (RPM) performance even under high traffic volumes.
Airbroke includes an authentication layer that allows you to secure access to the application by enabling user authentication. It supports various authentication providers, including:
- GitHub
- Atlassian
- Apple
- Authentik
- Cognito
- GitLab
- Keycloak
- Microsoft Entra ID
- Slack
- Okta
To configure the authentication layer, you need to set the necessary environment variables corresponding to the authentication providers you want to use. These environment variables typically include client IDs, client secrets, and other provider-specific configuration details. Make sure to keep these environment variables secure, as they contain sensitive information.
To complete the configuration, you also need to set the callback path in your OAuth applications for each provider. The callback path should be set to https://<myhostname>/api/auth/callback/<provider>. This path is where the authentication provider will redirect the user after successful authentication.
You can find a list of available authentication providers and their documentation on the NextAuth.js Providers page. Each provider has its own specific configuration requirements and authentication flow, so refer to their documentation for more details.
To configure the authentication providers, you'll need to set specific environment variables. You can find the list of required environment variables and their descriptions in the .env.dist file in the Airbroke repository.
To enable authentication in Airbroke and allow users to authenticate using third-party providers, follow these steps:
-
Configure the necessary environment variables for the desired authentication providers. You can refer to the
.env.distfile in the Airbroke repository for a list of required environment variables and their descriptions. Copy this file as.envand fill in the necessary values for your authentication providers. -
Create OAuth applications with the respective authentication providers. Each provider will have its own developer console or settings page where you can create an OAuth application. During the application setup, configure the callback url to match the Airbroke authentication callback path:
https://myairbroke.xyz/api/auth/callback/<provider>. Save the settings. -
Start the Airbroke application, ensuring that the environment variables are properly configured.
-
Users can now authenticate with Airbroke by clicking on the login button and selecting their desired authentication provider. They will be redirected to the provider's authentication page to enter their credentials. Upon successful authentication, users will be logged in to Airbroke.
Note: The callback path in step 2 is essential for the authentication flow to work correctly. It ensures that the authentication provider can redirect the user back to the Airbroke application after authentication is complete.
Please refer to the documentation of the respective authentication providers to obtain the necessary configuration details and understand their authentication flows.
Airbroke provides error grouping mechanisms that analyze the incoming error data and automatically group similar errors based on their attributes.
However when working with exceptions that include dynamic information as part of the exception itself (e.g., raise(NotFound, 'no record 1234')), it is important to consider efficient error collection and storage strategies. By following these practices, you can ensure that Airbroke maintains an efficient database and effectively groups and displays related errors without much overhead.
If the exceptions are generated within your own code, consider using more generic error messages and providing detailed reporting using the params field. Here's an example:
begin
data = { book_id: 22 }
raise 'ugh' # no dynamic data
rescue => e
Airbrake.notify(e, data) # ugh happened on book_id 22
endIf the exceptions are produced by libraries, consider collecting the necessary information, wrapping the exceptions, and re-raising them with cleaned-up messages. This approach allows you to provide more meaningful and informative error messages to Airbroke. Here's an example:
begin
# Your code that interacts with a library
rescue SomeLibraryError => e
# Collect necessary information
error_data = { library_error_message: e.message, library_error_code: e.code }
# Wrap and re-raise the exception with a cleaned-up message
wrapped_exception = RuntimeError.new("An error occurred in the library.")
Airbrake.notify(wrapped_exception, error_data)
raise wrapped_exception
endBy wrapping the library exception with a customized error message and including the relevant information in the params field, you can ensure that Airbroke receives clean and consistent error messages while retaining the necessary context.
By adopting these best practices, you can enhance the efficiency and effectiveness of error collection and storage in Airbroke. These strategies allow for better grouping and analysis of related errors, providing you with the insights needed to identify and address issues more effectively.
When working with error collection in Airbroke, you may come across situations where you find an error occurrence with a high count, but upon opening it, you discover that it only has one document to consult. This happens because Airbroke groups errors based on their "kind" and "message". If any of these attributes differ, Airbroke will create a new error group.
As a result, you may encounter repeated errors that don't expose the specific parameter or stack trace after the first occurrence, or they may have originated from a different part of the application. This tradeoff is made to ensure a compact database size and high performance. The underlying idea is to encourage you to address and resolve errors, so maintaining a clean and organized error slate will yield better insights and improvements over time.
By understanding these limitations and keeping your error collection streamlined, you can effectively utilize Airbroke's features to identify and resolve issues in your application.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for airbroke
Similar Open Source Tools
airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.
cluster-toolkit
Cluster Toolkit is an open-source software by Google Cloud for deploying AI/ML and HPC environments on Google Cloud. It allows easy deployment following best practices, with high customization and extensibility. The toolkit includes tutorials, examples, and documentation for various modules designed for AI/ML and HPC use cases.
trinityX
TrinityX is an open-source HPC, AI, and cloud platform designed to provide all services required in a modern system, with full customization options. It includes default services like Luna node provisioner, OpenLDAP, SLURM or OpenPBS, Prometheus, Grafana, OpenOndemand, and more. TrinityX also sets up NFS-shared directories, OpenHPC applications, environment modules, HA, and more. Users can install TrinityX on Enterprise Linux, configure network interfaces, set up passwordless authentication, and customize the installation using Ansible playbooks. The platform supports HA, OpenHPC integration, and provides detailed documentation for users to contribute to the project.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

HackBot
HackBot is an AI-powered cybersecurity chatbot designed to provide accurate answers to cybersecurity-related queries, conduct code analysis, and scan analysis. It utilizes the Meta-LLama2 AI model through the 'LlamaCpp' library to respond coherently. The chatbot offers features like local AI/Runpod deployment support, cybersecurity chat assistance, interactive interface, clear output presentation, static code analysis, and vulnerability analysis. Users can interact with HackBot through a command-line interface and utilize it for various cybersecurity tasks.
mahilo
Mahilo is a flexible framework for creating multi-agent systems that can interact with humans while sharing context internally. It allows developers to set up complex agent networks for various applications, from customer service to emergency response simulations. Agents can communicate with each other and with humans, making the system efficient by handling context from multiple agents and helping humans stay focused on specific problems. The system supports Realtime API for voice interactions, WebSocket-based communication, flexible communication patterns, session management, and easy agent definition.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.
AppAgent
AppAgent is a novel LLM-based multimodal agent framework designed to operate smartphone applications. Our framework enables the agent to operate smartphone applications through a simplified action space, mimicking human-like interactions such as tapping and swiping. This novel approach bypasses the need for system back-end access, thereby broadening its applicability across diverse apps. Central to our agent's functionality is its innovative learning method. The agent learns to navigate and use new apps either through autonomous exploration or by observing human demonstrations. This process generates a knowledge base that the agent refers to for executing complex tasks across different applications.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
langchain-google
LangChain Google is a repository containing three packages with Google integrations: langchain-google-genai for Google Generative AI models, langchain-google-vertexai for Google Cloud Generative AI on Vertex AI, and langchain-google-community for other Google product integrations. The repository is organized as a monorepo with a structure including libs for different packages, and files like pyproject.toml and Makefile for building, linting, and testing. It provides guidelines for contributing, local development dependencies installation, formatting, linting, working with optional dependencies, and testing with unit and integration tests. The focus is on maintaining unit test coverage and avoiding excessive integration tests, with annotations for GCP infrastructure-dependent tests.
ai-goat
AI Goat is a tool designed to help users learn about AI security through a series of vulnerable LLM CTF challenges. It allows users to run everything locally on their system without the need for sign-ups or cloud fees. The tool focuses on exploring security risks associated with large language models (LLMs) like ChatGPT, providing practical experience for security researchers to understand vulnerabilities and exploitation techniques. AI Goat uses the Vicuna LLM, derived from Meta's LLaMA and ChatGPT's response data, to create challenges that involve prompt injections, insecure output handling, and other LLM security threats. The tool also includes a prebuilt Docker image, ai-base, containing all necessary libraries to run the LLM and challenges, along with an optional CTFd container for challenge management and flag submission.
For similar tasks
airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.
instruct-ner
Instruct NER is a solution for complex Named Entity Recognition tasks, including Nested NER, based on modern Large Language Models (LLMs). It provides tools for dataset creation, training, automatic metric calculation, inference, error analysis, and model implementation. Users can create instructions for LLM, build dictionaries with labels, and generate model input templates. The tool supports various entity types and datasets, such as RuDReC, NEREL-BIO, CoNLL-2003, and MultiCoNER II. It offers training scripts for LLMs and metric calculation functions. Instruct NER models like Llama, Mistral, T5, and RWKV are implemented, with HuggingFace models available for adaptation and merging.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.
aiohttp-security
aiohttp_security is a library that provides identity and authorization for aiohttp.web. It offers features for handling authorization via cookies and supports aiohttp-session. The library includes examples for basic usage and database authentication, along with demos in the demo directory. For development, the library requires installation of specific requirements listed in the requirements-dev.txt file. aiohttp_security is licensed under the Apache 2 license.

EvoMaster
EvoMaster is an open-source AI-driven tool that automatically generates system-level test cases for web/enterprise applications. It uses Evolutionary Algorithm and Dynamic Program Analysis to evolve test cases, maximizing code coverage and fault detection. It supports REST, GraphQL, and RPC APIs, with whitebox testing for JVM-compiled APIs. The tool generates JUnit tests in Java or Kotlin, focusing on fault detection, self-contained tests, SQL handling, and authentication. Known limitations include manual driver creation for whitebox testing and longer execution times for better results. EvoMaster has been funded by ERC and RCN grants.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.
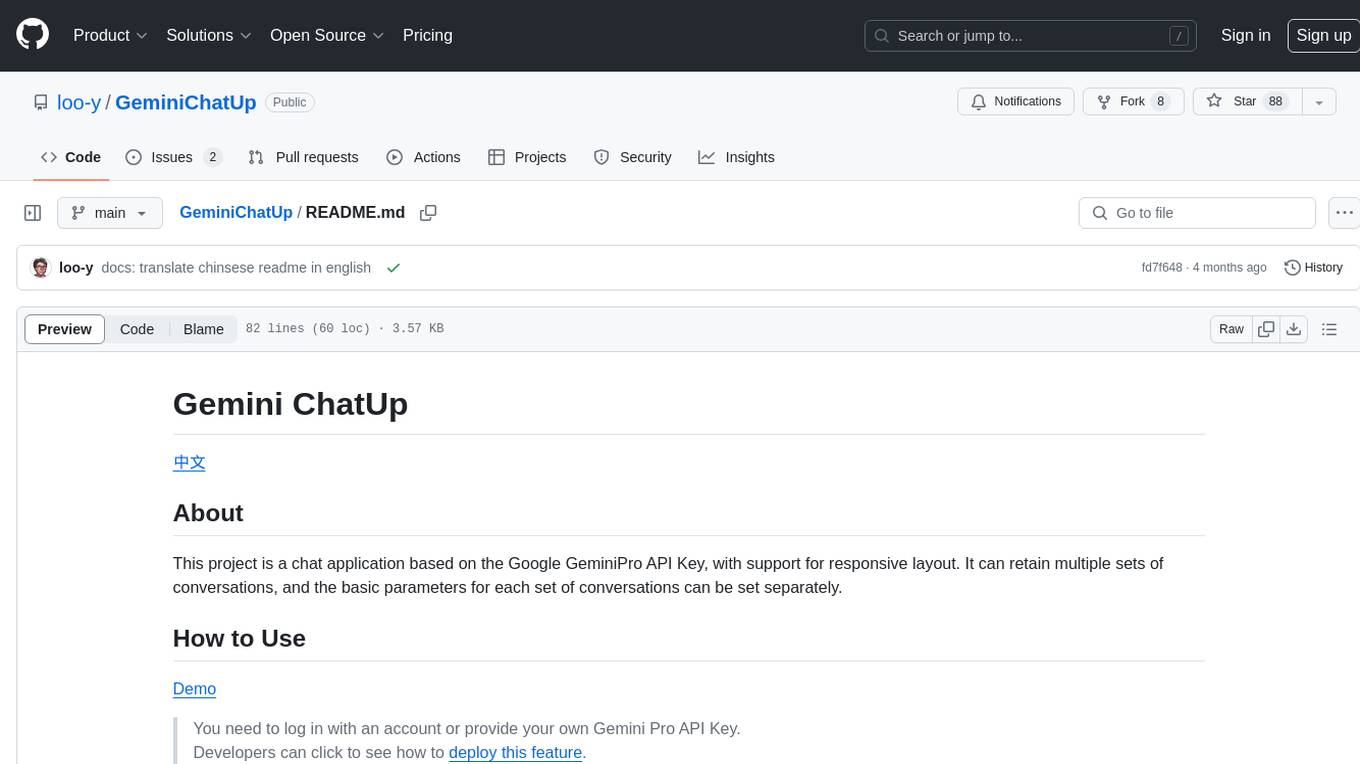
GeminiChatUp
Gemini ChatUp is a chat application utilizing the Google GeminiPro API Key. It supports responsive layout and can store multiple sets of conversations with customizable parameters for each set. Users can log in with a test account or provide their own API Key to deploy the feature. The application also offers user authentication through Edge config in Vercel, allowing users to add usernames and passwords in JSON format. Local deployment is possible by installing dependencies, setting up environment variables, and running the application locally.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.