
airflow
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Stars: 44279

Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
README:
| Category | Badges |
|---|---|
| License |  |
| PyPI |
 
|
| Containers |
  |
| Community |
  |
| Dev tools |
| Version | Build Status |
|---|---|
| Main | |
| 3.x | |
| 2.x |

Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows.
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Use Airflow to author workflows (Dags) that orchestrate tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on Dags a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
Table of contents
- Project Focus
- Principles
- Requirements
- Getting started
- Installing from PyPI
- Installation
- Official source code
- Convenience packages
- User Interface
- Semantic versioning
- Version Life Cycle
- Support for Python and Kubernetes versions
- Base OS support for reference Airflow images
- Approach to dependencies of Airflow
- Contributing
- Voting Policy
- Who uses Apache Airflow?
- Who maintains Apache Airflow?
- What goes into the next release?
- Can I use the Apache Airflow logo in my presentation?
- Links
- Sponsors
Airflow works best with workflows that are mostly static and slowly changing. When the Dag structure is similar from one run to the next, it clarifies the unit of work and continuity. Other similar projects include Luigi, Oozie and Azkaban.
Airflow is commonly used to process data, but has the opinion that tasks should ideally be idempotent (i.e., results of the task will be the same, and will not create duplicated data in a destination system), and should not pass large quantities of data from one task to the next (though tasks can pass metadata using Airflow's XCom feature). For high-volume, data-intensive tasks, a best practice is to delegate to external services specializing in that type of work.
Airflow is not a streaming solution, but it is often used to process real-time data, pulling data off streams in batches.
- Dynamic: Pipelines are defined in code, enabling dynamic dag generation and parameterization.
- Extensible: The Airflow framework includes a wide range of built-in operators and can be extended to fit your needs.
- Flexible: Airflow leverages the Jinja templating engine, allowing rich customizations.
Apache Airflow is tested with:
| Main version (dev) | Stable version (3.1.7) | Stable version (2.11.1) | |
|---|---|---|---|
| Python | 3.10, 3.11, 3.12, 3.13 | 3.10, 3.11, 3.12, 3.13 | 3.10, 3.11, 3.12 |
| Platform | AMD64/ARM64 | AMD64/ARM64 | AMD64/ARM64(*) |
| Kubernetes | 1.30, 1.31, 1.32, 1.33, 1.34, 1.35 | 1.30, 1.31, 1.32, 1.33 | 1.26, 1.27, 1.28, 1.29, 1.30 |
| PostgreSQL | 14, 15, 16, 17, 18 | 13, 14, 15, 16, 17 | 12, 13, 14, 15, 16 |
| MySQL | 8.0, 8.4, Innovation | 8.0, 8.4, Innovation | 8.0, Innovation |
| SQLite | 3.15.0+ | 3.15.0+ | 3.15.0+ |
* Experimental
Note: MariaDB is not tested/recommended.
Note: SQLite is used in Airflow tests. Do not use it in production. We recommend using the latest stable version of SQLite for local development.
Note: Airflow currently can be run on POSIX-compliant Operating Systems. For development, it is regularly
tested on fairly modern Linux Distros and recent versions of macOS.
On Windows you can run it via WSL2 (Windows Subsystem for Linux 2) or via Linux Containers.
The work to add Windows support is tracked via #10388, but
it is not a high priority. You should only use Linux-based distros as "Production" execution environment
as this is the only environment that is supported. The only distro that is used in our CI tests and that
is used in the Community managed DockerHub image is
Debian Bookworm.
Visit the official Airflow website documentation (latest stable release) for help with installing Airflow, getting started, or walking through a more complete tutorial.
Note: If you're looking for documentation for the main branch (latest development branch): you can find it on s.apache.org/airflow-docs.
For more information on Airflow Improvement Proposals (AIPs), visit the Airflow Wiki.
Documentation for dependent projects like provider distributions, Docker image, Helm Chart, you'll find it in the documentation index.
We publish Apache Airflow as apache-airflow package in PyPI. Installing it however might be sometimes tricky
because Airflow is a bit of both a library and application. Libraries usually keep their dependencies open, and
applications usually pin them, but we should do neither and both simultaneously. We decided to keep
our dependencies as open as possible (in pyproject.toml) so users can install different versions of libraries
if needed. This means that pip install apache-airflow will not work from time to time or will
produce unusable Airflow installation.
To have repeatable installation, however, we keep a set of "known-to-be-working" constraint
files in the orphan constraints-main and constraints-2-0 branches. We keep those "known-to-be-working"
constraints files separately per major/minor Python version.
You can use them as constraint files when installing Airflow from PyPI. Note that you have to specify
correct Airflow tag/version/branch and Python versions in the URL.
- Installing just Airflow:
Note: Only
pipinstallation is currently officially supported.
While it is possible to install Airflow with tools like Poetry or
pip-tools, they do not share the same workflow as
pip - especially when it comes to constraint vs. requirements management.
Installing via Poetry or pip-tools is not currently supported.
If you wish to install Airflow using those tools, you should use the constraint files and convert them to the appropriate format and workflow that your tool requires.
pip install 'apache-airflow==3.1.7' \
--constraint "https://raw.githubusercontent.com/apache/airflow/constraints-3.1.7/constraints-3.10.txt"- Installing with extras (i.e., postgres, google)
pip install 'apache-airflow[postgres,google]==3.1.7' \
--constraint "https://raw.githubusercontent.com/apache/airflow/constraints-3.1.7/constraints-3.10.txt"For information on installing provider distributions, check providers.
For comprehensive instructions on setting up your local development environment and installing Apache Airflow, please refer to the INSTALLING.md file.
Apache Airflow is an Apache Software Foundation (ASF) project, and our official source code releases:
- Follow the ASF Release Policy
- Can be downloaded from the ASF Distribution Directory
- Are cryptographically signed by the release manager
- Are officially voted on by the PMC members during the Release Approval Process
Following the ASF rules, the source packages released must be sufficient for a user to build and test the release provided they have access to the appropriate platform and tools.
There are other ways of installing and using Airflow. Those are "convenience" methods - they are
not "official releases" as stated by the ASF Release Policy, but they can be used by the users
who do not want to build the software themselves.
Those are - in the order of most common ways people install Airflow:
-
PyPI releases to install Airflow using standard
piptool -
Docker Images to install airflow via
dockertool, use them in Kubernetes, Helm Charts,docker-compose,docker swarm, etc. You can read more about using, customizing, and extending the images in the Latest docs, and learn details on the internals in the images document. - Tags in GitHub to retrieve the git project sources that were used to generate official source packages via git
All those artifacts are not official releases, but they are prepared using officially released sources. Some of those artifacts are "development" or "pre-release" ones, and they are clearly marked as such following the ASF Policy.
-
Dags: Overview of all Dags in your environment.
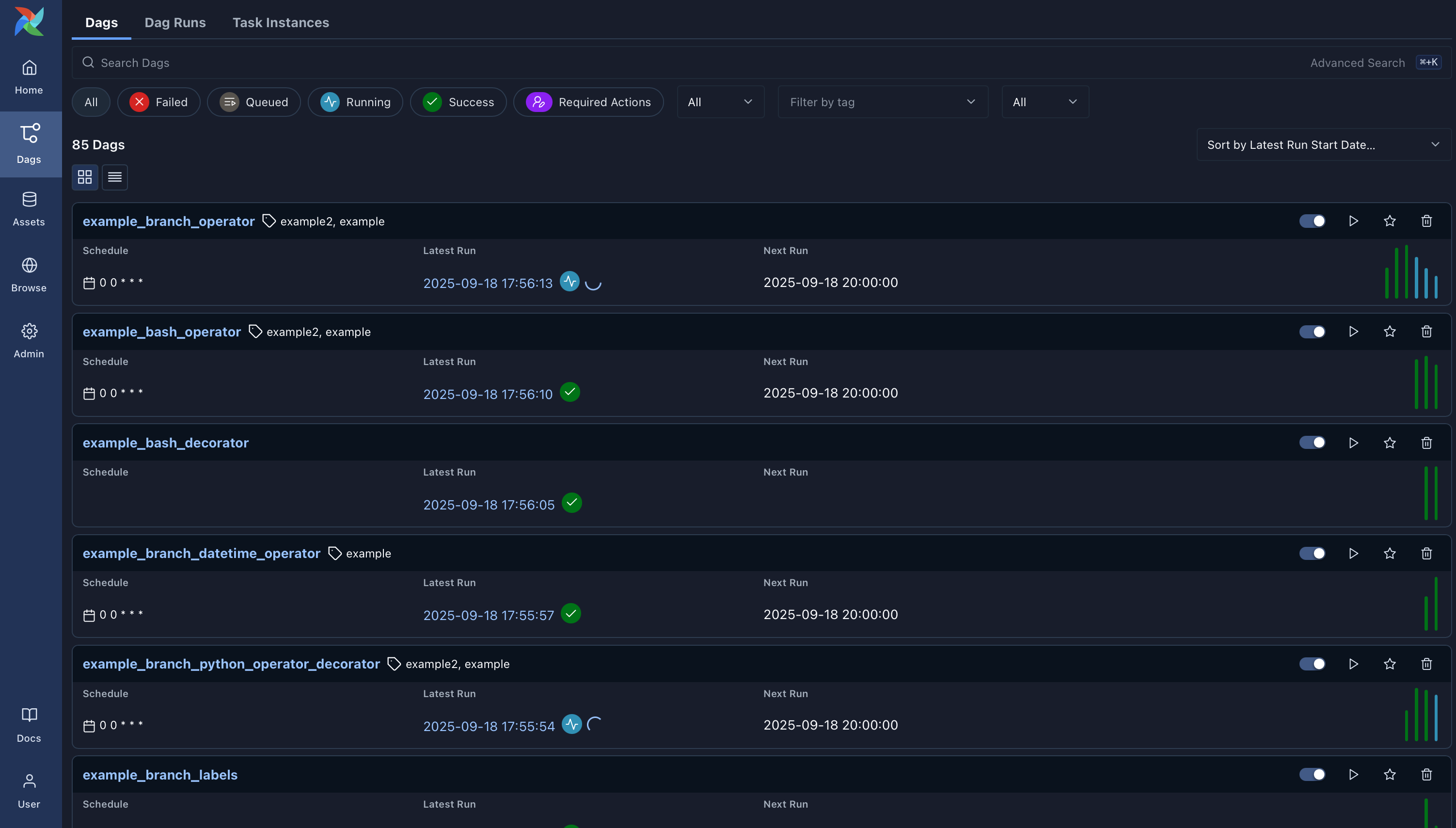
-
Assets: Overview of Assets with dependencies.
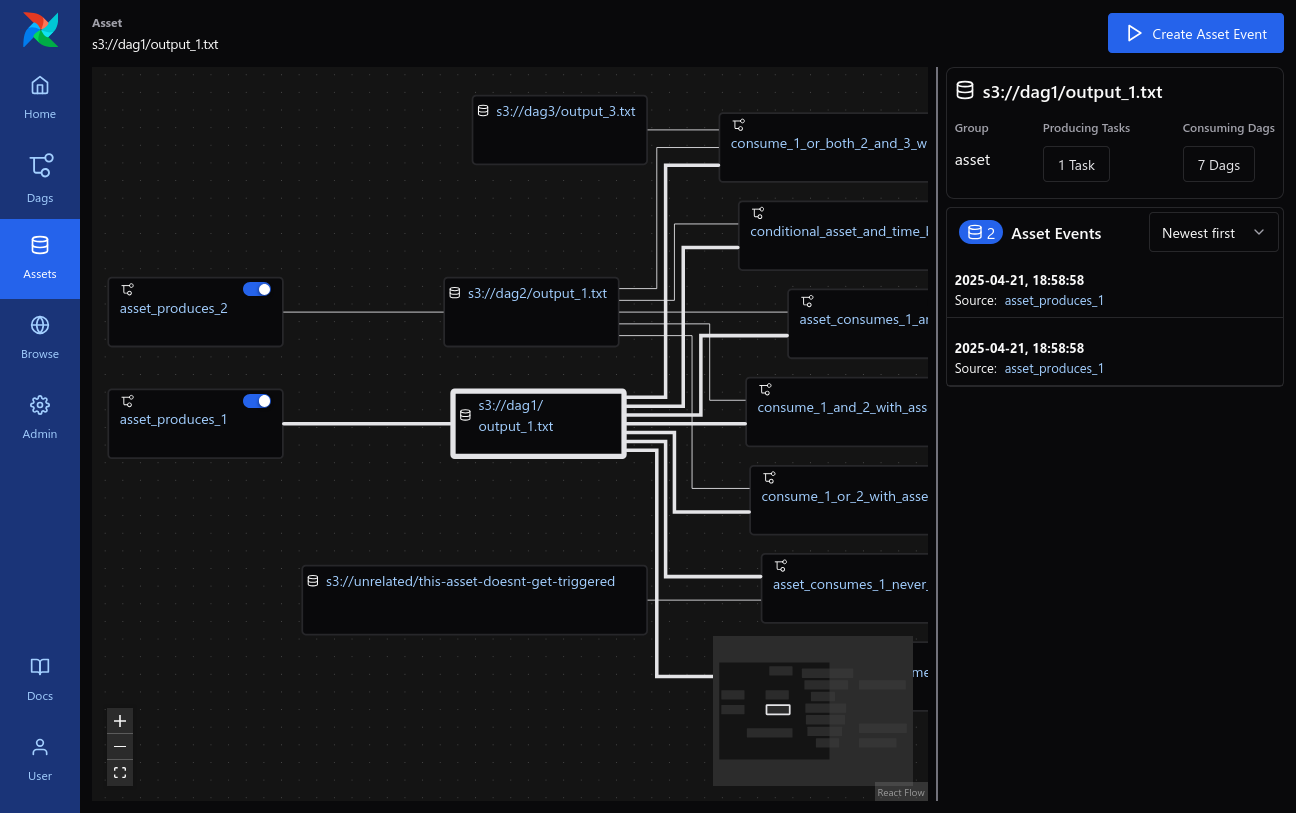
-
Grid: Grid representation of a Dag that spans across time.
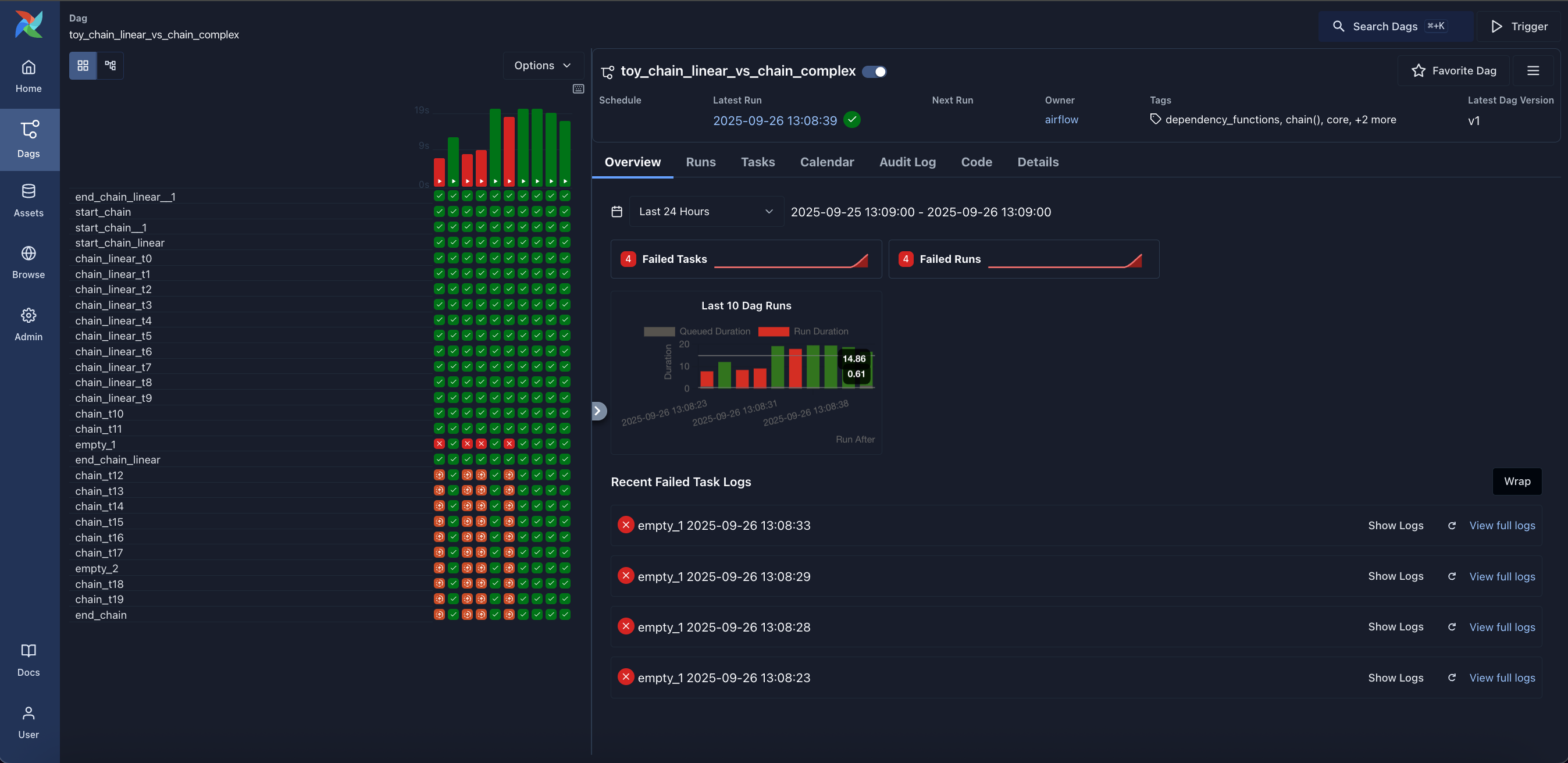
-
Graph: Visualization of a Dag's dependencies and their current status for a specific run.
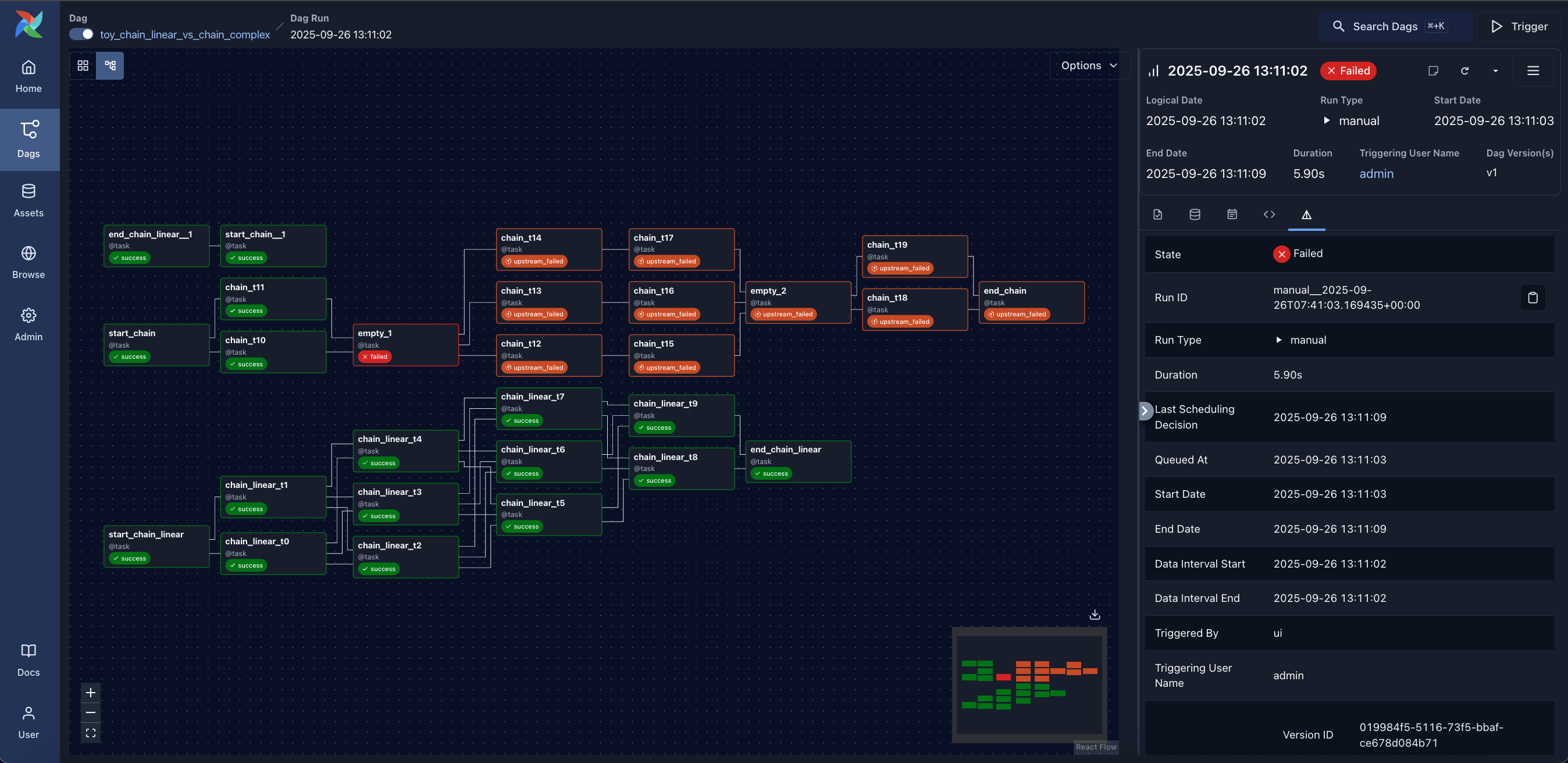
-
Home: Summary statistics of your Airflow environment.
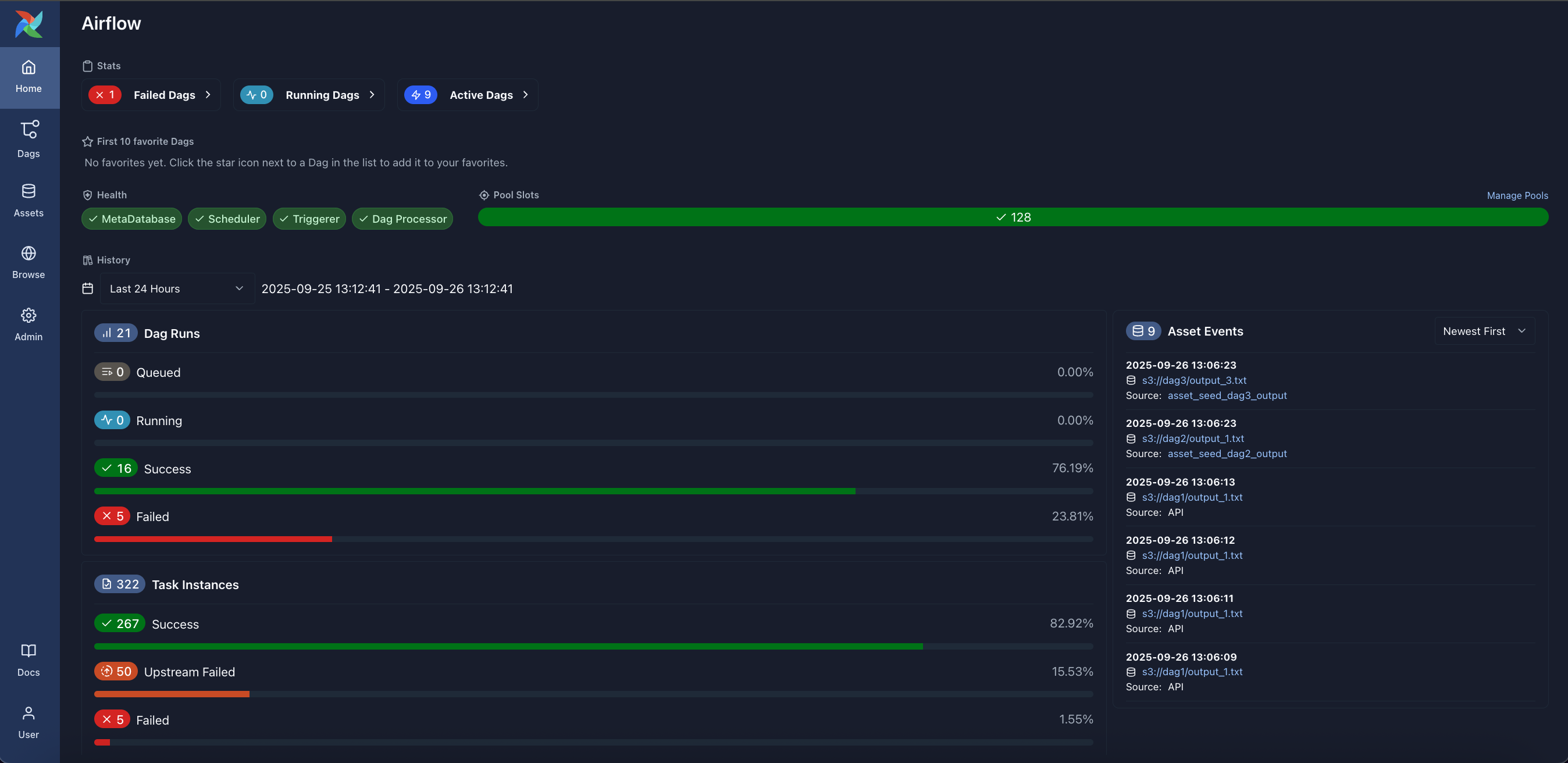
-
Backfill: Backfilling a Dag for a specific date range.
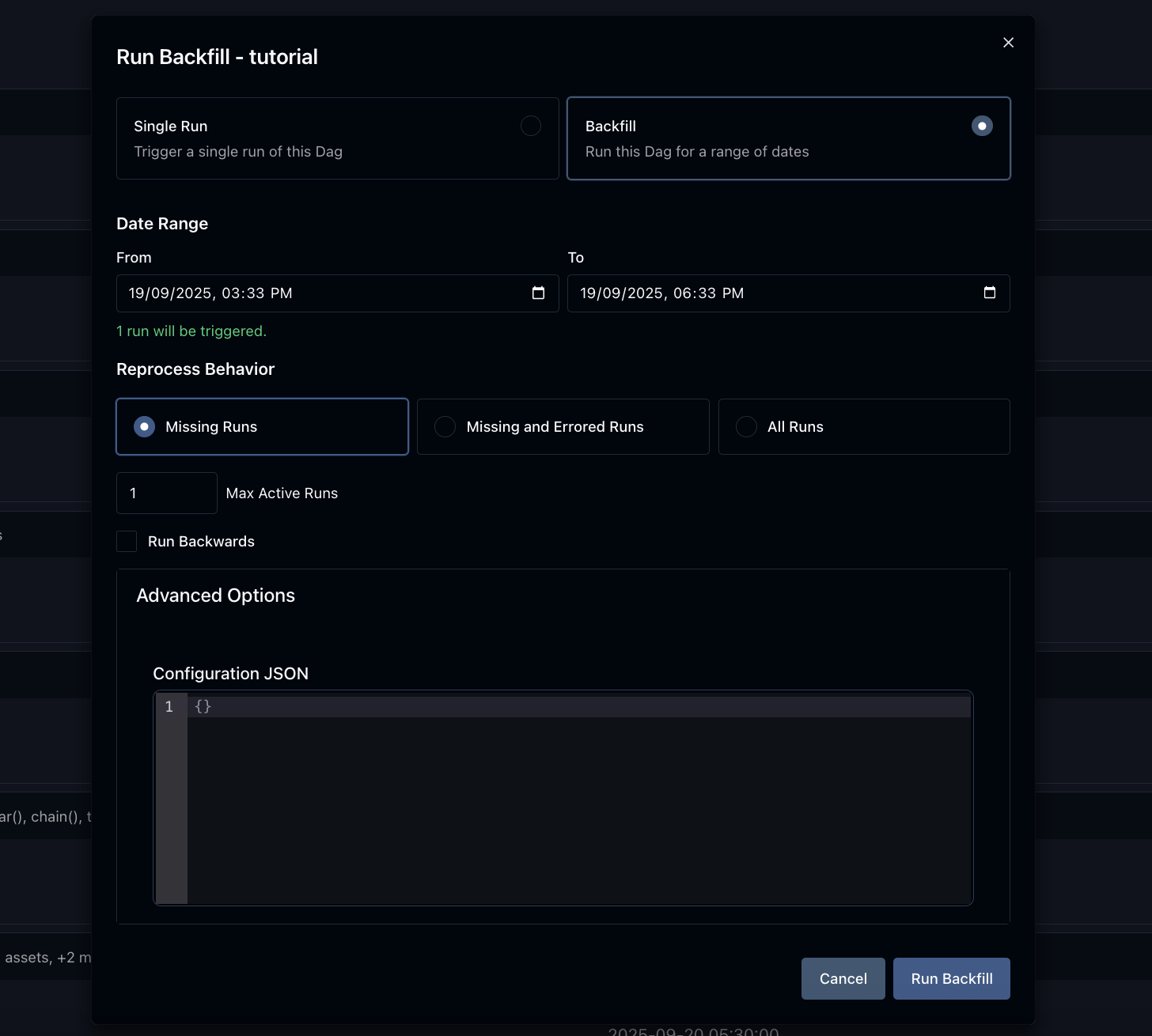
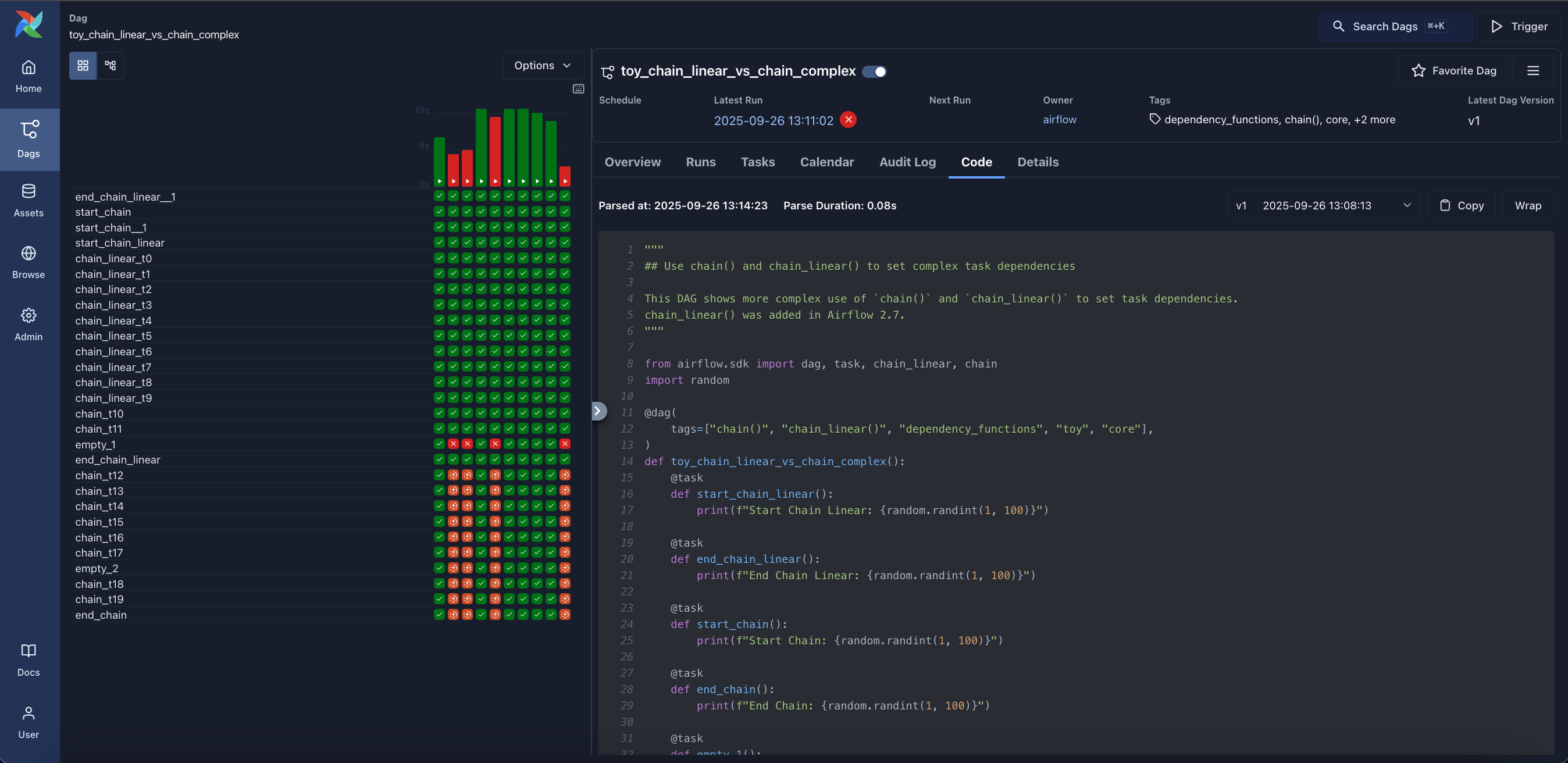
-
Code: Quick way to view source code of a Dag.
As of Airflow 2.0.0, we support a strict SemVer approach for all packages released.
There are few specific rules that we agreed to that define details of versioning of the different packages:
- Airflow: SemVer rules apply to core airflow only (excludes any changes to providers). Changing limits for versions of Airflow dependencies is not a breaking change on its own.
-
Airflow Providers: SemVer rules apply to changes in the particular provider's code only.
SemVer MAJOR and MINOR versions for the packages are independent of the Airflow version.
For example,
google 4.1.0andamazon 3.1.1providers can happily be installed withAirflow 2.1.2. If there are limits of cross-dependencies between providers and Airflow packages, they are present in providers asinstall_requireslimitations. We aim to keep backwards compatibility of providers with all previously released Airflow 2 versions but there will sometimes be breaking changes that might make some, or all providers, have minimum Airflow version specified. - Airflow Helm Chart: SemVer rules apply to changes in the chart only. SemVer MAJOR and MINOR versions for the chart are independent of the Airflow version. We aim to keep backwards compatibility of the Helm Chart with all released Airflow 2 versions, but some new features might only work starting from specific Airflow releases. We might however limit the Helm Chart to depend on minimal Airflow version.
- Airflow API clients: Their versioning is independent from Airflow versions. They follow their own SemVer rules for breaking changes and new features - which for example allows to change the way we generate the clients.
Apache Airflow version life cycle:
| Version | Current Patch/Minor | State | First Release | Limited Maintenance | EOL/Terminated |
|---|---|---|---|---|---|
| 3 | 3.1.7 | Maintenance | Apr 22, 2025 | TBD | TBD |
| 2 | 2.11.1 | Limited maintenance | Dec 17, 2020 | Oct 22, 2025 | Apr 22, 2026 |
| 1.10 | 1.10.15 | EOL | Aug 27, 2018 | Dec 17, 2020 | June 17, 2021 |
| 1.9 | 1.9.0 | EOL | Jan 03, 2018 | Aug 27, 2018 | Aug 27, 2018 |
| 1.8 | 1.8.2 | EOL | Mar 19, 2017 | Jan 03, 2018 | Jan 03, 2018 |
| 1.7 | 1.7.1.2 | EOL | Mar 28, 2016 | Mar 19, 2017 | Mar 19, 2017 |
Limited support versions will be supported with security and critical bug fix only. EOL versions will not get any fixes nor support. We always recommend that all users run the latest available minor release for whatever major version is in use. We highly recommend upgrading to the latest Airflow major release at the earliest convenient time and before the EOL date.
As of Airflow 2.0, we agreed to certain rules we follow for Python and Kubernetes support. They are based on the official release schedule of Python and Kubernetes, nicely summarized in the Python Developer's Guide and Kubernetes version skew policy.
-
We drop support for Python and Kubernetes versions when they reach EOL. Except for Kubernetes, a version stays supported by Airflow if two major cloud providers still provide support for it. We drop support for those EOL versions in main right after EOL date, and it is effectively removed when we release the first new MINOR (Or MAJOR if there is no new MINOR version) of Airflow. For example, for Python 3.10 it means that we will drop support in main right after 27.06.2023, and the first MAJOR or MINOR version of Airflow released after will not have it.
-
We support a new version of Python/Kubernetes in main after they are officially released, as soon as we make them work in our CI pipeline (which might not be immediate due to dependencies catching up with new versions of Python mostly) we release new images/support in Airflow based on the working CI setup.
-
This policy is best-effort which means there may be situations where we might terminate support earlier if circumstances require it.
The Airflow Community provides conveniently packaged container images that are published whenever we publish an Apache Airflow release. Those images contain:
- Base OS with necessary packages to install Airflow (stable Debian OS)
- Base Python installation in versions supported at the time of release for the MINOR version of Airflow released (so there could be different versions for 2.3 and 2.2 line for example)
- Libraries required to connect to supported Databases (again the set of databases supported depends on the MINOR version of Airflow)
- Predefined set of popular providers (for details see the Dockerfile).
- Possibility of building your own, custom image where the user can choose their own set of providers and libraries (see Building the image)
- In the future Airflow might also support a "slim" version without providers nor database clients installed
The version of the base OS image is the stable version of Debian. Airflow supports using all currently active stable versions - as soon as all Airflow dependencies support building, and we set up the CI pipeline for building and testing the OS version. Approximately 6 months before the end-of-regular support of a previous stable version of the OS, Airflow switches the images released to use the latest supported version of the OS.
For example switch from Debian Bullseye to Debian Bookworm has been implemented
before 2.8.0 release in October 2023 and Debian Bookworm will be the only option supported as of
Airflow 2.10.0.
Users will continue to be able to build their images using stable Debian releases until the end of regular
support and building and verifying of the images happens in our CI but no unit tests were executed using
this image in the main branch.
Airflow has a lot of dependencies - direct and transitive, also Airflow is both - library and application,
therefore our policies to dependencies has to include both - stability of installation of application,
but also ability to install newer version of dependencies for those users who develop Dags. We developed
the approach where constraints are used to make sure airflow can be installed in a repeatable way, while
we do not limit our users to upgrade most of the dependencies. As a result we decided not to upper-bound
version of Airflow dependencies by default, unless we have good reasons to believe upper-bounding them is
needed because of importance of the dependency as well as risk it involves to upgrade specific dependency.
We also upper-bound the dependencies that we know cause problems.
The constraint mechanism of ours takes care about finding and upgrading all the non-upper bound dependencies
automatically (providing that all the tests pass). Our main build failures will indicate in case there
are versions of dependencies that break our tests - indicating that we should either upper-bind them or
that we should fix our code/tests to account for the upstream changes from those dependencies.
Whenever we upper-bound such a dependency, we should always comment why we are doing it - i.e. we should have a good reason why dependency is upper-bound. And we should also mention what is the condition to remove the binding.
Those dependencies are maintained in pyproject.toml.
There are few dependencies that we decided are important enough to upper-bound them by default, as they are known to follow predictable versioning scheme, and we know that new versions of those are very likely to bring breaking changes. We commit to regularly review and attempt to upgrade to the newer versions of the dependencies as they are released, but this is manual process.
The important dependencies are:
-
SQLAlchemy: upper-bound to specific MINOR version (SQLAlchemy is known to remove deprecations and introduce breaking changes especially that support for different Databases varies and changes at various speed) -
Alembic: it is important to handle our migrations in predictable and performant way. It is developed together with SQLAlchemy. Our experience with Alembic is that it very stable in MINOR version -
Flask: We are using Flask as the back-bone of our web UI and API. We know major version of Flask are very likely to introduce breaking changes across those so limiting it to MAJOR version makes sense -
werkzeug: the library is known to cause problems in new versions. It is tightly coupled with Flask libraries, and we should update them together -
celery: Celery is a crucial component of Airflow as it used for CeleryExecutor (and similar). Celery follows SemVer, so we should upper-bound it to the next MAJOR version. Also, when we bump the upper version of the library, we should make sure Celery Provider minimum Airflow version is updated. -
kubernetes: Kubernetes is a crucial component of Airflow as it is used for the KubernetesExecutor (and similar). Kubernetes Python library follows SemVer, so we should upper-bound it to the next MAJOR version. Also, when we bump the upper version of the library, we should make sure Kubernetes Provider minimum Airflow version is updated.
The main part of the Airflow is the Airflow Core, but the power of Airflow also comes from a number of providers that extend the core functionality and are released separately, even if we keep them (for now) in the same monorepo for convenience. You can read more about the providers in the Providers documentation. We also have set of policies implemented for maintaining and releasing community-managed providers as well as the approach for community vs. 3rd party providers in the providers document.
Those extras and providers dependencies are maintained in provider.yaml of each provider.
By default, we should not upper-bound dependencies for providers, however each provider's maintainer might decide to add additional limits (and justify them with comment).
Want to help build Apache Airflow? Check out our contributors' guide for a comprehensive overview of how to contribute, including setup instructions, coding standards, and pull request guidelines.
If you can't wait to contribute, and want to get started asap, check out the contribution quickstart here!
Official Docker (container) images for Apache Airflow are described in images.
- Commits need a +1 vote from a committer who is not the author
- When we do AIP voting, both PMC member's and committer's
+1sare considered a binding vote.
We know about around 500 organizations that are using Apache Airflow (but there are likely many more) in the wild.
If you use Airflow - feel free to make a PR to add your organisation to the list.
Airflow is the work of the community, but the core committers/maintainers are responsible for reviewing and merging PRs as well as steering conversations around new feature requests. If you would like to become a maintainer, please review the Apache Airflow committer requirements.
Often you will see an issue that is assigned to specific milestone with Airflow version, or a PR that gets merged to the main branch and you might wonder which release the merged PR(s) will be released in or which release the fixed issues will be in. The answer to this is as usual - it depends on various scenarios. The answer is different for PRs and Issues.
To add a bit of context, we are following the Semver versioning scheme as described in
Airflow release process. More
details are explained in detail in this README under the Semantic versioning chapter, but
in short, we have MAJOR.MINOR.PATCH versions of Airflow.
-
MAJORversion is incremented in case of breaking changes -
MINORversion is incremented when there are new features added -
PATCHversion is incremented when there are only bug-fixes and doc-only changes
Generally we release MINOR versions of Airflow from a branch that is named after the MINOR version. For example
2.7.* releases are released from v2-7-stable branch, 2.8.* releases are released from v2-8-stable
branch, etc.
-
Most of the time in our release cycle, when the branch for next
MINORbranch is not yet created, all PRs merged tomain(unless they get reverted), will find their way to the nextMINORrelease. For example if the last release is2.7.3andv2-8-stablebranch is not created yet, the nextMINORrelease is2.8.0and all PRs merged to main will be released in2.8.0. However, some PRs (bug-fixes and doc-only changes) when merged, can be cherry-picked to currentMINORbranch and released in the nextPATCHLEVELrelease. For example, if2.8.1is already released and we are working on2.9.0dev, then marking a PR with2.8.2milestone means that it will be cherry-picked tov2-8-testbranch and released in2.8.2rc1, and eventually in2.8.2. -
When we prepare for the next
MINORrelease, we cut newv2-*-testandv2-*-stablebranch and preparealpha,betareleases for the nextMINORversion, the PRs merged to main will still be released in the nextMINORrelease untilrcversion is cut. This is happening because thev2-*-testandv2-*-stablebranches are rebased on top of main when nextbetaandrcreleases are prepared. For example, when we cut2.10.0beta1version, anything merged to main before2.10.0rc1is released, will find its way to 2.10.0rc1. -
Then, once we prepare the first RC candidate for the MINOR release, we stop moving the
v2-*-testandv2-*-stablebranches and the PRs merged to main will be released in the nextMINORrelease. However, some PRs (bug-fixes and doc-only changes) when merged, can be cherry-picked to currentMINORbranch and released in the nextPATCHLEVELrelease - for example when the last released version fromv2-10-stablebranch is2.10.0rc1, some of the PRs from main can be marked as2.10.0milestone by committers, the release manager will try to cherry-pick them into the release branch. If successful, they will be released in2.10.0rc2and subsequently in2.10.0. This also applies to subsequentPATCHLEVELversions. When for example2.10.1is already released, marking a PR with2.10.2milestone will mean that it will be cherry-picked tov2-10-stablebranch and released in2.10.2rc1and eventually in2.10.2.
The final decision about cherry-picking is made by the release manager.
Marking issues with a milestone is a bit different. Maintainers do not mark issues with a milestone usually, normally they are only marked in PRs. If PR linked to the issue (and "fixing it") gets merged and released in a specific version following the process described above, the issue will be automatically closed, no milestone will be set for the issue, you need to check the PR that fixed the issue to see which version it was released in.
However, sometimes maintainers mark issues with specific milestone, which means that the issue is important to become a candidate to take a look when the release is being prepared. Since this is an Open-Source project, where basically all contributors volunteer their time, there is no guarantee that specific issue will be fixed in specific version. We do not want to hold the release because some issue is not fixed, so in such case release manager will reassign such unfixed issues to the next milestone in case they are not fixed in time for the current release. Therefore, the milestone for issue is more of an intent that it should be looked at, than promise it will be fixed in the version.
More context and FAQ about the patchlevel release can be found in the
What goes into the next release document in the dev folder of the
repository.
Yes! Be sure to abide by the Apache Foundation trademark policies and the Apache Airflow Brandbook. The most up-to-date logos are found in this repo and on the Apache Software Foundation website.
The CI infrastructure for Apache Airflow has been sponsored by:


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for airflow
Similar Open Source Tools
airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
BeamNGpy
BeamNGpy is an official Python library providing an API to interact with BeamNG.tech, a video game focused on academia and industry. It allows remote control of vehicles, AI-controlled vehicles, dynamic sensor models, access to road network and scenario objects, and multiple clients. The library comes with low-level functions and higher-level interfaces for complex actions. BeamNGpy requires BeamNG.tech for usage and offers compatibility information for different versions. It also provides troubleshooting tips and encourages user contributions.

Robyn
Robyn is an experimental, semi-automated and open-sourced Marketing Mix Modeling (MMM) package from Meta Marketing Science. It uses various machine learning techniques to define media channel efficiency and effectivity, explore adstock rates and saturation curves. Built for granular datasets with many independent variables, especially suitable for digital and direct response advertisers with rich data sources. Aiming to democratize MMM, make it accessible for advertisers of all sizes, and contribute to the measurement landscape.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

onnx
Open Neural Network Exchange (ONNX) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types. Currently, we focus on the capabilities needed for inferencing (scoring). ONNX is widely supported and can be found in many frameworks, tools, and hardware, enabling interoperability between different frameworks and streamlining the path from research to production to increase the speed of innovation in the AI community. Join us to further evolve ONNX.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.
modular
The Modular Platform is a unified suite of AI libraries and tools designed for AI development and deployment. It abstracts hardware complexity to enable running popular open models with high GPU and CPU performance without code changes. The repository contains over 450,000 lines of code from 6000+ contributors, making it one of the largest open-source repositories for CPU and GPU kernels. Key components include the Mojo standard library, MAX GPU and CPU kernels, MAX inference server, MAX model pipelines, and code examples. The repository has main and stable branches for nightly builds and stable releases, respectively. Contributions are accepted for the Mojo standard library, MAX AI kernels, code examples, and Mojo docs.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
For similar tasks
airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
rill-flow
Rill Flow is a high-performance, scalable distributed workflow orchestration service that supports the execution of tens of millions of tasks per day with task execution latency less than 100ms. It is distributed and supports the orchestration and scheduling of heterogeneous distributed systems. Rill Flow is easy to use, supporting visual process orchestration and plug-in access. It is cloud native, allowing for cloud native container deployment and cloud native function orchestration. Additionally, Rill Flow supports rapid integration of LLM model services.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
torra-community
Torra Community Edition is a modern AI workflow and intelligent agent visualization editor based on Nuxt 4. It offers a lightweight but production-ready architecture with frontend VueFlow + Tailwind v4 + shadcn/ui, backend FeathersJS, and built-in LangChain.js runtime. It supports multiple databases (SQLite/MySQL/MongoDB) and local ↔ cloud hot switching. The tool covers various tasks such as visual workflow editing, modern UI, native integration of LangChain.js, pluggable storage options, full-stack TypeScript implementation, and more. It is designed for enterprises looking for an easy-to-deploy and scalable solution for AI workflows.
astron-rpa
AstronRPA is an enterprise-grade Robotic Process Automation (RPA) desktop application that supports low-code/no-code development. It enables users to rapidly build workflows and automate desktop software and web pages. The tool offers comprehensive automation support for various applications, highly component-based design, enterprise-grade security and collaboration features, developer-friendly experience, native agent empowerment, and multi-channel trigger integration. It follows a frontend-backend separation architecture with components for system operations, browser automation, GUI automation, AI integration, and more. The tool is deployed via Docker and designed for complex RPA scenarios.
PaiAgent
PaiAgent is an enterprise-level AI workflow visualization orchestration platform that simplifies the combination and scheduling of AI capabilities. It allows developers and business users to quickly build complex AI processing flows through an intuitive drag-and-drop interface, without the need to write code, enabling collaboration of various large models.
MateCat
Matecat is an enterprise-level, web-based CAT tool designed to make post-editing and outsourcing easy and to provide a complete set of features to manage and monitor translation projects.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.