
pyspur
A visual playground for agentic workflows: Iterate over your agents 10x faster
Stars: 4152
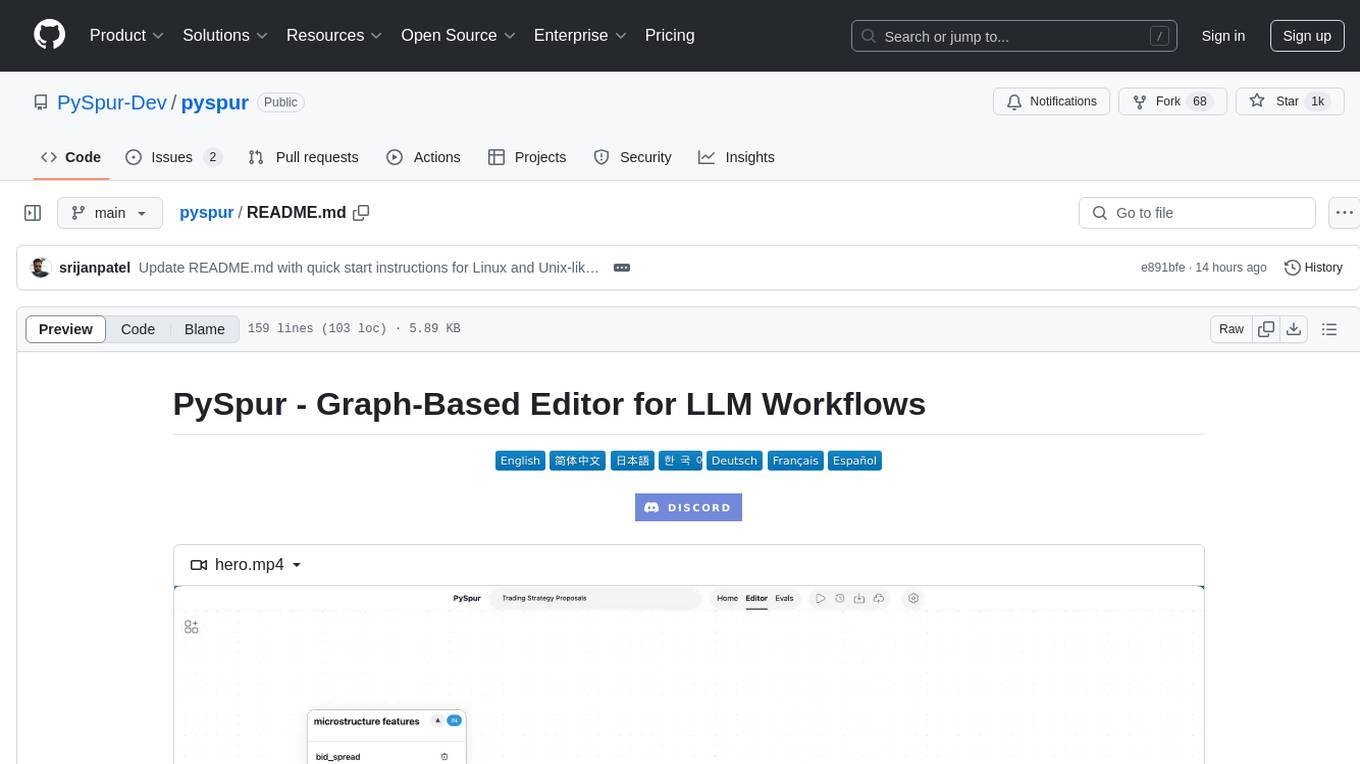
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
README:

Iterate over your agents 10x faster. AI engineers use PySpur to iterate over AI agents visually without reinventing the wheel.
https://github.com/user-attachments/assets/54d0619f-22fd-476c-bf19-9be083d7e710
AI engineers today face three problems of building agents:
- Prompt Hell: Hours of prompt tweaking and trial-and-error frustration.
- Workflow Blindspots: Lack of visibility into step interactions causing hidden failures and confusion.
- Terminal Testing Nightmare Squinting at raw outputs and manually parsing JSON.
We've been there ourselves, too. We launched a graphic design agent early 2024 and quickly reached thousands of users, yet, struggled with the lack of its reliability and existing debugging tools.
https://github.com/user-attachments/assets/ed9ca45f-7346-463f-b8a4-205bf2c4588f
https://github.com/user-attachments/assets/7043aae4-fad1-42bd-953a-80c94fce8253
https://github.com/user-attachments/assets/72c9901d-a39c-4f80-85a5-f6f76e55f473
https://github.com/user-attachments/assets/b14f34b2-9f16-4bd0-8a0f-1c26e690af93
- 👤 Human in the Loop: Persistent workflows that wait for human approval.
- 🔄 Loops: Iterative tool calling with memory.
- 📤 File Upload: Upload files or paste URLs to process documents.
- 📋 Structured Outputs: UI editor for JSON Schemas.
- 🗃️ RAG: Parse, Chunk, Embed, and Upsert Data into a Vector DB.
- 🖼️ Multimodal: Support for Video, Images, Audio, Texts, Code.
- 🧰 Tools: Slack, Firecrawl.dev, Google Sheets, GitHub, and more.
- 📊 Traces: Automatically capture execution traces of deployed agents.
- 🧪 Evals: Evaluate agents on real-world datasets.
- 🚀 One-Click Deploy: Publish as an API and integrate wherever you want.
- 🐍 Python-Based: Add new nodes by creating a single Python file.
- 🎛️ Any-Vendor-Support: >100 LLM providers, embedders, and vector DBs.
This is the quickest way to get started. Python 3.11 or higher is required.
-
Install PySpur:
pip install pyspur
-
Initialize a new project:
pyspur init my-project cd my-projectThis will create a new directory with a
.envfile. -
Start the server:
pyspur serve --sqlite
By default, this will start PySpur app at
http://localhost:6080using a sqlite database. We recommend you configure a postgres instance URL in the.envfile to get a more stable experience. -
[Optional] Configure Your Environment and Add API Keys:
- App UI: Navigate to API Keys tab to add provider keys (OpenAI, Anthropic, etc.)
-
Manual: Edit
.envfile (recommended: configure postgres) and restart withpyspur serve
These breakpoints pause the workflow when reached and resume whenever a human approves it. They enable human oversight for workflows that require quality assurance: verify critical outputs before the workflow proceeds.
https://github.com/user-attachments/assets/98cb2b4e-207c-4d97-965b-4fee47c94ce8
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
PDFs, Videos, Audio, Images, ...
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
We recommend using Cursor/VS Code with our dev container (.devcontainer/devcontainer.json) for:
- Consistent development environment with pre-configured tools and extensions
- Optimized settings for Python and TypeScript development
- Automatic hot-reloading and port forwarding
Option 1: Cursor/VS Code Dev Container (Recommended)
- Install Cursor/VS Code and the Dev Containers extension
- Clone and open the repository
- Click "Reopen in Container" when prompted
Option 2: Manual Setup
-
Clone the repository:
git clone https://github.com/PySpur-com/pyspur.git cd pyspur -
Launch using docker-compose.dev.yml:
docker compose -f docker-compose.dev.yml up --build -d
-
Customize your setup: Edit
.envto configure your environment (e.g., PostgreSQL settings).
Note: Manual setup requires additional configuration and may not include all dev container features.
You can support us in our work by leaving a star! Thank you!
Your feedback will be massively appreciated. Please tell us which features on that list you like to see next or request entirely new ones.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pyspur
Similar Open Source Tools
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
better-chatbot
Better Chatbot is an open-source AI chatbot designed for individuals and teams, inspired by various AI models. It integrates major LLMs, offers powerful tools like MCP protocol and data visualization, supports automation with custom agents and visual workflows, enables collaboration by sharing configurations, provides a voice assistant feature, and ensures an intuitive user experience. The platform is built with Vercel AI SDK and Next.js, combining leading AI services into one platform for enhanced chatbot capabilities.

InsForge
InsForge is a backend development platform designed for AI coding agents and AI code editors. It serves as a semantic layer that enables agents to interact with backend primitives such as databases, authentication, storage, and functions in a meaningful way. The platform allows agents to fetch backend context, configure primitives, and inspect backend state through structured schemas. InsForge facilitates backend context engineering for AI coding agents to understand, operate, and monitor backend systems effectively.

bytebot
Bytebot is an open-source AI desktop agent that provides a virtual employee with its own computer to complete tasks for users. It can use various applications, download and organize files, log into websites, process documents, and perform complex multi-step workflows. By giving AI access to a complete desktop environment, Bytebot unlocks capabilities not possible with browser-only agents or API integrations, enabling complete task autonomy, document processing, and usage of real applications.
Ivy-Framework
Ivy-Framework is a powerful tool for building internal applications with AI assistance using C# codebase. It provides a CLI for project initialization, authentication integrations, database support, LLM code generation, secrets management, container deployment, hot reload, dependency injection, state management, routing, and external widget framework. Users can easily create data tables for sorting, filtering, and pagination. The framework offers a seamless integration of front-end and back-end development, making it ideal for developing robust internal tools and dashboards.
kubewall
kubewall is an open-source, single-binary Kubernetes dashboard with multi-cluster management and AI integration. It provides a simple and rich real-time interface to manage and investigate your clusters. With features like multi-cluster management, AI-powered troubleshooting, real-time monitoring, single-binary deployment, in-depth resource views, browser-based access, search and filter capabilities, privacy by default, port forwarding, live refresh, aggregated pod logs, and clean resource management, kubewall offers a comprehensive solution for Kubernetes cluster management.

LynxHub
LynxHub is a platform that allows users to seamlessly install, configure, launch, and manage all their AI interfaces from a single, intuitive dashboard. It offers features like AI interface management, arguments manager, custom run commands, pre-launch actions, extension management, in-app tools like terminal and web browser, AI information dashboard, Discord integration, and additional features like theme options and favorite interface pinning. The platform supports modular design for custom AI modules and upcoming extensions system for complete customization. LynxHub aims to streamline AI workflow and enhance user experience with a user-friendly interface and comprehensive functionalities.
Roo-Code
Roo Code is an AI-powered development tool that integrates with your code editor to help you generate code from natural language descriptions and specifications, refactor and debug existing code, write and update documentation, answer questions about your codebase, automate repetitive tasks, and utilize MCP servers. It offers different modes such as Code, Architect, Ask, Debug, and Custom Modes to adapt to various tasks and workflows. Roo Code provides tutorial and feature videos, documentation, a YouTube channel, a Discord server, a Reddit community, GitHub issues tracking, and a feature request platform. Users can set up and develop Roo Code locally by cloning the repository, installing dependencies, and running the extension in development mode or by automated/manual VSIX installation. The tool uses changesets for versioning and publishing. Please note that Roo Code, Inc. does not make any representations or warranties regarding the tools provided, and users assume all risks associated with their use.
DeepSeekAI
DeepSeekAI is a browser extension plugin that allows users to interact with AI by selecting text on web pages and invoking the DeepSeek large model to provide AI responses. The extension enhances browsing experience by enabling users to get summaries or answers for selected text directly on the webpage. It features context text selection, API key integration, draggable and resizable window, AI streaming replies, Markdown rendering, one-click copy, re-answer option, code copy functionality, language switching, and multi-turn dialogue support. Users can install the extension from Chrome Web Store or Edge Add-ons, or manually clone the repository, install dependencies, and build the extension. Configuration involves entering the DeepSeek API key in the extension popup window to start using the AI-driven responses.
VibeSurf
VibeSurf is an open-source AI agentic browser that combines workflow automation with intelligent AI agents, offering faster, cheaper, and smarter browser automation. It allows users to create revolutionary browser workflows, run multiple AI agents in parallel, perform intelligent AI automation tasks, maintain privacy with local LLM support, and seamlessly integrate as a Chrome extension. Users can save on token costs, achieve efficiency gains, and enjoy deterministic workflows for consistent and accurate results. VibeSurf also provides a Docker image for easy deployment and offers pre-built workflow templates for common tasks.
CrewAI-Studio
CrewAI Studio is an application with a user-friendly interface for interacting with CrewAI, offering support for multiple platforms and various backend providers. It allows users to run crews in the background, export single-page apps, and use custom tools for APIs and file writing. The roadmap includes features like better import/export, human input, chat functionality, automatic crew creation, and multiuser environment support.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
swift-chat
SwiftChat is a fast and responsive AI chat application developed with React Native and powered by Amazon Bedrock. It offers real-time streaming conversations, AI image generation, multimodal support, conversation history management, and cross-platform compatibility across Android, iOS, and macOS. The app supports multiple AI models like Amazon Bedrock, Ollama, DeepSeek, and OpenAI, and features a customizable system prompt assistant. With a minimalist design philosophy and robust privacy protection, SwiftChat delivers a seamless chat experience with various features like rich Markdown support, comprehensive multimodal analysis, creative image suite, and quick access tools. The app prioritizes speed in launch, request, render, and storage, ensuring a fast and efficient user experience. SwiftChat also emphasizes app privacy and security by encrypting API key storage, minimal permission requirements, local-only data storage, and a privacy-first approach.
local-deep-research
Local Deep Research is a powerful AI-powered research assistant that performs deep, iterative analysis using multiple LLMs and web searches. It can be run locally for privacy or configured to use cloud-based LLMs for enhanced capabilities. The tool offers advanced research capabilities, flexible LLM support, rich output options, privacy-focused operation, enhanced search integration, and academic & scientific integration. It also provides a web interface, command line interface, and supports multiple LLM providers and search engines. Users can configure AI models, search engines, and research parameters for customized research experiences.
For similar tasks
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
rill-flow
Rill Flow is a high-performance, scalable distributed workflow orchestration service that supports the execution of tens of millions of tasks per day with task execution latency less than 100ms. It is distributed and supports the orchestration and scheduling of heterogeneous distributed systems. Rill Flow is easy to use, supporting visual process orchestration and plug-in access. It is cloud native, allowing for cloud native container deployment and cloud native function orchestration. Additionally, Rill Flow supports rapid integration of LLM model services.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
torra-community
Torra Community Edition is a modern AI workflow and intelligent agent visualization editor based on Nuxt 4. It offers a lightweight but production-ready architecture with frontend VueFlow + Tailwind v4 + shadcn/ui, backend FeathersJS, and built-in LangChain.js runtime. It supports multiple databases (SQLite/MySQL/MongoDB) and local ↔ cloud hot switching. The tool covers various tasks such as visual workflow editing, modern UI, native integration of LangChain.js, pluggable storage options, full-stack TypeScript implementation, and more. It is designed for enterprises looking for an easy-to-deploy and scalable solution for AI workflows.
astron-rpa
AstronRPA is an enterprise-grade Robotic Process Automation (RPA) desktop application that supports low-code/no-code development. It enables users to rapidly build workflows and automate desktop software and web pages. The tool offers comprehensive automation support for various applications, highly component-based design, enterprise-grade security and collaboration features, developer-friendly experience, native agent empowerment, and multi-channel trigger integration. It follows a frontend-backend separation architecture with components for system operations, browser automation, GUI automation, AI integration, and more. The tool is deployed via Docker and designed for complex RPA scenarios.
PaiAgent
PaiAgent is an enterprise-level AI workflow visualization orchestration platform that simplifies the combination and scheduling of AI capabilities. It allows developers and business users to quickly build complex AI processing flows through an intuitive drag-and-drop interface, without the need to write code, enabling collaboration of various large models.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.