
rill-flow
Rill Flow is a high-performance, scalable workflow orchestration engine for distributed workloads and LLMs
Stars: 306
Rill Flow is a high-performance, scalable distributed workflow orchestration service that supports the execution of tens of millions of tasks per day with task execution latency less than 100ms. It is distributed and supports the orchestration and scheduling of heterogeneous distributed systems. Rill Flow is easy to use, supporting visual process orchestration and plug-in access. It is cloud native, allowing for cloud native container deployment and cloud native function orchestration. Additionally, Rill Flow supports rapid integration of LLM model services.
README:
Rill Flow is a high-performance, scalable distributed workflow orchestration service with the following core features:
- High performance: Supports the execution of tens of millions of tasks per day, with task execution latency less than 100ms
- Distributed: Supports the orchestration and scheduling of heterogeneous distributed systems
- Ease to use: supports visual process orchestration and plug-in access
- Cloud native: Supports cloud native container deployment and cloud native function orchestration
- AIGC: supports rapid integration of LLM model services
Live Demo (sandbox/sandbox)
Before you begin, ensure that the following tools are installed:
- Environment suitable for OSX/Linux
- Docker
- Docker-Compose
Install Rill Flow services on your local environment using Docker-Compose:
git clone https://github.com/weibocom/rill-flow.gitEnter the Docker directory of the Rill-Flow source code and execute the one-click start command:
cd rill-flow/docker
docker-compose up -dIf your system has Docker Compose V2 installed instead of V1, please use docker compose instead of docker-compose. Check if this is the case by running docker compose version. Read more information here.
To check the status of Rill Flow, please execute the following command:
docker-compose psHere is the expected output:
Name Command State Ports
------------------------------------------------------------------------------------------------------------------------------------------------------------
rill-flow-mysql docker-entrypoint.sh --bin ... Up 0.0.0.0:3306->3306/tcp, 33060/tcp
rillflow_cache_1 docker-entrypoint.sh redis ... Up 6379/tcp
rillflow_jaeger_1 /go/bin/all-in-one-linux Up 14250/tcp, 14268/tcp, 0.0.0.0:16686->16686/tcp, 5775/udp, 5778/tcp, 6831/udp, 6832/udp
rillflow_rill-flow_1 catalina.sh run Up 0.0.0.0:8080->8080/tcp
rillflow_sample-executor_1 uvicorn main:app --host 0. ... Up
rillflow_ui_1 /docker-entrypoint.sh /bin ... Up 0.0.0.0:80->80/tcpIf your actual output matches the expected output, it means that Rill Flow has been successfully installed.
After the command is successfully executed, you can access the Rill Flow management background at http://localhost (admin/admin). If the server is deployed, use the server IP address for access (port 80 by default).
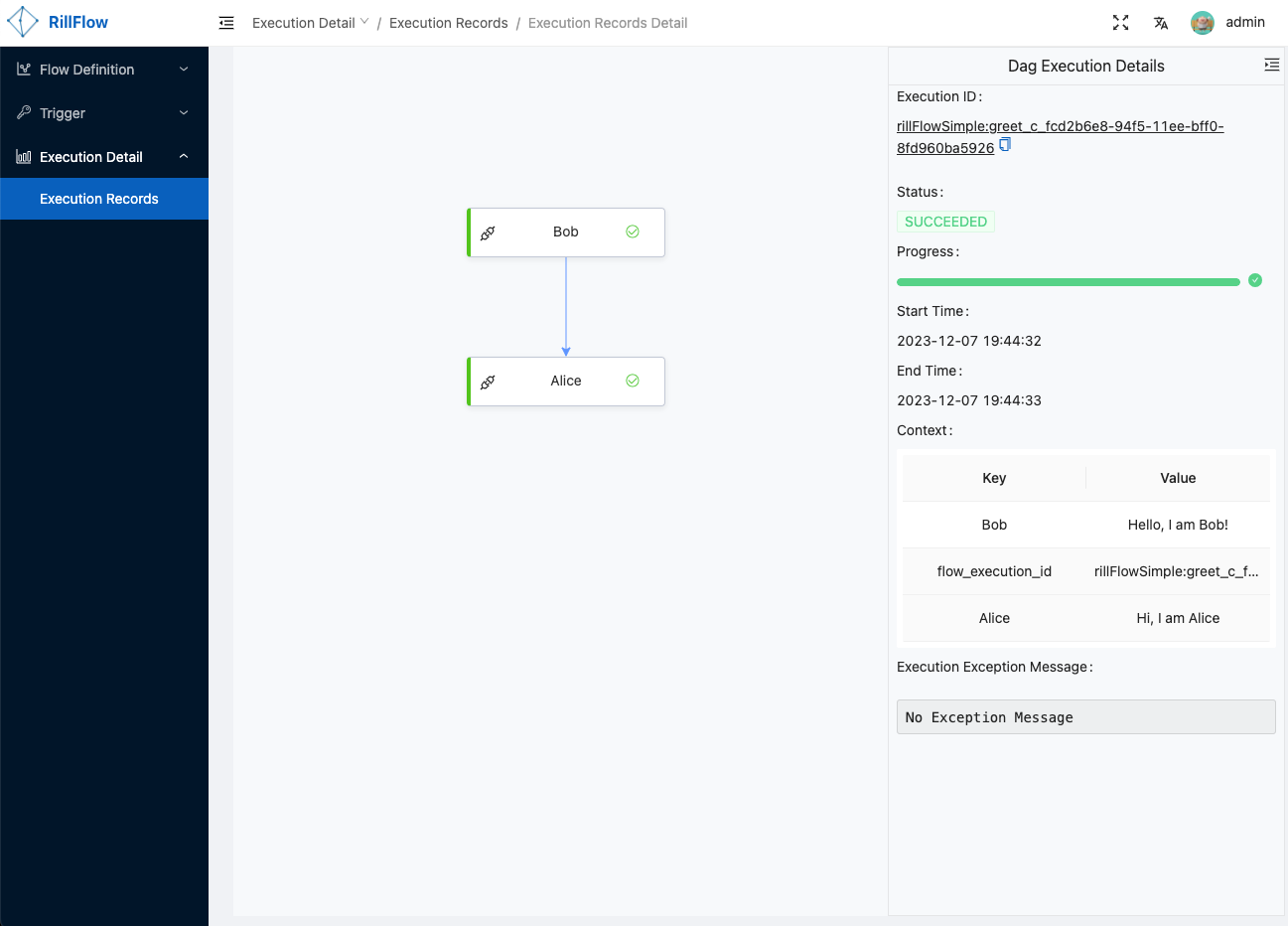
- Step 1: Open the Rill Flow management background, click the 'Flow Definition' menu, enter the 'Flow Definition List' page, click the 'Create' button
- Step 2: After entering the 'Flow Graph Edit' page, open the 'one-click import' switch, copy the following yaml file content into the text box, click the 'Submit' button, you can submit a simple flowchart.
version: 1.0.0
workspace: rillFlowSimple
dagName: greet
alias: release
type: flow
inputSchema: >-
[{"required":true,"name":"Bob","type":"String"},{"required":true,"name":"Alice","type":"String"}]
tasks:
- category: function
name: Bob
resourceName: http://sample-executor:8000/greet.json?user=Bob
pattern: task_sync
tolerance: false
next: Alice
inputMappings:
- source: "$.context.Bob"
target: "$.input.Bob"
- category: function
name: Alice
resourceName: http://sample-executor:8000/greet.json?user=Alice
pattern: task_sync
tolerance: false
inputMappings:
- source: "$.context.Alice"
target: "$.input.Alice"- Step 3: Submit the flow graph to execute the task
Click the 'Test' button, fill in the required parameters, and click the 'Submit' button.
- Step 4: Viewing the execution Result Click the 'Submit' button in the previous step and you will automatically jump to the execution details page. You can view the execution status and details by clicking the 'Execution Records' button.
More instructions on viewing results can be found in Execution Status
The following are contributors to the project along with their GitHub links:
- axb (@qdaxb) Maintainer
- techlog (@techloghub) Maintainer
- ch15084 (@ch15084) Maintainer
- Ocean (@hhh041)
- xilong-t (@xilong-t)
- qfl (@qiaofenlin)
- Kylen (@Kylen)
- zzfzzf (@zzfzzf)
- feifei (@feifei325)
- moqimoqidea (@moqimoqidea)
- Guo, Jiansheng (@guojiansheng0925)
Rill Flow is an open-source project under the Apache License 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rill-flow
Similar Open Source Tools
rill-flow
Rill Flow is a high-performance, scalable distributed workflow orchestration service that supports the execution of tens of millions of tasks per day with task execution latency less than 100ms. It is distributed and supports the orchestration and scheduling of heterogeneous distributed systems. Rill Flow is easy to use, supporting visual process orchestration and plug-in access. It is cloud native, allowing for cloud native container deployment and cloud native function orchestration. Additionally, Rill Flow supports rapid integration of LLM model services.

kaito
KAITO is an operator that automates the AI/ML model inference or tuning workload in a Kubernetes cluster. It manages large model files using container images, provides preset configurations to avoid adjusting workload parameters based on GPU hardware, supports popular open-sourced inference runtimes, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry. Using KAITO simplifies the workflow of onboarding large AI inference models in Kubernetes.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.

arbigent
Arbigent (Arbiter-Agent) is an AI agent testing framework designed to make AI agent testing practical for modern applications. It addresses challenges faced by traditional UI testing frameworks and AI agents by breaking down complex tasks into smaller, dependent scenarios. The framework is customizable for various AI providers, operating systems, and form factors, empowering users with extensive customization capabilities. Arbigent offers an intuitive UI for scenario creation and a powerful code interface for seamless test execution. It supports multiple form factors, optimizes UI for AI interaction, and is cost-effective by utilizing models like GPT-4o mini. With a flexible code interface and open-source nature, Arbigent aims to revolutionize AI agent testing in modern applications.
RooFlow
RooFlow is a VS Code extension that enhances AI-assisted development by providing persistent project context and optimized mode interactions. It reduces token consumption and streamlines workflow by integrating Architect, Code, Test, Debug, and Ask modes. The tool simplifies setup, offers real-time updates, and provides clearer instructions through YAML-based rule files. It includes components like Memory Bank, System Prompts, VS Code Integration, and Real-time Updates. Users can install RooFlow by downloading specific files, placing them in the project structure, and running an insert-variables script. They can then start a chat, select a mode, interact with Roo, and use the 'Update Memory Bank' command for synchronization. The Memory Bank structure includes files for active context, decision log, product context, progress tracking, and system patterns. RooFlow features persistent context, real-time updates, mode collaboration, and reduced token consumption.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
fastagency
FastAgency is an open-source framework designed to accelerate the transition from prototype to production for multi-agent AI workflows. It provides a unified programming interface for deploying agentic workflows written in AG2 agentic framework in both development and productional settings. With features like seamless external API integration, a Tester Class for continuous integration, and a Command-Line Interface (CLI) for orchestration, FastAgency streamlines the deployment process, saving time and effort while maintaining flexibility and performance. Whether orchestrating complex AI agents or integrating external APIs, FastAgency helps users quickly transition from concept to production, reducing development cycles and optimizing multi-agent systems.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.
llm-d-inference-sim
The `llm-d-inference-sim` is a lightweight, configurable, and real-time simulator designed to mimic the behavior of vLLM without the need for GPUs or running heavy models. It operates as an OpenAI-compliant server, allowing developers to test clients, schedulers, and infrastructure using realistic request-response cycles, token streaming, and latency patterns. The simulator offers modes of operation, response generation from predefined text or real datasets, latency simulation, tokenization options, LoRA management, KV cache simulation, failure injection, and deployment options for standalone or Kubernetes testing. It supports a subset of standard vLLM Prometheus metrics for observability.

AIOS
AIOS, a Large Language Model (LLM) Agent operating system, embeds large language model into Operating Systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, maintain access control for agents, and provide a rich set of toolkits for LLM Agent developers.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
For similar tasks

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
rill-flow
Rill Flow is a high-performance, scalable distributed workflow orchestration service that supports the execution of tens of millions of tasks per day with task execution latency less than 100ms. It is distributed and supports the orchestration and scheduling of heterogeneous distributed systems. Rill Flow is easy to use, supporting visual process orchestration and plug-in access. It is cloud native, allowing for cloud native container deployment and cloud native function orchestration. Additionally, Rill Flow supports rapid integration of LLM model services.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
torra-community
Torra Community Edition is a modern AI workflow and intelligent agent visualization editor based on Nuxt 4. It offers a lightweight but production-ready architecture with frontend VueFlow + Tailwind v4 + shadcn/ui, backend FeathersJS, and built-in LangChain.js runtime. It supports multiple databases (SQLite/MySQL/MongoDB) and local ↔ cloud hot switching. The tool covers various tasks such as visual workflow editing, modern UI, native integration of LangChain.js, pluggable storage options, full-stack TypeScript implementation, and more. It is designed for enterprises looking for an easy-to-deploy and scalable solution for AI workflows.
astron-rpa
AstronRPA is an enterprise-grade Robotic Process Automation (RPA) desktop application that supports low-code/no-code development. It enables users to rapidly build workflows and automate desktop software and web pages. The tool offers comprehensive automation support for various applications, highly component-based design, enterprise-grade security and collaboration features, developer-friendly experience, native agent empowerment, and multi-channel trigger integration. It follows a frontend-backend separation architecture with components for system operations, browser automation, GUI automation, AI integration, and more. The tool is deployed via Docker and designed for complex RPA scenarios.
PaiAgent
PaiAgent is an enterprise-level AI workflow visualization orchestration platform that simplifies the combination and scheduling of AI capabilities. It allows developers and business users to quickly build complex AI processing flows through an intuitive drag-and-drop interface, without the need to write code, enabling collaboration of various large models.
Tiktok_Automation_Bot
TikTok Automation Bot is an Appium-based tool for automating TikTok account creation and video posting on real devices. It offers functionalities such as automated account creation and video posting, along with integrations like Crane tweak, SMSActivate service, and IPQualityScore service. The tool also provides device and automation management system, anti-bot system for human behavior modeling, and IP rotation system for different IP addresses. It is designed to simplify the process of managing TikTok accounts and posting videos efficiently.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.