
codellm-devkit
codellm-devkit provides unified language to get off-the-shelf static analysis for multiple programming languages and support for applying those analyses for code LLM use cases.
Stars: 58

Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
README:

Codellm-devkit (CLDK) is a multilingual program analysis framework that bridges the gap between traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). Codellm-devkit allows developers to streamline the process of transforming raw code into actionable insights by providing a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs.
Codellm-devkit simplifies the complex process of analyzing codebases that span multiple programming languages, making it easier to extract meaningful insights and drive LLM-based code analysis. CLDK achieves this through an open-source Python library that abstracts the intricacies of program analysis and LLM interactions. With this library, developer can streamline the process of transforming raw code into actionable insights by providing a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs.
The purpose of Codellm-devkit is to enable the development and experimentation of robust analysis pipelines that harness the power of both traditional program analysis tools and CodeLLMs. By providing a consistent and extensible framework, Codellm-devkit aims to reduce the friction associated with multi-language code analysis and ensure compatibility across different analysis tools and LLM platforms.
Codellm-devkit is designed to integrate seamlessly with a variety of popular analysis tools, such as WALA, Tree-sitter, LLVM, and CodeQL, each implemented in different languages. Codellm-devkit acts as a crucial intermediary layer, enabling efficient and consistent communication between these tools and the CodeLLMs.
Codellm-devkit is constantly evolving to include new tools and frameworks, ensuring it remains a versatile solution for code analysis and LLM integration.
Codellm-devkit is:
- Unified: Provides a single framework for integrating multiple analysis tools and CodeLLMs, regardless of the programming languages involved.
- Extensible: Designed to support new analysis tools and LLM platforms, making it adaptable to the evolving landscape of code analysis.
- Streamlined: Simplifies the process of transforming raw code into structured, LLM-ready inputs, reducing the overhead typically associated with multi-language analysis.
Codellm-devkit is an ongoing project, developed at IBM Research.
For any questions, feedback, or suggestions, please contact the authors:
| Name | |
|---|---|
| Rahul Krishna | [email protected] |
| Rangeet Pan | [email protected] |
| Saurabh Sihna | [email protected] |
- CodeLLM-Devkit: A Python library for seamless interaction with CodeLLMs
Below is a very high-level overview of the architectural of CLDK:
graph TD
User <--> A[CLDK]
A --> 15[Retrieval ‡]
A --> 16[Prompting ‡]
A[CLDK] <--> B[Languages]
B --> C[Java, Python, Go ‡, C ‡, JavaScript ‡, TypeScript ‡, Rust ‡]
C --> D[Data Models]
D --> 13{Pydantic}
13 --> 7
C --> 7{backends}
7 <--> 9[WALA]
9 <--> 14[Analysis]
7 <--> 10[Tree-sitter]
10 <--> 14[Analysis]
7 <--> 11[LLVM ‡]
11 <--> 14[Analysis]
7 <--> 12[CodeQL ‡]
12 <--> 14[Analysis]
X[‡ Yet to be implemented]The user interacts by invoking the CLDK API. The CLDK API is responsible for handling the user requests and delegating them to the appropriate language-specific modules.
Each language comprises of two key components: data models and backends.
-
Data Models: These are high level abstractions that represent the various language constructs and componentes in a structured format using pydantic. This confers a high degree of flexibility and extensibility to the models as well as allowing for easy accees of various data components via a simple dot notation. In addition, the data models are designed to be easily serializable and deserializable, making it easy to store and retrieve data from various sources.
-
Analysis Backends: These are the components that are responsible for interfacing with the various program analysis tools. The core backends are Treesitter, Javaparse, WALA, LLVM, and CodeQL. The backends are responsible for handling the user requests and delegating them to the appropriate analysis tools. The analysis tools perfrom the requisite analysis and return the results to the user. The user merely calls one of several high-level API functions such as
get_method_body,get_method_signature,get_call_graph, etc. and the backend takes care of the rest.Some langugages may have multiple backends. For example, Java has WALA, Javaparser, Treesitter, and CodeQL backends. The user has freedom to choose the backend that best suits their needs.
We are currently working on implementing the retrieval and prompting components. The retrieval component will be responsible for retrieving the relevant code snippets from the codebase for RAG usecases. The prompting component will be responsible for generating the prompts for the CodeLLMs using popular prompting frameworks such as PDL, Guidance, or LMQL.
In this section, we will walk through a simple example to demonstrate how to use CLDK. We will:
- Set up a local ollama server to interact with CodeLLMs
- Build a simple code summarization pipeline for a Java and a Python application.
Before we begin, make sure you have the following prerequisites installed:
- Python 3.11 or later
- Ollama v0.3.4 or later
If don't already have ollama, please download and install it from here: Ollama.
Once you have ollama, start the server and make sure it is running.
If you're on MacOS, Linux, or WSL, you can check to make sure the server is running by running the following command:
sudo systemctl status ollamaYou should see an output similar to the following:
➜ sudo systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Active: active (running) since Sat 2024-08-10 20:39:56 EDT; 17s ago
Main PID: 23069 (ollama)
Tasks: 19 (limit: 76802)
Memory: 1.2G (peak: 1.2G)
CPU: 6.745s
CGroup: /system.slice/ollama.service
└─23069 /usr/local/bin/ollama serveIf not, you may have to start the server manually. You can do this by running the following command:
sudo systemctl start ollamaTo pull the latest version of the Granite 8b instruct model from ollama, run the following command:
ollama pull granite-code:8b-instructCheck to make sure the model was successfully pulled by running the following command:
ollama run granite-code:8b-instruct 'Write a function to print hello world in python'The output should be similar to the following:
➜ ollama run granite-code:8b-instruct 'Write a function to print hello world in python'
def say_hello():
print("Hello World!")
You may install the latest version of CLDK from PyPi:
pip install cldkOnce CLDK is installed, you can import it into your Python code:
from cldk import CLDKNow that we have set up the ollama server and installed CLDK, we can build a simple code summarization pipeline for a Java application.
-
Let's download a sample Java (apache-commons-cli):
- Download and unzip the sample Java application:
wget https://github.com/apache/commons-cli/archive/refs/tags/rel/commons-cli-1.7.0.zip -O commons-cli-1.7.0.zip && unzip commons-cli-1.7.0.zip - Record the path to the sample Java application:
export JAVA_APP_PATH=/path/to/commons-cli-1.7.0
- Download and unzip the sample Java application:
Below is a simple code summarization pipeline for a Java application using CLDK. It does the following things:
- Creates a new instance of the CLDK class (see comment
# (1)) - Creates an analysis object over the Java application (see comment
# (2)) - Iterates over all the files in the project (see comment
# (3)) - Iterates over all the classes in the file (see comment
# (4)) - Iterates over all the methods in the class (see comment
# (5)) - Gets the code body of the method (see comment
# (6)) - Initializes the treesitter utils for the class file content (see comment
# (7)) - Sanitizes the class for analysis (see comment
# (8)) - Formats the instruction for the given focal method and class (see comment
# (9)) - Prompts the local model on Ollama (see comment
# (10)) - Prints the instruction and LLM output (see comment
# (11))
# code_summarization_for_java.py
from cldk import CLDK
def format_inst(code, focal_method, focal_class):
"""
Format the instruction for the given focal method and class.
"""
inst = f"Question: Can you write a brief summary for the method `{focal_method}` in the class `{focal_class}` below?\n"
inst += "\n"
inst += f"```{language}\n"
inst += code
inst += "```" if code.endswith("\n") else "\n```"
inst += "\n"
return inst
def prompt_ollama(message: str, model_id: str = "granite-code:8b-instruct") -> str:
"""Prompt local model on Ollama"""
response_object = ollama.generate(model=model_id, prompt=message)
return response_object["response"]
if __name__ == "__main__":
# (1) Create a new instance of the CLDK class
cldk = CLDK(language="java")
# (2) Create an analysis object over the java application
analysis = cldk.analysis(project_path=os.getenv("JAVA_APP_PATH"))
# (3) Iterate over all the files in the project
for file_path, class_file in analysis.get_symbol_table().items():
class_file_path = Path(file_path).absolute().resolve()
# (4) Iterate over all the classes in the file
for type_name, type_declaration in class_file.type_declarations.items():
# (5) Iterate over all the methods in the class
for method in type_declaration.callable_declarations.values():
# (6) Get code body of the method
code_body = class_file_path.read_text()
# (7) Initialize the treesitter utils for the class file content
tree_sitter_utils = cldk.tree_sitter_utils(source_code=code_body)
# (8) Sanitize the class for analysis
sanitized_class = tree_sitter_utils.sanitize_focal_class(method.declaration)
# (9) Format the instruction for the given focal method and class
instruction = format_inst(
code=sanitized_class,
focal_method=method.declaration,
focal_class=type_name,
)
# (10) Prompt the local model on Ollama
llm_output = prompt_ollama(
message=instruction,
model_id="granite-code:20b-instruct",
)
# (11) Print the instruction and LLM output
print(f"Instruction:\n{instruction}")
print(f"LLM Output:\n{llm_output}")- Krishna, Rahul, Rangeet Pan, Raju Pavuluri, Srikanth Tamilselvam, Maja Vukovic, and Saurabh Sinha. "Codellm-Devkit: A Framework for Contextualizing Code LLMs with Program Analysis Insights." arXiv preprint arXiv:2410.13007 (2024).
- Pan, Rangeet, Myeongsoo Kim, Rahul Krishna, Raju Pavuluri, and Saurabh Sinha. "Multi-language Unit Test Generation using LLMs." arXiv preprint arXiv:2409.03093 (2024).
- Pan, Rangeet, Rahul Krishna, Raju Pavuluri, Saurabh Sinha, and Maja Vukovic., "Simplify your Code LLM solutions using CodeLLM Dev Kit (CLDK).", Blog.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for codellm-devkit
Similar Open Source Tools
codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
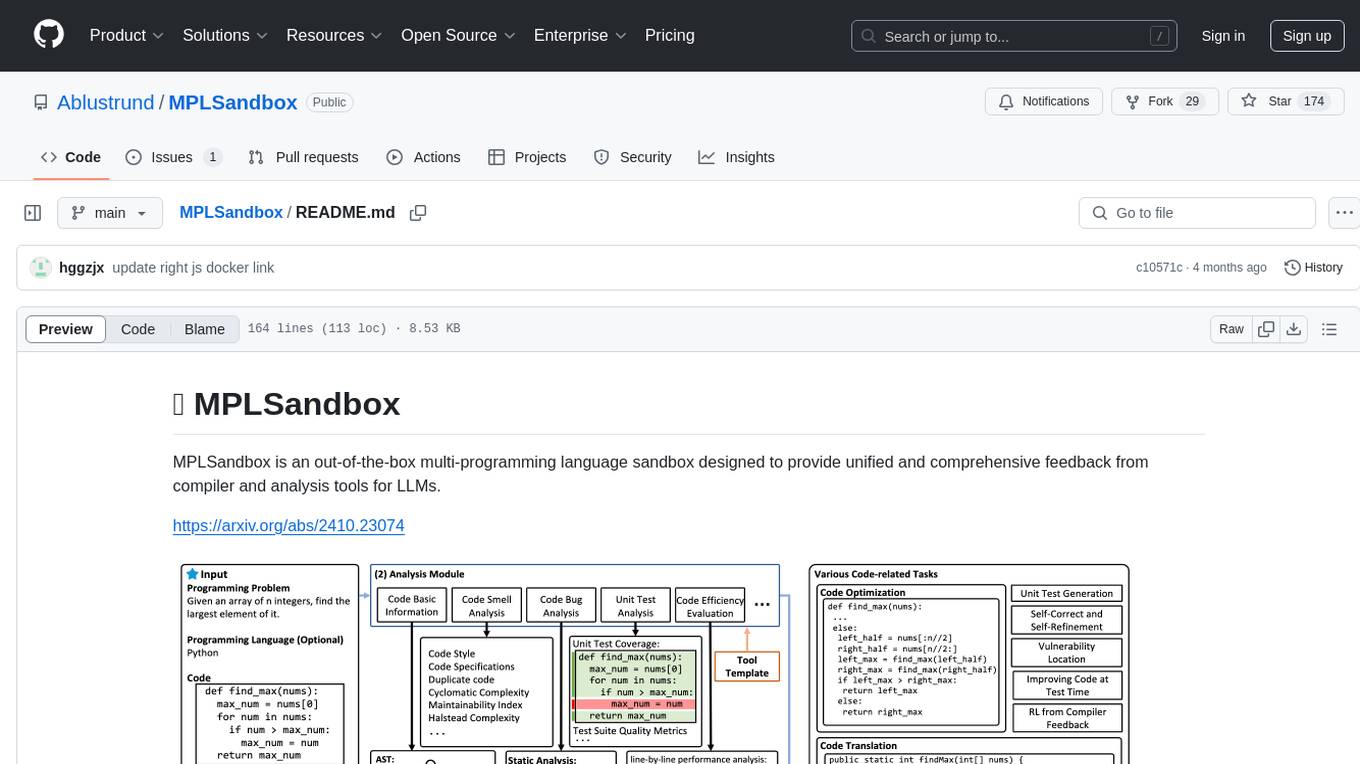
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

neuron-ai
Neuron AI is a PHP framework that provides an Agent class for creating fully functional agents to perform tasks like analyzing text for SEO optimization. The framework manages advanced mechanisms such as memory, tools, and function calls. Users can extend the Agent class to create custom agents and interact with them to get responses based on the underlying LLM. Neuron AI aims to simplify the development of AI-powered applications by offering a structured framework with documentation and guidelines for contributions under the MIT license.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.
For similar tasks
Awesome-LLM4EDA
LLM4EDA is a repository dedicated to showcasing the emerging progress in utilizing Large Language Models for Electronic Design Automation. The repository includes resources, papers, and tools that leverage LLMs to solve problems in EDA. It covers a wide range of applications such as knowledge acquisition, code generation, code analysis, verification, and large circuit models. The goal is to provide a comprehensive understanding of how LLMs can revolutionize the EDA industry by offering innovative solutions and new interaction paradigms.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
SinkFinder
SinkFinder + LLM is a closed-source semi-automatic vulnerability discovery tool that performs static code analysis on jar/war/zip files. It enhances the capability of LLM large models to verify path reachability and assess the trustworthiness score of the path based on the contextual code environment. Users can customize class and jar exclusions, depth of recursive search, and other parameters through command-line arguments. The tool generates rule.json configuration file after each run and requires configuration of the DASHSCOPE_API_KEY for LLM capabilities. The tool provides detailed logs on high-risk paths, LLM results, and other findings. Rules.json file contains sink rules for various vulnerability types with severity levels and corresponding sink methods.
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
air
air is an R formatter and language server written in Rust. It is currently in alpha stage, so users should expect breaking changes in both the API and formatting results. The tool draws inspiration from various sources like roslyn, swift, rust-analyzer, prettier, biome, and ruff. It provides formatters and language servers, influenced by design decisions from these tools. Users can install air using standalone installers for macOS, Linux, and Windows, which automatically add air to the PATH. Developers can also install the dev version of the air CLI and VS Code extension for further customization and development.
code-graph
Code-graph is a tool composed of FalkorDB Graph DB, Code-Graph-Backend, and Code-Graph-Frontend. It allows users to store and query graphs, manage backend logic, and interact with the website. Users can run the components locally by setting up environment variables and installing dependencies. The tool supports analyzing C & Python source files with plans to add support for more languages in the future. It provides a local repository analysis feature and a live demo accessible through a web browser.
For similar jobs
code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe is fully local, keeping code on the user's machine without relying on external APIs. It supports multiple languages, offers various search options, and can be used in CLI mode, MCP server mode, AI chat mode, and web interface. The tool is designed to be flexible, fast, and accurate, providing developers and AI models with full context and relevant code blocks for efficient code exploration and understanding.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.
code-assistant
Code Assistant is an AI coding tool built in Rust that offers command-line and graphical interfaces for autonomous code analysis and modification. It supports multi-modal tool execution, real-time streaming interface, session-based project management, multiple interface options, and intelligent project exploration. The tool provides auto-loaded repository guidance and allows for project configuration with format-on-save feature. Users can interact with the tool in GUI, terminal, or MCP server mode, and configure LLM providers for advanced options. The architecture highlights adaptive tool syntax, smart tool filtering, and multi-threaded streaming for efficient performance. Contributions are welcome, and the roadmap includes features like block replacing in changed files, compact tool use failures, UI improvements, memory tools, security enhancements, fuzzy matching search blocks, editing user messages, and selecting in messages.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe supports various features like AI-friendly code extraction, fully local operation without external APIs, fast scanning of large codebases, accurate code structure parsing, re-rankers and NLP methods for better search results, multi-language support, interactive AI chat mode, and flexibility to run as a CLI tool, MCP server, or interactive AI chat.
GitVizz
GitVizz is an AI-powered repository analysis tool that helps developers understand and navigate codebases quickly. It transforms complex code structures into interactive documentation, dependency graphs, and intelligent conversations. With features like interactive dependency graphs, AI-powered code conversations, advanced code visualization, and automatic documentation generation, GitVizz offers instant understanding and insights for any repository. The tool is built with modern technologies like Next.js, FastAPI, and OpenAI, making it scalable and efficient for analyzing large codebases. GitVizz also provides a standalone Python library for core code analysis and dependency graph generation, offering multi-language parsing, AST analysis, dependency graphs, visualizations, and extensibility for custom applications.