
cuvs
cuVS - a library for vector search and clustering on the GPU
Stars: 524
cuVS is a library that contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.
README:
[!note] cuVS is a new library mostly derived from the approximate nearest neighbors and clustering algorithms in the RAPIDS RAFT library of machine learning and data mining primitives. As of version 24.10 (Release in October 2024), cuVS contains the most fully-featured versions of the approximate nearest neighbors and clustering algorithms from RAFT. The algorithms which have been migrated over to cuVS will be removed from RAFT in version 24.12 (released in December 2024).
- Documentation: Library documentation.
- Build and Install Guide: Instructions for installing and building cuVS.
- Getting Started Guide: Guide to getting started with cuVS.
- Code Examples: Self-contained Code Examples.
- API Reference Documentation: API Documentation.
- RAPIDS Community: Get help, contribute, and collaborate.
- GitHub repository: Download the cuVS source code.
- Issue tracker: Report issues or request features.
cuVS contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.
Vector search is an information retrieval method that has been growing in popularity over the past few years, partly because of the rising importance of multimedia embeddings created from unstructured data and the need to perform semantic search on the embeddings to find items which are semantically similar to each other.
Vector search is also used in data mining and machine learning tasks and comprises an important step in many clustering and visualization algorithms like UMAP, t-SNE, K-means, and HDBSCAN.
Finally, faster vector search enables interactions between dense vectors and graphs. Converting a pile of dense vectors into nearest neighbors graphs unlocks the entire world of graph analysis algorithms, such as those found in GraphBLAS and cuGraph.
Below are some common use-cases for vector search
-
- Generative AI & Retrieval augmented generation (RAG)
- Recommender systems
- Computer vision
- Image search
- Text search
- Audio search
- Molecular search
- Model training
-
- Clustering algorithms
- Visualization algorithms
- Sampling algorithms
- Class balancing
- Ensemble methods
- k-NN graph construction
There are several benefits to using cuVS and GPUs for vector search, including
- Fast index build
- Latency critical and high throughput search
- Parameter tuning
- Cost savings
- Interoperability (build on GPU, deploy on CPU)
- Multiple language support
- Building blocks for composing new or accelerating existing algorithms
In addition to the items above, cuVS takes on the burden of keeping non-trivial accelerated code up to date as new NVIDIA architectures and CUDA versions are released. This provides a delightful development experience, guaranteeing that any libraries, databases, or applications built on top of it will always be getting the best performance and scale.
cuVS is built on top of the RAPIDS RAFT library of high performance machine learning primitives and provides all the necessary routines for vector search and clustering on the GPU.

cuVS comes with pre-built packages that can be installed through conda and pip. Different packages are available for the different languages supported by cuVS:
| Python | C/C++ |
|---|---|
cuvs |
libcuvs |
It is recommended to use mamba to install the desired packages. The following command will install the Python package. You can substitute cuvs for any of the packages in the table above:
conda install -c rapidsai -c conda-forge cuvsThe cuVS Python package can also be installed through pip <https://docs.rapids.ai/install#pip>_.
# CUDA 13
pip install cuvs-cu13 --extra-index-url=https://pypi.nvidia.com
# CUDA 12
pip install cuvs-cu12 --extra-index-url=https://pypi.nvidia.comIf installing a version that has not yet been released, the rapidsai channel can be replaced with rapidsai-nightly:
# CUDA 13
conda install -c rapidsai-nightly -c conda-forge cuvs=25.10 cuda-version=13.0
# CUDA 12
conda install -c rapidsai-nightly -c conda-forge cuvs=25.10 cuda-version=12.9cuVS also has pip wheel packages that can be installed. Please see the Build and Install Guide for more information on installing the available cuVS packages and building from source.
The following code snippets train an approximate nearest neighbors index for the CAGRA algorithm in the various different languages supported by cuVS.
from cuvs.neighbors import cagra
dataset = load_data()
index_params = cagra.IndexParams()
index = cagra.build(build_params, dataset)#include <cuvs/neighbors/cagra.hpp>
using namespace cuvs::neighbors;
raft::device_matrix_view<float> dataset = load_dataset();
raft::device_resources res;
cagra::index_params index_params;
auto index = cagra::build(res, index_params, dataset);For more code examples of the C++ APIs, including drop-in Cmake project templates, please refer to the C++ examples directory in the codebase.
#include <cuvs/neighbors/cagra.h>
cuvsResources_t res;
cuvsCagraIndexParams_t index_params;
cuvsCagraIndex_t index;
DLManagedTensor *dataset;
load_dataset(dataset);
cuvsResourcesCreate(&res);
cuvsCagraIndexParamsCreate(&index_params);
cuvsCagraIndexCreate(&index);
cuvsCagraBuild(res, index_params, dataset, index);
cuvsCagraIndexDestroy(index);
cuvsCagraIndexParamsDestroy(index_params);
cuvsResourcesDestroy(res);For more code examples of the C APIs, including drop-in Cmake project templates, please refer to the C examples
use cuvs::cagra::{Index, IndexParams, SearchParams};
use cuvs::{ManagedTensor, Resources, Result};
use ndarray::s;
use ndarray_rand::rand_distr::Uniform;
use ndarray_rand::RandomExt;
/// Example showing how to index and search data with CAGRA
fn cagra_example() -> Result<()> {
let res = Resources::new()?;
// Create a new random dataset to index
let n_datapoints = 65536;
let n_features = 512;
let dataset =
ndarray::Array::<f32, _>::random((n_datapoints, n_features), Uniform::new(0., 1.0));
// build the cagra index
let build_params = IndexParams::new()?;
let index = Index::build(&res, &build_params, &dataset)?;
println!(
"Indexed {}x{} datapoints into cagra index",
n_datapoints, n_features
);
// use the first 4 points from the dataset as queries : will test that we get them back
// as their own nearest neighbor
let n_queries = 4;
let queries = dataset.slice(s![0..n_queries, ..]);
let k = 10;
// CAGRA search API requires queries and outputs to be on device memory
// copy query data over, and allocate new device memory for the distances/ neighbors
// outputs
let queries = ManagedTensor::from(&queries).to_device(&res)?;
let mut neighbors_host = ndarray::Array::<u32, _>::zeros((n_queries, k));
let neighbors = ManagedTensor::from(&neighbors_host).to_device(&res)?;
let mut distances_host = ndarray::Array::<f32, _>::zeros((n_queries, k));
let distances = ManagedTensor::from(&distances_host).to_device(&res)?;
let search_params = SearchParams::new()?;
index.search(&res, &search_params, &queries, &neighbors, &distances)?;
// Copy back to host memory
distances.to_host(&res, &mut distances_host)?;
neighbors.to_host(&res, &mut neighbors_host)?;
// nearest neighbors should be themselves, since queries are from the
// dataset
println!("Neighbors {:?}", neighbors_host);
println!("Distances {:?}", distances_host);
Ok(())
}For more code examples of the Rust APIs, including a drop-in project templates, please refer to the Rust examples.
If you are interested in contributing to the cuVS library, please read our Contributing guidelines. Refer to the Developer Guide for details on the developer guidelines, workflows, and principles.
For the interested reader, many of the accelerated implementations in cuVS are also based on research papers which can provide a lot more background. We also ask you to please cite the corresponding algorithms by referencing them in your own research.
- CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search
- Top-K Algorithms on GPU: A Comprehensive Study and New Methods
- Fast K-NN Graph Construction by GPU Based NN-Descent
- cuSLINK: Single-linkage Agglomerative Clustering on the GPU
- GPU Semiring Primitives for Sparse Neighborhood Methods
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cuvs
Similar Open Source Tools
cuvs
cuVS is a library that contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.
zipnn
ZipNN is a lossless and near-lossless compression library optimized for numbers/tensors in the Foundation Models environment. It automatically prepares data for compression based on its type, allowing users to focus on core tasks without worrying about compression complexities. The library delivers effective compression techniques for different data types and structures, achieving high compression ratios and rates. ZipNN supports various compression methods like ZSTD, lz4, and snappy, and provides ready-made scripts for file compression/decompression. Users can also manually import the package to compress and decompress data. The library offers advanced configuration options for customization and validation tests for different input and compression types.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.

instructor-php
Instructor for PHP is a library designed for structured data extraction in PHP, powered by Large Language Models (LLMs). It simplifies the process of extracting structured, validated data from unstructured text or chat sequences. Instructor enhances workflow by providing a response model, validation capabilities, and max retries for requests. It supports classes as response models and provides features like partial results, string input, extracting scalar and enum values, and specifying data models using PHP type hints or DocBlock comments. The library allows customization of validation and provides detailed event notifications during request processing. Instructor is compatible with PHP 8.2+ and leverages PHP reflection, Symfony components, and SaloonPHP for communication with LLM API providers.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
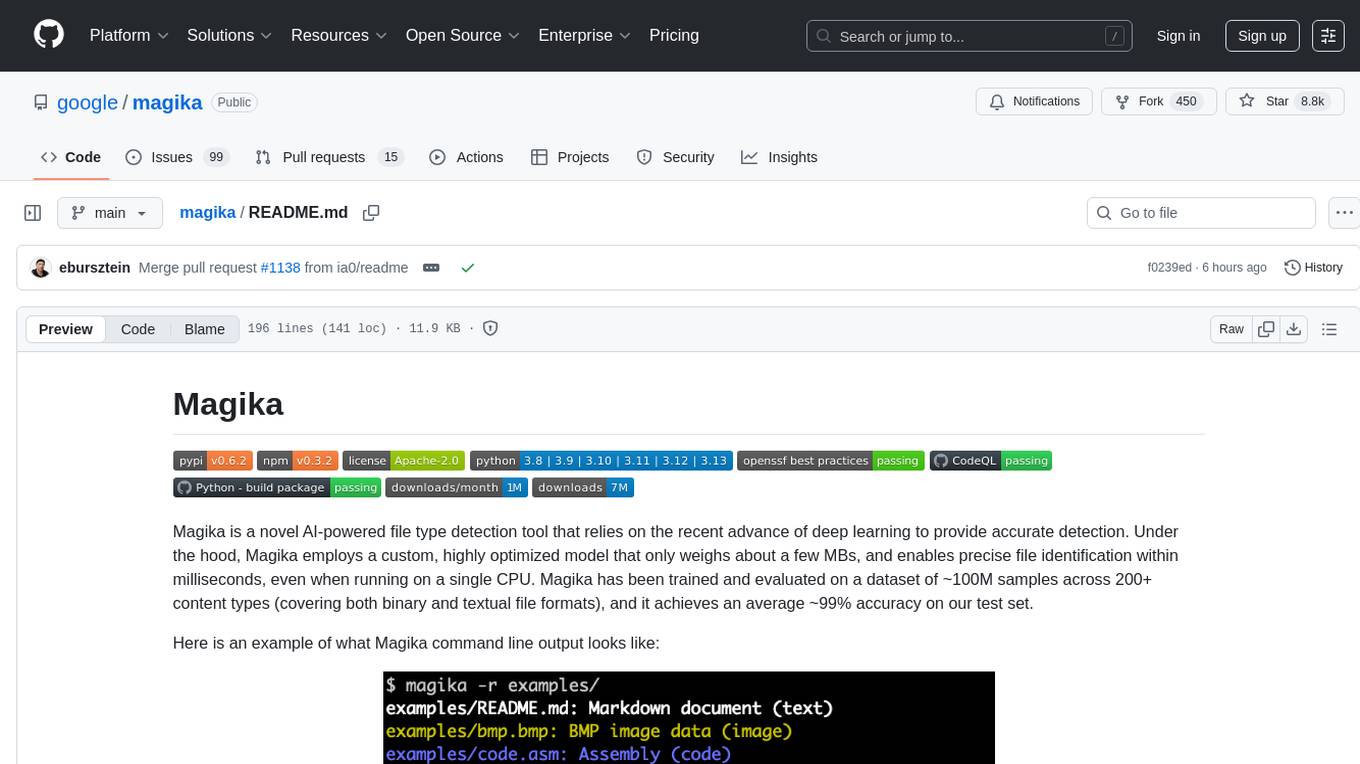
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.
Numpy.NET
Numpy.NET is the most complete .NET binding for NumPy, empowering .NET developers with extensive functionality for scientific computing, machine learning, and AI. It provides multi-dimensional arrays, matrices, linear algebra, FFT, and more via a strong typed API. Numpy.NET does not require a local Python installation, as it uses Python.Included to package embedded Python 3.7. Multi-threading must be handled carefully to avoid deadlocks or access violation exceptions. Performance considerations include overhead when calling NumPy from C# and the efficiency of data transfer between C# and Python. Numpy.NET aims to match the completeness of the original NumPy library and is generated using CodeMinion by parsing the NumPy documentation. The project is MIT licensed and supported by JetBrains.
For similar tasks
cuvs
cuVS is a library that contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.