
yalm
Yet Another Language Model: LLM inference in C++/CUDA, no libraries except for I/O
Stars: 190
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.
README:
yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, using no libraries except to load and save frozen LLM weights.
- This project is intended as an educational exercise in performance engineering and LLM inference implementation.
- The codebase therefore emphasizes documentation, whether external or in comments, scientific understanding of optimizations, and readability where possible.
- It is not meant to be run in production. See limitations section at bottom.
- See my blog post Fast LLM Inference From Scratch for more.
Latest benchmarks with Mistral-7B-Instruct-v0.2 in FP16 with 4k context, on RTX 4090 + EPYC 7702P:
| Engine | Avg. throughput (~120 tokens) tok/s | Avg. throughput (~4800 tokens) tok/s |
|---|---|---|
| huggingface transformers, GPU | 25.9 | 25.7 |
| llama.cpp, GPU | 61.0 | 58.8 |
| calm, GPU | 66.0 | 65.7 |
| yalm, GPU | 63.8 | 58.7 |
yalm requires a computer with a C++20-compatible compiler and the CUDA toolkit (including nvcc) to be installed. You'll also need a directory containing LLM safetensor weights and configuration files in huggingface format, which you'll need to convert into a .yalm file. Follow the below to download Mistral-7B-v0.2, build yalm, and run it:
# install git LFS
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get -y install git-lfs
# download Mistral
git clone [email protected]:mistralai/Mistral-7B-Instruct-v0.2
# clone this repository
git clone [email protected]:andrewkchan/yalm.git
cd yalm
pip install -r requirements.txt
python convert.py --dtype fp16 mistral-7b-instruct-fp16.yalm ../Mistral-7B-Instruct-v0.2/
./build/main mistral-7b-instruct-fp16.yalm -i "What is a large language model?" -m c
See the CLI help documentation below for ./build/main:
Usage: main <checkpoint> [options]
Example: main model.yalm -i "Q: What is the meaning of life?" -m c
Options:
-h Display this help message
-d [cpu,cuda] which device to use (default - cuda)
-m [completion,passkey,perplexity] which mode to run in (default - completion)
-T <int> sliding window context length (0 - max)
Perplexity mode options:
Choose one:
-i <string> input prompt
-f <filepath> input file with prompt
Completion mode options:
-n <int> number of steps to run for in completion mode, default 256. 0 = max_seq_len, -1 = infinite
Choose one:
-i <string> input prompt
-f <filepath> input file with prompt
Passkey mode options:
-n <int> number of junk lines to insert (default - 250)
-l <int> passkey position (-1 - random)
yalm comes with a basic test suite that checks implementations of attention, matrix multiplications, feedforward nets in the CPU and GPU backends. Build and run it like so:
make test
./build/test
The test binary also includes benchmarks for individual kernels (useful for profiling with ncu) and broader system tools such as 2 benchmarks to determine main memory bandwidth:
# Memory benchmarks
./build/test -b
./build/test -b2
# Kernel benchmarks
./build/test -k [matmul,mha,ffn]
- Only completions may be performed (in addition to some testing modes like computing perplexity on a prompt or performing a passkey test). Chat interface has not been implemented.
- Only a rudimentary sampler (argmax) has been implemented; temperature is not supported.
- An NVIDIA GPU is required.
- The GPU backend only works with a single GPU and the entire model must fit into VRAM.
- As of Dec 31, 2024 only the following models have been tested:
- Mistral-v0.2
- Mixtral-v0.1
- Llama-3.2
- calm - Much of my implementation is inspired by Arseny Kapoulkine’s inference engine. In a way, this project was kicked off by “understand calm and what makes it so fast.” I’ve tried to keep my code more readable for myself though, and as much as possible scientifically understanding optimizations, which means foregoing some advanced techniques used in calm like dynamic parallelism.
- llama2.c - Parts of the CPU backend come from Andrej Karpathy’s excellent C implementation of Llama inference.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for yalm
Similar Open Source Tools
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
facet
FACET is an open source library for human-explainable AI that combines model inspection and model-based simulation to provide better explanations for supervised machine learning models. It offers an efficient and transparent machine learning workflow, enhancing scikit-learn's pipelining paradigm with new capabilities for model selection, inspection, and simulation. FACET introduces new algorithms for quantifying dependencies and interactions between features in ML models, as well as for conducting virtual experiments to optimize predicted outcomes. The tool ensures end-to-end traceability of features using an augmented version of scikit-learn with enhanced support for pandas data frames. FACET also provides model inspection methods for scikit-learn estimators, enhancing global metrics like synergy and redundancy to complement the local perspective of SHAP. Additionally, FACET offers model simulation capabilities for conducting univariate uplift simulations based on important features like BMI.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
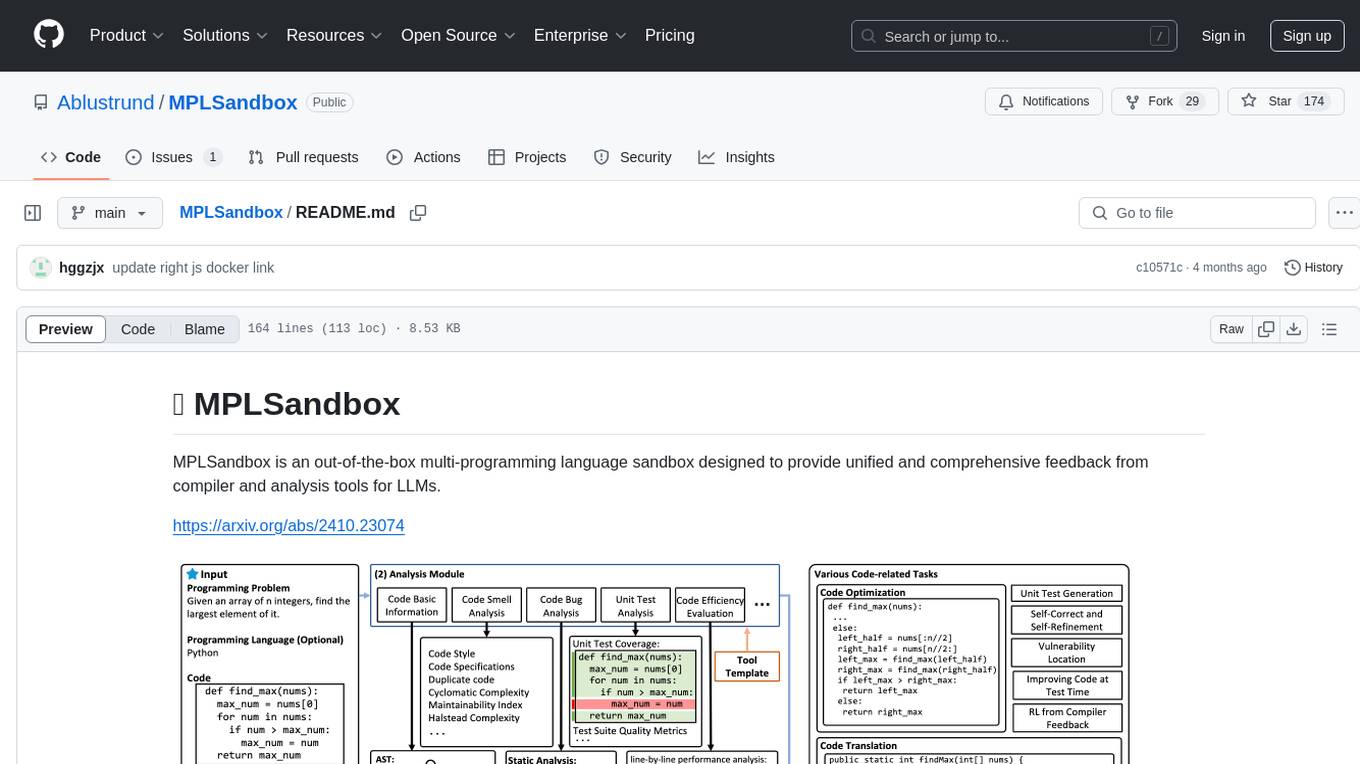
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.
For similar tasks
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
mlir-air
This repository contains tools and libraries for building AIR platforms, runtimes and compilers.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
aika
AIKA (Artificial Intelligence for Knowledge Acquisition) is a new type of artificial neural network designed to mimic the behavior of a biological brain more closely and bridge the gap to classical AI. The network conceptually separates activations from neurons, creating two separate graphs to represent acquired knowledge and inferred information. It uses different types of neurons and synapses to propagate activation values, binding signals, causal relations, and training gradients. The network structure allows for flexible topology and supports the gradual population of neurons and synapses during training.

nextpy
Nextpy is a cutting-edge software development framework optimized for AI-based code generation. It provides guardrails for defining AI system boundaries, structured outputs for prompt engineering, a powerful prompt engine for efficient processing, better AI generations with precise output control, modularity for multiplatform and extensible usage, developer-first approach for transferable knowledge, and containerized & scalable deployment options. It offers 4-10x faster performance compared to Streamlit apps, with a focus on cooperation within the open-source community and integration of key components from various projects.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.