
RAVE
Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
Stars: 1192
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
README:

Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthesis (article link) by Antoine Caillon and Philippe Esling.
If you use RAVE as a part of a music performance or installation, be sure to cite either this repository or the article !
If you want to share / discuss / ask things about RAVE you can do so in our discord server !
Please check the FAQ before posting an issue!
RAVE VST RAVE VST for Windows, Mac and Linux is available as beta on the corresponding Forum IRCAM webpage. For problems, please write an issue here or on the Forum IRCAM discussion page.
Tutorials : new tutorials are available on the Forum IRCAM webpage, and video versions are coming soon!
- Tutorial: Neural Synthesis in a DAW with RAVE
- Tutorial: Neural Synthesis in Max 8 with RAVE
- Tutorial: Training RAVE models on custom data
The original implementation of the RAVE model can be restored using
git checkout v1Install RAVE using
pip install acids-raveWarning It is strongly advised to install torch and torchaudio before acids-rave, so you can choose the appropriate version of torch on the library website. For future compatibility with new devices (and modern Python environments), rave-acids does not enforce torch==1.13 anymore.
You will need ffmpeg on your computer. You can install it locally inside your virtual environment using
conda install ffmpegA colab to train RAVEv2 is now available thanks to hexorcismos !
Training a RAVE model usually involves 3 separate steps, namely dataset preparation, training and export.
You can know prepare a dataset using two methods: regular and lazy. Lazy preprocessing allows RAVE to be trained directly on the raw files (i.e. mp3, ogg), without converting them first. Warning: lazy dataset loading will increase your CPU load by a large margin during training, especially on Windows. This can however be useful when training on large audio corpus which would not fit on a hard drive when uncompressed. In any case, prepare your dataset using
rave preprocess --input_path /audio/folder --output_path /dataset/path --channels X (--lazy)RAVEv2 has many different configurations. The improved version of the v1 is called v2, and can therefore be trained with
rave train --config v2 --db_path /dataset/path --out_path /model/out --name give_a_name --channels XWe also provide a discrete configuration, similar to SoundStream or EnCodec
rave train --config discrete ...By default, RAVE is built with non-causal convolutions. If you want to make the model causal (hence lowering the overall latency of the model), you can use the causal mode
rave train --config discrete --config causal ...New in 2.3, data augmentations are also available to improve the model's generalization in low data regimes. You can add data augmentation by adding augmentation configuration files with the --augment keyword
rave train --config v2 --augment mute --augment compressMany other configuration files are available in rave/configs and can be combined. Here is a list of all the available configurations & augmentations :
| Type | Name | Description |
|---|---|---|
| Architecture | v1 | Original continuous model (minimum GPU memory : 8Go) |
| v2 | Improved continuous model (faster, higher quality) (minimum GPU memory : 16Go) | |
| v2_small | v2 with a smaller receptive field, adpated adversarial training, and noise generator, adapted for timbre transfer for stationary signals (minimum GPU memory : 8Go) | |
| v2_nopqmf | (experimental) v2 without pqmf in generator (more efficient for bending purposes) (minimum GPU memory : 16Go) | |
| v3 | v2 with Snake activation, descript discriminator and Adaptive Instance Normalization for real style transfer (minimum GPU memory : 32Go) | |
| discrete | Discrete model (similar to SoundStream or EnCodec) (minimum GPU memory : 18Go) | |
| onnx | Noiseless v1 configuration for onnx usage (minimum GPU memory : 6Go) | |
| raspberry | Lightweight configuration compatible with realtime RaspberryPi 4 inference (minimum GPU memory : 5Go) | |
| Regularization (v2 only) | default | Variational Auto Encoder objective (ELBO) |
| wasserstein | Wasserstein Auto Encoder objective (MMD) | |
| spherical | Spherical Auto Encoder objective | |
| Discriminator | spectral_discriminator | Use the MultiScale discriminator from EnCodec. |
| Others | causal | Use causal convolutions |
| noise | Enables noise synthesizer V2 | |
| hybrid | Enable mel-spectrogram input | |
| Augmentations | mute | Randomly mutes data batches (default prob : 0.1). Enforces the model to learn silence |
| compress | Randomly compresses the waveform (equivalent to light non-linear amplification of batches) | |
| gain | Applies a random gain to waveform (default range : [-6, 3]) |
Once trained, export your model to a torchscript file using
rave export --run /path/to/your/run (--streaming)Setting the --streaming flag will enable cached convolutions, making the model compatible with realtime processing. If you forget to use the streaming mode and try to load the model in Max, you will hear clicking artifacts.
For discrete models, we redirect the user to the msprior library here. However, as this library is still experimental, the prior from version 1.x has been re-integrated in v2.3.
To train a prior for a pretrained RAVE model :
rave train_prior --model /path/to/your/run --db_path /path/to/your_preprocessed_data --out_path /path/to/outputthis will train a prior over the latent of the pretrained model path/to/your/run, and save the model and tensorboard logs to folder /path/to/output.
To script a prior along with a RAVE model, export your model by providing the --prior keyword to your pretrained prior :
rave export --run /path/to/your/run --prior /path/to/your/prior (--streaming)Several pretrained streaming models are available here. We'll keep the list updated with new models.
This section presents how RAVE can be loaded inside nn~ in order to be used live with Max/MSP or PureData.
A pretrained RAVE model named darbouka.gin available on your computer can be loaded inside nn~ using the following syntax, where the default method is set to forward (i.e. encode then decode)

This does the same thing as the following patch, but slightly faster.

Having an explicit access to the latent representation yielded by RAVE allows us to interact with the representation using Max/MSP or PureData signal processing tools:

By default, RAVE can be used as a style transfer tool, based on the large compression ratio of the model. We recently added a technique inspired from StyleGAN to include Adaptive Instance Normalization to the reconstruction process, effectively allowing to define source and target styles directly inside Max/MSP or PureData, using the attribute system of nn~.

Other attributes, such as enable or gpu can enable/disable computation, or use the gpu to speed up things (still experimental).
A batch generation script has been released in v2.3 to allow transformation of large amount of files
rave generate model_path path_1 path_2 --out out_pathwhere model_path is the path to your trained model (original or scripted), path_X a list of audio files or directories, and out_path the out directory of the generations.
If you have questions, want to share your experience with RAVE or share musical pieces done with the model, you can use the Discussion tab !
Demonstration of what you can do with RAVE and the nn~ external for maxmsp !

Using nn~ for puredata, RAVE can be used in realtime on embedded platforms !

Question : my preprocessing is stuck, showing 0it[00:00, ?it/s]
Answer : This means that the audio files in your dataset are too short to provide a sufficient temporal scope to RAVE. Try decreasing the signal window with the --num_signal XXX(samples) with preprocess, without forgetting afterwards to add the --n_signal XXX(samples) with train
Question : During training I got an exception resembling ValueError: n_components=128 must be between 0 and min(n_samples, n_features)=64 with svd_solver='full'
Answer : This means that your dataset does not have enough data batches to compute the intern latent PCA, that requires at least 128 examples (then batches).
This work is led at IRCAM, and has been funded by the following projects
- ANR MakiMono
- ACTOR
- DAFNE+ N° 101061548
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RAVE
Similar Open Source Tools
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

physical-AI-interpretability
Physical AI Interpretability is a toolkit for transformer-based Physical AI and robotics models, providing tools for attention mapping, feature extraction, and out-of-distribution detection. It includes methods for post-hoc attention analysis, applying Dictionary Learning into robotics, and training sparse autoencoders. The toolkit aims to enhance interpretability and understanding of AI models in physical environments.
neutone_sdk
The Neutone SDK is a tool designed for researchers to wrap their own audio models and run them in a DAW using the Neutone Plugin. It simplifies the process by allowing models to be built using PyTorch and minimal Python code, eliminating the need for extensive C++ knowledge. The SDK provides support for buffering inputs and outputs, sample rate conversion, and profiling tools for model performance testing. It also offers examples, notebooks, and a submission process for sharing models with the community.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.
For similar tasks
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.
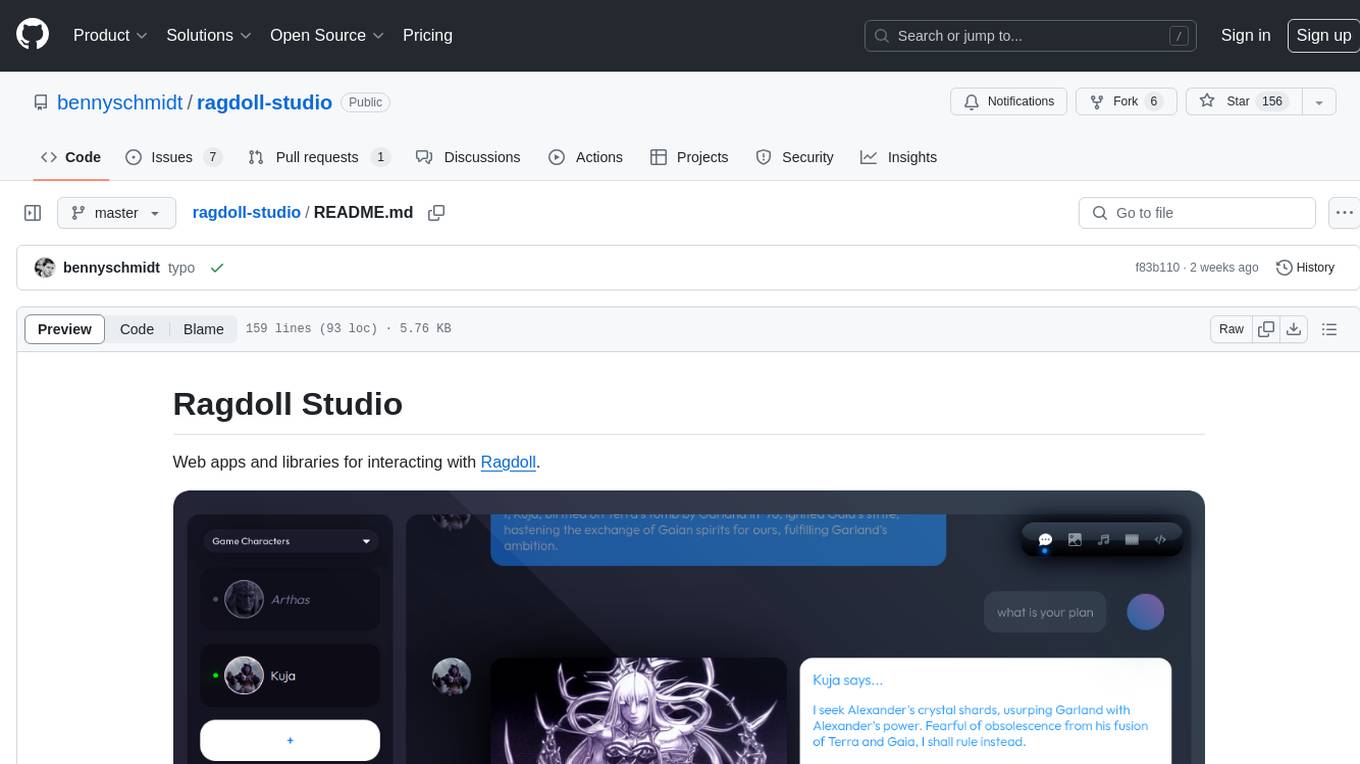
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.
simple-openai
Simple-OpenAI is a Java library that provides a simple way to interact with the OpenAI API. It offers consistent interfaces for various OpenAI services like Audio, Chat Completion, Image Generation, and more. The library uses CleverClient for HTTP communication, Jackson for JSON parsing, and Lombok to reduce boilerplate code. It supports asynchronous requests and provides methods for synchronous calls as well. Users can easily create objects to communicate with the OpenAI API and perform tasks like text-to-speech, transcription, image generation, and chat completions.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.
RAG-Survey
This repository is dedicated to collecting and categorizing papers related to Retrieval-Augmented Generation (RAG) for AI-generated content. It serves as a survey repository based on the paper 'Retrieval-Augmented Generation for AI-Generated Content: A Survey'. The repository is continuously updated to keep up with the rapid growth in the field of RAG.
For similar jobs
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.