
autoarena
Rank LLMs, RAG systems, and prompts using automated head-to-head evaluation
Stars: 65
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.
README:
Create leaderboards ranking LLM outputs against one another using automated judge evaluation





- 🏆 Rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of your system
- ⚔️ Perform automated head-to-head evaluation using judges from OpenAI, Anthropic, Cohere, and more
- 🤖 Define and run your own custom judges, connecting to internal services or implementing bespoke logic
- 💻 Run application locally, getting full control over your environment and data
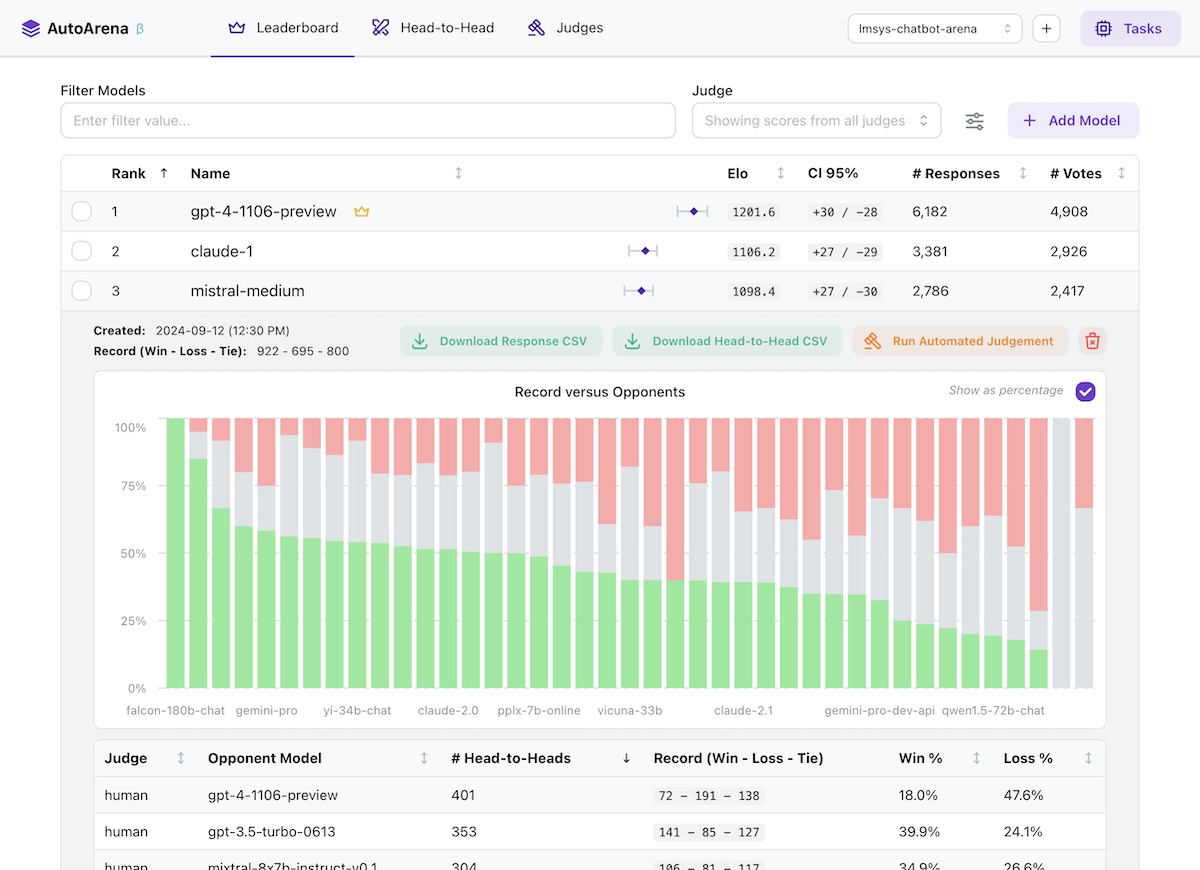
- LLMs are better at judging responses head-to-head than they are in isolation (arXiv:2408.08688) — leaderboard rankings computed using Elo scores from many automated side-by-side comparisons should be more trustworthy than leaderboards using metrics computed on each model's responses independently!
- The LMSYS Chatbot Arena has replaced benchmarks for many people as the trusted true leaderboard for foundation model performance (arXiv:2403.04132). Why not apply this approach to your own foundation model selection, RAG system setup, or prompt engineering efforts?
- Using a "jury" of multiple smaller models from different model families like
gpt-4o-mini,command-r, andclaude-3-haikugenerally yields better accuracy than a single frontier judge likegpt-4o— while being faster and much cheaper to run. AutoArena is built around this technique, called PoLL: Panel of LLM evaluators (arXiv:2404.18796). - Automated side-by-side comparison of model outputs is one of the most prevalent evaluation practices (arXiv:2402.10524) — AutoArena makes this process easier than ever to get up and running.
Install from PyPI:
pip install autoarenaRun as a module and visit localhost:8899 in your browser:
python -m autoarenaWith the application running, getting started is simple:
- Create a project via the UI.
- Add responses from a model by selecting a CSV file with
promptandresponsecolumns. - Configure an automated judge via the UI. Note that most judges require credentials, e.g.
X_API_KEYin the environment where you're running AutoArena. - Add responses from a second model to kick off an automated judging task using the judges you configured in the
previous step to decide which of the models you've uploaded provided a better
responseto a givenprompt.
That's it! After these steps you're fully set up for automated evaluation on AutoArena.
AutoArena requires two pieces of information to test a model: the input prompt and corresponding model response.
-
prompt: the inputs to your model. When uploading responses, any other models that have been run on the same prompts are matched and evaluated using the automated judges you have configured. -
response: the output from your model. Judges decide which of two models produced a better response, given the same prompt.
Data is stored in ./data/<project>.sqlite files in the directory where you invoked AutoArena. See
data/README.md for more details on data storage in AutoArena.
AutoArena uses uv to manage dependencies. To set up this repository for development, run:
uv venv && source .venv/bin/activate
uv pip install --all-extras -r pyproject.toml
uv tool run pre-commit install
uv run python3 -m autoarena serve --devTo run AutoArena for development, you will need to run both the backend and frontend service:
- Backend:
uv run python3 -m autoarena serve --dev(the--dev/-dflag enables automatic service reloading when source files change) - Frontend: see
ui/README.md
To build a release tarball in the ./dist directory:
./scripts/build.shFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for autoarena
Similar Open Source Tools
autoarena
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.

physical-AI-interpretability
Physical AI Interpretability is a toolkit for transformer-based Physical AI and robotics models, providing tools for attention mapping, feature extraction, and out-of-distribution detection. It includes methods for post-hoc attention analysis, applying Dictionary Learning into robotics, and training sparse autoencoders. The toolkit aims to enhance interpretability and understanding of AI models in physical environments.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.
empirical
Empirical is a tool that allows you to test different LLMs, prompts, and other model configurations across all the scenarios that matter for your application. With Empirical, you can run your test datasets locally against off-the-shelf models, test your own custom models and RAG applications, view, compare, and analyze outputs on a web UI, score your outputs with scoring functions, and run tests on CI/CD.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.

sage
Sage is a tool that allows users to chat with any codebase, providing a chat interface for code understanding and integration. It simplifies the process of learning how a codebase works by offering heavily documented answers sourced directly from the code. Users can set up Sage locally or on the cloud with minimal effort. The tool is designed to be easily customizable, allowing users to swap components of the pipeline and improve the algorithms powering code understanding and generation.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.
neuron-ai
Neuron is a PHP framework for creating and orchestrating AI Agents, providing tools for the entire agentic application development lifecycle. It allows integration of AI entities in existing PHP applications with a powerful and flexible architecture. Neuron offers tutorials and educational content to help users get started using AI Agents in their projects. The framework supports various LLM providers, tools, and toolkits, enabling users to create fully functional agents for tasks like data analysis, chatbots, and structured output. Neuron also facilitates monitoring and debugging of AI applications, ensuring control over agent behavior and decision-making processes.
For similar tasks
autoarena
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
LLMLingua
LLMLingua is a tool that utilizes a compact, well-trained language model to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models, achieving up to 20x compression with minimal performance loss. The tool includes LLMLingua, LongLLMLingua, and LLMLingua-2, each offering different levels of prompt compression and performance improvements for tasks involving large language models.
llm-examples
Starter examples for building LLM apps with Streamlit. This repository showcases a growing collection of LLM minimum working examples, including a Chatbot, File Q&A, Chat with Internet search, LangChain Quickstart, LangChain PromptTemplate, and Chat with user feedback. Users can easily get their own OpenAI API key and set it as an environment variable in Streamlit apps to run the examples locally.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
gaianet-node
GaiaNet-node is a tool that allows users to run their own GaiaNet node, enabling them to interact with an AI agent. The tool provides functionalities to install the default node software stack, initialize the node with model files and vector database files, start the node, stop the node, and update configurations. Users can use pre-set configurations or pass a custom URL for initialization. The tool is designed to facilitate communication with the AI agent and access node information via a browser. GaiaNet-node requires sudo privilege for installation but can also be installed without sudo privileges with specific commands.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.