
guidellm
Evaluate and Enhance Your LLM Deployments for Real-World Inference Needs
Stars: 207

GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.
README:
![]()





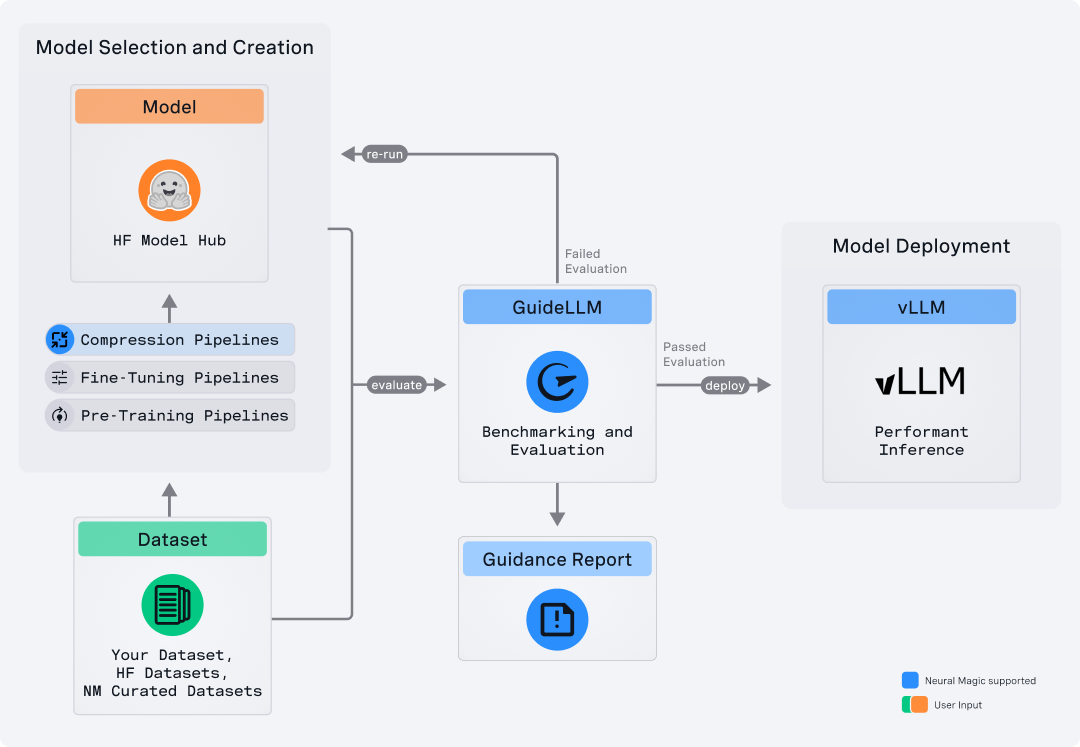
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality.
- Performance Evaluation: Analyze LLM inference under different load scenarios to ensure your system meets your service level objectives (SLOs).
- Resource Optimization: Determine the most suitable hardware configurations for running your models effectively.
- Cost Estimation: Understand the financial impact of different deployment strategies and make informed decisions to minimize costs.
- Scalability Testing: Simulate scaling to handle large numbers of concurrent users without degradation in performance.
Before installing, ensure you have the following prerequisites:
- OS: Linux or MacOS
- Python: 3.8 – 3.12
GuideLLM is available on PyPI and is installed using pip:
pip install guidellmFor detailed installation instructions and requirements, see the Installation Guide.
GuideLLM requires an OpenAI-compatible server to run evaluations. vLLM is recommended for this purpose. To start a vLLM server with a Llama 3.1 8B quantized model, run the following command:
vllm serve "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16"For more information on starting a vLLM server, see the vLLM Documentation.
GuideLLM requires an OpenAI-compatible server to run evaluations. Text Generation Inference can be used here. To start a TGI server with a Llama 3.1 8B using docker, run the following command:
docker run --gpus 1 -ti --shm-size 1g --ipc=host --rm -p 8080:80 \
-e MODEL_ID=meta-llama/Meta-Llama-3.1-8B-Instruct \
-e NUM_SHARD=1 \
-e MAX_INPUT_TOKENS=4096 \
-e MAX_TOTAL_TOKENS=6000 \
-e HF_TOKEN=$(cat ~/.cache/huggingface/token) \
ghcr.io/huggingface/text-generation-inference:2.2.0For more information on starting a TGI server, see the TGI Documentation.
To run a GuideLLM evaluation, use the guidellm command with the appropriate model name and options on the server hosting the model or one with network access to the deployment server. For example, to evaluate the full performance range of the previously deployed Llama 3.1 8B model, run the following command:
guidellm \
--target "http://localhost:8000/v1" \
--model "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16" \
--data-type emulated \
--data "prompt_tokens=512,generated_tokens=128"The above command will begin the evaluation and output progress updates similar to the following (if running on a different server, be sure to update the target!): 
Notes:
- The
--targetflag specifies the server hosting the model. In this case, it is a local vLLM server. - The
--modelflag specifies the model to evaluate. The model name should match the name of the model deployed on the server - By default, GuideLLM will run a
sweepof performance evaluations across different request rates, each lasting 120 seconds and the results are printed out to the terminal.
After the evaluation is completed, GuideLLM will summarize the results, including various performance metrics.
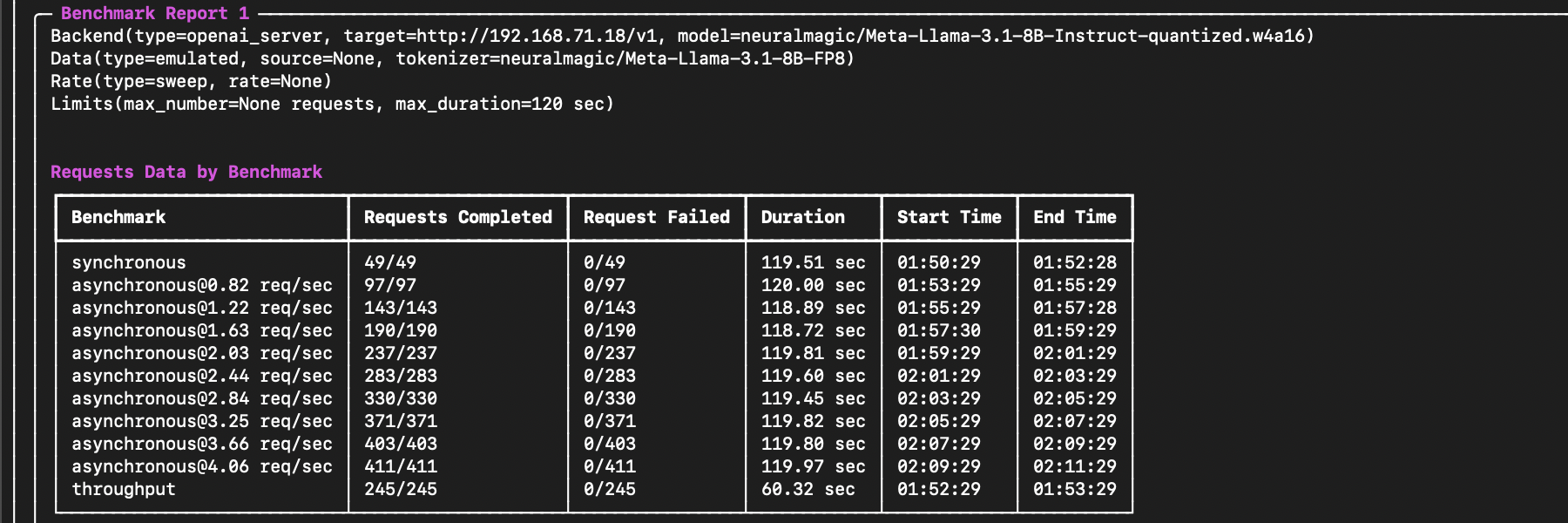
The output results will start with a summary of the evaluation, followed by the requests data for each benchmark run. For example, the start of the output will look like the following:
The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
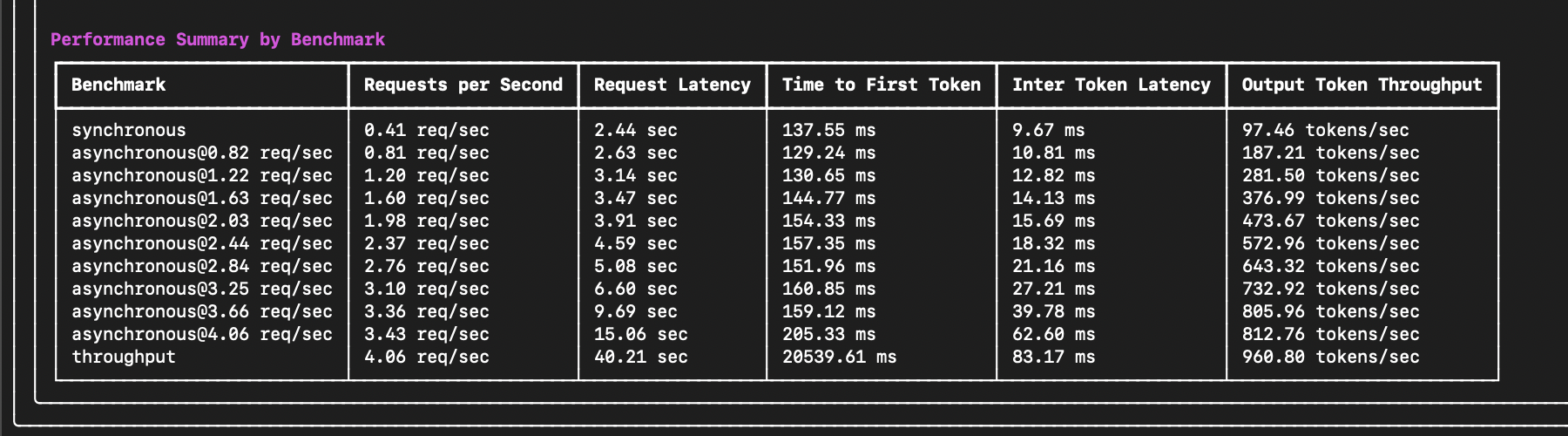
The results from GuideLLM are used to optimize your LLM deployment for performance, resource efficiency, and cost. By analyzing the performance metrics, you can identify bottlenecks, determine the optimal request rate, and select the most cost-effective hardware configuration for your deployment.
For example, if we deploy a latency-sensitive chat application, we likely want to optimize for low time to first token (TTFT) and inter-token latency (ITL). A reasonable threshold will depend on the application requirements. Still, we may want to ensure time to first token (TTFT) is under 200ms and inter-token latency (ITL) is under 50ms (20 updates per second). From the example results above, we can see that the model can meet these requirements on average at a request rate of 2.37 requests per second for each server. If you'd like to target a higher percentage of requests meeting these requirements, you can use the Performance Stats by Benchmark section to determine the rate at which 90% or 95% of requests meet these requirements.
If we deploy a throughput-sensitive summarization application, we likely want to optimize for the maximum requests the server can handle per second. In this case, the throughput benchmark shows that the server maxes out at 4.06 requests per second. If we need to handle more requests, consider adding more servers or upgrading the hardware configuration.
GuideLLM provides various CLI and environment options to customize evaluations, including setting the duration of each benchmark run, the number of concurrent requests, and the request rate.
Some typical configurations for the CLI include:
-
--rate-type: The rate to use for benchmarking. Options includesweep,synchronous,throughput,constant, andpoisson.-
--rate-type sweep: (default) Sweep runs through the full range of the server's performance, starting with asynchronousrate, thenthroughput, and finally, 10constantrates between the min and max request rate found. -
--rate-type synchronous: Synchronous runs requests synchronously, one after the other. -
--rate-type throughput: Throughput runs requests in a throughput manner, sending requests as fast as possible. -
--rate-type constant: Constant runs requests at a constant rate. Specify the request rate per second with the--rateargument. For example,--rate 10or multiple rates with--rate 10 --rate 20 --rate 30. -
--rate-type poisson: Poisson draws from a Poisson distribution with the mean at the specified rate, adding some real-world variance to the runs. Specify the request rate per second with the--rateargument. For example,--rate 10or multiple rates with--rate 10 --rate 20 --rate 30.
-
-
--data-type: The data to use for the benchmark. Options includeemulated,transformers, andfile.-
--data-type emulated: Emulated supports an EmulationConfig in string or file format for the--dataargument to generate fake data. Specify the number of prompt tokens at a minimum and optionally the number of output tokens and other parameters for variance in the length. For example,--data "prompt_tokens=128",--data "prompt_tokens=128,generated_tokens=128", or--data "prompt_tokens=128,prompt_tokens_variance=10". -
--data-type file: File supports a file path or URL to a file for the--dataargument. The file should contain data encoded as a CSV, JSONL, TXT, or JSON/YAML file with a single prompt per line for CSV, JSONL, and TXT or a list of prompts for JSON/YAML. For example,--data "data.txt"where data.txt contents are"prompt1\nprompt2\nprompt3". -
--data-type transformers: Transformers supports a dataset name or file path for the--dataargument. For example,--data "neuralmagic/LLM_compression_calibration".
-
-
--max-seconds: The maximum number of seconds to run each benchmark. The default is 120 seconds. -
--max-requests: The maximum number of requests to run in each benchmark.
For a complete list of supported CLI arguments, run the following command:
guidellm --helpFor a full list of configuration options, run the following command:
guidellm-configSee the GuideLLM Documentation for further information.
Our comprehensive documentation provides detailed guides and resources to help you get the most out of GuideLLM. Whether just getting started or looking to dive deeper into advanced topics, you can find what you need in our full documentation.
- Installation Guide - This guide provides step-by-step instructions for installing GuideLLM, including prerequisites and setup tips.
- Architecture Overview - A detailed look at GuideLLM's design, components, and how they interact.
- CLI Guide - Comprehensive usage information for running GuideLLM via the command line, including available commands and options.
- Configuration Guide - Instructions on configuring GuideLLM to suit various deployment needs and performance goals.
- vLLM Documentation - Official vLLM documentation provides insights into installation, usage, and supported models.
Visit our GitHub Releases page and review the release notes to stay updated with the latest releases.
GuideLLM is licensed under the Apache License 2.0.
We appreciate contributions to the code, examples, integrations, documentation, bug reports, and feature requests! Your feedback and involvement are crucial in helping GuideLLM grow and improve. Below are some ways you can get involved:
- DEVELOPING.md - Development guide for setting up your environment and making contributions.
- CONTRIBUTING.md - Guidelines for contributing to the project, including code standards, pull request processes, and more.
- CODE_OF_CONDUCT.md - Our expectations for community behavior to ensure a welcoming and inclusive environment.
We invite you to join our growing community of developers, researchers, and enthusiasts passionate about LLMs and optimization. Whether you're looking for help, want to share your own experiences, or stay up to date with the latest developments, there are plenty of ways to get involved:
- Neural Magic Community Slack - Join our Slack channel to connect with other GuideLLM users and developers. Ask questions, share your work, and get real-time support.
- GitHub Issues - Report bugs, request features, or browse existing issues. Your feedback helps us improve GuideLLM.
- Subscribe to Updates - Sign up for the latest news, announcements, and updates about GuideLLM, webinars, events, and more.
- Contact Us - Use our contact form for general questions about Neural Magic or GuideLLM.
If you find GuideLLM helpful in your research or projects, please consider citing it:
@misc{guidellm2024,
title={GuideLLM: Scalable Inference and Optimization for Large Language Models},
author={Neural Magic, Inc.},
year={2024},
howpublished={\url{https://github.com/neuralmagic/guidellm}},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for guidellm
Similar Open Source Tools
guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
autoarena
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.
AP2
The Agent Payments Protocol (AP2) repository contains code samples and demos showcasing the protocol. It includes curated scenarios demonstrating key components, utilizing the Agent Development Kit (ADK) and Gemini 2.5 Flash. Users are free to use any tools to build agents. The repository features various agents and servers, with source code located in specific directories. Users can run scenarios by following README instructions and using run scripts. Additionally, the repository provides guidance on setting up prerequisites, obtaining a Google API key, and installing the AP2 types package.

bedrock-claude-chatbot
Bedrock Claude ChatBot is a Streamlit application that provides a conversational interface for users to interact with various Large Language Models (LLMs) on Amazon Bedrock. Users can ask questions, upload documents, and receive responses from the AI assistant. The app features conversational UI, document upload, caching, chat history storage, session management, model selection, cost tracking, logging, and advanced data analytics tool integration. It can be customized using a config file and is extensible for implementing specialized tools using Docker containers and AWS Lambda. The app requires access to Amazon Bedrock Anthropic Claude Model, S3 bucket, Amazon DynamoDB, Amazon Textract, and optionally Amazon Elastic Container Registry and Amazon Athena for advanced analytics features.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.
humanoid-gym
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
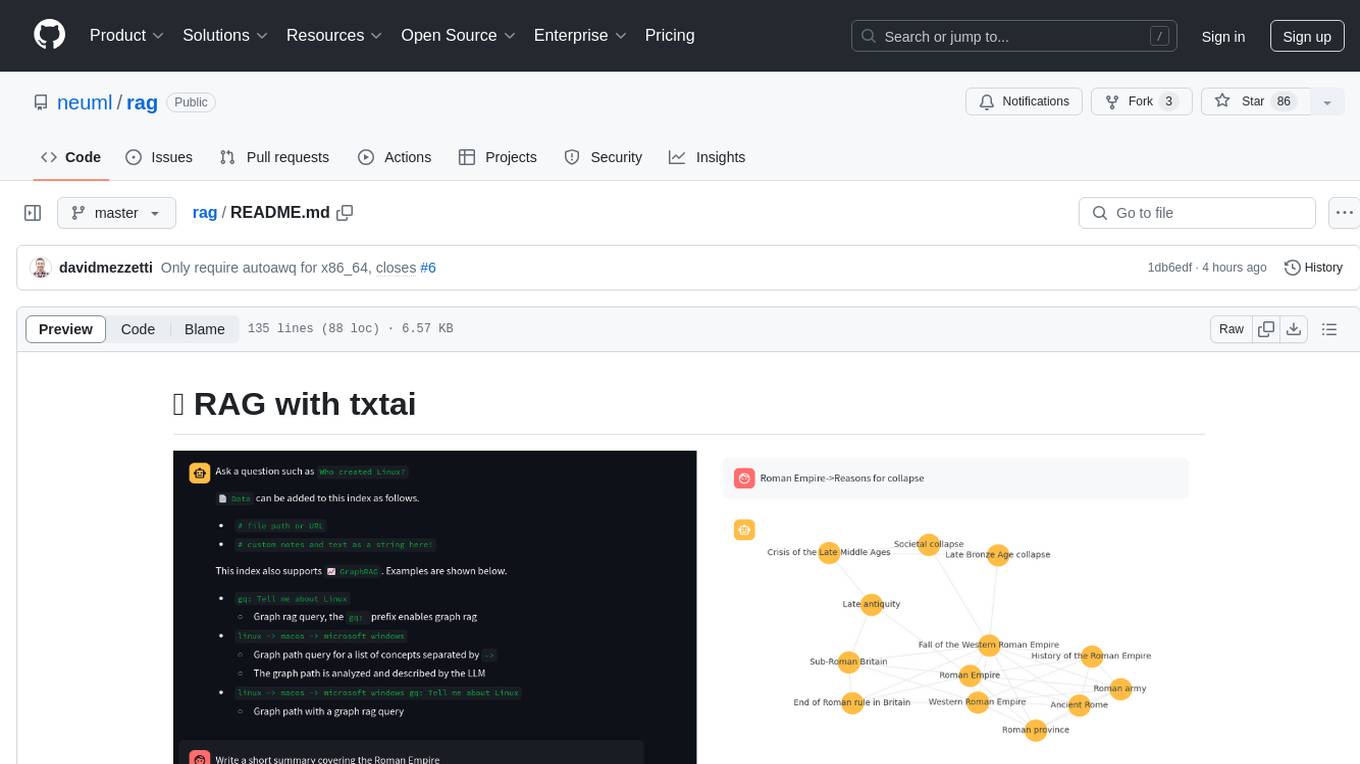
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.
kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.