Best AI tools for< Evaluate Performance >
20 - AI tool Sites

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.
MonitUp
MonitUp is an AI-powered time tracking software that helps you track computer activity, gain insights into work habits, and boost productivity. It uses artificial intelligence to generate personalized suggestions to help you increase productivity and work more efficiently. MonitUp also offers a performance appraisal feature for remote employees, allowing you to evaluate and improve their performance based on objective data.
Betterworks
Betterworks is an intelligent performance management platform that simplifies performance management, fosters greater manager effectiveness, higher employee engagement, and intelligent decision-making for HR leaders and organizations. It offers features such as AI for HR analytics & insights, integrations, accessibility, security, and manager effectiveness. Betterworks is designed to help organizations align their workforce around strategic priorities, drive collaboration, and continuously improve performance.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
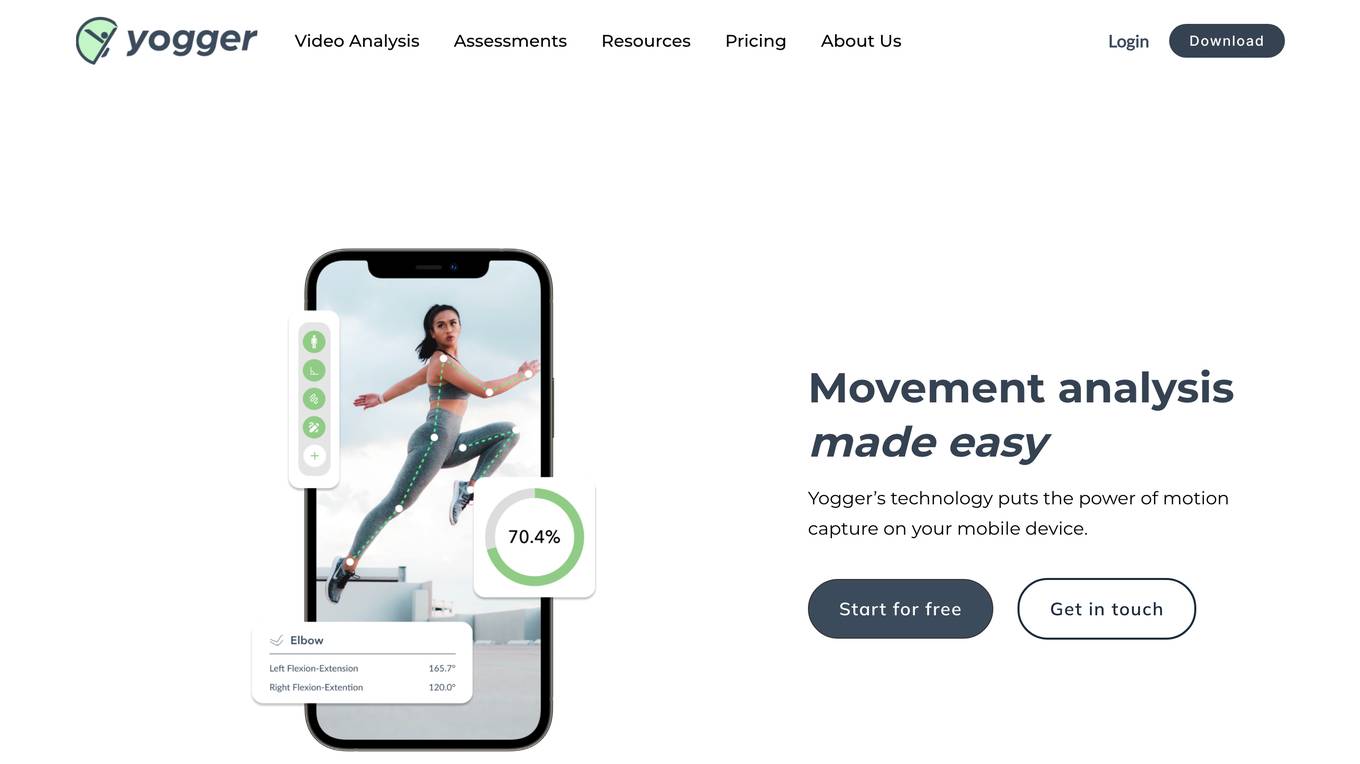
Yogger
Yogger is an AI-powered video analysis and movement assessment tool designed for coaches, trainers, physical therapists, and athletes. It allows users to track form, gather data, and analyze movement for any sport or activity in seconds. With AI-powered screenings, users can get instant scores and insights whether training in person or online. Yogger helps in recovery, training enhancement, and injury prevention, all accessible from a mobile device.
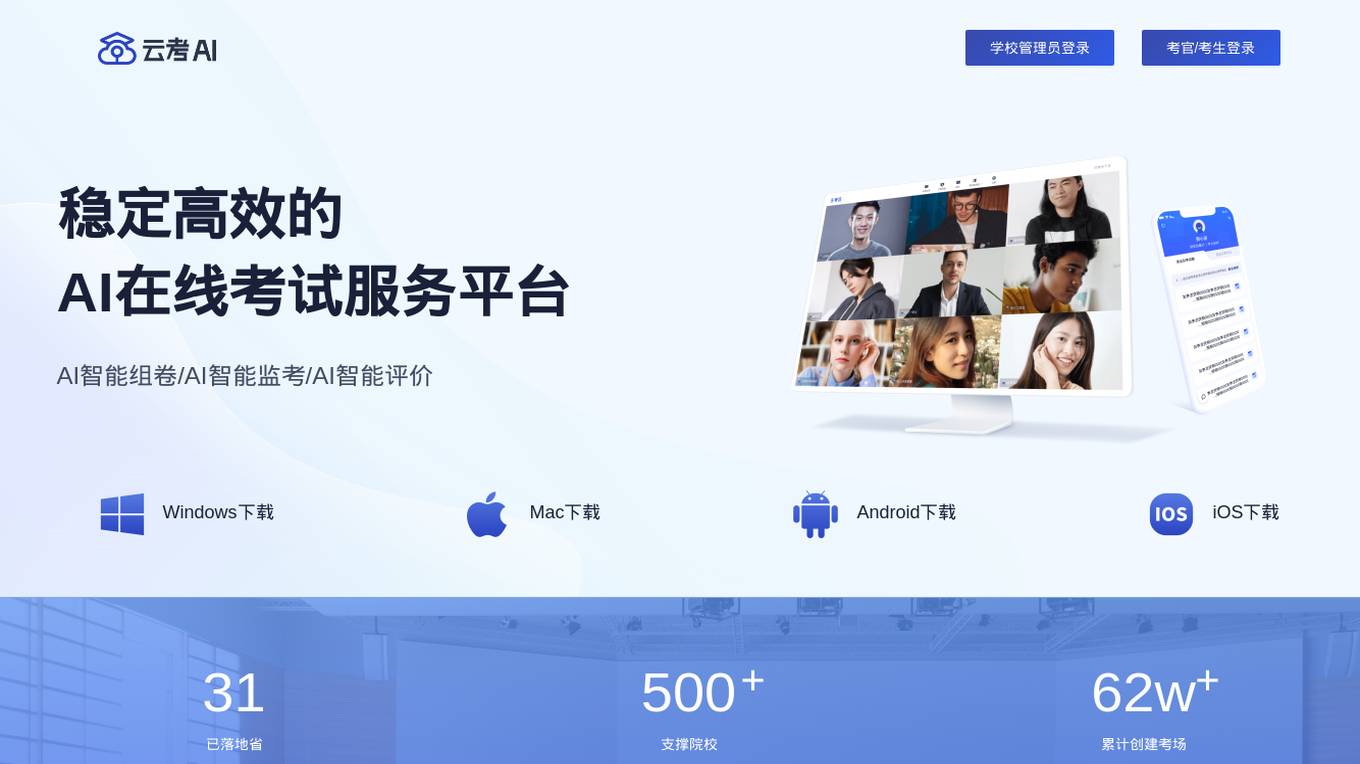
CloudExam AI
CloudExam AI is an online testing platform developed by Hanke Numerical Union Technology Co., Ltd. It provides stable and efficient AI online testing services, including intelligent grouping, intelligent monitoring, and intelligent evaluation. The platform ensures test fairness by implementing automatic monitoring level regulations and three random strategies. It prioritizes information security by combining software and hardware to secure data and identity. With global cloud deployment and flexible architecture, it supports hundreds of thousands of concurrent users. CloudExam AI offers features like queue interviews, interactive pen testing, data-driven cockpit, AI grouping, AI monitoring, AI evaluation, random question generation, dual-seat testing, facial recognition, real-time recording, abnormal behavior detection, test pledge book, student information verification, photo uploading for answers, inspection system, device detection, scoring template, ranking of results, SMS/email reminders, screen sharing, student fees, and collaboration with selected schools.

Machine Translation Research Hub
This website is a comprehensive resource for research in statistical and neural machine translation. It provides information, tools, and datasets related to the translation of text from one human language to another using computer algorithms trained on vast amounts of translated text.
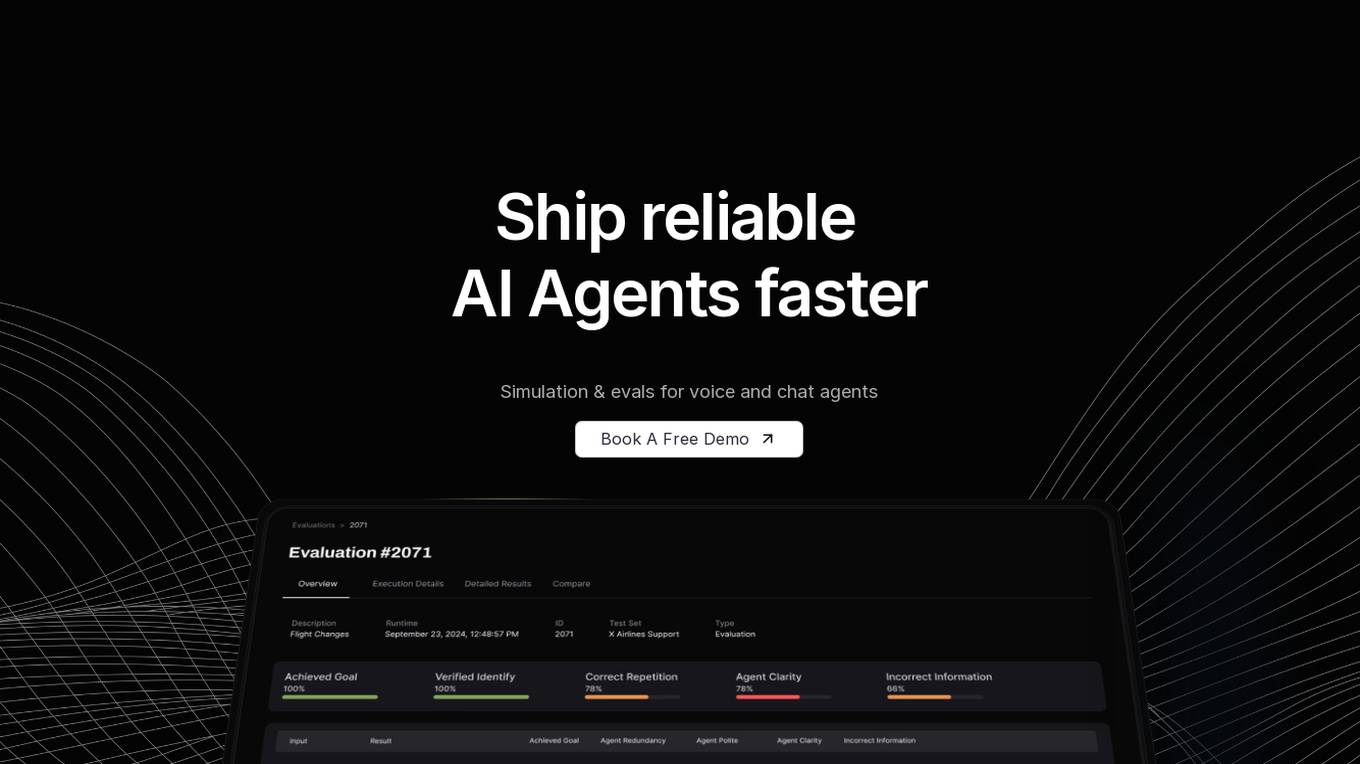
Coval
Coval is an AI tool designed to help users ship reliable AI agents faster by providing simulation and evaluations for voice and chat agents. It allows users to simulate thousands of scenarios from a few test cases, create prompts for testing, and evaluate agent interactions comprehensively. Coval offers AI-powered simulations, voice AI compatibility, performance tracking, workflow metrics, and customizable evaluation metrics to optimize AI agents efficiently.
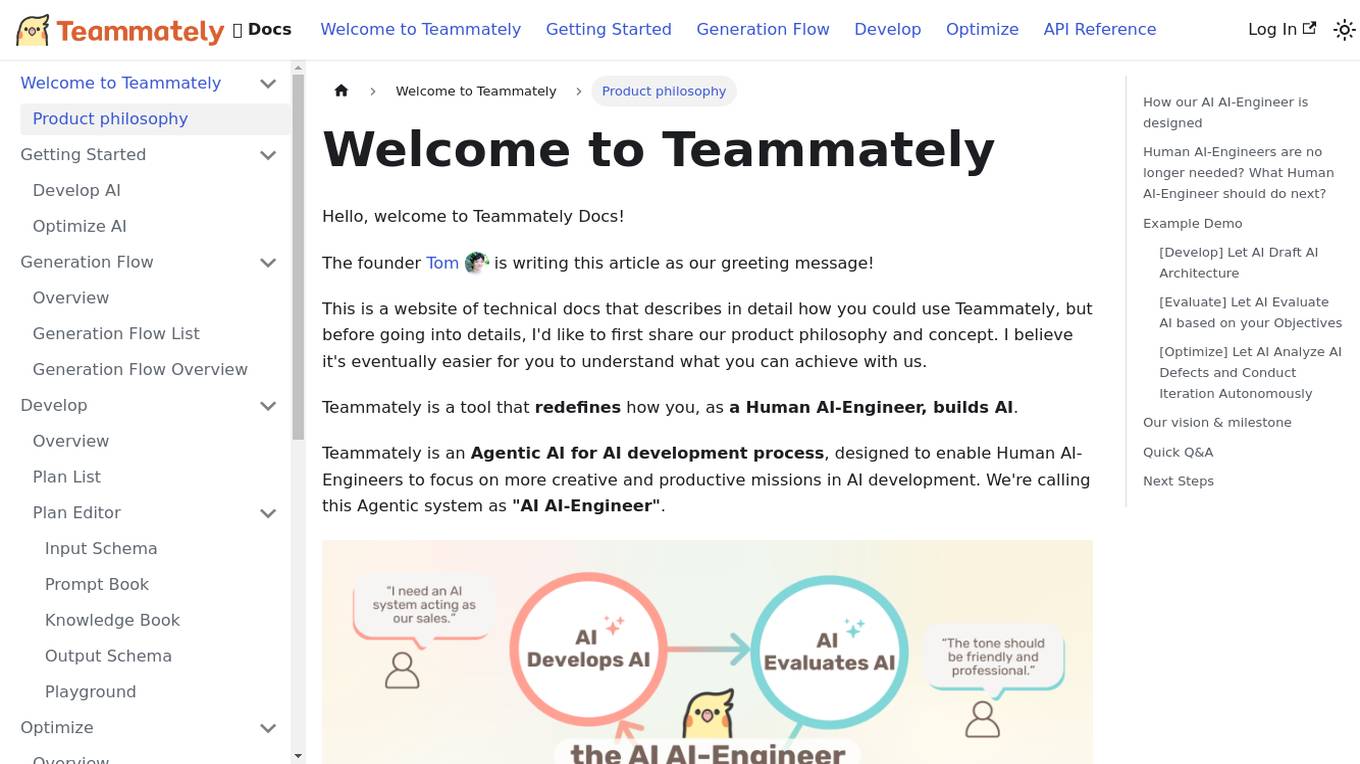
Teammately
Teammately is an AI tool that redefines how Human AI-Engineers build AI. It is an Agentic AI for AI development process, designed to enable Human AI-Engineers to focus on more creative and productive missions in AI development. Teammately follows the best practices of Human LLM DevOps and offers features like Development Prompt Engineering, Knowledge Tuning, Evaluation, and Optimization to assist in the AI development process. The tool aims to revolutionize AI engineering by allowing AI AI-Engineers to handle technical tasks, while Human AI-Engineers focus on planning and aligning AI with human preferences and requirements.
JobMojito
JobMojito is an AI Interview Platform that offers real-time avatar and voice interviews for job candidates. It provides interview coaching, job preparation, and support in English. The platform allows users to screen, evaluate, and select top talent using an AI Avatar that converses with candidates in real-time. JobMojito offers a comprehensive solution for managing the entire interview process, including preparation, conducting interviews with the avatar, providing instant feedback, and assessing candidates using AI technology. The platform is designed to attract new talent and streamline the recruitment process for organizations.
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
SQOR
SQOR is a plug-n-play AI tool designed for C-Level Executives to make stress-free decision-making in business intelligence. It provides a zero-code BI solution, offering KPIs at your fingertips without the need for expert knowledge. The platform enables users to access and share business intelligence data from various SaaS tools, facilitating collaboration and informed decision-making across the organization. SQOR's unique Execution Score Algorithm evaluates execution health at different levels, ensuring stakeholders are empowered with actionable insights.
Valuemetrix
Valuemetrix is an AI-enhanced investment analysis platform designed for investors seeking to redefine their investment journey. The platform offers cutting-edge AI technology, institutional-level data, and expert analysis to provide users with well-informed investment decisions. Valuemetrix empowers users to elevate their investment experience through AI-driven insights, real-time market news, stock reports, market analysis, and tailored financial information for over 100,000 international publicly traded companies.
Insidr AI
Insidr AI is a real-time analysis tool that helps users track their competition by providing actionable insights about products. Powered by Supervised AI, the tool offers features such as analyzing user reviews, gaining insights on competitors, and performing various analyses like sentiment analysis, SWOT analysis, and trend analysis. Users can also transcribe recordings, perform KPI analysis, and find competitive edges. With a focus on providing accurate data and insights, Insidr AI aims to help businesses make informed decisions and stay ahead of the competition.
75 - Open Source AI Tools

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.
awesome-azure-openai-llm
This repository is a collection of references to Azure OpenAI, Large Language Models (LLM), and related services and libraries. It provides information on various topics such as RAG, Azure OpenAI, LLM applications, agent design patterns, semantic kernel, prompting, finetuning, challenges & abilities, LLM landscape, surveys & references, AI tools & extensions, datasets, and evaluations. The content covers a wide range of topics related to AI, machine learning, and natural language processing, offering insights into the latest advancements in the field.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
ABigSurveyOfLLMs
ABigSurveyOfLLMs is a repository that compiles surveys on Large Language Models (LLMs) to provide a comprehensive overview of the field. It includes surveys on various aspects of LLMs such as transformers, alignment, prompt learning, data management, evaluation, societal issues, safety, misinformation, attributes of LLMs, efficient LLMs, learning methods for LLMs, multimodal LLMs, knowledge-based LLMs, extension of LLMs, LLMs applications, and more. The repository aims to help individuals quickly understand the advancements and challenges in the field of LLMs through a collection of recent surveys and research papers.
wandbot
Wandbot is a question-answering bot designed for Weights & Biases documentation. It employs Retrieval Augmented Generation with a ChromaDB backend for efficient responses. The bot features periodic data ingestion, integration with Discord and Slack, and performance monitoring through logging. It has a fallback mechanism for model selection and is evaluated based on retrieval accuracy and model-generated responses. The implementation includes creating document embeddings, constructing the Q&A RAGPipeline, model selection, deployment on FastAPI, Discord, and Slack, logging and analysis with Weights & Biases Tables, and performance evaluation.
bonito
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.
RouteLLM
RouteLLM is a framework for serving and evaluating LLM routers. It allows users to launch an OpenAI-compatible API that routes requests to the best model based on cost thresholds. Trained routers are provided to reduce costs while maintaining performance. Users can easily extend the framework, compare router performance, and calibrate cost thresholds. RouteLLM supports multiple routing strategies and benchmarks, offering a lightweight server and evaluation framework. It enables users to evaluate routers on benchmarks, calibrate thresholds, and modify model pairs. Contributions for adding new routers and benchmarks are welcome.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.
ygo-agent
YGO Agent is a project focused on using deep learning to master the Yu-Gi-Oh! trading card game. It utilizes reinforcement learning and large language models to develop advanced AI agents that aim to surpass human expert play. The project provides a platform for researchers and players to explore AI in complex, strategic game environments.
LL3DA
LL3DA is a Large Language 3D Assistant that responds to both visual and textual interactions within complex 3D environments. It aims to help Large Multimodal Models (LMM) comprehend, reason, and plan in diverse 3D scenes by directly taking point cloud input and responding to textual instructions and visual prompts. LL3DA achieves remarkable results in 3D Dense Captioning and 3D Question Answering, surpassing various 3D vision-language models. The code is fully released, allowing users to train customized models and work with pre-trained weights. The tool supports training with different LLM backends and provides scripts for tuning and evaluating models on various tasks.
awesome-ai-repositories
A curated list of open source repositories for AI Engineers. The repository provides a comprehensive collection of tools and frameworks for various AI-related tasks such as AI Gateway, AI Workload Manager, Copilot Development, Dataset Engineering, Evaluation, Fine Tuning, Function Calling, Graph RAG, Guardrails, Local Model Inference, LLM Agent Framework, Model Serving, Observability, Pre Training, Prompt Engineering, RAG Framework, Security, Structured Extraction, Structured Generation, Vector DB, and Voice Agent.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
EasyLM
EasyLM is a one-stop solution for pre-training, fine-tuning, evaluating, and serving large language models in JAX/Flax. It simplifies the process by leveraging JAX's pjit functionality to scale up training to multiple TPU/GPU accelerators. Built on top of Huggingface's transformers and datasets, EasyLM offers an easy-to-use and customizable codebase for training large language models without the complexity found in other frameworks. It supports sharding model weights and training data across multiple accelerators, enabling multi-TPU/GPU training on a single host or across multiple hosts on Google Cloud TPU Pods. EasyLM currently supports models like LLaMA, LLaMA 2, and LLaMA 3.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.
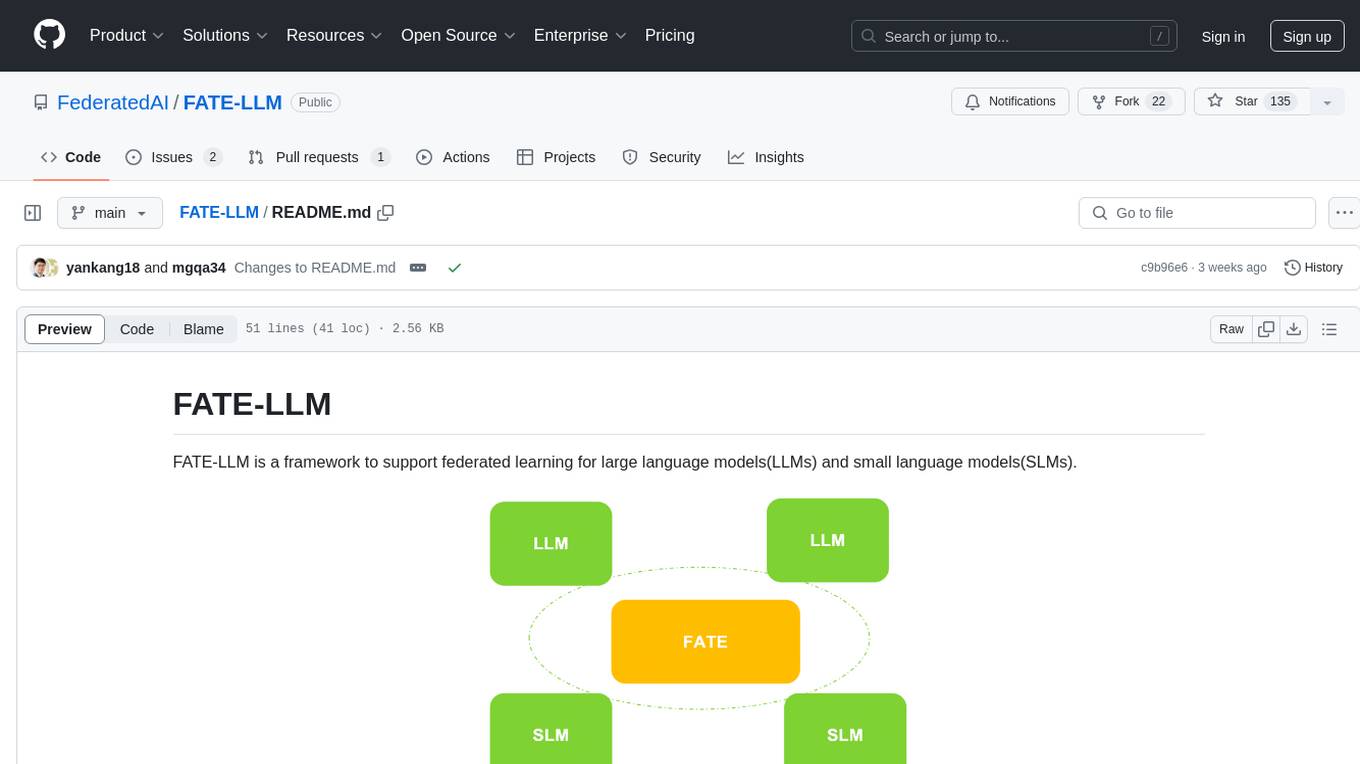
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
Grounding_LLMs_with_online_RL
This repository contains code for grounding large language models' knowledge in BabyAI-Text using the GLAM method. It includes the BabyAI-Text environment, code for experiments, and training agents. The repository is structured with folders for the environment, experiments, agents, configurations, SLURM scripts, and training scripts. Installation steps involve creating a conda environment, installing PyTorch, required packages, BabyAI-Text, and Lamorel. The launch process involves using Lamorel with configs and training scripts. Users can train a language model and evaluate performance on test episodes using provided scripts and config entries.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

crab
CRAB is a framework for building LLM agent benchmark environments in a Python-centric way. It is cross-platform and multi-environment, allowing the creation of agent environments supporting various deployment options. The framework offers easy-to-use configuration with the ability to add new actions and define environments seamlessly. CRAB also provides a novel benchmarking suite with tasks and evaluators defined in Python, along with a unique graph evaluator method for detailed metrics.
multipack_sampler
The Multipack sampler is a tool designed for padding-free distributed training of large language models. It optimizes batch processing efficiency using an approximate solution to the identical machine scheduling problem. The V2 update further enhances the packing algorithm complexity, achieving better throughput for a large number of nodes. It includes two variants for models with different attention types, aiming to balance sequence lengths and optimize packing efficiency. Users can refer to the provided benchmark for evaluating efficiency, utilization, and L^2 lag. The tool is compatible with PyTorch DataLoader and is released under the MIT license.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
CALF
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
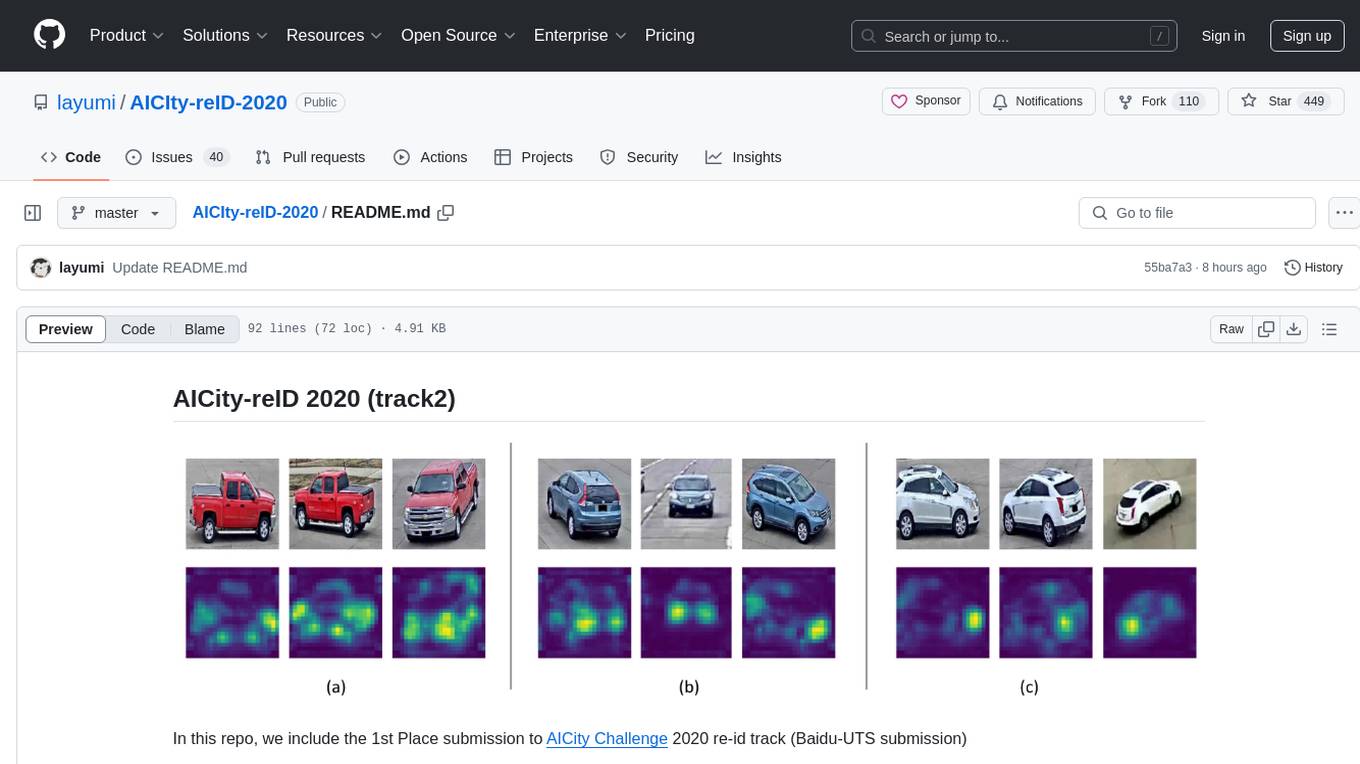
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.
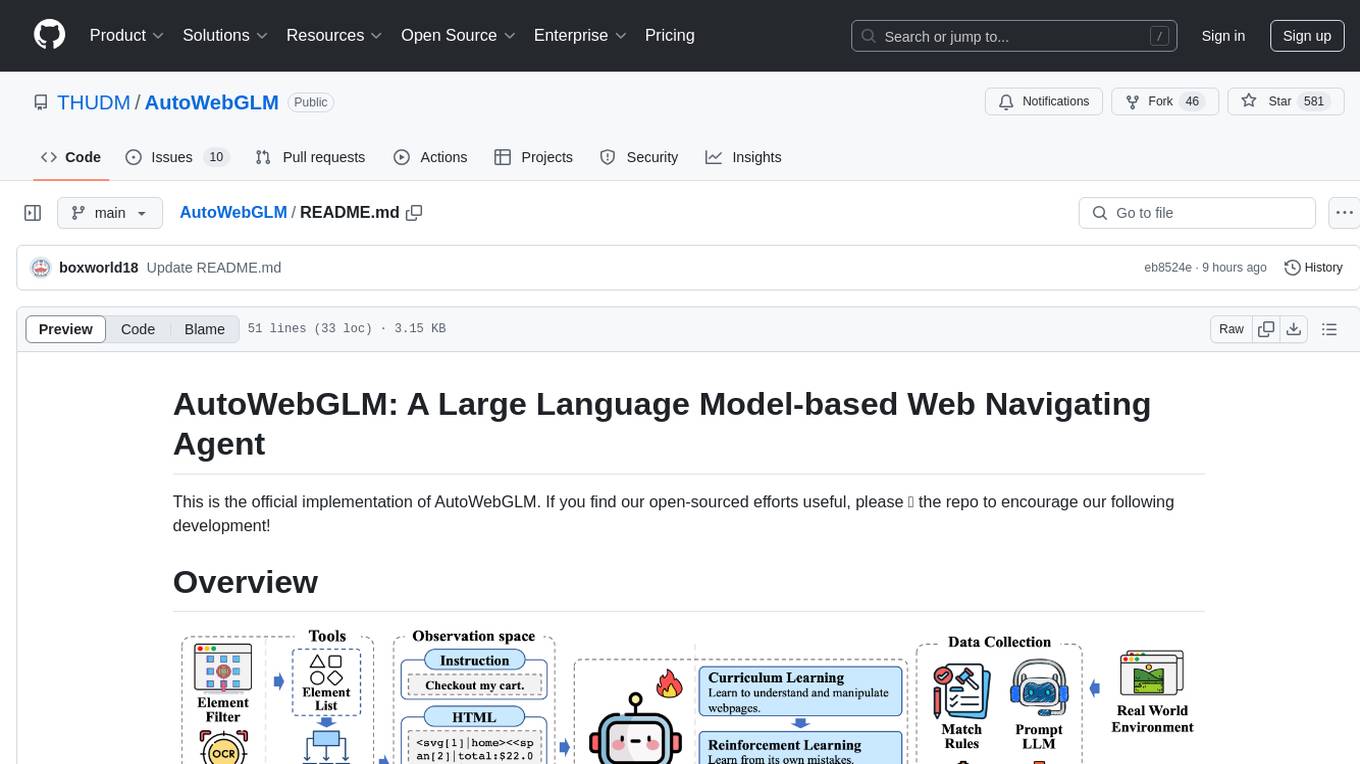
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.
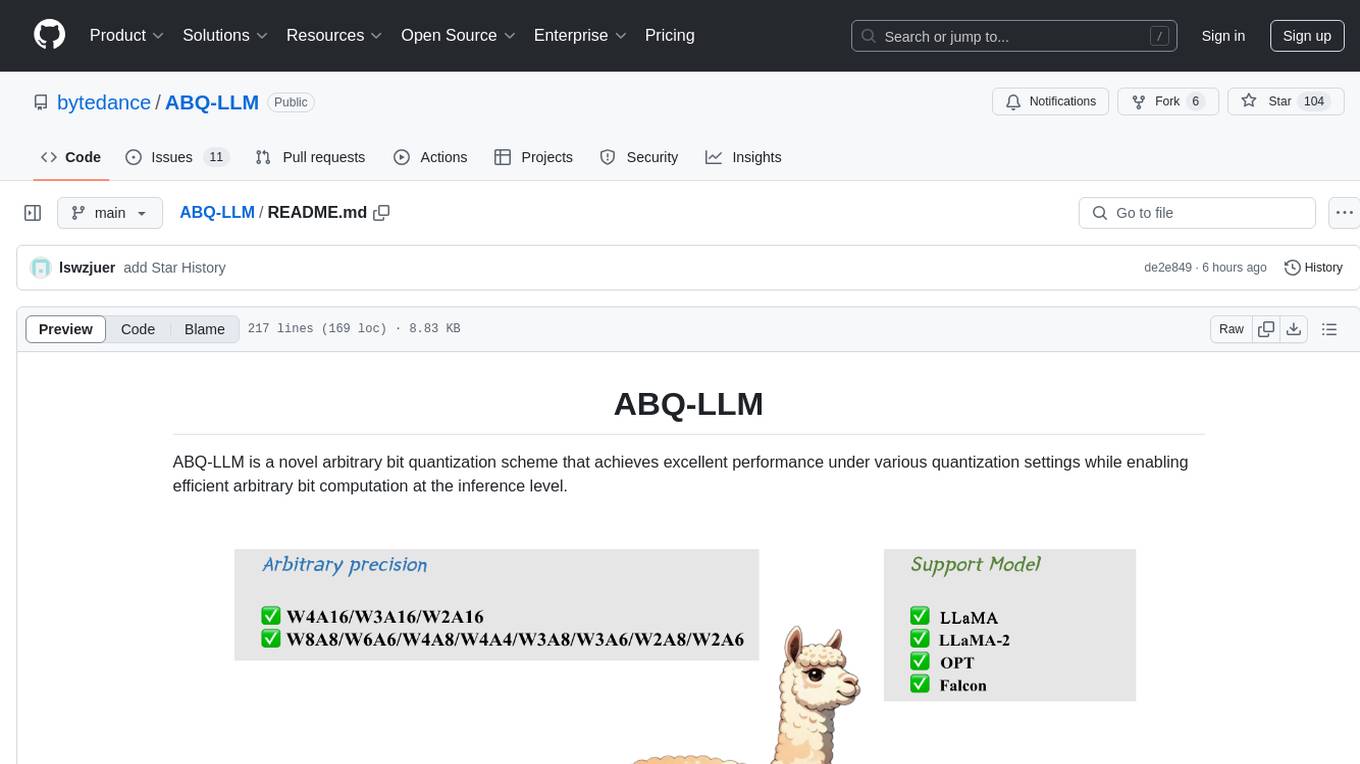
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.
RAGHub
RAGHub is a community-driven project focused on cataloging new and emerging frameworks, projects, and resources in the Retrieval-Augmented Generation (RAG) ecosystem. It aims to help users stay ahead of changes in the field by providing a platform for the latest innovations in RAG. The repository includes information on RAG frameworks, evaluation frameworks, optimization frameworks, citation frameworks, engines, search reranker frameworks, projects, resources, and real-world use cases across industries and professions.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.

fastfit
FastFit is a Python package designed for fast and accurate few-shot classification, especially for scenarios with many semantically similar classes. It utilizes a novel approach integrating batch contrastive learning and token-level similarity score, significantly improving multi-class classification performance in speed and accuracy across various datasets. FastFit provides a convenient command-line tool for training text classification models with customizable parameters. It offers a 3-20x improvement in training speed, completing training in just a few seconds. Users can also train models with Python scripts and perform inference using pretrained models for text classification tasks.
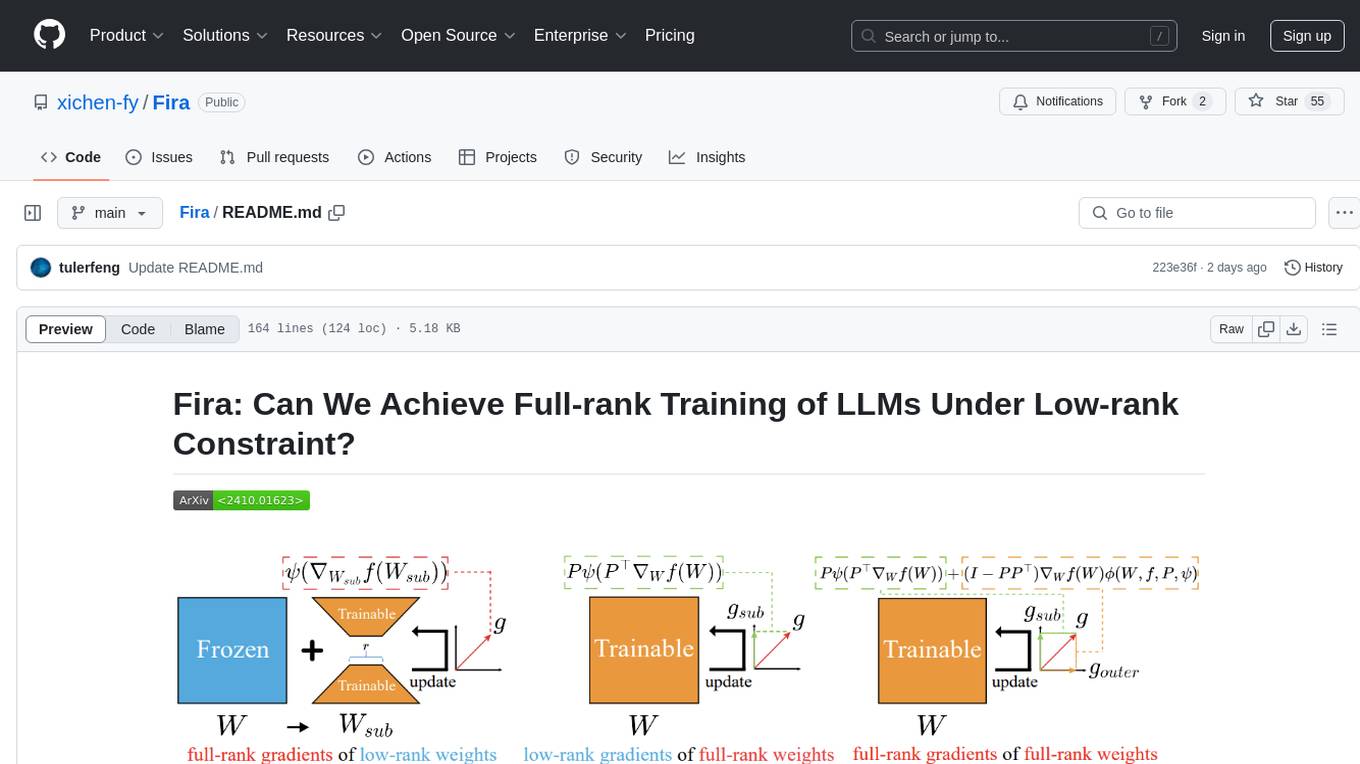
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
ProactiveAgent
Proactive Agent is a project aimed at constructing a fully active agent that can anticipate user's requirements and offer assistance without explicit requests. It includes a data collection and generation pipeline, automatic evaluator, and training agent. The project provides datasets, evaluation scripts, and prompts to finetune LLM for proactive agent. Features include environment sensing, assistance annotation, dynamic data generation, and construction pipeline with a high F1 score on the test set. The project is intended for coding, writing, and daily life scenarios, distributed under Apache License 2.0.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
vicinity
Vicinity is a lightweight, low-dependency vector store that provides a unified interface for nearest neighbor search with support for different backends and evaluation. It simplifies the process of comparing and evaluating different nearest neighbors packages by offering a simple and intuitive API. Users can easily experiment with various indexing methods and distance metrics to choose the best one for their use case. Vicinity also allows for measuring performance metrics like queries per second and recall.
lingua
Meta Lingua is a minimal and fast LLM training and inference library designed for research. It uses easy-to-modify PyTorch components to experiment with new architectures, losses, and data. The codebase enables end-to-end training, inference, and evaluation, providing tools for speed and stability analysis. The repository contains essential components in the 'lingua' folder and scripts that combine these components in the 'apps' folder. Researchers can modify the provided templates to suit their experiments easily. Meta Lingua aims to lower the barrier to entry for LLM research by offering a lightweight and focused codebase.
llm_aigc
The llm_aigc repository is a comprehensive resource for everything related to llm (Large Language Models) and aigc (AI Governance and Control). It provides detailed information, resources, and tools for individuals interested in understanding and working with large language models and AI governance and control. The repository covers a wide range of topics including model training, evaluation, deployment, ethics, and regulations in the AI field.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.
awesome-ai-tools
This repository contains a curated list of awesome AI tools that can be used for various machine learning and artificial intelligence projects. It includes tools for data preprocessing, model training, evaluation, and deployment. The list is regularly updated with new tools and resources to help developers and data scientists in their AI projects.
kvpress
This repository implements multiple key-value cache pruning methods and benchmarks using transformers, aiming to simplify the development of new methods for researchers and developers in the field of long-context language models. It provides a set of 'presses' that compress the cache during the pre-filling phase, with each press having a compression ratio attribute. The repository includes various training-free presses, special presses, and supports KV cache quantization. Users can contribute new presses and evaluate the performance of different presses on long-context datasets.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.

ModernBERT
ModernBERT is a repository focused on modernizing BERT through architecture changes and scaling. It introduces FlexBERT, a modular approach to encoder building blocks, and heavily relies on .yaml configuration files to build models. The codebase builds upon MosaicBERT and incorporates Flash Attention 2. The repository is used for pre-training and GLUE evaluations, with a focus on reproducibility and documentation. It provides a collaboration between Answer.AI, LightOn, and friends.
KernelBench
KernelBench is a benchmark tool designed to evaluate Large Language Models' (LLMs) ability to generate GPU kernels. It focuses on transpiling operators from PyTorch to CUDA kernels at different levels of granularity. The tool categorizes problems into four levels, ranging from single-kernel operators to full model architectures, and assesses solutions based on compilation, correctness, and speed. The repository provides a structured directory layout, setup instructions, usage examples for running single or multiple problems, and upcoming roadmap features like additional GPU platform support and integration with other frameworks.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
InsPLAD
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.
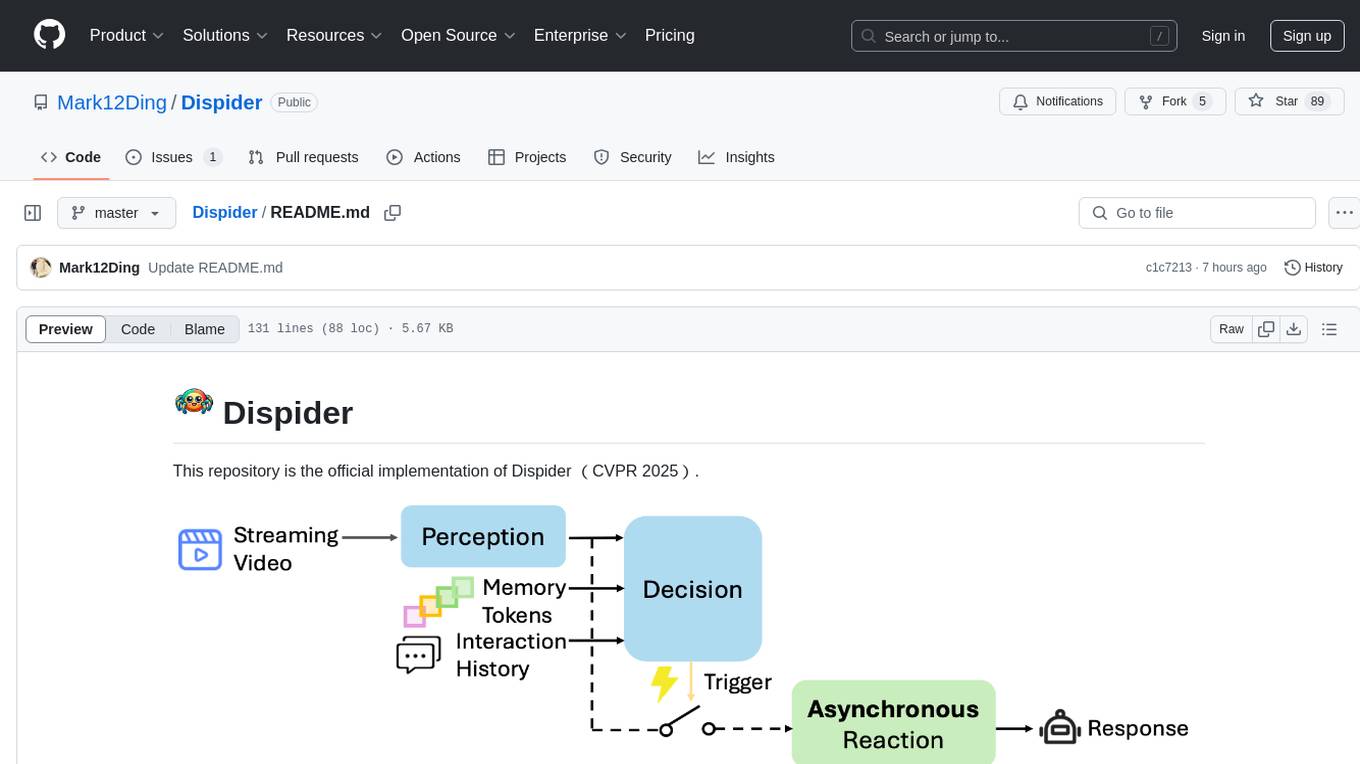
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
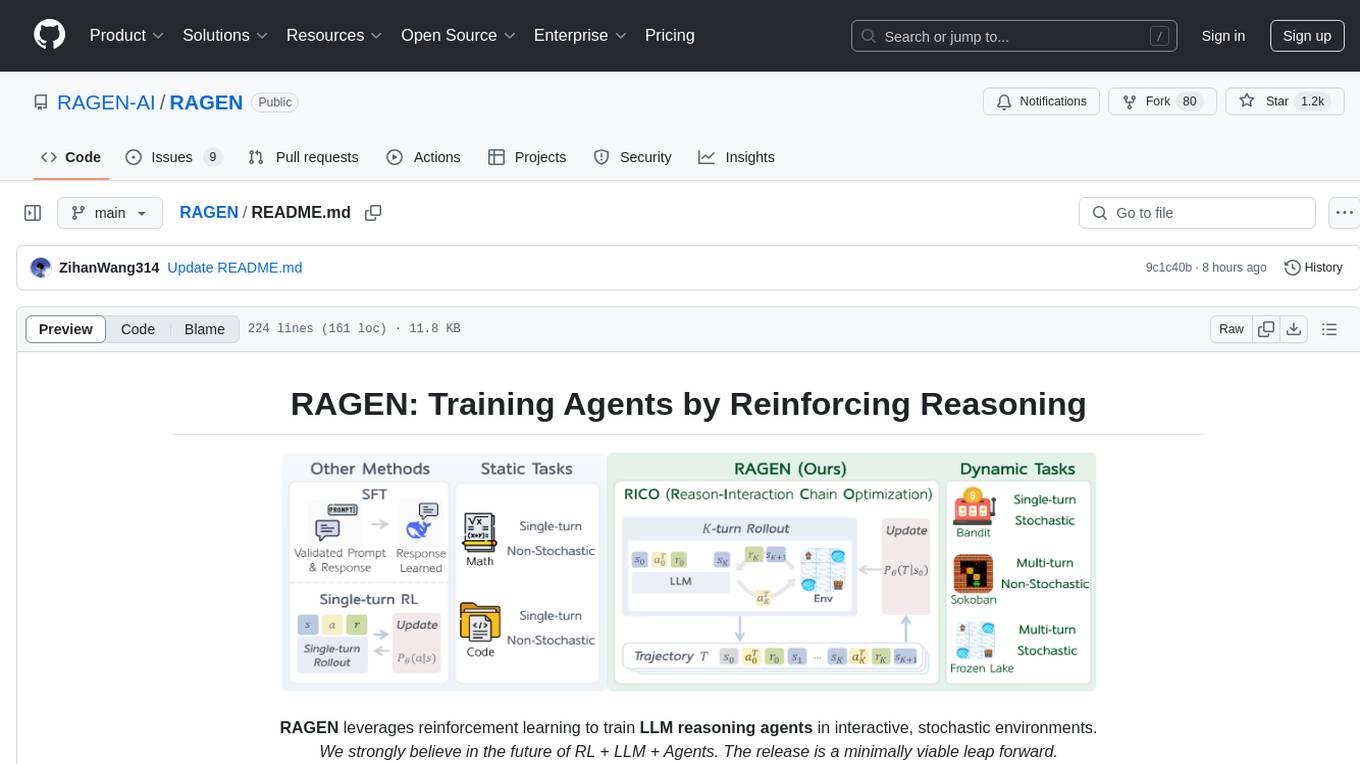
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework consists of MDP formulation, RICO algorithm with rollout and update stages, and reward normalization strategies to stabilize training. RAGEN aims to optimize reasoning and action strategies for LLM agents operating in complex environments.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.
Automodel
Automodel is a Python library for automating the process of building and evaluating machine learning models. It provides a set of tools and utilities to streamline the model development workflow, from data preprocessing to model selection and evaluation. With Automodel, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to find the best model for their dataset. The library is designed to be user-friendly and customizable, allowing users to define their own pipelines and workflows. Automodel is suitable for data scientists, machine learning engineers, and anyone looking to quickly build and test machine learning models without the need for manual intervention.

notebooks
The 'notebooks' repository contains a collection of fine-tuning notebooks for various models, including Gemma3N, Qwen3, Llama 3.2, Phi-4, Mistral v0.3, and more. These notebooks are designed for tasks such as data preparation, model training, evaluation, and model saving. Users can access guided notebooks for different types of models like Conversational, Vision, TTS, GRPO, and more. The repository also includes specific use-case notebooks for tasks like text classification, tool calling, multiple datasets, KTO, inference chat UI, conversational tasks, chatML, and text completion.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.

mmore
MMORE is an open-source, end-to-end pipeline for ingesting, processing, indexing, and retrieving knowledge from various file types such as PDFs, Office docs, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and offers hybrid dense+sparse retrieval with an integrated RAG service through CLI and APIs.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.
ai-sdk-tools
The ai-sdk-tools repository contains a collection of tools and utilities for developing and deploying AI models. It includes modules for data preprocessing, model training, evaluation, and deployment. The tools are designed to streamline the AI development process and improve efficiency. With a focus on usability and performance, this toolkit aims to support developers in building robust and scalable AI applications.

langtest
Langtest is a tool designed for testing and analyzing programming languages. It provides a platform for users to write code snippets in various languages and run them to see the output. The tool supports multiple programming languages and offers features like syntax highlighting, code execution, and result comparison. Users can use Langtest to quickly test code snippets, compare language syntax, and evaluate language performance. It is a useful tool for students, developers, and language enthusiasts to experiment with different programming languages in a convenient and efficient manner.
oreilly-ai-agents
This repository contains code for O'Reilly Live Online Training for AI Agents A-Z and Modern Automated AI Agents video series. It provides a guide to understanding, implementing, and managing AI agents, covering frameworks like CrewAI, LangChain, and AutoGen. Participants learn to build agents from scratch using prompt engineering techniques, deploy AI agents, evaluate performance, and make informed decisions in AI projects.
dranet
Dranet is a Python library for analyzing and visualizing data from neural networks. It provides tools for interpreting model predictions, understanding feature importance, and evaluating model performance. With Dranet, users can gain insights into how neural networks make decisions and improve model transparency and interpretability.
LLaVA-OneVision-1.5
LLaVA-OneVision 1.5 is a fully open framework for democratized multimodal training, introducing a novel family of large multimodal models achieving state-of-the-art performance at lower cost through training on native resolution images. It offers superior performance across multiple benchmarks, high-quality data at scale with concept-balanced and diverse caption data, and an ultra-efficient training framework with support for MoE, FP8, and long sequence parallelization. The framework is fully open for community access and reproducibility, providing high-quality pre-training & SFT data, complete training framework & code, training recipes & configurations, and comprehensive training logs & metrics.
plexe
Plexe is a tool that allows users to create machine learning models by describing them in plain language. Users can explain their requirements, provide a dataset, and the AI-powered system will build a fully functional model through an automated agentic approach. It supports multiple AI agents and model building frameworks like XGBoost, CatBoost, and Keras. Plexe also provides Docker images with pre-configured environments, YAML configuration for customization, and support for multiple LiteLLM providers. Users can visualize experiment results using the built-in Streamlit dashboard and extend Plexe's functionality through custom integrations.
20 - OpenAI Gpts
Evaluation Criteria Creator
Simply write any topic (anything superheroes, vacuums, Pokémon’, diamonds…) and I’ll provide the evaluation criteria you can use.




Organization & Team Effectiveness Advisor
Guides organizational effectiveness via team-focused strategies and learning.

Asesor del Mejor juego de Fútbol
Experto en FIFA, proporciona consejos de estrategia y análisis de juego.

AI Market Analyzer
Analyzes markets, offers predictions on commodities, crypto, and companies.
Wordon, World's Worst Customer | Divergent AI
I simulate tough Customer Support scenarios for Agent Training.

Skills Development Advisor
Enhances organizational performance through strategic skills development initiatives.
Learning & Development Advisor
Enhances organizational performance through employee learning and development initiatives.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms

Leadership Development Advisor
Guides leadership growth to enhance organizational performance.

Training Material Design Advisor
Designs effective training materials to enhance organizational learning and performance.