
FATE-LLM
Federated Learning for LLMs.
Stars: 135
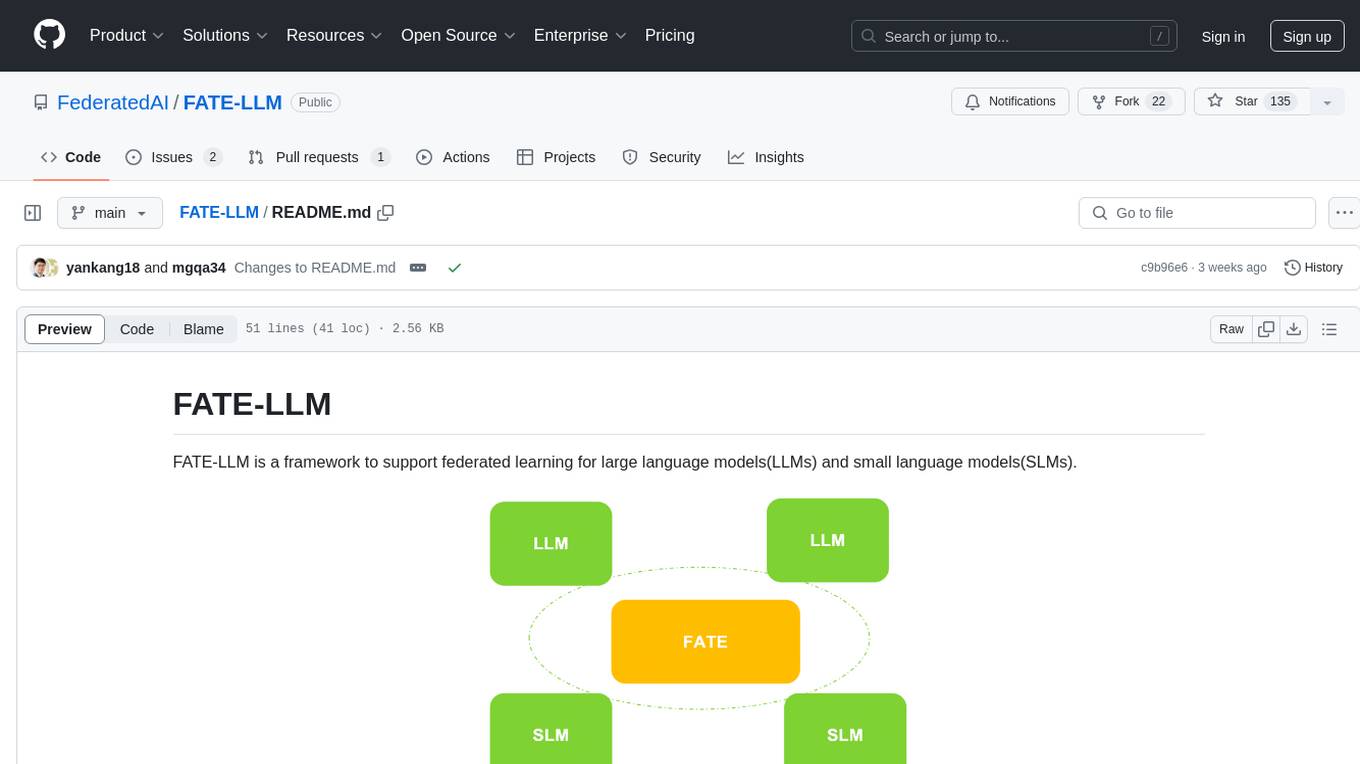
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.
README:
FATE-LLM is a framework to support federated learning for large language models(LLMs) and small language models(SLMs).

- Federated learning for large language models(LLMs) and small language models(SLMs).
- Promote training efficiency of federated LLMs using Parameter-Efficient methods.
- Protect the IP of LLMs using FedIPR.
- Protect data privacy during training and inference through privacy preserving mechanisms.

Please refer to FATE-Standalone deployment.
- To deploy FATE-LLM v2.0, deploy FATE-Standalone with version >= 2.1, then make a new directory
{fate_install}/fate_llmand clone the code into it, install the python requirements, and add{fate_install}/fate_llm/pythontoPYTHONPATH - To deploy FATE-LLM v1.x, deploy FATE-Standalone with 1.11.3 <= version < 2.0, then copy directory
python/fate_llmto{fate_install}/fate/python/fate_llm
Use FATE-LLM deployment packages to deploy, refer to FATE-Cluster deployment for more deployment details.
- Federated ChatGLM3-6B Training
- Builtin Models In PELLM
- Offsite Tuning: Transfer Learning without Full Model
- FedKSeed: Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
- InferDPT: Privacy-preserving Inference for Black-box Large Language Models
- FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
If you publish work that uses FATE-LLM, please cite FATE-LLM as follows:
@article{fan2023fate,
title={Fate-llm: A industrial grade federated learning framework for large language models},
author={Fan, Tao and Kang, Yan and Ma, Guoqiang and Chen, Weijing and Wei, Wenbin and Fan, Lixin and Yang, Qiang},
journal={Symposium on Advances and Open Problems in Large Language Models (LLM@IJCAI'23)},
year={2023}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FATE-LLM
Similar Open Source Tools
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

crab
CRAB is a framework for building LLM agent benchmark environments in a Python-centric way. It is cross-platform and multi-environment, allowing the creation of agent environments supporting various deployment options. The framework offers easy-to-use configuration with the ability to add new actions and define environments seamlessly. CRAB also provides a novel benchmarking suite with tasks and evaluators defined in Python, along with a unique graph evaluator method for detailed metrics.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.
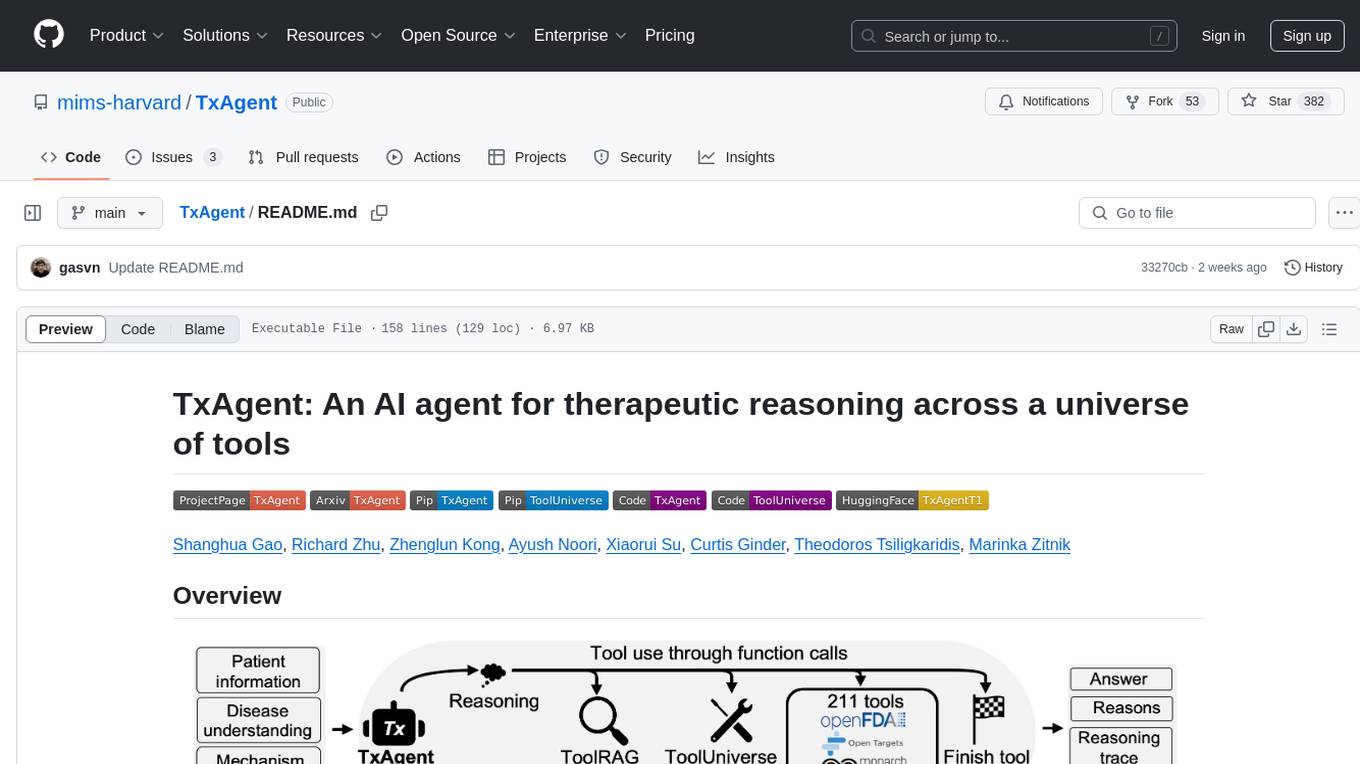
TxAgent
TxAgent is an AI agent designed for precision therapeutics, leveraging multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools. It evaluates drug interactions, contraindications, and tailors treatment strategies to individual patient characteristics. TxAgent outperforms leading models across various drug reasoning tasks and personalized treatment scenarios, ensuring treatment recommendations align with clinical guidelines and real-world evidence.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

AIOS
AIOS, a Large Language Model (LLM) Agent operating system, embeds large language model into Operating Systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, maintain access control for agents, and provide a rich set of toolkits for LLM Agent developers.

Vision-LLM-Alignment
Vision-LLM-Alignment is a repository focused on implementing alignment training for visual large language models (LLMs), including SFT training, reward model training, and PPO/DPO training. It supports various model architectures and provides datasets for training. The repository also offers benchmark results and installation instructions for users.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.