
burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
Stars: 10180

Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
README:



![]()

Burn is a new comprehensive dynamic Deep Learning Framework built using Rust
with extreme
flexibility, compute efficiency and portability as its primary goals.

Because we believe the goal of a deep learning framework is to convert computation into useful intelligence, we have made performance a core pillar of Burn. We strive to achieve top efficiency by leveraging multiple optimization techniques described below.
Click on each section for more details 👇
Automatic kernel fusion 💥
Using Burn means having your models optimized on any backend. When possible, we provide a way to automatically and dynamically create custom kernels that minimize data relocation between different memory spaces, extremely useful when moving memory is the bottleneck.
As an example, you could write your own GELU activation function with the high level tensor api (see Rust code snippet below).
fn gelu_custom<B: Backend, const D: usize>(x: Tensor<B, D>) -> Tensor<B, D> {
let x = x.clone() * ((x / SQRT_2).erf() + 1);
x / 2
}Then, at runtime, a custom low-level kernel will be automatically created for your specific implementation and will rival a handcrafted GPU implementation. The kernel consists of about 60 lines of WGSL WebGPU Shading Language, an extremely verbose lower level shader language you probably don't want to program your deep learning models in!
As of now, our fusion strategy is only implemented for our own WGPU and CUDA backends and supports only a subset of operations. We plan to add more operations very soon and extend this technique to other future in-house backends.
Asynchronous execution ❤️🔥
For backends developed from scratch by the Burn team, an asynchronous execution style is used, which allows to perform various optimizations, such as the previously mentioned automatic kernel fusion.
Asynchronous execution also ensures that the normal execution of the framework does not block the model computations, which implies that the framework overhead won't impact the speed of execution significantly. Conversely, the intense computations in the model do not interfere with the responsiveness of the framework. For more information about our asynchronous backends, see this blog post.
Thread-safe building blocks 🦞
Burn emphasizes thread safety by leveraging the ownership system of Rust. With Burn, each module is the owner of its weights. It is therefore possible to send a module to another thread for computing the gradients, then send the gradients to the main thread that can aggregate them, and voilà, you get multi-device training.
This is a very different approach from what PyTorch does, where backpropagation actually mutates the grad attribute of each tensor parameter. This is not a thread-safe operation and therefore requires lower level synchronization primitives, see distributed training for reference. Note that this is still very fast, but not compatible across different backends and quite hard to implement.
Intelligent memory management 🦀
One of the main roles of a deep learning framework is to reduce the amount of memory necessary to run models. The naive way of handling memory is that each tensor has its own memory space, which is allocated when the tensor is created then deallocated as the tensor gets out of scope. However, allocating and deallocating data is very costly, so a memory pool is often required to achieve good throughput. Burn offers an infrastructure that allows for easily creating and selecting memory management strategies for backends. For more details on memory management in Burn, see this blog post.
Another very important memory optimization of Burn is that we keep track of when a tensor can be mutated in-place just by using the ownership system well. Even though it is a rather small memory optimization on its own, it adds up considerably when training or running inference with larger models and contributes to reduce the memory usage even more. For more information, see this blog post about tensor handling.
Automatic kernel selection 🎯
A good deep learning framework should ensure that models run smoothly on all hardware. However, not all hardware share the same behavior in terms of execution speed. For instance, a matrix multiplication kernel can be launched with many different parameters, which are highly sensitive to the size of the matrices and the hardware. Using the wrong configuration could reduce the speed of execution by a large factor (10 times or even more in extreme cases), so choosing the right kernels becomes a priority.
With our home-made backends, we run benchmarks automatically and choose the best configuration for the current hardware and matrix sizes with a reasonable caching strategy.
This adds a small overhead by increasing the warmup execution time, but stabilizes quickly after a few forward and backward passes, saving lots of time in the long run. Note that this feature isn't mandatory, and can be disabled when cold starts are a priority over optimized throughput.
Hardware specific features 🔥
It is no secret that deep learning is mostly relying on matrix multiplication as its core operation, since this is how fully-connected neural networks are modeled.
More and more, hardware manufacturers optimize their chips specifically for matrix multiplication workloads. For instance, Nvidia has its Tensor Cores and today most cellphones have AI specialized chips. As of this moment, we support Tensor Cores with our LibTorch, Candle, CUDA and WGPU/SPIR-V backends, but not other accelerators yet. We hope this issue gets resolved at some point to bring support to our WGPU backend.
Custom Backend Extension 🎒
Burn aims to be the most flexible deep learning framework. While it's crucial to maintain compatibility with a wide variety of backends, Burn also provides the ability to extend the functionalities of a backend implementation to suit your personal modeling requirements.
This versatility is advantageous in numerous ways, such as supporting custom operations like flash attention or manually writing your own kernel for a specific backend to enhance performance. See this section in the Burn Book 🔥 for more details.

The whole deep learning workflow is made easy with Burn, as you can monitor your training progress with an ergonomic dashboard, and run inference everywhere from embedded devices to large GPU clusters.
Burn was built from the ground up with training and inference in mind. It's also worth noting how Burn, in comparison to frameworks like PyTorch, simplifies the transition from training to deployment, eliminating the need for code changes.
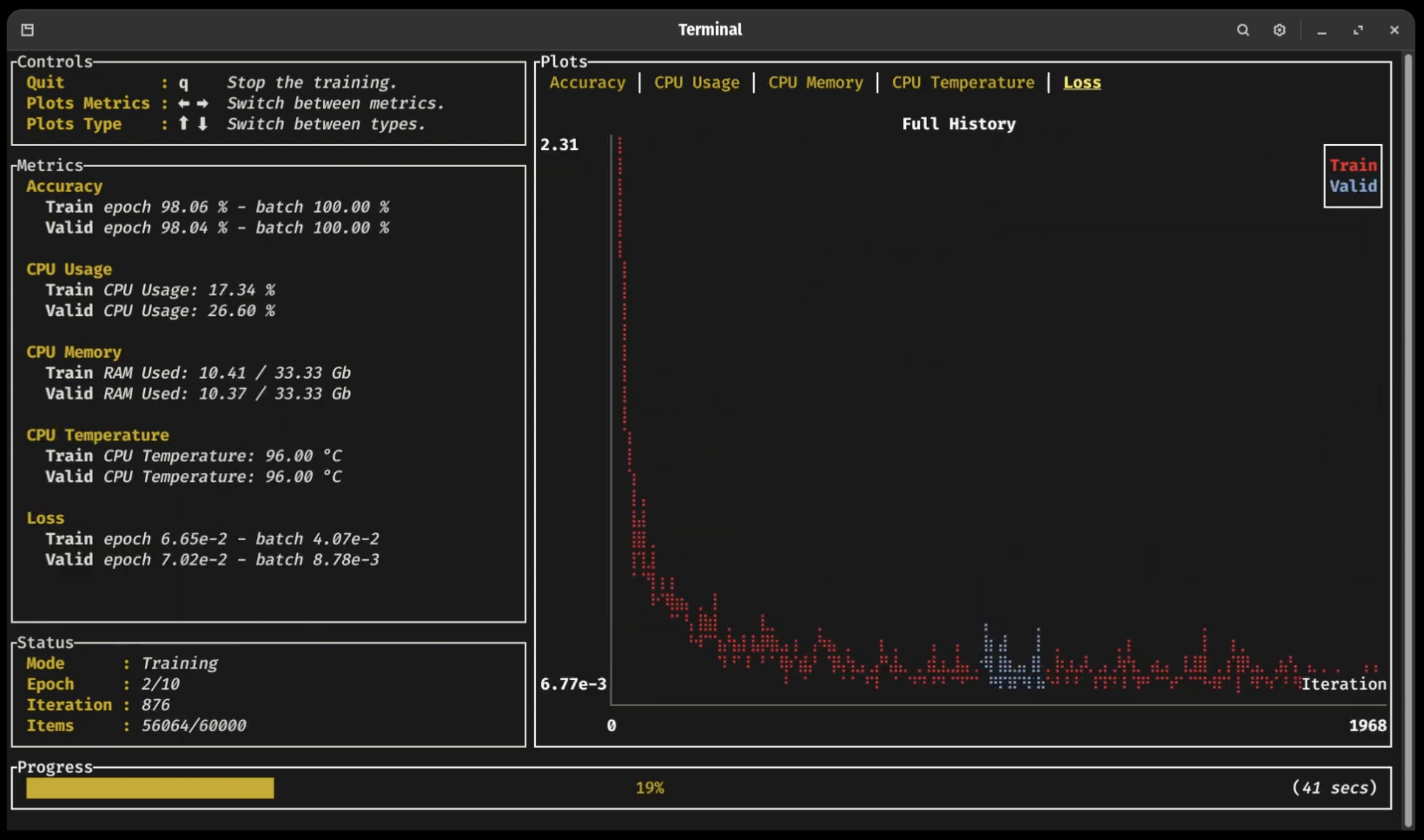
Click on the following sections to expand 👇
Training Dashboard 📈
As you can see in the previous video (click on the picture!), a new terminal UI dashboard based on the Ratatui crate allows users to follow their training with ease without having to connect to any external application.
You can visualize your training and validation metrics updating in real-time and analyze the lifelong progression or recent history of any registered metrics using only the arrow keys. Break from the training loop without crashing, allowing potential checkpoints to be fully written or important pieces of code to complete without interruption 🛡
ONNX Support 🐫
ONNX (Open Neural Network Exchange) is an open-standard format that exports both the architecture and the weights of a deep learning model.
Burn supports the importation of models that follow the ONNX standard so you can easily port a model you have written in another framework like TensorFlow or PyTorch to Burn to benefit from all the advantages our framework offers.
Our ONNX support is further described in this section of the Burn Book 🔥.
Note: This crate is in active development and currently supports a limited set of ONNX operators.
Importing PyTorch Models 🚚
Support for loading of PyTorch model weights into Burn’s native model architecture, ensuring seamless integration. See Burn Book 🔥 section on importing PyTorch
Inference in the Browser 🌐
Several of our backends can compile to Web Assembly: Candle and NdArray for CPU, and WGPU for GPU. This means that you can run inference directly within a browser. We provide several examples of this:
- MNIST where you can draw digits and a small convnet tries to find which one it is! 2️⃣ 7️⃣ 😰
- Image Classification where you can upload images and classify them! 🌄
Embedded: no_std support ⚙️
Burn's core components support no_std. This means it can run in bare metal environment such as embedded devices without an operating system.
As of now, only the NdArray backend can be used in a no_std environment.
 Burn strives to be as fast as possible on as many hardwares as possible, with robust implementations.
We believe this flexibility is crucial for modern needs where you may train your models in the cloud,
then deploy on customer hardwares, which vary from user to user.
Burn strives to be as fast as possible on as many hardwares as possible, with robust implementations.
We believe this flexibility is crucial for modern needs where you may train your models in the cloud,
then deploy on customer hardwares, which vary from user to user.
Compared to other frameworks, Burn has a very different approach to supporting many backends. By design, most code is generic over the Backend trait, which allows us to build Burn with swappable backends. This makes composing backend possible, augmenting them with additional functionalities such as autodifferentiation and automatic kernel fusion.
We already have many backends implemented, all listed below 👇
WGPU (WebGPU): Cross-Platform GPU Backend 🌐
The go-to backend for running on any GPU.
Based on the most popular and well-supported Rust graphics library, WGPU, this backend automatically targets Vulkan, OpenGL, Metal, Direct X11/12, and WebGPU, by using the WebGPU shading language WGSL, or optionally SPIR-V when targeting Vulkan. It can also be compiled to Web Assembly to run in the browser while leveraging the GPU, see this demo. For more information on the benefits of this backend, see this blog.
The WGPU backend is our first "in-house backend", which means we have complete control over its implementation details. It is fully optimized with the performance characteristics mentioned earlier, as it serves as our research playground for a variety of optimizations. We've since added CUDA, ROCm and SPIR-V support using the same compiler infrastructure, so a kernel written for burn once, can run anywhere.
See the WGPU Backend README and CUDA Backend README for more details.
Candle: Backend using the Candle bindings 🕯
Based on Candle by Hugging Face, a minimalist ML framework for Rust with a focus on performance and ease of use, this backend can run on CPU with support for Web Assembly or on Nvidia GPUs using CUDA.
See the Candle Backend README for more details.
Disclaimer: This backend is not fully completed yet, but can work in some contexts like inference.
LibTorch: Backend using the LibTorch bindings 🎆
PyTorch doesn't need an introduction in the realm of deep learning. This backend leverages PyTorch Rust bindings, enabling you to use LibTorch C++ kernels on CPU, CUDA and Metal.
See the LibTorch Backend README for more details.
NdArray: Backend using the NdArray primitive as data structure 🦐
This CPU backend is admittedly not our fastest backend, but offers extreme portability.
It is our only backend supporting no_std.
See the NdArray Backend README for more details.
Autodiff: Backend decorator that brings backpropagation to any backend 🔄
Contrary to the aforementioned backends, Autodiff is actually a backend decorator. This means that it cannot exist by itself; it must encapsulate another backend.
The simple act of wrapping a base backend with Autodiff transparently equips it with autodifferentiation support, making it possible to call backward on your model.
use burn::backend::{Autodiff, Wgpu};
use burn::tensor::{Distribution, Tensor};
fn main() {
type Backend = Autodiff<Wgpu>;
let x: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default);
let y: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}Of note, it is impossible to make the mistake of calling backward on a model that runs on a backend that does not support autodiff (for inference), as this method is only offered by an Autodiff backend.
See the Autodiff Backend README for more details.
Fusion: Backend decorator that brings kernel fusion to backends that support it 💥
This backend decorator enhances a backend with kernel fusion, provided that the inner backend supports it. Note that you can compose this backend with other backend decorators such as Autodiff. For now, only the WGPU and CUDA backends have support for fused kernels.
use burn::backend::{Autodiff, Fusion, Wgpu};
use burn::tensor::{Distribution, Tensor};
fn main() {
type Backend = Autodiff<Fusion<Wgpu>>;
let x: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default);
let y: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}Of note, we plan to implement automatic gradient checkpointing based on compute bound and memory bound operations, which will work gracefully with the fusion backend to make your code run even faster during training, see this issue.
See the Fusion Backend README for more details.

Just heard of Burn? You are at the right place! Just continue reading this section and we hope you can get on board really quickly.
The Burn Book 🔥
To begin working effectively with Burn, it is crucial to understand its key components and philosophy. This is why we highly recommend new users to read the first sections of The Burn Book 🔥. It provides detailed examples and explanations covering every facet of the framework, including building blocks like tensors, modules, and optimizers, all the way to advanced usage, like coding your own GPU kernels.
The project is constantly evolving, and we try as much as possible to keep the book up to date with new additions. However, we might miss some details sometimes, so if you see something weird, let us know! We also gladly accept Pull Requests 😄
Examples 🙏
Let's start with a code snippet that shows how intuitive the framework is to use! In the following, we declare a neural network module with some parameters along with its forward pass.
use burn::nn;
use burn::module::Module;
use burn::tensor::backend::Backend;
#[derive(Module, Debug)]
pub struct PositionWiseFeedForward<B: Backend> {
linear_inner: nn::Linear<B>,
linear_outer: nn::Linear<B>,
dropout: nn::Dropout,
gelu: nn::Gelu,
}
impl<B: Backend> PositionWiseFeedForward<B> {
pub fn forward<const D: usize>(&self, input: Tensor<B, D>) -> Tensor<B, D> {
let x = self.linear_inner.forward(input);
let x = self.gelu.forward(x);
let x = self.dropout.forward(x);
self.linear_outer.forward(x)
}
}We have a somewhat large amount of examples in the repository that shows how to use the framework in different scenarios.
Following the book:
-
Basic Workflow : Creates a custom CNN
Moduleto train on the MNIST dataset and use for inference. -
Custom Training Loop : Implements a basic training loop instead
of using the
Learner. - Custom WGPU Kernel : Learn how to create your own custom operation with the WGPU backend.
Additional examples:
- Custom CSV Dataset : Implements a dataset to parse CSV data for a regression task.
- Regression : Trains a simple MLP on the California Housing dataset to predict the median house value for a district.
- Custom Image Dataset : Trains a simple CNN on custom image dataset following a simple folder structure.
-
Custom Renderer : Implements a custom renderer to display the
Learnerprogress. - Image Classification Web : Image classification web browser demo using Burn, WGPU and WebAssembly.
- MNIST Inference on Web : An interactive MNIST inference demo in the browser. The demo is available online.
-
MNIST Training : Demonstrates how to train a custom
Module(MLP) with theLearnerconfigured to log metrics and keep training checkpoints. -
Named Tensor : Performs operations with the experimental
NamedTensorfeature. - ONNX Import Inference : Imports an ONNX model pre-trained on MNIST to perform inference on a sample image with Burn.
- PyTorch Import Inference : Imports a PyTorch model pre-trained on MNIST to perform inference on a sample image with Burn.
- Text Classification : Trains a text classification transformer model on the AG News or DbPedia dataset. The trained model can then be used to classify a text sample.
- Text Generation : Trains a text generation transformer model on the DbPedia dataset.
- Wasserstein GAN MNIST : Trains a WGAN model to generate new handwritten digits based on MNIST.
For more practical insights, you can clone the repository and run any of them directly on your computer!
Pre-trained Models 🤖
We keep an updated and curated list of models and examples built with Burn, see the tracel-ai/models repository for more details.
Don't see the model you want? Don't hesitate to open an issue, and we may prioritize it. Built a model using Burn and want to share it? You can also open a Pull Request and add your model under the community section!
Why use Rust for Deep Learning? 🦀
Deep Learning is a special form of software where you need very high level abstractions as well as extremely fast execution time. Rust is the perfect candidate for that use case since it provides zero-cost abstractions to easily create neural network modules, and fine-grained control over memory to optimize every detail.
It's important that a framework be easy to use at a high level so that its users can focus on innovating in the AI field. However, since running models relies so heavily on computations, performance can't be neglected.
To this day, the mainstream solution to this problem has been to offer APIs in Python, but rely on bindings to low-level languages such as C/C++. This reduces portability, increases complexity and creates frictions between researchers and engineers. We feel like Rust's approach to abstractions makes it versatile enough to tackle this two languages dichotomy.
Rust also comes with the Cargo package manager, which makes it incredibly easy to build, test, and deploy from any environment, which is usually a pain in Python.
Although Rust has the reputation of being a difficult language at first, we strongly believe it leads to more reliable, bug-free solutions built faster (after some practice 😅)!
Deprecation Note
Since0.14.0, the internal structure for tensor data has changed. The previousDatastruct was deprecated and officially removed since0.17.0in favor of the newTensorDatastruct, which allows for more flexibility by storing the underlying data as bytes and keeping the data type as a field. If you are usingDatain your code, make sure to switch toTensorData.
Loading Model Records From Previous Versions ⚠️
In the event that you are trying to load a model record saved in a version older than 0.14.0, make
sure to use a compatible version (0.14, 0.15 or 0.16) with the record-backward-compat
feature flag.
features = [..., "record-backward-compat"]
Otherwise, the record won't be deserialized correctly and you will get an error message. This error will also point you to the backward compatible feature flag.
The backward compatibility was maintained for deserialization when loading records. Therefore, as soon as you have saved the record again it will be saved according to the new structure and you can upgrade back to the current version
Please note that binary formats are not backward compatible. Thus, you will need to load your record
in a previous version and save it in any of the other self-describing record format (e.g., using the
NamedMpkFileRecorder) before using a compatible version (as described) with the
record-backward-compat feature flag.

If you are excited about the project, don't hesitate to join our Discord! We try to be as welcoming as possible to everybody from any background. You can ask your questions and share what you built with the community!
Contributing
Before contributing, please take a moment to review our code of conduct. It's also highly recommended to read the architecture overview, which explains some of our architectural decisions. Refer to our contributing guide for more details.
Burn is currently in active development, and there will be breaking changes. While any resulting issues are likely to be easy to fix, there are no guarantees at this stage.
Burn is distributed under the terms of both the MIT license and the Apache License (Version 2.0). See LICENSE-APACHE and LICENSE-MIT for details. Opening a pull request is assumed to signal agreement with these licensing terms.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for burn
Similar Open Source Tools
burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.
magic
Magic Cloud is a software development automation platform based on AI, Low-Code, and No-Code. It allows dynamic code creation and orchestration using Hyperlambda, generative AI, and meta programming. The platform includes features like CRUD generation, No-Code AI, Hyperlambda programming language, AI agents creation, and various components for software development. Magic is suitable for backend development, AI-related tasks, and creating AI chatbots. It offers high-level programming capabilities, productivity gains, and reduced technical debt.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.

wandb
Weights & Biases (W&B) is a platform that helps users build better machine learning models faster by tracking and visualizing all components of the machine learning pipeline, from datasets to production models. It offers tools for tracking, debugging, evaluating, and monitoring machine learning applications. W&B provides integrations with popular frameworks like PyTorch, TensorFlow/Keras, Hugging Face Transformers, PyTorch Lightning, XGBoost, and Sci-Kit Learn. Users can easily log metrics, visualize performance, and compare experiments using W&B. The platform also supports hosting options in the cloud or on private infrastructure, making it versatile for various deployment needs.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.
AppAgent
AppAgent is a novel LLM-based multimodal agent framework designed to operate smartphone applications. Our framework enables the agent to operate smartphone applications through a simplified action space, mimicking human-like interactions such as tapping and swiping. This novel approach bypasses the need for system back-end access, thereby broadening its applicability across diverse apps. Central to our agent's functionality is its innovative learning method. The agent learns to navigate and use new apps either through autonomous exploration or by observing human demonstrations. This process generates a knowledge base that the agent refers to for executing complex tasks across different applications.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.
burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.