
zippy
Detect AI-generated text [relatively] quickly via compression ratios
Stars: 172
ZipPy is a research repository focused on fast AI detection using compression techniques. It aims to provide a faster approximation for AI detection that is embeddable and scalable. The tool uses LZMA and zlib compression ratios to indirectly measure the perplexity of a text, allowing for the detection of low-perplexity text. By seeding a compression stream with AI-generated text and comparing the compression ratio of the seed data with the sample appended, ZipPy can identify similarities in word choice and structure to classify text as AI or human-generated.
README:
This is a research repo for fast AI detection using compression. While there are a number of existing LLM detection systems, they all use a large model trained on either an LLM or its training data to calculate the probability of each word given the preceding, then calculate a score where the more high-probability tokens are more likely to be AI-originated. Techniques and tools in this repo are looking for faster approximation to be embeddable and more scalable.
ZipPy uses either the LZMA or zlib compression ratios as a way to indirectly measure the perplexity of a text.
Compression ratios have been used in the past to detect anomalies in network data
for intrusion detection, so if perplexity is roughly a measure of anomalous tokens, it may be possible to use compression to detect low-perplexity text.
LZMA and zlib create a dictionary of seen tokens and then use though in place of future tokens. The dictionary size, token length, etc.
are all dynamic (though influenced by the 'preset' of 0-9--with 0 being the fastest but worse compression than 9). The basic idea
is to 'seed' a compression stream with a corpus of AI-generated text (ai-generated.txt) and then measure the compression ratio of
just the seed data with that of the sample appended. Samples that follow more closely in word choice, structure, etc. will achieve a higher
compression ratio due to the prevalence of similar tokens in the dictionary, novel words, structures, etc. will appear anomalous to the seeded
dictionary, resulting in a worse compression ratio.
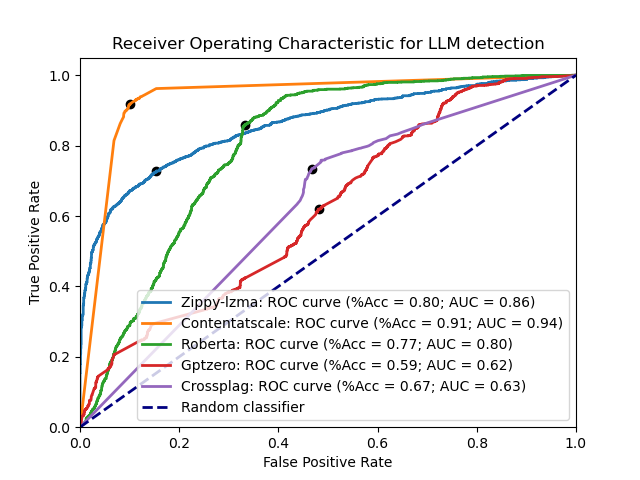
Some of the leading LLM detection tools are:
OpenAI's model detector (v2), Content at Scale, GPTZero, CrossPlag's AI detector, and Roberta.
Here are each of them compared with both the LZMA and zlib detector across the test datasets:
You can install zippy one of two ways:
Via pip:
pip3 install thinkst-zippyOr from source:
python3 setup.py build && python3 setup.py sdist && pip3 install dist/*.tar.gzNow you can import zippy in other scripts.
pkgx install zippy # or run it directly `pkgx zippy -h`ZipPy will read files passed as command-line arguments or will read from stdin to allow for piping of text to it.
Once you've installed zippy it will add a new script (zippy) that you can use directly:
$ zippy -h
usage: zippy [-h] [-p P] [-e {zlib,lzma,brotli,ensemble}] [-s | sample_files ...]
positional arguments:
sample_files Text file(s) containing the sample to classify
options:
-h, --help show this help message and exit
-p P Preset to use with compressor, higher values are slower but provide better compression
-e {zlib,lzma,brotli,ensemble}
Which compression engine to use: lzma, zlib, brotli, or an ensemble of all engines
-s Read from stdin until EOF is reached instead of from a file
$ zippy samples/human-generated/about_me.txt
samples/human-generated/about_me.txt
('Human', 0.06013429262166636)If you want to use the ZipPy technology in your browser, check out the Chrome extension or the Firefox extension that runs ZipPy in-browser to flag potentially AI-generated content.
At its core, the output from ZipPy is purely a statistical comparison of the similarity between the LLM-generate corpus (or corpi) and the provided sample to test. Samples that are closer (i.e., more tokens match the known-LLM corpus) will score with higher confidence as AI-generated; samples that are less compressible to an LLM-trained compression dictionary are flagged as human-generated. There are a few caveats to the output that are worth noting:
-
The comparison is based on the similarity of the text, a different type of sample, e.g., in a different language, or with many fictional names, will be less similar to the English-languge corpus. Either a new LLM-generated corpus is needed, or a different (larger) toolchain that can handle multiple language types is needed. Using ZipPy as-built willl provide poor responses to non-English human language samples, computer language samples, and English samples that are not clear prose (or poetry).
-
The confidence score is a raw delta between the compression ratios for the prelude file (LLM-generated corpus), and the compression ratio with the sample included. Higher values indicate more similarity for AI-classified inputs, and more dissimilarity for those classified as human, but the scores are not a percentage or otherwise a point on a discrete range. A score of 0 means there is no indication either way, it is possible in testing to ignore results that are "too close", in the browser extensions these values are adjusted slightly before being used to calculate the transparency to err on the side of not hiding text.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for zippy
Similar Open Source Tools
zippy
ZipPy is a research repository focused on fast AI detection using compression techniques. It aims to provide a faster approximation for AI detection that is embeddable and scalable. The tool uses LZMA and zlib compression ratios to indirectly measure the perplexity of a text, allowing for the detection of low-perplexity text. By seeding a compression stream with AI-generated text and comparing the compression ratio of the seed data with the sample appended, ZipPy can identify similarities in word choice and structure to classify text as AI or human-generated.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.
PINNACLE
PINNACLE is a flexible geometric deep learning approach that trains on contextualized protein interaction networks to generate context-aware protein representations. It provides protein representations split across various cell-type contexts from different tissues and organs. The tool can be fine-tuned to study the genomic effects of drugs and nominate promising protein targets and cell-type contexts for further investigation. PINNACLE exemplifies the paradigm of incorporating context-specific effects for studying biological systems, especially the impact of disease and therapeutics.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.
AI4U
AI4U is a tool that provides a framework for modeling virtual reality and game environments. It offers an alternative approach to modeling Non-Player Characters (NPCs) in Godot Game Engine. AI4U defines an agent living in an environment and interacting with it through sensors and actuators. Sensors provide data to the agent's brain, while actuators send actions from the agent to the environment. The brain processes the sensor data and makes decisions (selects an action by time). AI4U can also be used in other situations, such as modeling environments for artificial intelligence experiments.

LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.
Electronic-Component-Sorter
The Electronic Component Classifier is a project that uses machine learning and artificial intelligence to automate the identification and classification of electrical and electronic components. It features component classification into seven classes, user-friendly design, and integration with Flask for a user-friendly interface. The project aims to reduce human error in component identification, make the process safer and more reliable, and potentially help visually impaired individuals in identifying electronic components.
For similar tasks

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
For similar jobs

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.
PurpleLlama
Purple Llama is an umbrella project that aims to provide tools and evaluations to support responsible development and usage of generative AI models. It encompasses components for cybersecurity and input/output safeguards, with plans to expand in the future. The project emphasizes a collaborative approach, borrowing the concept of purple teaming from cybersecurity, to address potential risks and challenges posed by generative AI. Components within Purple Llama are licensed permissively to foster community collaboration and standardize the development of trust and safety tools for generative AI.
vpnfast.github.io
VPNFast is a lightweight and fast VPN service provider that offers secure and private internet access. With VPNFast, users can protect their online privacy, bypass geo-restrictions, and secure their internet connection from hackers and snoopers. The service provides high-speed servers in multiple locations worldwide, ensuring a reliable and seamless VPN experience for users. VPNFast is easy to use, with a user-friendly interface and simple setup process. Whether you're browsing the web, streaming content, or accessing sensitive information, VPNFast helps you stay safe and anonymous online.
taranis-ai
Taranis AI is an advanced Open-Source Intelligence (OSINT) tool that leverages Artificial Intelligence to revolutionize information gathering and situational analysis. It navigates through diverse data sources like websites to collect unstructured news articles, utilizing Natural Language Processing and Artificial Intelligence to enhance content quality. Analysts then refine these AI-augmented articles into structured reports that serve as the foundation for deliverables such as PDF files, which are ultimately published.
NightshadeAntidote
Nightshade Antidote is an image forensics tool used to analyze digital images for signs of manipulation or forgery. It implements several common techniques used in image forensics including metadata analysis, copy-move forgery detection, frequency domain analysis, and JPEG compression artifacts analysis. The tool takes an input image, performs analysis using the above techniques, and outputs a report summarizing the findings.
h4cker
This repository is a comprehensive collection of cybersecurity-related references, scripts, tools, code, and other resources. It is carefully curated and maintained by Omar Santos. The repository serves as a supplemental material provider to several books, video courses, and live training created by Omar Santos. It encompasses over 10,000 references that are instrumental for both offensive and defensive security professionals in honing their skills.

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
admyral
Admyral is an open-source Cybersecurity Automation & Investigation Assistant that provides a unified console for investigations and incident handling, workflow automation creation, automatic alert investigation, and next step suggestions for analysts. It aims to tackle alert fatigue and automate security workflows effectively by offering features like workflow actions, AI actions, case management, alert handling, and more. Admyral combines security automation and case management to streamline incident response processes and improve overall security posture. The tool is open-source, transparent, and community-driven, allowing users to self-host, contribute, and collaborate on integrations and features.