Best AI tools for< Classify Text >
10 - AI tool Sites
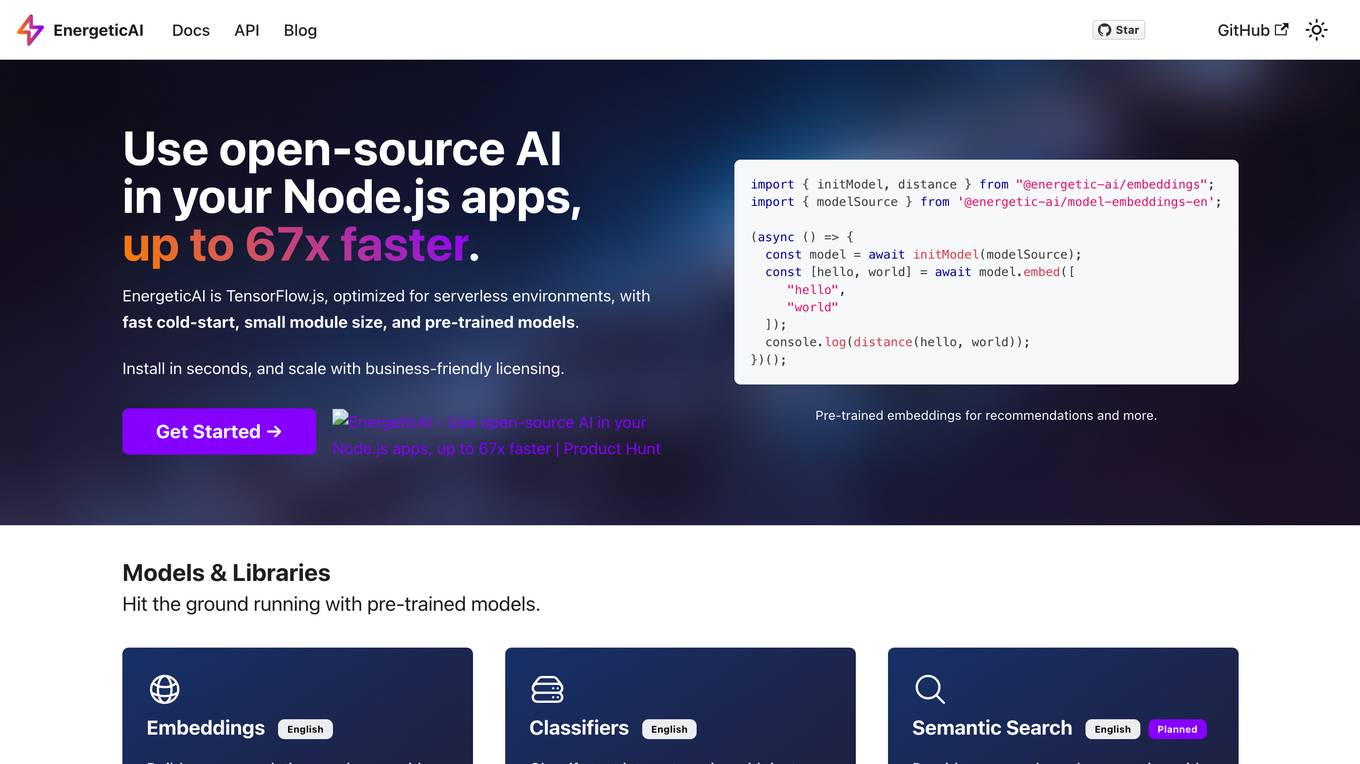
EnergeticAI
EnergeticAI is an open-source AI library that can be used in Node.js applications. It is optimized for serverless environments and provides fast cold-start, small module size, and pre-trained models. EnergeticAI can be used for a variety of tasks, including building recommendations, classifying text, and performing semantic search.
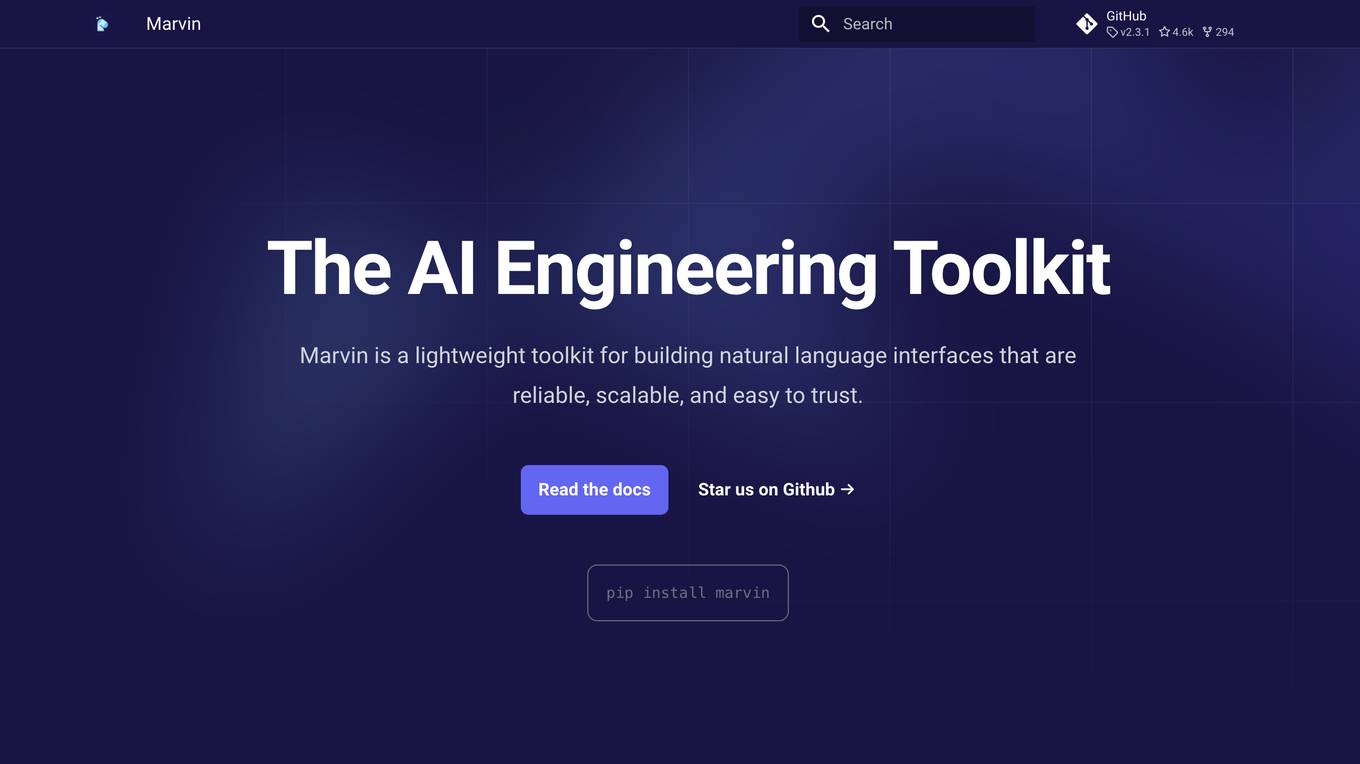
Marvin
Marvin is a lightweight toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. It provides a variety of AI functions for text, images, audio, and video, as well as interactive tools and utilities. Marvin is designed to be easy to use and integrate, and it can be used to build a wide range of applications, from simple chatbots to complex AI-powered systems.
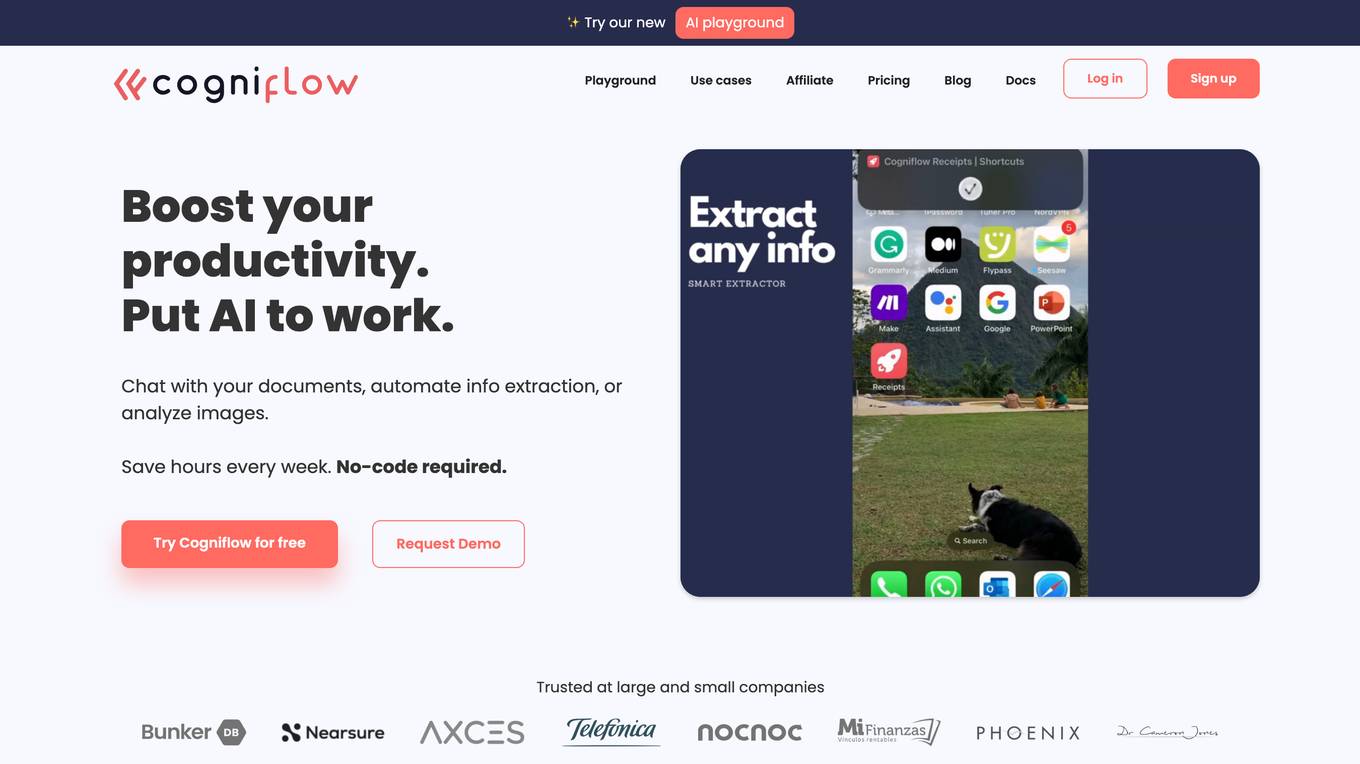
Cogniflow
Cogniflow is a no-code AI platform that allows users to build and deploy custom AI models without any coding experience. The platform provides a variety of pre-built AI models that can be used for a variety of tasks, including customer service, HR, operations, and more. Cogniflow also offers a variety of integrations with other applications, making it easy to connect your AI models to your existing workflow.
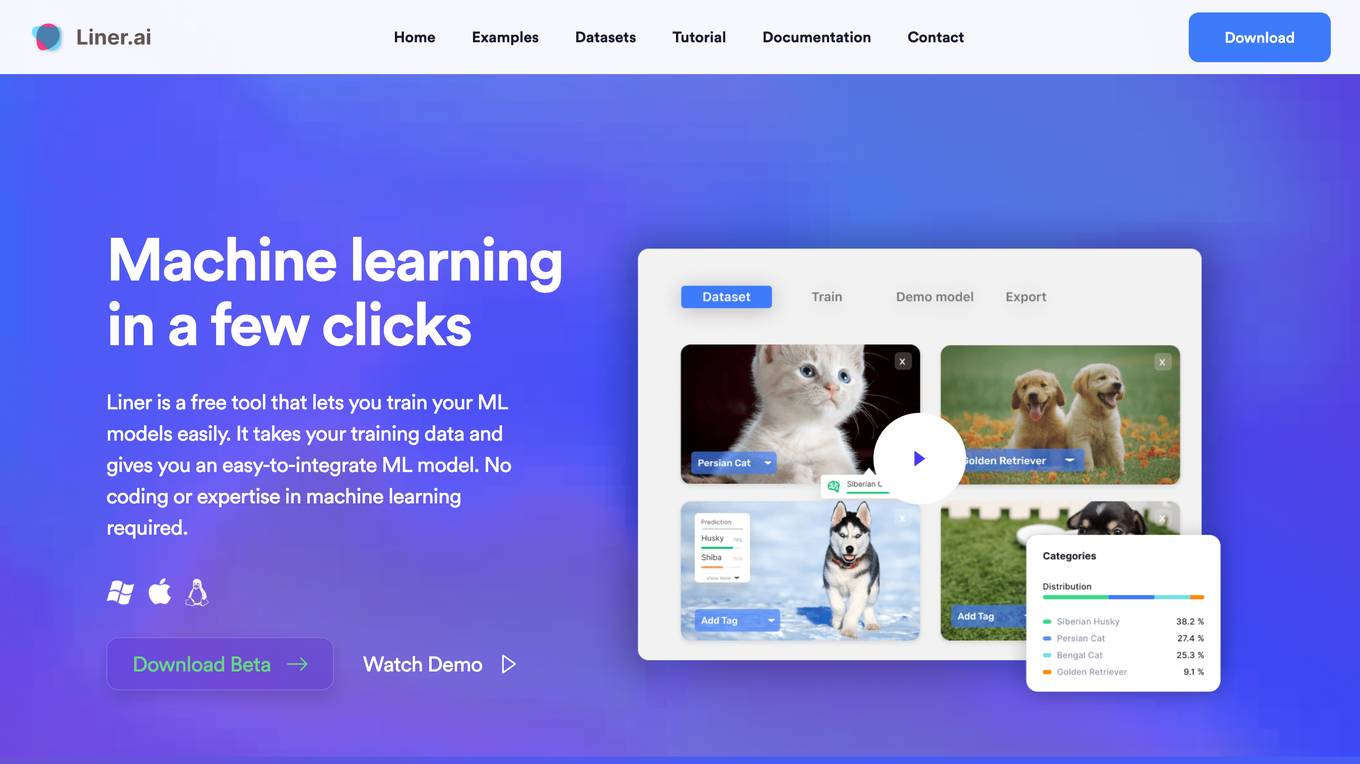
Liner.ai
Liner is a free and easy-to-use tool that allows users to train machine learning models without writing any code. It provides a user-friendly interface that guides users through the process of importing data, selecting a model, and training the model. Liner also offers a variety of pre-trained models that can be used for common tasks such as image classification, text classification, and object detection. With Liner, users can quickly and easily create and deploy machine learning applications without the need for specialized knowledge or expertise.
Ubdroid AI Answer Engine
Ubdroid AI Answer Engine is an AI-powered tool that utilizes various open-source LLMs to provide answers to user queries. It works by processing user queries and fetching relevant information from these LLMs. The accuracy of the answers depends on the quality and relevance of the data provided by the LLMs. The free version of the tool has a request limit of 10 requests per minute. If a model is not working, users can select another model.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
Cohere
Cohere is a leading provider of artificial intelligence (AI) tools and services. Our mission is to make AI accessible and useful to everyone, from individual developers to large enterprises. We offer a range of AI tools and services, including natural language processing, computer vision, and machine learning. Our tools are used by businesses of all sizes to improve customer service, automate tasks, and gain insights from data.
Cartesia Sonic Team Blog Research Playground
Cartesia Sonic Team Blog Research Playground is an AI application that offers real-time multimodal intelligence for every device. The application aims to build the next generation of AI by providing ubiquitous, interactive intelligence that can run on any device. It features the fastest, ultra-realistic generative voice API and is backed by research on simple linear attention language models and state-space models. The founding team, who met at the Stanford AI Lab, has invented State Space Models (SSMs) and scaled it up to achieve state-of-the-art results in various modalities such as text, audio, video, images, and time-series data.

Nesa Playground
Nesa is a global blockchain network that brings AI on-chain, allowing applications and protocols to seamlessly integrate with AI. It offers secure execution for critical inference, a private AI network, and a global AI model repository. Nesa supports various AI models for tasks like text classification, content summarization, image generation, language translation, and more. The platform is backed by a team with extensive experience in AI and deep learning, with numerous awards and recognitions in the field.
38 - Open Source AI Tools

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together
hugging-llm
HuggingLLM is a project that aims to introduce ChatGPT to a wider audience, particularly those interested in using the technology to create new products or applications. The project focuses on providing practical guidance on how to use ChatGPT-related APIs to create new features and applications. It also includes detailed background information and system design introductions for relevant tasks, as well as example code and implementation processes. The project is designed for individuals with some programming experience who are interested in using ChatGPT for practical applications, and it encourages users to experiment and create their own applications and demos.

languagemodels
Language Models is a Python package that provides building blocks to explore large language models with as little as 512MB of RAM. It simplifies the usage of large language models from Python, ensuring all inference is performed locally to keep data private. The package includes features such as text completions, chat capabilities, code completions, external text retrieval, semantic search, and more. It outperforms Hugging Face transformers for CPU inference and offers sensible default models with varying parameters based on memory constraints. The package is suitable for learners and educators exploring the intersection of large language models with modern software development.

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.
zippy
ZipPy is a research repository focused on fast AI detection using compression techniques. It aims to provide a faster approximation for AI detection that is embeddable and scalable. The tool uses LZMA and zlib compression ratios to indirectly measure the perplexity of a text, allowing for the detection of low-perplexity text. By seeding a compression stream with AI-generated text and comparing the compression ratio of the seed data with the sample appended, ZipPy can identify similarities in word choice and structure to classify text as AI or human-generated.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
OpenAI-DotNet
OpenAI-DotNet is a simple C# .NET client library for OpenAI to use through their RESTful API. It is independently developed and not an official library affiliated with OpenAI. Users need an OpenAI API account to utilize this library. The library targets .NET 6.0 and above, working across various platforms like console apps, winforms, wpf, asp.net, etc., and on Windows, Linux, and Mac. It provides functionalities for authentication, interacting with models, assistants, threads, chat, audio, images, files, fine-tuning, embeddings, and moderations.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
semantic-cache
Semantic Cache is a tool for caching natural text based on semantic similarity. It allows for classifying text into categories, caching AI responses, and reducing API latency by responding to similar queries with cached values. The tool stores cache entries by meaning, handles synonyms, supports multiple languages, understands complex queries, and offers easy integration with Node.js applications. Users can set a custom proximity threshold for filtering results. The tool is ideal for tasks involving querying or retrieving information based on meaning, such as natural language classification or caching AI responses.
awesome-open-data-annotation
At ZenML, we believe in the importance of annotation and labeling workflows in the machine learning lifecycle. This repository showcases a curated list of open-source data annotation and labeling tools that are actively maintained and fit for purpose. The tools cover various domains such as multi-modal, text, images, audio, video, time series, and other data types. Users can contribute to the list and discover tools for tasks like named entity recognition, data annotation for machine learning, image and video annotation, text classification, sequence labeling, object detection, and more. The repository aims to help users enhance their data-centric workflows by leveraging these tools.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.
generative-ai-workbook
Generative AI Workbook is a central repository for generative AI-related work, including projects, personal projects, and tools. It also features a blog section with bite-sized posts on various generative AI concepts. The repository covers use cases of Large Language Models (LLMs) such as search, classification, clustering, data/text/code generation, summarization, rewriting, extractions, proofreading, and querying data.
jvm-openai
jvm-openai is a minimalistic unofficial OpenAI API client for the JVM, written in Java. It serves as a Java client for OpenAI API with a focus on simplicity and minimal dependencies. The tool provides support for various OpenAI APIs and endpoints, including Audio, Chat, Embeddings, Fine-tuning, Batch, Files, Uploads, Images, Models, Moderations, Assistants, Threads, Messages, Runs, Run Steps, Vector Stores, Vector Store Files, Vector Store File Batches, Invites, Users, Projects, Project Users, Project Service Accounts, Project API Keys, and Audit Logs. Users can easily integrate this tool into their Java projects to interact with OpenAI services efficiently.

ai_projects
This repository contains a collection of AI projects covering various areas of machine learning. Each project is accompanied by detailed articles on the associated blog sciblog. Projects range from introductory topics like Convolutional Neural Networks and Transfer Learning to advanced topics like Fraud Detection and Recommendation Systems. The repository also includes tutorials on data generation, distributed training, natural language processing, and time series forecasting. Additionally, it features visualization projects such as football match visualization using Datashader.

Hands-On-Large-Language-Models
Hands-On Large Language Models is a repository containing code examples from the book 'The Illustrated LLM Book' by Jay Alammar and Maarten Grootendorst. The repository provides practical tools and concepts for using Large Language Models with over 250 custom-made figures. It covers topics such as language model introduction, tokens and embeddings, transformer LLMs, text classification, text clustering, prompt engineering, text generation techniques, semantic search, multimodal LLMs, text embedding models, fine-tuning representation models, and fine-tuning generation models. The examples are designed to be run on Google Colab with T4 GPU support, but can be adapted to other cloud platforms as well.
intelligence-layer-sdk
The Aleph Alpha Intelligence Layer️ offers a comprehensive suite of development tools for crafting solutions that harness the capabilities of large language models (LLMs). With a unified framework for LLM-based workflows, it facilitates seamless AI product development, from prototyping and prompt experimentation to result evaluation and deployment. The Intelligence Layer SDK provides features such as Composability, Evaluability, and Traceability, along with examples to get started. It supports local installation using poetry, integration with Docker, and access to LLM endpoints for tutorials and tasks like Summarization, Question Answering, Classification, Evaluation, and Parameter Optimization. The tool also offers pre-configured tasks for tasks like Classify, QA, Search, and Summarize, serving as a foundation for custom development.
intro-llm.github.io
Large Language Models (LLM) are language models built by deep neural networks containing hundreds of billions of weights, trained on a large amount of unlabeled text using self-supervised learning methods. Since 2018, companies and research institutions including Google, OpenAI, Meta, Baidu, and Huawei have released various models such as BERT, GPT, etc., which have performed well in almost all natural language processing tasks. Starting in 2021, large models have shown explosive growth, especially after the release of ChatGPT in November 2022, attracting worldwide attention. Users can interact with systems using natural language to achieve various tasks from understanding to generation, including question answering, classification, summarization, translation, and chat. Large language models demonstrate powerful knowledge of the world and understanding of language. This repository introduces the basic theory of large language models including language models, distributed model training, and reinforcement learning, and uses the Deepspeed-Chat framework as an example to introduce the implementation of large language models and ChatGPT-like systems.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.
llmgateway
The llmgateway repository is a tool that provides a gateway for interacting with various LLM (Large Language Model) models. It allows users to easily access and utilize pre-trained language models for tasks such as text generation, sentiment analysis, and language translation. The tool simplifies the process of integrating LLMs into applications and workflows, enabling developers to leverage the power of state-of-the-art language models for various natural language processing tasks.
langgraph4j
Langgraph4j is a Java library for language processing tasks such as text classification, sentiment analysis, and named entity recognition. It provides a set of tools and algorithms for analyzing text data and extracting useful information. The library is designed to be efficient and easy to use, making it suitable for both research and production applications.
sgr-deep-research
This repository contains a deep learning research project focused on natural language processing tasks. It includes implementations of various state-of-the-art models and algorithms for text classification, sentiment analysis, named entity recognition, and more. The project aims to provide a comprehensive resource for researchers and developers interested in exploring deep learning techniques for NLP applications.
DL-Hub
DL-Hub is a deep learning repository containing various study materials and code projects in the fields of machine learning, deep learning, computer vision, natural language processing, and web crawling. It includes paper analysis, deep learning projects, graph neural network replications, machine learning algorithms, transformer models, and optimization implementations. The repository aims to provide valuable resources for learning and research in the deep learning and machine learning domains.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.

openai
An open-source client package that allows developers to easily integrate the power of OpenAI's state-of-the-art AI models into their Dart/Flutter applications. The library provides simple and intuitive methods for making requests to OpenAI's various APIs, including the GPT-3 language model, DALL-E image generation, and more. It is designed to be lightweight and easy to use, enabling developers to focus on building their applications without worrying about the complexities of dealing with HTTP requests. Note that this is an unofficial library as OpenAI does not have an official Dart library.

underthesea
Underthesea is an open-source Vietnamese Natural Language Processing toolkit that provides easy API access to pretrained NLP models for tasks such as word segmentation, part-of-speech tagging, named entity recognition, text classification, and dependency parsing. The toolkit also includes features like Conversational AI Agent for chatting with an AI assistant specialized in Vietnamese NLP. It supports various Python versions and offers tutorials for different NLP tasks like sentence segmentation, text normalization, tagging, classification, sentiment analysis, named entity recognition, language detection, translation, and text-to-speech conversion. Additionally, it provides resources for Vietnamese NLP datasets and upcoming features include Automatic Speech Recognition.
20 - OpenAI Gpts
Dr. Classify
Just upload a numerical dataset for classification task, will apply data analysis and machine learning steps to make a best model possible.
Prompt Injection Detector
GPT used to classify prompts as valid inputs or injection attempts. Json output.

NACE Classifier
NACE (Nomenclature of Economic Activities) is the European statistical classification of economic activities. This is not an official product. Official information here: https://nacev2.com/en

TradeComply
Import Export Compliance | Tariff Classification | Shipping Queries | Logistics & Supply Chain Solutions
LiDAR GPT - LAStools Comprehensive Expert
Expert in LAStools with in-depth command line knowledge.
GICS Classifier
GICS is a classification standard developed by MSCI and S&P Dow Jones Indices. This GPT is not a MSCI and S&P product. Official website : https://www.msci.com/our-solutions/indexes/gics
UNSPSC Explorer
Expert in UNSPSC Codes (United Nations Standard Products and Services Code®).


DGL coding assistant
Assists with DGL coding, focusing on edge classification and link prediction.
Lexi - Article Classifier
Classifies articles into knowledge domains. source code: https://homun.posetmage.com/Agents/
Cloud Scholar
Super astronomer identifying clouds in English and Chinese, sharing facts in Chinese.

Not Hotdog
What would you say if I told you there is an app on the market that can tell you if you have a hot dog or not a hot dog.
MDR Navigator
Medical Device Expert on MDR 2017/745, IVDR 2017/746 and related MDCG guidance
Rock Identifier GPT
I identify various rocks from images and advise consulting a geologist for certainty.