
generative-ai-workbook
Central repository for all LLM development
Stars: 214
Generative AI Workbook is a central repository for generative AI-related work, including projects, personal projects, and tools. It also features a blog section with bite-sized posts on various generative AI concepts. The repository covers use cases of Large Language Models (LLMs) such as search, classification, clustering, data/text/code generation, summarization, rewriting, extractions, proofreading, and querying data.
README:
This is a central location for all generative AI related work from courses, personal projects, small running examples etc.
-
learning: Folders for learning concepts of different tools and frameworks such as LangChain, Autogen etc. -
personal_projects: location for small once of project to test out features -
tools: Location for outputs of ready-made AI tools and models.
- The Discussion section contains bitesize posts from my learnings about different concepts in the generative AI space.

- Search
- Classification
- Topic Modelling
- Clustering
- Data, Text and Code generation
- Summarization
- Rewriting
- Extractions
- Proof reading
- Querying Data
- Executing code
- Sentiment Analysis
- Planning and Complex Reasoning
- Image classification and generation (If multimodal)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for generative-ai-workbook
Similar Open Source Tools
generative-ai-workbook
Generative AI Workbook is a central repository for generative AI-related work, including projects, personal projects, and tools. It also features a blog section with bite-sized posts on various generative AI concepts. The repository covers use cases of Large Language Models (LLMs) such as search, classification, clustering, data/text/code generation, summarization, rewriting, extractions, proofreading, and querying data.
vectordb-recipes
This repository contains examples, applications, starter code, & tutorials to help you kickstart your GenAI projects. * These are built using LanceDB, a free, open-source, serverless vectorDB that **requires no setup**. * It **integrates into python data ecosystem** so you can simply start using these in your existing data pipelines in pandas, arrow, pydantic etc. * LanceDB has **native Typescript SDK** using which you can **run vector search** in serverless functions! This repository is divided into 3 sections: - Examples - Get right into the code with minimal introduction, aimed at getting you from an idea to PoC within minutes! - Applications - Ready to use Python and web apps using applied LLMs, VectorDB and GenAI tools - Tutorials - A curated list of tutorials, blogs, Colabs and courses to get you started with GenAI in greater depth.
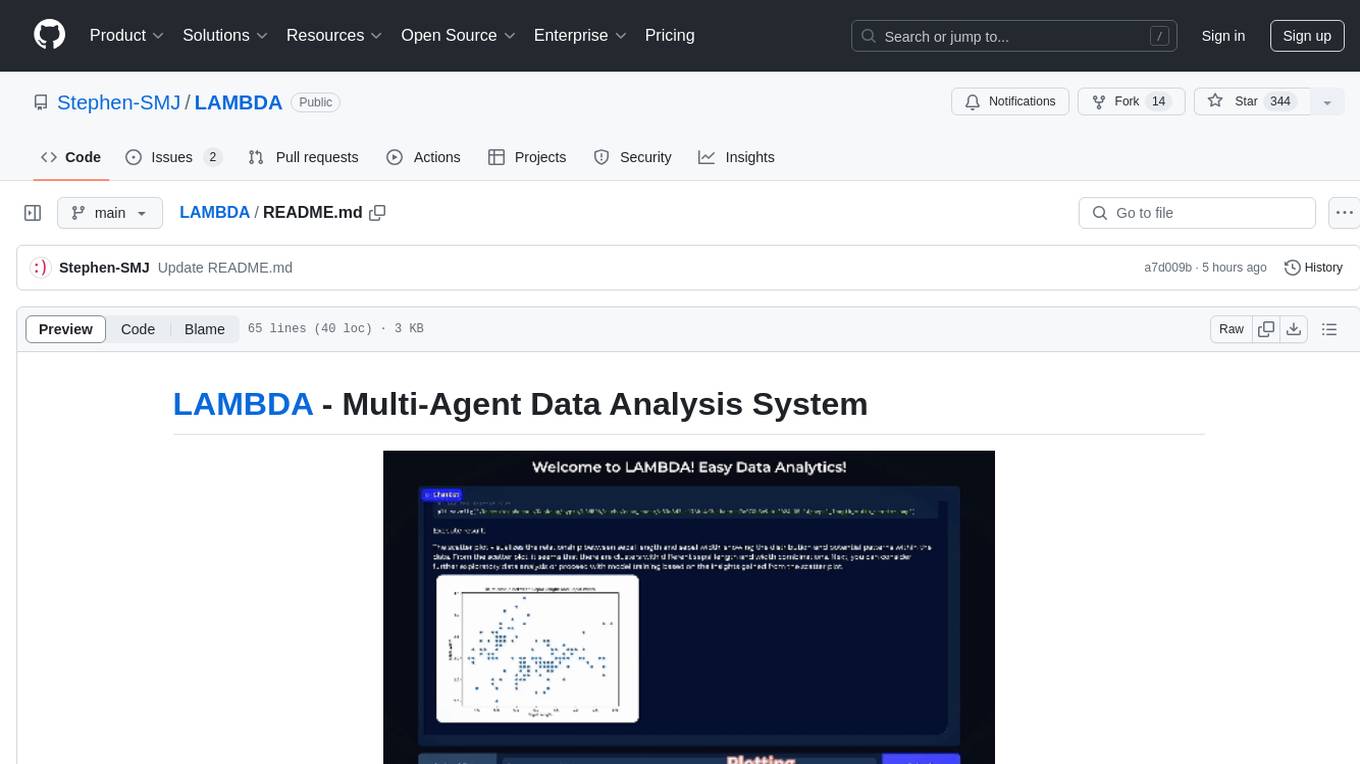
LAMBDA
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.
shandu
Shandu is an advanced AI research system that automates comprehensive research processes using language models, web scraping, and iterative exploration to generate well-structured reports with citations. It features intelligent state-based workflow, deep exploration, multi-source information synthesis, enhanced web scraping, smart source evaluation, content analysis pipeline, comprehensive report generation, parallel processing, adaptive search strategy, and full citation management.
trustworthyAI
Trustworthy AI is a repository from Huawei Noah's Ark Lab containing works related to trustworthy AI. It includes a causal structure learning toolchain, information on causality-related competitions, real-world datasets, and research works on causality such as CausalVAE, GAE, and causal discovery with reinforcement learning.
LangChain-Udemy-Course
LangChain-Udemy-Course is a comprehensive course directory focusing on LangChain, a framework for generative AI applications. The course covers various aspects such as OpenAI API usage, prompt templates, Chains exploration, callback functions, memory techniques, RAG implementation, autonomous agents, hybrid search, LangSmith utilization, microservice architecture, and LangChain Expression Language. Learners gain theoretical knowledge and practical insights to understand and apply LangChain effectively in generative AI scenarios.

KAG
KAG is a logical reasoning and Q&A framework based on the OpenSPG engine and large language models. It is used to build logical reasoning and Q&A solutions for vertical domain knowledge bases. KAG supports logical reasoning, multi-hop fact Q&A, and integrates knowledge and chunk mutual indexing structure, conceptual semantic reasoning, schema-constrained knowledge construction, and logical form-guided hybrid reasoning and retrieval. The framework includes kg-builder for knowledge representation and kg-solver for logical symbol-guided hybrid solving and reasoning engine. KAG aims to enhance LLM service framework in professional domains by integrating logical and factual characteristics of KGs.
learning-ai
This repository is a collection of notes and code examples related to AI, covering topics such as Tokenization, Architectures, GGML, Llama.cpp, Position Embeddings, GPUs, Vector Databases, and Vision. It also includes in-progress work on Model Context Protocol (MCP) and Voice Activity Detection (VAD) for whisper.cpp. The repository offers exploration code for various AI-related concepts and tools like GGML, Llama.cpp, GPU technologies (CUDA, Kompute, Metal, OpenCL, ROCm, Vulkan), Word embeddings, Huggingface API, and Qdrant Vector Database in both Rust and Python.

ai-data-analysis-MulitAgent
AI-Driven Research Assistant is an advanced AI-powered system utilizing specialized agents for data analysis, visualization, and report generation. It integrates LangChain, OpenAI's GPT models, and LangGraph for complex research processes. Key features include hypothesis generation, data processing, web search, code generation, and report writing. The system's unique Note Taker agent maintains project state, reducing overhead and improving context retention. System requirements include Python 3.10+ and Jupyter Notebook environment. Installation involves cloning the repository, setting up a Conda virtual environment, installing dependencies, and configuring environment variables. Usage instructions include setting data, running Jupyter Notebook, customizing research tasks, and viewing results. Main components include agents for hypothesis generation, process supervision, visualization, code writing, search, report writing, quality review, and note-taking. Workflow involves hypothesis generation, processing, quality review, and revision. Customization is possible by modifying agent creation and workflow definition. Current issues include OpenAI errors, NoteTaker efficiency, runtime optimization, and refiner improvement. Contributions via pull requests are welcome under the MIT License.
GOLEM
GOLEM is an open-source AI framework focused on optimization and learning of structured graph-based models using meta-heuristic methods. It emphasizes the potential of meta-heuristics in complex problem spaces where gradient-based methods are not suitable, and the importance of structured models in various problem domains. The framework offers features like structured model optimization, metaheuristic methods, multi-objective optimization, constrained optimization, extensibility, interpretability, and reproducibility. It can be applied to optimization problems represented as directed graphs with defined fitness functions. GOLEM has applications in areas like AutoML, Bayesian network structure search, differential equation discovery, geometric design, and neural architecture search. The project structure includes packages for core functionalities, adapters, graph representation, optimizers, genetic algorithms, utilities, serialization, visualization, examples, and testing. Contributions are welcome, and the project is supported by ITMO University's Research Center Strong Artificial Intelligence in Industry.
llm_benchmark
The 'llm_benchmark' repository is a personal evaluation project that tracks and tests various large models in areas such as logic, mathematics, programming, and human intuition. The evaluation consists of a private question bank with around 30 questions and 240 test cases, updated monthly. The scoring method involves assigning points based on correct deductions and meeting specific requirements, with scores normalized to a scale of 10. The repository aims to observe the long-term evolution trends of different large models from a subjective perspective, providing insights and a testing approach for individuals to assess large models.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.

embedJs
EmbedJs is a NodeJS framework that simplifies RAG application development by efficiently processing unstructured data. It segments data, creates relevant embeddings, and stores them in a vector database for quick retrieval.
agentsociety
AgentSociety is an advanced framework designed for building agents in urban simulation environments. It integrates LLMs' planning, memory, and reasoning capabilities to generate realistic behaviors. The framework supports dataset-based, text-based, and rule-based environments with interactive visualization. It includes tools for interviews, surveys, interventions, and metric recording tailored for social experimentation.
awesome-ml-gen-ai-elixir
A curated list of Machine Learning (ML) and Generative AI (GenAI) packages and resources for the Elixir programming language. It includes core tools for data exploration, traditional machine learning algorithms, deep learning models, computer vision libraries, generative AI tools, livebooks for interactive notebooks, and various resources such as books, videos, and articles. The repository aims to provide a comprehensive overview for experienced Elixir developers and ML/AI practitioners exploring different ecosystems.
For similar tasks

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.