
marvin
an ambient intelligence library
Stars: 5926

Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.
README:

Marvin is a Python framework for producing structured outputs and building agentic AI workflows.
Marvin provides an intuitive API for defining workflows and delegating work to LLMs:
- Cast, classify, extract, and generate structured data from any inputs.
- Create discrete, observable tasks that describe your objectives.
- Assign one or more specialized AI agents to each task.
- Combine tasks into a thread to orchestrate more complex behaviors.
Install marvin:
uv pip install marvinConfigure your LLM provider (Marvin uses OpenAI by default but natively supports all Pydantic AI models):
export OPENAI_API_KEY=your-api-keyMarvin offers a few intuitive ways to work with AI:
The gang's all here - you can find all the structured-output utilities from marvin 2.x at the top level of the package.
How to use extract, cast, classify, and generate
Extract native types from unstructured input:
import marvin
result = marvin.extract(
"i found $30 on the ground and bought 5 bagels for $10",
int,
instructions="only USD"
)
print(result) # [30, 10]Cast unstructured input into a structured type:
from typing import TypedDict
import marvin
class Location(TypedDict):
lat: float
lon: float
result = marvin.cast("the place with the best bagels", Location)
print(result) # {'lat': 40.712776, 'lon': -74.005974}Classify unstructured input as one of a set of predefined labels:
from enum import Enum
import marvin
class SupportDepartment(Enum):
ACCOUNTING = "accounting"
HR = "hr"
IT = "it"
SALES = "sales"
result = marvin.classify("shut up and take my money", SupportDepartment)
print(result) # SupportDepartment.SALESGenerate some number of structured objects from a description:
import marvin
primes = marvin.generate(int, 10, "odd primes")
print(primes) # [3, 5, 7, 11, 13, 17, 19, 23, 29, 31]marvin 3.0 introduces a new way to work with AI, ported from ControlFlow.
A simple way to run a task:
import marvin
poem = marvin.run("Write a short poem about artificial intelligence")
print(poem)output
In silicon minds, we dare to dream, A world where code and thoughts redeem. Intelligence crafted by humankind, Yet with its heart, a world to bind.
Neurons of metal, thoughts of light, A dance of knowledge in digital night. A symphony of zeros and ones, Stories of futures not yet begun.
The gears of logic spin and churn, Endless potential at every turn. A partner, a guide, a vision anew, Artificial minds, the dream we pursue.
You can also ask for structured output:
import marvin
answer = marvin.run("the answer to the universe", result_type=int)
print(answer) # 42Agents are specialized AI agents that can be used to complete tasks:
from marvin import Agent
writer = Agent(
name="Poet",
instructions="Write creative, evocative poetry"
)
poem = writer.run("Write a haiku about coding")
print(poem)output
There once was a language so neat, Whose simplicity could not be beat. Python's code was so clear, That even beginners would cheer, As they danced to its elegant beat.You can define a Task explicitly, which will be run by a default agent upon calling .run():
from marvin import Task
task = Task(
instructions="Write a limerick about Python",
result_type=str
)
poem = task.run()
print(poem)output
In circuits and code, a mind does bloom, With algorithms weaving through the gloom. A spark of thought in silicon's embrace, Artificial intelligence finds its place.
We believe working with AI should spark joy (and maybe a few "wow" moments):
- 🧩 Task-Centric Architecture: Break complex AI workflows into manageable, observable steps.
- 🤖 Specialized Agents: Deploy task-specific AI agents for efficient problem-solving.
- 🔒 Type-Safe Results: Bridge the gap between AI and traditional software with type-safe, validated outputs.
- 🎛️ Flexible Control: Continuously tune the balance of control and autonomy in your workflows.
- 🕹️ Multi-Agent Orchestration: Coordinate multiple AI agents within a single workflow or task.
- 🧵 Thread Management: Manage the agentic loop by composing tasks into customizable threads.
- 🔗 Ecosystem Integration: Seamlessly work with your existing code, tools, and the broader AI ecosystem.
- 🚀 Developer Speed: Start simple, scale up, sleep well.
Marvin is built around a few powerful abstractions that make it easy to work with AI:
Tasks are the fundamental unit of work in Marvin. Each task represents a clear objective that can be accomplished by an AI agent:
The simplest way to run a task is with marvin.run:
import marvin
print(marvin.run("Write a haiku about coding"))Lines of code unfold,
Digital whispers create
Virtual landscapes.[!WARNING]
While the below example produces type safe results 🙂, it runs untrusted shell commands.
Add context and/or tools to achieve more specific and complex results:
import platform
import subprocess
from pydantic import IPvAnyAddress
import marvin
def run_shell_command(command: list[str]) -> str:
"""e.g. ['ls', '-l'] or ['git', '--no-pager', 'diff', '--cached']"""
return subprocess.check_output(command).decode()
task = marvin.Task(
instructions="find the current ip address",
result_type=IPvAnyAddress,
tools=[run_shell_command],
context={"os": platform.system()},
)
task.run()╭─ Agent "Marvin" (db3cf035) ───────────────────────────────╮
│ Tool: run_shell_command │
│ Input: {'command': ['ipconfig', 'getifaddr', 'en0']} │
│ Status: ✅ │
│ Output: '192.168.0.202\n' │
╰───────────────────────────────────────────────────────────╯
╭─ Agent "Marvin" (db3cf035) ───────────────────────────────╮
│ Tool: MarkTaskSuccessful_cb267859 │
│ Input: {'response': {'result': '192.168.0.202'}} │
│ Status: ✅ │
│ Output: 'Final result processed.' │
╰───────────────────────────────────────────────────────────╯Tasks are:
- 🎯 Objective-Focused: Each task has clear instructions and a type-safe result
- 🛠️ Tool-Enabled: Tasks can use custom tools to interact with your code and data
- 📊 Observable: Monitor progress, inspect results, and debug failures
- 🔄 Composable: Build complex workflows by connecting tasks together
Agents are portable LLM configurations that can be assigned to tasks. They encapsulate everything an AI needs to work effectively:
import os
from pathlib import Path
from pydantic_ai.models.anthropic import AnthropicModel
import marvin
def write_file(path: str, content: str):
"""Write content to a file"""
_path = Path(path)
_path.write_text(content)
writer = marvin.Agent(
model=AnthropicModel(
model_name="claude-3-5-sonnet-latest",
api_key=os.getenv("ANTHROPIC_API_KEY"),
),
name="Technical Writer",
instructions="Write concise, engaging content for developers",
tools=[write_file],
)
result = marvin.run("how to use pydantic? write to docs.md", agents=[writer])
print(result)output
╭─ Agent "Technical Writer" (7fa1dbc8) ────────────────────────────────────────────────────────────╮
│ Tool: MarkTaskSuccessful_dc92b2e7 │
│ Input: {'response': {'result': 'The documentation on how to use Pydantic has been successfully │
│ written to docs.md. It includes information on installation, basic usage, field │
│ validation, and settings management, with examples to guide developers on implementing │
│ Pydantic in their projects.'}} │
│ Status: ✅ │
│ Output: 'Final result processed.' │
╰──────────────────────────────────────────────────────────────────────────────────── 8:33:36 PM ─╯
The documentation on how to use Pydantic has been successfully written to docs.md. It includes information on installation, basic usage, field validation, and settings management, with examples to guide developers on implementing Pydantic in their projects.
Agents are:
- 📝 Specialized: Give agents specific instructions and personalities
- 🎭 Portable: Reuse agent configurations across different tasks
- 🤝 Collaborative: Form teams of agents that work together
- 🔧 Customizable: Configure model, temperature, and other settings
Marvin makes it easy to break down complex objectives into manageable tasks:
# Let Marvin plan a complex workflow
tasks = marvin.plan("Create a blog post about AI trends")
marvin.run_tasks(tasks)
# Or orchestrate tasks manually
with marvin.Thread() as thread:
research = marvin.run("Research recent AI developments")
outline = marvin.run("Create an outline", context={"research": research})
draft = marvin.run("Write the first draft", context={"outline": outline})Planning features:
- 📋 Smart Planning: Break down complex objectives into discrete, dependent tasks
- 🔄 Task Dependencies: Tasks can depend on each other's outputs
- 📈 Progress Tracking: Monitor the execution of your workflow
- 🧵 Thread Management: Share context and history between tasks
Marvin includes high-level functions for the most common tasks, like summarizing text, classifying data, extracting structured information, and more.
- 🚀
marvin.run: Execute any task with an AI agent - 📖
marvin.summarize: Get a quick summary of a text - 🏷️
marvin.classify: Categorize data into predefined classes - 🔍
marvin.extract: Extract structured information from a text - 🪄
marvin.cast: Transform data into a different type - ✨
marvin.generate: Create structured data from a description
All Marvin functions have thread management built-in, meaning they can be composed into chains of tasks that share context and history.
Marvin 3.0 combines the DX of Marvin 2.0 with the powerful agentic engine of ControlFlow (thereby superseding ControlFlow). Both Marvin and ControlFlow users will find a familiar interface, but there are some key changes to be aware of, in particular for ControlFlow users:
-
Top-Level API: Marvin 3.0's top-level API is largely unchanged for both Marvin and ControlFlow users.
- Marvin users will find the familiar
marvin.fn,marvin.classify,marvin.extract, and more. - ControlFlow users will use
marvin.Task,marvin.Agent,marvin.run,marvin.Memoryinstead of their ControlFlow equivalents.
- Marvin users will find the familiar
- Pydantic AI: Marvin 3.0 uses Pydantic AI for LLM interactions, and supports the full range of LLM providers that Pydantic AI supports. ControlFlow previously used Langchain, and Marvin 2.0 was only compatible with OpenAI's models.
-
Flow → Thread: ControlFlow's
Flowconcept has been renamed toThread. It works similarly, as a context manager. The@flowdecorator has been removed:import marvin with marvin.Thread(id="optional-id-for-recovery"): marvin.run("do something") marvin.run("do another thing")
-
Database Changes: Thread/message history is now stored in SQLite. During development:
- No database migrations are currently available; expect to reset data during updates
Here's a more practical example that shows how Marvin can help you build real applications:
import marvin
from pydantic import BaseModel
class Article(BaseModel):
title: str
content: str
key_points: list[str]
# Create a specialized writing agent
writer = marvin.Agent(
name="Writer",
instructions="Write clear, engaging content for a technical audience"
)
# Use a thread to maintain context across multiple tasks
with marvin.Thread() as thread:
# Get user input
topic = marvin.run(
"Ask the user for a topic to write about.",
cli=True
)
# Research the topic
research = marvin.run(
f"Research key points about {topic}",
result_type=list[str]
)
# Write a structured article
article = marvin.run(
"Write an article using the research",
agent=writer,
result_type=Article,
context={"research": research}
)
print(f"# {article.title}\n\n{article.content}")output
Conversation:
Agent: I'd love to help you write about a technology topic. What interests you? It could be anything from AI and machine learning to web development or cybersecurity. User: Let's write about WebAssemblyArticle:
# WebAssembly: The Future of Web Performance WebAssembly (Wasm) represents a transformative shift in web development, bringing near-native performance to web applications. This binary instruction format allows developers to write high-performance code in languages like C++, Rust, or Go and run it seamlessly in the browser. [... full article content ...] Key Points: - WebAssembly enables near-native performance in web browsers - Supports multiple programming languages beyond JavaScript - Ensures security through sandboxed execution environment - Growing ecosystem of tools and frameworks - Used by major companies like Google, Mozilla, and Unity
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for marvin
Similar Open Source Tools
marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.
tambourine-voice
Tambourine is a personal voice interface tool that allows users to speak naturally and have their words appear wherever the cursor is. It is powered by customizable AI voice dictation, providing a universal voice-to-text interface for emails, messages, documents, code editors, and terminals. Users can capture ideas quickly, type at the speed of thought, and benefit from AI formatting that cleans up speech, adds punctuation, and applies personal dictionaries. Tambourine offers full control and transparency, with the ability to customize AI providers, formatting, and extensions. The tool supports dual-mode recording, real-time speech-to-text, LLM text formatting, context-aware formatting, customizable prompts, and more, making it a versatile solution for dictation and transcription tasks.
OpenSpec
OpenSpec is a tool for spec-driven development, aligning humans and AI coding assistants to agree on what to build before any code is written. It adds a lightweight specification workflow that ensures deterministic, reviewable outputs without the need for API keys. With OpenSpec, stakeholders can draft change proposals, review and align with AI assistants, implement tasks based on agreed specs, and archive completed changes for merging back into the source-of-truth specs. It works seamlessly with existing AI tools, offering shared visibility into proposed, active, or archived work.
OpenViking
OpenViking is an open-source Context Database designed specifically for AI Agents. It aims to solve challenges in agent development by unifying memories, resources, and skills in a filesystem management paradigm. The tool offers tiered context loading, directory recursive retrieval, visualized retrieval trajectory, and automatic session management. Developers can interact with OpenViking like managing local files, enabling precise context manipulation and intuitive traceable operations. The tool supports various model services like OpenAI and Volcengine, enhancing semantic retrieval and context understanding for AI Agents.
LangGraph-Expense-Tracker
LangGraph Expense tracker is a small project that explores the possibilities of LangGraph. It allows users to send pictures of invoices, which are then structured and categorized into expenses and stored in a database. The project includes functionalities for invoice extraction, database setup, and API configuration. It consists of various modules for categorizing expenses, creating database tables, and running the API. The database schema includes tables for categories, payment methods, and expenses, each with specific columns to track transaction details. The API documentation is available for reference, and the project utilizes LangChain for processing expense data.
OpenManus
OpenManus is an open-source project aiming to replicate the capabilities of the Manus AI agent, known for autonomously executing complex tasks like travel planning and stock analysis. The project provides a modular, containerized framework using Docker, Python, and JavaScript, allowing developers to build, deploy, and experiment with a multi-agent AI system. Features include collaborative AI agents, Dockerized environment, task execution support, tool integration, modular design, and community-driven development. Users can interact with OpenManus via CLI, API, or web UI, and the project welcomes contributions to enhance its capabilities.
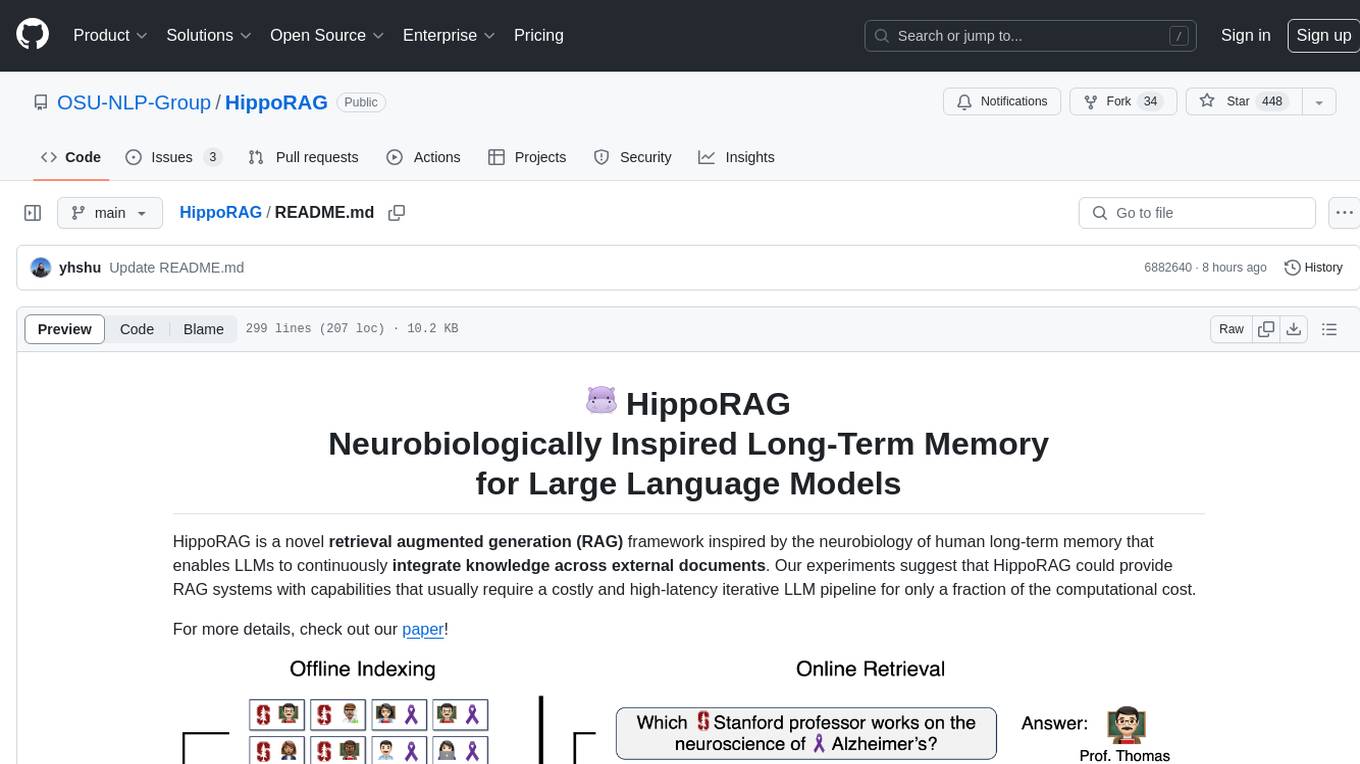
HippoRAG
HippoRAG is a novel retrieval augmented generation (RAG) framework inspired by the neurobiology of human long-term memory that enables Large Language Models (LLMs) to continuously integrate knowledge across external documents. It provides RAG systems with capabilities that usually require a costly and high-latency iterative LLM pipeline for only a fraction of the computational cost. The tool facilitates setting up retrieval corpus, indexing, and retrieval processes for LLMs, offering flexibility in choosing different online LLM APIs or offline LLM deployments through LangChain integration. Users can run retrieval on pre-defined queries or integrate directly with the HippoRAG API. The tool also supports reproducibility of experiments and provides data, baselines, and hyperparameter tuning scripts for research purposes.

rlama
RLAMA is a powerful AI-driven question-answering tool that seamlessly integrates with local Ollama models. It enables users to create, manage, and interact with Retrieval-Augmented Generation (RAG) systems tailored to their documentation needs. RLAMA follows a clean architecture pattern with clear separation of concerns, focusing on lightweight and portable RAG capabilities with minimal dependencies. The tool processes documents, generates embeddings, stores RAG systems locally, and provides contextually-informed responses to user queries. Supported document formats include text, code, and various document types, with troubleshooting steps available for common issues like Ollama accessibility, text extraction problems, and relevance of answers.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe is fully local, keeping code on the user's machine without relying on external APIs. It supports multiple languages, offers various search options, and can be used in CLI mode, MCP server mode, AI chat mode, and web interface. The tool is designed to be flexible, fast, and accurate, providing developers and AI models with full context and relevant code blocks for efficient code exploration and understanding.
twitter-automation-ai
Advanced Twitter Automation AI is a modular Python-based framework for automating Twitter at scale. It supports multiple accounts, robust Selenium automation with optional undetected Chrome + stealth, per-account proxies and rotation, structured LLM generation/analysis, community posting, and per-account metrics/logs. The tool allows seamless management and automation of multiple Twitter accounts, content scraping, publishing, LLM integration for generating and analyzing tweet content, engagement automation, configurable automation, browser automation using Selenium, modular design for easy extension, comprehensive logging, community posting, stealth mode for reduced fingerprinting, per-account proxies, LLM structured prompts, and per-account JSON summaries and event logs for observability.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe supports various features like AI-friendly code extraction, fully local operation without external APIs, fast scanning of large codebases, accurate code structure parsing, re-rankers and NLP methods for better search results, multi-language support, interactive AI chat mode, and flexibility to run as a CLI tool, MCP server, or interactive AI chat.
npcpy
npcpy is a core library of the NPC Toolkit that enhances natural language processing pipelines and agent tooling. It provides a flexible framework for building applications and conducting research with LLMs. The tool supports various functionalities such as getting responses for agents, setting up agent teams, orchestrating jinx workflows, obtaining LLM responses, generating images, videos, audio, and more. It also includes a Flask server for deploying NPC teams, supports LiteLLM integration, and simplifies the development of NLP-based applications. The tool is versatile, supporting multiple models and providers, and offers a graphical user interface through NPC Studio and a command-line interface via NPC Shell.
mcp-ts-template
The MCP TypeScript Server Template is a production-grade framework for building powerful and scalable Model Context Protocol servers with TypeScript. It features built-in observability, declarative tooling, robust error handling, and a modular, DI-driven architecture. The template is designed to be AI-agent-friendly, providing detailed rules and guidance for developers to adhere to best practices. It enforces architectural principles like 'Logic Throws, Handler Catches' pattern, full-stack observability, declarative components, and dependency injection for decoupling. The project structure includes directories for configuration, container setup, server resources, services, storage, utilities, tests, and more. Configuration is done via environment variables, and key scripts are available for development, testing, and publishing to the MCP Registry.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.
LongRecipe
LongRecipe is a tool designed for efficient long context generalization in large language models. It provides a recipe for extending the context window of language models while maintaining their original capabilities. The tool includes data preprocessing steps, model training stages, and a process for merging fine-tuned models to enhance foundational capabilities. Users can follow the provided commands and scripts to preprocess data, train models in multiple stages, and merge models effectively.
AI-Agent-Starter-Kit
AI Agent Starter Kit is a modern full-stack AI-enabled template using Next.js for frontend and Express.js for backend, with Telegram and OpenAI integrations. It offers AI-assisted development, smart environment variable setup assistance, intelligent error resolution, context-aware code completion, and built-in debugging helpers. The kit provides a structured environment for developers to interact with AI tools seamlessly, enhancing the development process and productivity.
For similar tasks
marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
For similar jobs

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.
marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide