
vanna
🤖 Chat with your SQL database 📊. Accurate Text-to-SQL Generation via LLMs using RAG 🔄.
Stars: 10803

Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.
README:
| GitHub | PyPI | Documentation |
|---|---|---|
 |
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.
https://github.com/vanna-ai/vanna/assets/7146154/1901f47a-515d-4982-af50-f12761a3b2ce
Vanna works in two easy steps - train a RAG "model" on your data, and then ask questions which will return SQL queries that can be set up to automatically run on your database.
- Train a RAG "model" on your data.
- Ask questions.

If you don't know what RAG is, don't worry -- you don't need to know how this works under the hood to use it. You just need to know that you "train" a model, which stores some metadata and then use it to "ask" questions.
See the base class for more details on how this works under the hood.
These are some of the user interfaces that we've built using Vanna. You can use these as-is or as a starting point for your own custom interface.
See the documentation for specifics on your desired database, LLM, etc.
If you want to get a feel for how it works after training, you can try this Colab notebook.
pip install vannaThere are a number of optional packages that can be installed so see the documentation for more details.
See the documentation if you're customizing the LLM or vector database.
# The import statement will vary depending on your LLM and vector database. This is an example for OpenAI + ChromaDB
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
# See the documentation for other optionsYou may or may not need to run these vn.train commands depending on your use case. See the documentation for more details.
These statements are shown to give you a feel for how it works.
DDL statements contain information about the table names, columns, data types, and relationships in your database.
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")Sometimes you may want to add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines XYZ as ...")You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")vn.ask("What are the top 10 customers by sales?")You'll get SQL
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;If you've connected to a database, you'll get the table:
| CUSTOMER_NAME | TOTAL_SALES | |
|---|---|---|
| 0 | Customer#000143500 | 6757566.0218 |
| 1 | Customer#000095257 | 6294115.3340 |
| 2 | Customer#000087115 | 6184649.5176 |
| 3 | Customer#000131113 | 6080943.8305 |
| 4 | Customer#000134380 | 6075141.9635 |
| 5 | Customer#000103834 | 6059770.3232 |
| 6 | Customer#000069682 | 6057779.0348 |
| 7 | Customer#000102022 | 6039653.6335 |
| 8 | Customer#000098587 | 6027021.5855 |
| 9 | Customer#000064660 | 5905659.6159 |
You'll also get an automated Plotly chart:

RAG
- Portable across LLMs
- Easy to remove training data if any of it becomes obsolete
- Much cheaper to run than fine-tuning
- More future-proof -- if a better LLM comes out, you can just swap it out
Fine-Tuning
- Good if you need to minimize tokens in the prompt
- Slow to get started
- Expensive to train and run (generally)
-
High accuracy on complex datasets.
- Vanna’s capabilities are tied to the training data you give it
- More training data means better accuracy for large and complex datasets
-
Secure and private.
- Your database contents are never sent to the LLM or the vector database
- SQL execution happens in your local environment
-
Self learning.
- If using via Jupyter, you can choose to "auto-train" it on the queries that were successfully executed
- If using via other interfaces, you can have the interface prompt the user to provide feedback on the results
- Correct question to SQL pairs are stored for future reference and make the future results more accurate
-
Supports any SQL database.
- The package allows you to connect to any SQL database that you can otherwise connect to with Python
-
Choose your front end.
- Most people start in a Jupyter Notebook.
- Expose to your end users via Slackbot, web app, Streamlit app, or a custom front end.
Vanna is designed to connect to any database, LLM, and vector database. There's a VannaBase abstract base class that defines some basic functionality. The package provides implementations for use with OpenAI and ChromaDB. You can easily extend Vanna to use your own LLM or vector database. See the documentation for more details.
https://github.com/vanna-ai/vanna/assets/7146154/eb90ee1e-aa05-4740-891a-4fc10e611cab
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vanna
Similar Open Source Tools
vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
SurfSense
SurfSense is a tool designed to help users save and organize content from the internet into a personal Knowledge Graph. It allows users to capture web browsing sessions and webpage content using a Chrome extension, enabling easy retrieval and recall of saved information. SurfSense offers features like powerful search capabilities, natural language interaction with saved content, self-hosting options, and integration with GraphRAG for meaningful content relations. The tool eliminates the need for web scraping by directly reading data from the DOM, making it a convenient solution for managing online information.
ocular
Ocular is a set of modules and tools that allow you to build rich, reliable, and performant Generative AI-Powered Search Platforms without the need to reinvent Search Architecture. We help you build you spin up customized internal search in days not months.

helix-db
HelixDB is a database designed specifically for AI applications, providing a single platform to manage all components needed for AI applications. It supports graph + vector data model and also KV, documents, and relational data. Key features include built-in tools for MCP, embeddings, knowledge graphs, RAG, security, logical isolation, and ultra-low latency. Users can interact with HelixDB using the Helix CLI tool and SDKs in TypeScript and Python. The roadmap includes features like organizational auth, server code improvements, 3rd party integrations, educational content, and binary quantisation for better performance. Long term projects involve developing in-house tools for knowledge graph ingestion, graph-vector storage engine, and network protocol & serdes libraries.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.
superflows
Superflows is an open-source alternative to OpenAI's Assistant API. It allows developers to easily add an AI assistant to their software products, enabling users to ask questions in natural language and receive answers or have tasks completed by making API calls. Superflows can analyze data, create plots, answer questions based on static knowledge, and even write code. It features a developer dashboard for configuration and testing, stateful streaming API, UI components, and support for multiple LLMs. Superflows can be set up in the cloud or self-hosted, and it provides comprehensive documentation and support.
workbench-example-hybrid-rag
This NVIDIA AI Workbench project is designed for developing a Retrieval Augmented Generation application with a customizable Gradio Chat app. It allows users to embed documents into a locally running vector database and run inference locally on a Hugging Face TGI server, in the cloud using NVIDIA inference endpoints, or using microservices via NVIDIA Inference Microservices (NIMs). The project supports various models with different quantization options and provides tutorials for using different inference modes. Users can troubleshoot issues, customize the Gradio app, and access advanced tutorials for specific tasks.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
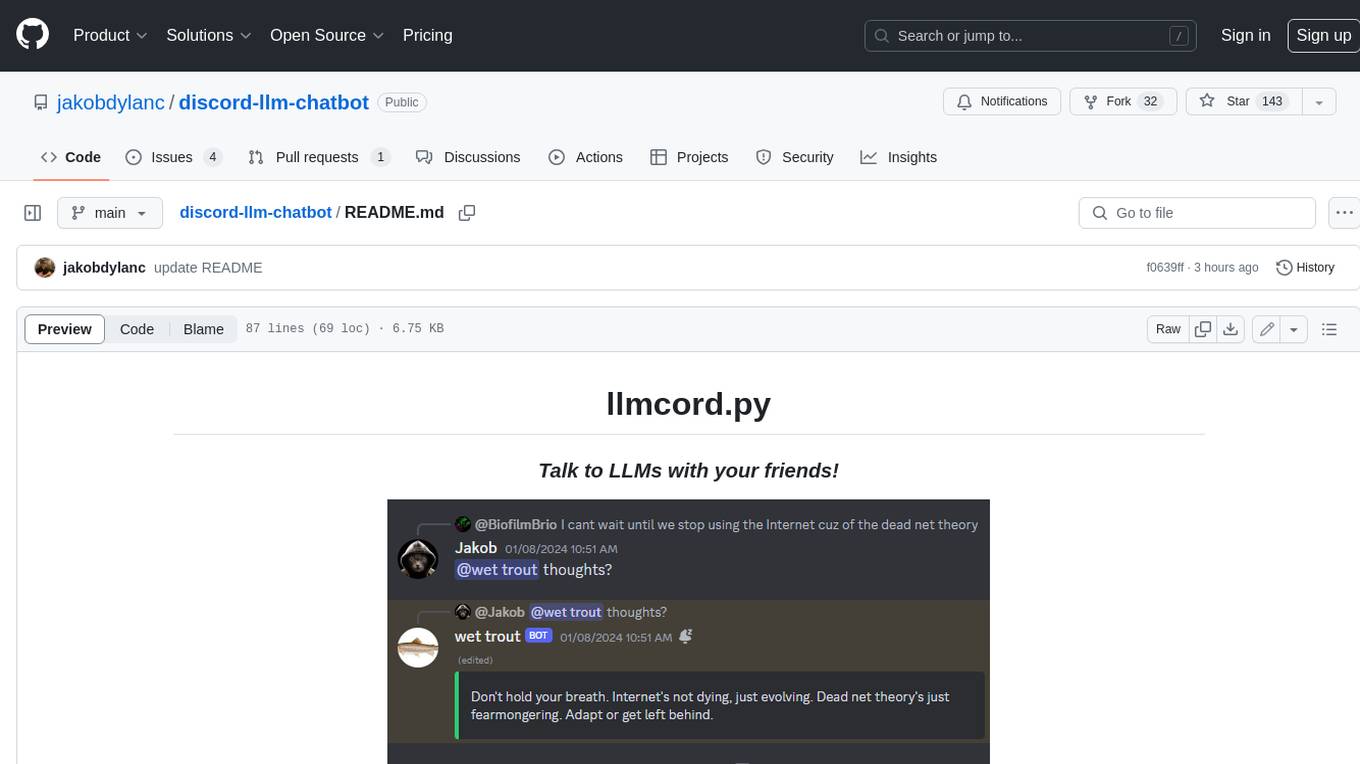
discord-llm-chatbot
llmcord.py enables collaborative LLM prompting in your Discord server. It works with practically any LLM, remote or locally hosted. ### Features ### Reply-based chat system Just @ the bot to start a conversation and reply to continue. Build conversations with reply chains! You can do things like: - Build conversations together with your friends - "Rewind" a conversation simply by replying to an older message - @ the bot while replying to any message in your server to ask a question about it Additionally: - Back-to-back messages from the same user are automatically chained together. Just reply to the latest one and the bot will see all of them. - You can seamlessly move any conversation into a thread. Just create a thread from any message and @ the bot inside to continue. ### Choose any LLM Supports remote models from OpenAI API, Mistral API, Anthropic API and many more thanks to LiteLLM. Or run a local model with ollama, oobabooga, Jan, LM Studio or any other OpenAI compatible API server. ### And more: - Supports image attachments when using a vision model - Customizable system prompt - DM for private access (no @ required) - User identity aware (OpenAI API only) - Streamed responses (turns green when complete, automatically splits into separate messages when too long, throttled to prevent Discord ratelimiting) - Displays helpful user warnings when appropriate (like "Only using last 20 messages", "Max 5 images per message", etc.) - Caches message data in a size-managed (no memory leaks) and per-message mutex-protected (no race conditions) global dictionary to maximize efficiency and minimize Discord API calls - Fully asynchronous - 1 Python file, ~200 lines of code

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.

supallm
Supallm is a Python library for super resolution of images using deep learning techniques. It provides pre-trained models for enhancing image quality by increasing resolution. The library is easy to use and allows users to upscale images with high fidelity and detail. Supallm is suitable for tasks such as enhancing image quality, improving visual appearance, and increasing the resolution of low-quality images. It is a valuable tool for researchers, photographers, graphic designers, and anyone looking to enhance image quality using AI technology.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
For similar tasks
vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.

dataherald
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over structured data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to: * Allow business users to get insights from the data warehouse without going through a data analyst * Enable Q+A from your production DBs inside your SaaS application * Create a ChatGPT plug-in from your proprietary data

WrenAI
WrenAI is a data assistant tool that helps users get results and insights faster by asking questions in natural language, without writing SQL. It leverages Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) technology to enhance comprehension of internal data. Key benefits include fast onboarding, secure design, and open-source availability. WrenAI consists of three core services: Wren UI (intuitive user interface), Wren AI Service (processes queries using a vector database), and Wren Engine (platform backbone). It is currently in alpha version, with new releases planned biweekly.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.
dstoolkit-text2sql-and-imageprocessing
This repository provides sample code for improving RAG applications with rich data sources including SQL Warehouses and documents analysed with Azure Document Intelligence. It includes components for Text2SQL generation and querying, linking Azure Document Intelligence with AI Search for processing complex documents, and deploying AI search indexes. The plugins and skills aim to enhance response quality in RAG applications by accessing and pulling data from SQL tables, drawing insights from complex charts and images, and intelligently grouping similar sentences.
For similar jobs

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.
vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide