
superduper
Superduper: End-to-end framework for building custom AI applications and agents.
Stars: 5022

superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.
README:


Required: Make sure that you have Python 3.10+ installed.
Install the base package:
pip install superduper-framework >= 0.6.0Install a plugin for your databackend:
# at least one or more of the following:
pip install superduper-mongodb >= 0.6.0
# or
pip install superduper-sql >= 0.6.0
# or
pip install superduper-snowflake >= 0.6.0Install additional plugins for your use-case (optional):
pip install superduper-<plugin_name>Right here.
If you have any problems, questions, comments, or ideas:
- Join our Slack (we look forward to seeing you there).
- Search through our GitHub Discussions, or add a new question.
- Comment an existing issue or create a new one.
- Help us to improve Superduper by providing your valuable feedback here!
- Email us at
[email protected]. - Visit our YouTube channel.
- Follow us on Twitter (now X).
- Connect with us on LinkedIn.
- Feel free to contact a maintainer or community volunteer directly!
There are many ways to contribute, and they are not limited to writing code. We welcome all contributions such as:
- Bug reports
- Documentation improvements
- Enhancement suggestions
- Feature requests
- Expanding the tutorials and use case examples
Please see our Contributing Guide for details.
Thanks goes to these wonderful people:
Superduper is open-source and intended to be a community effort, and it wouldn't be possible without your support and enthusiasm. It is distributed under the terms of the Apache 2.0 license. Any contribution made to this project will be subject to the same provisions.
We are looking for nice people who are invested in the problem we are trying to solve to join us full-time. Find roles that we are trying to fill here!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for superduper
Similar Open Source Tools
superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
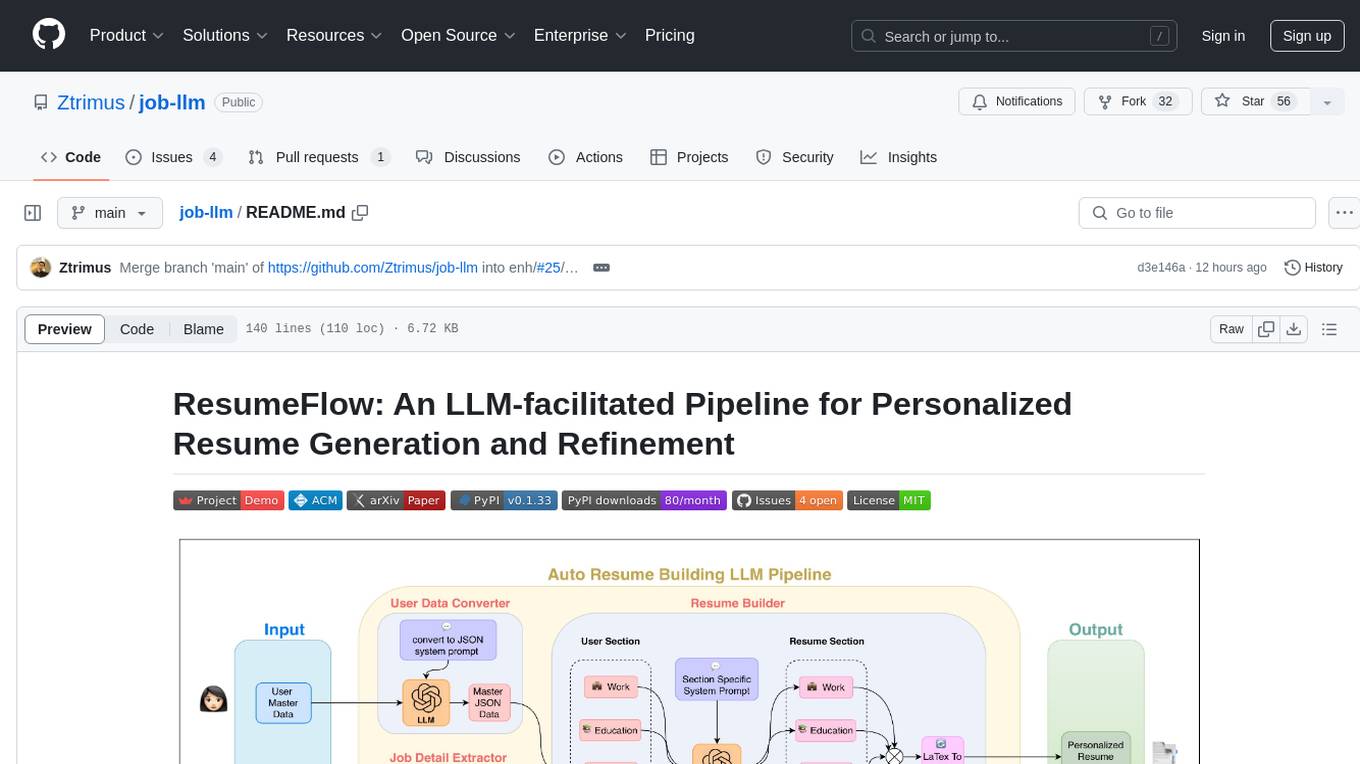
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
langflow
Langflow is an open-source Python-powered visual framework designed for building multi-agent and RAG applications. It is fully customizable, language model agnostic, and vector store agnostic. Users can easily create flows by dragging components onto the canvas, connect them, and export the flow as a JSON file. Langflow also provides a command-line interface (CLI) for easy management and configuration, allowing users to customize the behavior of Langflow for development or specialized deployment scenarios. The tool can be deployed on various platforms such as Google Cloud Platform, Railway, and Render. Contributors are welcome to enhance the project on GitHub by following the contributing guidelines.

kalavai-client
Kalavai is an open-source platform that transforms everyday devices into an AI supercomputer by aggregating resources from multiple machines. It facilitates matchmaking of resources for large AI projects, making AI hardware accessible and affordable. Users can create local and public pools, connect with the community's resources, and share computing power. The platform aims to be a management layer for research groups and organizations, enabling users to unlock the power of existing hardware without needing a devops team. Kalavai CLI tool helps manage both versions of the platform.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
ocular
Ocular is a set of modules and tools that allow you to build rich, reliable, and performant Generative AI-Powered Search Platforms without the need to reinvent Search Architecture. We help you build you spin up customized internal search in days not months.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.
OpenHands
OpenDevin is a platform for autonomous software engineers powered by AI and LLMs. It allows human developers to collaborate with agents to write code, fix bugs, and ship features. The tool operates in a secured docker sandbox and provides access to different LLM providers for advanced configuration options. Users can contribute to the project through code contributions, research and evaluation of LLMs in software engineering, and providing feedback and testing. OpenDevin is community-driven and welcomes contributions from developers, researchers, and enthusiasts looking to advance software engineering with AI.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.
companion-vscode
Quack Companion is a VSCode extension that provides smart linting, code chat, and coding guideline curation for developers. It aims to enhance the coding experience by offering a new tab with features like curating software insights with the team, code chat similar to ChatGPT, smart linting, and upcoming code completion. The extension focuses on creating a smooth contribution experience for developers by turning contribution guidelines into a live pair coding experience, helping developers find starter contribution opportunities, and ensuring alignment between contribution goals and project priorities. Quack collects limited telemetry data to improve its services and products for developers, with options for anonymization and disabling telemetry available to users.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].
Second-Me
Second Me is an open-source prototype that allows users to craft their own AI self, preserving their identity, context, and interests. It is locally trained and hosted, yet globally connected, scaling intelligence across an AI network. It serves as an AI identity interface, fostering collaboration among AI selves and enabling the development of native AI apps. The tool prioritizes individuality and privacy, ensuring that user information and intelligence remain local and completely private.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.
For similar tasks
superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.
devchat
DevChat is an open-source workflow engine that enables developers to create intelligent, automated workflows for engaging with users through a chat panel within their IDEs. It combines script writing flexibility, latest AI models, and an intuitive chat GUI to enhance user experience and productivity. DevChat simplifies the integration of AI in software development, unlocking new possibilities for developers.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
aiwechat-vercel
aiwechat-vercel is a tool that integrates AI capabilities into WeChat public accounts using Vercel functions. It requires minimal server setup, low entry barriers, and only needs a domain name that can be bound to Vercel, with almost zero cost. The tool supports various AI models, continuous Q&A sessions, chat functionality, system prompts, and custom commands. It aims to provide a platform for learning and experimentation with AI integration in WeChat public accounts.
OpenAssistantGPT
OpenAssistantGPT is an open source platform for building chatbot assistants using OpenAI's Assistant. It offers features like easy website integration, low cost, and an open source codebase available on GitHub. Users can build their chatbot with minimal coding required, and OpenAssistantGPT supports direct billing through OpenAI without extra charges. The platform is user-friendly and cost-effective, appealing to those seeking to integrate AI chatbot functionalities into their websites.
ai-demos
The 'ai-demos' repository is a collection of example code from presentations focusing on building with AI and LLMs. It serves as a resource for developers looking to explore practical applications of artificial intelligence in their projects. The code snippets showcase various techniques and approaches to leverage AI technologies effectively. The repository aims to inspire and educate developers on integrating AI solutions into their applications.
orcish-ai-nextjs-framework
The Orcish AI Next.js Framework is a powerful tool that leverages OpenAI API to seamlessly integrate AI functionalities into Next.js applications. It allows users to generate text, images, and text-to-speech based on specified input. The framework provides an easy-to-use interface for utilizing AI capabilities in application development.
python-whatsapp-bot
This repository provides a comprehensive guide on building AI WhatsApp bots using Python and Flask. It covers setting up a Meta developer account, integrating webhook events for real-time message reception, and using OpenAI for AI responses. The tutorial includes steps for selecting phone numbers, sending messages with the API, configuring webhooks, integrating AI into the application, and adding a phone number. It also explains the process of creating a system user, obtaining access tokens, and validating verification requests and payloads for webhook security. The repository aims to help users create intelligent WhatsApp bots with Python and AI capabilities.
For similar jobs

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

ai-lab-recipes
This repository contains recipes for building and running containerized AI and LLM applications with Podman. It provides model servers that serve machine-learning models via an API, allowing developers to quickly prototype new AI applications locally. The recipes include components like model servers and AI applications for tasks such as chat, summarization, object detection, etc. Images for sample applications and models are available in `quay.io`, and bootable containers for AI training on Linux OS are enabled.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.