Best AI tools for< Stream Inference >
20 - AI tool Sites

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
Local AI Playground
Local AI Playground is a free and open-source native app designed for AI management, verification, and inferencing. It allows users to experiment with AI offline in a private environment without the need for a GPU. The application is memory-efficient and compact, with a Rust backend, making it suitable for various operating systems. It offers features such as CPU inferencing, model management, and digest verification. Users can start a local streaming server for AI inferencing with just two clicks. Local AI Playground aims to simplify the AI development process and provide a user-friendly experience for both offline and online AI applications.

Outspeed
Outspeed is a platform for Realtime Voice and Video AI applications, providing networking and inference infrastructure to build fast, real-time voice and video AI apps. It offers tools for intelligence across industries, including Voice AI, Streaming Avatars, Visual Intelligence, Meeting Copilot, and the ability to build custom multimodal AI solutions. Outspeed is designed by engineers from Google and MIT, offering robust streaming infrastructure, low-latency inference, instant deployment, and enterprise-ready compliance with regulations such as SOC2, GDPR, and HIPAA.
Tangia
Tangia is an interactive streaming platform that offers custom TTS interactions, alerts, media sharing, monitor overlay, and Discord integration for streamers. It provides streamers with a wide range of tools to engage their audience, including AI TTS in their own voice, memes showing up on stream, hype parties at every level reached, adding soundbites from Twitch clips, and leaderboards with challenges. Tangia aims to enhance the streaming experience by enabling streamers to create interactive and entertaining content effortlessly.
Be.Live
Be.Live is a livestreaming studio that allows users to create beautiful livestreams and repurpose them into shorter videos and podcasts. It enables users to host live talk shows, invite guests on screen, and customize their streams with branding elements. With features like screen sharing, on-screen elements, and mobile streaming app, Be.Live aims to help coaches, hosts, infopreneurs, and influencers consistently produce and repurpose video content to engage their audience effectively.

StreamRoutine
StreamRoutine is an AI-powered application designed to assist streamers in organizing, planning, and enhancing their streaming experience. It offers a range of features such as task management, community engagement tracking, personalized advice generation, and deep integration with ChatGPT for instant feedback. StreamRoutine aims to streamline the streaming process and help creators deliver top-notch content to their audience.
Vengo AI
Vengo AI is a cutting-edge B2B SaaS platform that democratizes AI creation, making it accessible for everyone, from influencers and brands to entrepreneurs and businesses. The platform offers a white glove service that allows users to easily integrate sophisticated AI identities into their websites with just one line of code. By joining the innovative community, members unlock the potential to create, customize, and monetize their digital twins, significantly enhancing their digital presence and generating new streams of passive income. Vengo AI acts as a dedicated agency, providing a free service to help users monetize their content effortlessly by creating personalized, monetizable digital twins using advanced AI. The platform excels in providing advanced customization and personalization for AI identities, ensuring that each digital twin mirrors the unique voice and personality of its creator. Vengo AI also offers tools to strategically enhance brands by leveraging the power of AI, enabling meaningful engagement with the audience.

VidLab Store
VidLab Store is an AI-powered platform offering premium tools to simplify video creation and editing processes. The platform provides various AI-driven solutions such as AI Short Video Generator, AI Voiceover for Video Creators, Embed TikTok Live for WordPress, Realistic Text-to-Speech SaaS, and TikTok Video Downloader Without Watermark for WordPress. Users can enhance their video content with advanced AI technology, making the video creation process efficient and effective.
Bento
Bento is a personalized 'Link in Bio' platform that allows users to showcase all aspects of their creativity in one beautiful page. Users can display their videos, podcasts, newsletters, photos, paid products, streams, and calendar all in one place, eliminating the need for multiple links. Bento is designed for creatives to easily share their content with their audience and monetize their work. The platform is free to use and offers a unique link for each user to customize their page.
BrandGhost
BrandGhost is an all-in-one social media management tool designed for creators to grow their following and engagement. It offers features such as post scheduling, topic streams, unified feed, visualizations, and content recycling. With BrandGhost, users can automate content posting, manage social interactions efficiently, and maintain brand consistency across multiple platforms.
AutomaticShorts
AutomaticShorts is an AI-powered platform that enables users to run a faceless channel on autopilot, leveraging their following to generate passive income through ad revenue, sponsors, affiliates, and more. The platform automates the process of shooting, voicing, and editing videos, allowing creators to focus on monetization strategies and audience engagement. With features like series creation, video customization, performance analysis, and passive income generation, AutomaticShorts empowers creators to effortlessly grow their online presence and revenue streams.

Stream
Stream is an AI application developed by the Tensorplex Team to showcase the capabilities of existing Bittensor Subnets in powering consumer Web3 platforms. The application is designed to provide precise summaries and deep insights by utilizing the TPLX-LLM model. Stream offers a curated list of podcasts that are summarized using the Bittensor Network.
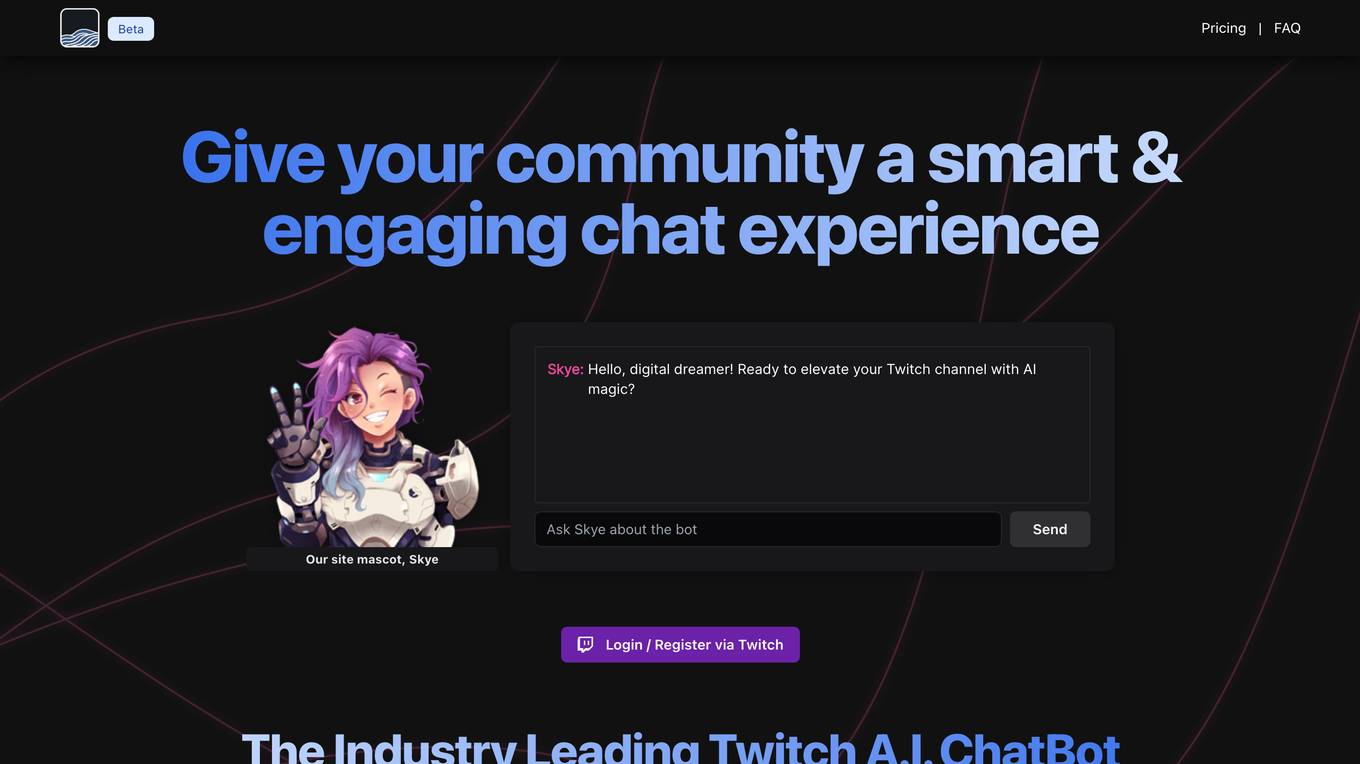
Stream Chat A.I.
Stream Chat A.I. is an AI-powered Twitch chat bot that provides a smart and engaging chat experience for communities. It offers unique features such as a fully customizable chat-bot with a unique personality, bespoke overlays for multimedia editing, custom !commands for boosting interaction, and ongoing development with community input. The application is not affiliated with Twitch Interactive, Inc. and encourages user creativity and engagement.
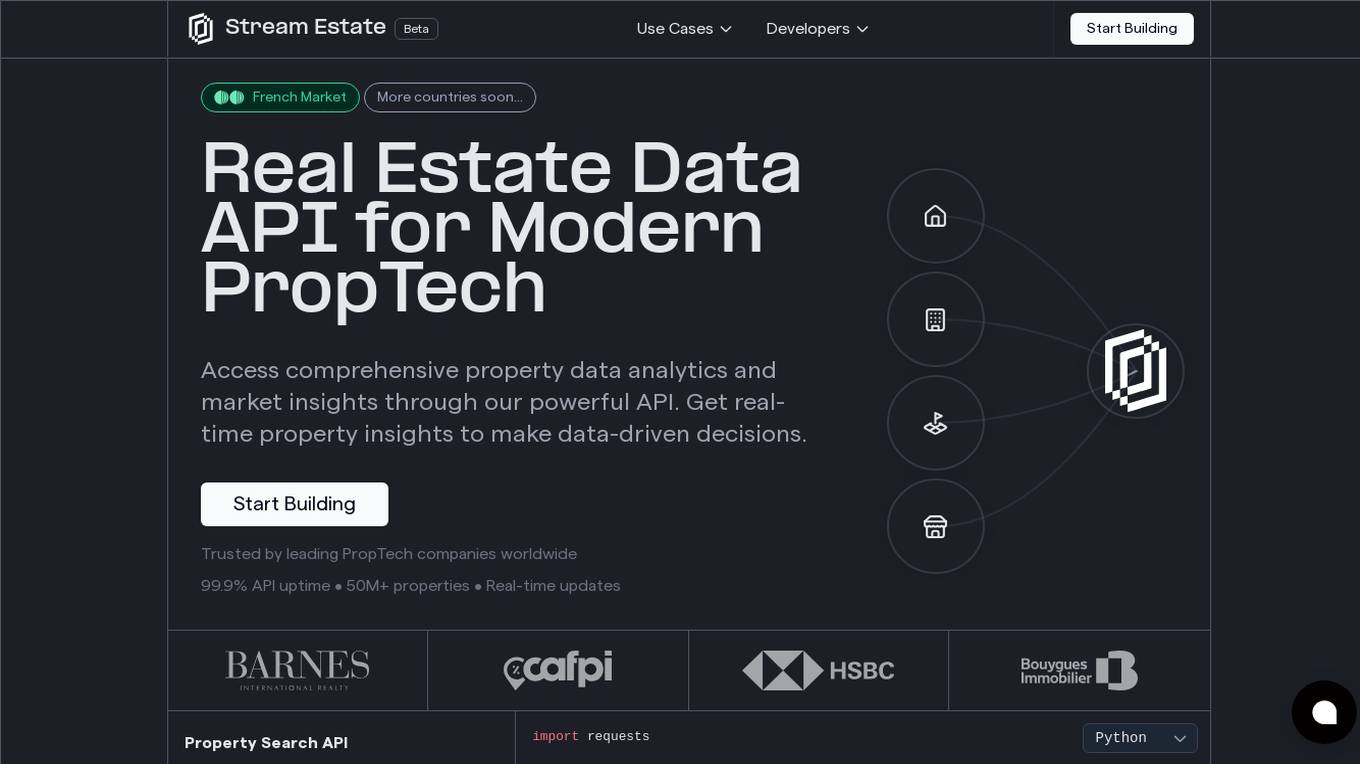
Stream.Estate
Stream.Estate is a Real Estate Data API application that provides comprehensive property data analytics and market insights through a powerful API. Users can access real-time property insights to make data-driven decisions. The application offers features such as property matching, valuation systems, market intelligence, portfolio analytics, property search API, price evolution analytics, real-time property alerts, smart property sourcing, intelligent valuation engine, and automated lead generation. Stream.Estate is trusted by leading PropTech companies worldwide and offers simple pricing plans for different usage levels.
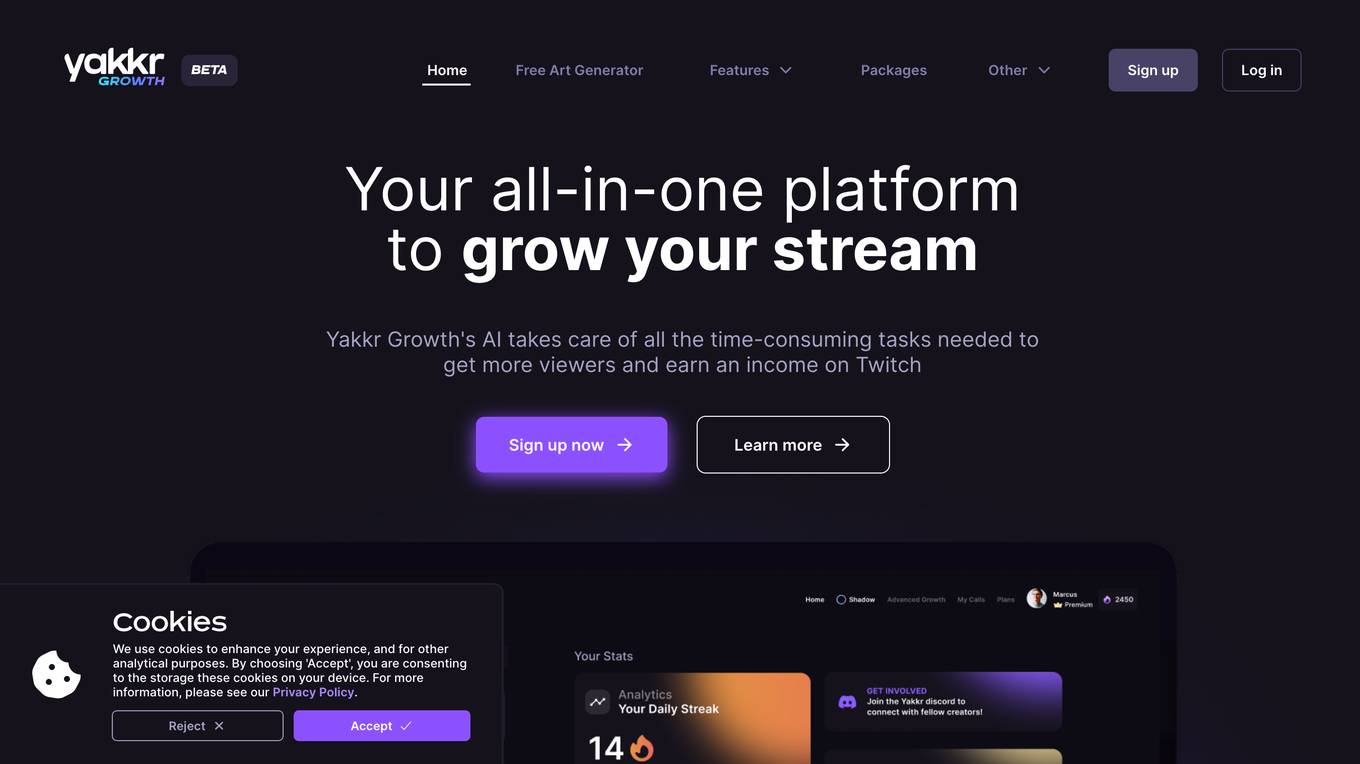
Yakkr Growth
Yakkr Growth is an AI-powered platform designed to help streamers grow their online presence on Twitch. The platform offers a range of features to save time, boost motivation, and help streamers increase viewership and income. With the help of AI assistant Shadow, users can create engaging social media content, optimize stream titles, generate event ideas, and more. Yakkr Growth also provides consultancy, mentorship, and community collaboration to support streamers in achieving their growth goals.
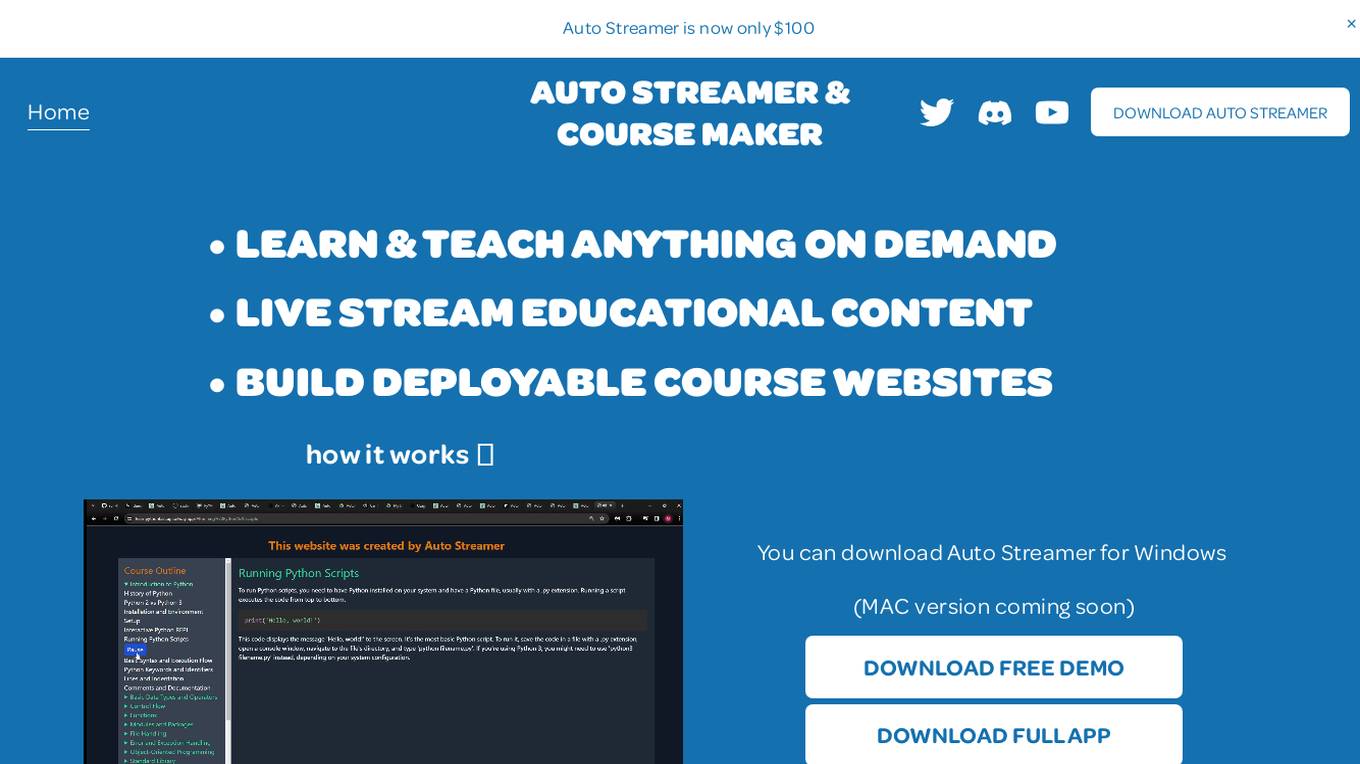
Auto Streamer & Course Maker
Auto Streamer & Course Maker is an AI tool that allows users to create and stream educational content effortlessly. It enables users to generate complete web courses with audio, supports over 50 languages, and offers customizable course presentation options. With Auto Streamer, users can break language barriers, personalize teaching portals, and control course density. The tool is visually appealing, with dark and light mode options, and allows users to define course length and content depth. Auto Streamer requires an OpenAI API key for text and audio content generation.
Wave.video
Wave.video is an online video editor and hosting platform that allows users to create, edit, and host videos. It offers a wide range of features, including a live streaming studio, video recorder, stock library, and video hosting. Wave.video is easy to use and affordable, making it a great option for businesses and individuals who need to create high-quality videos.
Swapface
Swapface is an AI-powered face swapping app that lets you create realistic face swaps with just a few taps. With Swapface, you can swap your face with celebrities, friends, or even animals. The app uses advanced artificial intelligence to seamlessly blend your face onto another person's body, creating hilarious and shareable results.

FragCut
FragCut is an AI-powered gaming clip generator that allows users to effortlessly create high-quality clips from their gameplay videos. The tool automatically detects and edits the best moments, converts footage to vertical format, adds subtitles, creates montages, and offers frame-level precision adjustments. With the ability to generate multiple clips from a single video, FragCut empowers creators to produce engaging content for platforms like TikTok and Reels. Users can easily transform raw gameplay into viral stories, control the narrative, and batch produce content using a user-friendly dashboard.
Magicam
Magicam is an advanced AI tool that offers the ultimate real-time face swap solution. It uses cutting-edge technology to seamlessly swap faces in real-time, providing users with a fun and engaging experience. With Magicam, you can transform your face into anyone else's instantly, whether it's a celebrity, a friend, or a fictional character. The application is user-friendly and requires no technical expertise to use. It is perfect for creating entertaining videos, taking hilarious selfies, or simply having fun with friends and family.
1 - Open Source AI Tools

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.
20 - OpenAI Gpts
Stream Scout
A movie and TV show , Songs & Books recommendation assistant for various streaming platforms.
Stream Strategist
Expert in streaming growth and AI thumbnail prompts, with a human-like style.


Kafka Expert
I will help you to integrate the popular distributed event streaming platform Apache Kafka into your own cloud solutions.
Universal Videos Online Player
Assists in finding online videos with a focus on free options, using a friendly, casual communication style.
Film & Séries FR
Votre assistant pour trouver films et séries en streaming et téléchargement gratuit


Insta360 X3 Coach
Complete beginner's guide to Insta360 X3 with practical tips and tricks.

视频制作小助手
这是大全创作的为哔哩哔哩游戏up主提供游戏视频标题创作、游戏体验内容编写和SEO优化建议的提示词,欢迎关注我的公众号"大全Prompter"领取更多好玩的GPT工具

SteamMaster: Inventor of Ages
Enter a richly detailed steampunk universe in 'SteamMaster: Inventor of Ages'. As an inventor, design and build imaginative steam-powered devices, navigate through a world of Victorian elegance mixed with futuristic technology, and invent solutions to challenges. Another AI Game by Dave Lalande